









1.简介
Channel(一般简写为 chan) 管道提供了一种机制:它在两个并发执行的协程之间进行同步,并通过传递与该管道元素类型相符的值来进行通信,它是Golang在语言层面提供的goroutine间的通信方式.通过Channel在不同的 goroutine中交换数据,在goroutine之间发送和接收消息,并且可以通过Channel实现Go依赖的CSP的并发模型这种同步模式
chan 可以理解为一个管道或者先进先出的队列,Golang并发的核心哲学是:不要通过共享内存来通信,而应该通过通信来共享内存,所以数据在不同协程中的传输都是通过拷贝的形式完成的,并且 channel 本身还可以支持有缓冲和无缓冲的,通过 channel + timeout 实现并发协程之间的同步也是常见的一种使用姿势
2.channel结构体
简单说明:
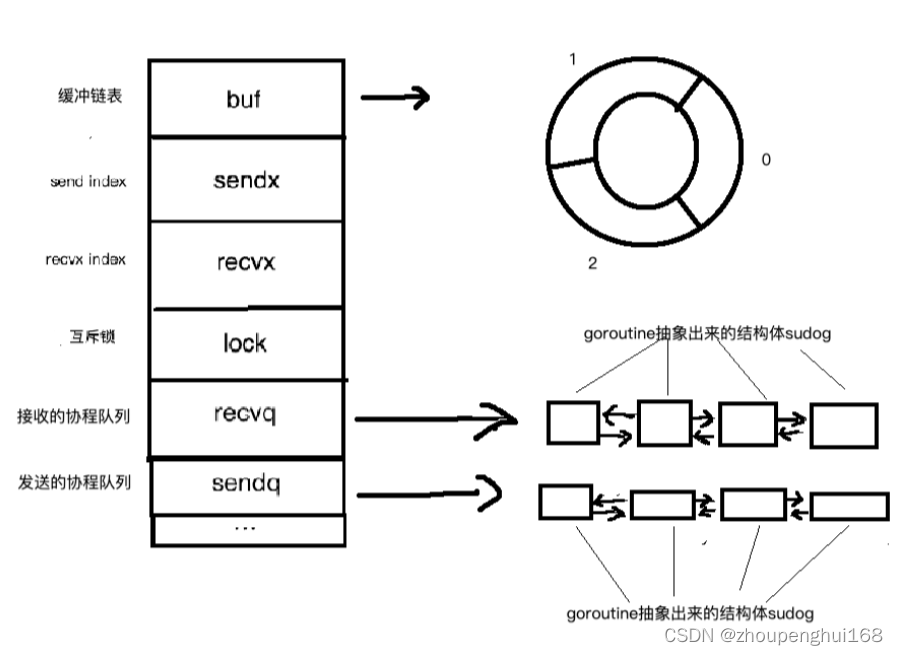
buf是有缓冲的channel所特有的结构,用来存储缓存数据,是个循环链表sendx和recvx用于记录buf这个循环链表中的发送或者接收的indexlock是个互斥锁recvq和sendq分别是接收(<-channel)或者发送(channel <- xxx)的goroutine抽象出来的结构体(sudog)的队列,是个双向链表
type hchan struct {
qcount uint // total data in the queue 当前队列里还剩余元素个数
dataqsiz uint // size of the circular queue 环形队列长度,即缓冲区的大小,即make(chan T,N) 中的N
buf unsafe.Pointer // points to an array of dataqsiz elements 环形队列指针
elemsize uint16 //每个元素的大小
closed uint32 //标识当前通道是否处于关闭状态,创建通道后,该字段设置0,即打开通道;通道调用close将其设置为1,通道关闭
elemtype *_type // element type 元素类型,用于数据传递过程中的赋值
sendx uint // send index 环形缓冲区的状态字段,它只是缓冲区的当前索引-支持数组,它可以从中发送数据
recvx uint // receive index 环形缓冲区的状态字段,它只是缓冲区当前索引-支持数组,它可以从中接受数据
recvq waitq // list of recv waiters 等待读消息的goroutine队列
sendq waitq // list of send waiters 等待写消息的goroutine队列
// lock protects all fields in hchan, as well as several
// fields in sudogs blocked on this channel.
//
// Do not change another G's status while holding this lock
// (in particular, do not ready a G), as this can deadlock
// with stack shrinking.
