







题目来源
题目描述

class Solution {
public:
int longestConsecutive(vector<int>& nums) {
}
};
题目解析
看数据量:0 <= nums.length <= 10^5,因此,必须O(N)级别的算法
暴力
一个很容易想到的解法是O(nlogn)的,对原数组进行排序并去重,然后一遍扫描就能直到答案。
class Solution {
public:
int longestConsecutive(vector<int>& nums) {
// 对整个数组进行排序
std::sort(nums.begin(), nums.end());
// 去重操作
nums.erase(std::unique(nums.begin(), nums.end()), nums.end());
// ans 是最终答案,cnt用于记录临时答案
int ans = 0, cnt = 0;
for (int i = 0; i < nums.size(); ++i) {
if(i > 0 && nums[i] == nums[i - 1] + 1){
++cnt;
}else{
cnt = 0;
}
ans = std::max(ans, cnt);
}
return ans;
}
};
首先我们看一下问题的时间复杂度要求,O(n)。
看到这个时间复杂度要求,基本上我们就要放弃所有与排序有关的算法了。
- 我们不能使用sort,因为sort时间复杂度为O(nlogn)
- 同理我们也不能使用set,map等一系列基于树的容器,因为这些容器的插入与查找操作时间复杂度均为O(logn),我们将只能执行常数次的插入或查找。
- 同时我们在vector 上只能执行常数次遍历操作,因为每次遍历的代价都是O(n)。
要求O(n),就是只能遍历固定次。既然要求时间,那么只能空间换时间了。
那能不能开一个指示数组A,初始化为0,对于数组中的每一个元素u,我们让
A
[
u
]
=
1
A[u] = 1
A[u]=1,这样子问题就变成了在一个数组上查找最长的连续
1
1
1的过程。这样就只需遍历两次就可以得到答案
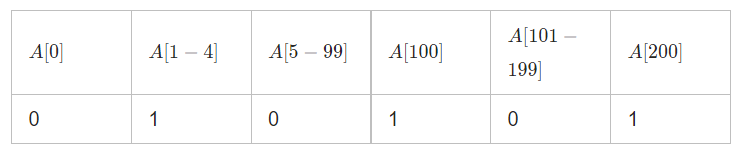
但是问题是,题目中并没有说明数组中元素最大值是多少,所以不太好。
难点在于,怎样才能让数组遍历一次就记住顺序呢
常见的空间换时间的方法有动态规划。动态规划常用vector 做备忘,但是本题给出的数组长度非常长,所以不能用vector。 我们用map或者set来记录
但是,因为时间复杂度的原因,所以我们只能选择unordered_map表了,它的查询、删除、插入都只有O(1)的时间复杂度。
采取动态规划记忆化搜索的方法
其实这个方法也可以被认为是,有向无环图求最长路的方法。
对于每个v我们都从v向v+1连一条线的话,输入数据就会成为一个有向无环图。
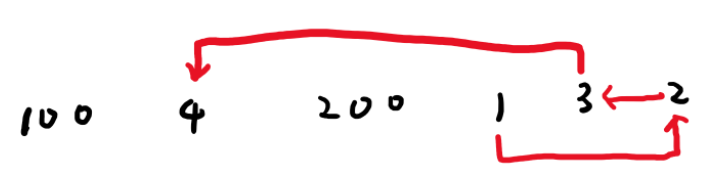
我们可以用一个基于hash的map记录答案。 mp[v]代表以v为起点的最长路的长度,同时有
- 递推式:mp[v] = mp[v+1] + 1, if v+1 in mp
- 基情况: mp[v] = 0, if v not in mp
class Solution {
public:
// 记忆化搜索 返回的结果是以v为起点的最长路的长度
int dfs(unordered_map<int, int>& mp, int v){
// 如果v不在集合中,就直接返回0,代表以v为起点的路长度为0
if (mp.find(v) == mp.end())
return 0;
// 如果这个节点已经搜索一遍了,直接返回结果
if (mp[v] != 0)
return mp[v];
// 如果当前节点还没有结果,
// 我们就去询问v+1为起点的最长路长度, 并+1得到自身的答案
// 并记录结果
return mp[v] = dfs(mp, v+1) + 1;
}
int longestConsecutive(vector<int>& nums) {
// mp[v] 表示以v为起点的最长路的长度
unordered_map<int, int> mp;
// 将数据插入mp并进行初始化
for (auto v: nums)
mp[v] = 0;
int ans = 0;
// 对每个元素进行记忆化搜索
for (auto v: nums){
ans = max(ans, dfs(mp, v));
}
return ans;
}
};
插入部分因为采用unordered_map,时间复杂度是O(n)。dfs部分的话,因为每个元素v最多只被访问两次,一次是以v为起点的dfs,一次是以v-1递归的访问v。所以dfs部分的时间复杂度也是O(n)
并查集
还是从图论的角度去思考这个问题,如果我们在v和v+1之间连一条边,那么这个问题就变成了寻找图中最大连通集的问题。
这个问题我们可以用并查集来解决,我们只需要用两个hash map 同时维护并查集,和并查集中每一个连通集的大小即可。
class Solution {
// rt 用于记录指向, sz 用于记录并查集这一子集的大小
unordered_map<int, int> rt, sz;
int find(int v){
// 这一步写法综合了路径压缩以及根的查找
