







 超级会员免费看
超级会员免费看
 本文介绍了在机器学习中遇到的数据不平衡问题及其影响,并重点讲解了如何使用Python的imbalanced-learn库中的SVMSMOTE方法进行上采样,以解决类别不平衡问题。此外,还提到了下采样、代价敏感学习和阈值调整等处理不平衡数据集的方法。
本文介绍了在机器学习中遇到的数据不平衡问题及其影响,并重点讲解了如何使用Python的imbalanced-learn库中的SVMSMOTE方法进行上采样,以解决类别不平衡问题。此外,还提到了下采样、代价敏感学习和阈值调整等处理不平衡数据集的方法。
python使用imbalanced-learn的SVMSMOTE方法进行上采样处理数据不平衡问题
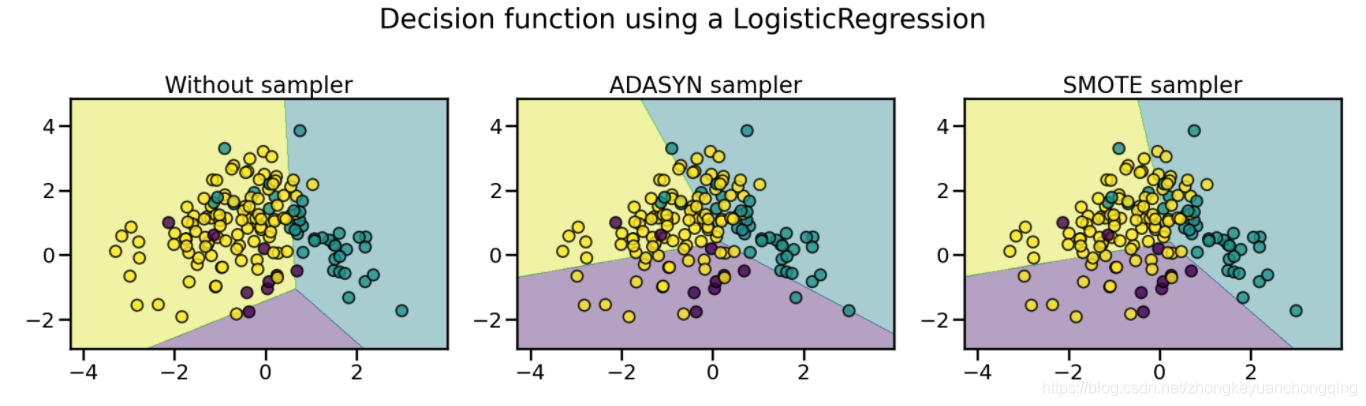
机器学习中常常会遇到数据的类别不平衡(class imbalance),也叫数据偏斜(class skew)。以常见的二分类问题为例,我们希望预测病人是否得了某种罕见疾病。但在历史数据中,阳性的比例可能很低(如百分之0.1)。在这种情况下,学习出好的分类器是很难的,而且在这种情况下得到结论往往也是很具迷惑性的。
以上面提到的场景来说,如果我们的分类器总是预测一个人未患病,即预测为反例,那么我们依然有高达99.9%的预测准确率。然而这种结果是没有意义的,对于这种情况该如何去评估模型如何去训练模型或者调整数据集?
所谓的不平衡数据集指的是数据集各个类别的样本量极不均衡。以二分类问题为例,假设正类的样本数量远大于负类的样本数量,通常情况下通常情况下把多数类样本的比例接近100:1这种情况下的数据称为不平衡数据。不平衡数据的学习即需要在分布不均匀的数据集中学习到有用的信息。
为什么类不平衡是不好的

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1010
1010

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











