







Web服务器可能会同时与数千个不同的客户端进行对话。这些服务器通常要记录下它们与谁交谈,而不会认为所有的请求都来自匿名的客户端。本文注意讨论一些服务器可以用来识别其交谈对象的技巧。
HTTP最初是一个匿名、无状态的请求/响应服务。服务器处理来自客户端的请求,然后向客户端回送一条响应。Web服务器几乎没有什么信息可以用来判定是哪个用户发送的请求,也无法记录来访用户的请求序列。
后来,Web设计者了提供了一些用户识别机制:
- 承载用户身份信息的HTTP首部
- 客户端IP地址跟踪,通过用户的IP地址对其进行识别
- 用户登录,用认证方式来识别用户
- 胖URL,一种在URL中嵌入识别信息的技术(很少用)
- cookie,一种功能强大而且高效的持久身份识别技术
HTTP首部

- From:首部中包含了用户E-mail地址。但是,这可能会被人恶意滥用。所以浏览器很少发送From首部
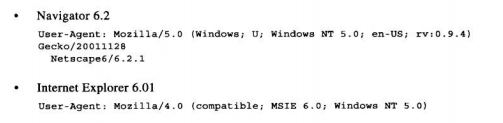
User-Agent:可以将用户使用的浏览器的相关信息告知服务器,包括程序的名字和版本,通常还包括操作系统的相关信息。要实现定制内容与特定的浏览器以及其属性间的良好互操作时,这个首部很有用,但它没有为失败特定的用户提供太多有意义的帮助。
Reference首部提供了用户来源页面的URL。Reference首部自身并不能完全标识用户,但它确实说明了用户之前访问过哪个页面。通过它可以更好的理解用户的浏览行为,以及用户的兴趣所在
From、User-Ageng以及Reference首部都不足以实现可靠的识别
客户端IP地址
很少用,因为因特网上IP地址太容易被欺骗了。
用户登录
Web浏览器无需被动的根据用户的IP地址来猜测他的身份,可以要求用户通过用户名和密码进行认证(登录)来显式的询问用户是谁。
为了使得Web站点的登录更加简便,HTTP中包含了一种内建机制,可以用www-Authenticate首部Authorization首部向Web站点传送用户的相关信息。一旦登录,浏览器就可以不断的在每条发往这个站点的请求中发送这个登录信息了。这样,就总是有登录信息可用了。
如果服务器希望在为用户提供对站点的访问之前,先行登录,可以向浏览器会送一条HTTP响应代码401 Login Required。然后,浏览器会显示一个登录对话框,并用Authoriazation首部在下一条对服务器的请求中提供这些信息(为了不让用户每发送一条请求都要登录一次,大多数浏览器会记住某站点的登录信息,并将登录信息放在发送给该站点的每台请求中)。
下图中:
- 浏览器对站点www.joes-hardware.com发送一条请求
- 站点不知道这个用户的身份,因此服务器返回
401 Login Required HTTP响应码,并添加www-Authentication首部,要求用户登录。这样浏览器就会弹出一个登录对话框 - 只要用户输入了用户名和密码(对其身份进行完整性检测),浏览器就会重复原来的请求。这次它会添加一个
Authorization首部,说明用户名和密码。对用户名和密码进行加密,防止泄露信息 - 现在,服务器知道用户的身份了
- 今后的请求要使用用户名和密码时,浏览器会自动将存储下来的值发送出去,甚至在站点没有要求发送的时候也会经常向其发送。浏览器在每次请求中都向服务器发送Authorization首部作为一种身份的标识,这样,只需要登录一次,就可以在整个会话期间维持用户的身份了
















 5934
5934











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