if(rt[v] == v){
return v;
}else{
return rt[v] = find(rt[v]);
}
}
int merge(int u, int v){
u = find(u);
v = find(v);
// 如果u和v不在同一个集合中
if(u != v){
sz[u] += sz[v];
rt[v] = rt[u]; // 修改元素的指向
}
// merge 函数返回当前集合的大小
return sz[u];
}
int init(vector<int>& nums){
for(auto v : nums){
sz[v] = 1;
rt[v] = v;
}
}
public:
int longestConsecutive(vector<int>& nums) {
if(nums.empty()){
return 0;
}
int ans = 1;
for(auto v : nums){
// 由于是连续数组,我们只需要考虑v与v-1就能照顾所有边
if(rt.find(v - 1) != rt.end()){
ans = max(ans, merge(v, -1));
}
}
return ans;
}
};
哈希表(最优解)
过程:
- 生成哈希表std::map<int, int> map,key为遍历过的某个数,value为代表key这个数所在的最长连续序列的长度。(nums[i],lenNum)
- 从左到右遍历nums,假设遍历到nums[i]
- 如果nums[i]之前出现过,直接遍历下一个数,只处理之前没有出现过的nums[i]。怎么处理呢?
- 首先在map中加入记录 ( n u m s [ i ] , 1 ) (nums[i], 1) (nums[i],1),表示当前nums[i]单独作为一个连续序列
- 然后看 m a p map map中是否含有 n u m s [ i ] − 1 nums[i] - 1 nums[i]−1,如果有,怎么 a r r [ i ] − 1 arr[i] - 1 arr[i]−1所在的连续序列可以和 a r r [ i ] arr[i] arr[i]合并,合并后记为A序列。利用map可以得到A序列的长度,记为lenA,最小值记为leftA,最大值记为rightA,只在map中更新,更新成 ( l e f t A , l e n A ) (leftA, lenA) (leftA,lenA), ( r i g h t A , l e n A ) (rightA, lenA) (rightA,lenA)
- 接下来看 m a p map map中是否含有 n u m s [ i ] + 1 nums[i] + 1 nums[i]+1,如果有,怎么 a r r [ i ] + 1 arr[i] + 1 arr[i]+1所在的连续序列可以和 a r r [ i ] arr[i] arr[i]合并,合并后记为B序列。利用map可以得到B序列的长度,记为lenB,最小值记为leftB,最大值记为rightB,只在map中更新 ( l e f t B , l e n B ) (leftB, lenB) (leftB,lenB), ( r i g h t B , l e n B ) (rightB, lenB) (rightB,lenB)
- 遍历的过程中用全局变量max记录每次合并出的序列的长度最大值,最后返回max
整个过程中,只是每个连续序列最小值和最大值在map中的记录有意义,中间值的记录不再更新,因为再也不会使用到。这是因为我们只处理之前没有出现过的数,如果一个没有出现过的数能够把某个连续区间扩大,或者把某两个连续区间连在一起,毫无疑问,只需要map中有关这个连续区间最小值和最大值的记录
时间复杂度为O(N),空间复杂度也是O(N)
class Solution {
int merge( std::map<int, int> & map, int less, int more){
int left = less - map[less] + 1;
int right = more + map[more] - 1;
int len = right - left + 1;
map[left] = len;
map[right] = right;
return len;
}
public:
int longestConsecutive(vector<int>& nums) {
if (nums.empty()) return 0;
int ans = 1;
std::map<int, int> map;
for(auto num : nums){
if(!map.count(num)){
map[num] = 1;
if(map.count(num - 1)){
ans = std::max(ans, merge(map, num - 1, num));
}
if(map.count(num + 1)){
ans = std::max(ans, merge(map, num, num + 1));
}
}
}
return ans;
}
};
容易理解的解法
用两个map,一个是连续区间头表,一个是连续区间尾表。其key = num,value = 区间长度
每个数来的时候:
- 先看之前map中有没有,如果有,那么就忽视
- 如果没有,自己建出自己的区间,看看跟之前的能不能合,看看跟后面的能不能合。
