






高频交易下证券公司交易系统的性能优化 - zyz_twt - twt企业IT交流平台
文章摘要:
高频交易一直在追求速度的跑道上竞赛,本文阐明了高频交易体系内涉及的各环节以及度量方法,同时对基础软硬件包括硬件、操作系统、网卡以及相应调优工具进行了介绍,给出了切实可行的试验方法供读者借鉴。同时作者提出交易链路的稳定性以及券商提供的业务资源更是服务专业客户核心竞争力值得各位深思。
第一章概述
交易系统性能优化是当前国内金融市场中一个备受关注的话题。近年来,随着T+0交易品种陆续上市 , 以及北交所、广期所的成立挂牌, 金融 交易市场机会不断涌现。在这个竞争激烈的环境下,如何在最短的时间内获取到最新的股票、期权、期货及相关的行情信息,并且能够以最快的速度向交易所提交订单请求, 是市场竞争的重要方向。
对于一次委托来说,订单全链路耗时即投资者的交易订单从订单形成系统发至经纪公司订单处理系统经过其处理确认后发往交易所及交易所确认报单后按原路径返回至订单形成系统的往返整体链路的耗时。而对于 高频 交易来说,投资者除了要求订单全链路耗时不断提速外,同时也会对分笔行情的获取有极高的要求,因此整个 高频 交易体系内的调优主要涵盖网络链路、订单形成系统、订单处理系统、交易所报盘网关、交易所内部系统、 行情 (接收) 、 分析行情(策略部分)等各环节。分析各环节的耗时占比及调优性价比权衡得出最适合当下的方案。
各家应用场景各有不同,本文针对基础软硬件和网络简单介绍下通用方案供各位参考:
第一,找寻影响因子,应当 建立稳定、高速的全链路数据 度量 通道,保证实时、准确地 获取网络快慢、系统优劣的度量数据。 全链路度量是对 高频 交易系统整个交易流程进行全方位的度量和评估。通过全链路度量,可以精确地评估每个环节的效率和时延,找出影响系统性能的瓶颈,并针对性地进行优化和改进。
第二,单元优选更换,使用 高性能的硬件设备 ,能够在底层搭好框架,保证提供高算力,完成订单匹配, 减少交易时延,提高交易执行的效率和成功率。
最终,系统调优观察,对于已获得的行情和交易数据,在高性能硬件上通过系统和软件优化,使 高频 交易系统达到极限性能,是目前证券公司的整体发力方向。在未来,也将 成为证券期货公司提升核心竞争力、追求长期稳定盈利的重要手段之一。
第二章常见问题
整体性能优化包含但不限于下述步骤:
1)影响因子评估;
2)瓶颈观测及分析;
3)单元调优;
4)系统级优化;
5)持续监控及改进。通常存在以下常见问题:
找寻影响因子
- 问题定位难:交易环境复杂,交易链条长,无法精准定位系统性能问题;
- 度量精度要求高:极速行情、交易软硬件频繁更新优化,常规测试方法无法达到精度要求,对比测试大费周章;
- 偶发问题难觉察:日常测试无法发现交易系统偶发问题(抖动、异常响应速度)。
单元优选更换
- 高性能服务器选择: 高频 交易系统需要处理大量的市场行情数据、历史数据和实时数据,并进行复杂的计算和分析。如何选择合适的高性能CPU和内存的服务器是至关重要的。高频率的多核处理器和大容量的内存可以快速处理数据,加速算法模型的计算和决策生成。
- 低延时网卡选择: 高频 交易系统需要及时获取和传输行情数据,而且通常需要与多个交易所和数据源连接。因此,选择具有高带宽和低延迟的 网卡 是必要的。
- 高稳定低延时交换机选择: 高频 交易系统通常需要持续运行,并承受大规模的数据处理和交易流量。因此,选择具有高可靠性和 低延时 的 交换机 可以提高系统的稳定性和可靠性。
系统调优观察
- 调优方案定夺:除了硬件层面优化,系统层面的优化 包括且不限制于进程调用、函数处理等,在开销及时延消耗比较大的函数栈中,通过进行定制化工具开发,实施埋点等操作,从而进行代码级性能瓶颈分析,并助力给出针对性的调优方案
- 持续观察分析:在调优手段覆盖之后,基于目前券商大多数系统环境,即使在某一次调优后达到了不错的数据,但是由于负载均衡、内核污染等等不可避的问题存在,单次调优无法达到应有效果,所以持续分析是不可缺少的一环。
第三章优化思路
找寻影响因子--度量
极速高频交易环境中,需要采用最快的网络设备进行组网,并且要对全链路节点的处理时延、流量、抖动等性能指标进行高精准统计与展示,帮助运维人员对应用系统性能异常和故障做出精准快速定位。
行情链路包括:行情网关 ,行情解码,行情转发,客户端,网络设备等;
交易链路包括:客户策略 ,交易系统,报盘网关,网络设备、防火墙等。
现有业务分析及监控平台主要采用系统内置分析模块,但只能分析单节点性能,不能分析全链路端到端性能;且软件操作系统打点,时间精度抖动较大,准确性不足。
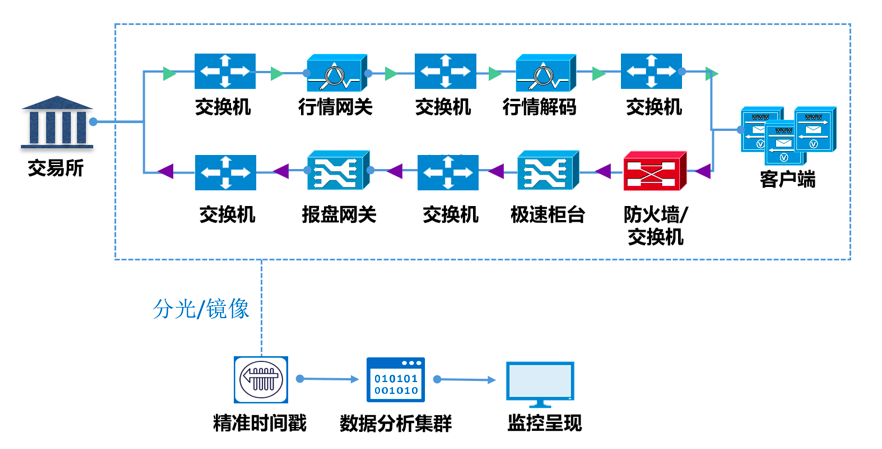
上图为一种全链路的高精度度量方案,此方案通过将网络流量旁路导出至高精准时间戳设备,在数据包尾部添加上可识别的时间戳标识,并实时进行流量解析计算,计算精度为皮秒级别,可以支持全链路时延精准度量。
单元优选更换—匹配
交易链的不同参与者对于 设备 的要求会有所不同,从底层链路、网络的选择上,都需要选择合适匹配的参与单元, 而作为关键点的交易系统和宿主机,在满足高性能低延时的同时,还需考虑载体、温度、功耗等一一来进行选型,并逐步建立测评选型基准 。 交易系统不光需要追求极低的延时,更重要的是保持整体稳定,稳定即可预期,可掌控,如果相对波动较大,就无法预测报单策略的有效性。
