







C++标准库在很多地方采用特殊对象处理内存的分配和规划,这样的对象称为分配器(allocator)。allocator表现出一种特殊内存模型,被当成一种用来把内存需求转换为内存低级调用的抽象层。如果在相同时间采用多个不同的allocator对象,就可以在同一个程序中采用不同的内存模型。
C++标准库定义了一个default allocator如下:
template <typename T>
class allocator
这个default allocator可以在allocator得以被当做实参使用的任何地方充当默认值,它会执行内存分配和回收的一般性方法:调用new和delete操作符。但是C++并没有规定在“什么时候以什么形式调用这些操作符”,所以defalte allocato内部可能采用缓存手法分配内存
分配器的基本要求
C++标准库中链表模板的完整参数定义是:
template<class T, class Alloc=allocator<T>> class list;
当省略最后的模板参数时,容器将采用标准中预定义的分配器std::allocator<T>。该分配器调用new/delete操作符申请和释放内存,足以满足大多数需求。而当需要定制容器中的内存操作时,可以按照标准中的分配器规范,将内存操作封装在一个新的分配器类模板中并传入容器,比如:
std::list<my_data, my_allocator<my_data>> custom_list;
标准库中可以接受分配器的容器模板包括:
- 序列型容器
vector、deque、list、forward_list - 集合容器
set、multiset、map、multimap - 散列表容器
unordered_set、unordered_multiset、unordered_map、unordered_multimap
数组容器array、整数集合bitset由于所用内存尺寸固定不变,无须再申请内存,也不支持分配器。容器转换器stack、queue、priority_queue的内存行为则随其所用容器而定。
通过上面模板参数的定义可以看出:
- 分配器是一个类(
class Alloc),而不是函数或者模板 - 分配器是和具体类型相关的,因为默认构造器
std::allocator<T>随容器保存类型的不同而不同。 - 可以想象,分配器的行为应该类型new/delete操作符,而不是malloc/free(前者需要知道空间所存放的类型而后者只关心空间的大小)。
- 具体来说,分配器内至少需要有两个成员函数分别响应容器的申请以及释放内存的请求;另外,由于vector容器需要将数据连续存储并随时调整存储空间大小,则分配器需要能申请给定尺寸的连续内粗努力下(即
new[n]T)而不是malloc(n)
C++标准其实对分配器的要求做了详细规定:
- 首先,分配器必须有如下表所举的嵌套类型定义(假设A为分配器类型,T为器所分配数据类型)
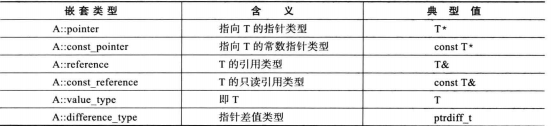
分配器的首要作用是申请与释放内存。通过两个成员函数allocate和deallocate来实现。无论其定义如何,两成员函数必须能够实现如下用法:
a.allocate(n); // 申请能保存n个value_type的数据, 如果申请空间失败,抛出异常std::bad_alloc
a.allocate(n, p);
a.deallocate(p, n); //要释放的空间指针p和空间大小n
- 分配器类还需要提供如下表所列成员函数功能(假定分配器关联类型T)

