






索引+index
index:索引、指数、指针
数据库的索引
数组的索引
。。。
指数基金:index fund
情绪指数:Sentiment index
。。。。
数据有索引,索引和查询效率的关系
数组有索引
System.IndexOutOfRangeException: 索引超出了数组界限。
索引数组,第一个索引始终是数字 0,且添加到数组中的每个后续元素的索引以 1 为增量递增。正如以下代码所示,可以调用 Array 类构造函数或使用数组文本初始化数组来创建索引数组:
Python可以使用索引来引用列表(LIST)中的元素,注意:列表中的索引是从0开始的,并且在列表中还支持负索引;
Python元组可以使用下标索引来访问元组中的值,如下实例:
tup2 = (1, 2, 3, 4, 5, 6, 7 ) print "tup2[1:5]: ", tup2[1:5]
Python中的复合数据类型:字符串,列表和序列。它们用整数作为索引。如果你试图用其他的类型做索引,就会产生错误。
字典的索引可以是字符串,除了这一点,它与其组合类型非常相似。当然,字典的索引也可以是整数。
............................
.............................
LAMP(Linux + Apache + MySQL/MariaDB/Percona + PHP)
LAMP 是最经典的建站环境之一,风靡世界十多年,迄今仍旧十分受中小站长的欢迎。而本脚本只需几个简单交互,选择需要安装的包,即可一路安装,无人值守。
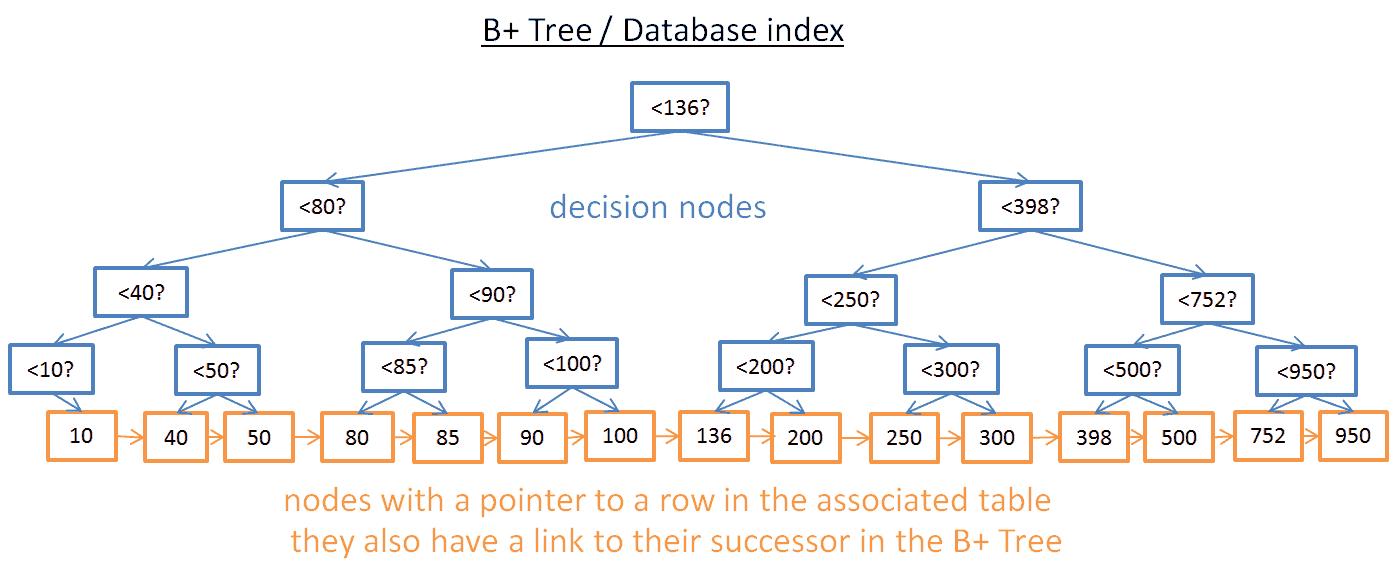
索引是一种数据结构,例如MySQL索引使用B+树来实现。
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。
实际上,您可以把索引理解为一种特殊的目录。数据库索引好比是一本书前面的目录,能加快数据库的查询速度。
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。 提取句子主干,就可以得到索引的本质:索引是数据结构。 我们知道,数据库查询是数据库的最主要功能之一。 我们都希望查询数据的速度能尽可能的快,因此数据库系统的设计者会从查询算法的角度进行优化。
什么是索引?