系统调优观察—定性
机器从出厂之后,就会有相关参数,而通过PCIE和速率、IO和负载、字节和网速等等,会计算出一个理想数值,但现实情况中往往达不到理想值。此时则需在整体系统中,对当前CPU、I O 、 Memory 等进行密集性、内存负载、 IO基准等测试, 如性能监控下,可采用 PCP 测试 ; 系统追踪中,运用 Pcef ;针对于系统调用,用 Toolkit进行 跟踪等等。如此以来,将将硬件、系统、应用等进行一连串调优,再根据每次调优后的数据计算出基线和饱和率,审视工作流。
在审视工作流完成基数标定之后, OS 层承上启下,单点定性后往往在某次调优后牵一发而动全身。 基于操作系统层面实现交易系统优化往往非常有效,比修改应用程序、改善硬件环境等问题解决更彻底、整体T CO 更优。 这个时候,针对于 OS 层面,往往需要确认四件事情。
- 命令集: 在调优 OS 层面时,首先需要确认使用的命令集。不同的硬件架构和处理器可能支持不同的命令集,例如 x86 、 x86-64 、 ARM 等。了解命令集对于确定可用的优化选项以及应用程序的性能影响非常重要。
- BIOS 设置: BIOS (基本输入 / 输出系统)是在计算机启动过程中加载的固件,它负责初始化硬件并传递控制权给操作系统。在调优 OS 层面时,需要确认 BIOS 设置是否合理。例如,检查 BIOS 中的电源管理选项、内存配置、硬件虚拟化支持等设置,以确保它们与应用程序的性能需求相匹配。
- .OS 本身: 操作系统本身也可能对系统性能产生影响。确保操作系统已经进行了必要的优化和调整,例如启用了适当的内核参数、关闭了不必要的服务、设置了正确的文件系统选项等。此外,还可以考虑更新操作系统补丁和驱动程序,以修复可能存在的性能问题。
4.负载容量规划: 在调优 OS 层面时,需要对负载容量进行规划和评估。这包括确定系统的预期负载和性能需求,以便为其分配足够的资源。可以考虑调整 CPU 调度策略、内存管理设置、文件系统缓存大小等,以优化系统的性能和响应能力。
而完成以上俩点后。金融行业的 系统 最佳不应当为系统在某一刻可以达到的峰值,而是针对于当前应用最匹配的一系列方案才可以称为最佳。比如在证券客户 交易 系统方面,缩短延时 (加快响应速度) 比提高 吞吐量(完成更多操作) 更重要。而这二者往往互相制约。同时针对于不同系统不同应用,也需要通过对业务的分析,进行某一点的最佳调优,再由点及面,才可以达到系统的最佳调优。
第四章性能天梯
高频交易端到端链路从架构上可分为应用交付层、支撑环境层、操作系统层、硬件设备层和基础设施层。应用交付层主要是交易应用程序和算法,支撑环境层包括了消息中间件、程序加速软件等环境软件,基础设施层主要由机房基础设施组成。端到端整体时延可以理解为证券公司从接收交易所行情入口到报盘至交易所间各个节点的延时之和,其中包括了行情系统、交易系统、网络设备、服务器网卡、光纤传输等等环节,各环节目前的时延量级如下:
- 毫秒(1 0 -3 秒) 级别:运营商专线
- 百微秒(1 0 -6 秒) 级别:交易系统、行情系统、交易网关等
- 微秒(1 0 -6 秒) 级别 : FPGA 系统、服务器网卡
- 百纳秒(1 0 -9 秒) 级别:低延时网络设备
- 纳秒(1 0 -9 秒) 级别:光纤、一层交换机
早期“端到端低延时研究”主要集中在交易系统的改进上,这是因为端到端交易流程整体延时的瓶颈集中在交易系统上。交易系统的每一次大的改进和创新,都有可能为整体交易速度带来几倍甚至几十倍的提升。在证券交易系统的延迟方面, 2006-2008 年间,性能很好的交易系统延迟都达到了 100 毫秒。 2009-2011 年间,较快交易系统的延迟达到了 100 微秒左右。目前,交易系统的延时已经来到了微秒级,行情系统的延时已经来到了百纳秒级别,底层的传输网络、服务器网卡和光纤传输在端到端流程的整体延时占比不断提高。
第五章调优技术
在选用合适的硬件之后,仅仅完成了初始阶段。怎么达到最佳性能,在目前的阶段还是没有尽头的。而在低延迟领域,如 高频 系统或实时媒体系统,大多要求服务器在10微秒以下提供一致的系统响应。这就需要硬件、操作系统、应用、网络等领域进行调优以达到这一要求。本章节将主要针对硬件及操作系统层面的调优技术做一些探索和分享。
硬件配置
要实现微秒级的低延迟,首先需要了解被测系统的硬件配置。影响时延的重要因素包括核心数、每个核心的执行线程数、插槽数、NUMA节点数、CPU和内存在NUMA拓扑中的排列,以及NUMA节点中的缓存拓扑。Linux系统可以时延lscpu命令,对硬件拓扑情况进行查看。
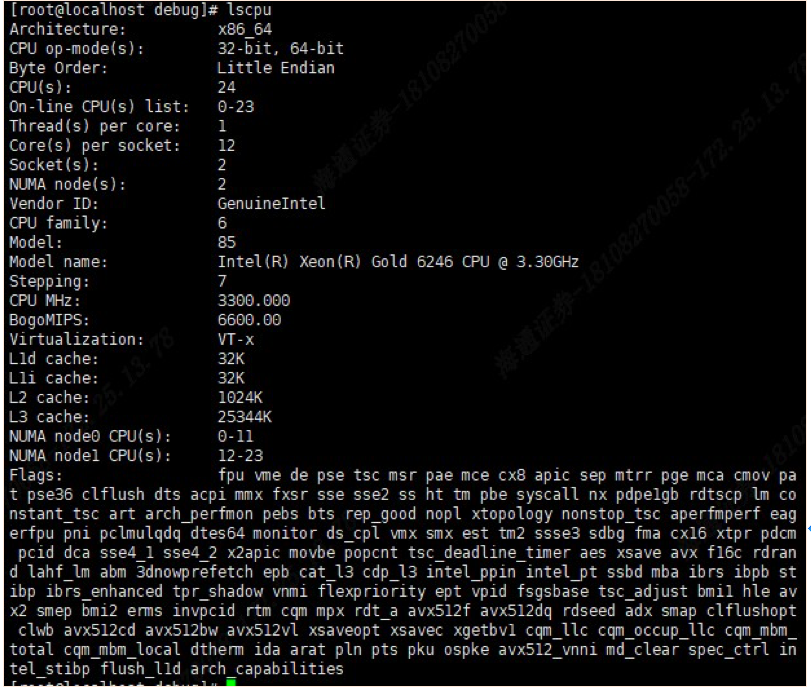
从上图,我们知道这是一台双路CPU的服务,总共安装了两颗CPU,Numa节点数为2等信息。请注意,如果应用系统所需线程数较少,单路CPU的服务器也是不错选择,它会减少一些槽位间通信的复杂性。
