







概述
常见的数据库都提供标准的导入功能,例如使用命令行工具,内置SQL命令或图形用户界面导入CSV文件或其他格式的数据。但是当面对大量数据处理时,标准导入的效率就显得不够高了。标准导入的请求执行路径几乎一致,从客户端接收到数据,SQL 层进行数据解析,容错处理,路由分发,事务封装最后再进程存储持久化,瓶颈点很明显:1)一行一行数据进行,2)SQL 层过滤解析,3)CLOG 日志量大,非常耗时低效。
同时,OceanBase(OB)的存储引擎是基于LSM(Log-Structured Merge Tree)的。它将LSM树划分为三层,第一层是MemTable,第二层是增量层(也称转储层,即LSM树C0层),第三层是基线层(即LSM树C1层)。在日常批量导入时,由于新增数据是写入内存MemTable的,有利于数据插入。但如果导入并发度控制不当,就会因为内存释放速度比不上新增速度导致租户内存不足的告警,增加运维成本,对OB稳定性也有威胁。
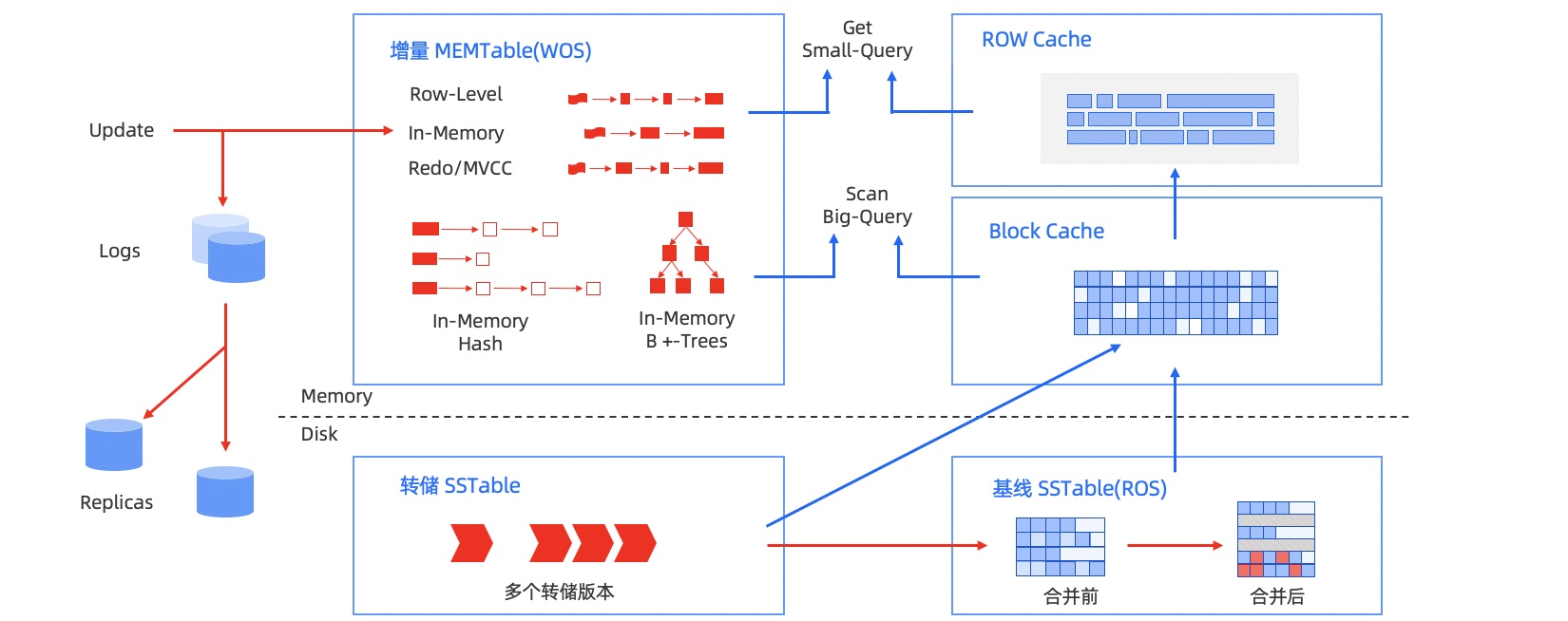
LSM 存储架构图
早期版本的OB 0.4已经有了旁路导入功能,但需要借助hadoop大数据平台对数据进行清理,架构和配置非常复杂。在OceanBase 4.1版本中,重新引入了旁路导入功能,并直接嵌入到SQL命令中。所谓旁路导入简单来说就是越过通用的执行路径,直接将数据按照目标端的数据格式写入到目标端的底层存储中。将这个功能应用到OB上,就是让数据绕过SQL引擎和事务引擎,直接按照存储引擎的格式生成持久化的数据,写入SSTable,通过定制流程优化导入数据的效率。同时这一过程中,内存使用量非常低,能够减轻内存不足的压力。当然高效导入的同时也必然带来各自的限制约束。
SQL命令
目前 OceanBase 数据库支持以下语句进行旁路导入:
LOAD /*+ direct parallel(N)*/ DATA INSERT /*+ append enable_parallel_dml parallel(N) */ INTO table_name select_sentence
测试内容
分别用标准导入和旁路导入在对规格为**(8vCPU,16GB 内存)租户对 LINEITEM 表(7.3GB,约6千万行)**进行数据导入测试对比。
特别说明:
-
LINEITEM 是TPC-H测试模型中一张表,用TPCH工具生成10G的数据量,包含7.3G的LINEITEM数据。具体数据生成过程和表结构 可参考《OceanBase 数据库 TPC-H 测试》 OceanBase分布式数据库-海量数据 笔笔算数
-
LOAD DATA 语句仅支持加载 OBServer 节点本地的输入文件。因此,用户需要在导入之前将文件拷贝到某台 OBServer 节点上。并对文件路径进行赋权
1、登录到要连接 OBServer 节点所在的机器。将导入数据复制到自定义目录下,如/home/admin
obclient -h *** -P2881 -uroot@tpch -p****** -c -A -D testdb2
2、设置导入的文件路径。
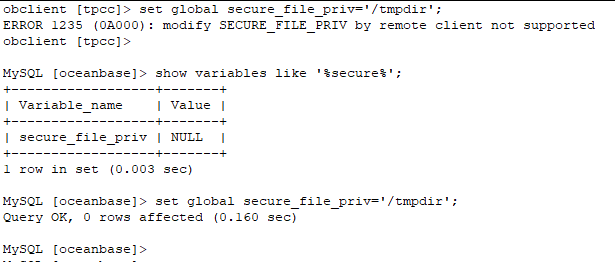
obclient [(testdb2)]> SET GLOBAL secure_file_priv = “/home/admin”;
Query OK, 0 rows affected -
旁路导入能力当前仅支持 CSV 格式数据文件
使用 LOAD DATA 语句旁路导入数据
使用须知
-
导入过程中会加表锁。会影响联机交易,特别注意。
-
不支持在触发器(Trigger)使用。
-
支持 lob 类型,但是性能比较差,lob 会走原来事务写入数据的路径。
-
不能在多行事务中运行。
基本语法
1、使用 APPEND Hint 启用旁路导入功能。 LOAD DATA /*+ PARALLEL(4) APPEND */ INFILE 'file_name' ... 参数解释 PARALLEL(N) 加载数据的并行度,N 默认为 4。 APPEND 使用 Hint 启用旁路导入功能,即支持直接在数据文件中分配空间并写入数据。APPEND Hint 默认等同于使用的 direct(false, 0),同时可以实现在线收集统计信息(GATHER\_OPTIMIZER\_STATISTICS Hint)的功能。 2、使用 direct(bool, int) Hint 启用旁路导入功能。 LOAD DATA /*+ direct(need_sort,max_error) PARALLEL(N) */ INFILE 'file_name' ... 参数解释: direct 表示走旁路导入。 need\_sort 表示是否需要 OceanBase 数据库对数据进行排序。true:表示需要排序。false:表示不需要排序。 max\_error 表示最大的容忍的错误的行数。值为 INT 类型,超过这个数值LOAD DATA 会报失败。 PARALLEL(N) 加载数据的并行度,N 默认为 4。
本次测试案例中使用使用 direct(bool, int) Hint 启用旁路导入功能
1、旁路导入命令 LOAD DATA /*+ direct(flase,0) PARALLEL(4) */ INFILE '/home/admin/tpch/lineitem.tbl' into table lineitem fields by '|' ; 2、标准导入命令 LOAD DATA /*+ PARALLEL(4) */ INFILE '/home/admin/tpch/lineitem.tbl' into table lineitem fields by '|' ;
使用 INSERT INTO SELECT 语句旁路导入数据
使用须知
-
只支持 PDML(Parallel Data Manipulation Language,并行数据操纵语言),非 PDML 不能用旁路导入。
-
导入过程中会加表锁。会影响联机交易,特别注意。
-
不支持在触发器(Trigger)使用。
-
支持
lob类型,但是性能比较差,lob会走原来事务写入数据的路径。 -
不能在多行事务中运行。
基本语法
