







一、jemter之beanshell
1)分类和作用
1.BeanShell PreProcessor:作用于测试计划,线程,http请求层,在请求发送之前执行。beanshell前置处理器,用来对 request数据 进行处理,如接口的加密,签名
2.BeanShell PostProcessor:作用于测试计划,线程,http请求层。beashell后置处理器,用来对 response数据 进行处理,如对返回数据进行比较复杂的提取,调用prev变量来获取前面请求的返回值,头部信息等
3.BeanShell Assertion:作用于测试计划,线程,http请求层。beashell断言,用来对 response数据或者提取的参数 进行处理,如对返回数据进行比较复杂的判断
4.beanshell定时器:作用于测试计划,线程,http请求层。利用线程的sleep方法来灵活休眠
5.BeanShell Sampler:仅作用于线程。beanshell取样器,按照位置顺序执行,不依赖于接口
2)实例操作
BeanShell PreProcessor处理数据


前置beanshell中sampler.getPath()、sampler.getArguments()能正常调用,后置beanshell报错。
接下来使用前置beanshell中sampler.getPath()、sampler.getArguments()方法进行签名
import org.apache.jmeter.config.Arguments;
import org.apache.jmeter.config.Argument;
import com.esb.demo.util.*;
Map fileds = new HashMap();
Map unsignedParams = new HashMap();
Arguments argms = sampler.getArguments();
int size = argms.getArgumentCount();
for(int i=0;i<size;i++){
Argument argm = argms.getArgument(i);
String argmName = argm.getName();
String argmValue = argm.getValue();
if(argmName != "sign"){
fileds.put(argmName,argmValue);//去掉sign后其它的入参put到map中
}
}
fileds = ParamsUtil.getParamMap(fileds,unsignedParams,"XXXXXXXXXX");//ParamsUtil.getParamMap()签名方法 jar包
vars.put("sign",fileds.get("sign"));
vars.put("time",fileds.get("timestamp"));
log.info(">>>>>>>>>>>>>>>>>>>>>>>"+vars.get("sign")+">>>>>>>>>>>>>>>");
log.info(">>>>>>>>>>>>>>>>>>>>>>>"+vars.get("time")+">>>>>>>>>>>>>>>")sampler.addArgument("digest",fileds.get("sign"));
sampler.addArgument("timestamp",fileds.get("timestamp"));//增加请求参数注意:生成的sign、time变量无法直接使用${sign} ${time}再引用到上面请求参数中,可以通过sampler.addArgument方式进行请求参数的修改,也可以进行请求header的修改
sampler.getHeaderManager().removeHeaderNamed("Content-SHA256");//移除header某项
sampler.getHeaderManager().add(new Header("Content-SHA256",contentSHA))//添加header某项
sampler.addArgument("digest",fileds.get("sign"));//添加请求param参数
BeanShell PostProcessor处理数据





前置beanshell和后置beanshell都能调用 prev.getResponseDataAsString()或者 prev.getResponseCode()方法,但是获取到的结果不一样
String body = prev.getResponseDataAsString();
String code = prev.getResponseCode();
log.info(">>>>>>>>>>>>>>BeanShell PostProcessor>>>>>>>>>"+body+">>>>>>>>>>>>>>>>>>>>>");
log.info(">>>>>>>>>>>>>>BeanShell PostProcessor>>>>>>>>>"+code+">>>>>>>>>>>>>>>>>>>>>");BeanShell Assertion处理数据(略)
BeanShell定时器使用

