






一、定义的概述
闭包表(Closure Table)是一种用于存储和查询树形数据结构的技术,它通过在关系表中记录树节点之间的直接和间接关系来表示节点之间的层次结构。闭包表的设计目的是支持高效的树遍历和查询操作。
二、闭包表的特点
闭包表通常是一个包含两个主要列的表:祖先列和后代列。每一行记录都表示一对节点之间的关系,其中祖先列存储父节点(或祖先节点)的标识,后代列存储子节点(或后代节点)的标识。通过在闭包表中插入适当的记录,可以建立节点之间的所有直接和间接关系。
使用闭包表可以快速地确定一个节点的所有祖先节点和后代节点。例如,要查询一个节点的所有后代节点,只需在后代列中查找包含该节点标识的记录。要查询一个节点的所有祖先节点,只需在祖先列中查找包含该节点标识的记录。
闭包表的结构和查询方式使得树的遍历和查询操作变得高效。它避免了在树结构中进行递归或迭代遍历的复杂性,通过简单的数据库查询语句即可完成。
闭包表还具有灵活性和可扩展性。当需要添加、删除或移动节点时,只需对闭包表进行相应的插入、删除或更新操作,而无需修改树结构本身。这种设计使得闭包表适用于动态变化的树结构。
三、闭包表的角色
在闭包表(Closure Table)的设计中,有几个关键角色扮演重要的作用:
节点(Node): 节点是树结构中的元素或实体,可以是任何具体的对象,如组织机构中的部门、分类体系中的分类、评论树中的评论等。每个节点在闭包表中都有唯一的标识符。
关系表(Closure Table): 关系表是存储节点之间关系的表格。它包含两个主要列:祖先列和后代列。每一行记录都表示节点之间的关系,其中祖先列存储父节点(或祖先节点)的标识,后代列存储子节点(或后代节点)的标识。
闭包(Closure): 闭包是指节点之间的直接和间接关系的集合。通过闭包表,可以通过查询祖先列或后代列来获取某个节点的闭包。闭包包含了节点的所有祖先节点和后代节点。
祖先节点(Ancestor): 祖先节点是指一个节点的直接或间接上级节点。在闭包表中,通过查询祖先列可以获得一个节点的所有祖先节点。
后代节点(Descendant): 后代节点是指一个节点的直接或间接下级节点。在闭包表中,通过查询后代列可以获得一个节点的所有后代节点。
四、一个案例演示闭包表
假设有一个组织结构的树形菜单,每个菜单项代表一个部门或子部门,其中包含部门名称和部门ID。我们可以使用闭包表来表示树形结构中的节点关系,并实现分页查询。
下面是一个使用闭包表实现树形结构数据的分页查询的案例。
4.1 闭包表创建
首先,我们创建部门信息表
CREATE TABLE `departments` (
`id` int NOT NULL COMMENT 'ID',
`name` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '部门名称',
`parent_id` int DEFAULT NULL COMMENT '父ID',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='部门表';然后,我们创建闭包表
CREATE TABLE `departments_closure_table` (
`ancestor` int NOT NULL COMMENT '祖先节点',
`descendant` int NOT NULL COMMENT '后代节点',
PRIMARY KEY (`ancestor`,`descendant`),
KEY `fk_descendant` (`descendant`),
CONSTRAINT `fk_ancestor` FOREIGN KEY (`ancestor`) REFERENCES `departments` (`id`) ON DELETE RESTRICT ON UPDATE RESTRICT,
CONSTRAINT `fk_descendant` FOREIGN KEY (`descendant`) REFERENCES `departments` (`id`) ON DELETE RESTRICT ON UPDATE RESTRICT
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='部门信息闭包表';4.2 闭包表数据初始化写入
初始化部门表
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (1, '集团总部', NULL);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (2, '华北总部', 1);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (3, '华南总部', 1);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (4, '华东总部', 1);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (5, '华中总部', 1);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (6, '华西总部', 1);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (7, '北京子公司', 2);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (8, '天津子公司', 2);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (9, '河北子公司', 2);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (10, '广东子公司', 3);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (11, '广西子公司', 3);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (12, '海南子公司', 3);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (13, '四川子公司', 