







基于JDBC的全量/增量数据迁移与同步原理
数据迁移实际上是数据导出、数据导入两个过程,一般情况下是指异构数据源之间的数据迁移,所谓异构指的是源端和目标端并不是同一种架构的数据源,比如说源端是关系型数据库,目标端是另一种关系型数据库,或者是另一种非关系型数据库等等。
关系型数据库的全量数据迁移最为直接的实现思路就是使用数据库本身的导出工具将数据表的数据导出为text/csv的文本格式,然后再load到目标数据源,如果目标也是关系型数据库,一般关系型数据库也有导入工具,可以直接导入文本格式的数据。但是这种方式过于依赖数据源本身的导入、导出工具,而不同数据源的导入、导出工具能力参差不齐,使用方式各异,不适合用来实现通用的数据迁移工具或服务,更加通用的方式可以考虑jdbc的方式,虽然可能会牺牲一些性能。
在别的语境下数据迁移和数据同步可能是同一个意思,但是在这篇文章中数据迁移和数据同步的语义是不一样的,数据迁移是指将数据从源端转移到目标端,如果是增量数据迁移,表现到目标端数据是只增不减的,而数据同步指的是源端数据的变化(增删该)会实时或准实时的反应到目标端,最终源端和目标端的数据是一致的,要注意这两个概念的区分。
一、关系库基于JDBC的全量数据迁移原理
基于jdbc目前最著名的三个开源的数据迁移或数据ETL工具是kettle、sqoop、datax,三个工具各自的侧重点不同。
kettle是真正意义上以数据流驱动的数据处理引擎,数据像水一样流动,流动的过程中做数据处理。所以个人认为kettle最大的优势就是数据的转换,是一个真正的ETL工具(抽取(extract)、转换(transform)、加载(load)至目的端),优势在于中间的transform。由于数据是逐行处理相对而言效率没那么高。
sqoop是使用mapreduce的思想,将关系库的数据分布式的抽取到hadoop平台,其侧重点在于充分利用分布式的资源进行分布式的计算,所以效率是sqoop的侧重点。
datax采用的是plugin+framework的架构思路,每一个数据源就是一个plugin,每个plugin有相同的输出(reader)和输入(writer), 通过framework进行串联。需要扩展数据源的时候只需要增加一个plugin的实现就可以了,而不需要修改framework,所以datax的侧重点是异构数据源。开源的datax不支持数据转换的功能。
基于jdbc的技术方案最终都是去源端数据库通过查询语句来获取数据,本质都是一样的,所以如果想要提升效率,思路其实也是一样的,就像sqoop和datax那样,都是将查询语句进行切片,每个切片抽取一部分数据,让切片并行或者并发的执行,从而达到提升效率的目的。datax和sqoop用来切片的方式也是一样的,都是采用where条件进行切片。
1.1 where条件切片方式
使用where条件进行切片,首先需要选择一个切分字段,这个字段由用户配置。然后去源库查询到切分字段的最大值和最小值,从而确定切分字段的取值范围,然后根据取值范围和切分数量均匀的划分切片。
1.1.1 原理
假如使用者配置的切分字段为id,切片数量为5,首先确定切分字段的取值范围:
select max(id),min(id) from table
假如查询获取到的最小值是1,最大值是100000;根据这个取值范围均匀的划分5个切片,按照情况会多出一个切片来处理切分字段有null值的情况,每个切片执行的sql如下:
select * from table where id >=1 and id < 20000
select * from table where id >=20000 and id < 40000
select * from table where id >= 40000 and id < 60000
select * from table where id >= 60000 and id < 80000
select * from table where id >= 80000 and id <= 100000
select * from table where id is null
1.1.2 优缺点
以where条件来划分切片的优点:
- where条件是一种通用的方式,关系数据库一般都支持min()和max()函数,也都支持where条件查询,所以这种划分切片的方式适用于所有关系性数据库
- 理想情况下,如果每个切片处理的数据量是均匀的,那每个切片的性能都是一样的,没有差别。
以where条件来划分切片的缺点:
以where条件进行切片要求使用者必须显示的选择一个切分列,而且这种方式的导数性能极其依赖选择的切分列,这其实是增加了使用的难度,因为使用者必须对源表的结构和数据有一定的了解。切分列不能随便选择,至少要考虑如下几个方面的因素:
- 切分列的类型有一定要求,需要能够进行比较,能够均匀的进行切分,除非有特殊的实现,否则一般只能选数值类型和时间类型。(要求使用者了解表结构)
- 切分列的数值要尽量分布均匀,以防止发生数据倾斜(要求使用者了解数据)虽然理想情况是切分列的数值均匀分布,但现实中几乎不存在这样的切分字段,数据倾斜几乎无法避免。而且往往使用者对数据的了解程度也不够,在源表数据量巨大的时候也无法估计哪个字段的数值是比较均匀的。
- 切分列上最好是有索引,有索引和没有索引差距巨大。
1.1.3 影响性能的因素:
- 1. max() min()函数
如果切分字段上面有索引,并且没有其它where条件,max和min函数都是直接返回数值的,时间复杂度O(1)
mysql> explain select max(id),min(id) from par_table_index\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: NULL
partitions: NULL
type: NULL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: NULL
filtered: NULL
Extra: Select tables optimized away
1 row in set, 1 warning (0.00 sec)
mysql> explain format=tree select max(id),min(id) from par_table_index\G
*************************** 1. row ***************************
EXPLAIN: -> Rows fetched before execution (cost=0.00 rows=1)
如上所示,id字段上面有普通索引(主键和唯一索引也一样),解释执行的时候看到Extra中有“Select tables optimized away”的信息,这个在mysql的官方文档中有解释(地址:mysql官方文档对于explain的解释)
大概意思是说,在生成执行计划之前已经获取到结果了,直接返回即可,时间复杂度为O(1), 原因是mysql中索引本身就是排好序的,直接通过索引可以获取到最小值最大值。
但如果切分字段上没有索引,min和max依然要进行全表扫描,时间复杂度为o(n),和count的效率差不多。
-
2. 切分列上数值不均匀导致的数据倾斜
数据倾斜指的是不同切片处理的数据量不一样,交给分布式节点去跑的时候,数据量多的任务运行慢,极端情况是所有其它mapper任务都已经执行完成,都在等某一个mapper任务执行完成。出现数据倾斜的原因在于使用的是条件进行划分的,上面的例子,按照计划划分了5个切片,理想情况是每个切片两万条数据,但是有可能这张表中间段进行了删除操作,比如id为15000到80000之间的数据全部删除了,总数并没有10万条数据,这个时候其实只有两个切片真正有数据要抽取,第一个切片数据量15000条,最后一个切片数据2万条,其余切片数据量为0。 -
3. 切分列上的索引
切分列上的索引不仅影响max()、min()函数的性能,更重要的是数据抽取时候的性能,因为切分列最终会作为where条件,所以切分列尽量是主键(mysql中根据主键索引可以直接在b+树的叶子节点中获取到所有列的数据,但如果是其它索引需要进行回表操作),如果不是主键,也要尽量有索引,并且尽量不包含null值。如果没有索引,执行的过程需要进行全表扫描。
1.2 limit/offset分页切片方式
如果使用limit/offset进行切片,首先要确定源端数据库支持limit/offset语法,然后通过count(*)的方式获取到总的数据量,根据总的数据量和切片的数量以分页的方式均匀的划分切片
1.2.1 原理
假如用户配置的切片数量为5,首先使用count(*)获取表中总的记录数:
select count(*) from table;
假设查询的结果为10万条,根据总数和切片数量来均匀划分切片,每个切片中执行的sql为:
select * from table limit 20000 offset 0;
select * from table limit 20000 offset 20000;
select * from table limit 20000 offset 40000;
select * from table limit 20000 offset 60000;
select * from table limit 20000 offset 80000;
1.2.2 优缺点
使用分页方式进行切片的优点:
1、不需要用户选择一个切分字段
2、每个切片的数据量是绝对均匀的
3、不会多出一个切片专门处理null的情况
使用分页方式进行切片的缺点:
1、并不是每一个关系型数据库都支持limit/offset语法,比如oracle、sql server早期的db2都不支持
2、offset值越大性能越差
1.2.3 影响性能的因素
- 1、count(*):
mysql中,如果是MyiSAM表(非事务表),表中记录数是直接记录在系统表中的,count(*)将直接返回系统表中记录的数值,时间复杂度O(1),速度非常快。但是对于InnoDB表(事务表),由于mysql要兼顾事务,不同事务可能看到的结果不一样,所以count(*)并不会直接返回系统表中记录的数值,而是在事务中进行全表扫描计算,时间复杂度O(n),在数值巨大的时候非常慢。
另外对于事务表来说,count(*)和count(1)没有任何区别,mysql在执行的时候都会自动优化到索引列上去(不管是什么类型的索引),如果没有索引就会扫描表数据。但实际上扫描表数据和扫描索引树差别不会有数量级的差距,因为即使使用索引也是要扫描所有行的。要注意count(col)计算的是col列非空的数量,这和count(*) count(1)是有区别的,所以不能count(col)的方式计算表中记录数,推荐方式就是count(*)。
InnoDB handles SELECT COUNT(*) and SELECT COUNT(1) operations in the same way. There is no performance difference.
