







主键索引的目录结构如下图
- 只要在一个主键索引里包含每个数据页跟它的最小主键值,就可以组成一个索引目录
- 然后后继你查询主键值,就可以在目录里二分查找直接定位到那条数据所属的数据页,接着到数据页里二分查找定位那条数据就可以了。
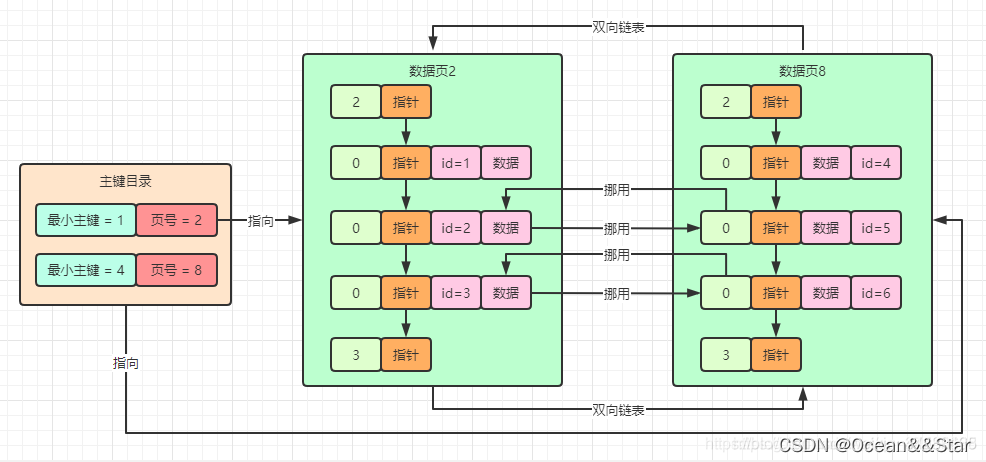
但是现在问题来了,你的表里的数据可能很多很多,比如有几百万、几千万,甚至单表几个亿的数据都是有可能的。所以此时你可能有大量的数据页,然后主键目录里就要存储大量的数据页和最小主键值。这怎么行呢?
所以在考虑这个问题的时候,实际上就是采用了一种把索引数据存储在数据页里的方式来做的。
- 也就是说,你的表的实际数据是存放在数据页里的,然后表的索引也是存放在数据页里的
- 假设你有很多很多的数据页,此时你就可以有很多索引页。如下图
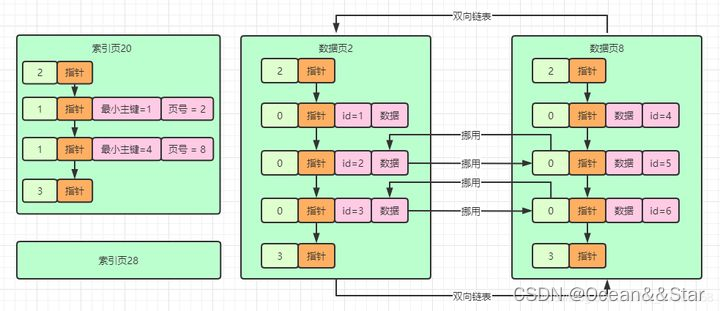
但是现在又会存在一个问题。当前有很多索引页,那怎么知道应该到哪个索引页里去找你的主键数据?是索引页20?还是索引页28?这也是个大问题
- 于是我们又可以把索引页多加一个层级出来,在更高的索引层级里,保存了每个索引页和索引页里的最下主键值。如下图:
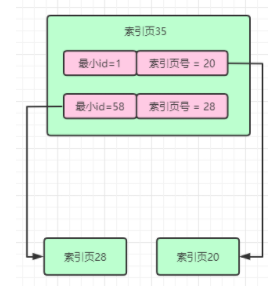
- 现在假设我们要查找ID=46的,直接先到最顶层的索引页35去找,直接通过二分查找可以定位到下一步应该到索引页20里去找;接下来就到索引页20里通过二分定位,也很快可以定位到数据应该在数据页8里面;再进入数据页8,就可以找到ID=46的那行数据了。
那么现在又有一个问题,加入你最顶层的那个索引页里存放的下层索引页的页号太多了,已经超出一个页的容量了。这该怎么办呢?
此时可以再次分裂,如下图:
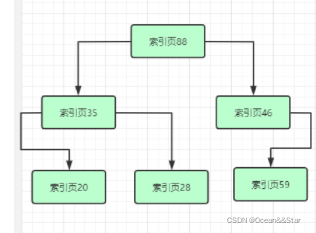
可以看到,随着索引页的层层分裂,就变成了一颗B+树。
以最简单最基础的主键索引为例,当你为一个表的主键建立起来索引之后,其实这个主键的索引就是一颗B+树;然后当你要根据主键来查数据的时候,直接从B+树的顶层开始(二分)查找,一层一层往下定位,最终一直定位到一个数据页里;在数据页内部的目录里二分查找,找到那条数据。
这就是索引最真实的物理存储结构,采用跟数据页一样的页结构来存储,一个索引就是很多页组成的一颗B+树。














 632
632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









