






文章说明:
本文目标为,根据pipeline,按顺序讲解每一个模块的原理、目标,更主要的是所有工程实现的细节。通过这种一步步的推导,希望提升对SD里各个模块内部、之间如何协同工作的理解。所以本文并不会涉及过多的,论文公式的推导和由来,而侧重于如何真正的实现公式的落地与应用。
同时要说明,本文章所用代码链接为: https://github.com/hkproj/pytorch-stable-diffusion.git因为讲述代码流程难免会有复杂的调用关系,最好还是下载好代码对照阅读不易走丢。
并在此推荐hkproj (Umar Jamil),其Coding Stable Diffusion from scratch in PyTorch,虽然时长达到五个小时,但是整体思路非常清晰。
整体框架:
一般来说,从整体框架入手,一部分一部分解决模块,思路会比较清晰。下面以文生图、图生图情况为例做一些说明(两者本质都一致)。
文生图:
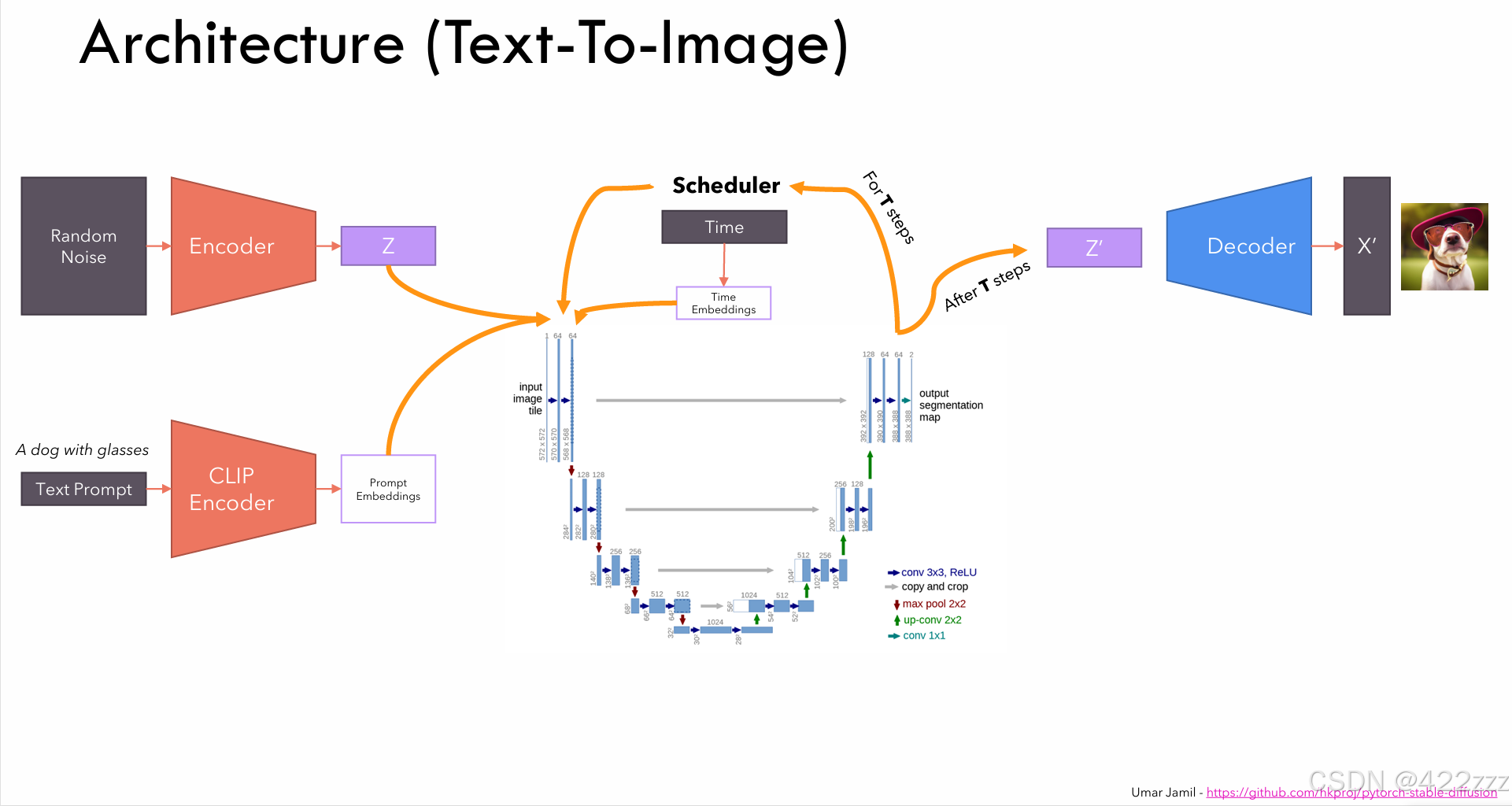
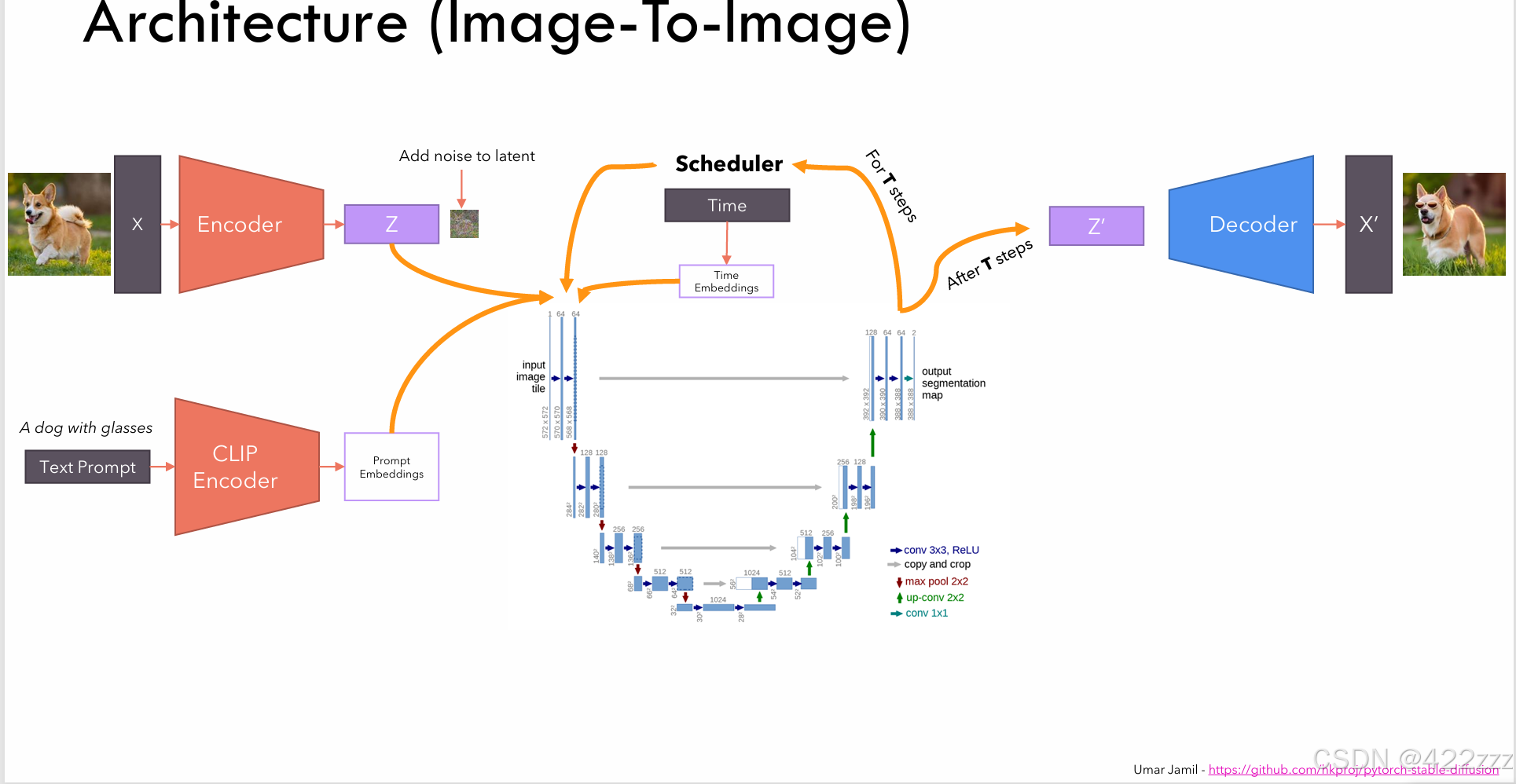
图生图:
理论论述:
在这一部分,对框架中的每一个模块的作用做一个简单的描述。
CLIP:
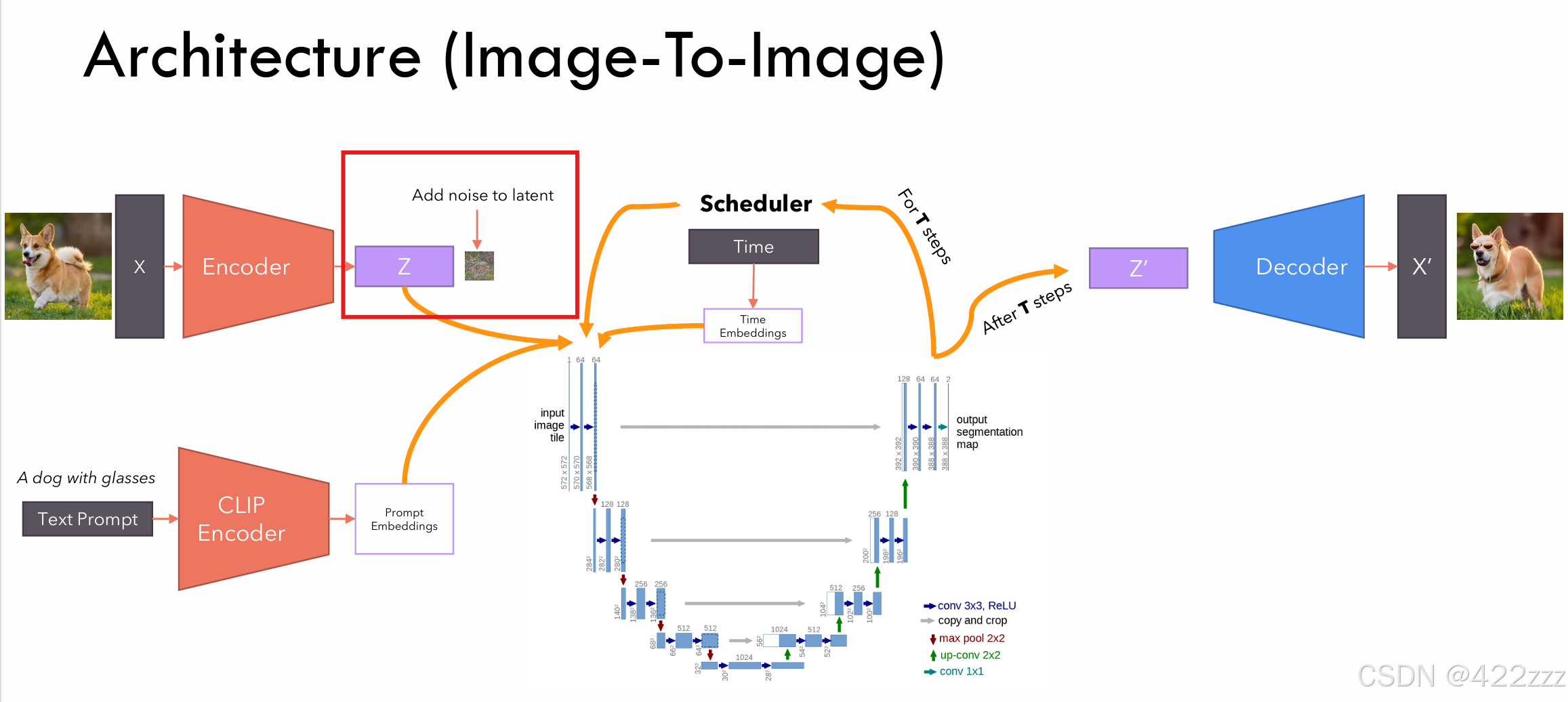
首先从下图的红框部分开始,即CLIP模块。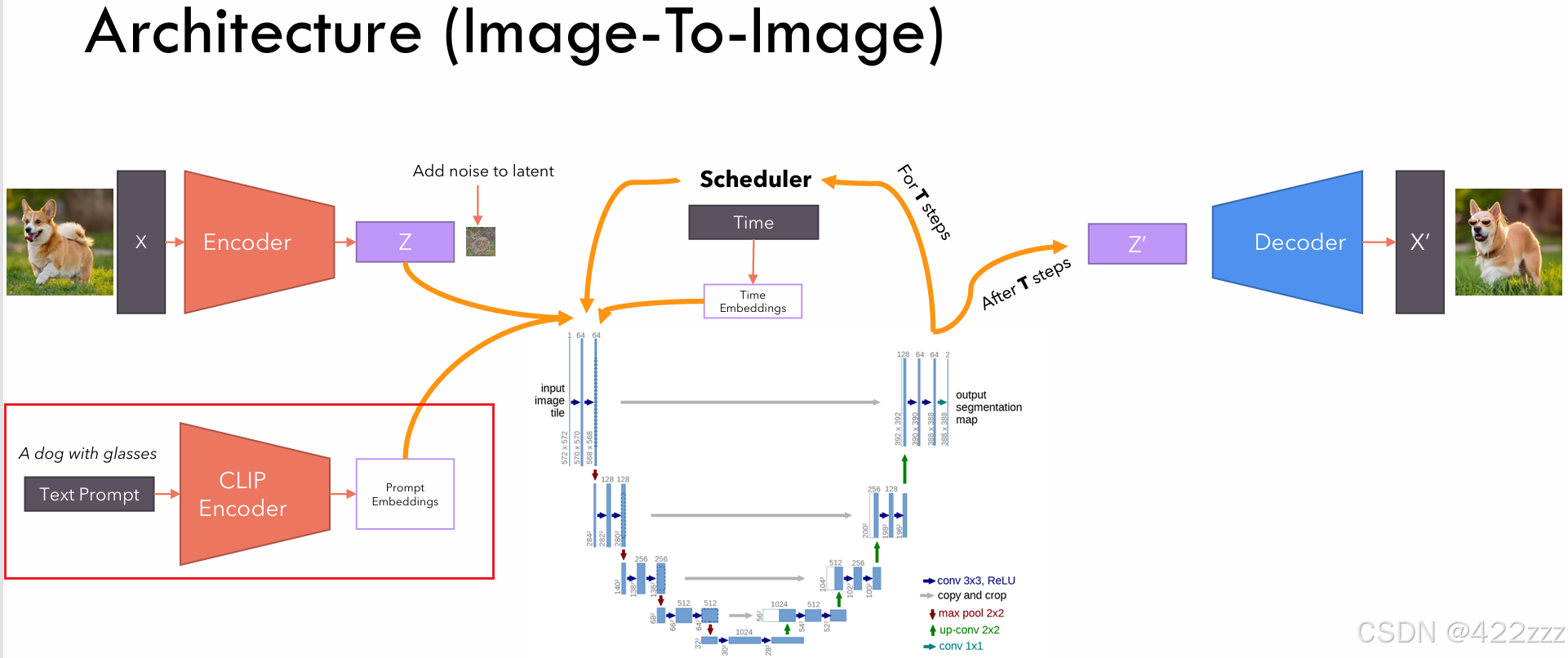
CLIP(Contrastive Language image pre-training)是OpenAI在2021年发布的模型,其作用为,将text prompt编码为prompt embedding。
其提出的契机为,例如在分类领域,如果用卷积神经网络来分类,其需求是需要大量的有标注的数据集,这在很多时候是很困难的。而CLIP的数据集是直接从互联网获取的,可以用很小的成本直接获取大量的文本与图像对应的训练数据集。这种标注可以称之为自然语言监督natural language supervision。
其训练时,用image encoder编码batch张图像至embedding space得到I向量,同时用text encoder编码 图像对应的描述 至embedding space得到T向量。之后T向量与I向量做余弦相似度。当然我们希望某个样本图像的潜在表达跟对应描述的潜在表达的相似度更高,而跟其他图像的描述的潜在表达的相似度更低。即如图,想让对角线上的值尽量大,其他位置尽量小。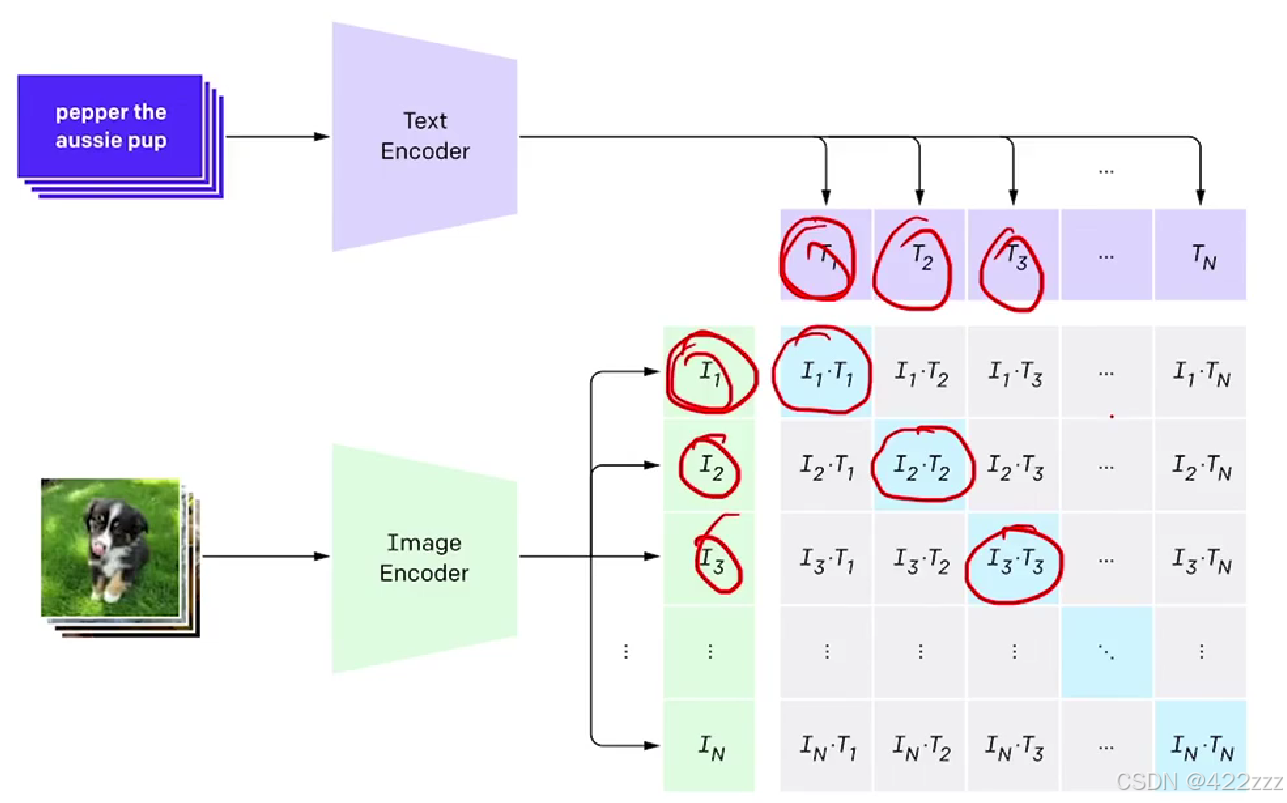
因为如何得到prompt embedding并不是SD的核心考量部分,在此不会过多阐述,可在代码部分略见一两。
VAE_Encoder:
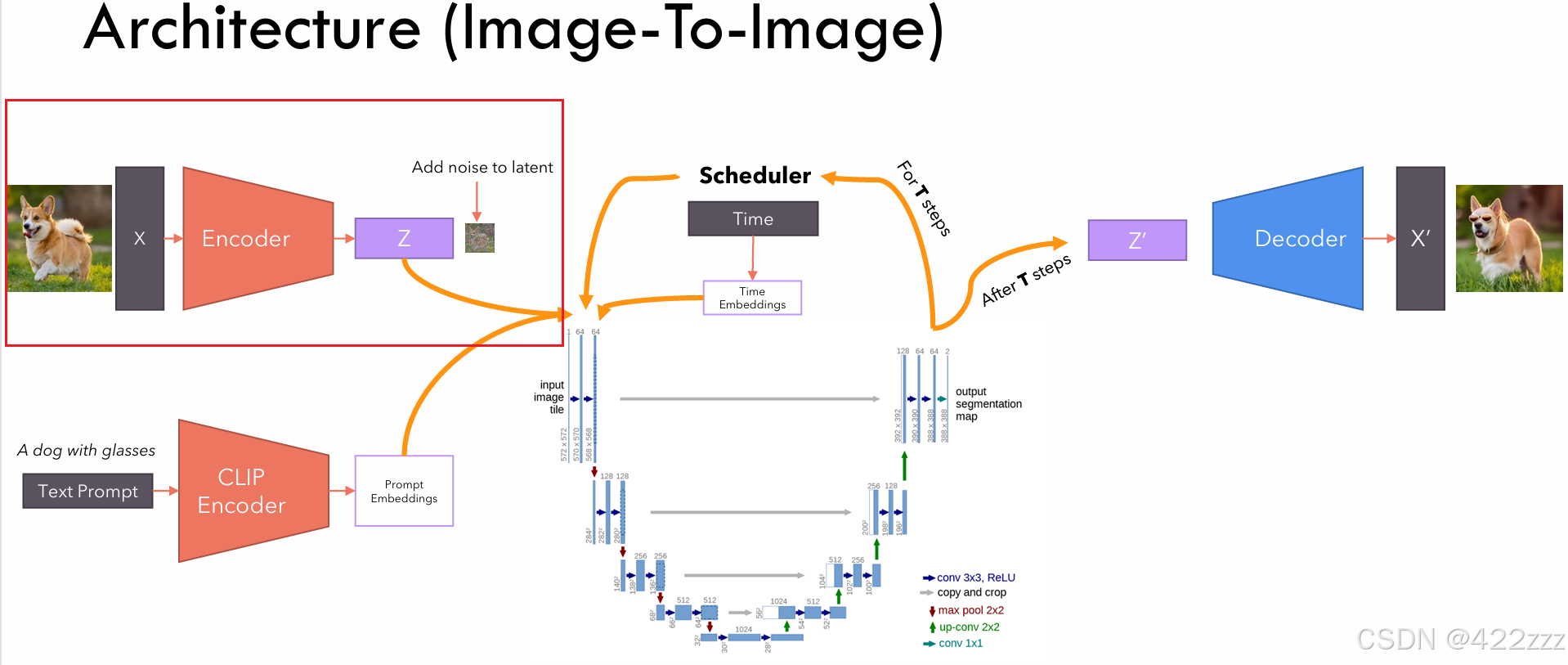
这一步就体现出SD的核心改善了。当图像分辨率很大时,如果每次都在UNET里对原始大小进行计算、处理,计算量很大,所以想办法要compress图像。SD就是用VAE,保证了UNET的操作对象是小尺寸的latent represent
对于图生图来说,首先VAE_encoder会将图像编码为latent represent,之后对latent represent加上噪声。这个所加的噪声强度就很有讲究了,因为生成图像时是一步步去噪的过程,如果这里加的噪声很少,模型能去除的噪声就少,相当于去噪的手段变少了。也就是说这里的噪声强度,相当于SD生成图像时的灵活性,如果所加噪声很弱,说明想让模型牢牢跟随original image的指挥,反之则让模型拥有更多自由发挥的空间。
对于文生图来说,因为没有original image,这里直接把随机采样的噪声作为latent represent即可。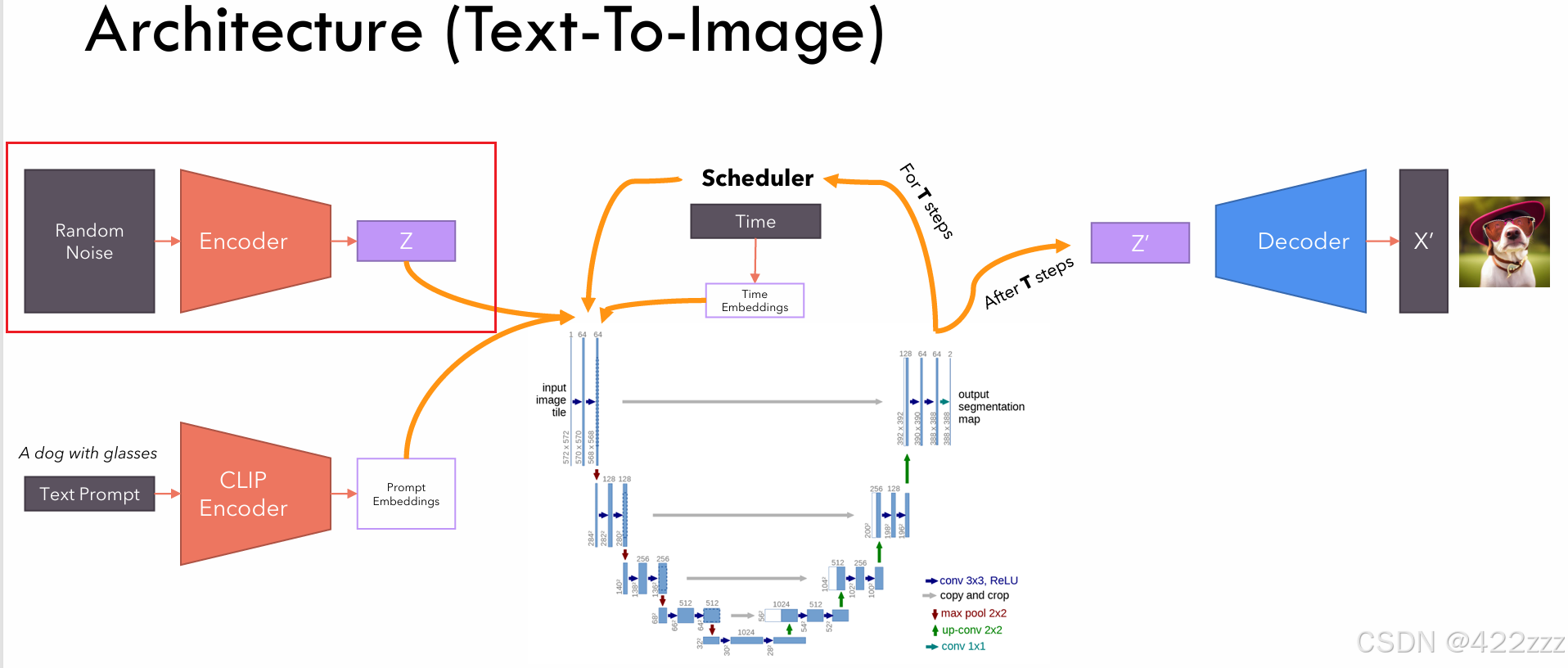
Diffusion:
中间的SD核心部分,其又可以分为,下面一部分的UNET和上面一部分的scheduler。UNET会取latent represent、prompt embedding以及当前的timestep,输出其预测的,若要使该latent向prompt发展,在该timestep时,该被去掉的噪声的强度。之后scheduler将该预测噪声从latent中去除,得到噪声更少的latent版本。两者合作遍历timestep,走完timestep,则得到其认为的无噪声的latent represent。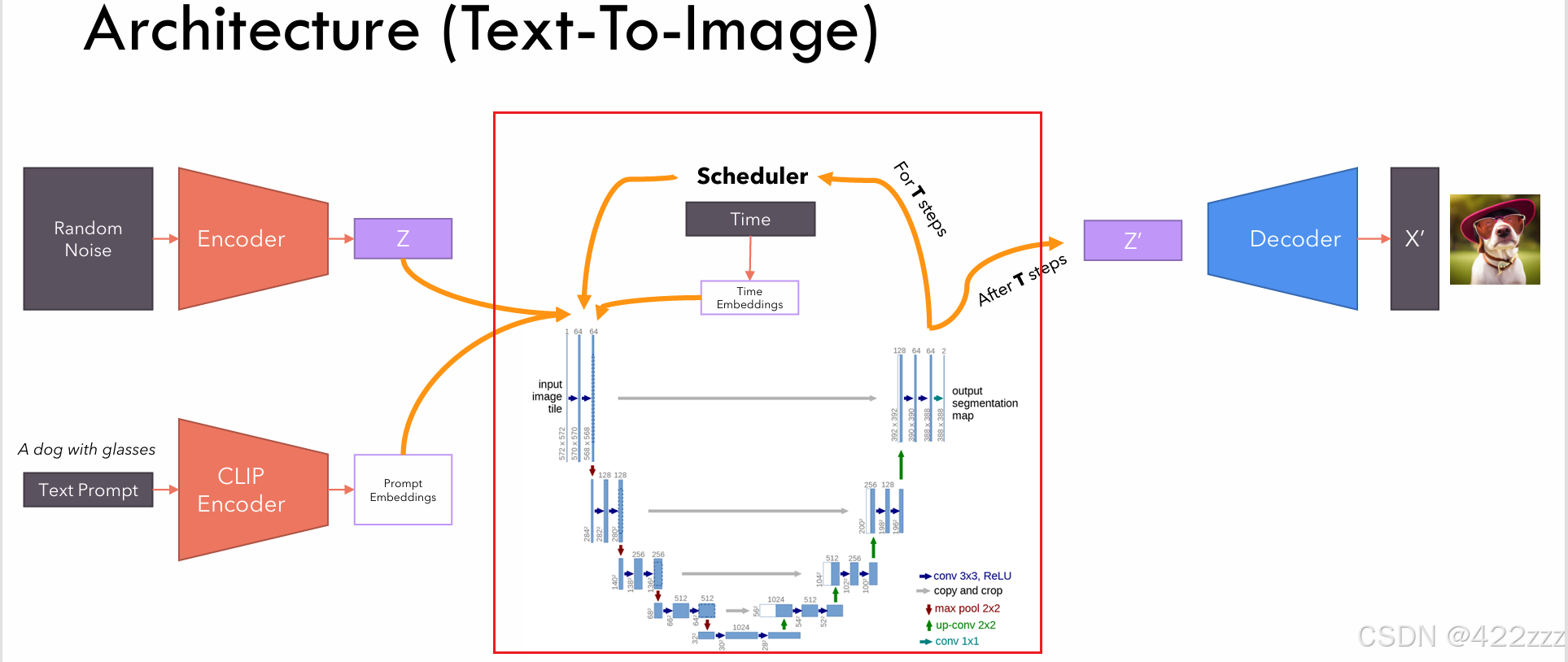
VAE_Decoder:
其将最终被预测为无噪声的latent,从latent space映射回原始的space,得到latent对应的图像。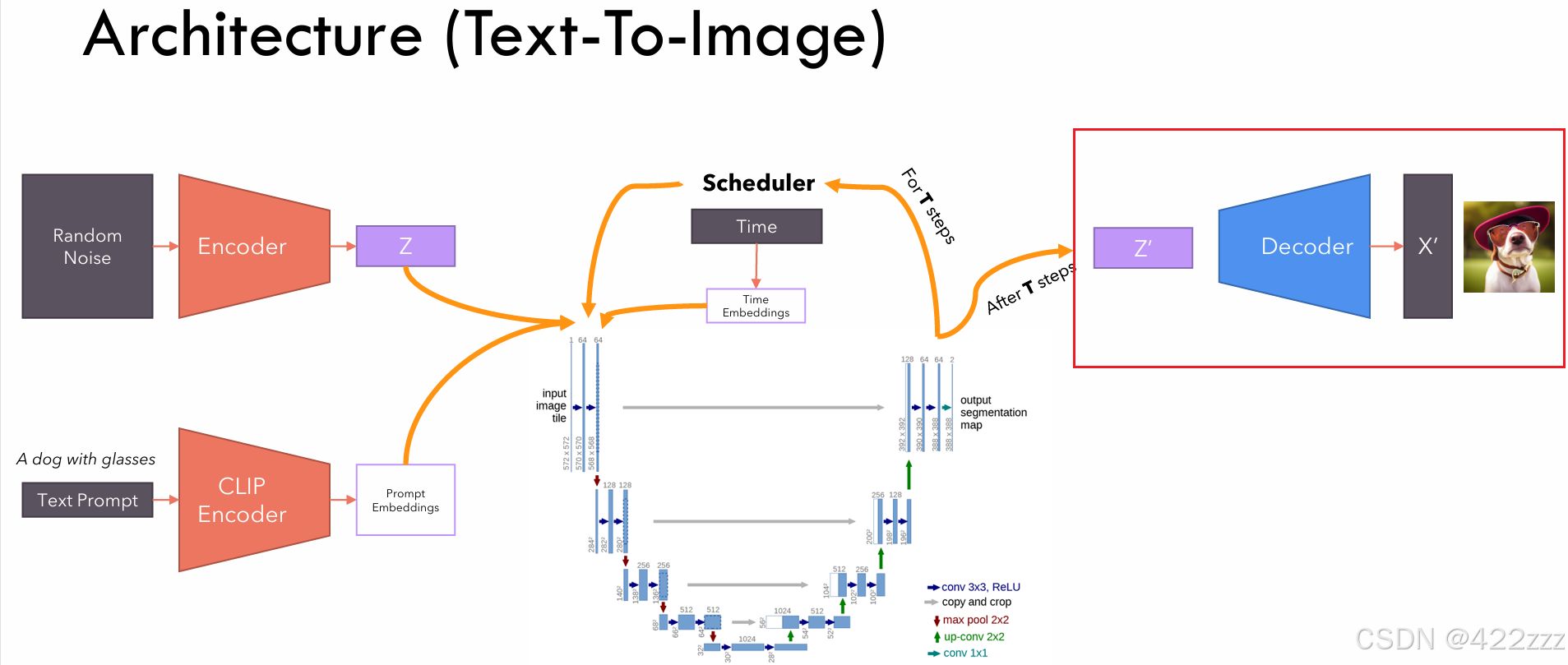
pipeline代码解析:
下面我将以构建pipeline为主线,逐步解析每一个流程,下面是完整的pipeline代码:
import torch
import numpy as np
from tqdm import tqdm
from ddpm import DDPMSampler
WIDTH = 512
HEIGHT = 512
LATENTS_WIDTH = WIDTH // 8
LATENTS_HEIGHT = HEIGHT // 8
def generate(
prompt,
uncond_prompt=None,
input_image=None,
strength=0.8,
do_cfg=True,
cfg_scale=7.5,
sampler_name="ddpm",
n_inference_steps=50,
models={},
seed=None,
device=None,
idle_device=None,
tokenizer=None,
):
with torch.no_grad():
if not 0 < strength <= 1:
raise ValueError("strength must be between 0 and 1")
if idle_device:
to_idle = lambda x: x.to(idle_device)
else:
to_idle = lambda x: x
# Initialize random number generator according to the seed specified
generator = torch.Generator(device=device)
if seed is None:
generator.seed()
else:
generator.manual_seed(seed)
clip = models["clip"]
clip.to(device)
if do_cfg:
# Convert into a list of length Seq_Len=77
cond_tokens = tokenizer.batch_encode_plus([prompt], padding="max_length", max_length=77).input_ids
# (Batch_Size, Seq_Len)
cond_tokens = torch.tensor(cond_tokens, dtype=torch.long, device=device)
# (Batch_Size, Seq_Len) -> (Batch_Size, Seq_Len, Dim)
cond_context = clip(cond_tokens)
# Convert into a list of length Seq_Len=77
uncond_tokens = tokenizer.batch_encode_plus([uncond_prompt], padding="max_length", max_length=77).input_ids
# (Batch_Size, Seq_Len)
uncond_tokens = torch.tensor(uncond_tokens, dtype=torch.long, device=device)
# (Batch_Size, Seq_Len) -> (Batch_Size, Seq_Len, Dim)
uncond_context = clip(uncond_tokens)
# (Batch_Size, Seq_Len, Dim) + (Batch_Size, Seq_Len, Dim) -> (2 * Batch_Size, Seq_Len, Dim)
context = torch.cat([cond_context, uncond_context])
else:
# Convert into a list of length Seq_Len=77
tokens = tokenizer.batch_encode_plus([prompt], padding="max_length", max_length=77).input_ids
# (Batch_Size, Seq_Len)
tokens = torch.tensor(tokens, dtype=torch.long, device=device)
# (Batch_Size, Seq_Len) -> (Batch_Size, Seq_Len, Dim)
context = clip(tokens)
to_idle(clip)
if sampler_name == "ddpm":
sampler = DDPMSampler(generator)
sampler.set_inference_timesteps(n_inference_steps)
else:
raise ValueError("Unknown sampler value %s. ")
latents_shape = (1, 4, LATENTS_HEIGHT, LATENTS_WIDTH)
if input_image:
encoder = models["encoder"]
encoder.to(device)
input_image_tensor = input_image.resize((WIDTH, HEIGHT))
input_image_tensor = np.array(input_image_tensor)
input_image_tensor = torch.tensor(input_image_tensor, dtype=torch.float32, device=device)
input_image_tensor = rescale(input_image_tensor, (0, 255), (-1, 1))
# (Height, Width, Channel) -> (Batch_Size, Height, Width, Channel)
input_image_tensor = input_image_tensor.unsqueeze(0)
# (Batch_Size, Height, Width, Channel) -> (Batch_Size, Channel, Height, Width)
input_image_tensor = input_image_tensor.permute(0, 3, 1, 2)
# (Batch_Size, 4, Latents_Height, Latents_Width)
encoder_noise = torch.randn(latents_shape, generator=generator, device=device)
# (Batch_Size, 4, Latents_Height, Latents_Width)
latents = encoder(input_image_tensor, encoder_noise)
# Add noise to the latents (the encoded input image)
# (Batch_Size, 4, Latents_Height, Latents_Width)
sampler.set_strength(strength=strength)
latents = sampler.add_noise(latents, sampler.timesteps[0])
to_idle(encoder)
else:
# (Batch_Size, 4, Latents_Height, Latents_Width)
latents = torch.randn(latents_shape, generator=generator, device=device)
diffusion = models["diffusion"]
diffusion.to(device)
timesteps = tqdm(sampler.timesteps)
for i, timestep in enumerate(timesteps):
# (1, 320)
time_embedding = get_time_embedding(timestep).to(device)