上文摘自mysql官方文档:mysql官方文档对于count的解释
-- par_table表有索引(主键、唯一键或者普通索引),扫描的是索引行
mysql> explain select count(*) from par_table\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: par_table
partitions: NULL
type: index
possible_keys: NULL
key: PRIMARY
key_len: 4
ref: NULL
rows: 99985
filtered: 100.00
Extra: Using index
1 row in set, 1 warning (0.00 sec)
-- par_table_no表无索引,扫描的是表数据
mysql> explain select count(*) from par_table_no\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: par_table_no
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 99841
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
上面两个explain结果,第一个有索引,第二个没有索引,返回的结果中区别在于type,有索引的表type为index,无索引的表type为ALL,区别可以查看官方文档:mysql官方文档对于explain的解释,大概的意思是说index方式和ALL方式的执行方式是类似的,都要扫描所有数据,区别在于index扫描的是索引树,而ALL扫描的是表数据,一般来说索引树要比表数据的大小小很多,所以index会比ALL快。
- 2、limit、offset的性能:
先说结论:offset越大执行效率越低。
然后分析原因,看如下两个limit语句的执行计划,前一个是limit 10,后一个是limit 10 offset 80000:
-- par_table_pk表中有主键,limit10的执行计划
mysql> explain select * from par_table_pk limit 10\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: par_table_pk
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 100130
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
mysql> explain format=tree select * from par_table_pk limit 10\G
*************************** 1. row ***************************
EXPLAIN: -> Limit: 10 row(s) (cost=10117.25 rows=10)
-> Table scan on par_table_pk (cost=10117.25 rows=100130)
1 row in set (0.00 sec)
-- par_table_pk表有主键,limit 10 offset 80000的执行计划
mysql> explain select * from par_table_pk limit 10 offset 80000\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: par_table_pk
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 100130
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
mysql> explain format=tree select * from par_table_pk limit 10 offset 80000\G
*************************** 1. row ***************************
EXPLAIN: -> Limit/Offset: 10/80000 row(s) (cost=10117.25 rows=10)
-> Table scan on par_table_pk (cost=10117.25 rows=100130)
1 row in set (0.00 sec)
上面的执行计划看起来比较奇怪,即使只取10行数据,执行计划中估算的行数也是整表的行数,目前网上大部分的说法都是mysql的执行计划会"忽略"limit,而这个说法最早来源于percona官网博客,时间是2006年,地址是: percona官网博客对limit执行计划的解释。里面提到:
LIMIT is not taken into account while estimating number of rows Even if you have LIMIT which restricts how many rows will be examined MySQL will still print full number.
意思就是mysql执行计划在估计行数时不会考虑limit,即使使用limit限制了要返回的行数,MySQL仍然会打印完整的行数。这个说法是正确的,但要说mysql的执行计划"忽略"了limit,个人认为不太恰当。我们看mysql官网对limit的描述:mysql官方文档对limit的解释,里面提到:
If you select only a few rows with LIMIT, MySQL uses indexes in some cases when normally it would prefer to do a full table scan.
翻译:如果你仅仅使用limit关键字来获取一部分记录,mysql在某些时候也会使用索引,但大多数时候mysql都会倾向于使用全表扫描
...
As soon as MySQL has sent the required number of rows to the client, it aborts the query unless you are using SQL_CALC_FOUND_ROWS. In that case, the number of rows can be retrieved with SELECT FOUND_ROWS()
翻译:除非你使用了SQL_CALC_FOUND_ROWS,否则当mysql server向客户端发送了指定数量的记录之后就会停止执行。
从官网文档来看mysql对select * from table limit m [offset n]的执行方式和select * from table的执行方式是一样的,只不过在加了limit之后,mysql边执行边往客户端返回数据,返回的数据达到了limit的限制之后,mysql就会停止执行。官方文档有提到SQL_CALC_FOUND_ROWS,加了这个语句,mysql在达到指定条数之后也不会停止,会将整个执行计划执行结束,然后可以通过SELECT FOUND_ROWS()来看执行结束之后有多少条语句,用法如下:
mysql> select SQL_CALC_FOUND_ROWS id,username,password from par_table_pk limit 10;
+----+----------+----------+
| id | username | password |
+----+----------+----------+
| 0 | user_0 | pass_0 |
| 1 | NULL | pass_1 |
| 2 | NULL | pass_2 |
| 3 | user_3 | pass_3 |
| 4 | user_4 | pass_4 |
| 5 | user_5 | pass_5 |
| 6 | user_6 | pass_6 |
| 7 | user_7 | |
| 8 | NULL | pass_8 |
| 9 | user_9 | |
+----+----------+----------+
10 rows in set, 1 warning (0.03 sec)
mysql> SELECT FOUND_ROWS();
+--------------+
| FOUND_ROWS() |
+--------------+
| 100000 |
+--------------+
1 row in set, 1 warning (0.00 sec)
可以看到即使limit 10,如果不停止执行,最终会扫描完整个表的数据。
回过头来看limit offset语法,为什么说offset越大执行效率越低,因为mysql是执行整个select语句,边执行边过滤,达到指定条数之后才停止执行,如果offset 0,那么从第一条开始计数,达到limit的限制之后就停止运行了。如果offset 80000,mysql依然会从第一条开始扫描,但是不符合offset的值,直到扫描到第80000条才符合,从这一条开始计数,达到limit之后停止执行。所以最后一个切片相当于全表扫描,效率必然是低于前面的切片的。这在数据量巨大的时候尤其体现明显。如果以分页的方式进行切片,数据量不易过大,另外切片的数量不宜过多。
针对mysql的limit、offset有多种优化方式:
