







什么是覆盖索引
覆盖索引不是一种索引,而是一种基于索引查询的方式而已。
- 索引覆盖,即将查询sql中的字段添加到联合索引里面,只要保证查询语句里面的字段都在索引文件中,就无需进行回表查询;
- 实际开发中,不可能把所有字段都建立联合索引,可以根据实际业务场景,把经常需要查询的字段建立到联合索引中
- 我们知道MySQL的B+Tree索引是用我们字段的数据来建立索引的
比如说我们的主键id字段,就是用所有的id来组织这颗索引树,如果我们再对name字段建立索引的话,这个二级索引就是用name字段的数据来组织这颗索引树。- 那么问题就来了,我们知道对于二级索引而言他的叶子节点存储了对应数据行的id(MySQL系列-B+Tree索引详解),也就是说最后我们的查询还是要通过主键id来进行查询获取数据。
- 如果我们只需要name这个字段呢?比如说 select name from table where name>‘aaa’; 我们这个二级索引上保存了的name字段的所有数据,那么就没有必要再通过id去访问数据行了,直接从索引上获取数据即可。称之为覆盖索引,有的也翻译为索引覆盖。
由于覆盖索引可以减少树的搜索次数,显著提高性能,所以使用覆盖索引是一个常用的优化手段
优点
- 索引条目通常远远小于数据行的大小,只需要读取索引,则mysql会极大的减少数据访问量
- 因为索引是按照列值顺序存储的,所以对于IO密集的范围查找会比随机从磁盘读取每一行数据的IO少很多
- 一些存储引擎(比如MyISAM)在内存中只缓存索引,而数据依赖于操作系统来缓存。因此,只访问索引可以不适用系统调用(比较费时)
- 对于InnoDB引擎,如果辅助索引上已经存在我们需要的数据,那么引擎就不会去主键上搜索数据了。【有效避免“回表”查询】
限制
- 覆盖索引并不适用于任意的索引类型,索引必须存储类的值
- 覆盖索引必须要存储索引列的值,而哈希索引、空间索引和全文索引不存储索引列的值,所以MySQL只能用B-Tree做覆盖查询
- 不同的存储引擎实现覆盖索引都是不同的,并不是所有的存储引擎都支持覆盖索引
- 如果要使用覆盖索引,一定要注意SELETC列表值取出需要的列,不可以支持SELECT * ,因为如果将所有字段一起做索引会导致时索引文件过大,查询性能下降
索引字段的维护总是有代价的。因此,在建立冗余索引来支持覆盖索引是就需要权衡考虑了。
注意
也正是因为这样,所以在写SQL语句的时候:
- 一方面要注意一下也许会用到联合索引,但是是否可能会导致大量的回表到聚簇索引,如果需要回表到聚簇索引的次数太多了,可能就直接走全表扫描而不走联合索引了
- 一方面是尽可能在SQL里只指定必要的字段,不要类似select *把所有字段都拿出来,甚至最好直接走覆盖索引的方式,不要去回表到聚簇索引
- 即使真的要回表到聚簇索引,也应该尽可能用limit、where之类的语句限定一下回表到聚簇索引的次数,就是从联合索引里筛选少数数据,然后再回表到聚簇索引里去,这样性能也会好一些。
判断是否使用覆盖索引
我们可以通过expalin来判断查询是否覆盖索引,主要看extra字段是否有 using index 。只要有了,就说明用到了覆盖索引。