为了获得最佳的响应时间,需要对系统拓扑进行优化,其中内存需要均匀的在NUMA节点上进行安装,并尽量最大化使用本地内存。关键应用需要运行在隔离CPU上,并且与Numa节点、PCIE网卡在系统拓扑上保持一致,以获得最优的数据路径。
Numa和内存
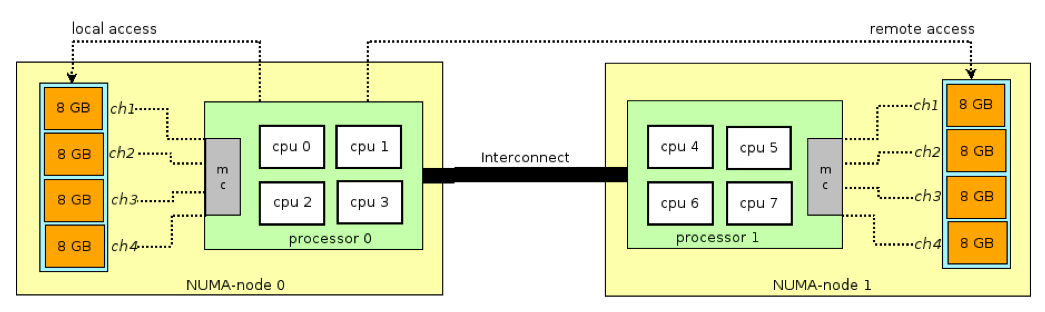
以我们常用的双路服务器为例, Numa架构大致如下。
我们可以通过numactl来查看numa节点信息:
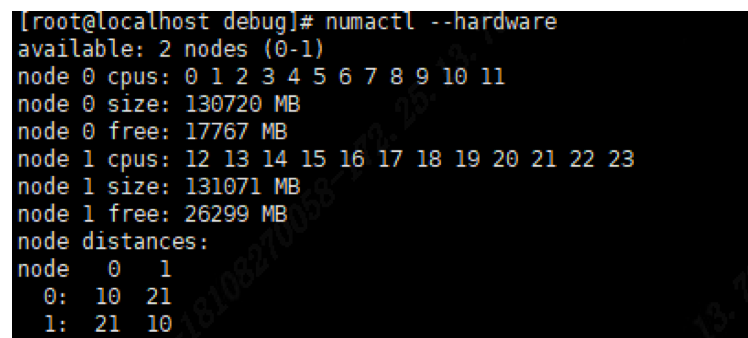
CPU远程访问Numa节点时,距离毕竟长,性能会受到极大影响,低时延应用程序需要避免跨Numa的远程内存访问,从下面的命令,我也可以看出远程访问Numa的性能远低于本地访问。
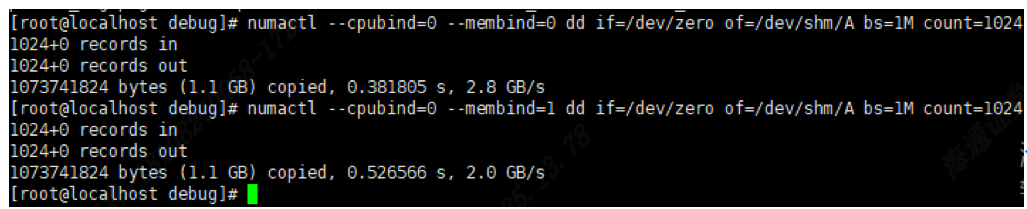
NUMA内存平衡
Linux支持基于自动NUMA内存平衡和手动迁移内存,但在NUMA节点之间迁移内存页面将导致内存的TLB被清除和页面故障,从而影响程序性能。
可以使用以下命令禁用自动NUMA内存平衡:
echo 0 > /proc/sys/kernel/numa_balancing
还可以禁用用户空间的numad服务,关闭NUMA内存平衡。
绑定核心
中断是CPU Core收到的,可以让关键线程绑定在某个Core上,然后避免各种中断源(IRQ)向这个Core发送中断。
绑定程序在一个核上运行,有两种方法:taskset和sched_setaffinity,其中sched_setaffinity是程序代码对绑核的实现,我们主要介绍通过taskset进行绑核。
CPU Affinity
CPU亲和性,是指在SMP结构下,能够将一个或多个进程绑定到一个或多个处理器上运行。
查看进程分配的CPU Core,可以使用taskset命令查看:
taskset -c -p <pid>
该CPU亲和力列表表明该进程可能会被安排在3-5中任意一个CPU Core上。
更具体地查看某进程当前正运行在哪个CPU Core上,我们可以使用top命令查看:
top -p <uid>
taskset
使用taskset命令将进程绑定到指定核,比如将31693绑定到1,2,3核上
taskset -cp 1,2,3 31693
该例会将PID为31693的进程绑定到1-3核上运行。
屏蔽硬中断(硬盘、网卡)
中断源(IRQ)向CPU Core发送中断,CPU Core调用中断处理程序对中断进程处理。我们可以通过改写/proc/irq/*/smp_affinity文件,避免中断源(IRQ)向某些CPU Core发送中断。该方法对硬盘、网卡等设备引起的硬中断有效。
查看设备中断数据
通过查看/proc/interrupts文件可查看设备中断数据:
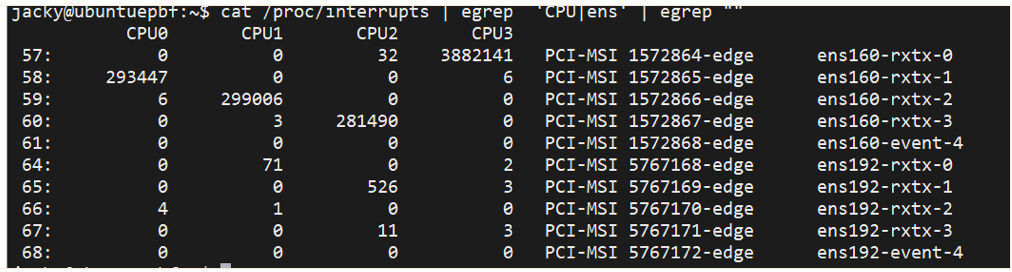
- 第一列是IRQ号
- 第二列开始表示某CPU内核被多少次中断。
SMP_AFFINITY
SMP,即symmetric multiprocessing(对称多处理器),通过多个处理器处理程序的方式。smp_affinity文件处理一个IRQ的中断亲和性。我们可用/proc/irq/{IRQ_NUMBER}/smp_affinity_list来制定所需要绑定的核,这里的IRQ_NUMBER就是前面中断输出中的IRQ号,比如我们想将ens160的所有中断绑定到CPU1和CPU2。
echo 1-2 > /proc/irq/57/smp_affinity_listecho 1-2 > /proc/irq/58/smp_affinity_listecho 1-2 > /proc/irq/59/smp_affinity_listecho 1-2 > /proc/irq/60/smp_affinity_list
内核参数
Watchdog
Watchdog在进行监控的过程中会触发中断,会引起抖动,可通过以下命令进行关闭:
echo 0 > /proc/sys/kernel/watchdog
Swappiness
交换倾向性,描述操作系统在内存不足时将数据移动到交换分区的偏好程度,swappiness 的值可以在0到100之间,为0表示不使用交换分区,针对低时延系统建议设置为较低值,或直接关闭。
echo 10 > /proc/sys/vm/swappiness
dirty_ratio
Dirty_ratio是控制脏页的比例,如果脏页超过一定比例,所有的写操作都会阻塞,知道一部分的脏页被写入磁盘。
echo 10 > /proc/sys/vm/dirty_ratio
dirty_background_ratio
Dirty_background_ratio 是一个限制值,当脏页数超过该值时,开始将这些脏页写入磁盘。
echo 3 > /proc/sys/vm/dirty_background_ratio
sched_latency_ns
指定在发生任务切换之前,任务可以在一个 CPU 核心上运行的最长时间(以纳秒为单位)
echo 24000000 > /proc/sys/kernel/sched_latency_ns
