







一.理解生产者与消费者
linux中有了生产者消费者这一概念,那么是不是可以和现实生活中的生产者消费者相联系起来去看待它?回答是肯定的,在我们生活中我们时时刻刻充当了消费者的角色,生产者生产商品,那么两者之间要进行交易那么就有了一个公共的交易场所,比如学校超市。可以用这样一个图来解释这种关系。

从中我们可以总结出一个 3 2 1 原则

如果我们去买东西,超市里面没有货物,我们会不会隔一秒就去查看一下有么有货物?很明显不会,此时我们应该怎么做呢?是不是可以留一个电话给售货员,让她有货的时候给我打电话,这时我只需要在接到电话的时候才去超市,可以利用时间去做其他的事,这样就能提高效率。
二 . 为什么要有缓冲区?
生产者与消费者之间直接交换数据不就完了么?还弄一个第三方(缓冲区)干什么?其实这样的优点有很多。
(1)高效利用时间
在实际生活中我们都会看到有可能生产者生产比较慢,或者消费者消费比较慢的情况。假如生产者生产的数据太多,消费者来不及消费,这时把那些未处理掉的数据放在缓冲区是不是比较合理的?然后生产者生产可以慢下来,等待消费者处理数据。同样的,如果没有这样一个缓冲区,那么生产者一次性生产了很多数据,全部交给消费者,但是消费者又要不了这么多,而消费者存放数据的地方也没有,那么创建一个缓冲区是不是很合理?
(2)支持并发
如果生产者直接调用消费者的某个方法,由于函数调用时同步的,在消费者方法没有返回之前,生产者就会一直等待,如果消费者一天处理一条数据,生产者任然在那死等(阻塞式等待),那么时间是不是就被浪费了。这是不合理的。
但是我们使用了生产者/消费者模式(3 2 1 原则),生产者与消费者是两个独立的并发主体,
生产者生产完成一条数据并放到缓冲区后,就可以生产下一条数据了,不依赖于消费者消费的速度。
这里我们写了一个基于单链表的生产者消费者模型
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
typedef int DataType; //为了实现通用,进行类型重命名
typedef struct ListNode
{
DataType data; //存放的数据
struct ListNode* next; //存放下一个节点的地址
}ListNode;
ListNode* List = NULL;
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER; //创建一把锁
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;//信号量
ListNode* BuyNode(DataType x)
{
ListNode *ptr;
ptr = (ListNode*)malloc(sizeof(ListNode));//动态开辟一块内存
if(ptr == NULL)
{
perror("malloc");
exit(1);
}
ptr->data = x;
ptr->next = NULL;
return ptr;
}
//打印所有节点
void PrintList(ListNode* pList)
{
//1.空
//2.多个节点,NULL结尾
if(pList == NULL)
return;
else
{
while(pList != NULL)
{
printf("%d ", pList->data);
pList = pList->next;
}
}
printf("\n");
}
//头部插入一个节点
void PushFront(ListNode** ppList, DataType x)
{
//1.没有节点
//2.多个节点
if(*ppList == NULL)
{
*ppList = BuyNode(x);
}
else
{
ListNode* tmp = BuyNode(x);
tmp->next = (*ppList);
*ppList = tmp;
}
}
//头部删一个节点
void PopFront(ListNode** ppList, int* out)
{
//没有节点
//多个节点
if((*ppList)->next == NULL)
return;
else
{
ListNode* tmp = (*ppList)->next;
(*ppList)->next = tmp->next;
*out = tmp->data;
free(tmp);
}
}
//销毁所有节点
void destroyList(ListNode **pList)
{
if(*pList == NULL)
return;
while(*pList != NULL)
{
ListNode *tmp = NULL;
tmp = (*pList)->next;
free(*pList);
*pList = tmp;
}
}
void* consume(void* arg)