1、where条件:select * from table where id > 80000 limit 20000。这种优化方式是减少了mysql扫描的无用数据,如果id是主键效率会更加高,缺点是必须要有类似id这样的一个列,必须明确知道分页的界限
2、覆盖索引+子查询:select * from table where id > (select id from table limit 1 offset 80000) limit 10。这种方式在子查询中至查询索引列上的数据,不用回表,而且只有一个字段,数据大小要比所有字段小,然后用where减少扫描的行数
这些优化措施对导数任务来说不太实用,主要原因还是在于需要选取一个切分列,同时也要了解数据的分布,如果已经知道这些内容,直接使用基于where条件的切片方式就可以了。
1.2.4 oracle基于分页的切片方式
对于mysql和postgresql来说由于可以使用limit/offset语法,分页方式比较简单,但是oracle并不支持limit/offset语法,分页相对而言会复杂一点。但是整体思路是一样的,依然是用count(*)计算出整表的记录数,然后根据切片数量均匀划分切片:
select count(*) from table;
假设查询结果为10万,切片数量为5,根据总数和切片数量来均匀划分切片,每个切片抽取数据量为20000, 每个切片中执行的sql为:
select <cols..> from (select a.*, rownum rno from par_table a where rownum <= 20000) where rno > 0;
select <cols..> from (select a.*, rownum rno from par_table a where rownum <= 40000) where rno > 20000;
select <cols..> from (select a.*, rownum rno from par_table a where rownum <= 60000) where rno > 40000;
select <cols..> from (select a.*, rownum rno from par_table a where rownum <= 80000) where rno > 60000;
select <cols..> from (select a.*, rownum rno from par_table a where rownum <= 100000) where rno > 80000;
和mysql的limit/offset一样,越往后的切片扫描的数据量越多,性能越差。
二、基于JDBC的增量数据迁移/同步原理
这里出现了迁移和同步的概念,再复习一下,迁移指的是源端数据转移到目标端,在增量迁移的场景下表现到目标端数据只增不减,同步指的是源表数据的变化会实时或者准实时的反应到目标表,最终源端和目标端数据是一致的。采用jdbc进行增量数据的迁移和同步的时候由于限制比较多,对源表和适用场景要有较高的要求,所以无论是开发人员在实现的时候还是用户在使用的时候都要先考虑清楚需求,既要清楚源表的特征又要明确增量迁移或同步适用的范围。
如果采用JDBC来进行增量数据迁移,由于最终仍然是使用查询语句来获取数据,源表如果有物理删除的操作,那么删除的这部分数据是无法通过查询语句获取到的,所以源表不能有物理删除,但可以是逻辑删除,因为逻辑删除本质也是更新。
在进行增量数据迁移的时候首先面临的问题就是从源表识别出增量数据,这需要源表有一个字段能够起到行版本戳的作用,每次插入或者更新操作都会使版本戳自增,这个字段我们称为增量标识列,我们每次执行数据迁移任务的时候都记录下这个版本戳,下次迁移的时候只迁移比记录的版本戳大的那些数据。
具体来说有两种表适合这种增量迁移的场景:第一种是源表只有插入操作,没有更新和删除,可以选择自增的主键id为增量标识列;第二种是源表有插入和更新的操作,但是有一个时间字段记录插入或者更新的时间,如果时间字段的精度足够高,那么这个时间字段也可以选择为增量标识列,但是要注意这种情况下源表的更新操作在目标端并不是更新,而是插入,所以目标端是会出现重复数据的,符合流水表的场景(但是做不了拉链表)。
增量数据的抽取也可以通过切片的方式提升效率,这里以基于where条件切片为例来讲解。假如源表有插入和更新操作,有一个时间字段update_time记录插入和更新的时间,该字段被选为增量标识列,源表有主键字段id,该字段被选为切分列,切片数量为3
第一次迁移可以认为是全量数据迁移,迁移之前先通过max()函数或取update_time的最大值,假如为"2021-05-10 10:08:25.213",那么第一次迁移的过程如下:
先确定切分列的范围:
select min(id), max(id) from (select * from table where update_time <= '2021-05-10 10:08:25.213') table_alias;
假设最小为0,最大为100000,根据最大值和最小值最终划分的3个切片为:
select * from (select * from table where update_time <= '2021-05-10 10:08:25.213') table_alias where id >=0 and id < 33334;
select * from (select * from table where update_time <= '2021-05-10 10:08:25.213') table_alias where id >=33334 and id < 66667;
select * from (select * from table where update_time <= '2021-05-10 10:08:25.213') table_alias where id >=66667 and id <= 100000;
第二次或者后续的增量迁移过程,同样的先查询增量标识列的最大值:
select max(update_time) from table;
假设为"2021-05-11 10:08:34.324", 上一次迁移的最大值为"2021-05-10 10:08:25.213",那么增量数据就是2021-05-10 10:08:25.213到2021-05-11 10:08:34.324之间的数据。
然后确定切分列的范围:
select min(id),max(id) from (select * from table where update_time > '2021-05-10 10:08:25.213' and update_time <= '2021-05-11 10:08:34.324') table_alias;
假设最小为60000(由于有更新操作,所以查询到的主键id可能小于上次的最大值100000),最大为150000,最终划分的三个切片为:
select * from (select * from table where update_time > '2021-05-10 10:08:25.213' and update_time <= '2021-05-11 10:08:34.324') table_alias where id >= 60000 and id < 90000;
select * from (select * from table where update_time > '2021-05-10 10:08:25.213' and update_time <= '2021-05-11 10:08:34.324') table_alias where id >= 90000 and id < 120000;
select * from (select * from table where update_time > '2021-05-10 10:08:25.213' and update_time <= '2021-05-11 10:08:34.324') table_alias where id >= 120000 and id <= 150000;
增量数据抽取时候性能影响因素会更多,也更容易发生数据倾斜,不过增量迁移的数据量相较于全量数据迁移要少很多,这种情况下其实更适合用分页方式进行切片,当然这并不是绝对的,具体问题具体分析。
上面是数据迁移的场景,如果是数据同步场景,基于jdbc其实也可以实现,基于jdbc的数据同步场景同样要求源表没有物理删除的操作(因为jdbc无法获取被删除的数据),同样要求有一个合适的增量标识列用于识别增量数据,除此之外还要求源表和目标表有互相对应的主键(或者不含空值的唯一键)。具体来说几乎只有一种表适用这种场景,这种表使用逻辑删除代替物理删除,同时有一个时间字段或者版本戳字段记录数据插入和更新的时间。
当我们识别出增量数据之后,其实我们无法区分增量数据中哪些是插入操作哪些是更新操作,但是我们可以进行统一的处理,首先将这部分增量数据的主键收集为一个集合,然后去目标端把主键在这个集合的数据全部删除,然后把这部分增量数据插入进去,这里要注意删除和插入必须在一个事务中,否则如果删除成功但是插入失败会丢失数据。由于关系型数据库适合少量数据的单条操作,而上述的同步过程都会涉及一批一批的数据,所以这种同步方式更适合具有事务能力的分析型数据库,因为分析型数据库是对批量操作友好的。