# (Batch_Size, 4, Latents_Height, Latents_Width)
model_input = latents
if do_cfg:
# (Batch_Size, 4, Latents_Height, Latents_Width) -> (2 * Batch_Size, 4, Latents_Height, Latents_Width)
model_input = model_input.repeat(2, 1, 1, 1)
# model_output is the predicted noise
# (Batch_Size, 4, Latents_Height, Latents_Width) -> (Batch_Size, 4, Latents_Height, Latents_Width)
model_output = diffusion(model_input, context, time_embedding)
if do_cfg:
output_cond, output_uncond = model_output.chunk(2)
model_output = cfg_scale * (output_cond - output_uncond) + output_uncond
# (Batch_Size, 4, Latents_Height, Latents_Width) -> (Batch_Size, 4, Latents_Height, Latents_Width)
latents = sampler.step(timestep, latents, model_output)
to_idle(diffusion)
decoder = models["decoder"]
decoder.to(device)
# (Batch_Size, 4, Latents_Height, Latents_Width) -> (Batch_Size, 3, Height, Width)
images = decoder(latents)
to_idle(decoder)
images = rescale(images, (-1, 1), (0, 255), clamp=True)
# (Batch_Size, Channel, Height, Width) -> (Batch_Size, Height, Width, Channel)
images = images.permute(0, 2, 3, 1)
images = images.to("cpu", torch.uint8).numpy()
return images[0]
def rescale(x, old_range, new_range, clamp=False):
old_min, old_max = old_range
new_min, new_max = new_range
x -= old_min
x *= (new_max - new_min) / (old_max - old_min)
x += new_min
if clamp:
x = x.clamp(new_min, new_max)
return x
def get_time_embedding(timestep):
# Shape: (160,)
freqs = torch.pow(10000, -torch.arange(start=0, end=160, dtype=torch.float32) / 160)
# Shape: (1, 160)
x = torch.tensor([timestep], dtype=torch.float32)[:, None] * freqs[None]
# Shape: (1, 160 * 2)
return torch.cat([torch.cos(x), torch.sin(x)], dim=-1)
我们一点点来拆解,首先我们处理的原始图像大小是512*512的,而其会被VAE映射到latent space,大小被压缩为64*64。
WIDTH = 512
HEIGHT = 512
LATENTS_WIDTH = WIDTH // 8
LATENTS_HEIGHT = HEIGHT // 8之后generate函数会有以下输入参数,每一个会在接下来遇到的时候做详细的解释:
def generate(
prompt,
uncond_prompt=None,
input_image=None,
strength=0.8,
do_cfg=True,
cfg_scale=7.5,
sampler_name="ddpm",
n_inference_steps=50,
models={},
seed=None,
device=None,
idle_device=None,
tokenizer=None,
):当然,因为当前是生成模式 ,所以不需要梯度计算 with torch.no_grad():。且因为整个生成过程,各模块是串行工作的,为避免GPU超负荷,我们提供了idle_device,让已经用好的模块存到idle_device中。
其次是随机种子的相关代码。
这里的strength即图生图时,对latent的所加的噪声的强度的控制参数,会在之后的相关函数中做更详细的说明。
with torch.no_grad():
if not 0 < strength <= 1:
raise ValueError("strength must be between 0 and 1")
if idle_device:
to_idle = lambda x: x.to(idle_device)
else:
to_idle = lambda x: x
# Initialize random number generator according to the seed specified
generator = torch.Generator(device=device)
if seed is None:
generator.seed()
else:
generator.manual_seed(seed)之后正是进入到第一个模块
CLIP:
clip = models["clip"]
clip.to(device)
if do_cfg:
# Convert into a list of length Seq_Len=77
cond_tokens = tokenizer.batch_encode_plus([prompt], padding="max_length", max_length=77).input_ids
# (Batch_Size, Seq_Len)
cond_tokens = torch.tensor(cond_tokens, dtype=torch.long, device=device)
# (Batch_Size, Seq_Len) -> (Batch_Size, Seq_Len, Dim)
cond_context = clip(cond_tokens)
uncond_tokens = tokenizer.batch_encode_plus([uncond_prompt], padding="max_length", max_length=77).input_ids
uncond_tokens = torch.tensor(uncond_tokens, dtype=torch.long, device=device)
uncond_context = clip(uncond_tokens)
# (Batch_Size, Seq_Len, Dim) + (Batch_Size, Seq_Len, Dim) -> (2 * Batch_Size, Seq_Len, Dim)
context = torch.cat([cond_context, uncond_context])
else:
tokens = tokenizer.batch_encode_plus([prompt], padding="max_length", max_length=77).input_ids
tokens = torch.tensor(tokens, dtype=torch.long, device=device)
context = clip(tokens)
to_idle(clip)首先,从models中去取出clip模型。其中models由来如下:
其中v1-5-pruned-emaonly.ckpt的下载地址为:https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5/tree/main
model_file = "../data/v1-5-pruned-emaonly.ckpt"
models = model_loader.preload_models_from_standard_weights(model_file, DEVICE)model_loader文件中的preload_models_from_standard_weights所做之事可以总结为:从模型参数集中,拆分各个模块的参数并保存下来。
def preload_models_from_standard_weights(ckpt_path, device):
state_dict = model_converter.load_from_standard_weights(ckpt_path, device)
encoder = VAE_Encoder().to(device)
encoder.load_state_dict(state_dict['encoder'], strict=True)
decoder = VAE_Decoder().to(device)
decoder.load_state_dict(state_dict['decoder'], strict=True)
diffusion = Diffusion().to(device)
diffusion.load_state_dict(state_dict['diffusion'], strict=True)
clip = CLIP().to(device)
clip.load_state_dict(state_dict['clip'], strict=True)
return {
'clip': clip,
'encoder': encoder,
'decoder': decoder,
'diffusion': diffusion,
}其中model_converter文件中load_from_standard_weights函数的用意为,实现参数名称的映射。因为预训练模型参数名称并不是很直观,在本文章的代码中,参数名称都改为了更清晰更直观的称呼。这就导致,如果没有把预训练的参数名称重映射为新的参数名称,则加载权重时,无法成功。
model_converter文件具体代码可参考链接:pytorch-stable-diffusion/sd/model_converter.py at main · hkproj/pytorch-stable-diffusion
之后判断do_cfg是否为真,即do classifier-free guidance or not,是否进行无分类器引导。
而在此无分类器引导可以认为是,每张最终输出的图像,都是两张生成图像的线性组合。其中一张是由positive prompt (参数prompt)出发生成的图像OUTPUTconditioned,另一张是由negative prompt (参数uncond_prompt)出发生成的图像OUTPUTunconditioned。最终输出为:
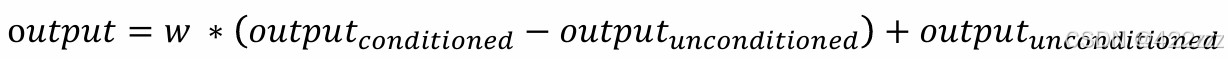
这里的prompt就是描述我们的生成目标,而uncond_prompt可以认为是告诉模型我们不要什么,或者一般就使用空字符串,即多给模型提供一些自由度。例如prompt参数为“生成一个慵懒的猫”,但是不想让它躺在沙发上,那么就给uncond_prompt传入“沙发”,或者不提其他要求,uncond_prompt传入“”空字符串。
拿传入空字符串的情况来理解权重w(也就是当前传参cfg_scale),即若cfg_scale很高表明我们希望模型严格按照我们的提示prompt来生成图像,自由发挥的灵活性小。
所以我们一次生成,需要两个提示内容,两者分别用CLIP处理得到token的embedding represent,且在最后将其连接起来,方便一起生成操作。
if do_cfg:
# Convert into a list of length Seq_Len=77
cond_tokens = tokenizer.batch_encode_plus([prompt], padding="max_length", max_length=77).input_ids
# (Batch_Size, Seq_Len)
cond_tokens = torch.tensor(cond_tokens, dtype=torch.long, device=device)
