









SQLConf
// This is used to set the default data source
val DEFAULT_DATA_SOURCE_NAME = buildConf("spark.sql.sources.default")
.doc("The default data source to use in input/output.")
.stringConf
.createWithDefault("parquet")
...
def defaultDataSourceName: String = getConf(DEFAULT_DATA_SOURCE_NAME)
...
test case
val df = spark.read.format("ParquetFileFormat").load(parquetFile)
df.show()
df.show() debug 出来的情况
FileScanRDD.scala
private def readCurrentFile(): Iterator[InternalRow] = {
try {
//readFunction 函数
readFunction(currentFile)
} catch {
case e: FileNotFoundException =>
throw new FileNotFoundException(
e.getMessage + "\n" +
"It is possible the underlying files have been updated. " +
"You can explicitly invalidate the cache in Spark by " +
"running 'REFRESH TABLE tableName' command in SQL or " +
"by recreating the Dataset/DataFrame involved.")
}
}
ParquetFileFormat.scala
override def buildReaderWithPartitionValues(
sparkSession: SparkSession,
dataSchema: StructType,
partitionSchema: StructType,
requiredSchema: StructType,
filters: Seq[Filter],
options: Map[String, String],
hadoopConf: Configuration): (PartitionedFile) => Iterator[InternalRow] = {
...
vectorizedReader.initialize(split, hadoopAttemptContext)
...
}
VectorizedParquetRecordReader.java
/**
* Implementation of RecordReader API.
*/
@Override
public void initialize(InputSplit inputSplit, TaskAttemptContext taskAttemptContext)
throws IOException, InterruptedException, UnsupportedOperationException {
super.initialize(inputSplit, taskAttemptContext);
initializeInternal();
}
SpecificParquetRecordReaderBase.java
//super.initialize
@Override
public void initialize(InputSplit inputSplit, TaskAttemptContext taskAttemptContext)
throws IOException, InterruptedException {
...
ReadSupport.ReadContext readContext = readSupport.init(new InitContext(
taskAttemptContext.getConfiguration(), toSetMultiMap(fileMetadata), fileSchema));