其实进行增量数据的同步更优的方式是利用关系数据库各自的CDC(Change Data Capture)方案来捕获并解析出变化数据,然后到目标端进行回放。比如mysql的binlog就是mysql的CDC方案,如果将binlog设置为row模式,binlog中会记录用户每个增删改的操作,包括操作类型、操作时间、操作前各行的值和操作后各行的值等信息,由于信息全也更适合用来进行数据同步。但本文聚焦于JDBC方式,所以不展开讲基于CDC的方案。
三、关系库的逻辑结构
我们进行关系库的数据迁移与同步,总是不可避免要和关系表打交道,首先面临的问题就是要知道关系库中有哪些表,表的结构是什么样的。这就要求我们要从关系库的逻辑结构中获取表结构。当我们描述数据库的逻辑结构的时候,我们总是习惯使用"库表"这样的说法(尤其是mysql的使用者),这里的"库"就是database,但是"database"其实是一个模糊的概念,不同的数据库有不同的含义,有些是逻辑范畴的,有些是物理范畴的,所谓逻辑范畴是指这个概念并不真实存在于文件系统或磁盘中,仅仅只是为了更清晰的组织结构而存在的,而物理范畴的概念则是一个真实存在的结构,存在于文件系统中。对于mysql来说database等同于schema,是逻辑的概念,但是对于oracle,"database"就是一个物理范畴的概念,真实存在于文件系统。
我们应该尽量避免使用"database"这样模糊的概念,会造成理解上的困难,那描述数据库逻辑结构更明确的概念是什么呢?我们来看sql标准中的描述:
Catalogs are named collections of schemas in an SQL-environment. An SQL-environment contains zero or more catalogs. A catalog contains one or more schemas, but always contains a schema named INFORMATION_SCHEMA that contains the views and domains of the Information Schema
上文摘自:sql1992标准 DIS 9075, p45
按照SQL标准的描述,数据库的逻辑结构应该用catalog(编目)/schema(模式)/table这样的树形层级结构来表示和描述,catalog和schema是数据库命名空间中的一个层次,都属于逻辑概念的范畴,catalog中有多个schema,schema中有多张表。下面是树形结构的示意图,仅仅用于理解层级结构:
-- catalog/schema/table的树形结构示意图,仅用于理解层级结构。
├── catalog1
│ ├── schema1
│ │ ├── table1
│ │ ├── table2
│ │ └── table3
│ └── schema2
│ ├── table1
│ └── table2
└── catalog2
└── schema1
├── table1
└── table2
如果是完整的三层逻辑结构,当我们需要访问表中数据的时候执行的完整sql应该为:
select * from <catalog>.<schema>.<table name>
如果以JDBC的方式获取表结构,应该先获取catalog列表,然后获取某个catalog中schema的列表,然后再获取某个schema下table的列表,如下:
// jdbc获取catalog列表:
public static List<String> getCatalogs(Connection conn) throws SQLException {
List<String> catalogs = new ArrayList<>();
try (ResultSet rs = conn.getMetaData().getCatalogs()) {
while (rs.next()) {
String catalog = rs.getString("TABLE_CAT");
if (catalog != null && !catalog.isEmpty()) {
catalogs.add(catalog);
}
}
}
return catalogs;
}
// jdbc获取某个catalog下的schema列表
public static List<String> getSchemas(Connection conn, String catalog) throws SQLException {
List<String> schemas = new ArrayList<>();
// 注意getSchemas()方法的两个参数,第一个参数是填确定的catalog名称,可以为null(null表示该数据库没有catalog层)
// 第二个参数填的是schema匹配的正则表达式,%是通配符,表示匹配所有schema
try (ResultSet rs = conn.getMetaData().getSchemas(catalog, "%")) {
while(rs.next()) {
String schema = rs.getString("TABLE_SCHEM");
if (schema != null && !schema.isEmpty()) {
schemas.add(schema);
}
}
}
return schemas;
}
// jdbc获取某个schema下所有表
public static List<String> getTableNames(Connection conn, String catalog, String schema) throws SQLException {
List<String> tableNames = new ArrayList<>();
// 注意getTables()方法的前三个参数,第一个填确定的catalog名称,可以为null
// 第二个参数是schema匹配的正则表达式,可以为null(null表示该数据库没有schema层)
// 第三个参数是table匹配的正则表达式,%是通配符,表示匹配所有表
try (ResultSet rs = conn.getMetaData().getTables(catalog, schema, "%", new String[] {"TABLE"})) {
while(rs.next()) {
String tableName = rs.getString("TABLE_NAME");
if (tableName != null && !tableName.isEmpty()) {
tableNames.add(tableName);
}
}
}
return tableNames;
}
但是不同的数据库厂商在实现数据库的时候并不一定会完整的实现SQL标准中的三层逻辑结构。
3.1 Mysql
mysql应该是我们最为熟悉的数据库了,使用mysql的时候我们习惯用"库表"来描述层级结构,一般我们认为mysql的表都存在于"库"中,这个"库"指的就是database,我们使用mysql客户端的时候也总是最先调用"show databases"语句查询mysql服务中有哪些库,但实际上将其理解为"database(库)"是不准确的,准确的理解应该是schema,"show databases"语句可以用"show schemas"语句等价代换,"create database"语句也可以用"create schema"语句等价替换。
我们还可以查询mysql中存储表信息的系统表来进行佐证, 在mysql客户端中执行:desc information_schema.TABLES;得到结果如下:
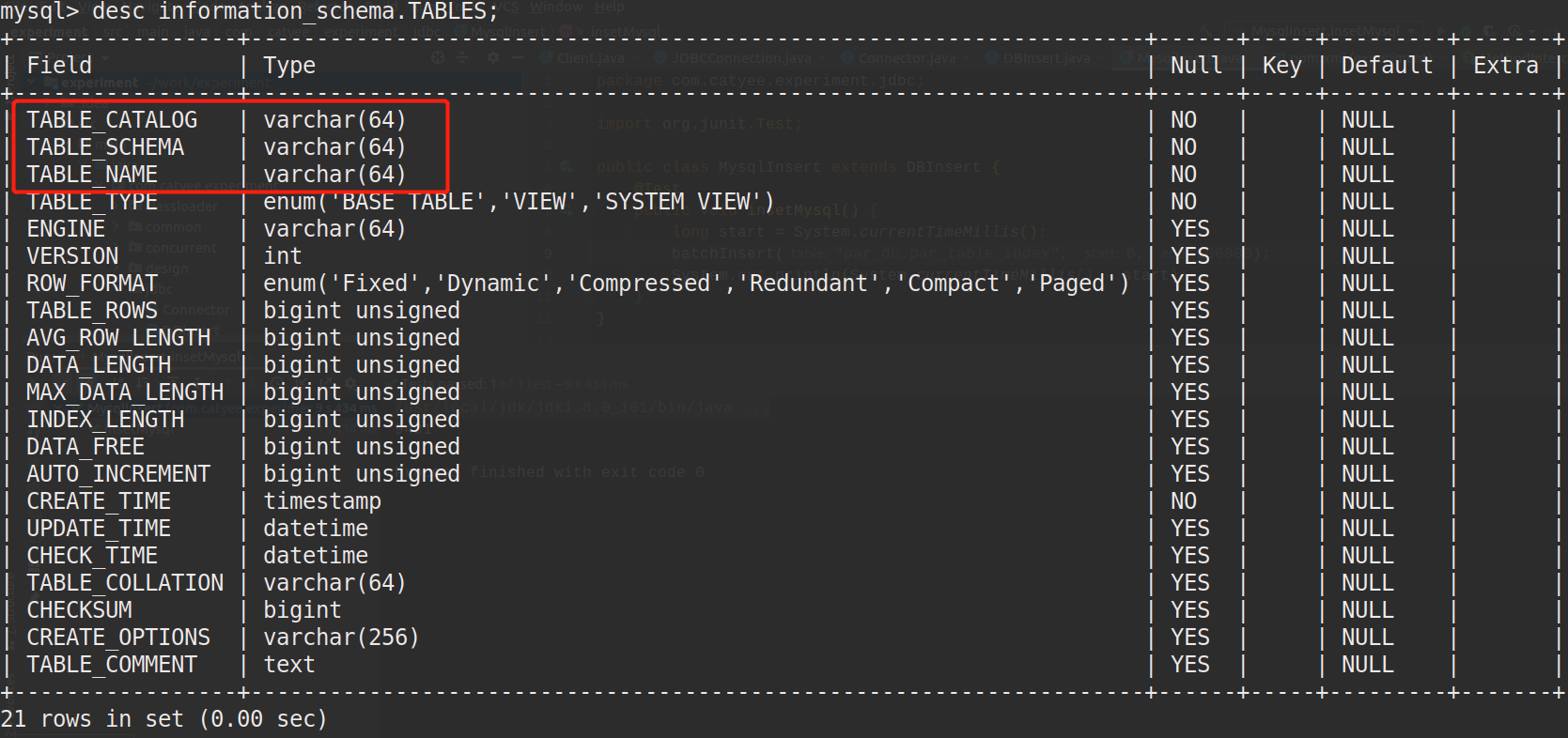
可以看到系统表TABLES中是有catalog和schema的概念的,查询其中的值:
mysql> select TABLE_CATALOG,TABLE_SCHEMA,TABLE_NAME from TABLES where TABLE_NAME='par_table';
+---------------+--------------+------------+
| TABLE_CATALOG | TABLE_SCHEMA | TABLE_NAME |
+---------------+--------------+------------+
| def | par_db | par_table |
+---------------+--------------+------------+
1 row in set (0.00 sec)
可以看到table_catalog存储的是一个缺省值,schema中存储的是所谓的"库"名。
也就是说对于mysql数据库,实际上是两层逻辑结构:schema/table,当我们想访问mysql表的数据的时候执行的完整sql应该为:
select * from <schema>.<table name>
由于mysql没有catalog层,如果我们用JDBC按照之前的方法去获取mysql的表结构,应该直接去获取mysql的schema列表。但是!但是!!你会发现通过jdbc获取schema列表是空的,而catalog列表反而是能获取到正确的"库"列表:
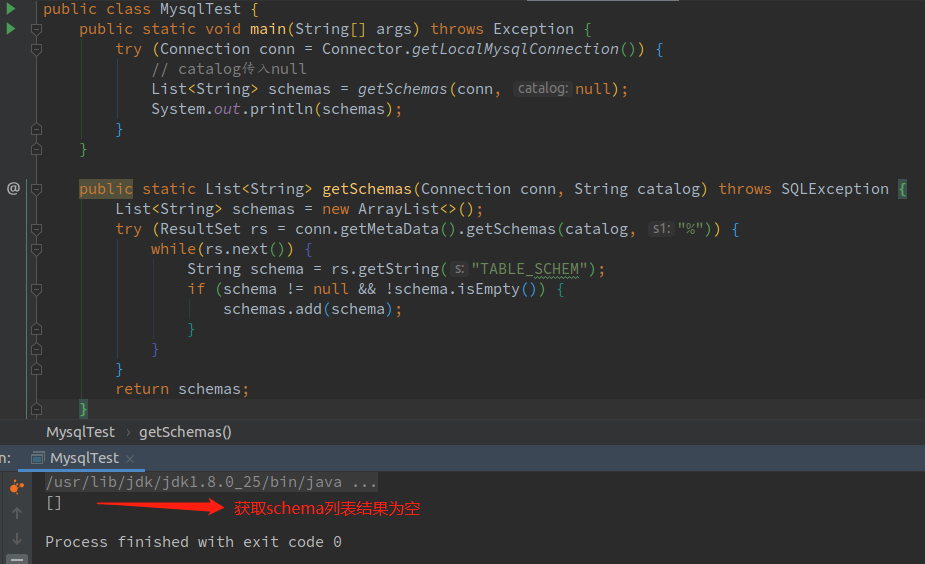
可以看到上面的代码运行结果中schema列表为空。
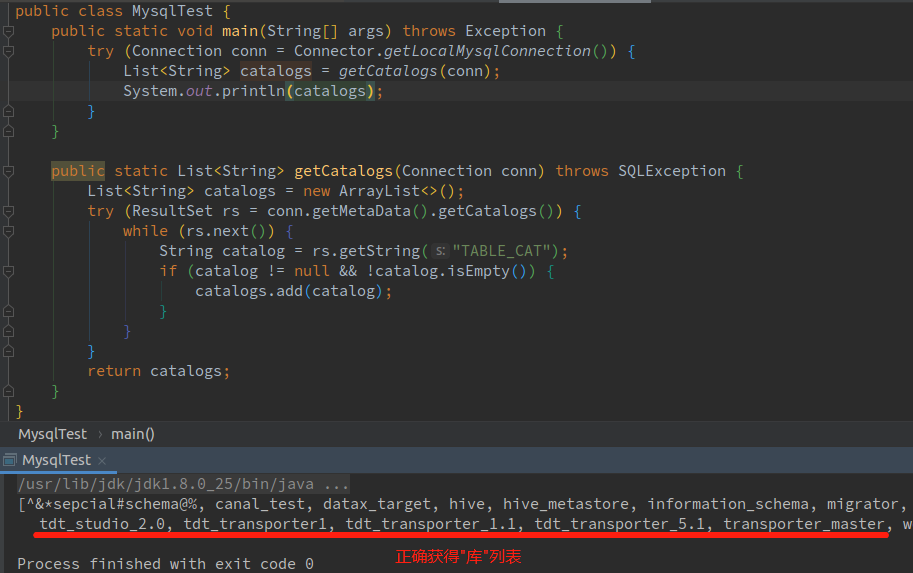
上面的代码运行结果中catalog列表为"库"列表。
也就是说通过JDBC获取到的结构层次为catalog/table,这和mysql实际的逻辑结构(schema/table)是不一致的,我不太明白mysql官方为什么要这么做,或许是最开始实现jdbc驱动的时候出错了,但是为了保证兼容性就一直没有改?