sched_min_granularity_ns
指定了最小的时间粒度(以纳秒为单位)不会被抢占的时间,在这个时间粒度内,一个任务可以在一个 CPU 核心上运行。
echo 10000000 > /proc/sys/kernel/sched_min_granularity_ns
sched_rt_runtime_us
用于控制系统中实时任务的运行时间片(以微秒为单位),默认值为950000,总共为1000000。设置为-1则禁止这个限制。
echo -1 > /proc/sys/kernel/sched_rt_runtime_us
stat_interval
以秒为单位的更新虚拟内存统计信息的间隔。默认值是 1 秒,这导致每秒进行信息统计。将其更改为 1000 秒可以避免这些中断,至少延迟了 16 分钟。
调频策略
scaling_governor调配策略的作用是控制CPU如何管理和调整其运行频率以平衡性能和能耗,同以下命令,选择“performance”使CPU保持在最高频率,以提供最大的计算性能。
echo performance > /sys/devices/system/cpu/cpu57/cpufreq/scaling_governor
操作系统配置
操作系统侧调优类别包括但不限于:
1)硬件资源调优;
2)微架构数据采样MDS;
3)SMT/HT/中断;
4)内核;
5)文件系统;
6)存储;
7)CPU;
8) MEM;
9)网络等。
其中网络部分主要涉及:
1)网卡驱动层面的优化,包括多队列,中断聚合,ring buffer等各种配置参数;
2)内核协议栈优化,Kernel backlog 队列优化,相关内核参数对应用性能的优化;3)网络相关的系统服务优化;IRQ Balance优化;网络延迟优化;大量连续数据流的吞吐量优化; 高吞吐量调整 TCP 连接优化等等;
4)网络应用优化;
5)网络连接优化性能验证等;最重要的是,操作系统可以与应用一起做性能联调。通过工具做持续性能监控、分析及优化。例如RHEL中有大量性能监控工具。sysstat软件包实用程序从内核计数器获取原始数据,并提供有关 CPU 使用率、磁盘 I/O、进程使用、内存使用等内容的性能监控。Performance Co-Pilot (PCP) 软件包提供了一个框架来监控和管理实时数据,以及记录和检索历史数据。 系统监控工具同时以命令行和图形用户界面形式提供。
BIOS配置
| 参数 | 值 | 描述 |
| Workload Profile | Low latency | 如果 BIOS 提供了低延迟的配置 文件,请选择此选项,以应用一 系列优化延迟的预设值 |
| Intel Hyperthreading Options | Disabled | 允许超线程 |
| Intel Turbo Boost Technology | Disabled | 允许超频 |
| Intel VT-d | Disabled | 启用 virtualized Directed I/O |
| SR-IOV | Disabled | SR-IOV运行虚机直接访问设备的 物理资源 |
| Memory patrol scrubbing | Disabled | 内存巡检清理 |
| L1 Stream HW | Enable | 一个硬件预取器,将数据内存加 载到 L1 缓存中,从而提高性能和 效率 |
| L2 Stream HW Prefetcher | Enable | 一个硬件预取器,将数据内存加 载到 L2 缓存中,从而提高性能和 效率 |
| Thermal Configuration | 首先尝试最佳冷却,然后增 加,直到最大冷却。 | 通过RBSU设置 |
| HPE Power Profile | Maximum Performance | 禁用所有电源管理选型,会损坏 性能 |
| HPE Power Regulator | HPE Static High Performance Mode | 处理器保持其最大功率/性能状态 |
| Intel QPI Link Power Management | Disabled | 不(将未使用的QPI链路置于低功 耗状态) |
| Intel UPI Link Power Management | Disabled | 不(将未使用的upi链路置于低功 耗状态) |
| Minimum Processor Idle Power Core C- State | No C-States | 阻止处理器转换为低功耗核心为C-States |
| Minimum Processor Idle Power Package C- State | No Package State | 阻止处理器转换到低功耗包C- States |
| Energy/Performance Bias | Maximum Performance | 为高性能/低延迟配置处理器子系 统 |
| Collaborative Power Control | Disabled | 阻止操作系统更改时钟频率 |