...
}
ParquetReadSupport.scala
/**
* Called on executor side before [[prepareForRead()]] and instantiating actual Parquet record
* readers. Responsible for figuring out Parquet requested schema used for column pruning.
*/
override def init(context: InitContext): ReadContext = {
catalystRequestedSchema = {
val conf = context.getConfiguration
val schemaString = conf.get(ParquetReadSupport.SPARK_ROW_REQUESTED_SCHEMA)
assert(schemaString != null, "Parquet requested schema not set.")
StructType.fromString(schemaString)
}
val caseSensitive = context.getConfiguration.getBoolean(SQLConf.CASE_SENSITIVE.key,
SQLConf.CASE_SENSITIVE.defaultValue.get)
val parquetRequestedSchema = ParquetReadSupport.clipParquetSchema(
context.getFileSchema, catalystRequestedSchema, caseSensitive)
new ReadContext(parquetRequestedSchema, Map.empty[String, String].asJava)
}
HadoopMapReduceCommitProtocol
-
When FileOutputCommitter algorithm version set to 1, we firstly move task attempt output files to /path/to/outputPath/.spark-staging-{jobId}/_temporary/{appAttemptId}/{taskId}/a=1/b=1, then move them to /path/to/outputPath/.spark-staging-{jobId}/a=1/b=1.
-
When FileOutputCommitter algorithm version set to 2, committing tasks directly move task attempt output files to /path/to/outputPath/.spark-staging-{jobId}/a=1/b=1.
-
At the end of committing job, we move output files from intermediate path to final path, e.g., move files from /path/to/outputPath/.spark-staging-{jobId}/a=1/b=1 to /path/to/outputPath/a=1/b=1
An FileCommitProtocol implementation backed by an underlying Hadoop OutputCommitter (from the newer mapreduce API, not the old mapred API).
Unlike Hadoop's OutputCommitter, this implementation is serializable.
Params:
jobId – the job's or stage's id
path – the job's output path, or null if committer acts as a noop