总结:
1)beanshell前置处理器能识别sampler.getPath()或者sampler.getArguments()方法,通过此方法可以循环获取到请求参数,从而对请求参数进行处理,做一些加密,签名处理。而beashell后置处理器识别不了sampler.getPath()或者sampler.getArguments()方法,无法获取请求参数
2)beanshell前置处理器和beashell后置处理器均能识别到 prev.getResponseDataAsString()或者 prev.getResponseCode()方法,通过此方法获取返回参数,从而对返回参数进行处理。但是beashell前置处理器获取的是前一个接口的返回数据,而beashell后置处理器获取的是此接口的返回数据
综上所述,beashell前置处理器是在接口请求之前运行,beashell后置处理器是在接口请求之后运行
二、jemter之csv
1、通过Test Plan 或者Thread Group添加CSV Data Set Config。
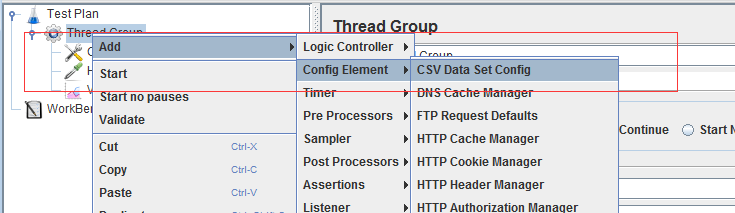
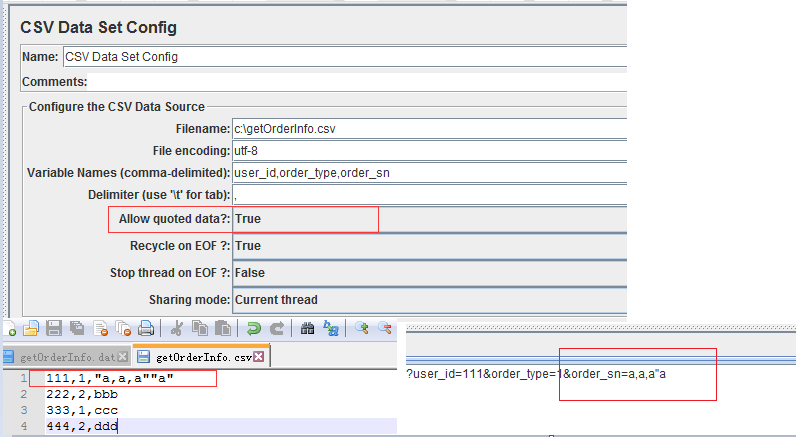
2、准备数据文件,一般以 .csv,.dat 等结尾的文件,数据之间的分隔符可用 ,或者 tab例如:
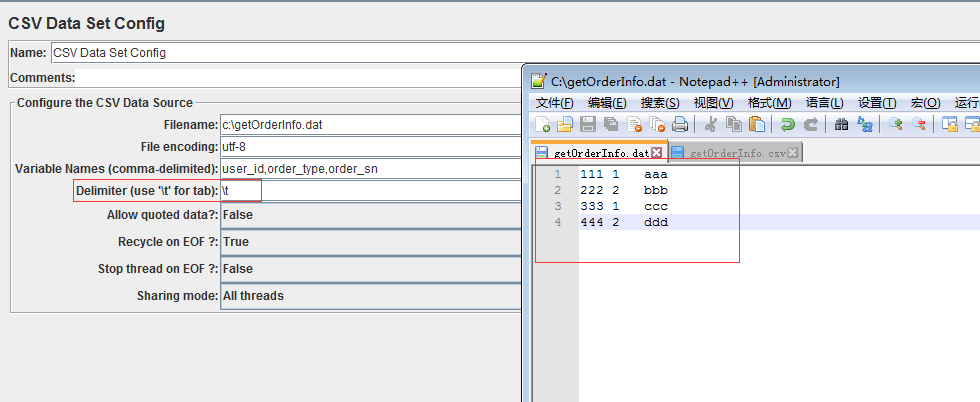
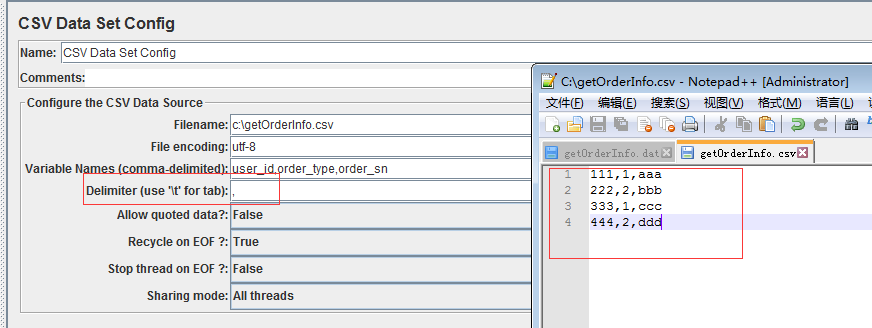
以下是CSV Data Set Config各个参数使用说明:
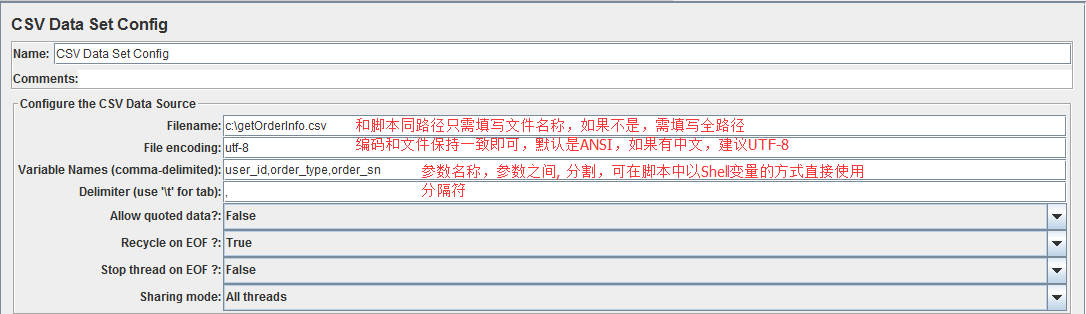
- Allow Quoated data: 是否允许带引号? 双引号相关,例:如果参数中需包含,或者” 等,该项可以选择True,效果如下(有引号的字符串需要引号引用,引号前面也需要加引号):
- Recycle on EOF: 遇到文件结束符再次循环? 设置为True后,允许循环取值
- Stop Thread EOF: 遇到文件结束符停止线程? 当Recycle on EOF为false并且Stop Thread EOF 为true,则读完csv文件中的记录后,停止运行,线程数及执行次数无效。
- Sharing Mode:共享模式:
- All threads:所有线程,所有线程循环取值,线程1取第一行,线程二取下一行。
- Current thread group:当前线程组,各个线程组分别循环取值。
- Current thread:当前线程,该测试计划内的所有线程都取第一行。
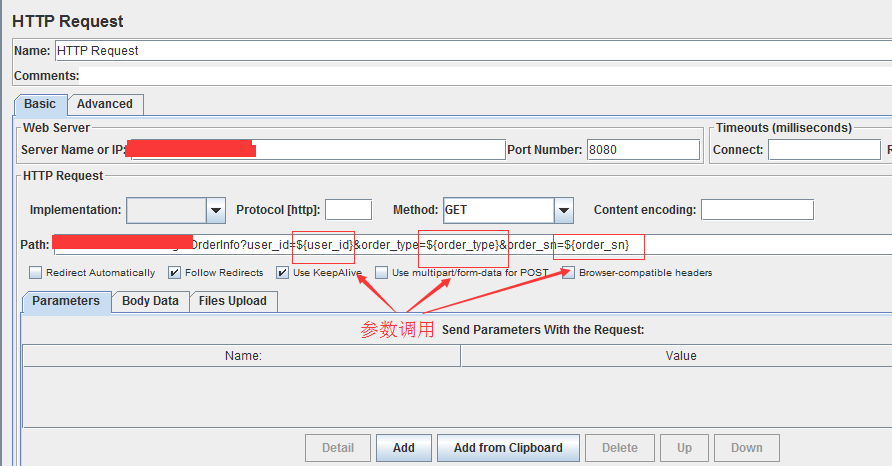
3、参数的引用:
三、jemter之重定向
自动重定向(状态码一般是200、20X):当重定向时,自动跳转时,只针对GET和Head请求,自动重定向可以自动跳转到最终目标页面,但是jmeter不记录重定向过程内容【在查看结果树中只能看到重定向后的响应内容】
跟随重定向(状态码一般是302、30X):当重定向时,自动跳转时,自动重定向可以自动跳转到最终目标页面,但是jmeter记录重定向过程内容【在查看结果树中既能看到重定向后的响应内容,也能看到重定向前的响应内容】