无论最初的原因是什么,现在事实都不会改变,开发过程中一定要注意这个细节。
个人感受:
mysql虽然是最为通用的开源数据库,学习的人也是最多的,很多人一开始接触数据库就是mysql,但是mysql中很多概念和其它数据库或者一些约定俗成的概念大相径庭,一旦形成印象就很难改变,在学习和理解其它数据库的时候很容易造成困扰,个人认为最开始可以学习postgresql,这是市面上另一个开源数据库。
3.2 Oracle
oracle的逻辑结构相比于mysql来说就清晰多了,oracle中没有catalog的层级,描述逻辑结构的时候也不会用"database"的概念,所以oracle的逻辑结构就是schema/table,没有任何歧义。在oracle中访问一张表的完整查询语句为:
select * from <schema>.<table>
oracle中一个用户会有一个同名的schema,大部分情况下用户都只会使用自己同名的schema,在这个schema中创建各种数据库对象,但是oracle是允许创建其它schema的,创建schema使用的是"create schema"语句,详细使用方法请参考官方文档:oracle中创建schema的方法
oracle中也有database的概念,但是oracle中database是一个物理范畴的概念,指的是数据文件。为了便于理解,这里也列举出oracle中的其它概念。当然学习一个数据库最好的方式仍然是去官网阅读官方文档,以下这些概念的理解也都来自于官方文档:oracle组织架构(Oracle Database Architecture)
3.2.1 oracle中的其它概念:
一个oracle服务(oracle database server)由一个database和至少一个database instance(实例)构成。
- database:database是物理范畴的概念,指一组文件集,实际存放于文件系统中,用来保存实际的数据。这些数据文件可以独立于数据库实例存在。从21c版本开始,"database"特指CDB、PDB和application container的数据文件。
- database instance: database instance即 数据库实例,指的是提供数据服务的程序,实例对内管理和操作实际的物理文件,对外则是提供数据服务,一般简称为instance,实例可以独立于数据文件存在。
database和database instance从概念上来说是有区别的,使用者经常"database"或者"database instance"指代oracle数据库服务(oracle
database server),这是不准确的,oracle数据库服务是"database"和"database instance"的结合,要注意概念的厘清,这有助于我们正确理解oracle数据库。在阅读下文的时候,要时刻记得database是一个物理范畴的概念,指的是存储于硬件上的数据文件,而database instance是运行在操作系统上的程序
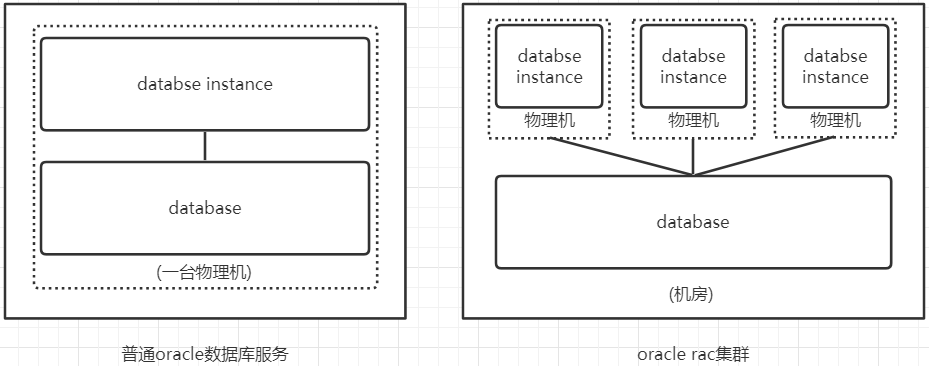
在oracle12c版本之前,databace instance和database是一对一或多对一的关系,一对一即普通的oracle数据库服务;多对一即oracle的RAC系统,RAC系统采用的是共享存储的数据库架构方式,也就是多个数据库实例(database instance)共享一套数据文件(database)。
一般来说一个RAC系统可以部署在同一个机房中,database instance部署在机房中的不同服务器节点(物理机)上,而数据文件存储在共享存储文件系统(NFC)或者集群文件系统(OCFS2)上,在存储区域网中所有服务器节点可以直接访问共享文件系统。如图所示,一个普通的oracle数据库部署在一台机器上,而一个rac集群部署在一个机房。
这里有另外一个要注意的点,我们在写oracle的jdbc thin格式连接串的的时候,一般有两种写法:
-- 使用sid (sid前是冒号)
1、jdbc:oracle:thin:@<host>:<port>:<sid>
-- 使用service_name (service_name前是/)
2、jdbc:oracle:thin:@//<host>:<port>/<service_name>
第一种方式是使用sid,sid指的就是database instance id(实例id);service_name顾名思义就是服务名称,service_name是在oracle8i引进的,也就是说8i之前只有sid,因为8i之前一个oracle数据库服务都只有一个实例,一个实例就只有一个sid,连接串中写这个参数就可以了;到了8i之后一个oracle数据库服务可能有多个实例了,每个实例都有一个sid,所以引入了service_name参数,这个参数用于指代一整个数据库服务,而不是一个实例。oracle官方推荐的写法也是使用service_name,sid的写法在逐渐被淘汰。
到了oracle12c版本的时候,oracle引入了多租户的部署,为了实现多租户环境下的部署,引入了CDB(数据库容器)和PDB(可插拔数据库)的概念
- PDB:全称为Pluggable Database,即可插拔数据库。它对外看起来就相当于一个non-CDB,也就是普通数据库,但是PDB并不能简单理解为之前的单数据库服务(non-CDB),准确说PDB是可移植的模式(schema),模式对象(schema objects)、非模式对象(nonschema objects)的集合。在物理层面,每个PDB都有自己的数据文件。PDB的可插拔体现在当你想移动或者归档一个PDB的时候你可以"拔掉"它,一个被"拔掉"的PDB由数据文件和一个元信息文件构成。
- CDB:全称为multitenant container database,即数据库容器,一个CDB中可以有多个PDB,还包括一个根容器(root)和一个种子容器(sed),根容器用于管理所有PDB,使用sqlplus /as sysdba连接进来,默认连接的是根容器,需要切换到其他的PDB容器才可以对单独的PDB操作。种子容器作为PDB的模板,用于生成PDB。
如图,是一个CDB-oracle部署的示意图,示意图中CDB-oracle数据库服务只部署在一台服务器上,只有一个database instance,但是有多个PDB。另外也可以将CDB-oracle部署为RAC集群,也就是说可以有多个database instance。
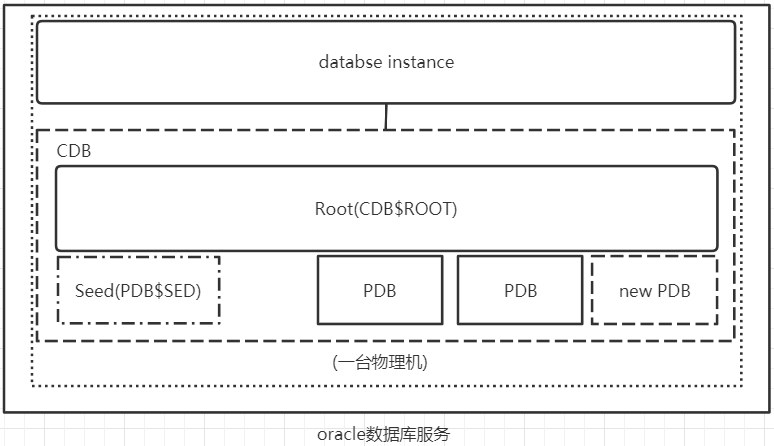
oracle中的"create database"语句就和mysql中含义完全不一样了,mysql中"create database"创建的是一个schema,也就是说只创建了一个逻辑范畴的层次结构。但是oracle中的"create database"实际上创建的是一个CDB,当执行这个命令的时候会创建一组data files、control files、online redo logs,这些都是物理文件。在CDB中使用"create pluggable database"时候创建的是一个PDB,这个命令执行的时候会创建一组data files,但是不包含control files和redo log files,一般情况下PDB共用CDB中的control files和redo log files。
上面提到的data files、control files、redo log files都是真实的物理文件,oracle还使用了一些逻辑上的存储结构对磁盘空间的使用进行更细粒度的控制:
- Data Block:即数据块,一个数据块对应于磁盘上的特定字节数,最终Oracle数据库的数据都存储在数据块中。
- Extent:即区,区是多个逻辑上连续的数据块。
- Segment:即分段,分段是一组区,用于存储用户对象(user object),比如表或索引,还用于存储undo data和临时数据
- TableSpace: 即表空间,表空间是分段的逻辑容器。oracle中一般一个用户有一个表空间,多个用户就有多个表空间。
3.3 PostgreSQL
PostgreSQL是市面上除了Mysql之外最为出名、使用最广泛的开源数据库。PostgreSQL从逻辑结构上来说有着catalog/schema/table完整的三层逻辑结构。
PostgreSQL中的"database"概念等价于"catalog",是逻辑范畴的概念,在PostgreSQL中可以使用"create database"语句创建database,也就是catalog,但是PostgreSQL中没有"create catalog"的语句。一个PostgreSQL数据库可以有多个database,从实现上来说不同database并不是完全隔离的,比如不同database会共享WAL,但从用户角度来说这些database是彼此隔离的,当我们连接一个PostgreSQL数据库服务的时候需要在连接串中指明需要连接的database name,这个连接将只能访问这一个database,以下是一个使用jdbc连接串的示例:
// 必须指定要连接的database,示例中连接的是test_db1
jdbc:postgresql://localhost:5432/test_db1
由于PostgreSQL是完整的三层逻辑结构,所以访问PostgreSQL中的表的时候,完整的查询语句是:
select * from <catalog>.<schema>.<table name>
但是由于PostgreSQL一个连接只能访问一个数据库,所以可以省略catalog,也就是:
select * from <schema>.<table name>
postgresql中默认的用户schema是"public",如果表是创建在public中的,还可以进一步省略:
-- 当表在public schema中
select * from <table name>
上面有提到不同的database从用户角度是彼此隔离的,一个重要的体现就在于不能跨库进行操作,即使是同一个用户,假如他创建了多个数据库,当他在连接其中一个库之后,他是不能在这个连接中操作其它库的,举例:
假设用户使用的连接串为:jdbc:postgresql://localhost:5432/test_db1
这个连接串表示用户连接postgresql的test_db1数据库
使用该连接串连接postgresql之后,用户可以访问test_db1库中的表(假如为test_table1):
select * from test_db1.public.test_table1
select * from public.test_table1
select * from test_table1
假设该用户创建过另外一个库test_db2,使用上面的连接串连接postgresql,用户不能访问test_db2中的表,如果执行下面的这个sql将会报错:
select * from test_db2.public.test_table2
报错的错误码为[0A000],含义是[FEATURE NOT SUPPORTED],具体报错信息为:[[0A000]: ERROR: cross-database references are not implemented: "test_db2.public.test_table2"],报错信息明确说明不能跨数据库引用。
当我们使用jdbc获取PostgreSQL的逻辑结构的时候,我们任然可以使用conn.getMetaData().getCatalogs()获取catalog列表,但是其返回结果的ResultSet中只会有一个值,这个值也就是jdbc连接串中指定的database。
当我们使用conn.getMetaData.getTables(String catalog, String schemaPattern, String tableNamePattern, String types[])方法获取表名列表的时候,尽管PostgreSQL有catalog的概念,但是由于在连接串中已经指明要连接的database,所以这个方法的第一个参数catalog是不起作用的,可以是null也可以随意填写。
3.3.1 PostgreSql中的TableSpace概念
PostgreSQL中的表空间用于指明存储database物理文件的路径,其创建语句如下:
CREATE TABLESPACE <scpace name> LOCATION '<path>'
-- 比如:CREATE TABLESPACE fastspace LOCATION '/ssd1/postgresql/data';
一旦tablespace创建完成,当我们创建数据库对象的时候就可以用这个名称引用表空间:
-- 创建表的时候指明表空间
CREATE TABLE foo(id int) TABLESPACE space1;
-- 还可以设置默认的表空间,这样就不需要显示指定表空间了:
SET default_tablespace = space1;
CREATE TABLE foo(id int);
PostgreSQL默认有两个表空间:pg_global和pg_default,前者用于存储全局的系统catalogs的数据。后者用于存储实例数据库的数据,如果用户在创建database的时候没有指定表空间,这个database也会使用默认的pg_default表空间。
以上均参考postgresql官方文档:PostgreSQL官方文档对逻辑结构的描述
3.4 SQLServer