dynamicPartitionOverwrite – If true, Spark will overwrite partition directories at runtime dynamically. Suppose final path is /path/to/outputPath, output path of FileOutputCommitter is an intermediate path, e.g. /path/to/outputPath/.spark-staging-{jobId}, which is a staging directory. Task attempts firstly write files under the intermediate path, e.g. /path/to/outputPath/.spark-staging-{jobId}/_temporary/ {appAttemptId}/_temporary/{taskAttemptId}/a=1/b=1/xxx.parquet.
When FileOutputCommitter algorithm version set to 1, we firstly move task attempt output files to /path/to/outputPath/.spark-staging-{jobId}/_temporary/ {appAttemptId}/{taskId}/a=1/b=1, then move them to /path/to/outputPath/.spark-staging-{jobId}/a=1/b=1. 2. When FileOutputCommitter algorithm version set to 2, committing tasks directly move task attempt output files to /path/to/outputPath/.spark-staging-{jobId}/a=1/b=1.
At the end of committing job, we move output files from intermediate path to final path, e.g., move files from /path/to/outputPath/.spark-staging-{jobId}/a=1/b=1 to /path/to/outputPath/a=1/b=1
class HadoopMapReduceCommitProtocol(
jobId: String,
path: String,
dynamicPartitionOverwrite: Boolean = false)
extends FileCommitProtocol with Serializable with Logging {
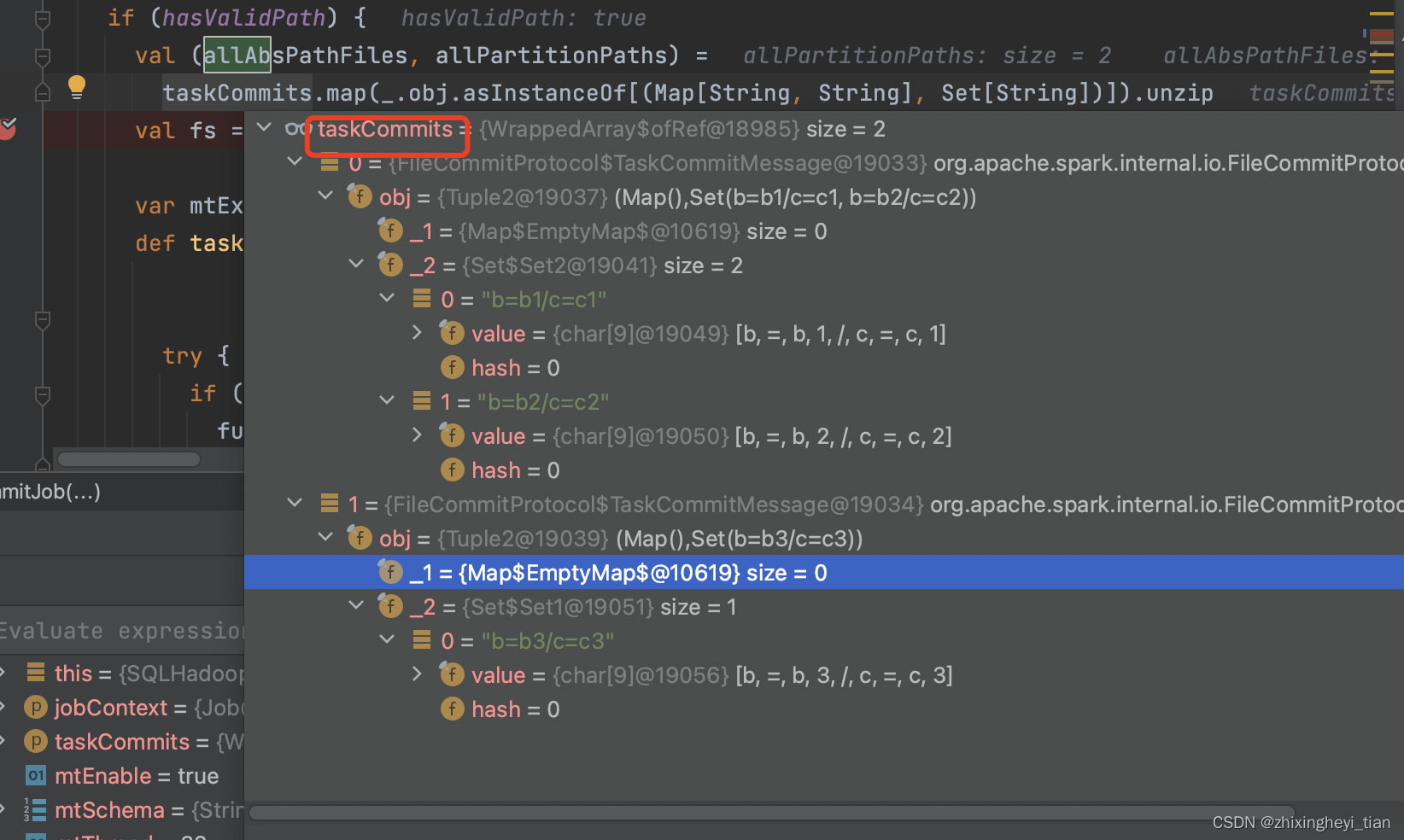
相关变量是这么提取的。
写数据流程
Spark在写出数据的时候,会根据分区为每个分区分配一个任务并将文件以并行方式写出;Spark在写出文件的时候,会为每个任务建立一个临时目录并将数据写到这个临时目录中;等到所有任务的写操作都完成时,Spark会将临时目录以文件移到方式修改为最终目录。具体的流程如图所示。
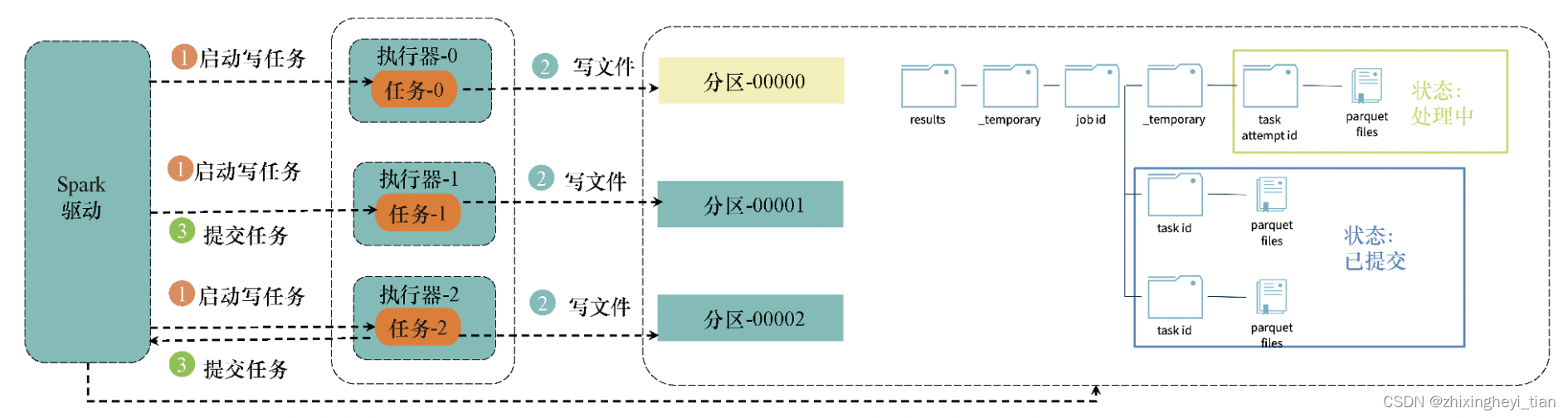
- Spark启动写任务。
- 对于每个任务,并行地将数据写入临时文件。
- 写操作完成后,提交任务到Spark驱动节点,这表示写任务已经完成。
- 当Spark驱动节点接收到所有写任务的“写成功”状态后,便认为所有的写文件操作都已经完成,于是提交写文件作业,并将临时目录以文件移到方式修改为最终目录,这样写文件的过程就完成了。
在写任务失败时重试
在写TB级别的文件时,由于网络原因,磁盘资源不足的问题经常会导致某些写任务失败。在这种情况下,Spark如何保障写任务失败情况下的容错性和数据最终的一致性呢?具体过程如下:当Spark中的某个写任务失败时,就向Spark驱动节点发出终止任务的请求,同时删除写路径下的文件;然后重新启动一个写任务,在新的写任务完成后,再次提交任务;当所有写任务完成后,Spark驱动节点就会提交作业,并将临时目录修改为最终目录;如图所示。
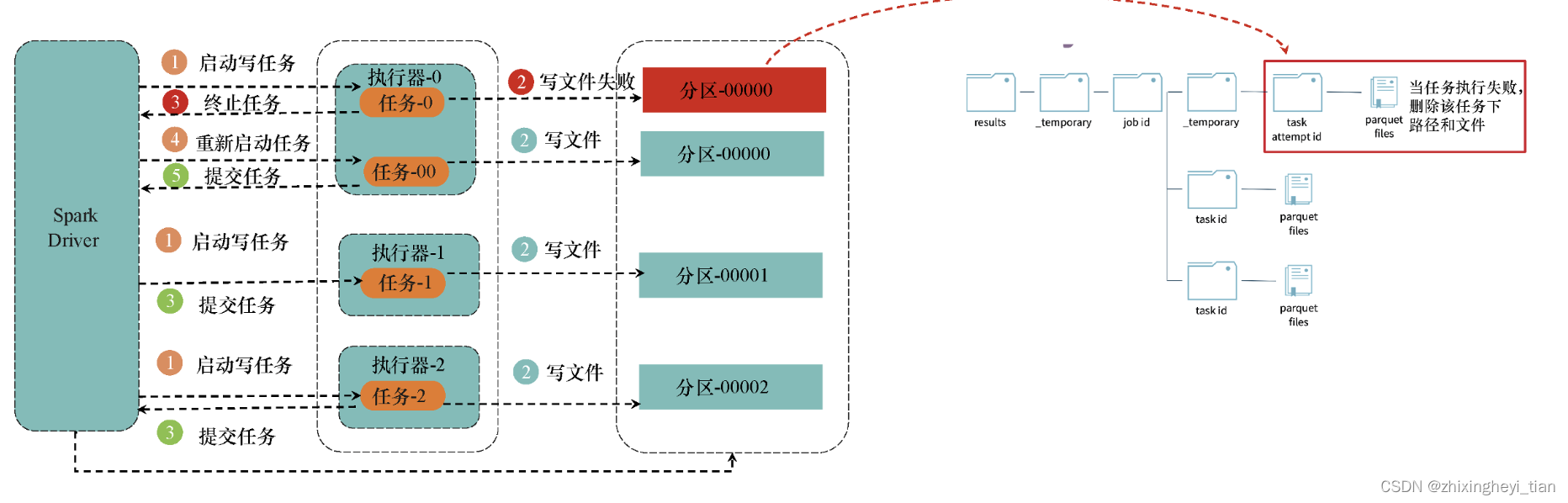
committask
可参见: https://m.dandelioncloud.cn/article/details/1503791675087613953