INSERT /*+ append enable_parallel_dml parallel(N) */ INTO table_name select_sentence 参数解释: append 表示走旁路导入。 enable_parallel_dml parallel(N) 加载数据的并行度,N 默认为 4。一般情况下,enable_parallel_dml Hint 和 parallel Hint 必须配合使用才能开启并行 DML。不过,当目标表的 Schema 上指定了表级别的并行度时,仅需指定 enable_parallel_dml Hint。
测试结果
在规格为 (8vCPU,16GB 内存) 租户下,分别用标准导入和旁路导入方式对LINEITEM 表 (7.3GB,约6千万行) 进行数据导入测试对比。** 为避免操作之间互相影响,每次执行导入命令前对环境数据进行清理并手动发起合并**。结果如下
结果统计
| column1 | 旁路导入 | 标准导入 |
|---|---|---|
| LOAD DATA | 6 min 3.950 sec | 27min 58.564 sec |
| INSERT INTO SELECT | 8min 27.754 sec | 59min 36.865 sec |
结果分析
结果显而易见,旁路导入在加载数据场景性能提升数倍。其中LOAD DATA场景约5倍,INSERT INTO SELECT场景约7倍。
其中,标准导入时,通过观察OCP性能监控,发现MEMStore使用百分比波动频繁,内存在不断占用释放,租户在不断的触发内存转储;租户事务日志数,事务日志量、事务锁等待次数也趋于高水位。基于标准导入的原理,资源占用情况符合预期。结合OBSERVER日志和SQL_AUDIT表,也能看到标准的LOAD DATA就是把数据改写成普通的INSERT INTO语句进行批量插入。
总结、建议
1、旁路导入时,可以通过GV$SESSION_LONGOPS查看导入进度,OPNAME为direct load ,有执行耗时,详见的备注信息,但TIME_REMAING字段当前好像没生效。标准导入方式则没有监控手段。
2、因为OB的旁路导入方式是通过加HINT方式,所以mysql或obclient命令行连接OB时,一定要加 -c 参数,否则数据库无法识别HINT。
3、旁路导入会把所有的已有的数据都写一遍。如果原表的数据比较大,导入的数据比较少,可能不适合使用旁路导入。
4、因为LOAD DATA 本质上是导入本地文件,但由于 OceanBase 是分布式数据库,各个分区的数据可能分布在各个不同的 OBServer 节点,LOAD DATA 会对解析出来的数据进行计算,决定数据需要被发送到哪个 OBServer 节点。所以为了达到最佳性能,建议导入表的主副本和文件在同一个节点上,避免出现远程或分布式执行计划影响。
5、旁路导入分两个阶段load写入和merge合并阶段。所以如果针对load和merge阶段相关参数进行调优的话,相信旁路导入性能还会进一步提升。这一点希望官方能提供4.x版本数据移植时参数优化意见,目前看来4.x和3.2.3版本内核参数还是很大调整的,不少参数已经找不到了。
6、希望旁路导入场景进一步丰富,限制进一步解除。比如OMS ,OB导数工具,备份恢复等场景。
一:旁路导入概念
首先我们先引用OB官方文档的一段话,“OceanBase 数据库支持旁路导入的方式向数据库插入数据,即 OceanBase 数据库支持向 data 文件中直接写入数据的功能。旁路导入可以绕过 SQL 层的接口,直接在 data 文件中直接分配空间并插入数据,从而提高数据导入的效率”。
通过这段描述,让我有种眼前一亮的感觉,因为在OB的运维过程中,我们经常面临的一个问题就是数据的导入导出,针对小表可能大家用一些图形化工具或者obloader感觉还是很不错的,但是如果数据量大的话,性能可能就无法满足要求,同时也担心出现memstore被打爆的风险。
根据OB官方文档介绍,OB支持两种方式的旁路导入,一种是我们以前经常在mysql中使用的load data方式,另外一种是在oracle中经常使用的insert /*+append parallel*/方式。
二:旁路导入测试
测试环境:本次测试采用的是三台虚拟机搭建的OB 4.1社区版。
2.1: LOAD DATA方式
2.1.1:修改变量secure_file_priv
这个与mysql是类似的,要想使用load data方式,必须先要修改secure_file_priv变量,默认为空。
使用限制:此变量必须在observer上修改,不允许从客户端远程修改。

2.1.2:测试数据准备
--新建测试表
create table test(id integer,name varchar(20),primary key(id));
create table t(id integer,name varchar(20),primary key(id));
--准备测试文件,将如下SQL放到ab.csv文件里
select ROW_NUMBER()over(),ROW_NUMBER()over() from `gv$plan_cache_plan_stat` limit 10000;
2.1.3:导入测试
使用限制:
1:文件必须放在observer上
2:文件放的位置必须与secure_file_priv变量对应的值一样
--数据文件放到/tmp目录下导入,报错
![]()
--文件放到/tmpdir目录下导入,成功
![]()
通过上面简单的测试,我们发现成功了,测试还是比较简单的。突然想到,如果我把文件的全路径去掉,它应该会去哪里找文件哪?
![]()
通过报错可以看出与前面不一样,说明他在默认路径没找到文件。将a.csv文件拷贝到ob的主目录(/data/myob4/oceanbase),然后再导入,就报错提示没权限。
![]()
将环境变量改为/data/myob4/oceanbase,再导入。成功导入。
![]()
![]()
上面我们成功导入少数据量,现在我们导入10000条看下效率如何。
--导入10000条数据,速度还是非常可观的。

以上的场景都是数据导入成功的验证,如果数据有问题会有什么情况哪?