6);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (14, '重庆子公司', 6);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (15, '贵州子公司', 6);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (16, '云南子公司', 6);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (17, '成都办事处', 13);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (18, '广元办事处', 13);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (19, '雅安办事处', 13);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (20, '绵阳办事处', 13);已经填充了departments表,现在我们需要填充闭包表。可以使用下面的SQL初始化(初始化的最大层次随着实际情况变动)。
-- 初始化自身关系
INSERT INTO departments_closure_table (ancestor, descendant, depth)
SELECT id, id, 0
FROM departments;
-- 初始化父子关系
INSERT INTO departments_closure_table (ancestor, descendant, depth)
SELECT ct.ancestor, d.id, ct.depth + 1
FROM departments_closure_table AS ct
JOIN departments AS d ON ct.descendant = d.parent_id
where ct.depth + 1 = 1;
-- 初始化爷孙关系
INSERT INTO departments_closure_table (ancestor, descendant, depth)
SELECT ct.ancestor, d.id, ct.depth + 1
FROM departments_closure_table AS ct
JOIN departments AS d ON ct.descendant = d.parent_id
where ct.depth + 1 = 2;
-- 初始化四代关系
INSERT INTO departments_closure_table (ancestor, descendant, depth)
SELECT ct.ancestor, d.id, ct.depth + 1
FROM departments_closure_table AS ct
JOIN departments AS d ON ct.descendant = d.parent_id
where ct.depth + 1 = 3;也可以这么初始化
INSERT INTO departments_closure_table (ancestor, descendant, depth)
WITH RECURSIVE cte AS (
SELECT id as ancestor, id as descendant, 0 as depth
FROM departments
UNION ALL
SELECT cte.ancestor, departments.id, cte.depth + 1
FROM cte
JOIN departments ON cte.descendant = departments.parent_id
)
SELECT ancestor, descendant, depth
FROM cte
WHERE ancestor != descendant;4.3 闭包表查询
我们可以使用闭包表来进行树形结构的分页查询。假设我们想要按照部门ID升序进行分页查询,每页显示5个部门
SELECT d.*
FROM departments AS d
JOIN departments_closure_table AS ct ON d.id = ct.descendant
WHERE ct.ancestor = 1 -- 根部门的ID
ORDER BY d.id
LIMIT 0, 5;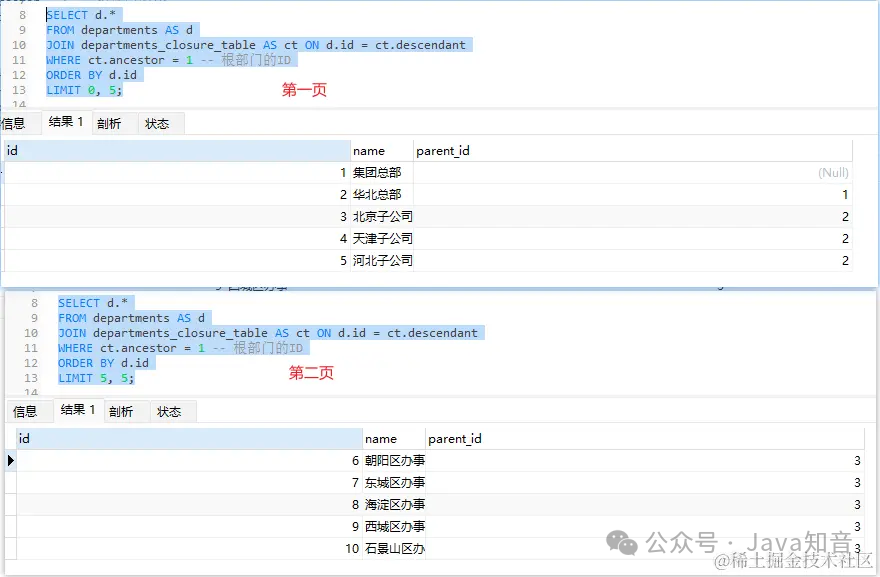
4.4 闭包表的更新
“注意:下面的更新案例是全量的,实际开发中你要带上参数,使用局部更新;切记切记
清空现有的闭包表数据:
DELETE FROM departments_closure_table;使用递归重新生成闭包表数据并插入到departments_closure_table表中:
INSERT INTO departments_closure_table (ancestor, descendant, depth)
WITH RECURSIVE cte AS (
SELECT id, id, 0
FROM departments
UNION ALL
SELECT cte.ancestor, departments.id, cte.depth + 1
FROM cte
JOIN departments ON cte.descendant = departments.parent_id
)
SELECT ancestor, descendant, depth
FROM cte
WHERE ancestor != descendant;五、总结
闭包表是一种用于存储和查询树形数据结构的技术,通过在关系表中记录节点之间的直接和间接关系,实现了高效的树遍历和查询操作。它提供了一种简单而灵活的方法来处理具有父子关系的层次结构数据。
来源|juejin.cn/post/7301155038755160116














 1068
1068











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