数据库索引好比是一本书前面的目录,能加快数据库的查询速度。
例如这样一个查询:select * from table1 where id=44。如果没有索引,必须遍历整个表,直到ID等于44的这一行被找到为止;有了索引之后(必须是在ID这一列上建立的索引),直接在索引里面找44(也就是在ID这一列找),就可以得知这一行的位置,也就是找到了这一行。可见,索引是用来定位的。
索引分为聚簇索引和非聚簇索引两种,聚簇索引是按照数据存放的物理位置为顺序的,而非聚簇索引就不一样了;聚簇索引能提高多行检索的速度,而非聚簇索引对于单行的检索很快。
概述
建立索引的目的是加快对表中记录的查找或排序。
为表设置索引要付出代价的:一是增加了数据库的存储空间,二是在插入和修改数据时要花费较多的时间(因为索引也要随之变动)。
为什么要创建索引
创建索引可以大大提高系统的性能。
第一,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
第二,可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
第三,可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
第四,在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
第五,通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
也许会有人要问:增加索引有如此多的优点,为什么不对表中的每一个列创建一个索引呢?因为,增加索引也有许多不利的方面。
第一,创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
第二,索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
第三,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
在哪建索引
索引是建立在数据库表中的某些列的上面。在创建索引的时候,应该考虑在哪些列上可以创建索引,在哪些列上不能创建索引。一般来说,应该在这些列上创建索引:
在经常需要搜索的列上,可以加快搜索的速度;
在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构;
在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度;在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;
在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
同样,对于有些列不应该创建索引。一般来说,不应该创建索引的的这些列具有下列特点:
第一,对于那些在查询中很少使用或者参考的列不应该创建索引。这是因为,既然这些列很少使用到,因此有索引或者无索引,并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度和增大了空间需求。
第二,对于那些只有很少数据值的列也不应该增加索引。这是因为,由于这些列的取值很少,例如人事表的性别列,在查询的结果中,结果集的数据行占了表中数据行的很大比例,即需要在表中搜索的数据行的比例很大。增加索引,并不能明显加快检索速度。
第三,对于那些定义为text, image和bit数据类型的列不应该增加索引。这是因为,这些列的数据量要么相当大,要么取值很少,不利于使用索引。
第四,当修改性能远远大于检索性能时,不应该创建索引。这是因为,修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能,降低检索性能。因此,当修改操作远远多于检索操作时,不应该创建索引。
数据库优化
此外,除了数据库索引之外,在LAMP结果如此流行的今天,数据库(尤其是MySQL)性能优化也是海量数据处理的一个热点。下面就结合自己的经验,聊一聊MySQL数据库优化的几个方面。
首先,在数据库设计的时候,要能够充分的利用索引带来的性能提升,至于如何建立索引,建立什么样的索引,在哪些字段上建立索引,上面已经讲的很清楚了,这里不在赘述。另外就是设计数据库的原则就是尽可能少的进行数据库写操作(插入,更新,删除等),查询越简单越好。如下:
其次,配置缓存是必不可少的,配置缓存可以有效的降低数据库查询读取次数,从而缓解数据库服务器压力,达到优化的目的,一定程度上来讲,这算是一个“围魏救赵”的办法。可配置的缓存包括索引缓存(key_buffer),排序缓存(sort_buffer),查询缓存(query_buffer),表描述符缓存(table_cache),如下图:
第三,切表,切表也是一种比较流行的数据库优化方法。分表包括两种方式:横向分表和纵向分表,其中,纵向分表比较有使用意义,但是分表会造成查询的负担,因此在数据库设计之初,要想好:
第四,日志分析,在数据库运行了较长一段时间以后,会积累大量的LOG日志,其实这里面的蕴涵的有用的信息量还是很大的。通过分析日志,可以找到系统性能的瓶颈,从而进一步寻找优化方案。
以上讲的都是单机MySQL的性能优化的一些经验,但是随着信息大爆炸,单机的数据库服务器已经不能满足我们的需求,于是,多多节点,分布式数据库网络出现了,其一般的结构如下:
这种分布式集群的技术关键就是“同步复制”。。。
Computer science
- Index, a key in an associative array
- Index (typography), a character in Unicode, its code is 132
- Index, the dataset maintained by search engine indexing
- Array index, an integer pointer into an array data structure
- BitTorrent index, a list of .torrent files available for searches
- Database index, a data structure that improves the speed of data retrieval
- Index mapping of raw data for an array
- Index register, a processor register used for modifying operand addresses during the run of a program
- Indexed color, in computer imagery
- Indexed Sequential Access Method (ISAM), used for indexing data for fast retrieval
- Lookup table, a data structure used to store precomputed information
- Site map, or site index, a list of pages of a web site accessible to crawlers or users
- Subject indexing, describing the content of a document by keywords
- Web indexing, Internet indexing
- Webserver directory index, a default or index web page in a directory on a web server, such as index.html
参考:数据库索引到底是什么,是怎样工作的?
参考:Index+ en.wikipedia.org
参考:数据结构与算法(7):数据库索引原理及优化















 2603
2603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