--重复数据导入,直接报错
![]()
出错后,会在oceanbase的日志目录生成一个obloaddata.log.*的文件,内容大致如下:
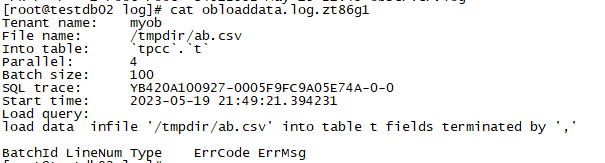
从日志中可以看到batch size是100,说明他是按照批次来“提交”数据的,本次测试我删除1230条,然后执行导入,发现它只导入进去了1200条,有30条是在一个批次内的第31条出现了重复数据,全部就“回滚”了。
有的时候,我们在导入数据的时候经常要忽略掉前多少条那种,这个时候就是ignore number rows的用武之地了。
--忽略1000条导入

--我们查看数据,是文件的前1000条没有导入哦。
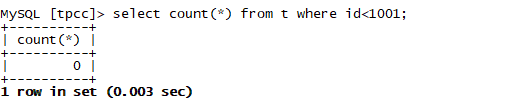
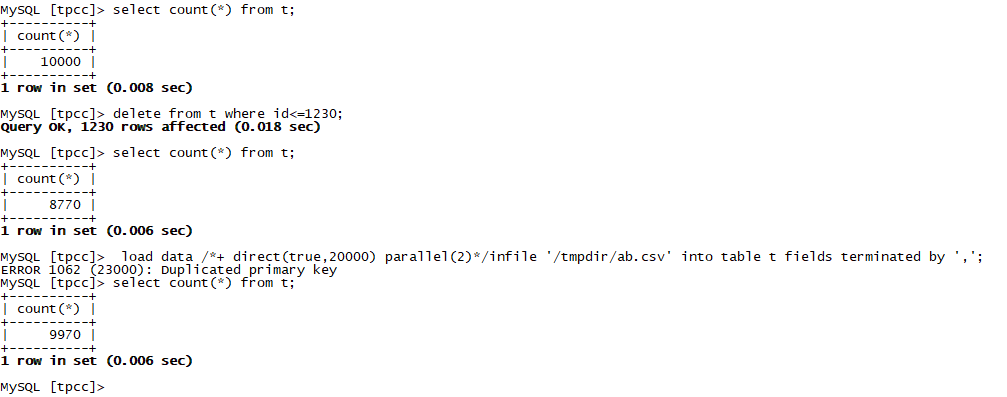
如果我们在导入的时候,表里有数据怎么办哪?我们想清空表在导入可以吗?答案是可以的。
--清空导入:

2.2: INSERT /*+append */方式
INSERT INTO SELECT 语句通过 Hint 使用 append 加上 enable_parallel_dml 来走旁路导入。
使用限制:
1:只支持 PDML,非 PDML 不能用旁路导入。
2:导入的过程中会先加表锁
2.2.1:默认的insert into
通过执行计划,我们可以看出默认insert into select方式是没有使用旁路导入的。主要是看最后一行(是否包含:Direct-mode)
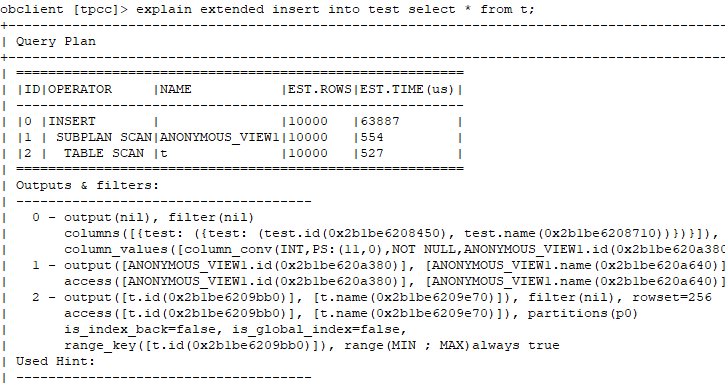
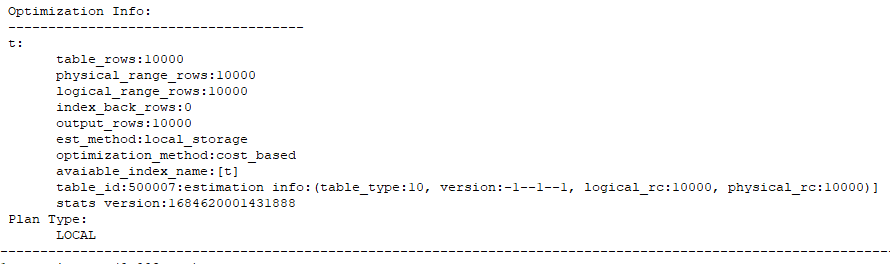
2.2.2:旁路导入
通过查看执行计划,可以看出使用了DIRECT方式。
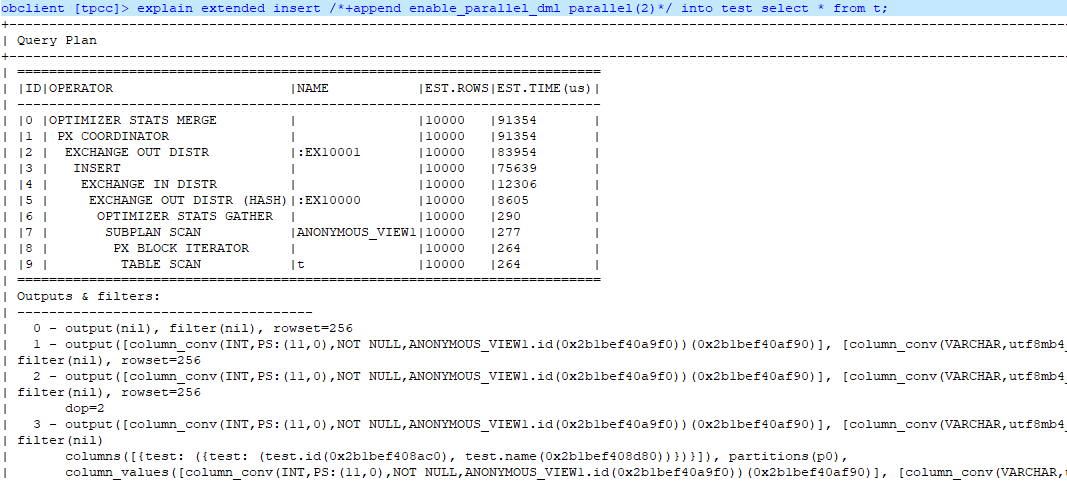

--如果去掉parallel会怎么样?
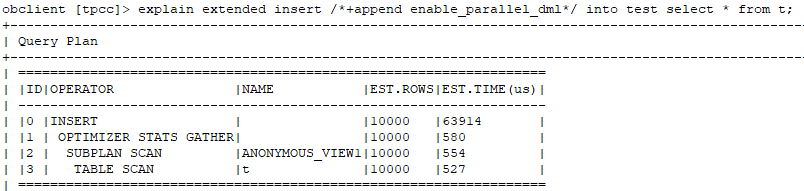
--如果去掉enable parallel dml会怎么样?
