







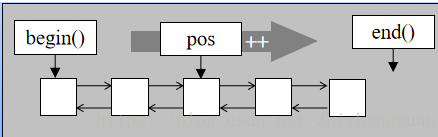
为什么要引入
指针与数组:用指针遍历数组
#include <iostream>
#include <vector>
#include <algorithm>
#include <iterator>
using namespace std;
void main()
{
const int arrsize = 10;
int a[arrsize]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
int *begin = a;
int *end = a + arrsize;
for (int *p = begin; p != end; p++)
{
cout << *p << endl;
}
system("pause");
}
- 但是在链表这种数据结构中,存储空间是非连续的。不能通过对指向这种数据结构的指针做累加来遍历
- 能不能提供一个行为类似指针的类,来对非数组的数据结构进行遍历?这样我们就能够以同样的方式来遍历所有的数据结构[所有容器
迭代器与容器:用迭代器遍历容器
#include <iostream>
#include <vector>
#include <algorithm>
#include <iterator>
using namespace std;
void main()
{
const int arrsize = 10;
int a[arrsize]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
vector<int>ivec(a, a+arrsize);
for (vector<int>::iterator iter = ivec.begin(); iter != ivec.end(); iter++)
cout << *iter << ends;
/*
每种容器都必须提供自己的迭代器
容器提供一些函数以获得迭代器并以之遍历所有的元素
*/
system("pause");
}
通过迭代器,我们可以用相同的方式来访问,遍历[泛型编程]容器
小结
- 迭代器在STL中起着粘合器的作用,用来将STL的各个部分结合在一起。从本质上来说,STL提供的所有算法都是模板,我们可以通过使用自己指定的迭代器对这些目标进行特化。

- C++中的迭代器相对于C中的对象指针更加一般化。
- 指针本身就可以作为定义好的迭代器来使用,即指针就是一种迭代器
- 这种一般化行为主要体现在可以在C++中声明新类,然后对于这些类中的大部分操作符进行重载,赋予它们新的意义。
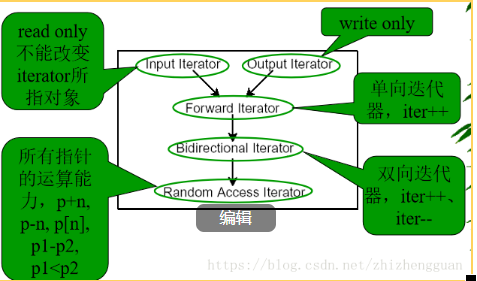
分类
- 输入迭代器
- 前向迭代器
- 双向迭代器
- 跳转迭代器
- 输出迭代器
输入迭代器
最基本、要求最低、涵盖最广的是输入迭代器。某类型X必须满足如下要求才能被称为输入迭代器:
| 表达式 | 含义 |
|---|---|
X u(a) | X可复制构造 |
u = a | X可赋值 |
u == a | 可比较相等 |
u != a | 可比较不等 |
*u | 可以去引用,而且如果u == a,则一定*u == *a |
u->m | 相当于(*u).m |
++u | 所有之前u值的副本将不再能用于去引用或者比较相等 |
(void)u++ | 等价于(void)++u |
*u++ | 等价于{X tmp = u; ++u; return tmp;} |
可见,对于输入迭代器,除了要求类型可复制构造、可赋值、可比较之外,其他要求可以归为两类:可去引用、可进行自加1运算。并且自加1运算之后可以使得运算之前的所有迭代器值“无效”,及不能再进行“去引用”,也不能用于比较。这是与前向比较器的一个关键区别。
前向迭代器
要求如下
| 表达式 | 含义 |
|---|---|
X u;、X(); | 可默认构造 |
X(a);、X u(a)、X u=a | 可复制构造 |
u == a | 可比较相等 |
u != a | 可比较不相等 |
u = a | 可赋值 |
可以去引用,而且如果u == a,则一定*u == *a | |
u->m | 相当于(*u).m |
++u | 如有u == a且都可去引用,则须有++u == ++a |
u++ | 等价于{X tmp = r; ++r; return tmp;} |
前向迭代器与输出迭代器的要求极为相似,除去构造函数和比较操作之外,二者都提供自加1操作前移一位以及去引用取值。关键区别在于,前向迭代器能够保证两个迭代器实例a与b如果满足a == b,则也一定满足++a == ++b,而输入迭代器不能保证这一点,指针以及标准库中所提供的迭代器,都满足这一要求。那么,怎么样的迭代器不能保证这一点呢?