- 对于spark write作业来说,提交的job task 过程交给了 hadoop 类库:
org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter - getCommittedTaskPath 获取的最终写入的文件名,,视algorithmVersion 而定
public void commitTask(TaskAttemptContext context, Path taskAttemptPath)
throws IOException {
TaskAttemptID attemptId = context.getTaskAttemptID();
if (hasOutputPath()) {
context.progress();
if(taskAttemptPath == null) {
taskAttemptPath = getTaskAttemptPath(context);
}
FileSystem fs = taskAttemptPath.getFileSystem(context.getConfiguration());
FileStatus taskAttemptDirStatus;
try {
taskAttemptDirStatus = fs.getFileStatus(taskAttemptPath);
} catch (FileNotFoundException e) {
taskAttemptDirStatus = null;
}
if (taskAttemptDirStatus != null) {
if (algorithmVersion == 1) {
Path committedTaskPath = getCommittedTaskPath(context);
if (fs.exists(committedTaskPath)) {
if (!fs.delete(committedTaskPath, true)) {
throw new IOException("Could not delete " + committedTaskPath);
}
}
if (!fs.rename(taskAttemptPath, committedTaskPath)) {
throw new IOException("Could not rename " + taskAttemptPath + " to "
+ committedTaskPath);
}
LOG.info("Saved output of task '" + attemptId + "' to " +
committedTaskPath);
} else {
// directly merge everything from taskAttemptPath to output directory
mergePaths(fs, taskAttemptDirStatus, outputPath, context);
LOG.info("Saved output of task '" + attemptId + "' to " +
outputPath);
if (context.getConfiguration().getBoolean(
FILEOUTPUTCOMMITTER_TASK_CLEANUP_ENABLED,
FILEOUTPUTCOMMITTER_TASK_CLEANUP_ENABLED_DEFAULT)) {
LOG.debug(String.format(
"Deleting the temporary directory of '%s': '%s'",
attemptId, taskAttemptPath));
if(!fs.delete(taskAttemptPath, true)) {
LOG.warn("Could not delete " + taskAttemptPath);
}
}
}
} else {
LOG.warn("No Output found for " + attemptId);
}
} else {
LOG.warn("Output Path is null in commitTask()");
}
}
public class ParquetOutputCommitter extends FileOutputCommitter {