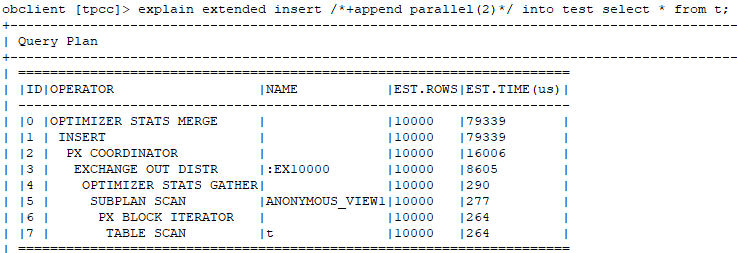
通过上述测试,可以发现append,enable_parallel_dml,parallel缺一不可啊。
三:总结
旁路导入这个工具还是非常不错的,也为OceanBase的导入导出增加了一个利器。整体使用方法比较简单
旁路导入可能会在大的数据量情况下性能会比较显著吧(当前没有测试数据量过大的场景),在数据量小的情况,有时可能还不如传统方法快。比如此次测试的时候,在insert /*+append*/ into场景下导入数据,导入10000条需要花3秒多的时间,而传统的insert into方式只需要0.03秒。可能insert /*+append*/into结合分区表会有更好的效果。
01.思路
我们首先根据 Demo 实现,分析了旁路导入的实现流程,其流程如下:

Demo 程序中提供的实现方式是单线程的,因此一个显而易见的优化方向,就是将其改为多线程来并行处理数据,并行写入 SSTable。
由于在写入 SSTable 前我们需要得到一个根据主键整体有序的数据,在这个基础上我们可以将其分为两个阶段:
第一阶段, CSV 解析,列值转换,主键排序;
第二阶段,写入 SSTable,这样也更有利于后续多线程的实现。
在确定使用多线程的优化思路后,最简单的实现思路就是,将一整个文件分为多个较小文件后,多个线程并行执行上述的那一套流程。这个样子使用多线程后需要解决的问题就出来了:
1. 多线程如何保证整体有序?
多个线程对多个文件执行解析排序后,只能保证数据在各自的线程中有序,并不能保证在整体有序,这个样子就不能直接写 SSTable。
2. 如何多线程写SSTable?
由于比赛有执行合并 Major SStable 不超过30s的限制,基本限定了我们只能直接写 Major SST able,而不是写mini或者 minor SSTable,因此带来了多线程写线程安全的问题。
解决完以上两个问题,实际上基本就能完成本次比赛中多线程部分的优化问题了。
02.多线程实现
1. 造轮子
最开始我们是处于一个盲人摸象的阶段,经过简单讨论后,决定使用线程池来管理多线程。其实 OceanBase 源码中是有线程池的库,我们可以拿来继承后改改直接用,但当时由于对 OceanBase 源码不太熟悉,所以我们第一版是直接自己实现了一个线程池。
class ThreadPool : noncopyable
{
public:
typedef std::function<void()> Task;
explicit ThreadPool(const std::string &nameArg = std::string("ThreadPool"));
~ThreadPool();
void set_max_queue_size(int maxSize) { max_queue_size_ = maxSize; }
int start(int num_threads);
void stop();
int run(Task f);
const std::string &name() const { return name_; }
size_t queue_size() const;
private:
...
};使用一个队列来保存 Tasks,每个线程空闲之后从队列中取 Task,通过锁保证线程安全的问题。
这个线程池实现其实并没有问题,但是当时我们忽略了 OceanBase 的一个特性,它是一个多租户架构的分布式数据库,每一个租户相当于传统数据库的一个实例,其中服务器资源的划分,包括 CPU 和内存,是从租户的可分配资源中分配的,这样会导致每一个线程会有一个租户上下文,而我们自己实现的线程池实际上并没有这个信息,因此在这个线程池中试图申请内存等资源时就会失败。
当时官方第一次答疑还没有开始,只能自己排查问题。我们首先放弃使用线程池,单线程测试划分文件后并没有出错,因此将问题锁定在线程池模块。我们改用手动启用多线程的方式,发现仍然出错,这个时候我们开始排查日志,发现在申请内存时,它的 tenant_id=0,而这个其实就是OB_INVALID_TENANT_ID。
这个时候我们意识到了问题所在,OceanBase 在分配内存时是使用 allocator 分配的,而 allocator 在初始化时会有这么一句:
allocator_.set_tenant_id(MTL_ID());这个就是设置当前的租户 id,而我们自己启动的线程在通过MTL_ID()时由于没有租户上下文,导致获取到了OB_INVALID_TENANT_ID,从而导致申请内存失败。
2. OB ThreadPool
在发现问题后,我们开始浏览 OceanBase 的源代码,试图解决租户问题,最后发现其实 OceanBase 源码中有提供线程池的库,提供了一个线程池的基类OBThreadPool,其中有一个方法:
// IRunWrapper 用于创建多租户线程时指定租户上下文
// cgroup_ctrl 和IRunWrapper配合使用,实现多租户线程的CPU隔离
void set_run_wrapper(IRunWrapper *run_wrapper, ThreadCGroup cgroup = ThreadCGroup::FRONT_CGROUP)
{
run_wrapper_ = run_wrapper;
cgroup_ = cgroup;
}通过这个方法就可以设置租户上下文,解决申请资源分配的问题。我们只需要在线程池初始化时 set_run_wrapper 就可以了。
因此我们只需要继承 OBThreadPool 就可以自定义自己的线程池。
class OxcoThreadPool : public share::ObThreadPool
{
static const int64_t QUEUE_WAIT_TIME = 100 * 1000;
public:
OxcoThreadPool();
virtual ~OxcoThreadPool();
int init(const int64_t thread_num, const int64_t task_num_limit, const char *name = "unknow"); // 初始化
void destroy(); // 析构
int push(void *task); // 添加任务
int64_t get_queue_num() const { return queue_.size(); }
private:
void handle(void *task); // 处理任务
void handle_drop(void *task) { handle(task); }
protected:
void run1() override; // 启动线程池
private:
const char *name_;
bool is_inited_;
common::ObLightyQueue queue_;
int64_t total_thread_num_;
int64_t active_thread_num_;
};这里我们使用了 OceanBase 库中提供的ObLightyQueue来维护线程队列,这是一个线程安全的队列,不用自己额外使用锁去维护。由于这个队列并不是模板类,因此它是使用 void 指针来存放队列元素,其定义为:
class ObLightyQueue
{
public:
...
int push(void* p);
int pop(void*& p, int64_t timeout = 0);
private:
...