四、jemter之数据库
1)配置JDBC Connection Configuration:
Variable Name:数据库连接池的名称,我们可以有多个jdbc connection configuration,每个可以起个不同的名称,在jdbc request中可以通过这个名称选择合适的连接池进行使用。
- Database URL:数据库url,jdbc:oracle:thin:@host_ip or machine_name:Oracle 监听器监听的端口:Oracle实例的名 (可在oracel安装目录下tnsnames.ora文件中找到这些信息)
- JDBC Driver class:JDBC驱动
- username:数据库登陆的用户名
- passwrod:数据库登陆的密码
2)配置JDBC Request:
Variable Name:数据库连接池的名字,需要与JDBC Connection Configuration的Variable Name Bound Pool名字保持一致
Query:填写的sql语句未尾不要加“;”
Parameter valus:参数值
Parameter types:参数类型,可参考:Javadoc for java.sql.Types
Variable names:保存sql语句返回结果的变量名
Result variable name:创建一个对象变量,保存所有返回的结果
Query timeout:查询超时时间
Handle result set:定义如何处理由callable statements语句返回的结果
3)执行结果
4)JDBC Request参数化
方法(一): 定义变量,在sql quety中使用变量:
1、在Test plan中定义三个变量
2、在sql query中使用${变量名}的方式引用
方法(二): 在sql quety中使用“?”作为占位符,并传递参数值和参数类型,如下图:
1、传递的参数值是常量,如下图传递了3个常量:10,ACCOUNTINGNEW YORK
2、传递的参数值是变量,如下图中${DNAME}
5)Variables names参数使用方法
Jmeter官网给的解释是:如果给这个参数设置了值,它会保存sql语句返回的数据和返回数据的总行数。假如,sql语句返回2行,3列,且variables names设置为A,,C,那么如下变量会被设置为:
A_#=2 (总行数)
A_1=第1列, 第1行
A_2=第1列, 第2行
C_#=2 (总行数)
C_1=第3列, 第1行
C_2=第3列, 第2行
- 如果返回结果为0,那么A_#和C_#会被设置为0,其它变量不会设置值。
- 如果第一次返回6行数据,第二次只返回3行数据,那么第一次那多的3行数据变量会被清除。
- 可以使用${A_#}、${A_1}...来获取相应的值
示例:
我们还是用上面的数据库,把所有数据查出来,DEPT表有有3个字段,4条记录
1、添加一个jdbc request名为select4,添加一个Debug Sampler用来查看输出的结果,设置 variables name为a,b,c:
2、执行结果:
6)Result variable name参数使用方法
如果给这个参数设置值,它会创建一个对象变量,保存所有返回的结果,获取具体值的方法:columnValue =vars.getObject("resultObject").get(0).get("Column Name")
执行结果
6)数据库驱动类和URL格式
| Datebase | Driver class | Database URL |
| MySQL | com.mysql.jdbc.Driver | jdbc:mysql://host:port/{dbname} |
| PostgreSQL | org.postgresql.Driver | jdbc:postgresql:{dbname} |
| Oracle | oracle.jdbc.driver.OracleDriver | jdbc:oracle:thin:@//host:port/service OR jdbc:oracle:thin:@(description=(address=(host={mc-name}) (protocol=tcp)(port={port-no}))(connect_data=(sid={sid}))) |
| Ingres (2006) | ingres.jdbc.IngresDriver | jdbc:ingres://host:port/db[;attr=value] |
| MSSQL | com.microsoft.sqlserver.jdbc.SQLServerDriver 或者 net.sourceforge.jtds.jdbc.Driver | jdbc:sqlserver://IP:port;databaseName=DBname 或者 jdbc:jtds:sqlserver://localhost:1433/"+"library" |
五、jemter之响应断言
1)响应断言
可根据要测试响应字段和模式匹配规则来设置断言,比如下方截图是匹配返回的结果中是否包含“code:200,”,如果包含则表示断言成功,否则失败。响应断言可添加多个,但是多个断言之间是与的关系,不能满足或的需求。