对于Sql Server,一台物理机上可以部署多个sql server服务(实例),每个实例都包含多个database(catalog),每个数据库包含多个schema,每个schema包含多张表,所以从逻辑结构来说,sql server是完整的catalog/schema/table三层结构。
和PostgreSql一样,sql server中的"database"也是等价于"catalog"的,是一个逻辑范畴的概念。但是和Postgre Sql不一样的是sql server不用强制在连接串中指明database,一个用户只要权限足够,它可以在一个连接中访问和操作多个database。访问SQL Server中的表的时候,完整的查询语句是:
select * from <catalog>.<schema>.<table name>
如果在sql server的连接串中指明了database name,且要访问的表刚好就是这个database中的表,则可以省略catalog;如果连接串中指明了database name,但是访问的表不在指定的这个database中,仍然要用完整的查询语句进行查询。
-- 连接串中指明了库名: jdbc:sqlserver://localhost:1433;databaseName=<database name>
select * from <schema>.<table name>
sql server中一个database默认的schema是"dbo",如果连接串中指明了库名,并且表在默认的"dbo"中,则可以直接使用表名进行访问:
select * from <table name>
3.4.1 SQLServer中的文件与文件组
sql server中没有表空间(TableSpace)的概念,而是**“文件"和"文件组”。"文件"是物理范畴的概念,也就是真实存放在物理硬盘上,sql server有两种类型的文件,即数据文件和日志文件**,数据文件用于存储数据和数据库对象元信息,又细分为主数据文件和辅助数据文件:
- 主数据文件(Primary File):主数据文件的后缀为.mdf,sql server中每个database有且只有一个主数据文件,主数据文件中存储了database的启动信息以及指向数据库中的其他文件的信息,如果创建数据库对象的时候没有显示指定文件组,这些数据库对象的数据和元信息也默认存储在主数据文件
- 辅助数据文件(Secondary File):辅助数据文件的后缀为.ndf,系统默认不会创建辅助数据文件,而是由用户手动创建,辅助数据文件也是用来存储数据和数据库对象元信息。用户可以将辅助数据文件放到不同磁盘上,从而分散存储的数据,提高io效率。
- 事务日志文件(Transaction Log):事务日志文件的后缀为.ldf,用于存储事物日志。
数据文件的组合称为文件组(File Group),文件组是一个逻辑范畴的概念,在sql server中不能直接操作数据文件,而是通过文件组来进行管理,这里要注意"数据文件"的组合才叫做文件组,也就是说日志文件是不包含在文件组中的。
在sql server实例中创建database的时候,如果只是简单指定了一个database的名称,如下:
create database <db name>
系统会自动创建一个名称为PRIMARY的文件组,叫做主文件组(Primary File Group),主文件组中包含了一个主数据文件,这个主数据文件也是系统自动创建的,主文件组中也可以包含辅助文件,除了主文件组之外,其他文件组只能包含辅助文件;系统还会自动创建一个事务日志文件,所以个sql server中一个database至少包含一个文件组和一个日志文件。
一个database默认的文件组就是主文件组,在创建数据库对象的时候如果没有显示的指定文件组,这些对象都将存储在默认文件组,我们可以修改数据库的默认文件组。一个database也可以包含多个文件组,除了系统自动生的主文件组之外,用户还可以根据需要添加自定义文件组,每一个自定义文件组管理一个或多个文件,这些文件都是辅助文件。举例:
-- 以下语句在sql server实例中创建了一个名称为MyDB的database,MyDB包含了一个主文件组PRIMARY,主文件组中包含一个主数据文件MyDB_Primary; 一个自定义文件组MyDB_FG1,自定义文件组中包含两个辅助数据文件:MyDB_FG1_Data1和MyDB_FG1_Data2; 一个Filestream文件组(需要开启Filestream功能); 一个事务日志文件
CREATE DATABASE MyDB
ON PRIMARY
( NAME='MyDB_Primary',
FILENAME=
'c:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_Prm.mdf',
SIZE=4MB,
MAXSIZE=10MB,
FILEGROWTH=1MB),
FILEGROUP MyDB_FG1
( NAME = 'MyDB_FG1_Data1',
FILENAME =
'c:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_FG1_1.ndf',
SIZE = 1MB,
MAXSIZE=10MB,
FILEGROWTH=1MB),
( NAME = 'MyDB_FG1_Data2',
FILENAME =
'c:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_FG1_2.ndf',
SIZE = 1MB,
MAXSIZE=10MB,
FILEGROWTH=1MB),
FILEGROUP FileStreamGroup1 CONTAINS FILESTREAM
( NAME = 'MyDB_FG_FS',
FILENAME = 'c:\Data\filestream1')
LOG ON
( NAME='MyDB_log',
FILENAME =
'c:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB.ldf',
SIZE=1MB,
MAXSIZE=10MB,
FILEGROWTH=1MB);
-- 使用关键词ON可以指定数据库对象存储的文件组,如果不显示指定文件组,会存储到默认文件组
CREATE TABLE MyTable
( cola int PRIMARY KEY,
colb char(8) )
ON MyDB_FG1;
-- 可以修改database的默认文件组,这样就可以不用每次都显示指定文件组了
ALTER DATABASE MyDB
MODIFY FILEGROUP MyDB_FG1 DEFAULT;
-- 在Filestream文件组中创建表
CREATE TABLE MyFSTable
(
cola int PRIMARY KEY,
colb VARBINARY(MAX) FILESTREAM NULL
);
以上均参考官方文档:SQL Server官方文档
3.5 DB2
在db2中同样是完整的三层结构,完整的查询语句是:
select * from <catalog>.<schema>.<table name>
其中catalog即database name,和postgresql一样,连接db2的时候必须指定需要连接的database,当指定了database之后同样是不能跨库进行访问和操作的,如果是jdbc连接串,使用方式如下:
// 必须在jdbc连接串中指定要连接的database,示例中连接的database是sample
jdbc:db2://localhost:50000/sample
由于在连接串中已经指定了database的名称,所以查询语句也可以省略catalog:
select * from <schema>.<table name>
db2创建一个database的时候,会创建一个与实例拥有者名称相同的schema(会自动转为大写),比如实例拥有者是db2inst1,那么在这个实例中创建的每一个database都会有一个默认的schema叫做DB2INST1,如果当前登陆用户就是db2inst1,而且表也在DB2INST1的schema中,查询语句可以进一步省略:
-- 登陆用户为db2inst1,并且表在db2inst1这个schema中
select * from <table name>
对于DB2通过jdbc获取逻辑结构时候有一些注意事项(以下使用10.1版本的驱动进行测试):
- 1. 虽然DB2中有catalog的概念,但是通过ResultSet rs = conn.getMetaData().getCatalogs()方法无法获取到,rs.getString(“TABLE_CAT”)会返回null
- 2.通过ResultSet rs = conn.getMetaData().getTables(null, schemaPattern, “%”, new String[]{“TABLE”})获取一个schema下所有表名的时候,第一个参数是catalog名称,虽然db2有catalog的概念,但是不能填写,第一个参数只能置为null,也可以为"",即空字符串,也可以为通配符"%",但是不能填写jdbc连接串中的database名,也不能填其它值,否则无法获取到表名列表。
可以看到db2和postgresql都需要在连接串中指定要连接的database名称,但是通过jdbc获取逻辑结构的时候是有很多区别的,要特别注意。
四、关系库的特殊字符、保留字处理
一般来说我们都会避免在关系库中使用特殊字符或者关键库的保留字。但这并不意味关系库不允许用户使用特殊字符和保留字。以下是mysql中使用特殊字符和关键字的实例:
-- mysql中创建含有特殊字符的表:
create table `table#1`(id int primary key, col1 varchar(10));
-- mysql中以保留字作为表名:
create table `table`(id int primary key, col1 varchar(10));
上面第一个建表语句中表名含有特殊字符,第二个建表语句中表名是保留字,所以这两个表名都使用了反引号,如果没有加反引号执行将会报错。不光表名,catalog名、schema名、表名、列名或其它数据库对象的命名都有可能出现特殊字符或者保留字,当我们使用这些名称的时候就必须加上定界标识符(delimited identifier)。
一般来说关系数据库都使用双引号来做为定界标识符("),只有mysql使用反引号(`),同样的建表语句,在oracle中要按照下面的方式书写:
-- oracle中创建含有特殊字符的表:
create table "table#1"(id int primary key, col1 varchar(10));
-- oracle中以保留字作为表名:
create table "table"(id int primary key, col1 varchar(10));
下表列出了一些常见关系数据库的定界标识符:
| 关系库 | 定界标识符 |
|---|---|
| mysql | 反引号(`) |
| oracle | 双引号(") |
| postgresql | 双引号(") |
| sql server | 双引号(") |
| db2 | 双引号(") |
| hana | 双引号(") |
| 达梦(DM) | 双引号(") |
另外普通的名称也可以使用定界标识符,所以很多中间件在处理数据库对象的时候会统一在名称上加上定界标识符:
create table `test_db`.`test_table`(`id` int primary key, `col1` varchar(20));
但是要注意,一般来说,当使用定界标识符之后,关系库会直接使用定界标识符所标定的名称,而不再做任何处理。我们知道mysql中都会默认将数据库对象的名称转换为小写,而oracle会默认转换为大写,当使用定界标识符之后就不会在进行大小写的转换了。
-- 比如在Oracle中创建用如下语句建表
create table "case_table"(id int, col1 varchar2(20));
-- 尽管case_table中并没有特殊字符,也不是保留字,但是如果执行以下sql任然会出错:
select * from case_table;
select * from CASE_TABLE;
-- oracle中会默认将小写转为大写,所以上面两个sql是完全等价的,这两个sql执行会报找不到表的错误。原因在于oracle认为存在的表是"case_table"而不是CASE_TABLE
-- 正确的书写方式是:
select * from "case_table";
-- 反过来也是成立的,如果建表语句是:
create table case_table(id int, col1 varchar2(20));
-- 以下sql执行将会报找不到表的错误
select * from "case_table";
-- 正确的书写方式是:
select * from case_table;
select * from CASE_TABLE;
select * from "CASE_TABLE";
所以在处理数据库对象的名称的时候并不是统一加上定界标识符就万事大吉了,一般来说关系库不会处理定界标识符所标定的名称,需要视情况进行处理。注意这里"一般来说"的描述,因为并没有找到一个规定来规定关系库一定要这么处理,大家只是约定俗称,所以总是有几率出现例外。目前我所接触的数据库只有hive会无视定界标识符,关系库还没出现过例外。
另外还记得jdbc获取表结构的方法吗?