void** data_;
};在使用时需要将任务转换为void*指针。
OceanBase 线程池的用法和其他线程池并没有什么不同,只需要初始化时设置租户上下文即可,如下:
int OxcoThreadPool::init(const int64_t thread_num, const int64_t task_num_limit, const char *name){ int ret = OB_SUCCESS; ... is_inited_ = true; lib::ThreadPool::set_run_wrapper(MTL_CTX()); //设置租户上下文 ... return ret;}初始化完成后,只需要将任务 task 添加进线程池就可以使用。
这个问题也是我们在比赛初期遇到的比较大的困难。后来官方也在第一次答疑中说明了这个问题,并直接给出了用法,但是我们能够在答疑前通过自己定位到问题所在,并通过浏览 OceanBase 源码自己解决问题,还是有很大的成就感。这个过程也锻炼了自己 Debug 的能力,拓展了 Debug 的方法,也锻炼了在大型项目中浏览代码并解决问题的能力。
03. 实现整体有序
1. 整体有序的方法
使用多线程的问题解决了,接下来面临的问题就是如何得到一个整体有序的数据。在分割文件之后各个线程对自己负责部分的文件进行解析排序只能得到块内有序的数据,而下一阶段写 SSTable 则需要一个整体有序的数据,所以我们需要一个方法来解决这个问题。
最简单的方法是利用外部排序的方法,各个线程在内部排序后,建立多个内部有序的临时文件,再利用归并排序对这些内部有序的临时文件进行合并,最终合并成一个整体有序的大文件。在写 SSTable 的时候,再读取这个整体有序的大文件即可。
但这样会有一个问题,就是在临时文件合并的过程中,会有大量的 IO 产生,而提供的机器中,IO 读只有约 250MB/s,写只有 150MB/s,因此这样产生大量不必要的耗时,在实现这部分的时候我们经过测试,如果触发文件合并的话,导入耗时会增加整整16分钟。因此合并的代价是很大的,想要高效的导入,必然需要另外的方法。
我们翻阅 OceanBase 源码,发现使用的是ObExternalSort这个模块,其定义如下:
template <typename T, typename Compare>
class ObExternalSort
{
public:
typedef ObMemorySortRound<T, Compare> MemorySortRound;
typedef ObExternalSortRound<T, Compare> ExternalSortRound;
ObExternalSort();
virtual ~ObExternalSort();
int init(const int64_t mem_limit, const int64_t file_buf_size, const int64_t expire_timestamp,
const uint64_t tenant_id, Compare *compare);
int get_next_item(const T *&item);
void clean_up();
int add_fragment_iter(ObFragmentIterator<T> *iter);
int transfer_final_sorted_fragment_iter(ObExternalSort<T, Compare> &merge_sorter);
int get_current_round(ExternalSortRound *&round);
TO_STRING_KV(K(is_inited_), K(file_buf_size_), K(buf_mem_limit_), K(expire_timestamp_), K(merge_count_per_round_),
KP(tenant_id_), KP(compare_));
private:
static const int64_t EXTERNAL_SORT_ROUND_CNT = 2;
bool is_inited_;
int64_t file_buf_size_;
int64_t buf_mem_limit_;
int64_t expire_timestamp_;
int64_t merge_count_per_round_;
Compare *compare_;
MemorySortRound memory_sort_round_;
ExternalSortRound sort_rounds_[EXTERNAL_SORT_ROUND_CNT];
ExternalSortRound *curr_round_;
ExternalSortRound *next_round_;
bool is_empty_;
uint64_t tenant_id_;
