







1、概述
最近做一个数值统计,统计固定周期内(比如100行统一次)每列的非零值,实现不难,先统计0值个数,再计算非零值个数,主要是有些关于dataframe的操作技巧可以作为以后的参考。
data.csv文件数据示例格式如下:
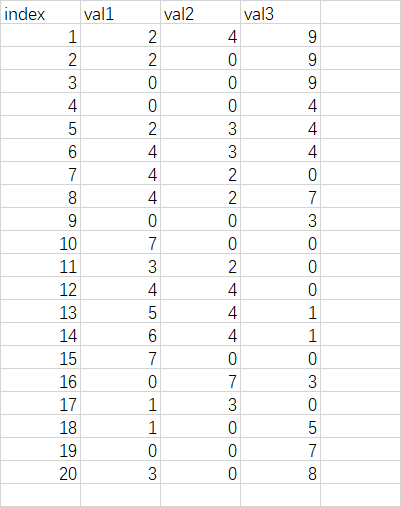
想要得到的结果为:

2、代码
import pandas as pd
def non_zeros_count(df):
s = 0
calc_interval = 5 # 统计周期数
new_columns = []
for i in range(len(df.columns)):
new_columns.append(df.columns[i]+'_non_zero_count') # 重新组织列名
non_zeros_count = pd.DataFrame(columns=df.columns[1:]) # 新建dataframe 储存最后统计结果(没有计算第一列“时间”)
# 对所有数据按照每 “calc_interval” 计算每个字段中的非0个数
while s + calc_interval <= df.shape[0]:
data_piece = df.iloc[s:s + calc_interval, 1:]
count_zero = data_piece.apply(lambda x: x.value_counts().get(0.0, 0.0)) # 0值个数
# np.count_nonzero(data_piece,axis = 0) #这种方法也可以得到,但是得到的是类型是ndarray
non_zeros = calc_interval - count_zero # 非零值个数(每列计算周期内的总数-每列的0值数)
non_zeros_to_frame = non_zeros.to_frame() # series转dataframe
non_zeros_transp = pd.DataFrame(non_zeros_to_frame.values.T,
index=non_zeros_to_frame.columns,
columns=non_zeros_to_frame.index) # 取转置
non_zeros_count = pd.concat([non_zeros_count, non_zeros_transp]) # 数据合并
s = s + calc_interval
non_zeros_count.index = [i for i in range(non_zeros_count.shape[0])]
# non_zeros_count.values.reshape(30,24) # dataframe
non_zeros_count.columns = new_columns[1:] # 重新修改列名
non_zeros_count.to_csv('./non_zeros_count.csv',encoding= 'utf-8')
if __name__=='__main__':
sv_data = pd.read_csv('data.csv',encoding='utf-8')
non_zeros_count(sv_data)















 491
491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