private static final Logger LOG = LoggerFactory.getLogger(ParquetOutputCommitter.class);
private final Path outputPath;
public ParquetOutputCommitter(Path outputPath, TaskAttemptContext context) throws IOException {
super(outputPath, context);
this.outputPath = outputPath;
}
debug 进去之后,竟变成了这样,只能看下面的变量了.
出现如下的红色问题,其实就是 pom 对应 hadoop 子版本号和实际compile 的 hadoop.version 有出入,修改下hadoop.version 重新debug 即可。
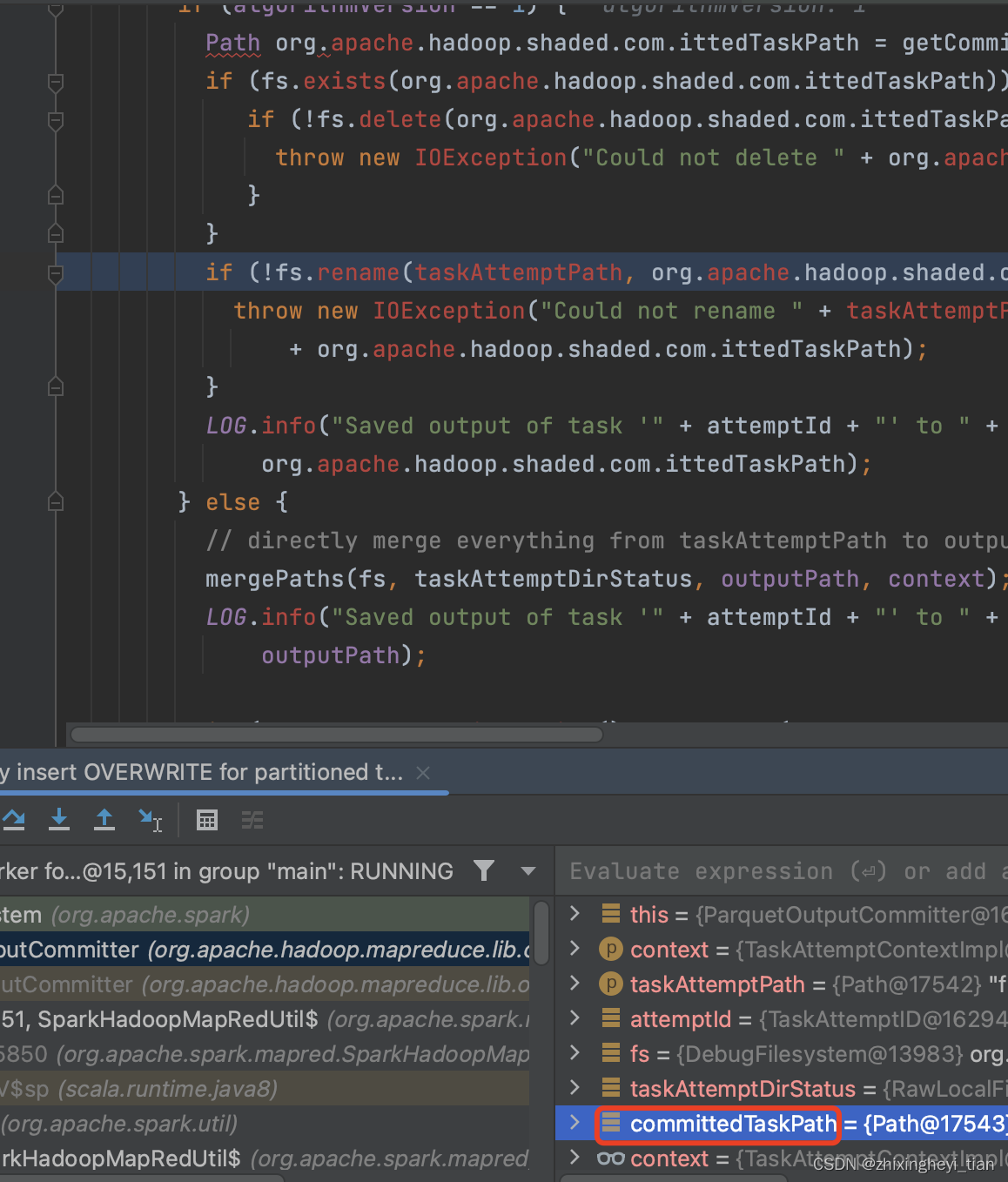
源头在这里触发的
commitTask 会去掉第二个 task level 的 _temporary
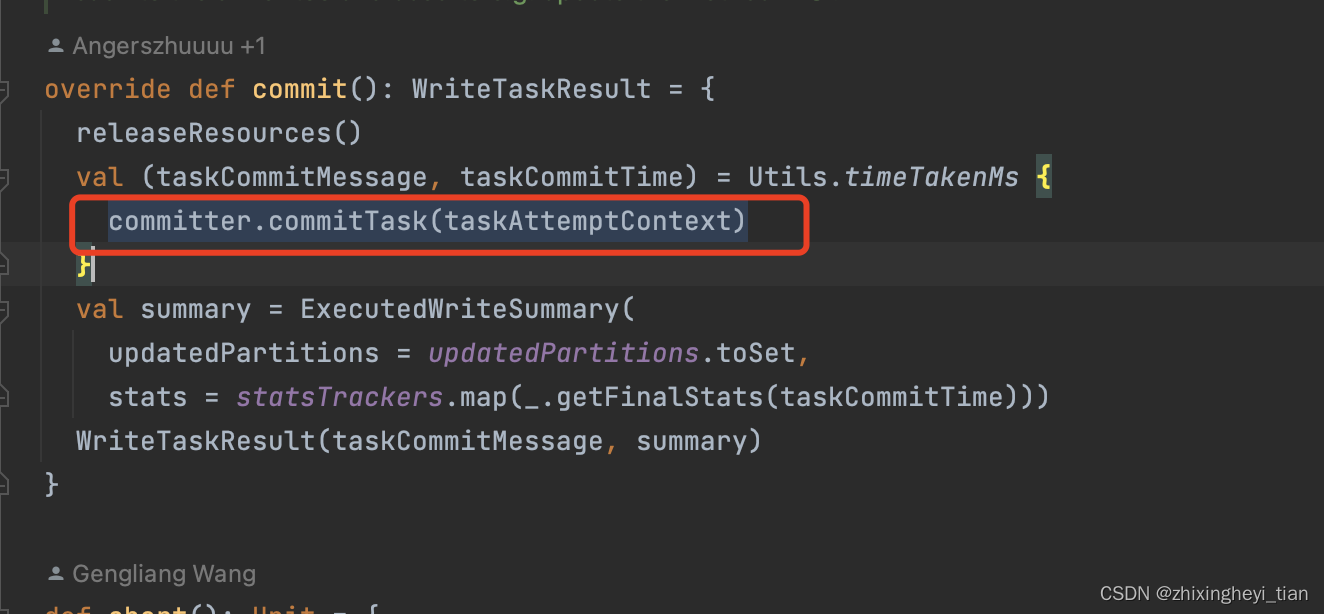
commitJob
committer.commitJob(jobContext) 会去掉第一个 job level 的 _temporary

org.apache.parquet.hadoop.ParquetOutputCommitter
public void commitJob(JobContext jobContext) throws IOException {
super.commitJob(jobContext);
Configuration configuration = ContextUtil.getConfiguration(jobContext);
writeMetaDataFile(configuration,outputPath);
}
这边直接会去掉第一个 _temporary
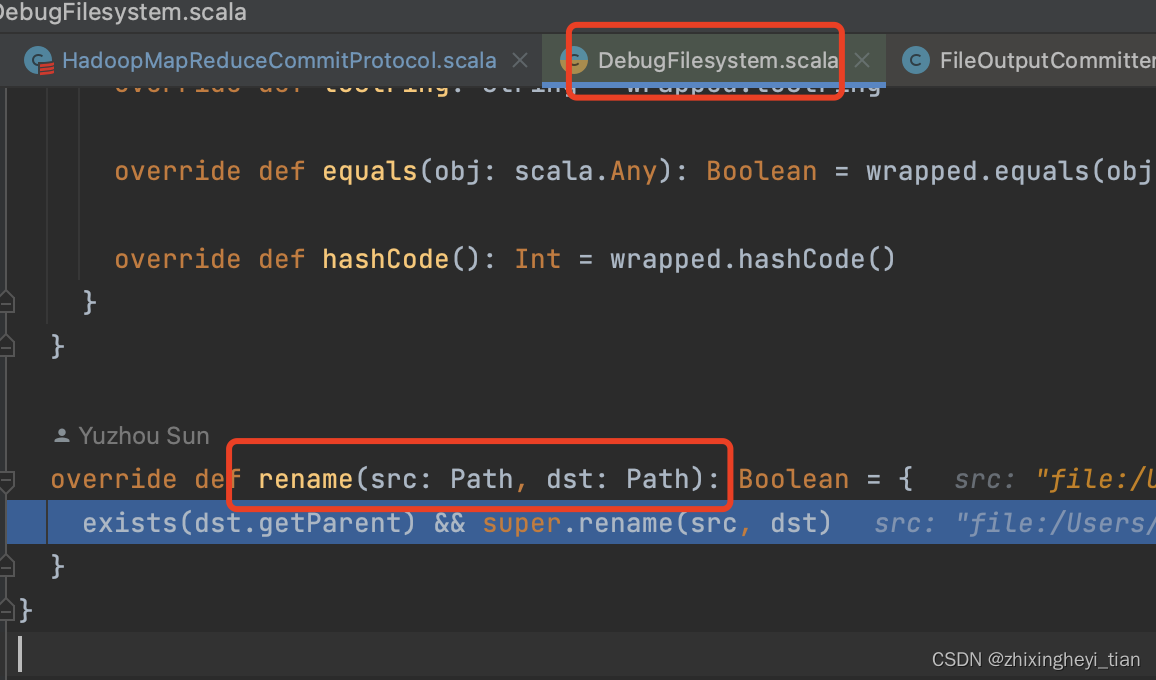
datasource table instert 最后阶段的 rename
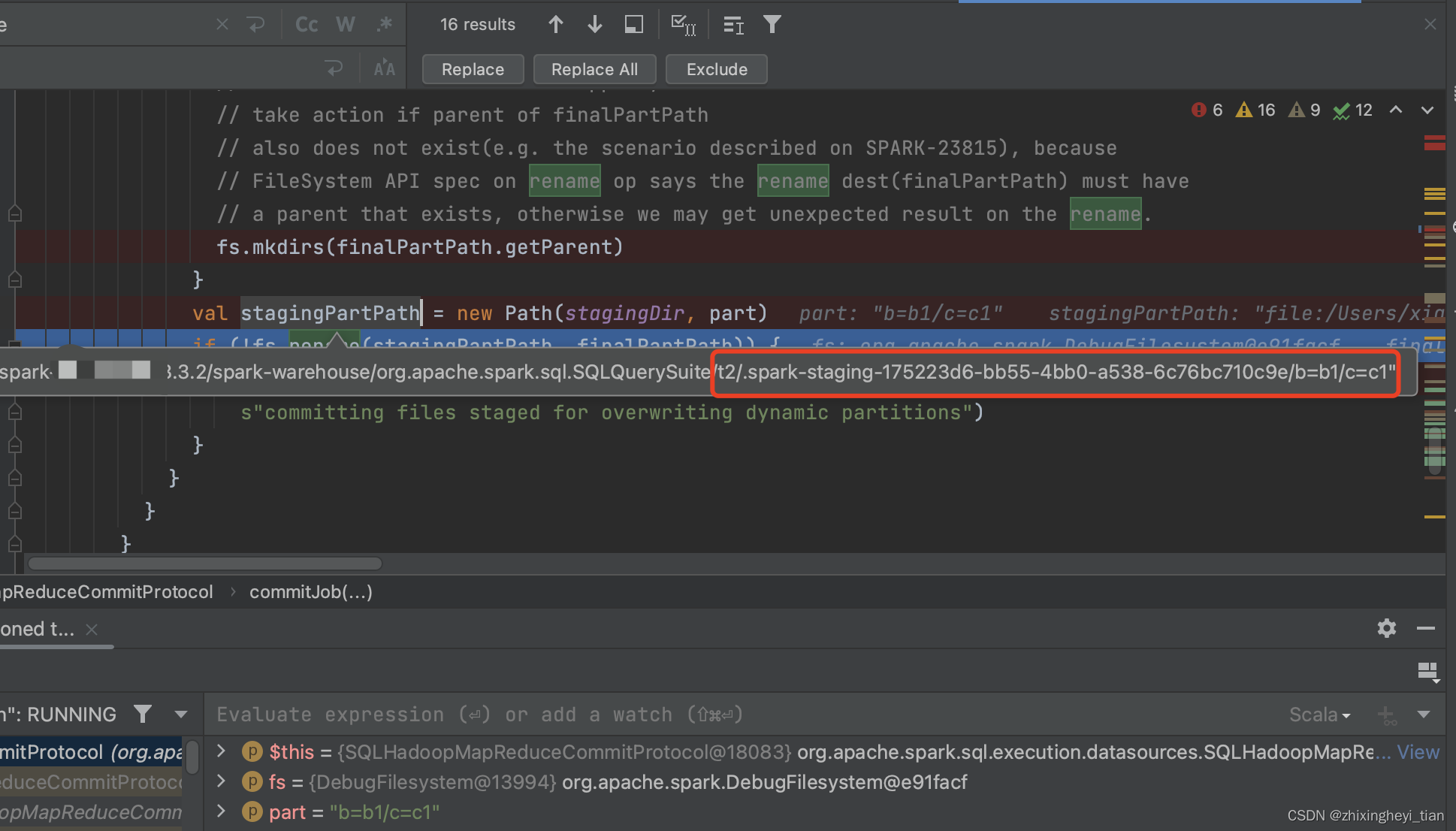
hive table insert
saveAsHiveFile.scala
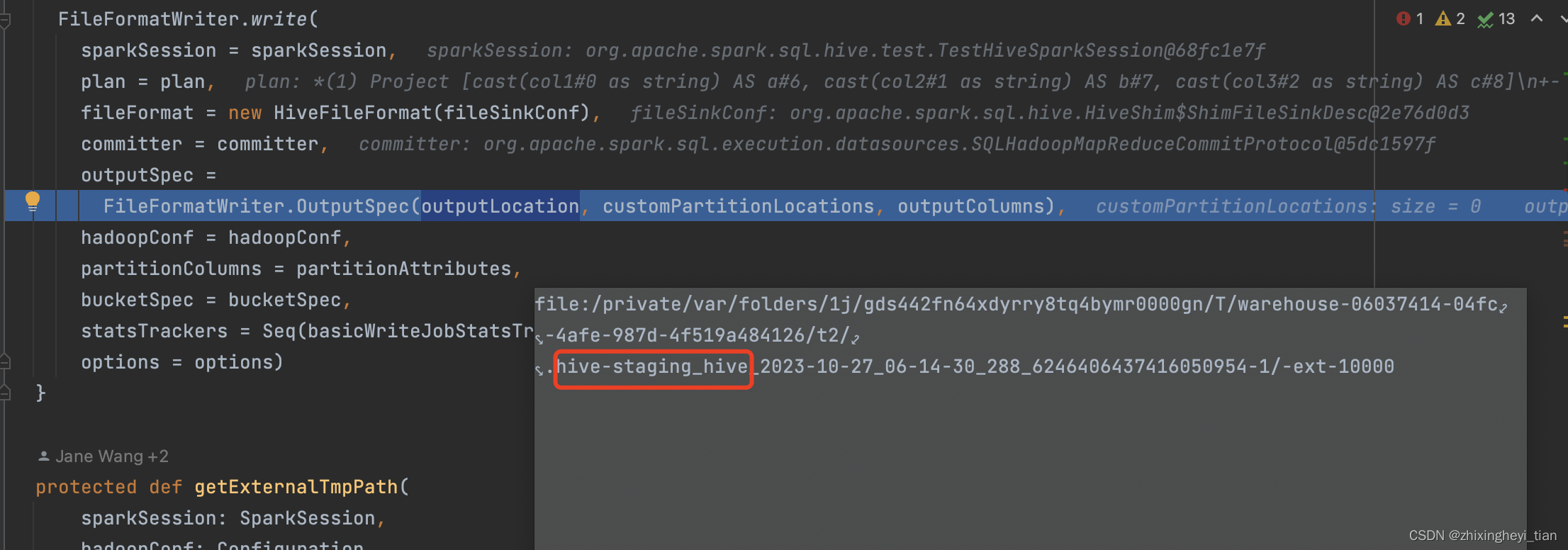
但是依旧会走 datasource. table 的路径 FileFormatWriter.scala
org.apache.spark.sql.execution.datasources.FileFormatWriter
val (_, duration) = Utils.timeTakenMs { committer.commitJob(job, commitMsgs) }
然后走到 HadoopMapReduceCommitProtocol.scala
override def commitJob(jobContext: JobContext, taskCommits: Seq[TaskCommitMessage]): Unit = {
committer.commitJob(jobContext)
堆栈调用如下:
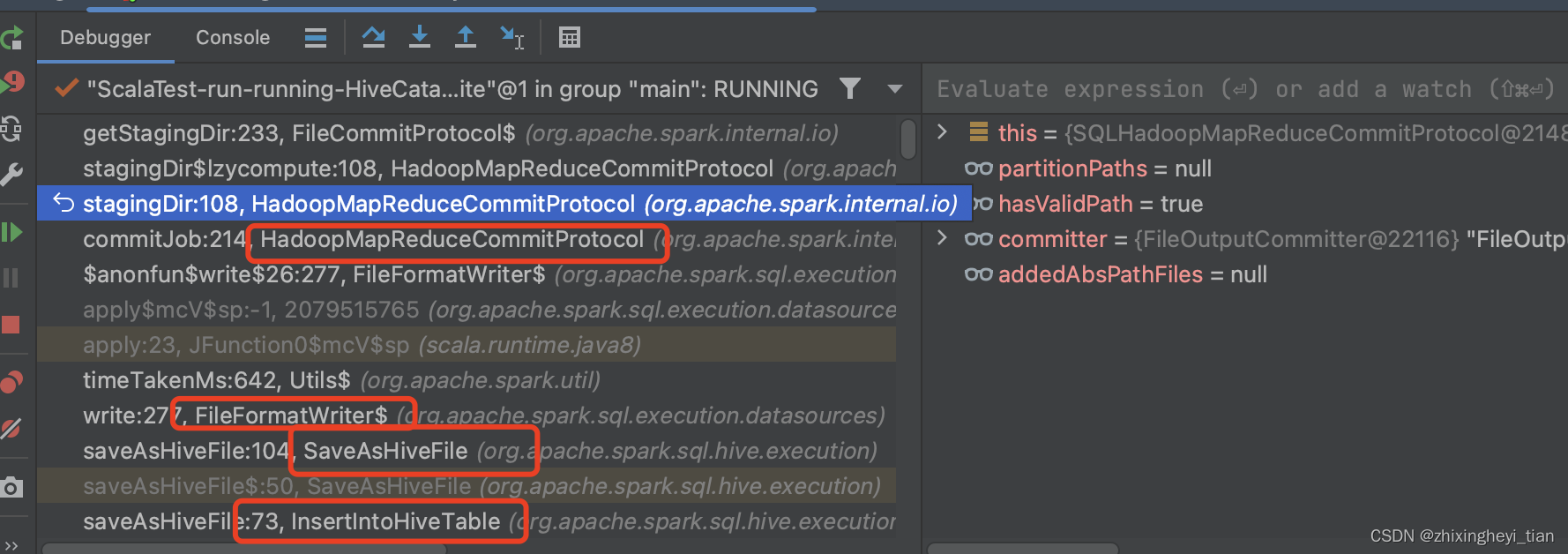
org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
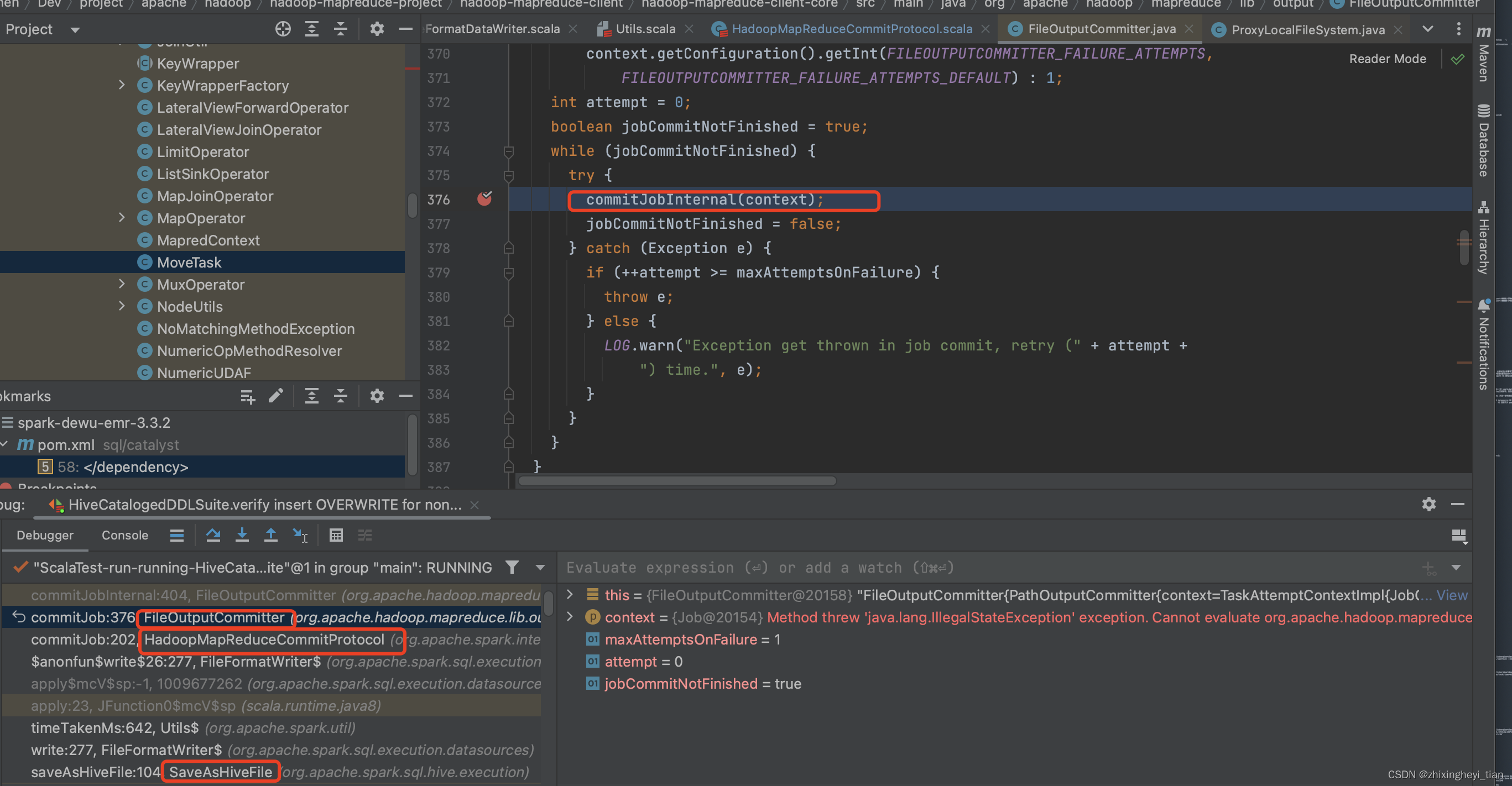
hiveinsert 之 commitjob
org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
/**
* The job has completed, so do works in commitJobInternal().
* Could retry on failure if using algorithm 2.
* @param context the job's context
*/
public void commitJob(JobContext context) throws IOException {