每次合完之后,其最长的连续区间:随便哪一张表,取出value最大就可以了
class Solution {
public:
int longestConsecutive(vector<int>& nums) {
std::map<int, int >headMap;
std::map<int, int> tailMap;
std::set<int> visited;
for (int & num : nums) {
if(!visited.count(num)){
visited.emplace(num);
headMap.insert({num, 1});
tailMap.insert({num, 2});
if(tailMap.count(num - 1)){
int preLen = tailMap[num - 1];
int preHead = num - preLen;
headMap[preHead] = preLen + 1;
tailMap[num] = preLen + 1;
headMap.erase(num);
tailMap.erase(num - 1);
}
if(headMap.count(num + 1)){
int preLen = tailMap[num];
int preHead = num - preLen + 1;
int postLen = headMap[num + 1];
int postTail = num + postLen;
headMap[preHead] = preLen + postLen;
tailMap[postTail] = preLen + postLen;
headMap.erase(num + 1);
tailMap.erase(num);
}
}
}
int ans = 0;
for (auto len : headMap) {
ans = std::max(ans, len.second);
}
return ans;
}
};
暴力
暴力递归
- 先将nums中的所有元素用set保存一下,待会儿用来判断连续问题
- 然后我们从0到nums.length遍历每个元素,对于对于每个元素nums[i]我们都dfs的搜索nums中比它大1的元素,每搜索到一个,len+1。直到所有不到下一个为止,保存当前最大len为候选答案。
class Solution {
public:
int longestConsecutive(vector<int>& nums) {
std::set<int> set;
for(int num : nums){
set.insert(num);
}
// 定义dfs为以len开头的连续序列长度
std::function<int(int)> dfs = [&](int num)->int{
int len = 0;
if(set.count(num + 1)){
len = dfs(num + 1) + 1;
}else{
len = 1;
}
return len;
};
int result = 0;
for (int num : nums) {
result = std::max(dfs(num), result);
}
return result;
}
};
备忘录
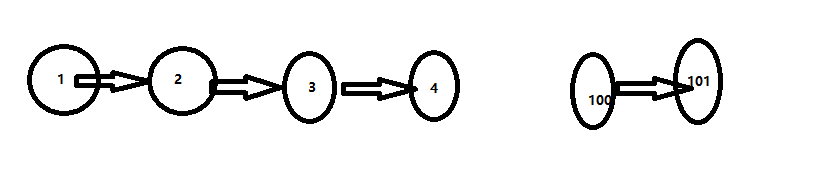
我们很容易发现,dfs形成的递归树中有重复子结构。
- 比如[100, 4, 200, 1, 3, 2],当我们dfs(1)时,dfs(4)已经计算过了;当我们dfs(3)时,dfs(4)已经计算过了;当我们dfs(2)时,dfs(3)、dfs(4)已经计算过了;所以备忘录:
class Solution {
public:
int longestConsecutive(vector<int>& nums) {
std::set<int> set;
for(int num : nums){
set.insert(num);
}
std::map<int, int> mapper;
std::function<int(int)> dfs = [&](int num)->int{
if(mapper.count(num)){
return mapper[num];
}
int len = 0;
if(set.count(num + 1)){
len = dfs(num + 1) + 1;
}else{
len = 1;
}
mapper[num] = len;
return len;
};
int result = 0;
for (int num : nums) {
result = std::max(dfs(num), result);
}
return result;
}
};

记录另一头端点的策略
逐步加入节点
逐步加入节点,一般就是四种情况
- 加入的节点会连接左边和右边的区间
- 加入的节点扩展了右边的区间
- 加入的节点扩展了左边的区间
- 加入的节点是一个孤立点
用一个map把各个区域的最大最小值和区间信息的映射保存,然后遍历数组时,直接查map就可以知道是上述哪种情况,直接分类处理就行














 932
932











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









