







转载:https://www.cnblogs.com/haoxinyue/p/5208136.html
系统唯一ID是我们在设计一个系统的时候常常会遇见的问题,也常常为这个问题而纠结。生成ID的方法有很多,适应不同的场景、需求以及性能要求。所以有些比较复杂的系统会有多个ID生成的策略。下面就介绍一些常见的ID生成策略。
1. 数据库自增长序列或字段
最常见的方式。利用数据库,全数据库唯一。
优点:
1)简单,代码方便,性能可以接受。
2)数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
1)不同数据库语法和实现不同,数据库迁移的时候或多数据库版本支持的时候需要处理。
2)在单个数据库或读写分离或一主多从的情况下,只有一个主库可以生成。有单点故障的风险。
3)在性能达不到要求的情况下,比较难于扩展。
4)如果遇见多个系统需要合并或者涉及到数据迁移会相当痛苦。
5)分表分库的时候会有麻烦。
优化方案:
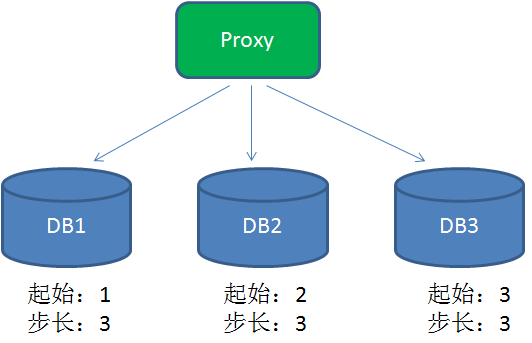
1)如果有多个Master库,则每个Master库设置的不同的起始值,步长和Master库数量相等。比如:Master1 生成的是 1,4,7,10,Master2生成的是2,5,8,11 Master3生成的是 3,6,9,12。这样就可以有效生成集群中的唯一ID,也可以大大降低ID生成数据库操作的负载。
2. UUID
UUID是通用唯一识别码 (Universally Unique Identifier),可以生成一个长度32位的全局唯一识别码。可以利用数据库也可以利用程序生成。
优点:
1)简单,代码方便。
2)生成ID性能非常好,基本不会有性能问题。
3)全球唯一,在遇见数据迁移,系统数据合并,或者数据库变更等情况下,可以从容应对。
缺点:
1)没有排序,无法保证趋势递增。
2)UUID往往是使用字符串存储,查询的效率比较低(B+树)。
3)存储空间比较大,如果是海量数据库,就需要考虑存储量的问题。
4)传输数据量大
5)不可读。
优化方案:
1)为了解决UUID不可读,可以使用UUID to Int64的方法
2)为了解决UUID无序,NHibernate在其主键生成方式中提供了Comb算法(combined guid/timestamp)。保留GUID的10个字节,用另6个字节表示GUID生成的时间(DateTime)
3. Redis生成ID
当使用数据库来生成ID性能不够要求的时候,我们可以尝试使用Redis来生成ID。这主要依赖于Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR和INCRBY来实现。
可以使用Redis集群来解决单点故障和获取更高的吞吐量,如一个集群中有5台Redis。可以初始化每台Redis的值分别是1,2,3,4,5,然后步长都是5。
另外,比较适合使用Redis来生成每天从0开始的流水号。比如订单号=日期+当日自增长号。可以每天在Redis中生成一个Key,使用INCR进行累加。
优点:
1)不依赖于数据库,灵活方便,且性能优于数据库。
2)数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
1)需要编码和配置的工作量比较大。
4. Twitter的snowflake算法
snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID),最后还有一个符号位,永远是0。具体实现的代码可以参看https://github.com/twitter/snowflake。
snowflake算法可以根据自身项目的需要进行一定的修改。比如估算未来的数据中心个数,每个数据中心的机器数以及统一毫秒可以能的并发数来调整在算法中所需要的bit数。
Java代码实例
import java.io.UnsupportedEncodingException;
import java.net.InetAddress;
/**
* @ClassName: SnowflakeIdWorker
*/
public class SnowflakeIdWorker {
/** 开始时间截 (2015-01-01) */
private final long twepoch = 1420041600000L;
/** 机器id所占的位数 */
private final long workerIdBits = 5L;
/** 数据标识id所占的位数 */
private final long datacenterIdBits = 5L;
/** 支持的最大机器id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数) */
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
/** 支持的最大数据标识id,结果是31 */
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
/** 序列在id中占的位数 */
private final long sequenceBits = 12L;
/** 机器ID向左移12位 */
private final long workerIdShift = sequenceBits;
/** 数据标识id向左移17位(12+5) */
private final long datacenterIdShift = sequenceBits + workerIdBits;
/** 时间截向左移22位(5+5+12) */
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
/** 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095) */
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
/** 工作机器ID(0~31) */
private long workerId;
/** 数据中心ID(0~31) */
private long datacenterId;