lock mutex //互斥锁,为每个读写操作锁定通道,因为发送和接受必须是互斥操作
}
// sudog 代表goroutine
type waitq struct {
first *sudog
last *sudog
}
3.Channel 操作符和操作方式
通信操作符
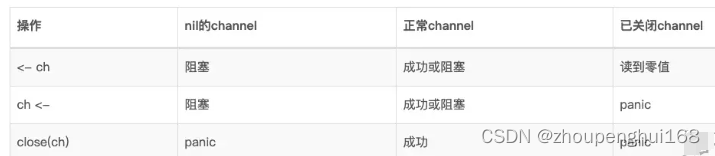
<-的箭头指示数据流向,箭头指向哪里,数据就流向哪里,它是一个二元操作符,可以支持任意类型,对于 channel 的操作只有4种方式:
- 创建 channel (通过make()函数实现,包括无缓存 channel 和有缓存 channel);
- 向 channel 中添加数据(channel<-data);
- 从 channel 中读取数据(data<-channel);
- data<-channel, 从 channel 中接收数据并赋值给 data
- <-channel,从 channel 中接收数据并丢弃
- 关闭 channel(通过 close()函数实现)
- 读取关闭后的无缓存通道,不管通道中是否有数据,返回值都为 0 和 false。
- 读取关闭后的有缓存通道,将缓存数据读取完后,再读取返回值为 0 和 false。
- 对于一个关闭的 channel,如果继续向 channel 发送数据,会引起 panic
- channel 不能 close 两次,多次 close 会 panic
4.Channel 有无缓冲 & 同步、异步
channel 分为有缓冲 channel 和无缓冲 channel,两种 channel 的创建方法如下:
- var ch = make(chan int) //无缓冲 channel,等同于make(chan int ,0),是一个同步的 Channel
- 无缓冲 channel 在读和写的过程中是都会阻塞,由于阻塞的存在,所以使用 channel 时特别注意使用方法,防止死锁和协程泄漏的产生。
- 无缓冲 channel 的发送动作一直要到有一个接收者接收这个值才算完成,否则都是阻塞着的,也就是说,发送的数据需要被读取后,发送才会完成
- 一般要配合 select + timeout 处理,然后再在这里添加超时时间
- var ch = make(chan int,10) //有缓冲channel,缓冲大小是10,是一个异步的Channel
- 带缓存的 channel 实际上是一个阻塞队列。队列满时写协程会阻塞,队列空时读协程阻塞。
- 有缓冲的时候,写操作是写完之后直接返回的。相对于不带缓存 channel,带缓存 channel 不易造成死锁。
5.Channel 各种操作导致阻塞和协程泄漏的场景
写操作,什么时候会被阻塞?
- 向 nil 通道发送数据会被阻塞
- 向无缓冲 channel 写数据,如果读协程没有准备好,会阻塞
- 无缓冲 channel ,必须要有读有写,写了数据之后,必须要读出来,否则导致 channel 阻塞,从而使得协程阻塞而使得协程泄漏
- 一个无缓冲 channel,如果每次来一个请求就开一个 go 协程往里面写数据,但是一直没有被读取,那么就会导致这个 chan 一直阻塞,使得写这个 chan 的 go 协程一直无法释放从而协程泄漏。
- 向有缓冲 channel 写数据,如果缓冲已满,会阻塞
- 有缓冲的 channel,在缓冲 buffer 之内,不读取也不会导致阻塞,当然也就不会使得协程泄漏,但是如果写数据超过了 buffer 还没有读取,那么继续写的时候就会阻塞了。如果往有缓冲的 channel 写了数据但是一直没有读取就直接退出协程的话,一样会导致 channel 阻塞,从而使得协程阻塞并泄漏。
读操作,什么时候会被阻塞?
- 从 nil 通道接收数据会被阻塞
- 从无缓冲 channel 读数据,如果写协程没有准备好,会阻塞
- 从有缓冲 channel 读数据,如果缓冲为空,会阻塞
close 操作,什么时候会被阻塞?
- close channel 对 channel 阻塞是没有任何效果的,写了数据但是不读,直接 close,还是会阻塞的。
6.Channel 各种操作对应的状态
- 正常的 channel,可读、可写
- nil 的 channel,表示未初始化的状态,只进行了声明,或者手动赋值为 nil
- 已经 closed 的 channel,表示已经 close 关闭了,千万不要误认为关闭 channel 后,channel 的值是 nil
7.Channel 长度和容量
容量(capacity)代表 Channel 容纳的最多的元素的数量,代表Channel的缓存的大小。如果没有设置容量,或者容量设置为0, 说明 Channel 没有缓存,长度和容量的两个函数是 cap 和 len 。
示例如下:
c := make(chan int, 100) // cap 就是 100,但是此时 len 为 0
c <- 0 // len = 1, cap = 100
c <- 0 // len = 2, cap = 100
<- c // len = 1, cap = 1008.Channel 的缺点
Channel 的缺点:
- Channel 可能会导致循环阻塞或者协程泄漏,这个是最最最要重点关注的
- Channel 中传递指针会导致数据竞态问题(data race/ race conditions)
- Channel 中传递的都是数据的拷贝,可能会影响性能,但是就目前我们的机器性能来看,这点数据拷贝所带来的 CPU 消耗,大多数的情况下可以忽略
9.Go Channel 实现协程同步
channel 实现并发同步的说明:channel 作为 Go 并发模型的核心思想:不要通过共享内存来通信,而应该通过通信来共享内存,那么在 Go 里面,当然也可以很方便通过 channel 来实现协程的并发和同步了,并且 channel 本身还可以支持有缓冲和无缓冲的,通过 channel + timeout 实现并发协程之间的同步也是常见的一种使用姿势。
无缓冲 chan 示例
示例如下:
package main
import "fmt"
func main() {
var ch = make(chan string)
for i := 0; i < 10; i++ {
go sum(i, i+10, ch)
}
for i := 0; i < 10; i++ {
fmt.Print(<-ch)
}
}
func sum(start, end int, ch chan string) {
var sum int = 0
for i := start; i < end; i++ {
sum += i
}
ch <- fmt.Sprintf("Sum from %d to %d is %d\n", start, end, sum)
}有缓冲 chan 示例
message_chan := make(chan int, 2)
go func() {
time.Sleep(time.Second * 3)
println("start recv...")
println(<-message_chan)
println(<-message_chan)
println(<-message_chan)
println("finish recv...")
}()
println("start send 10...")
message_chan <- 10
println("start send 20...")
message_chan <- 20
println("start send 30...")
message_chan <- 30
println("finish send...")
time.Sleep(time.Second * 3)
close(message_chan)参考
Channels in Go(https://go101.org/article/channel.html)
How to Gracefully Close Channels(https://go101.org/article/channel-closing.html)















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