必看的博客:
示例
建表
mysql> create table user(
-> id int(10) auto_increment,
-> name varchar(30),
-> age tinyint(4),
-> primary key (id),
-> index idx_age (age)
-> )engine=innodb charset=utf8mb4;
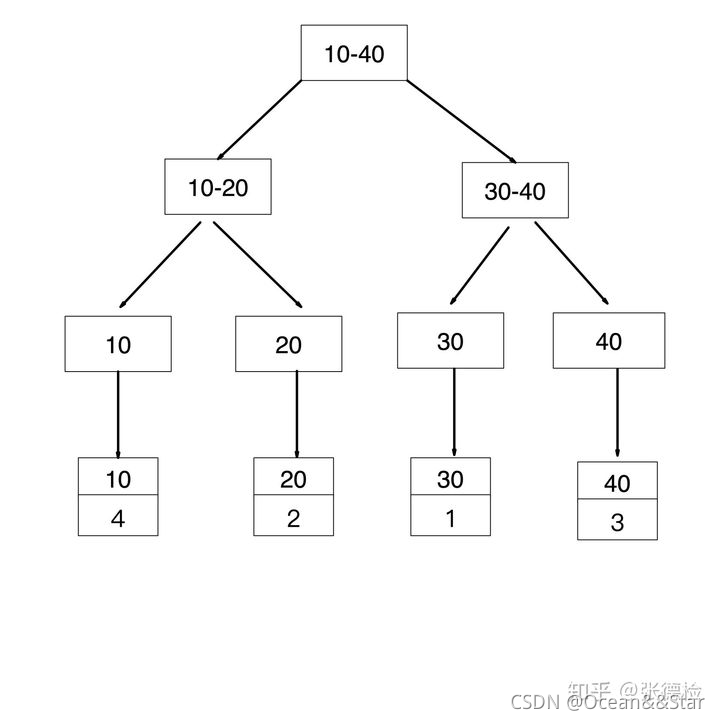
id字段是聚簇索引,age字段是普通索引
填充数据
insert into user(name,age) values('张三',30);
insert into user(name,age) values('李四',20);
insert into user(name,age) values('王五',40);
insert into user(name,age) values('刘八',10);
mysql> select * from user;
+----+--------+------+
| id | name | age |
+----+--------+------+
| 1 | 张三 | 30 |
| 2 | 李四 | 20 |
| 3 | 王五 | 40 |
| 4 | 刘八 | 10 |
+----+--------+------+
索引存储结构
id是主键,所以是聚簇索引,其叶子节点存储的是对应行记录的数据
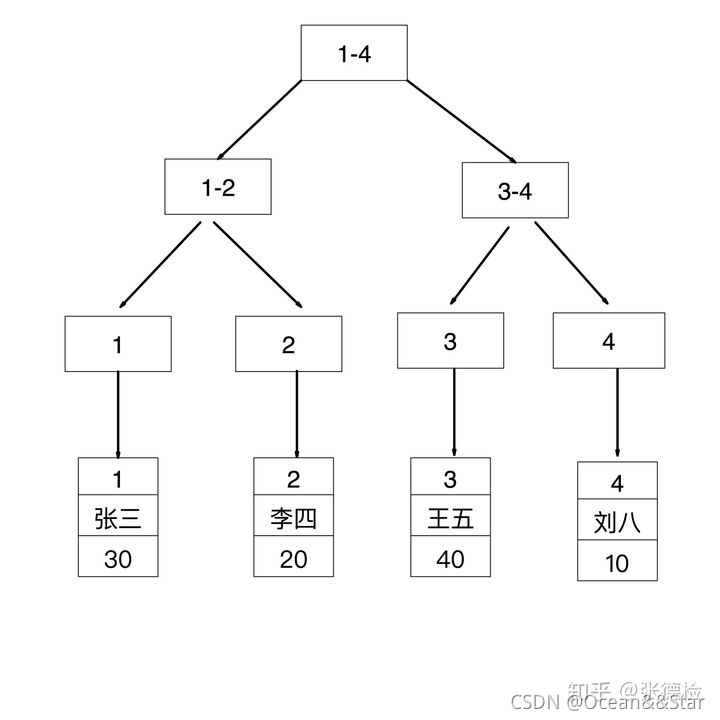
age是普通索引(二级索引),非聚簇索引,其叶子节点存储的是聚簇索引的值
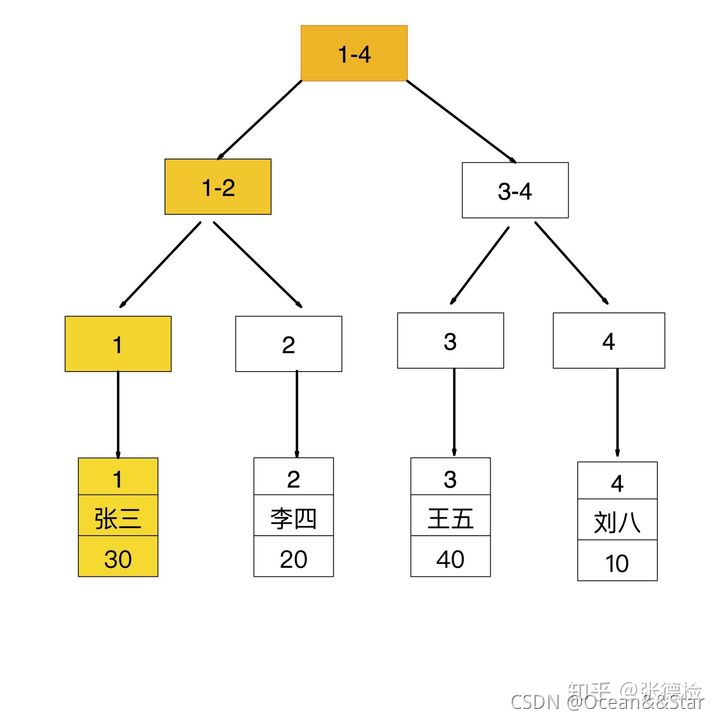
如果查询条件为主键(聚簇索引),则只需要扫描一次B+树就可以通过聚簇索引定位到要查找的行记录数据。比如:select * from user where id = 1;
如果查询条件为普通索引(非聚簇索引),需要扫描两次B+树,第一次扫描通过普通索引定位到聚簇索引的值,然后第二次扫描通过聚簇索引的值定位到要查找的行记录数据。 如:select * from user where age = 30;
- 先通过普通索引 age=30 定位到主键值 id=1
- 再通过聚集索引 id=1 定位到行记录数据