// 获取某个schema下table列表
ResultSet getTables(String catalog, String schemaPattern, String tableNamePattern, String types[]) throws SQLException;
注意以上方法中的参数schemaPattern,tableNamePatern,这两个参数实际上是正则表达式,如果我们传入的是一个完整的名称,实际上是严格匹配,举个例子,比如我们在sql server中要获取"cata1/sche1"下的所有表,应该如下调用方法:
ResultSet getTables("cata1", "sche1", "%", new String[] {"TABLE"};
第一个参数传入catalog的完整名称,第二个参数我们虽然传入的是"sche1"这个schema的完整名称,但是jdbc在处理的时候是当作正则在处理的,由于是一个不带正则符号的字符串,jdbc会严格进行匹配,所以只会匹配到一个schema,而不会匹配到其它的schema,这里要注意由于是当作正则处理,所以是区分大小写的,如果数据库中的schema是"SCHE1",但是我们传入的参数是"sche1",实际上匹配不到的。类似的方法还有获取某张表的列:
// 获取某个表的column列表
ResultSet getColumns(String catalog, String schemaPattern,
String tableNamePattern, String columnNamePattern) throws SQLException;
这样会有一个问题,如果一个schema名或者table名本身含有特殊字符,使用上述方法的时候被jdbc识别成了正则符号,获取的结果就会不准,或者会出错。当然这种情况并不是一定会出现的,与具体的名称有关,但是存在这样的几率。如果真的遇到这种情况,其实是没办法的,通过jdbc的标准接口是没法处理这种情况的,只能想其它方式,比如在权限允许的情况下查询数据库的系统表(数据字典)来获取表结构。
其实还有更多无法处理的情况,举个例子,在oracle中创建一张表,表名为"test`table",由于oracle中的定界标识符是双引号,所以名称中是可以含有反引号的。如果现在有一个业务需求是把这张表迁移到mysql中去,由于mysql中的定界标识符是反引号,所以是怎么都无法创建出这张表的,只能修改表名。
五、驱动的加载与卸载
是否有驱动加载和卸载的问题主要取决于驱动包管理的方式以及我们开发的是一个数据迁移常驻服务,还是数据迁移工具。对于工具而言,一般跑一次任务就是jvm启动->运行任务->jvm停止的过程,每次跑任务都会重新加载驱动;而对于服务而言,jvm启动之后是常驻的,由于java类加载的机制,如果没有进行特意的设计,驱动加载进去之后就很难再加载同数据库的不同版本驱动,有可能会造成一些问题。
由于这一部分展开来讲要耗费大量篇幅,所以用单独的文章进行讲解,如有兴趣了解请移步:JDBC驱动的隔离加载与卸载
六、数据类型的映射
不同数据库之间进行表迁移的时候总是要进行表结构的映射,表结构的映射最重要的就是数据类型的映射。在进行数据迁移的时候,一般都是让用户自己手动去目标端建表,迁移工具或服务只进行数据的迁移,sqoop、datax都是这样,用户手动建表的时候就需要考虑类型映射的问题,这实际上是把类型映射的任务和映射失败的风险都转移给了用户。那么为什么迁移工具或服务不自己进行表结构的迁移呢?
虽然不同数据库厂商会遵循标准实现一些通用的数据类型(数值类型、字符串类型、时间类型、binary类型),但是不同数据库厂商有不同的实现方式,就算相同的数据类型也可能会有不同的存储范围和精度,在进行类型映射的时候会带来困难,更何况每种数据库都多多少少有一些独有的数据类型,虽然这些数据类型被使用的概率要低很多,但是一旦使用在类型映射的时候就会非常头疼。正是因为这个原因,数据类型的映射没有一种特别完美和通用的方式,尤其是对于中间件来说,中间件没法在数据库端做文章,但是目标数据库自己可以,现在有很多国产的数据库会进行MySQL、Oracle方言的兼容,如果实现的完整,数据类型也会兼容,这种情况是最理想的,这意味着中间件不需要做类型的映射。然而这只是理想情况,由于兼容性实现的难度,几乎没有数据库能做到完整的兼容,大多数情况仍然需要由用户或者中间件来处理类型映射。
如果让中间件来进行类型映射,就会发现类型映射是一个吃力不讨好的工作,由于没有完美和通用的方式,想尽量让功能完备的话就需要了解源端数据库和目标端数据库各种数据类型的适用范围、存储范围和精度,然后进行映射,如果致力于通用数据迁移工具或服务的开发(比如datax),源端和目标端都可以是不同的数据库,那类型映射就是n*n的开发任务,非常费劲,而且容易出错。
之前有想过一种看起来成本更小的方式,每个数据库都会将自己的数据类型映射为JDBC的数据类型(java.sql.Types类维护了JDBC的数据类型),jdbc数据类型是已知并且稳定的,并且源端数据库类型映射为jdbc的数据类型是由源端数据库自己维护的,我们只需要完成将jdbc的数据类型映射为目标数据库的类型的工作,将原先nn的映射任务转换为了1n的映射任务,看起来减少了开发成本。但实际上并没有,因为每个数据库将自己的数据类型映射为jdbc的数据类型的时候映射方式也是不一样的,说到底还是与源库的数据类型有关,比如oracle的decimal和Float类型都会映射为jdbc的Types.NUMERIC(值为2)类型,而mysql的Float类型会映射为jdbc的Types.FLOAT(值为6)类型,decimal会映射为Types.DECIMAL(值为3)类型。更何况还要处理精度问题,细分的话应该是precision(精度)和scale(标度),数据类型中一般用precision表示有效位数,而scale表示小数点的位数,比如12.345的precision=5,而scale=3。不同数据库在表示精度的时候方式也是不一样的,比如oracle的timestamp类型,映射到jdbc之后会有scale来记录精度,范围是0-9,也就是小数点后面最高9位,比如"2021-05-08 12:35:24.123123123",而mysql的timestamp类型映射到jdbc之后用的是precision来记录精度的,范围是19-26,也就是有效位数最高26位,换算下来就是小数点后最高6位,比如"2021-05-08 12:35:24.123123",字符长度刚好26。由于类型映射方式的不统一和表示精度方式的不同,最终仍然要按不同数据库来单独进行映射,仍然是n*n的开发任务。
从技术上来说类型映射没有高深的原理,但是要耗费很大的学习成本(学习源库和目标库的每一个数据类型)、测试成本和维护成本,所以一般开源的数据迁移工具比如sqoop、datax都没有表结构迁移的功能,用户必须自己在目标端事先将表创建好,由用户自己保证类型映射的方式,自己承担映射失败的风险。
七、其它注意事项
7.1 sql server的timestamp类型
sql server中timestamp类型和其它关系型数据库都不太一样,sql server中的timestamp并不是一个时间类型,而是一个递增的二进制数字,通常用来作为表的版本戳,timestamp类型不能手动插入和更新数值,而是有数据库自动插入和更新。一个表只能有一个timestamp字段,如果一张表含有timestamp字段,对表进行插入或者对表中的行进行更新的时候,该行的timestamp就会增加,但是要注意timestamp并不是由表维护的,而是数据库(catalog同义)维护的,sql server中一个数据库只会维护一个timestamp。
在sql server中如果想用时间类型,需要使用datetime类型,而不能使用timestamp类型。由于与sql标准不符,sql server后来又增加了rowversion作为timestamp的同义词,所以尽量使用rowversion来代替timestamp。未来sql server可能会修改timestamp的语义和行为,使之与sql标准相符。
7.2 mysql/postgresql setFetchSize()方法
我们在java中执行一个查询语句的时候,如果查询语句的返回结果可能有很多行,为了防止一次性将返回结果全部加载到内存引发OOM,在执行语句之前要先调用setFetchSize方法设置每次加载进内存的行数。
比如这样一个sql:
select * from test_table;
假如这张表有一千万条数据,如果不设置fetchSize,这一千万条数据会全部加载进内存,相当于一个大对象(实际上是一个大数组),如果无法为这个大对象分配足够的内存就会发生OOM。
一般数据库在Statement或者ResultSet中调用setFetchSize方法就可以了:
try (Connection conn = DriverManager.getConnection(jdbcUrl, username, password);
Statement st = conn.createStatement()) {
st.setFetchSize(1000);
...