# (Batch_Size, Seq_Len) -> (Batch_Size, Seq_Len, Dim)
cond_context = clip(cond_tokens)
uncond_tokens = tokenizer.batch_encode_plus([uncond_prompt], padding="max_length", max_length=77).input_ids
uncond_tokens = torch.tensor(uncond_tokens, dtype=torch.long, device=device)
uncond_context = clip(uncond_tokens)
# (Batch_Size, Seq_Len, Dim) + (Batch_Size, Seq_Len, Dim) -> (2 * Batch_Size, Seq_Len, Dim)
context = torch.cat([cond_context, uncond_context])这里用tokenizer将prompt处理为cond_tokens,将uncond_prompt处理为uncond_tokens的具体实现就不加具体阐述了,可以直接理解为把提示句子按某种具体的方法切割成每个word。由下面这行代码得到现成的tokenizer。文件下载地址: https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5/tree/main/tokenizer
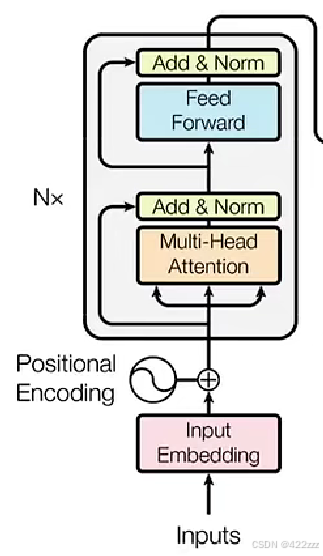
tokenizer = CLIPTokenizer("../data/tokenizer_vocab.json", merges_file="../data/tokenizer_merges.txt")此时重点就在于clip到底做了什么事,可以参考transformer中的编码器部分,如图:
首先CLIP类定义为:
class CLIP(nn.Module):
def __init__(self):
super().__init__()
self.embedding = CLIPEmbedding(49408, 768, 77)
self.layers = nn.ModuleList([CLIPLayer(12, 768) for i in range(12)])
self.layernorm = nn.LayerNorm(768)
def forward(self, tokens: torch.LongTensor) -> torch.FloatTensor:
tokens = tokens.type(torch.long)
# (Batch_Size, Seq_Len) -> (Batch_Size, Seq_Len, Dim)
state = self.embedding(tokens)
# Apply encoder layers similar to the Transformer's encoder.
for layer in self.layers:
# (Batch_Size, Seq_Len, Dim) -> (Batch_Size, Seq_Len, Dim)
state = layer(state)
# (Batch_Size, Seq_Len, Dim) -> (Batch_Size, Seq_Len, Dim)
output = self.layernorm(state)
return output对于理解这种自定义的类,我倾向于从forward,也就是真正使用它的部分来下手。
首先一个基础的类型转换,因为之前得到的tokens是torch.LongTensor,但是之后embedding需要torch.long。
而这里的self.embedding是自定义的CLIPEmbedding,如下:
class CLIPEmbedding(nn.Module):
def __init__(self, n_vocab: int, n_embd: int, n_token: int):
super().__init__()
self.token_embedding = nn.Embedding(n_vocab, n_embd)
# A learnable weight matrix encodes the position information for each token
self.position_embedding = nn.Parameter(torch.zeros((n_token, n_embd)))
def forward(self, tokens):
# (Batch_Size, Seq_Len) -> (Batch_Size, Seq_Len, Dim)
x = self.token_embedding(tokens)
# (Batch_Size, Seq_Len) -> (Batch_Size, Seq_Len, Dim)
x += self.position_embedding
return x对每个token,我们需要两个embedding,一个input embedding,一个position embedding。
input embedding即相当于一个词汇表,每个单词会对应一个数字,再通过 nn.Embedding把这个数字映射成word对应的input embedding。也就是把单词用一个可学习的矩阵来表达。
position embedding即相当于,我们要对单词所在的位置进行编码表达。整体的CLIPembedding是input embedding与position embedding的和,即一起关注单词本身的意思以及它所在的位置。
且这里体现出词汇表的大小为n_vocab=49408,句子最长可为n_token=77,而两种嵌入的表达向量长度为n_embd=768。
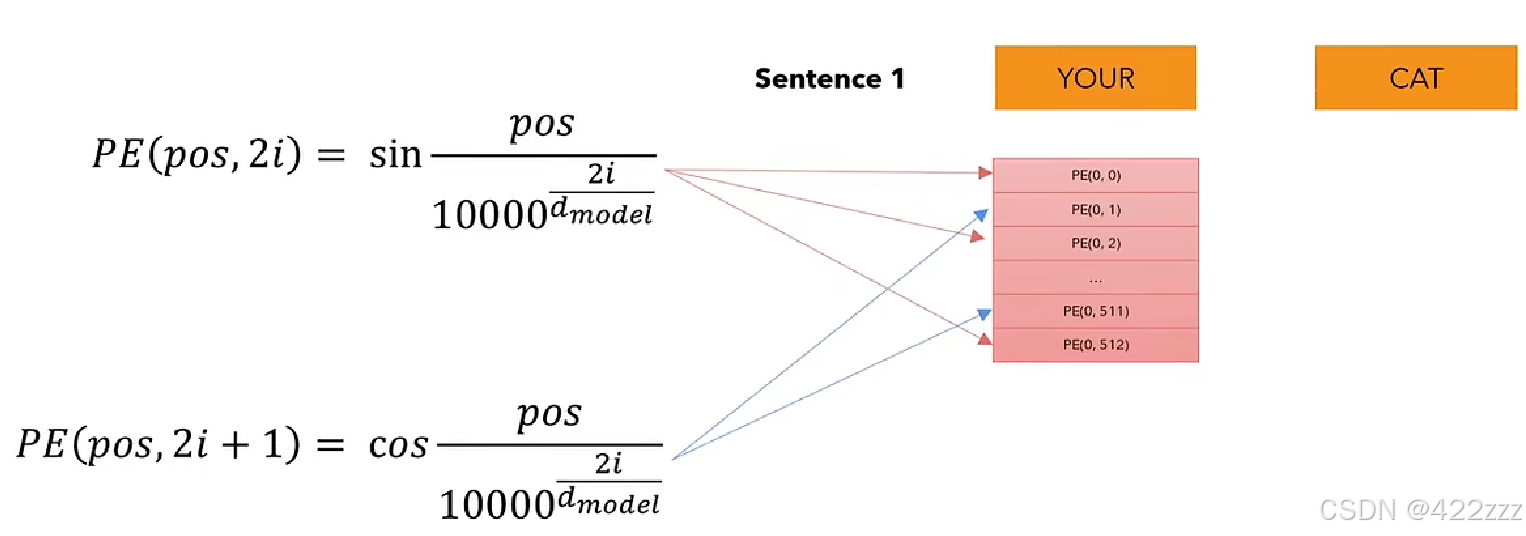
与transformer中的position embedding不同的是,transformer中位置编码是固定的,如典型的代码如下:
class PositionalEncoding(nn.Module):
def __init__(self, d_model: int, seq_len: int, dropout: float) -> None:
super().__init__()
self.d_model = d_model
self.seq_len = seq_len
self.dropout = nn.Dropout(dropout)
# Create a matrix of shape (seq_len, d_model)
pe = torch.zeros(seq_len, d_model)
# Create a vector of shape (seq_len)
position = torch.arange(0, seq_len, dtype=torch.float).unsqueeze(1) # (seq_len, 1)
# Create a vector of shape (d_model)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)) # (d_model / 2)
# Apply sine to even indices
pe[:, 0::2] = torch.sin(position * div_term) # sin(position * (10000 ** (2i / d_model))
# Apply cosine to odd indices
pe[:, 1::2] = torch.cos(position * div_term) # cos(position * (10000 ** (2i / d_model))
# Add a batch dimension to the positional encoding
pe = pe.unsqueeze(0) # (1, seq_len, d_model)
# Register the positional encoding as a buffer
self.register_buffer('pe', pe)
def forward(self, x):
x = x + (self.pe[:, :x.shape[1], :]).requires_grad_(False) # (batch, seq_len, d_model)
return self.dropout(x)它是不可学习的,在初始化时就固定好了。利用的是正弦和余弦的编码方式,具体函数如下图:
而在这里CLIP中位置编码是可学习的参数,初始化为0。为什么呢?我认为图像像素之间的空间关系比文本序列中的位置关系复杂得多,固定的正余弦编码可能无法充分表达这种复杂的空间依赖。
之后便是遍历全部self.layers = nn.ModuleList([CLIPLayer(12, 768) for i in range(12)]),CLIPLayer定义如下:
class CLIPLayer(nn.Module):
def __init__(self, n_head: int, n_embd: int):
super().__init__()
# Pre-attention norm
self.layernorm_1 = nn.LayerNorm(n_embd)
# Self attention
self.attention = SelfAttention(n_head, n_embd)
# Pre-FNN norm
self.layernorm_2 = nn.LayerNorm(n_embd)
# Feedforward layer
self.linear_1 = nn.Linear(n_embd, 4 * n_embd)
self.linear_2 = nn.Linear(4 * n_embd, n_embd)
def forward(self, x):
# (Batch_Size, Seq_Len, Dim)
### SELF-ATTENTION ###
residue = x
x = self.layernorm_1(x)
x = self.attention(x, causal_mask=True)
x += residue
### FEEDFORWARD LAYER ###
residue = x
x = self.layernorm_2(x)
# (Batch_Size, Seq_Len, Dim) -> (Batch_Size, Seq_Len, 4 * Dim)
x = self.linear_1(x)
x = x * torch.sigmoid(1.702 * x) # QuickGELU activation function
# (Batch_Size, Seq_Len, 4 * Dim) -> (Batch_Size, Seq_Len, Dim)
x = self.linear_2(x)
x += residue
return x这里每个CLIPLayer所做的就是两个残差块,一个是关于多头自注意力的,另一个是向前反馈层的,我们一步步说。希望可以耐心继续阅读下去,因为注意力等模块是后面基本所有大模块的基石,在这论述的详细一些,在之后就可直接调用了。
我们还是借助transformer的编码器部分的流程图来看:
首先来实现
多头自注意力的残差块:
def forward(self, x):
# (Batch_Size, Seq_Len, Dim)
### SELF-ATTENTION ###
residue = x
x = self.layernorm_1(x)
x = self.attention(x, causal_mask=True)
x += residue保留初始输入为残差residue。对输入先进行层归一化处理self.layernorm_1 = nn.LayerNorm(n_embd)。所谓层归一化(Layer Normalization),是对每个样本的所有特征进行归一化,对于每个token的特征向量,层归一化会计算该向量的均值和方差,然后进行归一化,使得每个token的嵌入向量在每个维度上具有零均值和单位方差。如图:
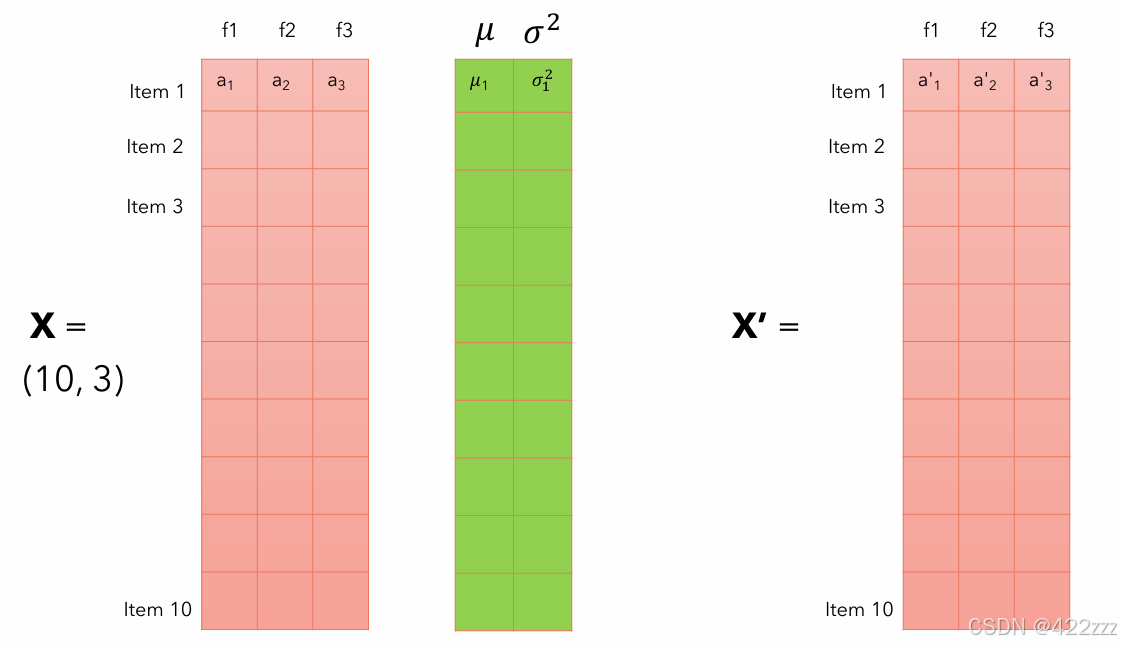
一些常见的归一化的对比,可以见下图:
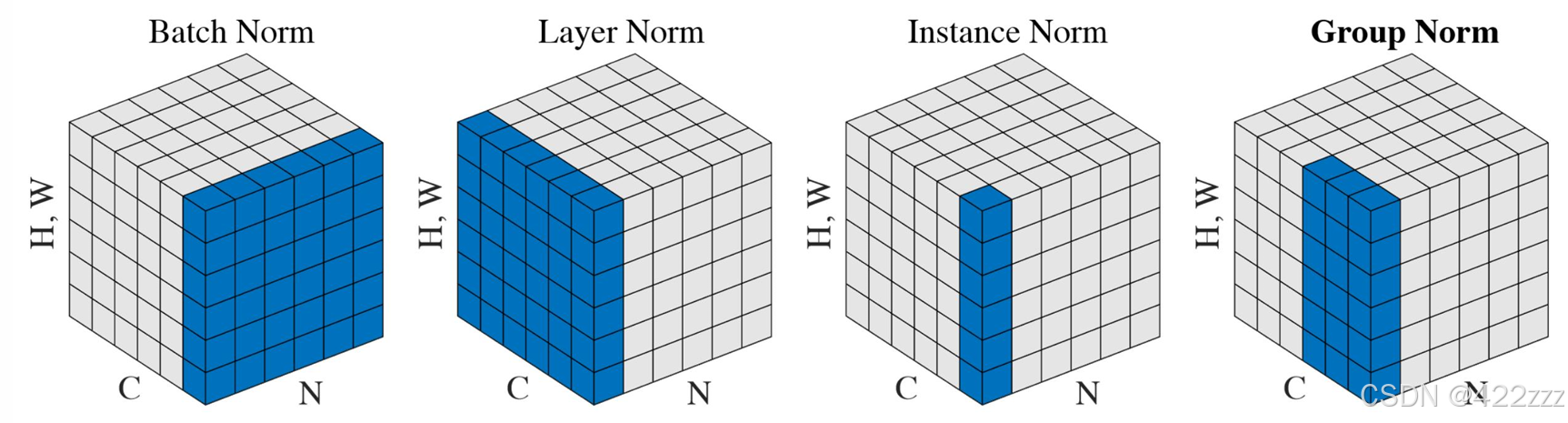
之后对层归一化后的输入使用自注意力self.attention = SelfAttention(n_head, n_embd),SelfAttention函数如下:
class SelfAttention(nn.Module):
def __init__(self, n_heads, d_embed, in_proj_bias=True, out_proj_bias=True):
super().__init__()