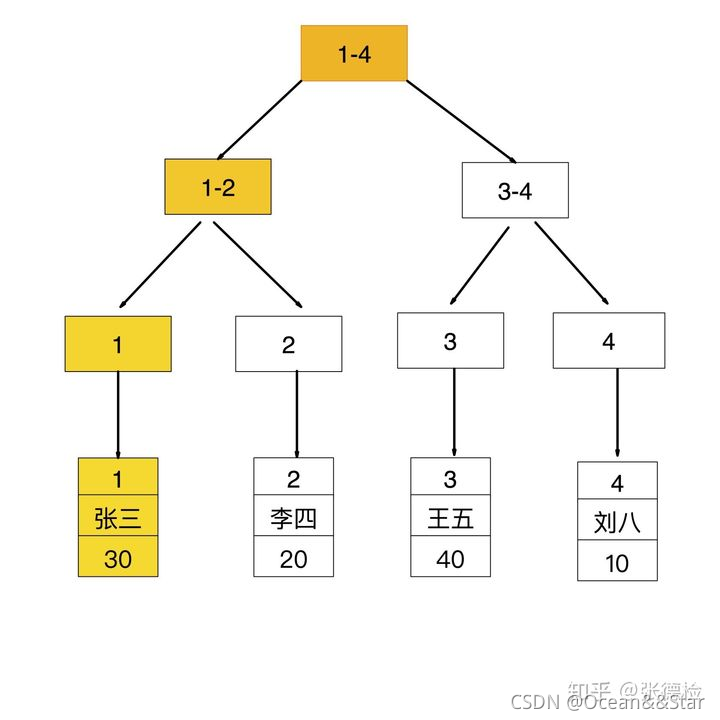
回表查询
- 先通过普通索引的值定位聚簇索引值,再通过聚簇索引的值定位行记录数据,需要扫描两次索引B+树,它的性能较扫一次索引树更低
覆盖索引(避免回表)
- 只需要在一棵索引树上就能获取SQL所需的所有列数据,无需回表,速度更快。例如:
select id,age from user where age = 10;
如何实现覆盖索引
常见的方法是:将被查询的字段,建立到联合索引里去。
- 比如实现:
select id,age from user where age = 10;
explain分析:因为age是普通索引,使用到了age索引,通过一次扫描B树就可以查询到相应的结构,这样就实现了覆盖索引

- 实现:
select id,age,name from user where age = 10;
expliain分析:arg是普通索引,但是name列不在索引树上,所以通过age索引在查询id和age的值后,需要进行回表再查询name的值。此时的Extra列的NULL表示进行了回表查询。

为了实现索引覆盖,需要建组合索引idx_age_name(age,name)
drop index idx_age on user;
create index idx_age_name on user(`age`,`name`);
explain分析:此时字段age和name是组合索引idx_age_name,查询的字段id、age、name的值刚刚都在索引树上,只需扫描一次组合索引B+树即可,这就是实现了索引覆盖,此时的Extra字段为Using index表示使用了索引覆盖。

哪些场景适合使用索引覆盖来优化SQL
全表count查询优化
mysql> create table user(
-> id int(10) auto_increment,
-> name varchar(30),
-> age tinyint(4),
-> primary key (id),
-> )engine=innodb charset=utf8mb4;
例如:select count(age) from user;

使用索引覆盖优化:创建age字段索引
create index idx_age on user(age);

列查询回表优化
前文在描述索引覆盖使用的例子就是
例如:select id,age,name from user where age = 10;
使用索引覆盖:建组合索引idx_age_name(age,name)即可
分页查询
例如:select id,age,name from user order by age limit 100,2;
因为name字段不是索引,所以在分页查询需要进行回表查询,此时Extra为Using filesort文件排序,查询性能低下。

使用索引覆盖:建组合索引idx_age_name(age,name)


















 831
831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