| Dynamic Power Capping Functionality | Disabled | 允许在启动过程中禁用系统ROM 电源校准 |
| QPI Snoop Configuration* | Early Snoop, Home Snoop, or Cluster on Die | |
| ACPI SLITPreferences | Enabled | 支持SLIT的操作系统可以使用这 些信息通过更有效地分配资源和 工作负载来提高性能。 |
| Processor Power and Utilization Monitoring | Disabled | 禁用ILO处理器状态模式切换 |
| Memory Pre-Failure Notification | Disabled | 禁用内存故障前通知 |
| Node Interleaving | Disabled | 节点交错 |
| Channel interleaving | Enabled | 内存通道交错 |
CPU安全漏洞
近年频繁暴露出CPU漏洞,比如MDS、Zombieload、Spectre、Meltdown、L1TF在Intel x86微处理器中发现的安全漏洞,它们都利用了微处理器的预测执行(speculative execution)功能来窃取敏感数据。这些漏洞都需要在固件和内核层面进行修补,但这会导致性能的下降。
MDS(Microarchitectural Data Sampling,微架构数据采样)是一组在2018年发现的漏洞,它们可以通过读取处理器内部的数据缓冲区来泄露跨越保护边界的数据
Zombieload是MDS的一种变体,它可以通过监视处理器执行的指令来获取敏感数据,例如密码、密钥、浏览历史等。
Spectre(幽灵)是一组在2018年初公开的漏洞,它们可以通过操纵处理器的分支预测(branch prediction)功能来迫使目标程序执行非预期的指令,并从其缓存中读取敏感数据
Meltdown(熔断)是一组与Spectre类似的漏洞,它们可以通过利用处理器的乱序执行(out-of-order execution)功能来绕过内存隔离机制,并从内核或其他进程中读取敏感数据
L1TF(L1 Terminal Fault,L1终端故障)是一组在2018年中公开的漏洞,它们可以通过访问L1缓存中的无效或不可访问的物理地址来泄露跨越保护边界的数据。L1TF包括以下几种变体:Foreshadow, Foreshadow-NG (OS, SMM, VMM)。
这些漏洞都对Intel x86微处理器造成了严重的威胁,尤其是使用超线程技术(Hyper-Threading)的处理器。为了防止这些漏洞的攻击,用户需要更新系统和固件,并可能需要关闭超线程技术。但这些措施都会影响处理器的性能,不同的工作负载会有不同程度的下降。
在高频交易领域,特别是针对券商行情、交易系统、报盘这些应用,因为部署环境处于内网,安全环境比较好,可以通过内核参数mitigations=off来关闭缓解措施,以提升系统性能。
屏蔽软中断(Local Timer Interrupt)
Linux的scheduler time slice是通过LOC实现的,如果我们让一个线程独占一个CPU Core,就不需要scheduler在这个CPU Core上切换进程。可以通过isolcpus系统启动选项隔离一些核,让他们只能被绑定的线程使用。同时,我们还可以启用:
“adaptive-ticks”模式,达到减少独占线程收到LOC频率的效果,这可以通过nohz_full和rcu_nocbs启动选项实现。
假设令6-8三个核心屏蔽软中断,我们需要在系统启动选项中加入:
nohz=on nohz_full=6-8 rcu_nocbs=6-8
进入adaptive-ticks模式后,如果CPU Core上的running task只有一个是,系统向其发送的LOC频率会显著降低,但LOC不能被完全屏蔽,系统内核的一些操作比如计算CPU负载等仍然需要周期性的LOC。
关闭交换分区
关闭所有的交换分区和文件,释放交换空间中的数据到内存中。这样可以提高系统的性能:
swapoff -a
关闭透明大页
Linux透明大页(THP)允许内核自动将常规内存页面提升为大页。大页减少了TLB的压力,但将页面提升为大页会触发内存压缩,引入了延迟峰值。
通过提供内核命令行参数transparent_hugepage=never或运行以下命令来禁用透明大页支持:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
同页合并
Linux内核同页合并(KSM)是一项功能,用于去重包含相同数据的内存页面。合并过程需要锁定页面表并清除TLB,从而导致内存访问延迟不可预测。KSM仅对已经通过madvise(...MADV_MERGEABLE)选择加入同页合并的内存页面进行操作。如果需要,可以通过运行以下命令在系统范围内禁用KSM:
echo 0 > /sys/kernel/mm/ksm/run
使用大页
应用程序访问的页面在TLB中缺失时,内存管理单元(MMU)遍历整个页表,会有极大的性能开销。通过使用2MB或1GB的大页面,可以显著的减少TLB未命中次数。
