







HTTP对国际化内容的支持
HTTP报文中可以承载以任意语言表示的内容,就像它能承载图像、影片或者任何类型的媒体那样。对HTTP来说,实体主体只是二进制信息的容器而已。
为了支持国际性的内容,服务器需要告知客户端每个文档的字母表和语言,这样客户端才能正确地把文档中的信息解包为字符并把内容呈现给用户。
服务器通常HTTP协议的Content-Type首部中的charset参数和Content-Language首部告知客户端文档的字母表和语言。这些首部描述了实体主体的“信息盒子”里面装的是什么,如何把内容转换成合适的字符以便显示在屏幕上以及里面的词语表示的哪种语言。
同时,客户端需要告知服务器用户理解何种语言,浏览器上安装了何种字母表编码算法。客户端发送Accept-Charset首部和Accept-Language首部,告知服务器它理解哪些字符集编码算法和语言以及其中的优先顺序
下面HTTP报文表示客户端接收法语以及一点点英语,支持iso-8847-1西欧字符集编码和UTF-8 Unicode字符集编码:

字符集和HTTP
字符集是吧字符转换为二进制码的编码
HTTP字符集的值说明如何把实体内容的二进制码转换为特定字母表中的字符。每个字符集标记都命名了一种把二进制码转换为字符的算法(反之亦然)。
下面的Content-Type首部告知接受者,传输的内容是一份HTML文件,用charset参数告知接受者使用iso-8859-6阿拉伯字符集的解码算法把内容中的二进制码转换为字符。


字符集和编码如何工作
现在我们来看看字符集合编码到底做了什么。
我们想把文档中的二进制码转换为字符以便显示在屏幕上。但由于有很多不同的字母表,也有很多不同的方法把字符编码成二进制码,我们需要一种标准方法来描述并应用把二进制码转换为字符的编码算法。
把二进制码转换为字符要经过两个步骤
- 图a中,文档中的二进制码被转换成字符代码,它表示了特定编码字符集中某个特定编码的字符。这里,转换后的字符代码是255
- 图b中,字符代码用于从编码的字符集中选择特定的元素。在iso-8859-6中,值255对应阿拉伯字母"FEH"。在步骤a和b中使用的算法取决于MIME的charset标记

国际化字符系统的关键目标是把语义(字母)和表示(图形化的显示形式)隔离开来。HTTP只关心字符数据和相关语言以及字符集标签的传输。字符形状的显示是由用户的图形显示软件(包括浏览器、操作系统、字体等)完成的
标准化的MIME charset值
特定的字符编码方案和特定的已编码字符集组合成一个MIME字符集(MIME charset)。HTTP在Content-Type和Accept-Charset首部中使用标准化的MIME charset标记。MIME charset中的值都会在IANA注册。下面给出了一些常见的MIME charset编码方案:

如果客户端无法推断出字符编码,就假定使用的是iso-8859-1
Accept-Charset首部
HTTP客户端可以使用Accept-Charset请求首部来明确告知服务器它支持哪些字符系统。Accept-Charset首部的值列出了客户端支持的字符编码方案。比如,下面的HTTP请求首部表明,客户端接收ios-8859-1和UTF-8变长的Unicode兼容系统,服务器可以随便选择这两种字符编码之一来返回内容。

注意,没有Content-Charset这样的响应首部与Accept-Charset请求首部匹配。为了和MIME标准兼容,响应的字符集是服务器通过Content-Type响应首部的charset参数带回来的.
语言标记和HTTP
Content-Language首部
实体的Content-Language首部字段描述实体的目标受众语言。如果内容主要是给法语受众的,其Content-Language首部字段就将包含:

如果内容是面向多种语言的,可以列出多种语言:
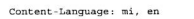
Accept-Language首部
可以用Accept-Language标记接收语言:

可以在Accept-Language首部中放入多个语言标记以枚举所支持的全部语言以及其优先顺序(从左到右):
















 425
425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