int maxAttemptsOnFailure = isCommitJobRepeatable(context) ?
context.getConfiguration().getInt(FILEOUTPUTCOMMITTER_FAILURE_ATTEMPTS,
FILEOUTPUTCOMMITTER_FAILURE_ATTEMPTS_DEFAULT) : 1;
int attempt = 0;
boolean jobCommitNotFinished = true;
while (jobCommitNotFinished) {
try {
commitJobInternal(context);
jobCommitNotFinished = false;
} catch (Exception e) {
if (++attempt >= maxAttemptsOnFailure) {
throw e;
} else {
LOG.warn("Exception get thrown in job commit, retry (" + attempt +
") time.", e);
}
}
}
}
hive table 之 insert override
入口在这
org.apache.spark.sql.hive.execution.InsertIntoHiveTable
InsertIntoHiveTable 继承于 SaveAsHiveFile
case class InsertIntoHiveTable(
table: CatalogTable,
partition: Map[String, Option[String]],
query: LogicalPlan,
overwrite: Boolean,
ifPartitionNotExists: Boolean,
outputColumnNames: Seq[String]) extends SaveAsHiveFile {
然后在commit job 之后,在 loadTable 接口中 实现 staging 目录 move 到 finalpath
} else {
externalCatalog.loadTable(
table.database,
table.identifier.table,
tmpLocation.toString, // TODO: URI
overwrite,
isSrcLocal = false)
org.apache.spark.sql.hive.HiveExternalCatalog
override def loadTable(
db: String,
table: String,
loadPath: String,
isOverwrite: Boolean,
isSrcLocal: Boolean): Unit = withClient {
requireTableExists(db, table)
client.loadTable(
loadPath,
s"$db.$table",
isOverwrite,
isSrcLocal)
}
org.apache.spark.sql.hive.client
def loadTable(
loadPath: String, // TODO URI
tableName: String,
replace: Boolean,
isSrcLocal: Boolean): Unit = withHiveState {
shim.loadTable(
client,
new Path(loadPath),
tableName,
replace,
isSrcLocal)
}
org.apache.hadoop.hive.ql.metadata.Hive
注意一下接口调用的是 replaceFiles, 且 destf 和 oldPath是填写的一样
/**
* Load a directory into a Hive Table. - Alters existing content of table with
* the contents of loadPath. - If table does not exist - an exception is
* thrown - files in loadPath are moved into Hive. But the directory itself is
* not removed.
