







需求
pdf文件大多是出版物或者word转换而来,带有页眉页脚,在识别内容的时候,会把页眉页脚的内容识别到,导致内容中包含大量无用信息,可以在识别的时候,根据提前设置的页眉页脚大小,忽略掉此部分内容。
此教程同时也适用指定矩形区域识别。并且识别的结果是按照段落进行识别,避免了文字错乱,文字换行错乱的情况。本教程使用的是pdfbox进行操作。步骤如下:
前提准备
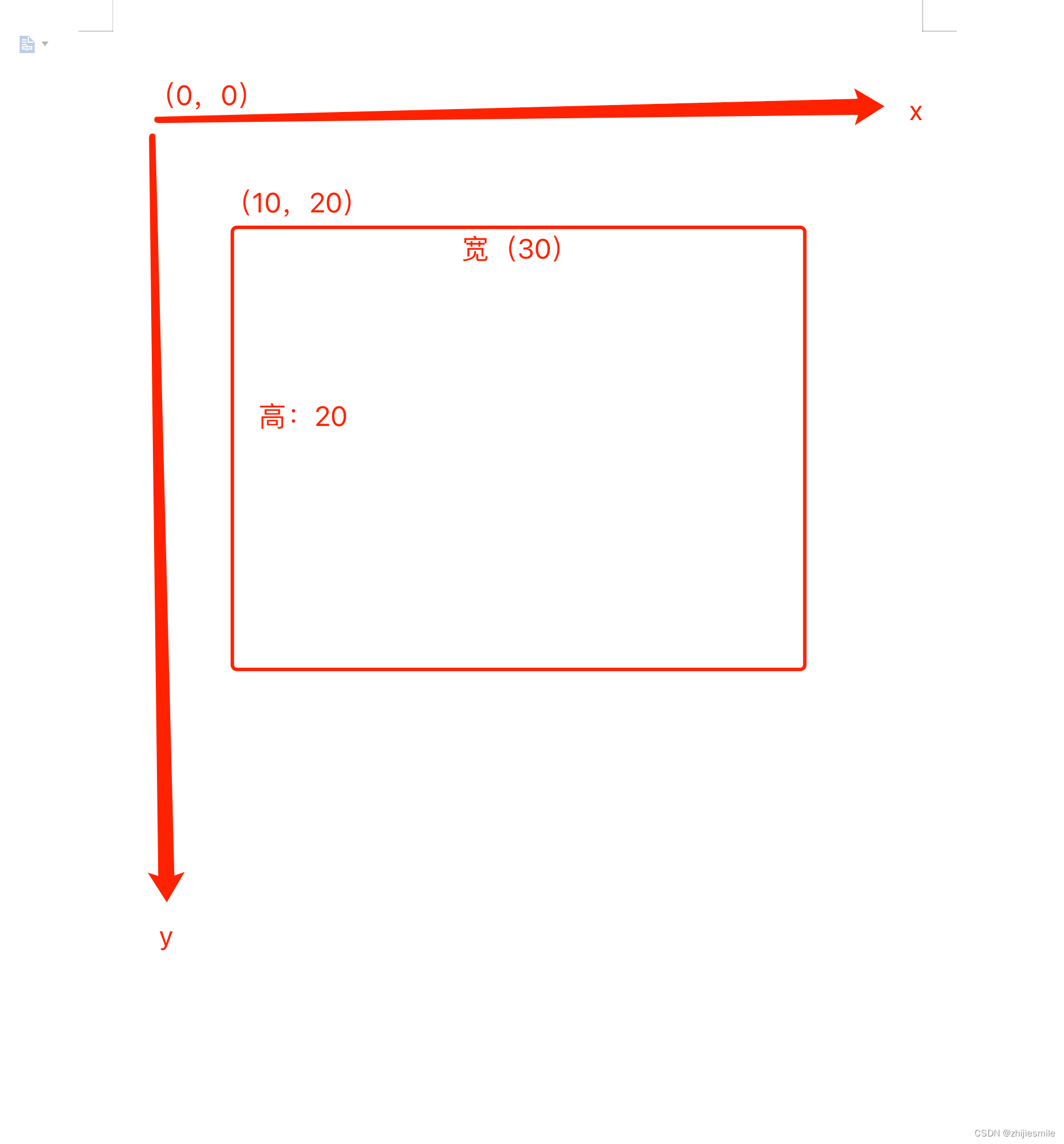
开发者需要了解一个前提,在pdf识别的过程做,坐标系是以左上角为起点(0,0),往右下角是正。
代码示例开始
引入依赖
<dependency>
<!-- 主要是这个依赖包 -->
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.26</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>fontbox</artifactId>
<version>2.0.26</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>jempbox</artifactId>
<version>1.8.16</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>xmpbox</artifactId>
<version>2.0.26</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>preflight</artifactId>
<version>2.0.26</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox-tools</artifactId>
<version>2.0.26</version>
</dependency>
代码示例
以下代码复制到idea中可直接运行:
import org.apache.commons.lang3.StringUtils;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.pdmodel.PDDocumentCatalog;
import org.apache.pdfbox.pdmodel.PDPage;
import org.apache.pdfbox.pdmodel.PDPageTree;
import org.apache.pdfbox.text.PDFTextStripper;
import org.apache.pdfbox.text.PDFTextStripperByArea;
import org.apache.pdfbox.text.TextPosition;
import java.awt.*;
import java.io.File;
import java.io.IOException;
import java.util.List;
public class PdfDemo {
public static void main(String[] args) {
try {
//页眉高度百分比
float headerRate = 0.1F;
//页脚高度百分比
float footerRate = 0.1F;
// 加载PDF文档
PDDocument document = PDDocument.load(new File("这是文档.pdf"));
int pageSize = document.getNumberOfPages();
//获取目录
PDDocumentCatalog catalog = document.getDocumentCatalog();
//获取页码树
PDPageTree pages = catalog.getPages();
for (int i = 0; i < pageSize; i++) {
PDPage page = pages.get(i);
float width = page.getMediaBox().getWidth();
float height = page.getMediaBox().getHeight();
PDFTextStripperByArea stripper = new PDFTextStripperByArea();
//页眉页脚都是??常量的height
float startHeight = height * headerRate;
float endHeight = height - height * headerRate + height * footerRate;
//新建区域,坐标:x,y;宽高:width,height
Rectangle rectangle = new Rectangle(0, (int) startHeight, (int) width, (int) endHeight);
//设置区域
stripper.addRegion("regionName", rectangle);
//提取页面信息
stripper.extractRegions(page);
//获取指定区域名称对应区域的文本
String regionText = stripper.getTextForRegion("regionName");
System.out.println(regionText);
}
// 关闭文档
document.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
rectangle需要设置起始坐标和矩形的长宽。















 3537
3537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