{
int c = 0;
while(1){
c = -1;
sleep(1);
//加锁
pthread_mutex_lock(&lock);
while(List->next == NULL){
printf("consumer begin waiting\n");
pthread_cond_wait(&cond, &lock);
}
PopFront(&List, &c);
//解锁
pthread_mutex_unlock(&lock);
printf("consumer is done:%d\n", c);
}
}
void* product(void* arg)
{
sleep(1);
while(1){
int num = rand()%1234;
//加锁
pthread_mutex_lock(&lock);
PushFront(&List, num);
//解锁
pthread_mutex_unlock(&lock);
//获取返回时的状态
pthread_cond_signal(&cond);
printf("product is done:%d\n", num);
sleep(3);
}
}
int main()
{
pthread_t c,p;
//创建两个线程
pthread_create(&c, NULL, consume, NULL);
pthread_create(&p, NULL, product, NULL);
//线程等待,必须等待
pthread_join(c, NULL);
pthread_join(p, NULL);
pthread_mutex_destroy(&lock);
pthread_cond_destroy(&cond);
destroyList(&List);
return 0;
}
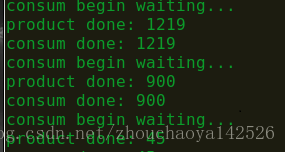
至此,生产者消费者就完成了。
总结如下:
1.考虑生产者与消费者对缓冲区操作时的互斥与同步机制。
2.生产者只有等待有空缓冲区才能投放产品,消费者要等待有非空缓冲区才能去取产品。为了很好地解释缓冲区问题,我们可以用一个环形队列解释它。
三、环形队列
缓冲区是一个先进先出队列。写入模块将信息插入队列;读出模块将信息弹出队列。
写入模块与读出模块需要进行信息的协调和同步。
对于多线程和多进程的写入或读出模块,写入模块间以及读出模块间需要进行临界区处理。
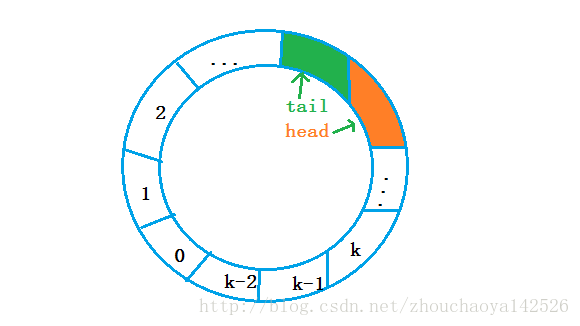
四、环形队列特点
1.保证互斥或串行访问资源,不套圈(摒弃了空和满的两种状态),消费者在生产者之后,生产者和消费者可同时运行。
2.生产者申请格子成功则可生产,生产完成之后释放数据,利于消费者消费。
3.消费者消费数据之后,释放格子,便于生产者生产。
#include <stdio.h>
#include <pthread.h>
#include <semaphore.h>
#define SIZE 64
int ring[SIZE];
sem_t dataSem; //定义两个信号量
sem_t blankSem;
void* consume(void* arg)//消费者
{
int i = 0;
int data;
while(1){
//sleep(1);
sem_wait(&dataSem);
data = ring[i++];
sem_post(&blankSem);
i %= SIZE;
printf("consume : %d\n", data);
sleep(1);
}
}
void* product(void* arg)//生产者
{
int i = 0;
int data = 0;
while(1){
//sleep(1);
sem_wait(&blankSem);
ring[i++] = data;
//sem_post(&data);
i %= SIZE;
sem_post(&dataSem);
printf("product: %d\n", data++);
}
sleep(1);
}
int main()
{
pthread_t c,p;
sem_init(&blankSem, 0, SIZE);
sem_init(&dataSem, 0, 0);
pthread_create(&c, NULL, consume, NULL);
pthread_create(&c, NULL, product, NULL);
pthread_join(c, NULL);
pthread_join(p, NULL);
sem_destroy(&blankSem);
sem_destroy(&dataSem);
return 0;
}














 444
444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