};ObExternalSort的实现逻辑是这样的,首先将数据读取到预先分配好的内存中,即memory_sort_round_,当达到预分配的内存阈值后,会将内存中的数据排序,并写入临时文件中,由ExternalSortRound进行维护,这样一个临时文件我们将其称为一个fragment,将文件读完并排序后,我们就得到了多个各自有序的fragment,并可以通过ExternalSortRound进行访问。
而多个fragment如何得到或者说访问到整体有序的文件呢?
我们再看ObExternalSort的实现,通过它的get_next_item方法我们可以看到,它将多个fragment中的第一个元素取出来,组成一个堆,每次从堆顶取元素,取完元素后,再从堆顶元素对应的fragment中取出一个元素,再对堆进行调整,这样就可以不进行文件合并的同时又获得整体有序的文件。而且可以注意到这些fragment,可以通过ObFragmentIterator来进行索引和访问。
所以整体有序的数据获取方法就显而易见了,每个线程利用ObExternalSort排完序后,将这些ObFragmentIterator收集到一起,最后通过堆访问就可以实现有序数据的获取。
2. 划分范围的有序文件
有了上述方法后,我们可以获得任意临时文件组成的有序数据,但是还有一个问题,在写 SSTable 的时候,要实现多线程写,就需要保证写的部分不能重复,因此我们需要对有序的文件划分范围,而上述方法并不支持划分范围的做法,因为每个临时文件之间的数值范围实际上是有重叠的,但是我们可以利用上述的方法来构造可划分范围的有序数据。
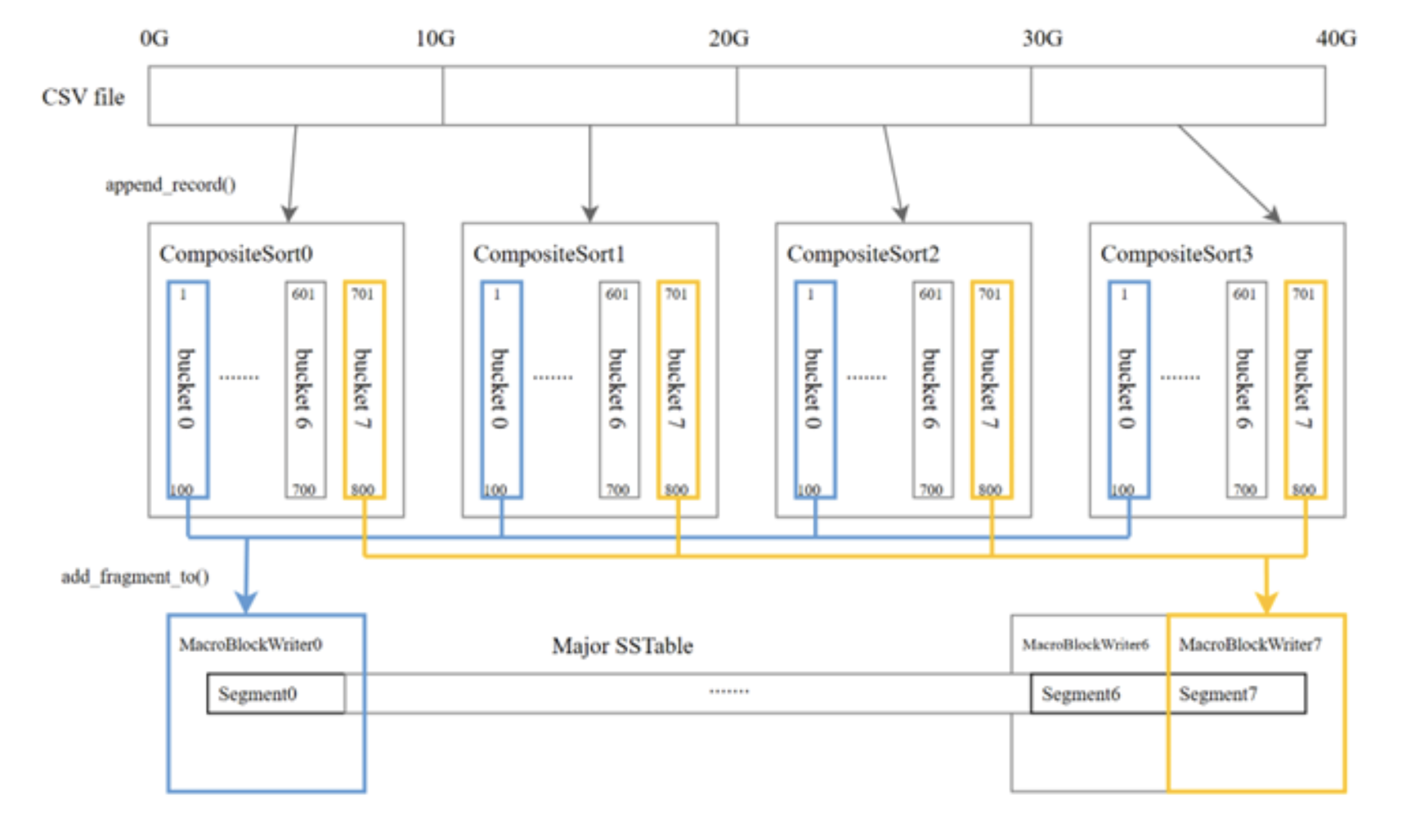
受到快速排序以及桶排序的启发,我们首先根据线程数量划分n个数值范围,例如4线程读4线程写,此时我们需要将范围划分为4个段。例如0-100,101-200,201-300,301-400。每个线程中我们创建4个ObExternalSort,每个ObExternalSort只负责各自范围内的数据,当文件读取完并排序完成后,我们再将每个线程中对应范围的ObFragmentIterator各自集中到一起,例如将四个线程中负责0-100范围的集中到一起就能够获得0-100整体有序的数据,同样的再将其他三个范围的集中,那我们就能获得四个范围内有序,并且范围间有序的数据,然后四个线程各自取各自范围内的数据写 SSTable 就可以保证写的部分不重叠了。
04. 多线程写 SSTable
前面的实现完成后,这部分反而是最简单的。
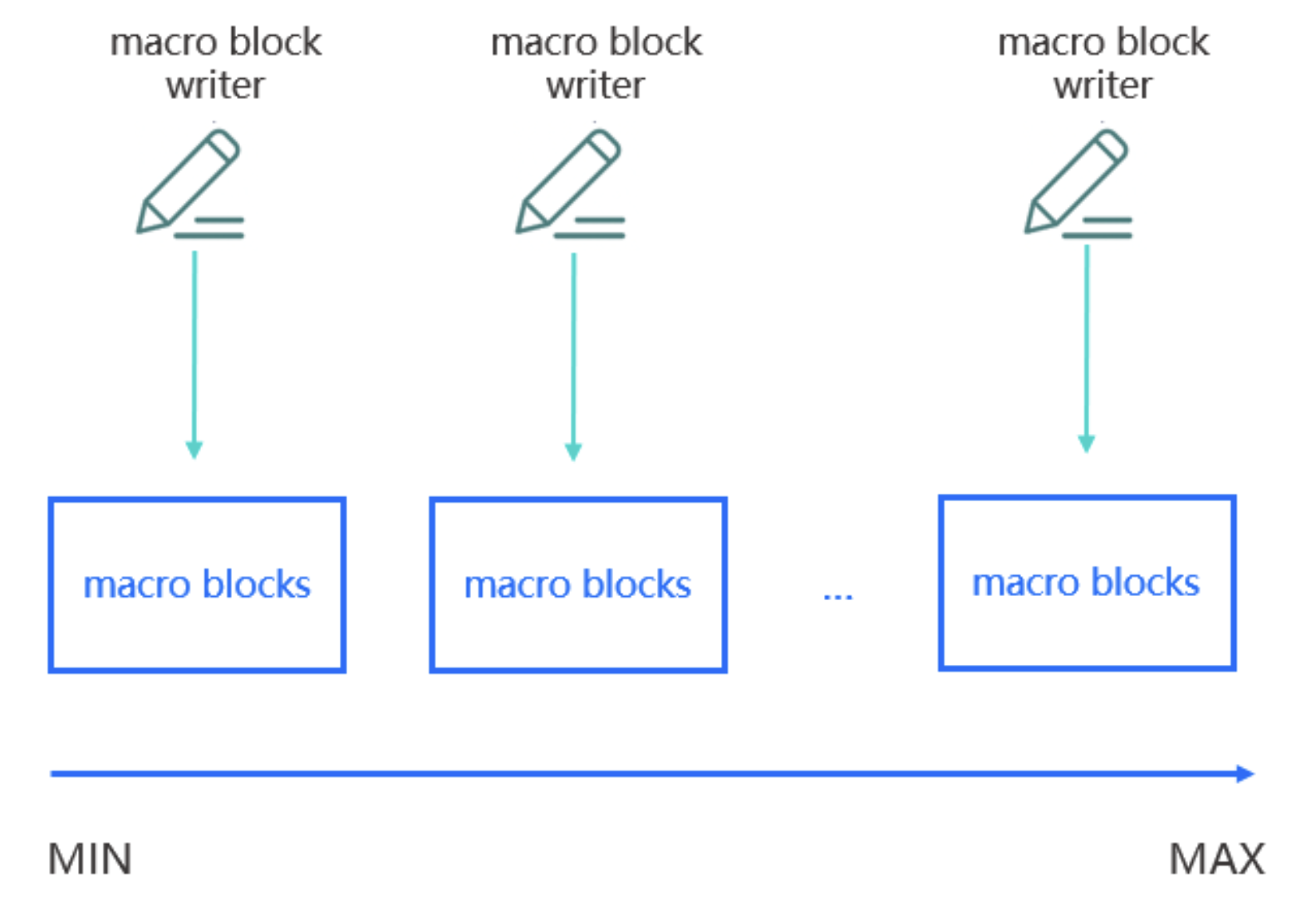
根据 OceanBase 的文档,SSTable 的一个基本单位是一个宏块,可以创建多个 macro_block_writer,每个 macro_block_writer 写各自范围的数据即可,因此可以每个线程维护一个 macro_block_writer,其用法如下:
ObSSTableIndexBuilder sstable_index_builder;
ObDataStoreDesc data_store_desc;
data_store_desc.sstable_index_builder_ = &sstable_index_builder;
ObMacroBlockWriter macro_block_writer;
ObMacroDataSeq data_seq;
// 设置顺序
data_seq.set_parallel_degree(parallel_idx);
macro_block_writer.open(data_store_desc, data_seq);其中关键部分就是data_seq.set_parallel_degree(parallel_idx);,这里给每个 macro_block_writer 设定一个标识,只需要保证当前范围的 parallel_idx 大于前面范围的 parallel_idx 即可。
05. 一些小细节
1. 多线程同步
前面提到,我们需要第一阶段,也就是全部数据排完序后才能开始写,但是多线程执行时间是不确定的,因此我们需要一个机制来等待所有线程执行完排序后通知主线程继续往下执行。
OBThreadPool 提供了一个方法wait,可以等待所有的线程执行完,但这个方法会有一定的问题,其实现为:
void Thread::wait(){if (pth_ != 0) {pthread_join(pth_, nullptr);destroy_stack();pth_ = 0;pid_ = 0;tid_ = 0;runnable_ = nullptr;}}在等待线程执行完成后,会将该线程销毁,在任务数大于线程数时,会导致剩下的任务无法被执行。因此我们采用另外一种方法,也就是条件变量的方法来进行线程间的同步。
利用std::condition_variable中的wait方法,就能够实现一个简单的线程间同步机制。
2. 线程数的确定
在确定使用多线程后,如何确定开启的线程的数目呢?
数量多了线程切换开销太大,数量少了又不利于充分利用 CPU。此次比赛给我们提供的机器以及测评机都是8核16G内存的机器,因此最好的就是最多开8线程。
根据取舍,最终我们采取的线程数量为第一阶段4线程处理,第二阶段8线程处理。
为什么前面不用8线程,反而用4线程呢?
