







阿狗要好好来整理一下啦,感觉自己数据结构不太熟,比如排序算法的思想大概理解,用代码复现又是另一回事,懂得不同场景下的应用又又又又是另一回事,碰到笔试排序算法的题又双叒叕是另另另一回事。所以说啊,学无止境,学海无涯阿狗得飘啊。还有还长一段时间呢,阿狗加油ヾ(◍°∇°◍)ノ゙
01---算法介绍:
1、冒泡排序
思想:
通过与相邻元素的比较和交换来把最大的值交换到最后面。这个过程类似于水泡一样,重的往下沉(轻的往上浮),因此得名。
实现:
定义两个for循环,外层循环控制排序趟数,内层循环控制每一趟排序多少次。

这个图实在是太可爱啦,如图所以,每次相邻两两比较将最大的往后放,再来放次大的,直到遍历结束。
看我捞代码还带测试:
public class BubbleSort {
public static void bubblesort(int[] arr){
for(int i=0;i<arr.length-1;i++){ //外层循环控制排序趟数
for(int j=0;j<arr.length-i-1;j++){ 内层循环控制每一趟排序多少次
if(arr[j]>arr[j+1]){
int t=arr[j];
arr[j]=arr[j+1];
arr[j+1]=t;
}
}
}
}
public static void main(String[] args){
int[] arr={2,5,8,3,5,6,9,1};
BubbleSort.bubblesort(arr);
for(int i=0;i<arr.length;i++){
System.out.print(arr[i]+",");
}
}
}2、选择排序
思想:
首先在未排序序列中找到最小元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找次小元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
实现:
定义两个for循环,外层循环控制比较次数,内层循环遍历未排序元素。
与冒泡排序相比,冒泡是通过相邻元素的比较和交换,而选择排序是通过对整体遍历一遍再进行的挑选,是在确定了最小数的前提下才进行交换,大大减少了交换的次数。

public class SelectSort {
public static void selectsort(int[] arr){
for(int i=0;i<arr.length-1;i++){
for(int j=i+1;j<arr.length;j++){
if(arr[i]>arr[j]){
int t=arr[i];
arr[i]=arr[j];
arr[j]=t;
}
}
}
}3、插入
思想:
通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。这个其实和我们打扑克牌的时候一毛一样,你想想你是怎么排牌的,哈哈哈哈哈~~
实现:定义两个for循环,外层循环遍历元素,内层循环比较未排序元素应该向已排序元素插入的位置。

public static void insertsort(int[] arr){
for(int i=0;i<arr.length;i++){
for(int j=i;j>0;j--){
if(arr[j]<arr[j-1]){
int t=arr[j];
arr[j]=arr[j-1];
arr[j-1]=t;
}
}
}
}4、归并
思想:
该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。即:先递归划分子问题,然后合并结果。
实现:
1)把长度为n的输入序列分成两个长度为n/2的子序列;
2)对这两个子序列分别采用归并排序;
3)将两个排序好的子序列合并成一个最终的排序序列。

分治法通常有3步:Divide(分解子问题的步骤) 、 Conquer(递归解决子问题的步骤)、 Combine(子问题解求出来后合并成原问题解的步骤)。
伪代码:

注意合并的思想,其实就是两段子序列分别比较它们的首元素,大的就往list里面放。加一个循环判断,如果左边的放完了就直接把右边的整个拷贝,反之亦然。
注意一定要判断如果子序列长度为1,返回其本身,不然会StackOverflowError!!!
public class MergeSort{
public static void main(String[] args){
int [] arr={3,56,2,1,8,4,6};
int [] arr2=sort(arr);
for(int i:arr2){
System.out.print(i+",");
}
}
public static int[] sort(int[] arr){
if(arr.length <=1){
return arr;
}
int len=arr.length/2;
int[] left=sort(Arrays.copyOfRange(arr, 0,len));
int[] right=sort(Arrays.copyOfRange(arr, len, arr.length));
return merge(left,right);
}
public static int[] merge(int[] left,int[] right){
int l=0;
int r=0;
List<Integer> list=new ArrayList();
while(l<left.length&&r<right.length){
if(left[l]<right[r]){
list.add(left[l]);
l++;
}
else{
list.add(right[r]);
r++;
}
}
if(l>=left.length){
for(int i=r;i<right.length;i++){
list.add(right[i]);
}
}
if(r>=right.length){
for(int i=l;i<left.length;i++){
list.add(left[i]);
}
}
int[] result=new int[list.size()];
for(int i=0;i<list.size();i++){
result[i]=list.get(i);
}
return result;
}
}5、快排
思想:
在待排序的n个记录中任取一个记录(通常取第一个记录),把该记录放入适当位置后,数据序列被此记录划分成两部分。所有关键字比该记录关键字小的记录放置在前一部分,所有比它大的记录放置在后一部分,并把该记录排在这两部分的中间(称为该记录归位),这个过程称作一趟快速排序。
实现:
选数列中第一个数作为 “基准”(pivot),定义两个变量---i、j。j从后面开始遍历,若小于基准则与其交换位置,同时 i 从前开始遍历,若大于基准再交换位置,再 j 从后开始遍历。这样一趟下来所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
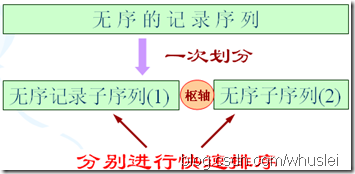