我们可以使用perf工具监控TLB未命中情况:
# perf stat -e 'dTLB-loads,dTLB-load-misses,iTLB-loads,iTLB-load-misses' -a --timeout 10000Performance counter stats for 'system wide':10,525,620 dTLB-loads2,964,792 dTLB-load-misses # 所有dTLB缓存命中的28.17%1,998,243 iTLB-loads1,068,635 iTLB-load-misses # 所有iTLB缓存命中的53.48%10.002451754秒的已用时间
上述输出显示了未命中的数据加载(dTLB)和指令加载(iTLB)的比例。我们观察到大量的TLB未命中,应考虑使用大页面以减少TLB未命中次数。
关闭服务
关闭一些多余服务,减少系统扰动
#!/bin/shfor SERVICE in \\avahi-daemon.service crond.service dnsmasq.service \\firewalld.service lvm2-monitor.service postfix.service \\rpcgssd.service rpcidmapd.service rpcsvcgssd.service \\wpa_supplicant.servicedosystemctl disable $SERVICEsystemctl stop $SERVICEdone
应用配置
屏蔽Work queue
workqueue是自kernel2.6引入的一种任务执行机制,和softirq,tasklet并称下半部(bottom half)三剑客。workqueue在进程上下文异步执行任务,能够进行睡眠。可以通过改写/sys/devices/virtual/workqueue/*/cpumask文件实现屏蔽Work queue的软中断。
/sys/devices/virtual/workqueue/cpumask文件中记录了全局的cpumask,可以影响所有的workqueue。比如我们只希望CPU0和CPU3来执行workqueue,我们计算初CPU0和CPU3的cpumask为0x9(二级制:10001)
echo 9 /sys/devices/virtual/workqueue/cpumask
网卡配置
检查网卡Numa信息
根据网卡的numa_node设置对应的RPS队列,变为网卡的中断绑定
cat /sys/class/net/ens3f1/device/numa_node
Kernal Bypass
Kernel Bypass技术在高频交易系统中有大量应用。在不变更程序代码的角度来说,目前可用的解决方案有:Solarflare onload、Mellanox VMA和Exasock三种。Kernel Bypass的优点就是实现了用户态网络协议栈(User-space Networking)允许应用程序在用户态中运行网络协议栈,避免了数据包在Linux内核中的传输过程,以及涉及内核态的切入切出,还有零Copy等技术的使用,极大的提升效率,降低传输时延。
Onload
Solarflare onload是一种由Solarflare Communications开发的网络加速技术,旨在提高服务器和数据中心网络性能,降低网络通信的延迟和CPU负载。这项技术主要用于高性能计算(HPC)、云计算和金融领域等需要低延迟和高吞吐量网络连接的应用程序。onload无需对应用程序进行修改就可实现加速效果。
onload sockperf server -i 11.4.3.3
VMA
Mellanox VMA(Virtual Memory Acceleration)是一种由Mellanox Technologies(现在是NVIDIA的一部分)开发的网络加速技术。它旨在提高网络性能,减少网络传输的CPU负载,并降低延迟。VMA无需对应用程序进行修改就可实现加速效果。
LD_PRELOAD=libvma.so VMA_SPEC=latency sockperf server -i 11.4.3.3
Exasock
思科Nexus SmartNIC(前身为ExaNIC)Kernal Bypass方案,无需对应用程序进行修改。通过简单的在应用程序前加exasock来执行。
exasock nc -u -l 1234
Kernal Bypass在降低网络时延的同时,也带来了一些列的问题,他们一般都会对阻塞select(), poll(), epoll_wait(), recv(), read() 和 accept()这些调用来等待数据到来,会较多占用CPU运行时间,导致这段时间可用CPU数变少,如果应用程序的线程数大于可用CPU资源数时,就会存在CPU资源竞争,导致性能下降。所以是否应用Kernel Bypass方案,要根据实际程序的运行情况来确定。
网络配置