# This combines the Wq, Wk and Wv matrices into one matrix
self.in_proj = nn.Linear(d_embed, 3 * d_embed, bias=in_proj_bias)
# This one represents the Wo matrix
self.out_proj = nn.Linear(d_embed, d_embed, bias=out_proj_bias)
self.n_heads = n_heads
self.d_head = d_embed // n_heads
def forward(self, x, causal_mask=False):
# x: # (Batch_Size, Seq_Len, Dim)
# (Batch_Size, Seq_Len, Dim)
input_shape = x.shape
batch_size, sequence_length, d_embed = input_shape
# (Batch_Size, Seq_Len, H, Dim / H)
interim_shape = (batch_size, sequence_length, self.n_heads, self.d_head)
# (Batch_Size, Seq_Len, Dim) -> (Batch_Size, Seq_Len, Dim * 3) -> 3 tensor of shape (Batch_Size, Seq_Len, Dim)
q, k, v = self.in_proj(x).chunk(3, dim=-1)
# (Batch_Size, Seq_Len, Dim) -> (Batch_Size, Seq_Len, H, Dim / H) -> (Batch_Size, H, Seq_Len, Dim / H)
q = q.view(interim_shape).transpose(1, 2)
k = k.view(interim_shape).transpose(1, 2)
v = v.view(interim_shape).transpose(1, 2)
# (Batch_Size, H, Seq_Len, Dim / H) @ (Batch_Size, H, Dim / H, Seq_Len) -> (Batch_Size, H, Seq_Len, Seq_Len)
weight = q @ k.transpose(-1, -2)
if causal_mask:
# Mask where the upper triangle (above the principal diagonal) is 1
mask = torch.ones_like(weight, dtype=torch.bool).triu(1)
# Fill the upper triangle with -inf
weight.masked_fill_(mask, -torch.inf)
# Divide by d_k (Dim / H).
# (Batch_Size, H, Seq_Len, Seq_Len) -> (Batch_Size, H, Seq_Len, Seq_Len)
weight /= math.sqrt(self.d_head)
# (Batch_Size, H, Seq_Len, Seq_Len) -> (Batch_Size, H, Seq_Len, Seq_Len)
weight = F.softmax(weight, dim=-1)
# (Batch_Size, H, Seq_Len, Seq_Len) @ (Batch_Size, H, Seq_Len, Dim / H) -> (Batch_Size, H, Seq_Len, Dim / H)
output = weight @ v
# (Batch_Size, H, Seq_Len, Dim / H) -> (Batch_Size, Seq_Len, H, Dim / H)
output = output.transpose(1, 2)
# (Batch_Size, Seq_Len, H, Dim / H) -> (Batch_Size, Seq_Len, Dim)
output = output.reshape(input_shape)
# (Batch_Size, Seq_Len, Dim) -> (Batch_Size, Seq_Len, Dim)
output = self.out_proj(output)
return output其流程为:
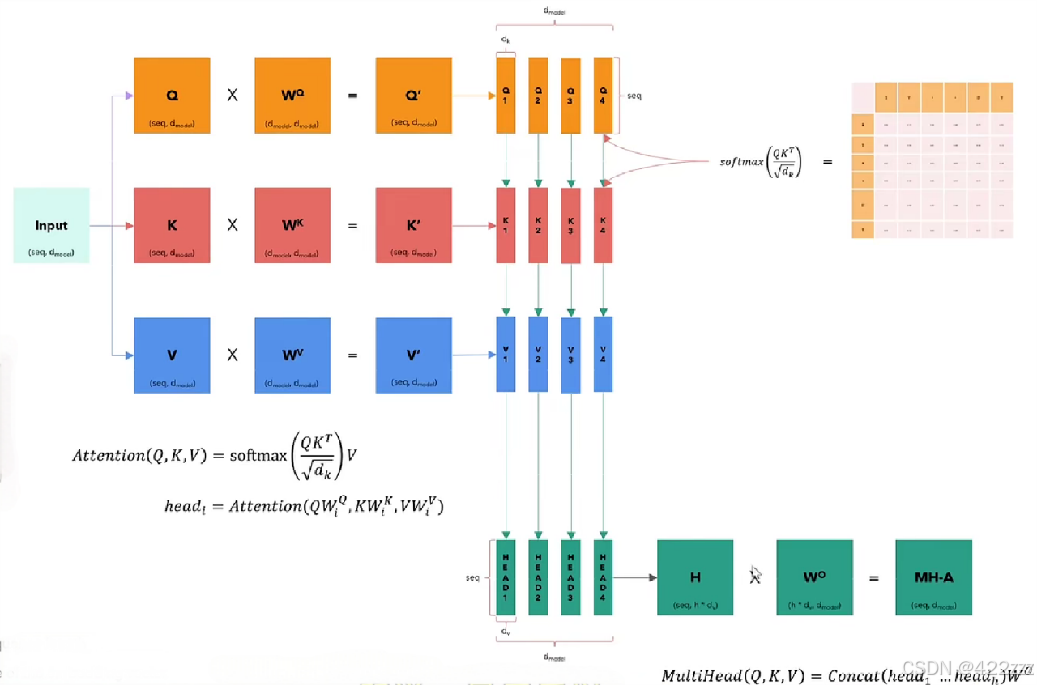
首先,其是自注意力(Self-attention allows the model to relate words to each other )。即Q(query)K(key)V(value)在这都是同一个矩阵,即input,即归一化后的x。所以这里直接把x输入到self.in_proj = nn.Linear(d_embed, 3 * d_embed, bias=in_proj_bias)中,将其映射成三个矩阵,再在之后切割回q, k, v = self.in_proj(x).chunk(3, dim=-1),qkv即可,这里的qkv即是经过WQ,WQ,WV映射后得到的Q'K'V'。
之后通过传参n_heads设置head数,以及每头的维度,self.d_head = d_embed // n_heads,从而得到interim_shape = (batch_size, sequence_length, self.n_heads, self.d_head)
随后使用view对qkv做切割为多头即可(因为其存储是连续的,所以可以直接切割):
注意还需要使用transpose改变维度的顺序,因为我们希望每个头都可以包含整个句子序列,包含每个单词的不同表达。
# (Batch_Size, Seq_Len, Dim) -> (Batch_Size, Seq_Len, H, Dim / H) -> (Batch_Size, H, Seq_Len, Dim / H)
q = q.view(interim_shape).transpose(1, 2)
k = k.view(interim_shape).transpose(1, 2)
v = v.view(interim_shape).transpose(1, 2)然后是计算注意力的基础公式
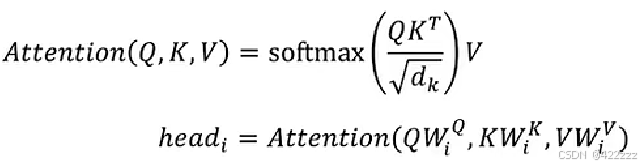
首先来算QKT:
# (Batch_Size, H, Seq_Len, Dim / H) @ (Batch_Size, H, Dim / H, Seq_Len) -> (Batch_Size, H, Seq_Len, Seq_Len)
weight = q @ k.transpose(-1, -2)之后除以维度的square root:
# Divide by d_k (Dim / H).
# (Batch_Size, H, Seq_Len, Seq_Len) -> (Batch_Size, H, Seq_Len, Seq_Len)
weight /= math.sqrt(self.d_head)接着,在使用softmax之间,会使用一个因果遮罩Causal_mask。它的意图为把weight矩阵的上三角部分人为的设置为负无穷。
if causal_mask:
# Mask where the upper triangle (above the principal diagonal) is 1
mask = torch.ones_like(weight, dtype=torch.bool).triu(1)
# Fill the upper triangle with -inf
weight.masked_fill_(mask, -torch.inf)这一点可以由特殊的mask入手理解,即我们可以通过人为的设置mask哪些位置为1或0,以此来决定weight的哪些位置需要被设置为负无穷(或1e-9即可),例如:
if mask is not None:
# Write a very low value (indicating -inf) to the positions where mask == 0
attention_scores.masked_fill_(mask == 0, -1e9)这可以理解为一种,不希望哪两个token互相产生关联的一种做法。例如不想让长发与男人直接有相关性,我们直接让这两者的token直接计算出来的注意力score,在softmax前被赋值为负无穷即可。
因为softmax的公式为: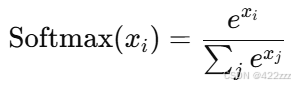
若每一项x为负无穷,即当前项在softmax之后会被强制接近0,即强制两者无关。
这里的因果遮罩,将上三角的注意力score强制设置为0,意为让模型获取不到当前像素与未来像素的相关性,即模型无法关注到未来的像素,只会关注当前像素与之前模型见到过的像素之间的关联度。【在训练中,如果模型可以访问未来时间步的信息,它可能直接记住这些信息,而不是学习如何正确预测。遮罩机制通过屏蔽未来时间步,防止这种 投机取巧 的行为,让模型学会真正的推理能力】
所以遮罩处理完,使用softmax,并乘上V矩阵,之后同理把维度顺序换回去,即把多头cat回一起:
weight = F.softmax(weight, dim=-1)
# (Batch_Size, H, Seq_Len, Seq_Len) @ (Batch_Size, H, Seq_Len, Dim / H) -> (Batch_Size, H, Seq_Len, Dim / H)
output = weight @ v
# (Batch_Size, H, Seq_Len, Dim / H) -> (Batch_Size, Seq_Len, H, Dim / H)
output = output.transpose(1, 2)
# (Batch_Size, Seq_Len, H, Dim / H) -> (Batch_Size, Seq_Len, Dim)
output = output.reshape(input_shape)最后WO矩阵重新表达一次output即可:
self.out_proj = nn.Linear(d_embed, d_embed, bias=out_proj_bias):
# (Batch_Size, Seq_Len, Dim) -> (Batch_Size, Seq_Len, Dim)
output = self.out_proj(output)
return output到此,已经得到了x = self.attention(x, causal_mask=True),返回之前的多头自注意力残差块,此时将注意力返回矩阵加上残差residue即可完成此残差块:
### SELF-ATTENTION ###
residue = x
x = self.layernorm_1(x)
x = self.attention(x, causal_mask=True)
x += residue第二个残差块为
向前反馈残差块:
这个就比较容易了,其的作用是对每个位置的特征进行进一步非线性转换,因为Self-Attention 机制通过计算sequence中每个位置之间的关系,捕获了全局信息,但它本身并不具有强大的非线性变换能力,这个feed forward残差层,通过将输入维度扩展到 4 倍,QuickGELU激活函数,再将维度从 4 倍还原到原来的维度,增强了模型的表达能力。
### FEEDFORWARD LAYER ###
residue = x
x = self.layernorm_2(x)
# (Batch_Size, Seq_Len, Dim) -> (Batch_Size, Seq_Len, 4 * Dim)
x = self.linear_1(x)
x = x * torch.sigmoid(1.702 * x) # QuickGELU activation function
# (Batch_Size, Seq_Len, 4 * Dim) -> (Batch_Size, Seq_Len, Dim)
x = self.linear_2(x)
x += residue
其中:
self.linear_1 = nn.Linear(n_embd, 4 * n_embd)
self.linear_2 = nn.Linear(4 * n_embd, n_embd)所以至此,两个残差块一起连用,即组成了CLIPLayer。而12个CLIPLayer串行使用,构成了:self.layers = nn.ModuleList([CLIPLayer(12, 768) for i in range(12)]),且这里head数为12。
所以,回到CLIP类的定义中,我们已经实现到此了:串行应用所有CLIPLayer,即12个编码器一起使用,每个编码器又是由自注意力残差块以及向前反馈残差块组成的。最后对输出做一个层归一化。