public class QuickSort{
public static void partion(int[] arr,int start,int end){
if(start>end){
return;
}
int i=start;
int j=end;
int index=arr[i];
while(i<j&arr[j]>=index){
j--;
}
if(i<j&&arr[j]<index){
arr[i++]=arr[j];
}
while(i<j&&arr[i]<=index){
i++;
}
if(i<j&&arr[i]>index){
arr[j--]=arr[i];
}
arr[i]=index;
partion(arr, start, i-1);
partion(arr, i+1, end);
}
public static void quicksort(int arr[]){
partion(arr,0,arr.length-1);
}
public static void main(String[] args){
int[] arr={3,5,34,14,52,13};
quicksort(arr);
System.out.println(Arrays.toString(arr));
}
}6、希尔
思想:
递减增量排序算法,实际上是一种分组插入方法。
实现:
先取定一个小于n的整数d1作为第一个增量,把表的全部记录分成d1个组,所有距离为d1的倍数的记录放在同一个组中,在各组内进行直接插入排序;然后,取第二个增量d2(<d1),重复上述的分组和排序,直至所取的增量dt=1(dt<dt-1<…<d2<d1),即所有记录放在同一组中进行直接插入排序为止。

三重循环,一重用来控制每次步长,直到变为1。一重用来控制比较的元素,一重控制相隔n个步长要比较的元素。
同时注意在第三重比较的时候,为了防止数组越界我定义 j=i-h 比较 arr [ j ] 和 arr [ j+h ]的值。
public static void shell(int[] arr){
int l=arr.length/2;
for(int h=l;h>0;h=h/2){
for(int i=h;i<arr.length;i++){
for(int j=i-h;j>=0;j=j-h){
if(arr[j]>arr[j+h]){
int m=arr[j];
arr[j]=arr[j+h];
arr[j+h]=m;
}
else break;
}
}
}
}
7、堆排序
思想:
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
注意:如果想升序排序就使用大顶堆,反之使用小顶堆。原因是堆顶元素需要交换到序列尾部。
实现:
1)创建一个堆H[0..n-1]
2)把堆首(最大值)和堆尾互换
3)把堆的尺寸缩小1,并调用shift_down(0),目的是把新的数组顶端数据调整到相应位置
4) 重复步骤2,直到堆的尺寸为1

package paixu;
public class HeapSort{
//堆排序
public static void adjustMinHeap(int a[],int pos,int len){
int temp;
int child;
for(temp=a[pos];2*pos+1<=len;pos=child){
child=2*pos+1;
if(child<len&&a[child]>a[child+1])
child++;
if(a[child]<temp)
a[pos]=a[child];
else break;
}
a[pos]=temp;
}
public static void myMinHeapSort(int array[]){
int i;
int len=array.length;
for(i=len/2-1;i>=0;i--)
adjustMinHeap(array,i,len-1);
for(i=len-1;i>=0;i--){
int tmp=array[0];
array[0]=array[i];
array[i]=tmp;
adjustMinHeap(array,0,i-1);
}
}
public static void main(String[] args){
int a[]={3,9,8,4,2,1};
myMinHeapSort(a);
for(int i=0;i<a.length;i++){
System.out.print(a[i]+",");
}
}
}7、基数排序
思想:
它是一种非比较排序。基数排序是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次类推,直到最高位。

02---算法复杂度

相关概念
稳定:两个相同的值a=b,如果a原本在b前面,排序之后a仍然在b的前面。
不稳定:两个相同的值a=b,如果a原本在b的前面,排序之后 a 可能会出现在 b 的后面。
时间复杂度:对排序数据的总的操作次数。反映当n变化时,操作次数呈现什么规律。
空间复杂度:是指算法在计算机内执行时所需存储空间的度量,它也是数据规模n的函数。
03---场景应用
-
数据规模很小(插入、简单选择、冒泡)
- 数据有序时,可选直接插入排序;
- 数据无序时,对稳定性不作要求宜用简单选择排序,对稳定性有要求宜用插入或冒泡
-
数据规模一般(快速排序、归并排序)
- 完全可以用内存空间,序列杂乱无序,对稳定性没有要求,快速排序,此时要付出log(N)的额外空间。
- 序列本身可能有序,对稳定性有要求,空间允许下,宜用归并排序
-
数据规模很大(归并、桶)
- 对稳定性有求,则可考虑归并排序。
- 对稳定性没要求,宜用堆排序
-
待排序列初始基本有序(正序),宜用直接插入,冒泡
注:快速排序是目前基于比较的内部排序中最好的方法, 其次是归并和希尔,堆排序在数据量很大时效果明显。当数据是随机分布时快速排序的平均时间最短。















 570
570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