}
mysql中setFetchSize方法的正确用法:
不过这个方法在mysql和postgresql中有些不同。在mysql中要设置游标移动方式为ResultSet.TYPE_FORWARD_ONLY,也就是游标只能向前移动,然后设置fetchSize为int最小值,这样才能生效,实际上这样设置是一行一行的读取:
try (Connection conn = DriverManager.getConnection(jdbcUrl, username, password);
Statement st = conn.createStatement(esultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY)) {
st.setFetchSize(Integer.MIN_VALUE);
...
}
Postgre SQL中setFetchSize方法的正确用法:
在postgre sql中限制会更加严格:postgre sql的版本至少要是7.4的版本;连接不能是autocommit的模式;游标移动方式为ResultSet.TYPE_FORWARD_ONLY;只能是单条sql,不能是分号分隔的多条语句,只有满足这些条件才能生效:
try (Connection conn = DriverManager.getConnection(jdbcUrl, username, password)) {
conn.setAutoCommit(false);
try (Statement st = conn.createStatement(esultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY)) {
st.setFetchSize(1000);
...
}
PostgreSql官方文档对于setFetchSize()方法的说明:PostgreSql官方文档对于setFetchSize()方法的说明
7.3 mysql中正确的批量操作方式
一般用jdbc进行批量插入的常规写法如下:
// 相关表的建表语句为:create table par_db.par_table(id int, username varchar(20), password varchar(20), gender char(1), married char(1), create_time datetime, update_time datetime, version int)
public void batchInsert(int start, int end) throws SQLException {
// 1、SQL中使用占位符,表有7个字段,每个字段都设置值,所以是7个占位符
String insertSql = "insert into par_db.par_table values(?, ?, ?, ?, ?, ?, ?, ?)";
try (Connection connection = DriverManager.getConnection(jdbcUrl, username, password)) {
// 2、设置自动提交为false
connection.setAutoCommit(false);
// 3、使用PrepareStatement,调用addBatch()方法
try (PreparedStatement pst = connection.prepareStatement(insertSql)) {
for (int i = start; i < end; i++) {
pst.setObject(1, i);
pst.setObject(2, "user_" + i);
pst.setObject(3, "pass_" + i);
pst.setString(4, "M");
pst.setString(5, "Y");
pst.setObject(6, new Date(System.currentTimeMillis()));
pst.setObject(7, new Date(System.currentTimeMillis()));
pst.setObject(8, 1);
pst.addBatch();
}
// 4、批量执行
pst.executeBatch();
// 5、最后手动提交事务
connection.commit();
}
}
}
对于其它数据库而言,上面的写法就是标准写法。但是mysql驱动不一样,如果没有特意的设置,mysql驱动其实仍然是一条一条插入的,举个例子,假如我们想插入了四条语句,我们期望是批量插入,最终批量插入的sql应该是:
begin;
insert into par_db.par_table values(1, 'user_1', 'pass_1', 'M', 'W', '2021-05-07 12:35:42', '2021-05-07 12:35:42', 1), (2, 'user_2', 'pass_2', 'M', 'W', '2021-05-07 12:35:43', '2021-05-07 12:35:43', 1), (3, 'user_3', 'pass_3', 'M', 'W', '2021-05-07 12:35:43', '2021-05-07 12:35:43', 1);
commit;
然而MySQL驱动实际执行的语句是:
begin;
insert into par_db.par_table values(1, 'user_1', 'pass_1', 'M', 'W', '2021-05-07 12:35:42', '2021-05-07 12:35:42', 1);
insert into par_db.par_table values(2, 'user_2', 'pass_2', 'M', 'W', '2021-05-07 12:35:43', '2021-05-07 12:35:43', 1);
insert into par_db.par_table values(3, 'user_3', 'pass_3', 'M', 'W', '2021-05-07 12:35:43', '2021-05-07 12:35:43', 1);
commit;
为什么会这样呢?我们可以去看一下mysql驱动的源码,下面的源码来自mysql8.0.21版本驱动的ClientPreparedStatement类:
// mysql 8.0.21版本驱动中ClientPreparedStatement类
protected long[] executeBatchInternal() throws SQLException {
synchronized (checkClosed().getConnectionMutex()) {
if (this.connection.isReadOnly()) {
throw new SQLException(Messages.getString(
"PreparedStatement.25") + Messages.getString("PreparedStatement.26"),
MysqlErrorNumbers.SQL_STATE_ILLEGAL_ARGUMENT);
}
if (this.query.getBatchedArgs() == null || this.query.getBatchedArgs().size() == 0) {
return new long[0];
}
// we timeout the entire batch, not individual statements
int batchTimeout = getTimeoutInMillis();
setTimeoutInMillis(0);
resetCancelledState();
try {
statementBegins();
clearWarnings();
// 满足这个if语句才会执行批量操作,if语句中有两个条件:
// 第一个batchHasPlainStatements在用户调用PrepareStatement的addPatch()方法时才置为true
// 第二个检查rewriteBatchedStatements参数是否为true
if (!this.batchHasPlainStatements && this.rewriteBatchedStatements.getValue()) {
// canRewriteAsMultiValueInsertAtSqlLevel()方法判断能否改写insert语句
// 1、不能是分号分隔的多个sql语句
// 2、不能是insert into ... select ...语句
// 3、不能是insert into ... on duplicate key update id=last_insert_id(...)语句
if (((PreparedQuery<?>) this.query).getParseInfo().canRewriteAsMultiValueInsertAtSqlLevel()) {
return executeBatchedInserts(batchTimeout);
}
// 其它批量操作,比如批量更新、批量删除或者不能进行insert语句改写的插入操作
// 1、使用PrepareStatement,并调用了addPatch()方法
// 2、批量参数不为空并且批量参数长度大于3 (至少调用4次addBatch()方法)
if (!this.batchHasPlainStatements && this.query.getBatchedArgs() != null
&& this.query.getBatchedArgs().size() > 3 /* cost of option setting rt-wise */) {
return executePreparedBatchAsMultiStatement(batchTimeout);
}
}
// 如果不满足上面的if语句将会串行执行
return executeBatchSerially(batchTimeout);
} finally {
this.query.getStatementExecuting().set(false);
clearBatch();
}
}
}
PrepareStatement的executeBatch()方法最终会调用到ClientPreparedStatement的executeBatchInternal()方法,在这个方法中我们看到它使用了一个if语句,只有满足if语句才会进行进一步的判断,如果不满足就会串行执行。if语句检查了两个条件,第一个条件batchHasPlainStatements只有调用了PrepareStatement的addPatch()方法的时候才会置为true,所以如果没有使用PrepareStatement的addPatch()方法是不会执行批量操作的,第二个条件检查了rewriteBatchedStatements是否为true,如果不为true也不会执行批量操作,这个参数默认是false,那么这个参数要怎么设置呢?在mysql的jdbcUrl中进行设置就可以了:
jdbc:mysql://localhost:3306?rewriteBatchedStatements=true
满足了这两个条件之后还会进一步的判断。mysql驱动可以对insert类型sql进行语言层面的改写,也就是将多条insert语句改写为一条包含多个values的insert语句,mysql驱动会判断能否进行语言层面的改写,也就是canRewriteAsMultiValueInsertAtSqlLevel()方法,该方法进行了几个条件的判断:1、是否是分号分隔的多个语句,如果是,不符合要求;2、是否是insert into … select … 语句,如果是,不符合要求;3、是否是insert into … on duplicate key update id=last_insert_id(…)语句,如果是,不符合要求,这三个条件任何一个不符合都不能改写,但如果复合就会执行executeBatchedInserts方法,executeBatchedInserts方法会把多条insert语句改写为一条包含多个value的insert语句,然后执行。
和insert不一样,对于update和delete操作,没有语言层面的批量执行方式,但如果符合上面源码第36行的所有条件,mysql驱动就会执行executePreparedBatchAsMultiStatement方法,executePreparedBatchAsMultiStatement方法会把多条sql拼接成一条多个分号分隔的复合sql语句,然后执行,举个例子:
public void batchUpdate(int start, int end) throws SQLException {
// 1、SQL中使用占位符
String insertSql = "update par_db.par_table set username=? where id=?";
try (Connection connection = DriverManager.getConnection(jdbcUrl, username, password)) {
// 2、关闭自动提交
connection.setAutoCommit(false);
// 3、使用PreparedStatement,调用addBatch()方法
try (PreparedStatement pst = connection.prepareStatement(sql)) {
for (int i = start; i < end; i++) {
pst.setString(1, "new_user");
pst.setInt(2, i);
pst.addBatch();
}
// 4、批量执行
pst.executeBatch();
// 5、手动提交事务
connection.commit();
}
}
}
最终会调用executePreparedBatchAsMultiStatement方法,在executePreparedBatchAsMultiStatement方法中最终执行的sql是一个复合sql:
update par_db.par_table set username='new_user' where id=0;update par_db.par_table set username='new_user' where id=1;update par_db.par_table set username='new_user' where id=2;update par_db.par_table set username='new_user' where id=3;update par_db.par_table set username='new_user' where id=4;update par_db.par_table set username='new_user' where id=5
这种优化实际上是通过减少客户端和服务端之间的通信次数来提升性能,所以对于mysql的批量操作而言,除了正确的编写批量操作的程序,还需要将rewriteBatchedStatements参数设置为true。














 997
997











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









