







《机器学习》系列总结(导学/复习)—第一章 绪论
什么是机器学习?
在日常生活中,我们如果看到天空阴沉、燕子低飞时,可能会说等会可能要下雨;在超市购买苹果,我们会挑选红且没有斑点的苹果,因为我们认为这种苹果会更好吃,更好一点;再例如我们西瓜书全文以西瓜为例,就为了告诉我们如何选西瓜🍉(bushi)。我们通过这些特征/现象(天空阴沉、苹果红、西瓜敲得响),以此预测(或判断)得出一个结论。机器学习也与此类似
机器学习:一种计算机通过“数据”产生“模型”的算法(叫做“学习算法”)。或者数学的角度讲就是构建一个函数。或者说是基于数据进行学习,从数据样本中寻求规律,再利用规律对未来的数据进行预测。比如我们有很多数据,我们把这些经验数据“喂”给它后,它基于数据产生模型,在遇到新情况时,通过模型即能得到一个相应的判断结果。
模型:此处泛指从数据中学到的结果- 理解:类似我们通过很多次的观察发现,有天空阴沉、燕子低飞现象时,会下雨—这就是我们接收的数据。从而我们得到一个“算法”,当发现天阴沉,燕子低飞时,则我们可以预测会下雨
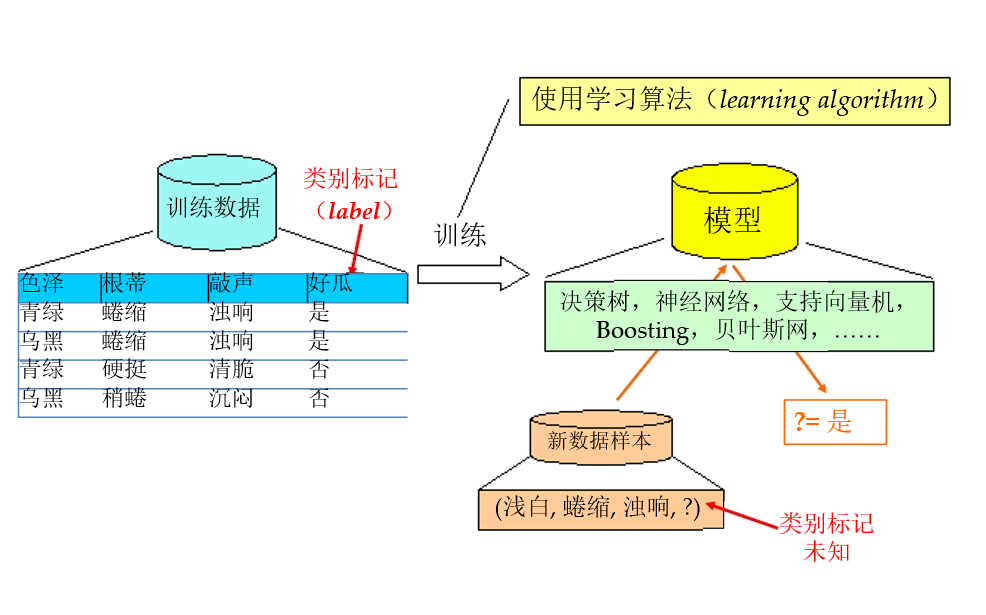
典型的机器学习过程:
- 训练数据(包含类别标记) 使用学习算法(learning algorithm)或者说选择采用某种模型进行训练
- 得到最终的模型(训练得到模型内部的参数)
- 根据最终得到的模型,传入新的数据样本(不含类别标记)
- 输出类别标记
基本术语
-
监督学习和无监督学习:区别在于数据是否有标签
- 监督学习有标签
- 无监督学习无标签
-
数据集、训练集、测试集
- 数据集:所有数据记录的一个集合
- 训练集:训练过程中使用的数据
- 测试集:学得模型后,拿一些确定得数据去测试模型,这些数据构成测试集。注意测试集中的测试例已知它的标签(结果)
-
示例(instance)或样本(sample):数据集中的每一条数据记录
-
属性(attribute)或特征(feature):反应事件或对象在某方面的表现或性质的那些事项。比如西瓜的“色泽”,“敲声”,“根蒂”等,或者说”天气的状况“,”动物的行为“等。
-
属性值(attribute value):在属性上的取值。如”天气晴朗“,”燕子高飞“或者 ” 天气阴沉“,”蚂蚁搬家“或者”青绿“、”响亮“、”乌黑“
-
属性空间、样本空间、输入空间:将多个属性张开成空间。比如“色泽”,“敲声”,“根蒂”分别作为三个坐标轴,形成一个三维空间,把一条记录的这些属性在空间中找到其位置。
-
特征向量:样本空间中点对应的坐标向量
-
标记空间 或 输出空间:预测时,得出样本的结果的标记信息,所标记的集合即为样本空间
-
假设(hypothesis):学得模型对应数据的某种潜在规律
-
真相(ground-truth):潜在规律自身
-
学习器(learner):学习过程中逐渐找出或逼近真相,也可以说就是学习算法在空间中实例化
-
演绎:从一般到特殊—“特化”
-
归纳:从特殊到一般—“泛化”
-
归纳学习:
- 从样例中学习
- (狭义)概念学习
-
版本空间:与训练集一致的假设集合
-
归纳偏好:机器学习算法在学习过程中对某种类型假设的偏好,简而言之就是学习得到哪种模型更好
-
泛化(generalization):模型使用新样本的能力称为泛化能力
泛化(generalization):模型使用新样本的能力称为泛化能力


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