因为在比赛的过程中,经过我们的测试发现,其性能瓶颈并没有在 CPU 上,而是在 IO 读取上。8线程读取文件和四线程读取文件速度一样,但是在写文件时,8线程比4线程更容易遇到写阻塞,导致第一阶段8线程反而会比4线程更慢。而第二阶段,因为涉及到数据的压缩,加密和解密,是一个CPU密集型操作,因此为了充分利用CPU,我们选择了使用8线程写 SSTable。
因此线程数并不是越多越好,而是需要根据实际情况分析,再来选取合适的线程数,无脑拉高线程数目可能会导致适得其反。
OceanBase 存储引擎初探——Major SSTable 生成实践
01. 组织形式——LSM Tree
在比赛过程中,我们了解到,OceanBase 采用 LSM-Tree 作为其存储引擎的结构组织方式,其核心思想就是,将离散的随机写请求都转换成批量的顺序写请求。
当用户有数据写入时,会写入内存中的 MemTable 和数据日志 log,WAL(Write-Ahead Log) 机制保证重启后通过回放数据日志,可以恢复到重启之前的状态。
当 MemTable 的数据量达到阈值,会将 MemTable 冻结为只读状态的 Frozen MemTable,冻结的同时会创建一个新的 MemTable 用于提供数据写入。后台会将 Frozen MemTable 的数据以 Rowkey 递增的次序顺序写入磁盘中,生成一个 SSTable(Sorted String table,内部有序的磁盘文件,按照 Key 排序,可以使用二分搜索的方式快速得到指定 key 的数据)。
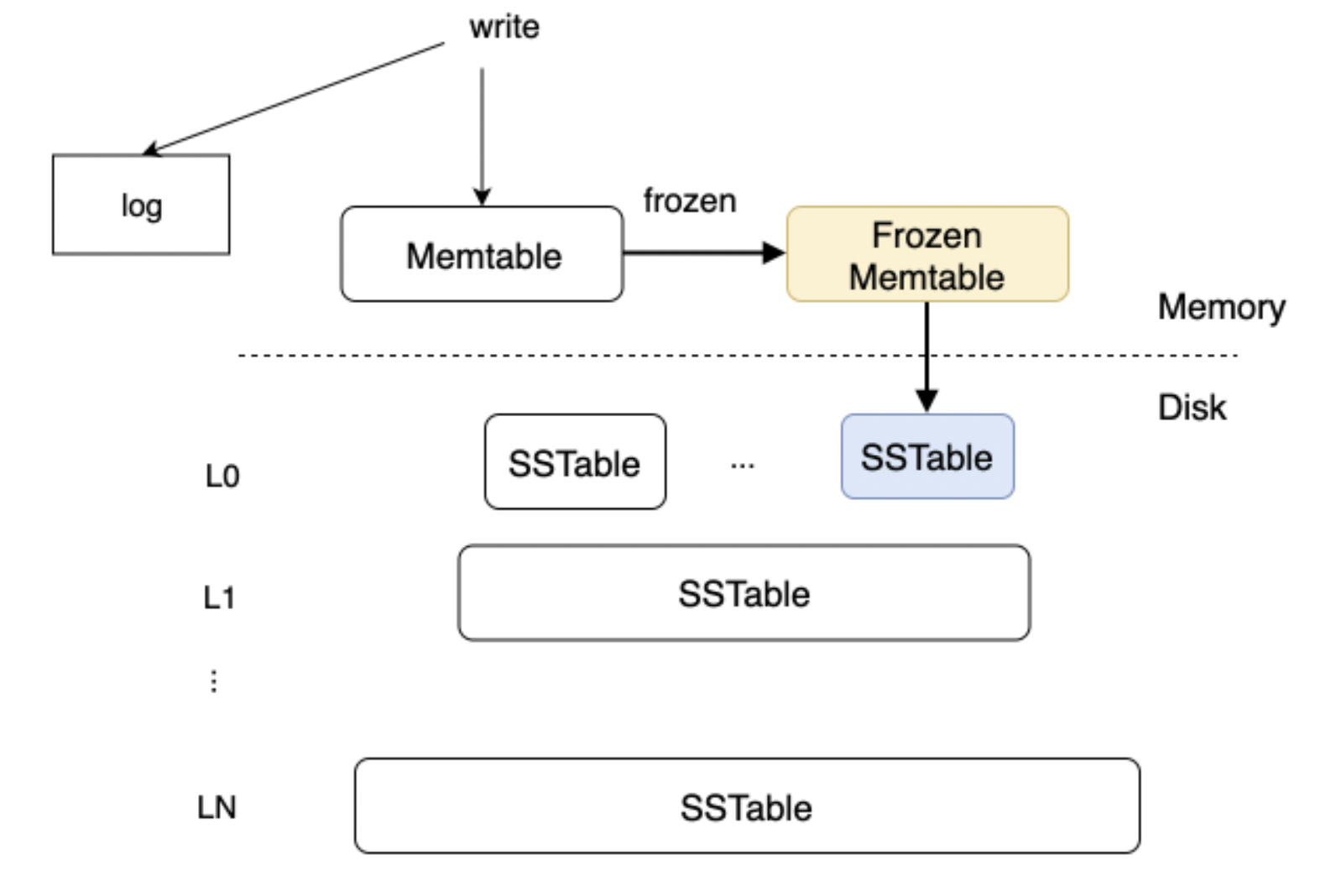
随着用户数据写入 MemTable,MemTable 超过内存阈值转化为磁盘上的 SSTable,SSTable 的数量会持续增多,导致查询需要访问的 SSTable 文件增多,降低查询的效率,因此便有了 Compaction 操作,这是对数据的一次重新整合,其实质是多路归并排序,将若干个 SSTable 按照 Rowkey 递增排序,最后输出为一个 SSTable。Compaction 的触发是由于某个 Level 的数据量超过了阈值( SSTable 会被划分为多个 Level,越下层的level数据越全越旧,最底层的 SSTable 包含全部的数据)。