如何区分输入迭代器与前向迭代器呢?
标准容器中的栈(stack)维护一种先进后出的数据结构,并且约束用户只能访问栈顶数据。因为这个约束,栈不提供通常意义上的迭代器。但是,没有什么能够阻止栈对“迭代”的向往。如下,实现了一种栈的迭代器stack_iterator
#include <iostream>
#include <stack>
template<typename Stack>
class stack_iterator{
public:
typedef typename Stack::value_type value_type;
typedef typename Stack::reference reference;
private:
Stack &s;
value_type *pos; // C++默认行规:pos记录所指向数据。
public:
stack_iterator(Stack &_s) :
s(_s),
pos(_s.size() ? &_s.top() : nullptr) {}
reference operator*() const {return *pos;}
stack_iterator& operator ++ (){
s.pop();
pos = s.size() ? &s.top() : nullptr;
return *this;
}
bool operator == (stack_iterator const &rh) const {return pos == rh.pos;}
bool operator != (stack_iterator const &rh) const {return pos != rh.pos;}
// ...
};
int main(){
using namespace std;
int numbers[] = {0, 1, 2, 3, 4};
typedef stack<int> int_stack;
int_stack s;
for(int i = 0; i < 5; i++){
s.push(numbers[i]);
}
stack_iterator<int_stack> a(s);
stack_iterator<int_stack> b(s);
cout << *a << "," << *b << "\n";
cout << ((a == b) ? "a == b" : "a != b") << "\n";
++a; ++b;
cout << ((a == b) ? "++a == ++b" : "++a != ++b") << "\n";
cout << *a << "," << *b << "\n"; //危险操作,a所指数据已经出栈,空间已经被释放了
}
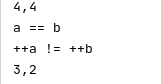
判断两迭代器是否相等的准则是看两迭代器是否指向同一个数据。所以上面判断两个stack_iterator是否相等,要看其成员是否指向同一个地址。
上例中main中的两个栈迭代器a和b原本指向同一栈顶数据,所以二者相等。但是在两迭代器先后前移之后,实际上引发了两次栈顶数据弹出,并且只有b此时指向栈顶数据,而a则指向了已被弹出的前栈顶数据的地址,也由此可以判断由a == b不能得出 ++a == ++b。所以,该迭代器只满足输入迭代器不满足前向迭代器。
输入迭代器的自加1的意义:一旦某迭代器通过自加1操作前移一位之后,则所有指向之前位置的迭代器不能保证仍然有效。 所以即使迭代器的前移不是破坏了容器中的数据至少也是屏蔽了之前的数据,总之不可在借由其他迭代器访问。所以,如果一个算法是基于输入迭代器的,就只能“遍历”一遍,之后所有迭代器都失效。 而基于前向迭代器的算法则不同,虽然前向迭代器只能前移,但是可以保证a == b可以得出++a==++a,故可以通过保存迭代器的多个副本来实现多遍遍历。(这是前向迭代器和输入迭代器最根本的区别) 比如:
b = a; // a、b是两个迭代器
addr1 = &*(++a);
do_something_on(*addr1 );
++a;
addr2 = &*(++a); // addr2==addr1;
do_onthersomething_on(*addr2 );
双向迭代器和跳转迭代器
双向迭代器在前向迭代器的基础上新增了可以后退一位的要求。其新增要求如下:
| 表达式 | 含义 |
|---|---|
--u | 将迭代器后退一位,只要存在迭代器s满足++s = u,则--u = s |
u-- | 等价于{X tmp =u; --u; return tmp;} |
跳转迭代器则是在双向迭代器的基础上新增前进或者后退指定位的的要求,具体如下:
| 表达式 | 含义 |
|---|---|
u += n | 等价于当n > 0是n次++u表达式,否则` |
u -= n | 等价于u += -n |
u + n、n + u | 等价于 {X tmp = u; return tmp += n; } |
u - n | 等价于 {X tmp = u; return tmp -= n; } |
v - u | 两迭代器相减应得到其间的距离,为一个整数n而且满足 v = u + n |
u[n] | 等价于*(u + n) |
u <v |等价于u - v < 0 | |
u > v | 等价于v < u |
u <= v | 等价于!(u > v) |
u >= v | 等价于!(u < v) |
输出迭代器
与输入迭代器类似,输出迭代器移至下一位置后也不能保证之前的迭代器还有效,作用于输出迭代器的算法也只能被遍历一次。具体要求如下:
注意: X是迭代器类型;a的类型为X&;T是元素类型,t的类型为T
| 表达式 | 结构的类型 | 含义 | 注释 |
|---|---|---|---|
X(a) | X | 产生a的一个拷贝(可复制构造) | 析构函数是可见的。*X(a)=t与*a=t的作用相同 |
X u(a)、X u=a | X& | u是a的拷贝(可复制构造) | |
r = a | X& | 将a赋值给r | 结果*r=t和*a=t作用相同 |
*a = t | void | 在序列中存储新元素 | |
++r | X& | 迭代器指向下一个元素 | &r = &++r |
r++ | 可以转换为const X& | 等价于{X tmp = r; ++r; return tmp;} | |
*r++=t | void |
如果迭代器能够满足输出迭代器的要求,则可以称为是可写迭代器,既通过迭代器可以改变其所指数据的值;否则就称为只读迭代器
前面介绍的五种标准迭代器中,除了输出迭代器之外,其余四种依次满足包含关系,即前向迭代器一直是输入迭代器,双向迭代器一直是前向迭代器,跳转迭代器一定是双向迭代器。
属性类模板
既然期望算法只面向迭代器,那么迭代器类除了要提供必要的操作外,还应该包含足够的信息以描述其自身的属性,如所属迭代器类型、所指数据类型等。
一般来说,相关属性都是通过在迭代器类型中嵌套定义类型来实现的,但也不能排除无法按约定声明嵌套类型的情况。因此,标准中特别定义了一个模板类std::iterator_traits<T>为算法提取迭代器各种属性之用。
标准中为迭代器规定了五个属性:
difference_type(迭代器差值类型)value_type(迭代器所指数据类型)pointer(数据指针类型)reference(数据引用类型)interator_category(迭代器所属类型)
interator_category标记了迭代器所属类型。标准中为了区分迭代器类型,特意定义了如下标签:
struct input_iterator_tag{};
struct output_iterator_tag{};
struct forward_iterator_tag : public output_iterator_tag {};
struct bidirectional_iterator_tag : public forward_iterator_tag {};
struct random_assess_iterator_tag : public bidirectional_iterator_tag {};
所谓标签,即一个空结构体,纯为标记类型所用。这也是模板编程中一种常见的手段。
利用interator_category,算法作者可以根据迭代器类型采取不同的策略。例如:
// 前向迭代器
template<typename I>
void advance_impl(I &i,
typename std::iterator_traits<I>::difference_type n,
std::forward_iterator_tag){
for(; n > 0; n--){
++i;
}
}
// 跳转迭代器
template<typename I>
void advance_impl(I &i,
typename std::iterator_traits<I>::differnece_type n,
std::random_access_iterator_tag){
i += n;
}
template<typename I>
void advance(I &i,
typename I::difference_type n){
// 以iterator_category()为哑函数指导编译器选择适当的重载实现。
advance_impl(i, n, typename std::iterator_traits<I>::iterator_category());
}
上面的advance函数模板实际上调用advance_impl来实现前进操作。针对前向和跳转迭代器的不同前进操作实现方式则包装在advance_impl的不同重载函数中,并用最后一个参数类型加以区别。这个参数不参与任何实现工作,纯为编译器分辨重载而设,可以称为哑参数,所以在函数的参数列表中只需要标记出参数类型即可,无须为该参数命名。
在大多数情况下,迭代器类型的嵌套类型value_type、pointer、reference都是T、T8、T&的关系,而另一嵌套类型difference_type也常常是ptrdiff_t。为了方便用户定义迭代器属性,标准中还预定义了一个迭代器基类模板:
namespace std{
template<typename Category,
typename Value,
typename Distance = std::ptrdiff_t,
typename Pointer = Value*,
typename Reference = Value&>
struct iterator{
typedef Category iterator_category;
typedef Value value_type;
typedef Distance difference_type;
typedef Reference reference;
};
};
有这个基类模板辅助,则一个通常情况下的迭代器可以很方便的定义成以下形式:
template<typename T>
struct my_iterator : public std::iterator<std::forward_iterator_tag, T>{
// ...