证券交易网络通信通常具有一个非常明显的特征:Microburst。即从宏观结构上来看,平均每秒流量非常小,但是缩放到毫秒级刻度,则会出现链路使用率几乎满载的情况,如下图所示:
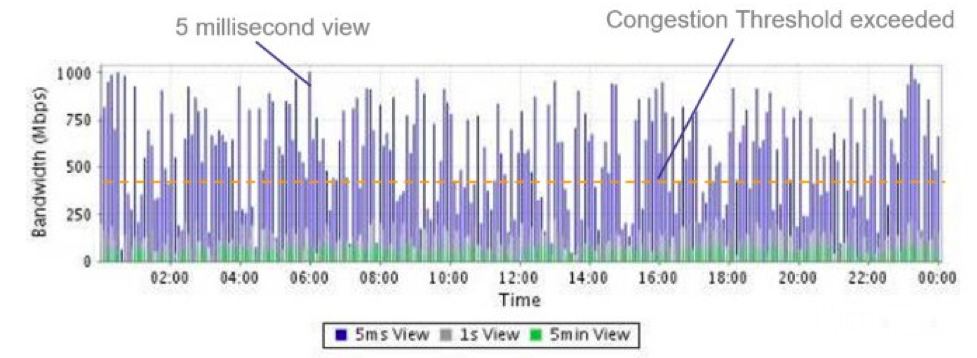
交易数据从局域网内部一台主机传输到另一台主机,沿途会经历几种不同类型的时延:丢包时延(Packet Drop Delay)、排队时延(Queuing Delay)、路由交换转发时延(Switch Processing Delay)、传输时延(Propagation Delay)和串行化时延(Serialization Delay)。其中丢包时延、排队时延、串行化时延都和交换机端口带宽和端口缓存直接相关,而传输时延一般受距离影响较大,路由交换转发时延则是交换机设备的转发耗时。因此,使用更低时延的交换机和更大的带宽通常可以有效缓解延迟问题。
极致的网络环境中可以适当选择一层或FPGA交换机来做到极低时延的网络转发。一层交换机的实现原理是通过复制电平高低信号来实现信号的快速复制传播,并且能够将电信号进行增强及平稳处理,使得直通转发时延低至5ns以内。较适用于高速行情分发场景。FPGA交换机可以将同一用户的策略服务器订单上报后进行汇聚输出,时延低至40ns以内;也针对不同用户的策略服务器连接,可以通过VLAN进行划分隔离。
调优工具
调优工具跟踪机制
| 机制 | 特点 | 内核支持 |
| kprobes/kretprobes/uprobes | 主要用来对内核或用户空间进行动态调试追踪,可以动态的指定探测点,需要保存和恢复寄存器和指令,以及处理异常和中断。 | 是 |
| tracepoint | 是内核预先定义好的探测点,只需要检查一个标志位来判断是否执行用户函数 | 是 |
| perf_event | perf_event是一种Linux内核提供的接口,它可以用于测量软件和硬件的性能数据,它可以利用tracepoint和kprobe作为数据源,也可以利用其他硬件或软件事件作为数据源 | 是 |
| ftrace | ftrace(function trace) 则更像是一个完整的追踪框架, 可以支持对 tracepoint, kprobes, uprobes 机制的处理, 同时还提供了事件追踪(event tracing, 类似 tracepoint 和 function trace 的组合) , 追踪过滤, 事件的计数和计时, 记录函数执行流程等功能. | 是 |
| systemtap | systemtap 可以同时追踪内核空间和用户空间的函数,可以在函数中的任意位置实现探测。systemtap类似 awk 的脚本语言,可以自由扩展和编写复杂的逻辑,同时将脚本翻译成 C 代码,然后作为模块编译并加载到运行的 Linux 内核中,从而实现更强大的功能 | 否 |
| eBPF | eBPF: extended Berkeley Packet Filter 已经被合并到了 Linux 内核的主版本中, 相当于一个内核虚拟机, 以 JIT(Just In Time) 的方式运行事件相关的追踪程序, 同时 eBPF 也支持对 ftrace, perf_events 等机制的处理. | 是 |
常用工具
| 工具 | 说明 | Debug包 |
| perf | perf 工具是一款很强大的工具, 基于 ftrace, utrace 的机制, perf 工具现在更多的用于 cpu 性能, 内核函数以及函数调用链的追踪分析上。 | 支持,但不是必须 |
| systemtap | systemtap 可以同时追踪内核空间和用户空间的函数,可以在函数中的任意位置实现探测。systemtap类似 awk 的脚本语言,可以自由扩展和编写复杂的逻辑,同时将脚本翻译成 C 代码,然后作为模块编译并加载到运行的 Linux 内核中,从而实现更强大的功能 | 必须 |
| ftrace和utrace | 基于 ftrace, utrace 机制的分析工具主要基于 debugfs 文件系统提供的接口而实,绝大多数的 Linux 发行版都默认支持。 | 支持,但不是必须 |
| sysdig | sysdig 以内核模块的方式监控获取所有的系统调用, 其使用方式类似 libpcap/tcpdump 的用法, 可以将一段时间内的系统调用数据暂存起来供后续的跟踪分析。Sysdig运行在内核态,支持非阻塞和零拷贝,性能远高于strace。 | 支持,但不是必须 |
| strace | strace 已经存在了很长时间, 其主要依靠 ptrace 来追踪用户空间的所有系统调用, 这种机制的问题在于应用程序每做一次系统调用都需要 ptrace 进行捕获, 获取到数据后再放行相应的系统调用,因此对程序运行性能影响较大。 | 不需要 |
| ebpf工具 | bpf在内核追踪, 应用性能追踪, 流控等方面都有强大的能力,目前bpf的主要前端工具有BCC和bpftrace,它们可以利用BPF的能力来创建各种高效的内核跟踪工具。其中bcc还提供python接口,可以对bpf跟踪采集的数据进行灵活的分析和处理。 | 支持,但不是必须 |
内核版本低于4.1
