







0.LoFTR简介
Local Feature Transformers (LoFTR)是一种Detector-free的局部特征匹配方法,使用了具有自注意层和互注意层的Transformer模块来处理从卷积网络中提取的密集局部特征:首先在低特征分辨率(图像维度的1/8)上提取密集匹配,然后从这些匹配中选择具有高可信度的匹配,使用基于相关的方法将其细化到高分辨率的亚像素级别。这样,模型的大感受野使转换后的特征符能够体现出上下文和位置信息,通过多次自注意力和互注意层,LoFTR学习在GT中的匹配先验。另外,LOFTR还采用Linear Attention方法将计算复杂度降低到可接受的水平。
源码地址:https://github.com/zju3dv/LoFTR
论文下载地址:https://arxiv.org/pdf/2104.00680.pdf
在LoFTR之前的图像匹配算法中,都比较依赖于检测到的特征点,一旦点找不到,就没有办法完成匹配;对于位置不同的两个点,如果它们的背景特征相似或者说缺乏纹理特征,也会导致匹配失败。LoFTR的优势就是不需要先得到特征点,而且采用End2End的方式,用起来比较方便。
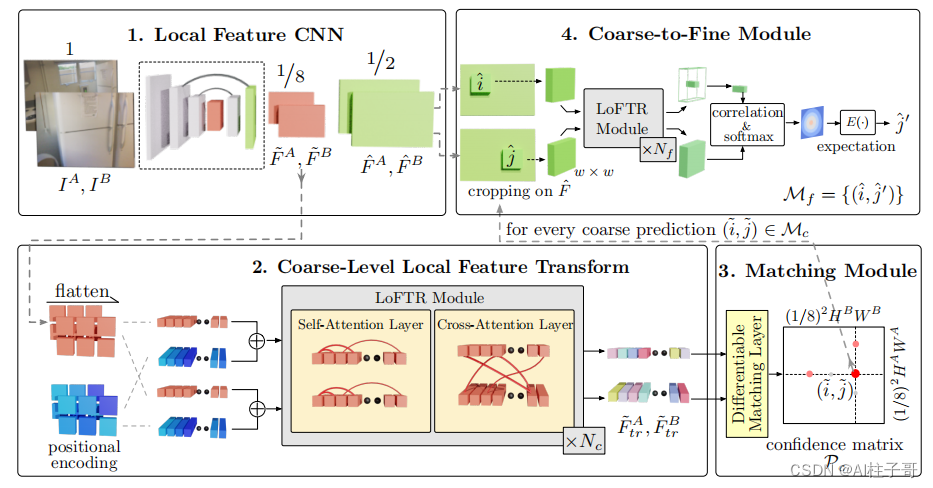
- 局部特征CNN从图像对中提取粗粒度特征图 F ~ A \tilde{F}^{A} F~A , F ~ B \tilde{F}^{B} F~B,以及细粒度特征图 F ^ A \hat{F}^{A} F^A , F ^ B \hat{F}^{B} F^B
- 粗粒度的特征经过flatten操作并添加位置编码,然后由LoFTR模块进行处理;该模块中包括自注意和互注意层,并重复
Nc 次 - 使用可微匹配层来匹配LoFTR模块输出的特征 F ~ t r A \tilde{F}_{tr}^{A} F~trA , F ~ t r B \tilde{F}_{tr}^{B} F~trB,得到一个置信矩阵 P c P_c Pc ,然后根据置信阈值和最近邻算法(MNN)选择匹配对,得到粗粒度的匹配预测 M c M_c Mc
- 对于每个粗粒度匹配对 ,从细粒度级特征图中裁剪一个大小为w*w的局部窗口,粗粒度匹配将在此窗口内细化为亚像素级别,并作为最终的匹配预测 M f M_f Mf
1.源码解析
源码的结构层次比较鲜明,在模型文件loftr.py的forward函数中,可以清晰的看到整个模型的前向路径:
- Local Feature CNN
- coarse-level loftr module
- match coarse-level
- fine-level refinement
- match fine-level
基础特征提取模块Local Feature CNN
通过CNN提取特征图
# 1. Local Feature CNN
data.update({
'bs': data['image0'].size(0),
'hw0_i': data['image0'].shape[2:], 'hw1_i': data['image1'].shape[2:]
})
if data['hw0_i'] == data['hw1_i']: # faster & better BN convergence
print(torch.cat([data['image0'], data['image1']], dim=0).shape)
feats_c, feats_f = self.backbone(torch.cat([data['image0'], data['image1']], dim=0))
print(feats_c.shape) # 1/8
print(feats_f.shape) # 1/2
(feat_c0, feat_c1), (feat_f0, feat_f1) = feats_c.split(data['bs']), feats_f.split(data['bs'])
print(feat_c0.shape 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









