







磁盘、內存、缓存(cache)和寄存器特点不同,参考LLVM寄存器分配(一) - GetIt01

0、使用选项llc -mtriple=aarch64-none-linux-gnu -verify-machineinstrs -mattr=+neon **.mir -o - -debug-only=regalloc -run-pass=simple-register-coalescing显示寄存器分配情况
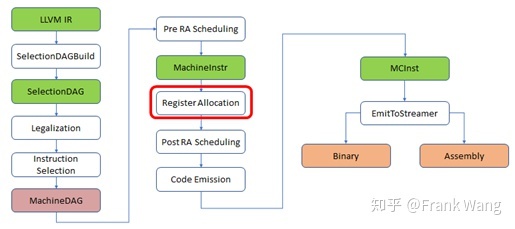
1、使用llc -O3 reduced.ll -stop-before=greedy -simplify-mir -o - &> greedy-simple.mir获取寄存器分配前的输入MIR文件,也就是寄存器分配发生在MIR阶段,和机器相关
注意:选项-simplify-mir 只是简化输出表达,详见https://llvm.org/docs/MIRLangRef.html
2、LLVM中支持的寄存器分配算法有4种:Basic Register Allocator、Fast Register Allocator、PBQP Register Allocator、Greedy Register Allocator,参考
3、LLVM3.0之前的缺省寄存器分配器是线性扫描分配器,LLVM3.0之后新增了基本(basic)分配器和贪厌(greedy)分配器,而贪厌分配器是LLVM新的缺省分配器. 并详细介绍llvm贪婪算法greedy的实现细节,参考LLVM寄存器分配(二) - 知乎
calculateSpillWeightAndHint->weightCalcHelper 实际计算指令的Weight
a) weightCalcHelper->getSpillWeight->getBlockFreqRelativeToEntryBlock 可以看到,spill代价和指令对应BB块的概率有关
结论:通过调整weight来决定哪些寄存器被spill ?
4、寄存器默认的顺序定义,参考LLVM物理寄存器分配顺序问题 - 知乎,一般的顺序
a) 硬件自动保存的callee-save, b) caller-save c) callee-save d) 返回值寄存器 e) 参数寄存器

5、栈的图染色特性使能及调试方法,参考Is SafeStack coloring safe to enable? - #7 by tstellar - IR & Optimizations - LLVM Discussion Forums
6、 浮点数初始化,gcc使用浮点寄存器d0, clang使用标量寄存器x8,参考Compiler Explorer,是否在大型用例中需要评估哪类寄存器是瓶颈 ?
7、TwoAddressInstruction尝试将二元操作数的指令做转换:a = b op c a=b, a op= c,但是我们却无法在后续的AArch64 Redundant Copy Elimination优化mov z3.d, z0.d+orr z3.d, z3.d, #0x1中的mov指令,这是因为sve中orr要求源和目的操作数必须一致(硬件约束),参考https://github.com/llvm/llvm-project/issues/54930,相关的pattern描述中增加了Constraints
1629 class sve_int_log_imm<bits<2> opc, string asm>
1630 : I<(outs ZPR64:$Zdn), (ins ZPR64:$_Zdn, logical_imm64:$imms13),
1631 asm, "\t$Zdn, $_Zdn, $imms13",
1632 "", []>, Sched<[]> {
1640
1641 let Constraints = "$Zdn = $_Zdn";
1642 let DecoderMethod = "DecodeSVELogicalImmInstruction";
1645 }defm ORR_ZI : sve_int_log_imm<0b00, "orr", "orn", or>;
8、isel 中插入 INSERT_SUBREG--> Two-Address instrunction中将调整为sub_32:gpr64->Virtula Register Rewriter 中引入rename $w0 = KILL $w0, implicit-def $x0-> 从而最终能够消除冗余的寄存器mov (SUBREG_TO_REG相比INSERT_SUBREG更加高效,参考D132325LLVM: LLVM: llvm::TargetOpcode Namespace Reference)

const TargetRegisterClass *RC = MRI->getRegClass(DstReg)
size_t RegSize = TRI->getRegSizeInBits(*RC)
TRI->isTypeLegalForClass(*RC, MVT::i64)
9、避免对NZCV相关的寄存器进行合并优化(因为没有NZCV的spill 数据通路),参考D127294
10、Pattern描述中增加对寄存器约束,确保分配不同的寄存器,参考⚙ D138888 [AArch64][SVE] Replace destructive operand of vector zeros with a bundled MOVPRFX instruction
Given the unary instructions have a dedicated operand for the inactive lanes I believe we can add a constraint to PredOneOpPassthruPseudo to ensure safe register allocation for movprfx usage. Something like
let Constraints = !if(!eq(flags, FalseLanesZero), "$Zd = $Passthru,@earlyclobber $Zd", "");
11、针对spill的寄存器分配处理策略,PR #67351
使用向量寄存器保存spill
12、swp寻址II时考虑寄存器压力,参考pr74807
13、寄存器分配不考虑prologue/epilogue和shrink-wrapping的代价,参考aarch64 unconditionally spills when x86-64 does not · Issue #82252 · llvm/llvm-project (github.com)

















 545
545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