标准对分配器还提出了一个要求:其中必须有一个嵌套的类模板定义rebind,使得表达式typedef A::rebind<U>::other another_allocator可以从一个分配器类型A得到一个为类型U管理内存空间的分配器类型。
为什么要这样呢?我们先回想一下各容器内部的数据组织方式:
- 首先,vector是一段连续的空间存储数据,所以使用一个关联其数据类型的分配器便可以正常运转
- 而list不同,list中是使用类似下面结果的节点类来保存数据:
template<typename Value>
struct list_node{
Value v;
list_node *prev, *next;
};
- 根据数据增减,需要随机申请和释放若干个(通常是1个)节点类空间,所以list实际需要一个管理其节点类型的内存空间分配器,但是其模板参数给出的确是一个管理其数据类型内存空间的分配器。deque、forword_list等也有类似的需求。此时,要得到关联其他类型的分配器,就需要用到
rebind元函数。比如:
template<class T, class Alloc>
class list{
class node{}; // 节点类
typedef Alloc:rebind<node>::other node_allocator_type;
node_allocator_type node_alloc; // node_alloc用于管理节点空间
};
在引入模板型模板参数后(rebind模板型参数没有引入之前的做法,现在推荐用模板型模板参数解决),对于上面的问题,就有了新的解决方法:
template<class Value, template<class> class Alloc=std::allocator>
class list{
class node{ /*实现略*/};
typedef Alloc<node>node_allocator_type;
};
template<class Value, template<class>class Alloc=std::allocator>
class vector{
typedef Alloc<Value>value_allocator_type;
};
交换容器内容时的特殊处理
容器通过其若干分配器成员来申请以及释放内存。当交换两个容器的内容时,是否需要交换两容器的分配器成员?这个问题,一直困扰着标准委员会、标准库提供方和用户。
标准库提供函数模板swap用于快速交换两个同类型容器的内容,各容器也有自己的swap成员函数实现同样的功能。
所谓快速交换,是通过直接交换两容器所申请的内存空间指针来实现。比如,vector只交换其内部连续空间的指针,list只需要交换表头指针。由于内存交换会将一方申请的内存空间交给另一方管理,这就可能导致容器内的分配器与其所拥有的内存不匹配。如果分配器都如std::allocator<T>一样,只是调用new/delete操作符来申请/释放内存,则不成问题。因为无论哪个分配器实例,都是统一向系统申请和释放内存。
但是当分配器由用户自定义时,情况就不可控制。用户完全可以自定义一种分配器,为每个实例分配不同的内存空间,并通过容器的构造函数将分配器实例传入。是的,容器除复制构造函数外的其他构造函数都有一个隐藏参数用于传入分配器,统一在参数列表的最后。比如标准库中的list:
template<class Value, class Alloca = std::allocator<Value>>
class list{
public:
explicit list(const Alloc& = Alloc());
explicit list(size_type n);
list(size_type n, const Value&, const Alloc& = Alloc());
template<typename InputIterator>
list(InputIterator first, InputIterator last, const Alloc& = Alloc());
list(const list<Value, Alloc>&);
//...
};
所以,从语法上来说,用户可以传入不同内存区域的分配器。这时就会出问题。
来看个例子:有一大批数据要先经过筛选出一小部分数据再进行某种运算,又基于某种原因,筛选和运算不能在同一个容器内进行(比如数据筛选与运算利用多线程并行进行)。如下:
std::vector small_vec;
std::vector large_vec;
do{
load_data(large_vec);
parallel_filtering_and_computing(large_vec, small_vec);
// large_vec经过筛选后尺寸已经缩小到与small_vect相同
swap(large_vec, small_vec); // 通过swap将筛选结果快速送到small_vec
} while(continue_process());
这样的代码在使用标准库中的默认分配器时可以正常运行。但是,假如说large_vec反复修改尺寸会导致多次内存申请和释放。为了提高效率,用户设计一种分配器一次预留一块足够大的内存。每次申请都从预留的内存中提取空间。基于同样的利用,small_vec也利用自定义分配器从另一块预申请的内存中提取空间。即:
int small_pool[SMALL_POOL_SIZE];
int large_pool[LARGE_POOL_SIZE];
mem_pool_allocator alloc_0(mem_pool_0):
mem_pool_allocator alloc_1(mem_pool_1):
std::vector small_vec(alloc_0);
std::vector large_vec(alloc_1);
do{
load_data(large_vec);
parallel_filtering_and_computing(large_vec, small_vec);
// large_vec经过筛选后尺寸已经缩小到与small_vect相同
swap(large_vec, small_vec); // 危险
} while(continue_process());
此时,两个vector的分配器分别工作在不同的内存区域,如果调用swap交换两个vector内容,按常量将交换两个vector内的数据空间指针。之后,如果不交换分配器,则内存区域与分配器失配,在申请释放内存时可能会出错。而即使交换了分配器,则large_vector的分配器此时工作在一个小内存,在随后的取大量数据的过程load_data中可能因为预分配内存耗尽而出错。此时最保险的方法是既不交换内存也不交换分配器,只将所存数据值一一交换,但无疑性能将受到很大影响。
有态分配器与无态分配器
可以想象,上例中的mem_pool_allocator 必须拥有非静态成员变量,才能使得其不同实例可以保存不同的工作区域。像这样的拥有非静态成员变量的分配器叫做有态分配器。而像std::abblocator<T>那样只是调用new/delete操作符在“全局”内存范围内工作的分配器并不需要成员变量,叫做无态分配器
采用无态分配器的容器之间互换数据是安全的,而有态分配器对互换的影响则很难预测,通常都隐藏着危险。
标准中约定通过分配器实例之间的相等与不等操作符来判断两分配器实例是否可以互换内存。任何自定义分配器都必须重载==和!=两个操作符。如果是分配器模板,则还要实现不同参数的模板实例之间的相等和不等操作
对于无态分配器,显然任何实例都相等。而有态分配器则要根据其状态来判断是否相等。如果相等就可以安全互换,如果不等,就要具体分析。
在C++11中将对分配器的操作交给用户自定义。C++11中新增了一个标准类模板std::allocator_traits<T>,用于描述所有与分配器有关的属性、成员函数等。容器中所有对分配器的操作都通过allocator_traits来调用。当需要调用分配器来申请内存时,过程如下:
template<class T, class Alloc>
class some_container{
Alloc a;
void some_container(size_t n){
allocator_traits<Alloc>::allocate(a, n);
}
};
而在allocator_traits模板通例中定义了默认的调用分配器申请内存的方法:
template<class Alloc>
struct allocator_traits{
typedef typename Alloc::value_type value_type;
typedef value_type* pointer;
...
static pointer allocate(Alloc& a, size_t n){
a.allocate(n);
}
};
当allocator_traits没有对应分配器的特例时,按照通例的方法,将会调用分配器的allocate成员函数来分配内存。















 1131
1131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