/** 毫秒内序列(0~4095) */
private long sequence = 0L;
/** 上次生成ID的时间截 */
private long lastTimestamp = -1L;
public SnowflakeIdWorker(long workerId, long datacenterId) {
this.workerId = workerId;
this.datacenterId = datacenterId;
}
public synchronized long nextId() {
long timestamp = timeGen();
//如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常
if (timestamp < lastTimestamp) {
throw new RuntimeException(
String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
//如果是同一时间生成的,则进行毫秒内序列
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
//毫秒内序列溢出
if (sequence == 0) {
//阻塞到下一个毫秒,获得新的时间戳
timestamp = tilNextMillis(lastTimestamp);
}
}
//时间戳改变,毫秒内序列重置
else {
sequence = 0L;
}
//上次生成ID的时间截
lastTimestamp = timestamp;
//移位并通过或运算拼到一起组成64位的ID
return ((timestamp - twepoch) << timestampLeftShift) //
| (datacenterId << datacenterIdShift) //
| (workerId << workerIdShift) //
| sequence;
}
/**
* 阻塞到下一个毫秒,直到获得新的时间戳
* @param lastTimestamp 上次生成ID的时间截
* @return 当前时间戳
*/
protected long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
/**
* 返回以毫秒为单位的当前时间
* @return 当前时间(毫秒)
*/
protected long timeGen() {
return System.currentTimeMillis();
}
private static String hostName;
static {
try {
InetAddress netAddress = InetAddress.getLocalHost();
hostName = netAddress.getHostAddress();
} catch (Exception e) {
hostName = "0.0.0.1";
}
}
public static String getHostName() {
return hostName;
}
public static String getHostPK4() {
String pk = hostName.replaceAll("\\.", "");
return pk.substring(pk.length() - 1, pk.length()) + "-";
}
public String[] generate(String host, int amount) throws UnsupportedEncodingException {
SnowflakeIdWorker idWorker = new SnowflakeIdWorker(0, 0);
String[] newOids = new String[amount];
String pk = host == null ? getHostPK4() : host + "-";
for (int i = 0; i < amount; ++i) {
newOids[i] = pk + idWorker.nextId();
//System.out.println(newOids[i]);
}
return newOids;
}
public String generate(String host) throws UnsupportedEncodingException {
SnowflakeIdWorker idWorker = new SnowflakeIdWorker(0, 0);
String[] newOids = new String[1];
String pk = host == null ? getHostPK4() : host + "-";
for (int i = 0; i < 1; ++i) {
newOids[i] = pk + idWorker.nextId();
}
return newOids[0].toString();
}
public static void main(String[] args) throws UnsupportedEncodingException {
new SnowflakeIdWorker(11, 11).generate("5", 3);
System.out.println("-------------------");
new SnowflakeIdWorker(12, 12).generate("2", 3);
new SnowflakeIdWorker(12, 12).generate("2");
//System.out.println(getHostPK4());
}
}优点:
1)不依赖于数据库,灵活方便,且性能优于数据库。
2)ID按照时间在单机上是递增的。
缺点:
1)如果分布式环境每台机器上的时钟不完全同步,可能产生ID乱序或者冲突。
5. 其它方案
MongoDB的ObjectId、Zookeeper的znode















 2242
2242











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