2)Beanshell断言
当某些断言不能满足使用时,比如多个断言或的情况,可以使用Beanshell Assertion来进行处理。
例如“code:200”或者“code:800034”都认为断言成功时,可以使用如下方法来进行处理:

3)Json Path断言
当接口返回json格式数据时,除了前两种方法,我们还可以使用JSON Path Assertion。使用JSON Path Assertion,需先在安装Jmeter Plugins Manage,然后在Jmeter Plugins Manage中下载jpgc - Standard Set插件。在Json Path中添加匹配规则,在Expect value中填写期望值,如下图所示:

4)Xpath断言
当请求返回页面时,通过对比页面元素是否存在,使用XPath Assertion比较合适

对比:

六、jemter之正则表达式

七、jemter之远程控制器
1)服务器(slave)配置
- 服务器(slave)需安装jmeter,最好与客户端(controller)保持同版本,jdk最好也保持同版本,无法满足时至少保证服务器上的jmeter能正常运行(如jmeter3.0以后需要jdk1.7及以上版本)。
-
在slave的%JMETER_HOME%bin目录下执行./jmeter-server命令启动jmeter服务就可以,启动成功如下图:
-
注意:上图红框中的ip为服务器的ip地址,当服务器有多网卡时它会随机挑选一个网卡使用,红框中的端口号port为启动jmeter服务监听的port,一般会有个默认端口号1099,但最好自定义,确保端口号不冲突。修改方法在下文介绍。
2)客户端(controller)配置
-
在客户端上要保证执行命令能发送到服务器,因此需配置客户端远程的ip地址和port。在客户端安装目录的bin文件夹下,找到jmeter.properties,修改配置如下图,其中ip和port即为上一步slave的ip和port,如上图中jmeter-server启动时红框中显示的内容。多个slave机器的配置可通过逗号分隔。
remote_hosts=10.165.124.6:1029 -
配置完成后打开客户端jmeter的GUI界面,在运行-远程启动中即可看到自己配置的slave机器。
-
添加一个脚本,点击远程启动即可启动运行slave机器,此时在服务器上可看到控制台信息,在客户端通过监听器-聚合报告或察看结果数可看到执行结果。
八、jemter之吞吐量控制器
1)添加吞吐量控制器
注意:只能在线程上进行添加,吞吐量控制器下面再添加http请求


2)设置
总线程数为10,“添加”这个请求占比80%,即执行8次,“登录”这个请求占比20%,即执行2次



结果:

总线程数为10,“添加”这个请求7次,“登录”这个请求3次


结果:

Per User



结果:

九、jemter之聚合报告

- Label:httpRequest name属性值。
- Samples:测试的过程中一共发出了多少个请求即总线程数,(如果模拟10个用户,每个用户迭代10次,这里就显示100),对应图形报表中的样本数目。
- Average:单个Request的平均响应时间,计算方法是总运行时间除以发送到服务器的总请求数,对应图形报表中的平均值。
- Median:50%用户的响应时间。
- 90%Line:90%用户的响应时间。
- Min:服务器响应的最短时间。
- Max:服务器响应的最长时间。
- Error%:本次测试中出错率,请求的数量/请求的总数。
- Throughput:吞吐量,默认情况下表示每秒完成的请求数。
- KB/Sec:每秒从服务器接收到的数据量,即每秒钟请求的字节数,时间单位均为ms。
十、jemter之图形结果分析
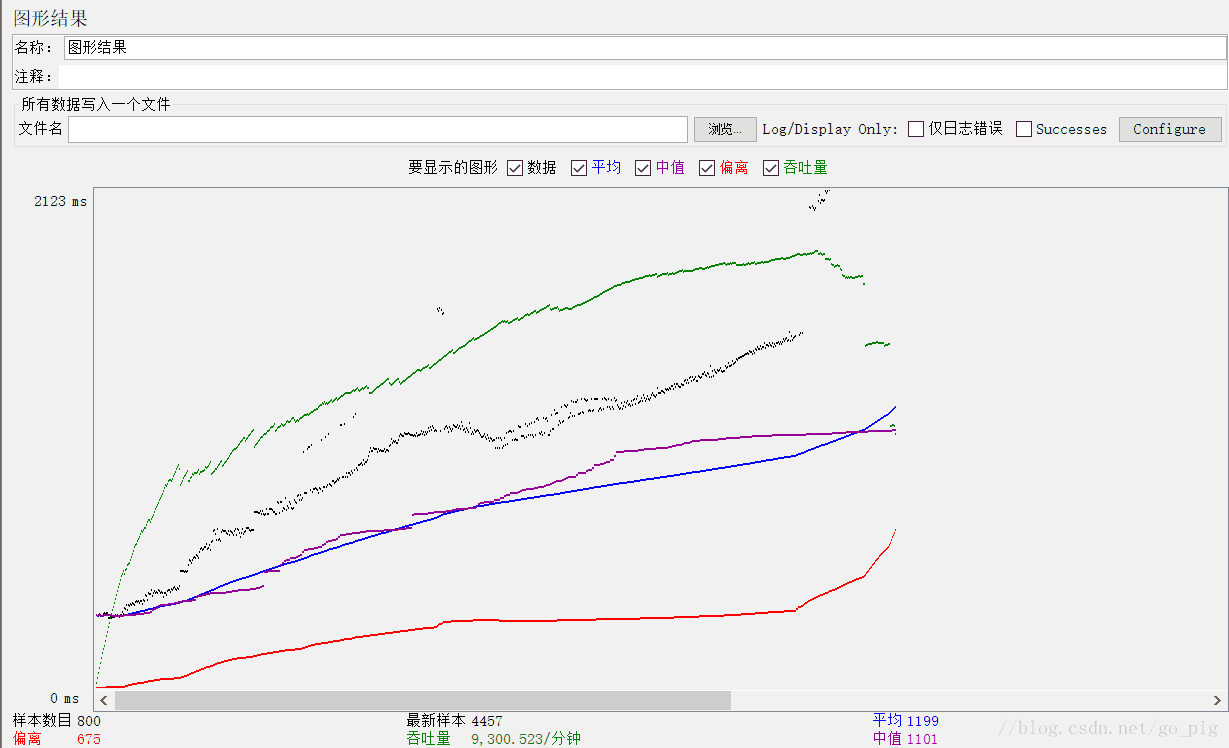
- 样本数目:总共发送到服务器的请求数。
- 最新样本:代表时间的数字,是服务器响应最后一个请求的时间。
- 吞吐量:服务器每分钟处理的请求数。
- 平均值:总运行时间除以发送到服务器的请求数。
- 中间值:有一半的服务器响应时间低于改值而另一半高于该值。
-
偏离:表示服务器响应时间变化、离散程度测量值的大小。
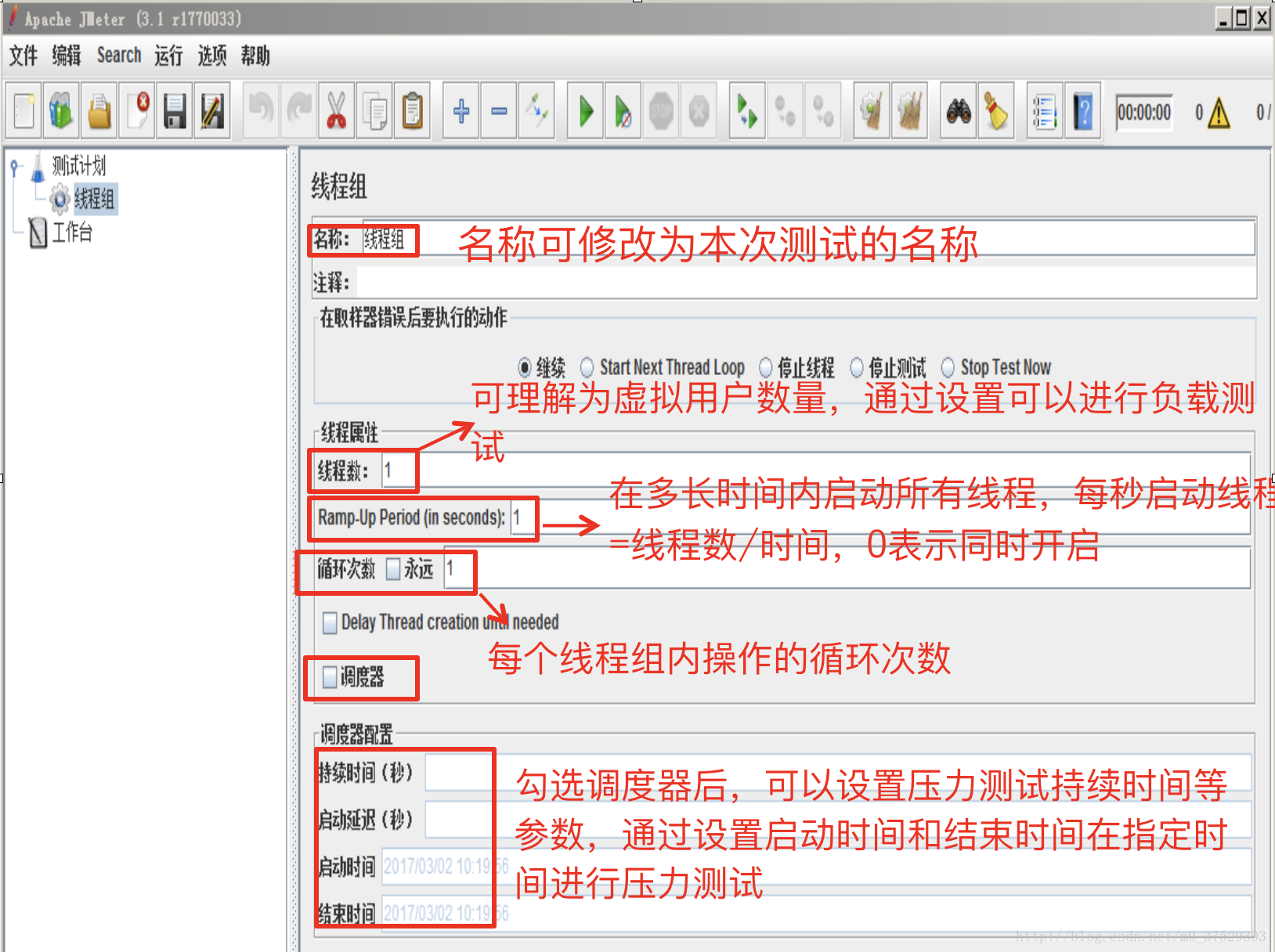
十一、jemter之压测配置















 1481
1481











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