# Apply encoder layers similar to the Transformer's encoder.
for layer in self.layers:
# (Batch_Size, Seq_Len, Dim) -> (Batch_Size, Seq_Len, Dim)
state = layer(state)
# (Batch_Size, Seq_Len, Dim) -> (Batch_Size, Seq_Len, Dim)
output = self.layernorm(state)这便是clip forward的所有内容。即将tokens,转换为了对应的嵌入表达。
对于不使用无分类器引导的模式,context直接就是tokenizer拆解prompt后输入clip后得到的值:
之后clip的使用到此告一段落,可以将其移至idle_device了。
else:
tokens = tokenizer.batch_encode_plus([prompt], padding="max_length", max_length=77).input_ids
tokens = torch.tensor(tokens, dtype=torch.long, device=device)
context = clip(tokens)
to_idle(clip)CLIP之后的模块是
VAE_Encoder:
更详细的关于VAE的论述因为内容实在太多,且数学论述太多,本着本篇文章尽量少公式的想法,之后会单独论述一篇VAE的文章。
if sampler_name == "ddpm":
sampler = DDPMSampler(generator)
sampler.set_inference_timesteps(n_inference_steps)
else:
raise ValueError("Unknown sampler value %s. ")
latents_shape = (1, 4, LATENTS_HEIGHT, LATENTS_WIDTH)
if input_image:
encoder = models["encoder"]
encoder.to(device)
input_image_tensor = input_image.resize((WIDTH, HEIGHT))
input_image_tensor = np.array(input_image_tensor)
input_image_tensor = torch.tensor(input_image_tensor, dtype=torch.float32, device=device)
input_image_tensor = rescale(input_image_tensor, (0, 255), (-1, 1))
# (Height, Width, Channel) -> (Batch_Size, Height, Width, Channel)
input_image_tensor = input_image_tensor.unsqueeze(0)
# (Batch_Size, Height, Width, Channel) -> (Batch_Size, Channel, Height, Width)
input_image_tensor = input_image_tensor.permute(0, 3, 1, 2)
# (Batch_Size, 4, Latents_Height, Latents_Width)
encoder_noise = torch.randn(latents_shape, generator=generator, device=device)
# (Batch_Size, 4, Latents_Height, Latents_Width)
latents = encoder(input_image_tensor, encoder_noise)
# Add noise to the latents (the encoded input image)
# (Batch_Size, 4, Latents_Height, Latents_Width)
sampler.set_strength(strength=strength)
latents = sampler.add_noise(latents, sampler.timesteps[0])
to_idle(encoder)
else:
# (Batch_Size, 4, Latents_Height, Latents_Width)
latents = torch.randn(latents_shape, generator=generator, device=device)如果使用的是文生图,即无original image,那么上面的代码可以简化为如下代码,即直接采样高斯分布噪声作为latent represent:
latents_shape = (1, 4, LATENTS_HEIGHT, LATENTS_WIDTH)
# (Batch_Size, 4, Latents_Height, Latents_Width)
latents = torch.randn(latents_shape, generator=generator, device=device)若要图生图,才会使用VAE_Encoder(代码开头的ddpm部分在后面论述),先来看VAE_Encoder部分,首先读取encoder模型:
if input_image:
encoder = models["encoder"]
encoder.to(device)先是对original image的处理,包括resize缩放其大小至(WIDTH, HEIGHT)=(64, 64),并将其值缩放到(-1,1),并unsqueeze增加一个batch维度便于广播,并调换维度顺序,保证channel维度紧跟batch维度之后:
input_image_tensor = input_image.resize((WIDTH, HEIGHT))
input_image_tensor = np.array(input_image_tensor)
input_image_tensor = torch.tensor(input_image_tensor, dtype=torch.float32, device=device)
input_image_tensor = rescale(input_image_tensor, (0, 255), (-1, 1))
# (Height, Width, Channel) -> (Batch_Size, Height, Width, Channel)
input_image_tensor = input_image_tensor.unsqueeze(0)
# (Batch_Size, Height, Width, Channel) -> (Batch_Size, Channel, Height, Width)
input_image_tensor = input_image_tensor.permute(0, 3, 1, 2)然后要明白encoder的相关操作,需要明白
encoder:
内部的操作:
encoder_noise = torch.randn(latents_shape, generator=generator, device=device)
latents = encoder(input_image_tensor, encoder_noise)VAE_Encoder代码为:
class VAE_Encoder(nn.Sequential):
def __init__(self):
super().__init__(
# (Batch_Size, Channel, Height, Width) -> (Batch_Size, 128, Height, Width)
nn.Conv2d(3, 128, kernel_size=3, padding=1),
VAE_ResidualBlock(128, 128),
VAE_ResidualBlock(128, 128),
# (Batch_Size, 128, Height, Width) -> (Batch_Size, 128, Height / 2, Width / 2)
nn.Conv2d(128, 128, kernel_size=3, stride=2, padding=0),
# (Batch_Size, 128, Height / 2, Width / 2) -> (Batch_Size, 256, Height / 2, Width / 2)
VAE_ResidualBlock(128, 256),
VAE_ResidualBlock(256, 256),
# (Batch_Size, 256, Height / 2, Width / 2) -> (Batch_Size, 256, Height / 4, Width / 4)
nn.Conv2d(256, 256, kernel_size=3, stride=2, padding=0),
# (Batch_Size, 256, Height / 4, Width / 4) -> (Batch_Size, 512, Height / 4, Width / 4)
VAE_ResidualBlock(256, 512),
VAE_ResidualBlock(512, 512),
# (Batch_Size, 512, Height / 4, Width / 4) -> (Batch_Size, 512, Height / 8, Width / 8)
nn.Conv2d(512, 512, kernel_size=3, stride=2, padding=0),
VAE_ResidualBlock(512, 512),
VAE_ResidualBlock(512, 512),
VAE_ResidualBlock(512, 512),
VAE_AttentionBlock(512),
VAE_ResidualBlock(512, 512),
nn.GroupNorm(32, 512),
nn.SiLU(),
# (Batch_Size, 512, Height / 8, Width / 8) -> (Batch_Size, 8, Height / 8, Width / 8).
nn.Conv2d(512, 8, kernel_size=3, padding=1),
# (Batch_Size, 8, Height / 8, Width / 8) -> (Batch_Size, 8, Height / 8, Width / 8)
nn.Conv2d(8, 8, kernel_size=1, padding=0),
)
def forward(self, x, noise):
# x: (Batch_Size, Channel, Height, Width)
# noise: (Batch_Size, 4, Height / 8, Width / 8)
for module in self:
if getattr(module, 'stride', None) == (2, 2): # Padding at downsampling should be asymmetric (see #8)
x = F.pad(x, (0, 1, 0, 1))
x = module(x)
# (Batch_Size, 8, Height / 8, Width / 8) -> two tensors of shape (Batch_Size, 4, Height / 8, Width / 8)
mean, log_variance = torch.chunk(x, 2, dim=1)
# Clamp the log variance between -30 and 20, so that the variance is between (circa) 1e-14 and 1e8.
log_variance = torch.clamp(log_variance, -30, 20)
variance = log_variance.exp()
stdev = variance.sqrt()
# Transform N(0, 1) -> N(mean, stdev)
x = mean + stdev * noise
# Scale by a constant
x *= 0.18215
return x首先要明确一点,图像生成任务的本质目标是学习图像数据的分布,而因为SD引入了latent represent,且将latent variable建模为一个多变量的高斯分布,即VAR_Encoder本质上学习的就是两个值,一个是高斯分布的均值,另一个就是高斯分布的方差。
如此一来,若我们想从latent space采样出一个latent,我们可以先从标准高斯分布中采样出一个标准latent样本,然后用VAE_Encoder学习到的mean与stdev去处理标准latent样本,即可得到从VAE高斯空间中采样出的latent样本了。因为将标准高斯分布 Z∼N(0,1) 转换为一个新的高斯分布 X∼N(μ,σ2)可以由如下线性变换得到: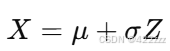 所以,在此也就是把:
所以,在此也就是把:
从标准高斯分布中采样得到的noise,也就是encoder_noise = torch.randn(latents_shape, generator=generator, device=device),latents = encoder(input_image_tensor, encoder_noise)这里的encoder_noise。然后如此处理即可:
# Transform N(0, 1) -> N(mean, stdev)
x = mean + stdev * noise最后的x *= 0.18215是出于工程实际考虑,保证训练稳定。
那么我们来看看这个mean和stdev是如何得到的。
主方向即串行遍历所有定义的模块,最终的输出可以被分割为latent space的mean和log_variance。再加上clamp强制区间范围,其取指数即可得到variance,开根号得到上述需要的stdev。
mean, log_variance = torch.chunk(x, 2, dim=1)
# Clamp the log variance between -30 and 20, so that the variance is between (circa) 1e-14 and 1e8.
log_variance = torch.clamp(log_variance, -30, 20)
variance = log_variance.exp()
stdev = variance.sqrt()那在这,为什么训练VAE_Encoder的时候,要选择学习log_variance,而不是直接学习variance呢? 因为variance是非负的,而log_variance是可以取全实数的,此时模型的参数空间更宽广,避免了对variance进行优化时可能出现的数值限制和不稳定情况。这是一个常见的技巧,可以增强模型的灵活性。
那接下来就是VAE_Encoder的模块序列了:
class VAE_Encoder(nn.Sequential):
def __init__(self):
super().__init__(
# (Batch_Size, Channel, Height, Width) -> (Batch_Size, 128, Height, Width)
nn.Conv2d(3, 128, kernel_size=3, padding=1),
VAE_ResidualBlock(128, 128),
VAE_ResidualBlock(128, 128),
# (Batch_Size, 128, Height, Width) -> (Batch_Size, 128, Height / 2, Width / 2)
nn.Conv2d(128, 128, kernel_size=3, stride=2, padding=0),
# (Batch_Size, 128, Height / 2, Width / 2) -> (Batch_Size, 256, Height / 2, Width / 2)
VAE_ResidualBlock(128, 256),
VAE_ResidualBlock(256, 256),
# (Batch_Size, 256, Height / 2, Width / 2) -> (Batch_Size, 256, Height / 4, Width / 4)
nn.Conv2d(256, 256, kernel_size=3, stride=2, padding=0),
# (Batch_Size, 256, Height / 4, Width / 4) -> (Batch_Size, 512, Height / 4, Width / 4)
VAE_ResidualBlock(256, 512),
VAE_ResidualBlock(512, 512),
# (Batch_Size, 512, Height / 4, Width / 4) -> (Batch_Size, 512, Height / 8, Width / 8)
nn.Conv2d(512, 512, kernel_size=3, stride=2, padding=0),
VAE_ResidualBlock(512, 512),
VAE_ResidualBlock(512, 512),
VAE_ResidualBlock(512, 512),
VAE_AttentionBlock(512),
VAE_ResidualBlock(512, 512),
nn.GroupNorm(32, 512),
nn.SiLU(),
# (Batch_Size, 512, Height / 8, Width / 8) -> (Batch_Size, 8, Height / 8, Width / 8).
nn.Conv2d(512, 8, kernel_size=3, padding=1),
# (Batch_Size, 8, Height / 8, Width / 8) -> (Batch_Size, 8, Height / 8, Width / 8)
nn.Conv2d(8, 8, kernel_size=1, padding=0),
)我认为学习该序列,抓住一些本质以及大局观即可:
首先,明确目标是要让图像尺寸变小。过程中是先增加通道,之后再减少通道。基本的过程就为,用Conv2d减少尺寸,之后跟上两个残差卷积块增加深度但保持尺寸。
具体而言,第一个Conv2d,改变通道,保持尺寸,然后两个残差,不改变尺寸。
之后Conv2d的用途为保持通道,减半尺寸,然后两个残差,一个用于增多通道,一个保持。直到通道达到512,此时后一个Conv2d将尺寸变为 Height / 8, Width / 8。之后引入三个残差保持尺寸。
之后引入了注意力模块,接一个残差,然后有组归一化GroupNorm【组归一化其类似于layer normalization。但是并不是所有特征共用一个mean与variance。而是将feature分组,由每组自身的mean与variance对改组进行normalization】以及SiLU激活。
最后两个卷积,一个减少通道至8,保持尺寸,另一个保持通道8以及尺寸,作为最后一层的表达。
一些具体实现的说明:
首先遍历module的代码为:
def forward(self, x, noise):
# x: (Batch_Size, Channel, Height, Width)
# noise: (Batch_Size, 4, Height / 8, Width / 8)
for module in self:
if getattr(module, 'stride', None) == (2, 2): # Padding at downsampling should be asymmetric (see #8)
x = F.pad(x, (0, 1, 0, 1))
x = module(x)可以看出,stride=2的Conv2d会在卷积前对特征图进行非对称的填充,以保证尺寸能正常减半。
其次,其中的注意力模块,在之前论述过,在这里,其就是一个单头的自注意力的实现:
class VAE_AttentionBlock(nn.Module):
def __init__(self, channels):
super().__init__()
self.groupnorm = nn.GroupNorm(32, channels)
self.attention = SelfAttention(1, channels)
def forward(self, x):
# x: (Batch_Size, Features, Height, Width)
residue = x
x = self.groupnorm(x)
n, c, h, w = x.shape
# (Batch_Size, Features, Height, Width) -> (Batch_Size, Features, Height * Width)
x = x.view((n, c, h * w))
# (Batch_Size, Features, Height * Width) -> (Batch_Size, Height * Width, Features).
# Each pixel becomes a feature of size "Features", the sequence length is "Height * Width".
x = x.transpose(-1, -2)
x = self.attention(x)
# (Batch_Size, Height * Width, Features) -> (Batch_Size, Features, Height * Width)
x = x.transpose(-1, -2)
# (Batch_Size, Features, Height * Width) -> (Batch_Size, Features, Height, Width)
x = x.view((n, c, h, w))
x += residue
return x这里的residual模块也比较简单,即包含两层组归一化、silu激活、卷积。以及典型的保证残差连接正常(即residue与最后的x通道维度保持一致)的residual_layer。
class VAE_ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.groupnorm_1 = nn.GroupNorm(32, in_channels)
self.conv_1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)
self.groupnorm_2 = nn.GroupNorm(32, out_channels)
self.conv_2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
if in_channels == out_channels:
self.residual_layer = nn.Identity()
else:
self.residual_layer = nn.Conv2d(in_channels, out_channels, kernel_size=1, padding=0)
def forward(self, x):
residue = x
x = self.groupnorm_1(x)
x = F.silu(x)
x = self.conv_1(x)
x = self.groupnorm_2(x)
x = F.silu(x)
x = self.conv_2(x)
return x + self.residual_layer(residue)到此我们实现到了pipeline的这一步:
# (Batch_Size, 4, Latents_Height, Latents_Width)
encoder_noise = torch.randn(latents_shape, generator=generator, device=device)
# (Batch_Size, 4, Latents_Height, Latents_Width)
latents = encoder(input_image_tensor, encoder_noise)在图文图的情况下,已经将original image转换为latents,现在我们需要向其添加噪声了。
# Add noise to the latents (the encoded input image)
# (Batch_Size, 4, Latents_Height, Latents_Width)
sampler.set_strength(strength=strength)
latents = sampler.add_noise(latents, sampler.timesteps[0])而这里的sampler_name也是generate的一个传参,且:
if sampler_name == "ddpm":
sampler = DDPMSampler(generator)
sampler.set_inference_timesteps(n_inference_steps)
else:
raise ValueError("Unknown sampler value %s. ")那我们首先得来看这个
DDPMSampler:
扩散模型的基本原理是将一个真实的图像逐渐加上噪声,直到它变成纯噪声,然后再通过反向过程(逆向扩散)逐步去除噪声,恢复出原始图像。DDPMSampler类实现了这个过程。
我们先给出完整的DDPMSampler类的代码:
class DDPMSampler:
def __init__(self, generator: torch.Generator, num_training_steps=1000, beta_start: float = 0.00085, beta_end: float = 0.0120):
# Params "beta_start" and "beta_end" taken from: https://github.com/CompVis/stable-diffusion/blob/21f890f9da3cfbeaba8e2ac3c425ee9e998d5229/configs/stable-diffusion/v1-inference.yaml#L5C8-L5C8
# For the naming conventions, refer to the DDPM paper (https://arxiv.org/pdf/2006.11239.pdf)
self.betas = torch.linspace(beta_start ** 0.5, beta_end ** 0.5, num_training_steps, dtype=torch.float32) ** 2
self.alphas = 1.0 - self.betas
self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
self.one = torch.tensor(1.0)
self.generator = generator
self.num_train_timesteps = num_training_steps
self.timesteps = torch.from_numpy(np.arange(0, num_training_steps)[::-1].copy())
# 是否这样即可 self.timesteps = torch.arange(num_training_steps - 1, -1, -1) # 生成倒序张量
def set_inference_timesteps(self, num_inference_steps=50):
self.num_inference_steps = num_inference_steps
step_ratio = self.num_train_timesteps // self.num_inference_steps
self.timesteps = (torch.arange(num_inference_steps - 1, -1, -1) * step_ratio).long()
def _get_previous_timestep(self, timestep: int) -> int:
prev_t = timestep - self.num_train_timesteps // self.num_inference_steps
return prev_t
def _get_variance(self, timestep: int) -> torch.Tensor:
prev_t = self._get_previous_timestep(timestep)
alpha_prod_t = self.alphas_cumprod[timestep]
alpha_prod_t_prev = self.alphas_cumprod[prev_t] if prev_t >= 0 else self.one
current_beta_t = 1 - alpha_prod_t / alpha_prod_t_prev
# For t > 0, compute predicted variance βt (see formula (6) and (7) from https://arxiv.org/pdf/2006.11239.pdf)
# and sample from it to get previous sample
# x_{t-1} ~ N(pred_prev_sample, variance) == add variance to pred_sample
variance = (1 - alpha_prod_t_prev) / (1 - alpha_prod_t) * current_beta_t
# we always take the log of variance, so clamp it to ensure it's not 0
variance = torch.clamp(variance, min=1e-20)
return variance
def set_strength(self, strength=1):
"""
Set how much noise to add to the input image.
More noise (strength ~ 1) means that the output will be further from the input image.
Less noise (strength ~ 0) means that the output will be closer to the input image.