};
通过公开继承std::iterator,其所有嵌套定义类型都已按照iterator_traits通例的要求自动定义好,无须再为其声明iterator_traits的特例
迭代器转换器
正如容器有容器转换器一样,迭代器也有迭代器转换器。在标准中预定义的几个迭代器转换器,可以改变迭代器的行为或者流包装成迭代器。
反转迭代器
反转迭代器模板reverse_iterator<T>可以构造一个前进方向与原迭代器完全相反的迭代器。对于需要反向访问序列的算法,这一转换器非常有用
reverse_iterator<T>要求所转换的迭代器类型T至少满足双向迭代器要求。当将反转迭代器当作跳转迭代器使用时,则T必须也满足跳转迭代器要求。
#include <iostream>
#include <memory>
#include <cstring>
#include <algorithm>
void print(char c){ std::cout << c; }
int main()
{
char array[] = "Madam I'm Adam";
using namespace std;
typedef reverse_iterator<char*> backward_iterator;
backward_iterator b(array + strlen(array));
backward_iterator end(array);
for(; b != end; ++b){
cout << *b;
}
std::for_each(b, end, print);
}
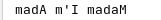
插入迭代器
标准中还预定义了三种插入迭代器,可以将算法“写入”数据的行为改变为“插入”。算法在利用迭代器写入数据时总是要调用*i = v;的语句,先对迭代器去引用得到要写入数据的左值引用,再用赋值语句写入新值。而插入迭代器则通过其特别的去引用操作和赋值操作实现了改“写入”为“插入”。其去引用将返回迭代器自身,而其赋值操作则是将数据插入到容器中。
三种插入迭代器分别为:
back_insert_iterator<C>(在容器末尾插入数据)front_insert_iterator<C>(在容器前端插入数据)insert_iterator<T>(在容器的指定位置插入数据)
三种迭代器模板都以容器类型为模板参数。末端以及前端插入迭代器需要在其构造函数中给定所插入容器,容器分别需要有push_back(v)以及push_front(v)成员函数。而指定位置插入迭代器不仅需要给定所插入容器,还需要给定插入位置的迭代器。容器需要有insert(i, v)成员函数,所有数据都将通过调用该函数而插入,按照习惯是插入在指定位置之前。插入迭代器符合输出迭代器的要求,所以只能进行自身运算,并且其自加运算不做任何事情,不会改变插入位置。
为了方便构造插入迭代器,在标准中还预设了三个助手函数模板:back_inserter(c)、front_inserter(c)、inserter(c, i)
插入迭代器的典型用法是与标准算法copy结合,将原本是复制数据的算法改为向容器中插入数据:
using namespace std;
int array[] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
std::list<int>l;
// 将array[5] -- array[9]插入到l末尾
copy(array+5, array+10, std::back_inserter(l));
//将array[4]-- array[10]插入到l前端,为保持数据顺序不变,需要reverse_iterator
copy(array_reverse_iterator(array + 5), array_reverse_iterator(array), front_inserter(l));
流迭代器
流迭代器使得算法的作用范围超出了内存(通常容器的数据都保存在内存中)而可以直接应用于外部数据(通常流所面向的是外部的数据,比如文件,标准输入/输出等)。也由于外部数据的存取通常有很多限制,不如在内存中数据那样自如,流迭代器都只符合输入或者输出迭代器的要求,只能为算法提供单次遍历。
预定义的流迭代器类模板有四种:
istream_iterator(输入流迭代器)ostream_iteratoa(输出流迭代器)istreambuf_iterator(输入流缓冲区迭代器)ostreambuf_iteratoa(输出流缓冲区迭代器)
istream_iterator模板用>>操作符从流中提取数据,其主要模板参数即为所提取值的类型。其他模板参数用于描述字符集以及迭代器差值,而且都有默认值。(注意>>遇到空白会分段)
istream_iterator<T>在构造时接受一个流参数并从中提取一个T型值。随后每次自加操作都会从中提取一个值,直到提取值失败或者流结束。每次去引用操作则返回所提取的值。无论是提取值失败还是遇到流结束,istream_iterator都会进入一个“无效”状态,此时对这个istream_iterator去引用所得值不确定。istream_iterator的默认构造函数将直接构造一个“无效”实例,而两无效实例总是相等,所以,可以用一个默认构造实例来标记迭代范围结束:
using namespace std;
istreamstream s("the quick brownfox jumps over the lazy dog");
cout << count(char_istream_iterator(s), char_istream_iterator(), 'o'); // 统计流中某字符的弧线次数。
上面无法统计 空格出现的次数,如果需要统计的话,请用更低层次的istreambuf_iterator。istreambuf_iterator只提取字符,所以其主要模板参数时字符类型char或者wchar_t。istreambuf_iterator除了是用流的sgetc()提取字符之外,其行为与istream_iterator一致。
#include <cstring>
#include <iostream>
#include <iterator>
#include <algorithm>
int main()
{
char array[] = "MADN I'm Adam";
using namespace std;
typedef reverse_iterator<char*> backward_iterator ;
copy(backward_iterator(array + strlen(array)),
backward_iterator(array),
ostream_iterator<char>(cout));
}

注意:当为标准库中的容器或者其他类重载>>或者<<以用于流迭代器以及标准算法时,必须将该重载操作符写在std命名空间内,否则编译器无法找到该函数。, 这是因为标准算法以及流迭代器等均在std空间内,在流迭代器中调用<<和>>时,编译器只会在std内搜索匹配的重载函数,如下:
#include <cstring>
#include <iostream>
#include <iterator>
#include <map>
namespace std{
template<typename T0, typename T1>
ostream& operator<<(ostream&os, pair<T0, T1> const &p){
os << "(" << p.first << ", " << p.second << ")";
}
};
int main()
{
using namespace std;
typedef map<int, char> ic_map;
typedef ic_map::value_type value_type;
// 初始值
value_type data[] = {
value_type (0, 'a'),
value_type (1, 'b'),
value_type (2, 'c'),
};
ic_map m(data, data+3);
copy(m.begin(), m.end(),
ostream_iterator<ic_map::value_type>(cout, " "));
}
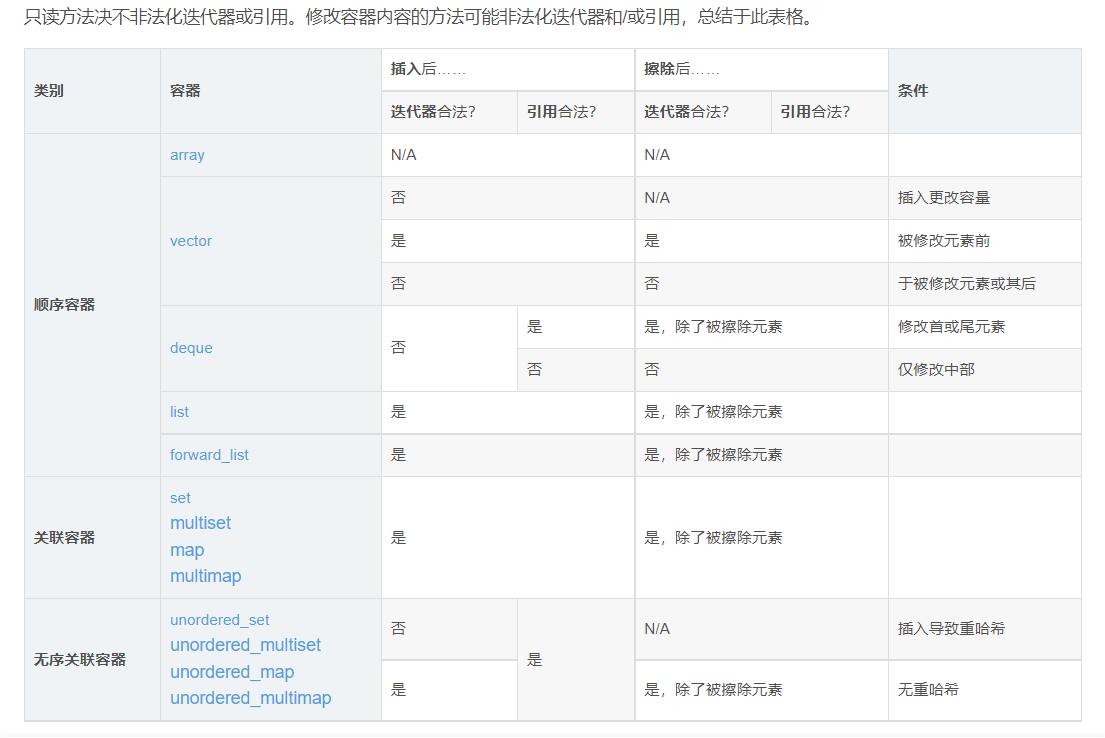
迭代器非法化














 2320
2320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