以 Centos7 系统为例, 其依赖 3.10.0 内核版本, 这就决定了我们只能通过 perf_event, ftrace/utrace 和 systemtap 的方式进行系统调试. 在实际使用的时候我们需要考虑不同的需求使用不同的工具, 如下所示为简单的总结:
| 需求 | 工具 |
| cpu 性能分析 | perf, systemtap |
| 函数调用链 | perf, ftrace |
| 函数及堆栈统计分析 | perf, systemtap |
| 函数执行追踪 | ftrace/utrace, systemtap |
| 系统调用分析 | ftrace, sysdig, strace(慎用), systemtap |
如果 Redhat/Centos 7 内核高于 3.10.0-940.el7.x86_64 , 可以酌情使用基于 eBPF 的 bcc-tools 工具。
内核版本高于4.1
高于 4.1+ 版本的系统可以直接通过 eBPF 获取想要调试的信息。当然也可以继续使用 frace, systemtap 等工具。
工具示意
在当前的Linux 发行版中,perf 和 strace 是两个得到广泛支持的分析工具。它们提供了丰富的功能,用于诊断和优化系统性能问题,他们安装最为便捷,同时对于环境的依赖较小,输出信息可读性也比较好。
perf 进行信息采集示例
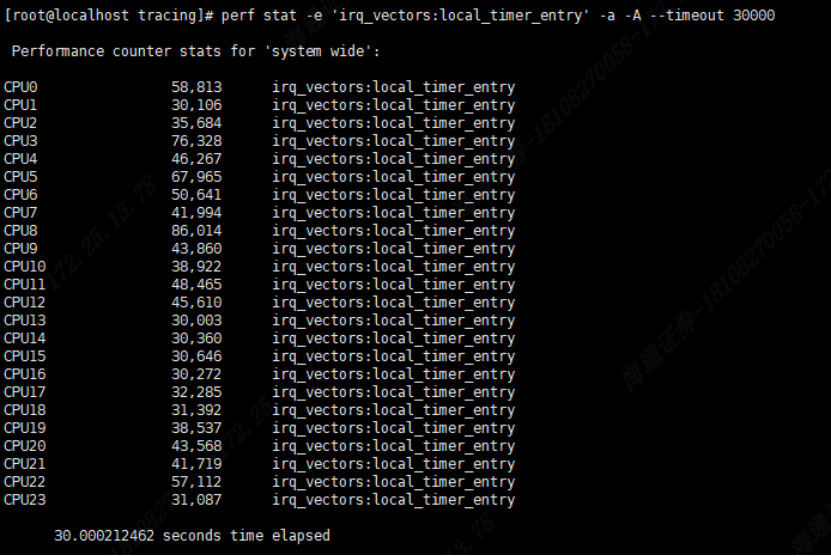
1 . 通过perf stat 命令可以统计程序的性能指标例如指令数、周期数、缓存命中率等。例如,要统计当前系统的Local Timer 中断情况,同时安装每个CPU进行汇总:
Perf stat –e ‘ irq _vectors:local_timer_entry’ -a -A --timeout 30000
2 . 通过perf record命令可以记录程序的性能事件,然后使用 perf report 命令来分析记录的数据。例如,要记录驱动程序接受网络数据包事件:
perf record -e ‘net:netif_recevie_skb’ -a
记录perf .data 数据以后还可以通过p erf report 进行查看
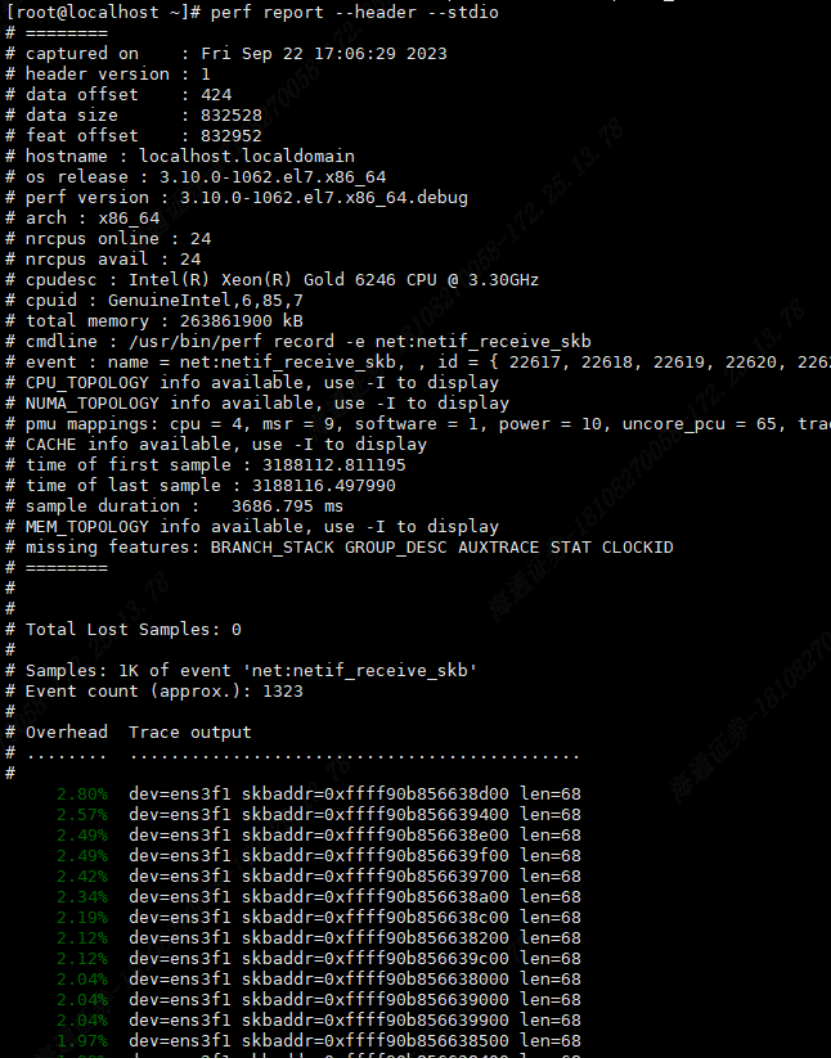
- perf trace 是 perf 工具套件的一部分,用于跟踪系统上的函数调用和事件流,以便分析应用程序和系统的行为。它的主要作用是提供更详细的系统跟踪和分析,以帮助识别性能问题和故障排除。
例如:我们可以用p erf record -s –p 3329 来记录进程系统调用的汇总信息,通过汇总信息我们可以初步评估进程主要的系统调用情况。
strace`进行信息采集
使用strace 来跟踪程序的系统调用。例如,要跟踪某一进程的系统调用,可以运行以下命令:
s trace –tt -T -yy -ff –p 8661
通过输出的信息,我们可以跟踪某一进程的recvfrom和sendto的系统调用。

第六章、成果及效益
通过探索系统整体调优方案,我们获得了以下方面的收益:
1) 从系统性能提升的优化目标而言,实现了4.8GHz服务器在非实时普通内核上,系统定时的抖动误差从优化前的3 0 us , 降低到4us以内;2.6GHz服务器的系统定时抖动误差也从优化前的8 0us, 降低到10us以内。
2)构建了一套持续性能优化的方法体系: 找寻影响因子→单元优选更换→系统调优观察 ,通过持续对业务系统进行时延和性能的监控度量,用可视化的方式呈现问题,综合运用工具定位问题,针对性对系统进行优化或调整。体系化方案的建立,也有利于软硬件知识的沉淀,支撑逐步向其他系统、甚至整个IT体系进行传导。
第七章、总结和展望
总结
对 投资者和 经纪公司来说,交易的延时无疑至关重要,本文通过关注找寻 全链路各环节的 影响因子、单元优选更换、系统调优观察几个维度,对系统优化提出了体系化的方法思路,并取得了一定的成果,对我司 有效支持机构 高频 客户对交易全链路稳定和低延时的极致需求, 全面提升公司 交易服务 能力有指导性意义。
基于操作系统层实现交易系统性能优化,需要对L inux 内核等深度掌握。 券商同行可以一方面持续提高自己的队伍在这方面的能力,同时也可考虑采用红帽等专业厂商的调优服务来为己所用。
展望
我们此次主要针对操作系统和网络层面进行了优化探索, 但Linux内核、CPU 知识体系庞大,仍需持续深入学习研究。 包括上层应用系统的架构及代码均可持续优化。
同时我们也要意识到,速度虽然重要但不是全部,目前 交易系统 的军备竞赛已经上升到微妙级,去除交易所侧在百微甚至几十微的也不在少数,而这种情况下一个网络抖动、开盘的脉冲干扰或者交易所侧的其他不确定因素可能直接覆盖了其他环节的耗时。因此我们同样需要做好稳定性的保障。
券商作为经纪业务服务商,如何利用各方面资源服务好投资者,留住投资者个人认为更是我们的核心竞争力。


















 519
519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