*
* @param loadPath
* Directory containing files to load into Table
* @param tableName
* name of table to be loaded.
* @param replace
* if true - replace files in the table, otherwise add files to table
* @param isSrcLocal
* If the source directory is LOCAL
* @param isSkewedStoreAsSubdir
* if list bucketing enabled
* @param hasFollowingStatsTask
* if there is any following stats task
* @param isAcid true if this is an ACID based write
*/
public void loadTable(Path loadPath, String tableName, boolean replace, boolean isSrcLocal,
boolean isSkewedStoreAsSubdir, boolean isAcid, boolean hasFollowingStatsTask)
throws HiveException {
List<Path> newFiles = null;
Table tbl = getTable(tableName);
HiveConf sessionConf = SessionState.getSessionConf();
if (conf.getBoolVar(ConfVars.FIRE_EVENTS_FOR_DML) && !tbl.isTemporary()) {
newFiles = Collections.synchronizedList(new ArrayList<Path>());
}
if (replace) {
Path tableDest = tbl.getPath();
boolean isAutopurge = "true".equalsIgnoreCase(tbl.getProperty("auto.purge"));
replaceFiles(tableDest, loadPath, tableDest, tableDest, sessionConf, isSrcLocal, isAutopurge);
} else {
replaceFiles 接口是区分 destf 和 oldPath
/**
* Replaces files in the partition with new data set specified by srcf. Works
* by renaming directory of srcf to the destination file.
* srcf, destf, and tmppath should resident in the same DFS, but the oldPath can be in a
* different DFS.
* * @param tablePath path of the table. Used to identify permission inheritance.
* @param srcf
* Source directory to be renamed to tmppath. It should be a
* leaf directory where the final data files reside. However it
* could potentially contain subdirectories as well.
* @param destf
* The directory where the final data needs to go
* @param oldPath
* The directory where the old data location, need to be cleaned up. Most of time, will be the same
* as destf, unless its across FileSystem boundaries.
* @param purge
* When set to true files which needs to be deleted are not moved to Trash
* @param isSrcLocal
* If the source directory is LOCAL
*/
protected void replaceFiles(Path tablePath, Path srcf, Path destf, Path oldPath, HiveConf conf,
boolean isSrcLocal, boolean purge) throws HiveException {
try {
- 这里进行了oldpath 的删除
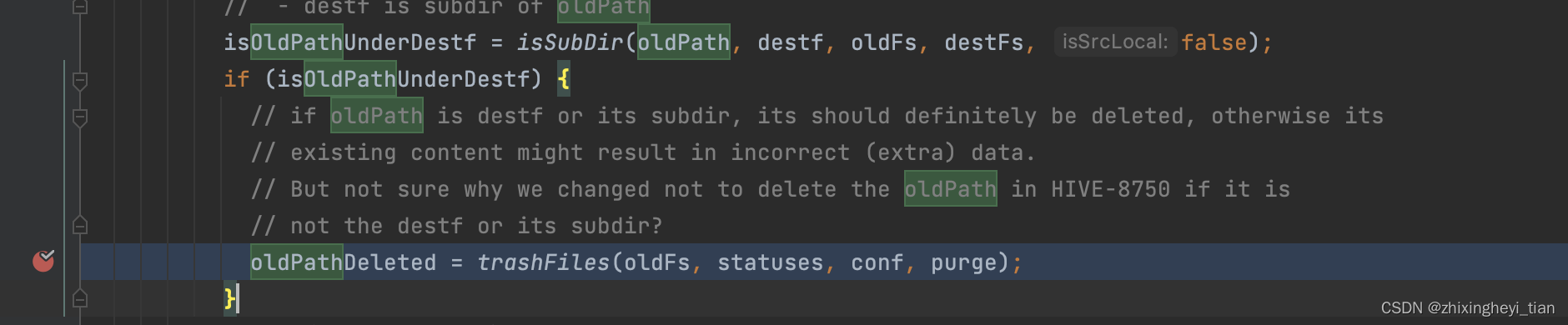
- trashFiles 封装了25个线程,进行删除
/**
* Trashes or deletes all files under a directory. Leaves the directory as is.
* @param fs FileSystem to use
* @param statuses fileStatuses of files to be deleted
* @param conf hive configuration
* @return true if deletion successful
* @throws IOException
*/
public static boolean trashFiles(final FileSystem fs, final FileStatus[] statuses,
final Configuration conf, final boolean purge)
throws IOException {
boolean result = true;
if (statuses == null || statuses.length == 0) {
return false;
}
final List<Future<Boolean>> futures = new LinkedList<>();
final ExecutorService pool = conf.getInt(ConfVars.HIVE_MOVE_FILES_THREAD_COUNT.varname, 25) > 0 ?
Executors.newFixedThreadPool(conf.getInt(ConfVars.HIVE_MOVE_FILES_THREAD_COUNT.varname, 25),
new ThreadFactoryBuilder().setDaemon(true).setNameFormat("Delete-Thread-%d").build()) : null;
final SessionState parentSession = SessionState.get();
for (final FileStatus status : statuses) {
if (null == pool) {
result &= FileUtils.moveToTrash(fs, status.getPath(), conf, purge);
} else {
futures.add(pool.submit(new Callable<Boolean>() {
@Override
public Boolean call() throws Exception {
SessionState.setCurrentSessionState(parentSession);
return FileUtils.moveToTrash(fs, status.getPath(), conf, purge);
}
}));
}
}
if (null != pool) {
pool.shutdown();
for (Future<Boolean> future : futures) {
try {
result &= future.get();
} catch (InterruptedException | ExecutionException e) {
LOG.error("Failed to delete: ",e);
pool.shutdownNow();
throw new IOException(e);
}
}
}
return result;
}
- debug 中显示的delete 方法
org.apache.hadoop.fs.ChecksumFileSystem
/**
* Implement the delete(Path, boolean) in checksum
* file system.