"""
# start_step is the number of noise levels to skip
start_step = self.num_inference_steps - int(self.num_inference_steps * strength)
self.timesteps = self.timesteps[start_step:]
self.start_step = start_step
def step(self, timestep: int, latents: torch.Tensor, model_output: torch.Tensor):
t = timestep
prev_t = self._get_previous_timestep(t)
# 1. compute alphas, betas
alpha_prod_t = self.alphas_cumprod[t]
alpha_prod_t_prev = self.alphas_cumprod[prev_t] if prev_t >= 0 else self.one
beta_prod_t = 1 - alpha_prod_t
beta_prod_t_prev = 1 - alpha_prod_t_prev
current_alpha_t = alpha_prod_t / alpha_prod_t_prev
current_beta_t = 1 - current_alpha_t
# 2. compute predicted original sample from predicted noise also called
# "predicted x_0" of formula (15) from https://arxiv.org/pdf/2006.11239.pdf
pred_original_sample = (latents - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
# 4. Compute coefficients for pred_original_sample x_0 and current sample x_t
# See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
pred_original_sample_coeff = (alpha_prod_t_prev ** (0.5) * current_beta_t) / beta_prod_t
current_sample_coeff = current_alpha_t ** (0.5) * beta_prod_t_prev / beta_prod_t
# 5. Compute predicted previous sample µ_t
# See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
pred_prev_sample = pred_original_sample_coeff * pred_original_sample + current_sample_coeff * latents
# 6. Add noise
variance = 0
if t > 0:
noise = torch.randn(model_output.shape, generator=self.generator, device=model_output.device, dtype=model_output.dtype)
variance = (self._get_variance(t) ** 0.5) * noise
pred_prev_sample = pred_prev_sample + variance
return pred_prev_sample
def add_noise(self,original_samples: torch.FloatTensor,timesteps: torch.IntTensor,) -> torch.FloatTensor:
alphas_cumprod = self.alphas_cumprod.to(device=original_samples.device, dtype=original_samples.dtype)
timesteps = timesteps.to(original_samples.device)
sqrt_alpha_prod = alphas_cumprod[timesteps] ** 0.5
sqrt_alpha_prod = sqrt_alpha_prod.flatten()
while len(sqrt_alpha_prod.shape) < len(original_samples.shape):
sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)
sqrt_one_minus_alpha_prod = (1 - alphas_cumprod[timesteps]) ** 0.5
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
while len(sqrt_one_minus_alpha_prod.shape) < len(original_samples.shape):
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)
# Sample from q(x_t | x_0) as in equation (4) of https://arxiv.org/pdf/2006.11239.pdf
# Because N(mu, sigma) = X can be obtained by X = mu + sigma * N(0, 1)
# here mu = sqrt_alpha_prod * original_samples and sigma = sqrt_one_minus_alpha_prod
noise = torch.randn(original_samples.shape, generator=self.generator, device=original_samples.device, dtype=original_samples.dtype)
noisy_samples = sqrt_alpha_prod * original_samples + sqrt_one_minus_alpha_prod * noise
return noisy_samples我们先不看其他方法,来看看init中创建了什么:
def __init__(self, generator: torch.Generator, num_training_steps=1000, beta_start: float = 0.00085, beta_end: float = 0.0120):
# Params "beta_start" and "beta_end" taken from: https://github.com/CompVis/stable-diffusion/blob/21f890f9da3cfbeaba8e2ac3c425ee9e998d5229/configs/stable-diffusion/v1-inference.yaml#L5C8-L5C8
# For the naming conventions, refer to the DDPM paper (https://arxiv.org/pdf/2006.11239.pdf)
self.betas = torch.linspace(beta_start ** 0.5, beta_end ** 0.5, num_training_steps, dtype=torch.float32) ** 2
self.alphas = 1.0 - self.betas
self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
self.one = torch.tensor(1.0)
self.generator = generator
self.num_train_timesteps = num_training_steps
self.timesteps = torch.arange(num_training_steps - 1, -1, -1) # 生成倒序张量这里的β是指,DDPM forward时每一步所加的噪声的方差,如DDPM论文中所述:
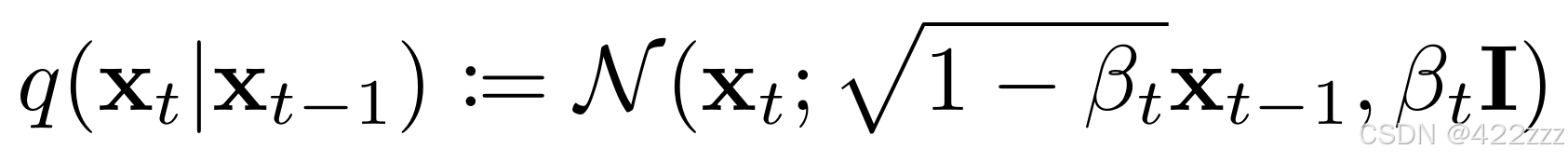
而这种β的序列,在确定起始β与结束β后,又有不同的变化schedule可以选,如余弦,线性等schedule,这里利用linear schedule。因为设定了一共处理多少步,再给定起始β与结束β,即可得到β schedule:
这里使用了num_training_steps=1000, beta_start: float = 0.00085, beta_end: float = 0.0120
而实际上,这个schedule是针对标准差的:
self.betas = torch.linspace(beta_start ** 0.5, beta_end ** 0.5, num_training_steps, dtype=torch.float32) ** 2为什么前期加的噪声小,后前加的噪声多?因为噪声较小,模型可以较容易地学习到数据的结构,后期加噪多是为了加速扩散过程,使得模型能够更快地从噪声中恢复出清晰的数据。
而在真正使用时,我们会引入α(这里累乘操作,用torch.cumprod可以轻松实现):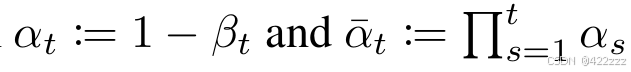
在引入α之后,我们就不再需要一步一步按顺序用β来处理图像了,例如加噪我们可以直接:
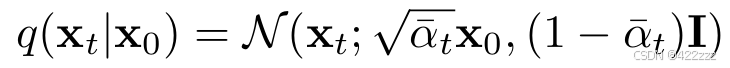
之后我们还是只看目前遇到的需要用的方法,sampler.set_inference_timesteps(n_inference_steps):
def set_inference_timesteps(self, num_inference_steps=50):
self.num_inference_steps = num_inference_steps
step_ratio = self.num_train_timesteps // self.num_inference_steps
self.timesteps = (torch.arange(num_inference_steps - 1, -1, -1) * step_ratio).long()这个方法的意图为重新创建timesteps。主要目的是在推理(或生成)阶段设置扩散过程的时间步数,从而控制反向扩散过程的细节和生成图像的质量。相当于是,训练的时候模型学的是怎么样去噪1000次,而得到无噪声图像,但是我们实际在推理时,不需要这么多步就可以得到很好的效果。以推理50步来生成为例,我们只需要让模型对图像进行第1000次去噪,第980次去噪,第960次去噪...直到第0次去噪即可,而不需要第999,998,997等次的去噪。
之后我们遇到了sampler.set_strength和sampler.add_noise。
# Add noise to the latents (the encoded input image)
# (Batch_Size, 4, Latents_Height, Latents_Width)
sampler.set_strength(strength=strength)
latents = sampler.add_noise(latents, sampler.timesteps[0])sampler.set_strength其的含义是,如果我不希望模型的输出太偏离我给定的original image,那么我当然只能给original image的latent少加点noise,减少去噪扩撒推理时的灵活性。
如果没有set_strength,之前我们的timestep是[50,49,48..0]->[1000,980,960…0],也就是一开始的噪声加的是time1000时的噪声,这个噪声很大。
而若此时set_strength处理:
def set_strength(self, strength=1):
"""
Set how much noise to add to the input image.
More noise (strength ~ 1) means that the output will be further from the input image.
Less noise (strength ~ 0) means that the output will be closer to the input image.
"""
# start_step is the number of noise levels to skip
start_step = self.num_inference_steps - int(self.num_inference_steps * strength)
self.timesteps = self.timesteps[start_step:]
self.start_step = start_step若strength=0.8,则其把[50,49,48..0]->[40,39,38…0]
也就是[40,39,38…0]*(1000//50) == [800,780,760…0]
也就是现在,此步骤中加上的噪声是time800的噪声,噪声更少了。
因为注意到latents = sampler.add_noise(latents, sampler.timesteps[0]),为latent加上的噪声是与timesteps[0]对应的。那接下来再来看看add_noise方法:
def add_noise(self,original_samples: torch.FloatTensor,timesteps: torch.IntTensor,) -> torch.FloatTensor:
alphas_cumprod = self.alphas_cumprod.to(device=original_samples.device, dtype=original_samples.dtype)
timesteps = timesteps.to(original_samples.device)
sqrt_alpha_prod = alphas_cumprod[timesteps] ** 0.5
sqrt_alpha_prod = sqrt_alpha_prod.flatten()
while len(sqrt_alpha_prod.shape) < len(original_samples.shape):
sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)
sqrt_one_minus_alpha_prod = (1 - alphas_cumprod[timesteps]) ** 0.5
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
while len(sqrt_one_minus_alpha_prod.shape) < len(original_samples.shape):
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)
# Sample from q(x_t | x_0) as in equation (4) of https://arxiv.org/pdf/2006.11239.pdf
# Because N(mu, sigma) = X can be obtained by X = mu + sigma * N(0, 1)
# here mu = sqrt_alpha_prod * original_samples and sigma = sqrt_one_minus_alpha_prod
noise = torch.randn(original_samples.shape, generator=self.generator, device=original_samples.device, dtype=original_samples.dtype)
noisy_samples = sqrt_alpha_prod * original_samples + sqrt_one_minus_alpha_prod * noise
return noisy_samples首先由之前加噪声的闭式解可以看到,其是对原始图像加上一个噪声,该噪声是从对应的高斯分布中采样得来的。【实际上不是从目标高斯分布中直接采样,而是采样标准高斯分布,用均值与标准差将其处理为目标高斯分布】。
然后,先首先保证设备一致
alphas_cumprod = self.alphas_cumprod.to(device=original_samples.device, dtype=original_samples.dtype)
timesteps = timesteps.to(original_samples.device)之后得到均值和方差,且用while、unsqueeze,添加维度使之其与要融合的原始图像original_samples【注意这里用的是闭式解,是直接对原始图像加噪声,而不是马尔科夫链对上一步的输出图像加噪声】的维度数一致,保证可以正常广播:
sqrt_alpha_prod = alphas_cumprod[timesteps] ** 0.5
sqrt_alpha_prod = sqrt_alpha_prod.flatten()
while len(sqrt_alpha_prod.shape) < len(original_samples.shape):
sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)
sqrt_one_minus_alpha_prod = (1 - alphas_cumprod[timesteps]) ** 0.5
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
while len(sqrt_one_minus_alpha_prod.shape) < len(original_samples.shape):
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)
# Sample from q(x_t | x_0) as in equation (4) of https://arxiv.org/pdf/2006.11239.pdf
# Because N(mu, sigma) = X can be obtained by X = mu + sigma * N(0, 1)
# here mu = sqrt_alpha_prod * original_samples and sigma = sqrt_one_minus_alpha_prod
noise = torch.randn(original_samples.shape, generator=self.generator, device=original_samples.device, dtype=original_samples.dtype)
noisy_samples = sqrt_alpha_prod * original_samples + sqrt_one_minus_alpha_prod * noise
return noisy_samples到此,我们已经完成了VAE_Encoder的编写了,其实现了(若是图生图)将original image映射到latent,并向其中添加可控大小的噪声,从而控制diffusion的灵活性。
接下来老样子,把encoder转到idle_device,且若只要文生图的话,直接采样高斯噪声作为latent即可,下面重新回顾一遍encoder部分的代码吧:
if sampler_name == "ddpm":
sampler = DDPMSampler(generator)
sampler.set_inference_timesteps(n_inference_steps)
else:
raise ValueError("Unknown sampler value %s. ")
latents_shape = (1, 4, LATENTS_HEIGHT, LATENTS_WIDTH)
if input_image:
encoder = models["encoder"]
encoder.to(device)
input_image_tensor = input_image.resize((WIDTH, HEIGHT))
input_image_tensor = np.array(input_image_tensor)
input_image_tensor = torch.tensor(input_image_tensor, dtype=torch.float32, device=device)
input_image_tensor = rescale(input_image_tensor, (0, 255), (-1, 1))
# (Height, Width, Channel) -> (Batch_Size, Height, Width, Channel)
input_image_tensor = input_image_tensor.unsqueeze(0)
# (Batch_Size, Height, Width, Channel) -> (Batch_Size, Channel, Height, Width)
input_image_tensor = input_image_tensor.permute(0, 3, 1, 2)
# (Batch_Size, 4, Latents_Height, Latents_Width)
encoder_noise = torch.randn(latents_shape, generator=generator, device=device)
# (Batch_Size, 4, Latents_Height, Latents_Width)
latents = encoder(input_image_tensor, encoder_noise)
# Add noise to the latents (the encoded input image)
# (Batch_Size, 4, Latents_Height, Latents_Width)
sampler.set_strength(strength=strength)
latents = sampler.add_noise(latents, sampler.timesteps[0])
to_idle(encoder)
else:
# (Batch_Size, 4, Latents_Height, Latents_Width)
latents = torch.randn(latents_shape, generator=generator, device=device)那接下来就到了
Diffusion:
完整代码为:
diffusion = models["diffusion"]
diffusion.to(device)
timesteps = tqdm(sampler.timesteps)
for i, timestep in enumerate(timesteps):
# (1, 320)
time_embedding = get_time_embedding(timestep).to(device)
# (Batch_Size, 4, Latents_Height, Latents_Width)
model_input = latents
if do_cfg:
# (Batch_Size, 4, Latents_Height, Latents_Width) -> (2 * Batch_Size, 4, Latents_Height, Latents_Width)
model_input = model_input.repeat(2, 1, 1, 1)
# model_output is the predicted noise
# (Batch_Size, 4, Latents_Height, Latents_Width) -> (Batch_Size, 4, Latents_Height, Latents_Width)
model_output = diffusion(model_input, context, time_embedding)
if do_cfg:
output_cond, output_uncond = model_output.chunk(2)
model_output = cfg_scale * (output_cond - output_uncond) + output_uncond
# (Batch_Size, 4, Latents_Height, Latents_Width) -> (Batch_Size, 4, Latents_Height, Latents_Width)
latents = sampler.step(timestep, latents, model_output)
to_idle(diffusion)首先老样子读取diffusion的模型,之后将timesteps创建一个进度条,来显示当前的diffusion进度。
diffusion = models["diffusion"]
diffusion.to(device)
timesteps = tqdm(sampler.timesteps)之后就是遍历timesteps,一步步对输入的latent进行去噪:
每一步去噪,有如下几个小步骤,首先,要明确当前的time是第几步,这里会对timestep进行一个time embedding: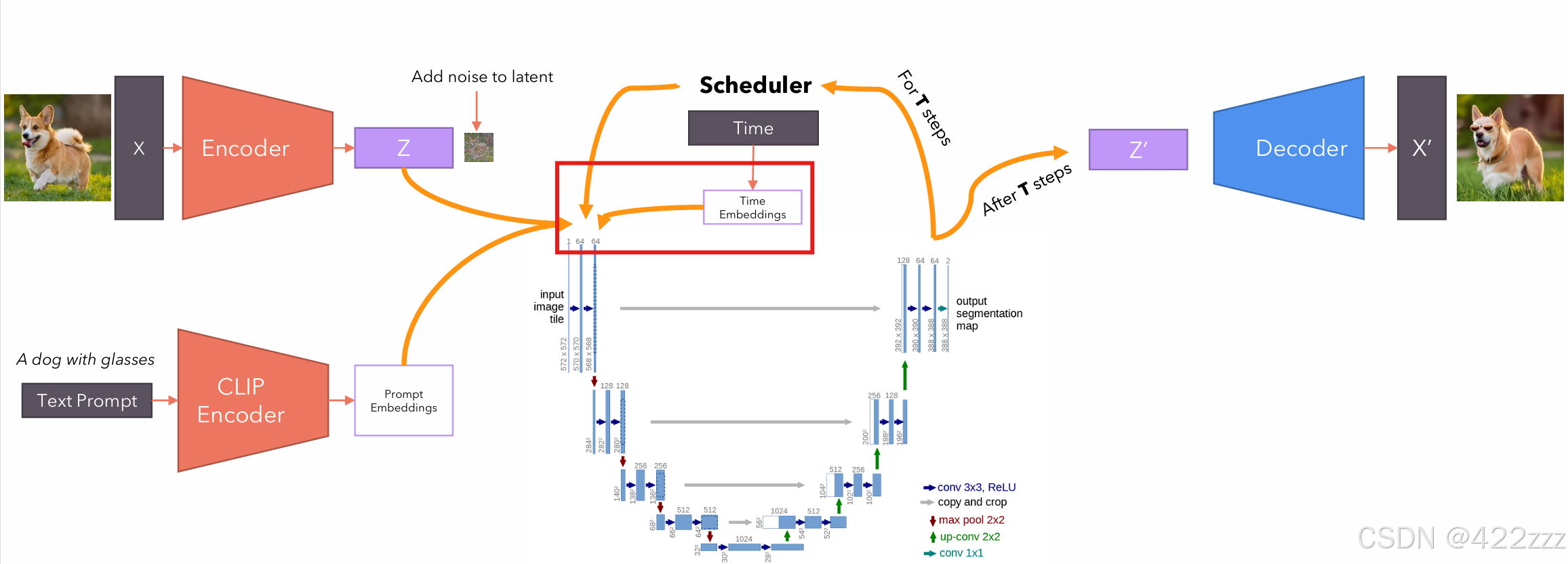
def get_time_embedding(timestep):
# Shape: (160,)
freqs = torch.pow(10000, -torch.arange(start=0, end=160, dtype=torch.float32) / 160)
# Shape: (1, 160)
x = torch.tensor([timestep], dtype=torch.float32)[:, None] * freqs[None]
# Shape: (1, 160 * 2)
return torch.cat([torch.cos(x), torch.sin(x)], dim=-1)得到time embedding之后,因为如果要do_cfg的话,之前其的context是有prompt的latent和无prompt的context cat到一起的,所以这里为了匹配维度,将其可以一起计算,所以这个VAE_Encoder的输出,在do_cfg的模式下,需要被repeat:
model_input = latents
if do_cfg:
# (Batch_Size, 4, Latents_Height, Latents_Width) -> (2 * Batch_Size, 4, Latents_Height, Latents_Width)
model_input = model_input.repeat(2, 1, 1, 1)
之后就是把model_input,context以及time_embedding一起输入给diffusion,让其预测当前图像,在当前时间步时,应该被去掉的噪声是什么样的。
# model_output is the predicted noise
# (Batch_Size, 4, Latents_Height, Latents_Width) -> (Batch_Size, 4, Latents_Height, Latents_Width)
model_output = diffusion(model_input, context, time_embedding)那么接下来来看看
diffusion(UNET):
来看diffusion类的定义:
class Diffusion(nn.Module):
def __init__(self):
super().__init__()
self.time_embedding = TimeEmbedding(320)
self.unet = UNET()