*/
@Override
public boolean delete(Path f, boolean recursive) throws IOException{
FileStatus fstatus = null;
try {
fstatus = fs.getFileStatus(f);
} catch(FileNotFoundException e) {
return false;
}
- replaceFiles 方法 处理完 oldpath,然后调用moveFile接口
org.apache.hadoop.hive.ql.metadata.Hive
//it is assumed that parent directory of the destf should already exist when this
//method is called. when the replace value is true, this method works a little different
//from mv command if the destf is a directory, it replaces the destf instead of moving under
//the destf. in this case, the replaced destf still preserves the original destf's permission
public static boolean moveFile(final HiveConf conf, Path srcf, final Path destf,
boolean replace, boolean isSrcLocal) throws HiveException {
final FileSystem srcFs, destFs;
try {
destFs = destf.getFileSystem(conf);
} catch (IOException e) {
LOG.error("Failed to get dest fs", e);
throw new HiveException(e.getMessage(), e);
}
try {
org.apache.hadoop.hive.ql.metadata.Hive
注意,这边的rename 也是采用了多线程, 以文件为粒度,进行切分task。
//it is assumed that parent directory of the destf should already exist when this
//method is called. when the replace value is true, this method works a little different
//from mv command if the destf is a directory, it replaces the destf instead of moving under
//the destf. in this case, the replaced destf still preserves the original destf's permission
public static boolean moveFile(final HiveConf conf, Path srcf, final Path destf,
boolean replace, boolean isSrcLocal) throws HiveException {
final FileSystem srcFs, destFs;
try {
destFs = destf.getFileSystem(conf);
} catch (IOException e) {
LOG.error("Failed to get dest fs", e);
throw new HiveException(e.getMessage(), e);
}
try {
......
List<Future<Void>> futures = new LinkedList<>();
final ExecutorService pool = conf.getInt(ConfVars.HIVE_MOVE_FILES_THREAD_COUNT.varname, 25) > 0 ?
Executors.newFixedThreadPool(conf.getInt(ConfVars.HIVE_MOVE_FILES_THREAD_COUNT.varname, 25),
new ThreadFactoryBuilder().setDaemon(true).setNameFormat("Move-Thread-%d").build()) : null;
/* Move files one by one because source is a subdirectory of destination */
for (final FileStatus srcStatus : srcs) {
final Path destFile = new Path(destf, srcStatus.getPath().getName());
if (null == pool) {
if(!destFs.rename(srcStatus.getPath(), destFile)) {
throw new IOException("rename for src path: " + srcStatus.getPath() + " to dest:"
+ destf + " returned false");
}
} else {
futures.add(pool.submit(new Callable<Void>() {
@Override
public Void call() throws Exception {
SessionState.setCurrentSessionState(parentSession);
final String group = srcStatus.getGroup();
if(destFs.rename(srcStatus.getPath(), destFile)) {
if (inheritPerms) {
HdfsUtils.setFullFileStatus(conf, desiredStatus, group, destFs, destFile, false);
}
spark.sql.sources.partitionOverwriteMode
需要注意的是,这个配置只对 datasource table 有效,而对 hive table无效。
val PARTITION_OVERWRITE_MODE =
buildConf("spark.sql.sources.partitionOverwriteMode")
.doc("When INSERT OVERWRITE a partitioned data source table, we currently support 2 modes: " +
"static and dynamic. In static mode, Spark deletes all the partitions that match the " +
"partition specification(e.g. PARTITION(a=1,b)) in the INSERT statement, before " +
"overwriting. In dynamic mode, Spark doesn't delete partitions ahead, and only overwrite " +
"those partitions that have data written into it at runtime. By default we use static " +
"mode to keep the same behavior of Spark prior to 2.3. Note that this config doesn't " +
"affect Hive serde tables, as they are always overwritten with dynamic mode. This can " +
"also be set as an output option for a data source using key partitionOverwriteMode " +
"(which takes precedence over this setting), e.g. " +
"dataframe.write.option(\"partitionOverwriteMode\", \"dynamic\").save(path)."
)
.version("2.3.0")
.stringConf
.transform(_.toUpperCase(Locale.ROOT))
.checkValues(PartitionOverwriteMode.values.map(_.toString))
.createWithDefault(PartitionOverwriteMode.STATIC.toString)
对 hive table无效的原因
org.apache.spark.sql.hive.execution.SaveAsHiveFile.scala
Hive table write 数据的操作,最终走SaveAsHiveFile.saveAsHiveFile()这个方法
val committer = FileCommitProtocol.instantiate(
sparkSession.sessionState.conf.fileCommitProtocolClass,
jobId = java.util.UUID.randomUUID().toString,
outputPath = outputLocation)
org.apache.spark.internal.io.FileCommitProtocol.scala
/**
* Instantiates a FileCommitProtocol using the given className.
*/
def instantiate(
className: String,
jobId: String,
outputPath: String,
dynamicPartitionOverwrite: Boolean = false): FileCommitProtocol = {
logDebug(s"Creating committer $className; job $jobId; output=$outputPath;" +
s" dynamic=$dynamicPartitionOverwrite")
val clazz = Utils.classForName[FileCommitProtocol](className)
// First try the constructor with arguments (jobId: String, outputPath: String,
// dynamicPartitionOverwrite: Boolean).
// If that doesn't exist, try the one with (jobId: string, outputPath: String).
try {
val ctor = clazz.getDeclaredConstructor(classOf[String], classOf[String], classOf[Boolean])
logDebug("Using (String, String, Boolean) constructor")
ctor.newInstance(jobId, outputPath, dynamicPartitionOverwrite.asInstanceOf[java.lang.Boolean])
} catch {
case _: NoSuchMethodException =>
logDebug("Falling back to (String, String) constructor")
require(!dynamicPartitionOverwrite,
"Dynamic Partition Overwrite is enabled but" +
s" the committer ${className} does not have the appropriate constructor")
val ctor = clazz.getDeclaredConstructor(classOf[String], classOf[String])
ctor.newInstance(jobId, outputPath)
}
}
因为没有直接设置 dynamicPartitionOverwrite, 所以 “spark.sql.sources.partitionOverwriteMode” 的配置项 对hive 表来说就形同虚设。
对 datasource table 生效的原因
org.apache.spark.sql.execution.datasources.InsertIntoHadoopFsRelationCommand.scala
val committer = FileCommitProtocol.instantiate(
sparkSession.sessionState.conf.fileCommitProtocolClass,
jobId = jobId,
outputPath = outputPath.toString,
dynamicPartitionOverwrite = dynamicPartitionOverwrite)
dynamicPartitionOverwrite 是通过配置直接传递进去的,所以直接生效了。
Job, task 配置获取
spark 相关配置亦可通过TaskAttemptContext 获取
override protected def setupCommitter(context: TaskAttemptContext): OutputCommitter = {
var committer = super.setupCommitter(context)
val configuration = context.getConfiguration
val clazz =
configuration.getClass(SQLConf.OUTPUT_COMMITTER_CLASS.key, null, classOf[OutputCommitter])
val PARTITION_OVERWRITE_MODE = context.getConfiguration.get(
SQLConf.PARTITION_OVERWRITE_MODE.key)
注意事项
通过spark提交的spark开头的配置在程序启动后会添加到SparkConf中,但是hadoop相关的配置非spark开头会被过滤掉,但是只要在这些配置的key前面添加spark.hadoop.前缀,则该key就不会被过滤,会被放置到SparkConf中;最终会存储在Configuration 对象中,存入之前会将 spark.hadoop.前缀截掉
spark-submit --conf spark.hadoop.hbase.zookeeper.quorum
// 在spark应用中如果要是用这些key,只需要添加如下代码即可:
Configuration conf = ss.sparkContext().hadoopConfiguration();
String quorum = conf.get("hbase.zookeeper.quorum");














 1134
1134











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