self.final = UNET_OutputLayer(320, 4)
def forward(self, latent, context, time):
# latent: (Batch_Size, 4, Height / 8, Width / 8)
# context: (Batch_Size, Seq_Len, Dim)
# time: (1, 320)
# (1, 320) -> (1, 1280)
time = self.time_embedding(time)
# (Batch, 4, Height / 8, Width / 8) -> (Batch, 320, Height / 8, Width / 8)
output = self.unet(latent, context, time)
# (Batch, 320, Height / 8, Width / 8) -> (Batch, 4, Height / 8, Width / 8)
output = self.final(output)
# (Batch, 4, Height / 8, Width / 8)
return output首先,之前已经对当前timestep做了一次正余弦的编码了:
time_embedding = get_time_embedding(timestep).to(device)这里又把time_embedding再次输入到TimeEmbedding函数中继续映射,代码为:
class TimeEmbedding(nn.Module):
def __init__(self, n_embd):
super().__init__()
self.linear_1 = nn.Linear(n_embd, 4 * n_embd)
self.linear_2 = nn.Linear(4 * n_embd, 4 * n_embd)
def forward(self, x):
# x: (1, 320)
# (1, 320) -> (1, 1280)
x = self.linear_1(x)
x = F.silu(x)
x = self.linear_2(x)
return x因为类似于transformer的位置编码,第一步time embedding是固定值,这里在使用前,重新来一次可学习的编码,用两层全连接以及silu激活,以获得更有效的时间嵌入表达。
得到time表达后,就正式进入UNET:
首先明确UNET的目标是根据当前latent以及时间步以及prompt,预测此时需要被去除的噪声。
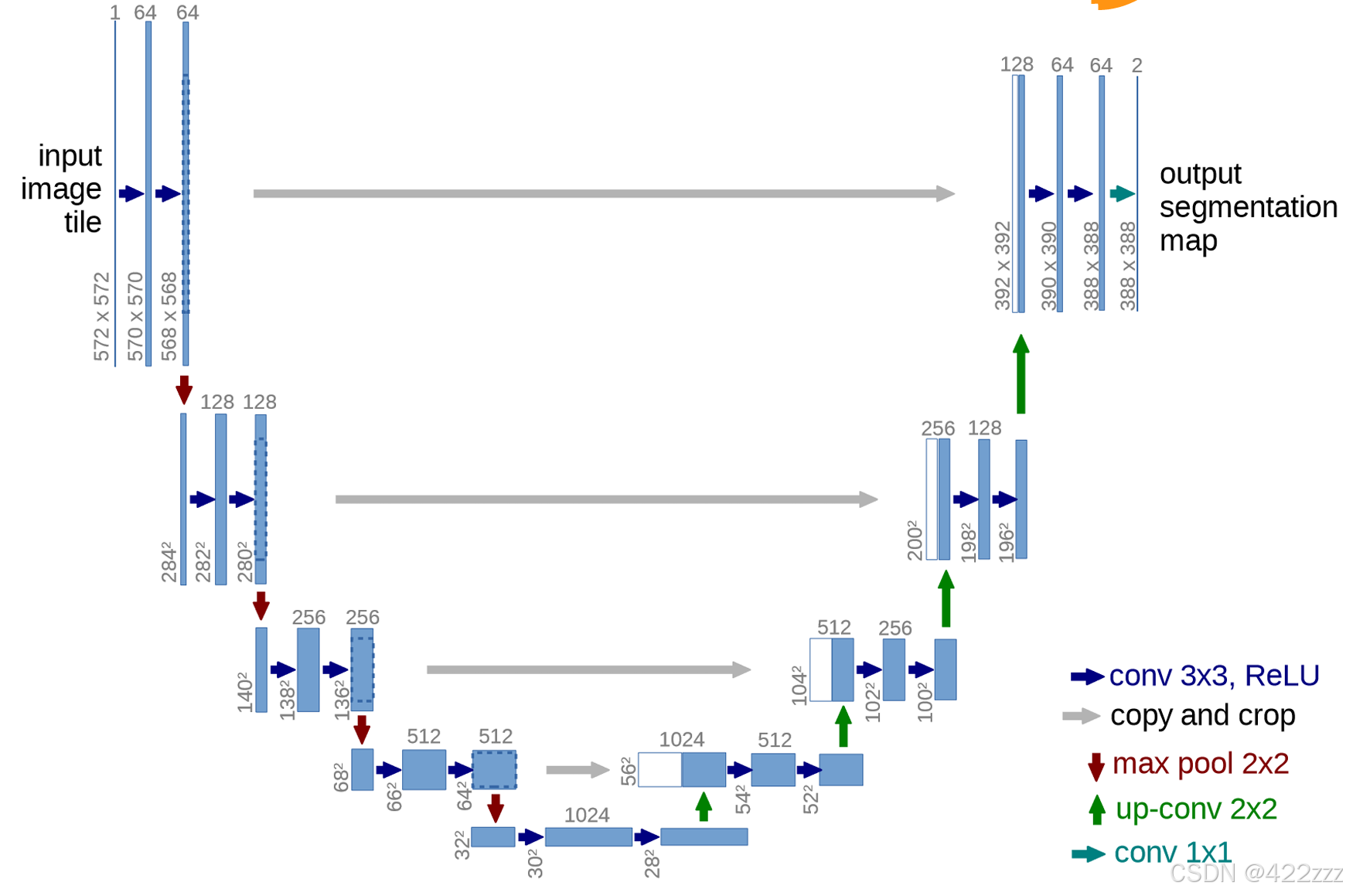
观察UNET的流程图可以发现,其还可以被分为三个小部分,encoder,bottleneck,decoder。
其次还有一点显著的特点,每一层对应的encoder和decoder之间都有残差连接。
所以UNET的forward可以如下:
def forward(self, x, context, time):
# x: (Batch_Size, 4, Height / 8, Width / 8)
# context: (Batch_Size, Seq_Len, Dim)
# time: (1, 1280)
skip_connections = []
for layers in self.encoders:
x = layers(x, context, time)
skip_connections.append(x)
x = self.bottleneck(x, context, time)
for layers in self.decoders:
# Since we always concat with the skip connection of the encoder, the number of features increases before being sent to the decoder's layer
x = torch.cat((x, skip_connections.pop()), dim=1)
x = layers(x, context, time)
return x接着来看encoders:
self.encoders = nn.ModuleList([
# (Batch_Size, 4, Height / 8, Width / 8) -> (Batch_Size, 320, Height / 8, Width / 8)
SwitchSequential(nn.Conv2d(4, 320, kernel_size=3, padding=1)),
SwitchSequential(UNET_ResidualBlock(320, 320), UNET_AttentionBlock(8, 40)),
SwitchSequential(UNET_ResidualBlock(320, 320), UNET_AttentionBlock(8, 40)),
# (Batch_Size, 320, Height / 8, Width / 8) -> (Batch_Size, 320, Height / 16, Width / 16)
SwitchSequential(nn.Conv2d(320, 320, kernel_size=3, stride=2, padding=1)),
# (Batch_Size, 320, Height / 16, Width / 16) -> (Batch_Size, 640, Height / 16, Width / 16) -> (Batch_Size, 640, Height / 16, Width / 16)
SwitchSequential(UNET_ResidualBlock(320, 640), UNET_AttentionBlock(8, 80)),
SwitchSequential(UNET_ResidualBlock(640, 640), UNET_AttentionBlock(8, 80)),
# (Batch_Size, 640, Height / 16, Width / 16) -> (Batch_Size, 640, Height / 32, Width / 32)
SwitchSequential(nn.Conv2d(640, 640, kernel_size=3, stride=2, padding=1)),
# (Batch_Size, 640, Height / 32, Width / 32) -> (Batch_Size, 1280, Height / 32, Width / 32) -> (Batch_Size, 1280, Height / 32, Width / 32)
SwitchSequential(UNET_ResidualBlock(640, 1280), UNET_AttentionBlock(8, 160)),
SwitchSequential(UNET_ResidualBlock(1280, 1280), UNET_AttentionBlock(8, 160)),
# (Batch_Size, 1280, Height / 32, Width / 32) -> (Batch_Size, 1280, Height / 64, Width / 64)
SwitchSequential(nn.Conv2d(1280, 1280, kernel_size=3, stride=2, padding=1)),
SwitchSequential(UNET_ResidualBlock(1280, 1280)),
SwitchSequential(UNET_ResidualBlock(1280, 1280)),
])注意到SwitchSequential,其实其很简单,就相当于为当前函数配置输入参数:
class SwitchSequential(nn.Sequential):
def forward(self, x, context, time):
for layer in self:
if isinstance(layer, UNET_AttentionBlock):
x = layer(x, context)
elif isinstance(layer, UNET_ResidualBlock):
x = layer(x, time)
else:
x = layer(x)
return x这里的residual,代码为:
class UNET_ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, n_time=1280):
super().__init__()
self.groupnorm_feature = nn.GroupNorm(32, in_channels)
self.conv_feature = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)
self.linear_time = nn.Linear(n_time, out_channels)
self.groupnorm_merged = nn.GroupNorm(32, out_channels)
self.conv_merged = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
if in_channels == out_channels:
self.residual_layer = nn.Identity()
else:
self.residual_layer = nn.Conv2d(in_channels, out_channels, kernel_size=1, padding=0)
def forward(self, feature, time):
# feature: (Batch_Size, In_Channels, Height, Width)
# time: (1, 1280)
residue = feature
feature = self.groupnorm_feature(feature)
feature = F.silu(feature)
# (Batch_Size, In_Channels, Height, Width) -> (Batch_Size, Out_Channels, Height, Width)
feature = self.conv_feature(feature)
time = F.silu(time)
# (1, 1280) -> (1, Out_Channels)
time = self.linear_time(time)
# Add width and height dimension to time.
# 广播(Batch_Size, Out_Channels, Height, Width) + (1, Out_Channels, 1, 1) -> (Batch_Size, Out_Channels, Height, Width)
merged = feature + time.unsqueeze(-1).unsqueeze(-1)
merged = self.groupnorm_merged(merged)
merged = F.silu(merged)
merged = self.conv_merged(merged)
return merged + self.residual_layer(residue)首先其将特征图保留residue,对齐组归一化、silu激活,并进行卷积。之后对time embedding做一个全连接层的变换表达,将其维度扩展到至于feature相同后,将两个相加混合在一起。再用组归一化、silu激活,以及再一个卷积操作得到merged。最后merged与残差residue=feature相加,作为该模块的返回。相当于是该模块实现了特征与时间步的混合。
还有一个为attention,代码为:
class UNET_AttentionBlock(nn.Module):
def __init__(self, n_head: int, n_embd: int, d_context=768):
super().__init__()
channels = n_head * n_embd
self.groupnorm = nn.GroupNorm(32, channels, eps=1e-6)
self.conv_input = nn.Conv2d(channels, channels, kernel_size=1, padding=0)
self.layernorm_1 = nn.LayerNorm(channels)
self.attention_1 = SelfAttention(n_head, channels, in_proj_bias=False)
self.layernorm_2 = nn.LayerNorm(channels)
self.attention_2 = CrossAttention(n_head, channels, d_context, in_proj_bias=False)
self.layernorm_3 = nn.LayerNorm(channels)
self.linear_geglu_1 = nn.Linear(channels, 4 * channels * 2)
self.linear_geglu_2 = nn.Linear(4 * channels, channels)
self.conv_output = nn.Conv2d(channels, channels, kernel_size=1, padding=0)
def forward(self, x, context):
# x: (Batch_Size, Features, Height, Width)
# context: (Batch_Size, Seq_Len, Dim)
residue_long = x
# (Batch_Size, Features, Height, Width) -> (Batch_Size, Features, Height, Width)
x = self.groupnorm(x)
# (Batch_Size, Features, Height, Width) -> (Batch_Size, Features, Height, Width)
x = self.conv_input(x)
n, c, h, w = x.shape
# (Batch_Size, Features, Height, Width) -> (Batch_Size, Features, Height * Width) -> (Batch_Size, Height * Width, Features)
x = x.view((n, c, h * w)).transpose(-1, -2)
# Normalization + Self-Attention with skip connection
# (Batch_Size, Height * Width, Features)
residue_short = x
# (Batch_Size, Height * Width, Features) -> (Batch_Size, Height * Width, Features)
x = self.layernorm_1(x)
# (Batch_Size, Height * Width, Features) -> (Batch_Size, Height * Width, Features)
x = self.attention_1(x)
# (Batch_Size, Height * Width, Features) + (Batch_Size, Height * Width, Features) -> (Batch_Size, Height * Width, Features)
x += residue_short
# (Batch_Size, Height * Width, Features)
residue_short = x
# Normalization + Cross-Attention with skip connection
# (Batch_Size, Height * Width, Features) -> (Batch_Size, Height * Width, Features)
x = self.layernorm_2(x)
# (Batch_Size, Height * Width, Features) -> (Batch_Size, Height * Width, Features)
x = self.attention_2(x, context)
# (Batch_Size, Height * Width, Features) + (Batch_Size, Height * Width, Features) -> (Batch_Size, Height * Width, Features)
x += residue_short
# (Batch_Size, Height * Width, Features)
residue_short = x
# Normalization + FFN with GeGLU and skip connection
# (Batch_Size, Height * Width, Features) -> (Batch_Size, Height * Width, Features)
x = self.layernorm_3(x)
# GeGLU as implemented in the original code: https://github.com/CompVis/stable-diffusion/blob/21f890f9da3cfbeaba8e2ac3c425ee9e998d5229/ldm/modules/attention.py#L37C10-L37C10
# (Batch_Size, Height * Width, Features) -> two tensors of shape (Batch_Size, Height * Width, Features * 4)
x, gate = self.linear_geglu_1(x).chunk(2, dim=-1)
# Element-wise product: (Batch_Size, Height * Width, Features * 4) * (Batch_Size, Height * Width, Features * 4) -> (Batch_Size, Height * Width, Features * 4)
x = x * F.gelu(gate)
# (Batch_Size, Height * Width, Features * 4) -> (Batch_Size, Height * Width, Features)
x = self.linear_geglu_2(x)
# (Batch_Size, Height * Width, Features) + (Batch_Size, Height * Width, Features) -> (Batch_Size, Height * Width, Features)
x += residue_short
# (Batch_Size, Height * Width, Features) -> (Batch_Size, Features, Height * Width)
x = x.transpose(-1, -2)
# (Batch_Size, Features, Height * Width) -> (Batch_Size, Features, Height, Width)
x = x.view((n, c, h, w))
# Final skip connection between initial input and output of the block
# (Batch_Size, Features, Height, Width) + (Batch_Size, Features, Height, Width) -> (Batch_Size, Features, Height, Width)
return self.conv_output(x) + residue_long首先一个前置的卷积,先把输入进来的x进行一次卷积重表达。
然后一个小的残差块,主体操作是做自注意力:
residue_short = x
# (Batch_Size, Height * Width, Features) -> (Batch_Size, Height * Width, Features)
x = self.layernorm_1(x)
# (Batch_Size, Height * Width, Features) -> (Batch_Size, Height * Width, Features)
x = self.attention_1(x)
# (Batch_Size, Height * Width, Features) + (Batch_Size, Height * Width, Features) -> (Batch_Size, Height * Width, Features)
x += residue_shortattention_1为无偏置的8头自注意力块,其使上一步中feature与time的混合进一步内部消化,自己找出相关性:
self.attention_1 = SelfAttention(n_head, channels, in_proj_bias=False)之后一个残差块,主体操作是做交叉注意力:
residue_short = x
# Normalization + Cross-Attention with skip connection
# (Batch_Size, Height * Width, Features) -> (Batch_Size, Height * Width, Features)
x = self.layernorm_2(x)
# (Batch_Size, Height * Width, Features) -> (Batch_Size, Height * Width, Features)
x = self.attention_2(x, context)
# (Batch_Size, Height * Width, Features) + (Batch_Size, Height * Width, Features) -> (Batch_Size, Height * Width, Features)
x += residue_shortattention_2为无偏置的8头交叉注意力块:
self.attention_2 = CrossAttention(n_head, channels, d_context, in_proj_bias=False)其内部为:
def __init__(self, n_heads, d_embed, d_cross, in_proj_bias=True, out_proj_bias=True):
super().__init__()
self.q_proj = nn.Linear(d_embed, d_embed, bias=in_proj_bias)
self.k_proj = nn.Linear(d_cross, d_embed, bias=in_proj_bias)
self.v_proj = nn.Linear(d_cross, d_embed, bias=in_proj_bias)
self.out_proj = nn.Linear(d_embed, d_embed, bias=out_proj_bias)
self.n_heads = n_heads
self.d_head = d_embed // n_heads
def forward(self, x, y):
# x (latent): # (Batch_Size, Seq_Len_Q, Dim_Q)
# y (context): # (Batch_Size, Seq_Len_KV, Dim_KV) = (Batch_Size, 77, 768)
input_shape = x.shape
batch_size, sequence_length, d_embed = input_shape
# Divide each embedding of Q into multiple heads such that d_heads * n_heads = Dim_Q
interim_shape = (batch_size, -1, self.n_heads, self.d_head)
# (Batch_Size, Seq_Len_Q, Dim_Q) -> (Batch_Size, Seq_Len_Q, Dim_Q)
q = self.q_proj(x)
# (Batch_Size, Seq_Len_KV, Dim_KV) -> (Batch_Size, Seq_Len_KV, Dim_Q)
k = self.k_proj(y)
# (Batch_Size, Seq_Len_KV, Dim_KV) -> (Batch_Size, Seq_Len_KV, Dim_Q)
v = self.v_proj(y)
# (Batch_Size, Seq_Len_Q, Dim_Q) -> (Batch_Size, Seq_Len_Q, H, Dim_Q / H) -> (Batch_Size, H, Seq_Len_Q, Dim_Q / H)
q = q.view(interim_shape).transpose(1, 2)
# (Batch_Size, Seq_Len_KV, Dim_Q) -> (Batch_Size, Seq_Len_KV, H, Dim_Q / H) -> (Batch_Size, H, Seq_Len_KV, Dim_Q / H)
k = k.view(interim_shape).transpose(1, 2)
# (Batch_Size, Seq_Len_KV, Dim_Q) -> (Batch_Size, Seq_Len_KV, H, Dim_Q / H) -> (Batch_Size, H, Seq_Len_KV, Dim_Q / H)
v = v.view(interim_shape).transpose(1, 2)
# (Batch_Size, H, Seq_Len_Q, Dim_Q / H) @ (Batch_Size, H, Dim_Q / H, Seq_Len_KV) -> (Batch_Size, H, Seq_Len_Q, Seq_Len_KV)
weight = q @ k.transpose(-1, -2)
# (Batch_Size, H, Seq_Len_Q, Seq_Len_KV)
weight /= math.sqrt(self.d_head)
# (Batch_Size, H, Seq_Len_Q, Seq_Len_KV)
weight = F.softmax(weight, dim=-1)
# (Batch_Size, H, Seq_Len_Q, Seq_Len_KV) @ (Batch_Size, H, Seq_Len_KV, Dim_Q / H) -> (Batch_Size, H, Seq_Len_Q, Dim_Q / H)
output = weight @ v
# (Batch_Size, H, Seq_Len_Q, Dim_Q / H) -> (Batch_Size, Seq_Len_Q, H, Dim_Q / H)
output = output.transpose(1, 2).contiguous()
# (Batch_Size, Seq_Len_Q, H, Dim_Q / H) -> (Batch_Size, Seq_Len_Q, Dim_Q)
output = output.view(input_shape)
# (Batch_Size, Seq_Len_Q, Dim_Q) -> (Batch_Size, Seq_Len_Q, Dim_Q)
output = self.out_proj(output)
# (Batch_Size, Seq_Len_Q, Dim_Q)
return output整体和自注意力都差不多,只是这里,上一个自注意力的输出(也就是上一个残差块在融合feature与time embedding之后其自身的自注意力矩阵)仅仅作为Q矩阵query查询,而之前由prompt得到的context会在此作为k与v,即key键与value值。相当于计算了当前latent在当前timestep,与prompt描述的目标之间的相关性。
这便组成了UNET中的encoders,再来看看中间的bottleneck,很简洁,即融合时间-计算自注意力-融合时间:
self.bottleneck = SwitchSequential(
UNET_ResidualBlock(1280, 1280),
UNET_AttentionBlock(8, 160),
UNET_ResidualBlock(1280, 1280),
)之后便是进入UET的decoder:
self.decoders = nn.ModuleList([
# (Batch_Size, 2560, Height / 64, Width / 64) -> (Batch_Size, 1280, Height / 64, Width / 64)
SwitchSequential(UNET_ResidualBlock(2560, 1280)),
# (Batch_Size, 2560, Height / 64, Width / 64) -> (Batch_Size, 1280, Height / 64, Width / 64)
SwitchSequential(UNET_ResidualBlock(2560, 1280)),
# (Batch_Size, 2560, Height / 64, Width / 64) -> (Batch_Size, 1280, Height / 64, Width / 64) -> (Batch_Size, 1280, Height / 32, Width / 32)
SwitchSequential(UNET_ResidualBlock(2560, 1280), Upsample(1280)),
# (Batch_Size, 2560, Height / 32, Width / 32) -> (Batch_Size, 1280, Height / 32, Width / 32) -> (Batch_Size, 1280, Height / 32, Width / 32)
SwitchSequential(UNET_ResidualBlock(2560, 1280), UNET_AttentionBlock(8, 160)),
# (Batch_Size, 2560, Height / 32, Width / 32) -> (Batch_Size, 1280, Height / 32, Width / 32) -> (Batch_Size, 1280, Height / 32, Width / 32)
SwitchSequential(UNET_ResidualBlock(2560, 1280), UNET_AttentionBlock(8, 160)),
# (Batch_Size, 1920, Height / 32, Width / 32) -> (Batch_Size, 1280, Height / 32, Width / 32) -> (Batch_Size, 1280, Height / 32, Width / 32) -> (Batch_Size, 1280, Height / 16, Width / 16)
SwitchSequential(UNET_ResidualBlock(1920, 1280), UNET_AttentionBlock(8, 160), Upsample(1280)),
# (Batch_Size, 1920, Height / 16, Width / 16) -> (Batch_Size, 640, Height / 16, Width / 16) -> (Batch_Size, 640, Height / 16, Width / 16)
SwitchSequential(UNET_ResidualBlock(1920, 640), UNET_AttentionBlock(8, 80)),
# (Batch_Size, 1280, Height / 16, Width / 16) -> (Batch_Size, 640, Height / 16, Width / 16) -> (Batch_Size, 640, Height / 16, Width / 16)
SwitchSequential(UNET_ResidualBlock(1280, 640), UNET_AttentionBlock(8, 80)),
# (Batch_Size, 960, Height / 16, Width / 16) -> (Batch_Size, 640, Height / 16, Width / 16) -> (Batch_Size, 640, Height / 16, Width / 16) -> (Batch_Size, 640, Height / 8, Width / 8)
SwitchSequential(UNET_ResidualBlock(960, 640), UNET_AttentionBlock(8, 80), Upsample(640)),
# (Batch_Size, 960, Height / 8, Width / 8) -> (Batch_Size, 320, Height / 8, Width / 8) -> (Batch_Size, 320, Height / 8, Width / 8)
SwitchSequential(UNET_ResidualBlock(960, 320), UNET_AttentionBlock(8, 40)),
# (Batch_Size, 640, Height / 8, Width / 8) -> (Batch_Size, 320, Height / 8, Width / 8) -> (Batch_Size, 320, Height / 8, Width / 8)
SwitchSequential(UNET_ResidualBlock(640, 320), UNET_AttentionBlock(8, 40)),
# (Batch_Size, 640, Height / 8, Width / 8) -> (Batch_Size, 320, Height / 8, Width / 8) -> (Batch_Size, 320, Height / 8, Width / 8)
SwitchSequential(UNET_ResidualBlock(640, 320), UNET_AttentionBlock(8, 40)),
])模组都对称,只不过这里有一个新的Upsample模块:
class Upsample(nn.Module):
def __init__(self, channels):
super().__init__()
self.conv = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
def forward(self, x):
# (Batch_Size, Features, Height, Width) -> (Batch_Size, Features, Height * 2, Width * 2)
x = F.interpolate(x, scale_factor=2, mode='nearest')
return self.conv(x)其实现也非常简单,简单的使用interpolate,做nearest模式的插值,使特征图尺寸翻倍,之后用一个卷积增强表达即可。
到此,已经完成了如下代码:
output = self.unet(latent, context, time)此时维度与所需不符,需要来一个final层控制输出维度:
# (Batch, 320, Height / 8, Width / 8) -> (Batch, 4, Height / 8, Width / 8)
output = self.final(output)final为:
self.final = UNET_OutputLayer(320, 4)class UNET_OutputLayer(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.groupnorm = nn.GroupNorm(32, in_channels)
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)
def forward(self, x):
# x: (Batch_Size, 320, Height / 8, Width / 8)
# (Batch_Size, 320, Height / 8, Width / 8) -> (Batch_Size, 320, Height / 8, Width / 8)
x = self.groupnorm(x)
# (Batch_Size, 320, Height / 8, Width / 8) -> (Batch_Size, 320, Height / 8, Width / 8)
x = F.silu(x)
# (Batch_Size, 320, Height / 8, Width / 8) -> (Batch_Size, 4, Height / 8, Width / 8)
x = self.conv(x)
# (Batch_Size, 4, Height / 8, Width / 8)
return x其就是简单的组归一化后silu激活,用一层卷积来改变通道数即可。
到此我们正式完成了当前噪声的预测:
model_output = diffusion(model_input, context, time_embedding)但是若要do_cfg,因为输入相当于batch为2,一个是用prompt一个是不用prompt,且最终输出为:
所以会有如下处理:
if do_cfg:
output_cond, output_uncond = model_output.chunk(2)
model_output = cfg_scale * (output_cond - output_uncond) + output_uncond至此model_output真正得到了对当前latent中噪声的预测。
接着就是对latent去掉噪声model_output:
latents = sampler.step(timestep, latents, model_output)我们来看DDPMSampler的step:
def step(self, timestep: int, latents: torch.Tensor, model_output: torch.Tensor):
t = timestep
prev_t = self._get_previous_timestep(t)
# 1. compute alphas, betas
alpha_prod_t = self.alphas_cumprod[t]
alpha_prod_t_prev = self.alphas_cumprod[prev_t] if prev_t >= 0 else self.one
beta_prod_t = 1 - alpha_prod_t
beta_prod_t_prev = 1 - alpha_prod_t_prev
current_alpha_t = alpha_prod_t / alpha_prod_t_prev
current_beta_t = 1 - current_alpha_t
# 2. compute predicted original sample from predicted noise also called
# "predicted x_0" of formula (15) from https://arxiv.org/pdf/2006.11239.pdf
pred_original_sample = (latents - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
# 4. Compute coefficients for pred_original_sample x_0 and current sample x_t
# See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
pred_original_sample_coeff = (alpha_prod_t_prev ** (0.5) * current_beta_t) / beta_prod_t
current_sample_coeff = current_alpha_t ** (0.5) * beta_prod_t_prev / beta_prod_t
# 5. Compute predicted previous sample µ_t
# See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
pred_prev_sample = pred_original_sample_coeff * pred_original_sample + current_sample_coeff * latents
# 6. Add noise
variance = 0
if t > 0:
noise = torch.randn(model_output.shape, generator=self.generator, device=model_output.device, dtype=model_output.dtype)
variance = (self._get_variance(t) ** 0.5) * noise
pred_prev_sample = pred_prev_sample + variance
return pred_prev_sample首先我们来明确去噪的公式,首先论文中提出了两种公式来去噪:
第一种:

第二种为:
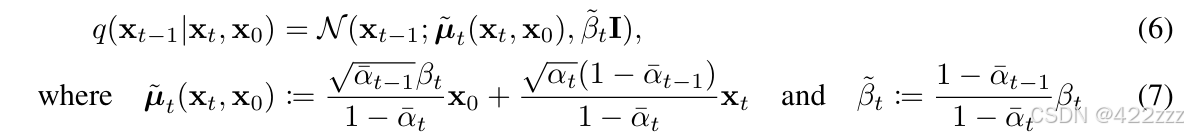
其中这里的x0不是真实的original image,而是我们预测的其可能的原始图像,且有如下公式:
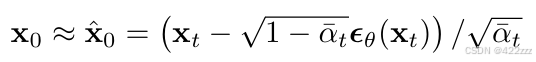
所以可以理解为去噪后的latent是目前的latent与预测的原始无噪声latent的之间的线性组合。
我们在这选择第二种实现方法:
首先我们要得到上一个时刻t-1时的α相关值:
t = timestep
prev_t = self._get_previous_timestep(t)def _get_previous_timestep(self, timestep: int) -> int:
prev_t = timestep - self.num_train_timesteps // self.num_inference_steps
return prev_t # 1. compute alphas, betas
alpha_prod_t = self.alphas_cumprod[t]
alpha_prod_t_prev = self.alphas_cumprod[prev_t] if prev_t >= 0 else self.one
beta_prod_t = 1 - alpha_prod_t
beta_prod_t_prev = 1 - alpha_prod_t_prev
current_alpha_t = alpha_prod_t / alpha_prod_t_prev
current_beta_t = 1 - current_alpha_t然后我们需要取计算 预测的无噪声的latent,直接带公式即可:
pred_original_sample = (latents - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)接着因为是原始与当前的线性组合,两者的系数需要计算:
pred_original_sample_coeff = (alpha_prod_t_prev ** (0.5) * current_beta_t) / beta_prod_t
current_sample_coeff = current_alpha_t ** (0.5) * beta_prod_t_prev / beta_prod_t pred_prev_sample = pred_original_sample_coeff * pred_original_sample + current_sample_coeff * latents要注意这只是去噪后的latent的mean的表达,最后还有加上variance,所以:
# 6. Add noise
variance = 0
if t > 0:
noise = torch.randn(model_output.shape, generator=self.generator, device=model_output.device, dtype=model_output.dtype)
variance = (self._get_variance(t) ** 0.5) * noise
pred_prev_sample = pred_prev_sample + variance
return pred_prev_sample其中get_variance为:
def _get_variance(self, timestep: int) -> torch.Tensor:
prev_t = self._get_previous_timestep(timestep)
alpha_prod_t = self.alphas_cumprod[timestep]
alpha_prod_t_prev = self.alphas_cumprod[prev_t] if prev_t >= 0 else self.one
current_beta_t = 1 - alpha_prod_t / alpha_prod_t_prev
# For t > 0, compute predicted variance βt (see formula (6) and (7) from https://arxiv.org/pdf/2006.11239.pdf)
# and sample from it to get previous sample
# x_{t-1} ~ N(pred_prev_sample, variance) == add variance to pred_sample
variance = (1 - alpha_prod_t_prev) / (1 - alpha_prod_t) * current_beta_t
# we always take the log of variance, so clamp it to ensure it's not 0
variance = torch.clamp(variance, min=1e-20)
return variance其也是按公式创建即可,且最终用clamp也最小值限制在1e-20.
所以此时我们已经得到了pred_prev_sample,所以循环
timesteps = tqdm(sampler.timesteps)
for i, timestep in enumerate(timesteps):
...
latents = sampler.step(timestep, latents, model_output)会得到最终的预测的无噪声的latent。到此我们diffusion部分就结束了,将其移到idle_device:
to_idle(diffusion)下一步,我们就只剩
VAE_decoder:
把latent映射回图像了:
decoder = models["decoder"]
decoder.to(device)
# (Batch_Size, 4, Latents_Height, Latents_Width) -> (Batch_Size, 3, Height, Width)
images = decoder(latents)
to_idle(decoder)来看看decoder其forward:
def forward(self, x):
# x: (Batch_Size, 4, Height / 8, Width / 8)
# Remove the scaling added by the Encoder.
x /= 0.18215
for module in self:
x = module(x)
# (Batch_Size, 3, Height, Width)
return x首先,因为encoder时处于工程原因,回对latent进行x *= 0.18215的缩小,这里进入decoder module前先将其放大回来 x /= 0.18215,之后就是遍历module:
class VAE_Decoder(nn.Sequential):
def __init__(self):
super().__init__(
# (Batch_Size, 4, Height / 8, Width / 8) -> (Batch_Size, 4, Height / 8, Width / 8)
nn.Conv2d(4, 4, kernel_size=1, padding=0),
# (Batch_Size, 4, Height / 8, Width / 8) -> (Batch_Size, 512, Height / 8, Width / 8)
nn.Conv2d(4, 512, kernel_size=3, padding=1),
VAE_ResidualBlock(512, 512),
VAE_AttentionBlock(512),
VAE_ResidualBlock(512, 512),
VAE_ResidualBlock(512, 512),
VAE_ResidualBlock(512, 512),
VAE_ResidualBlock(512, 512),
# (Batch_Size, 512, Height / 8, Width / 8) -> (Batch_Size, 512, Height / 4, Width / 4)
nn.Upsample(scale_factor=2),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
VAE_ResidualBlock(512, 512),
VAE_ResidualBlock(512, 512),
VAE_ResidualBlock(512, 512),
# (Batch_Size, 512, Height / 4, Width / 4) -> (Batch_Size, 512, Height / 2, Width / 2)
nn.Upsample(scale_factor=2),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
VAE_ResidualBlock(512, 256),
VAE_ResidualBlock(256, 256),
VAE_ResidualBlock(256, 256),
# (Batch_Size, 256, Height / 2, Width / 2) -> (Batch_Size, 256, Height, Width)
nn.Upsample(scale_factor=2),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
VAE_ResidualBlock(256, 128),
VAE_ResidualBlock(128, 128),
VAE_ResidualBlock(128, 128),
# (Batch_Size, 128, Height, Width) -> (Batch_Size, 128, Height, Width)
nn.GroupNorm(32, 128),
nn.SiLU(),
# (Batch_Size, 128, Height, Width) -> (Batch_Size, 3, Height, Width)
nn.Conv2d(128, 3, kernel_size=3, padding=1),
)所有模块都在之前介绍过了,而decoder的结构也与encoder对称,这里不再做重复的论述了。
最后,我们将decoder解码出的图像,重新表达为原始图像的存储格式:
images = rescale(images, (-1, 1), (0, 255), clamp=True)
# (Batch_Size, Channel, Height, Width) -> (Batch_Size, Height, Width, Channel)
images = images.permute(0, 2, 3, 1)
images = images.to("cpu", torch.uint8).numpy()
return images[0]到此,终于获得了想要的图像了!
最后的最后来写个demo运行整个逻辑:
import model_loader
import pipeline
from PIL import Image
from pathlib import Path
from transformers import CLIPTokenizer
import torch
DEVICE = "cpu"
ALLOW_CUDA = False
ALLOW_MPS = False
if torch.cuda.is_available() and ALLOW_CUDA:
DEVICE = "cuda"
elif (torch.has_mps or torch.backends.mps.is_available()) and ALLOW_MPS:
DEVICE = "mps"
print(f"Using device: {DEVICE}")
tokenizer = CLIPTokenizer("../data/tokenizer_vocab.json", merges_file="../data/tokenizer_merges.txt")
model_file = "../data/v1-5-pruned-emaonly.ckpt"
models = model_loader.preload_models_from_standard_weights(model_file, DEVICE)
## TEXT TO IMAGE
prompt = "A cat stretching on the floor, highly detailed, ultra sharp, cinematic, 8k resolution"
uncond_prompt = "" # Also known as negative prompt
do_cfg = True
cfg_scale = 8 # min: 1, max: 14
## IMAGE TO IMAGE
input_image = None
# Comment to disable image to image
image_path = "../images/yibo.jpg"
# input_image = Image.open(image_path)
# Higher values means more noise will be added to the input image, so the result will further from the input image.
# Lower values means less noise is added to the input image, so output will be closer to the input image.
strength = 0.9
## SAMPLER
sampler = "ddpm"
num_inference_steps = 50
seed = 42
output_image = pipeline.generate(
prompt=prompt,
uncond_prompt=uncond_prompt,
input_image=input_image,
strength=strength,
do_cfg=do_cfg,
cfg_scale=cfg_scale,
sampler_name=sampler,
n_inference_steps=num_inference_steps,
seed=seed,
models=models,
device=DEVICE,
idle_device="cpu",
tokenizer=tokenizer,
)
# Combine the input image and the output image into a single image.
Image.fromarray(output_image)最终,生成了文章封面的图像:

至此整个流程全部结束,撒花。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