磁盘中的 SSTable 根据 Compaction 策略的不同便有了不同的组织形式,常用的有Classic Leveled、Size-Tiered、Tiered & Leveled 、FIFO,OceanBase 权衡写放大、空间放大与读放大的利弊,采用了 Tiered & Leveled 方式:
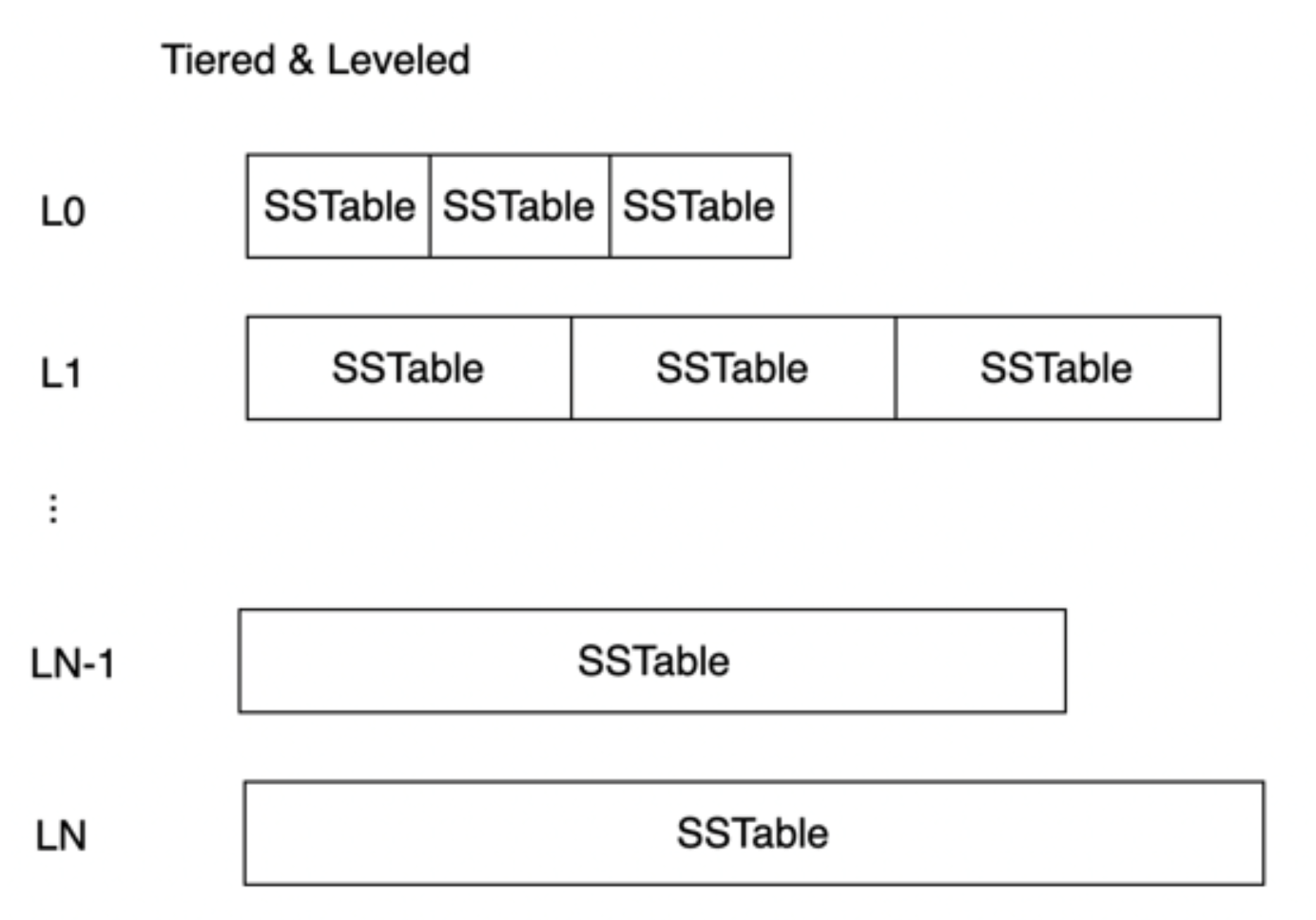
这种模式是:
对于层级较小的 Level,数据量比较小,写入的数据较新,被更新的可能性比较大,使用 Size-Tiered 模式(划分为 N 个 Level,每个 Level 可以包含多个 SSTable。相同 Level 的 SSTable 的 key range存在交集)减少写放大问题。
对于层级较大的 Level,SSTable 的数据量较大,数据比较旧不太容易被更新,使用 Leveled 模式(划分为 N 个 Level,每个 Level 仅包含一个 SSTable)减少空间放大问题。
02. MacroblockWriter 分析与并行化写入 SSTable
比赛要求的旁路导入简单来说,就是要将 csv 文件经过 Parse、排序、类型转换、写入等阶段,最终转换为 table 对应的最底层的单版本 SSTable。
为了提高效率,我们采用了多线程来实现这一过程:
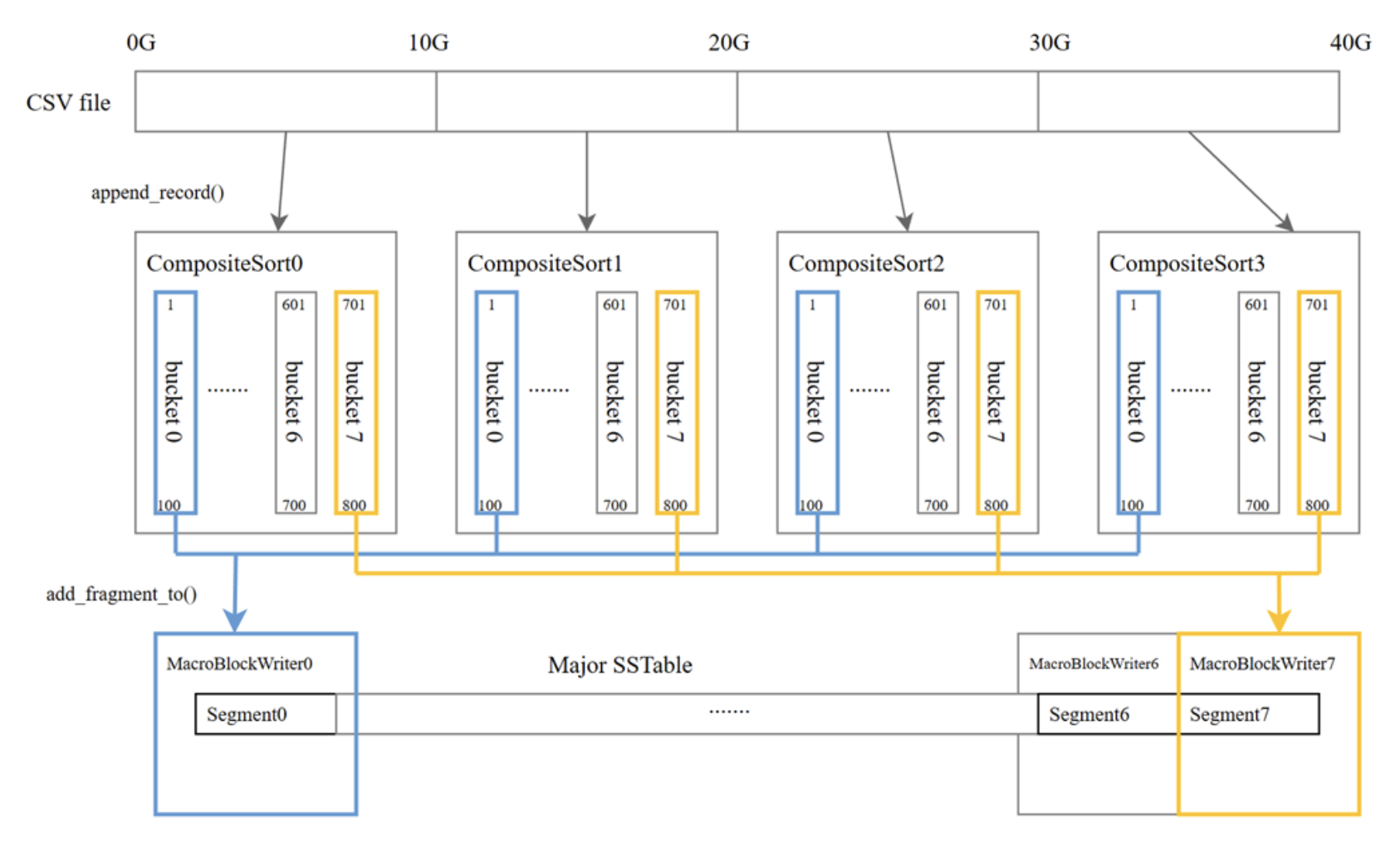
1. 将 csv 文件均匀切分为几段;
2. 让多个线程分别对每一段 CSV 执行 CompositeSort 过程(Parse->类型转换->按照数据范围分桶->对每个桶执行外部排序);
3. 将相同数据范围内的外排临时文件收集,在堆上构造有序迭代器;
4. 将每一段有序数据分配给一个线程,并行写入对应段的数据,最终构造成最底层的Major SSTable。
而构造 SSTable 需要解决以下几个问题:
- Major SSTable 的磁盘文件格式是什么样的,单文件?多文件?
- 有没有生成 SSTable 结构的接口,怎么用?
- 并行分段写入时,如何给每个线程设置初始偏移量?
经过阅读文档、源码与指导交流,我们了解到:
1. Major SSTable 按数据大小分为宏块(Macro Block)和微块(Micro Block)。宏块是数据写 I/O 的基本单位,是大小为 2M 的定长数据块;微块是数据读 I/O 的基本单位,为变长数据块,微块内部数据可以按照行存或者列式编码存储,每个宏块包含多个微块,如下图所示:
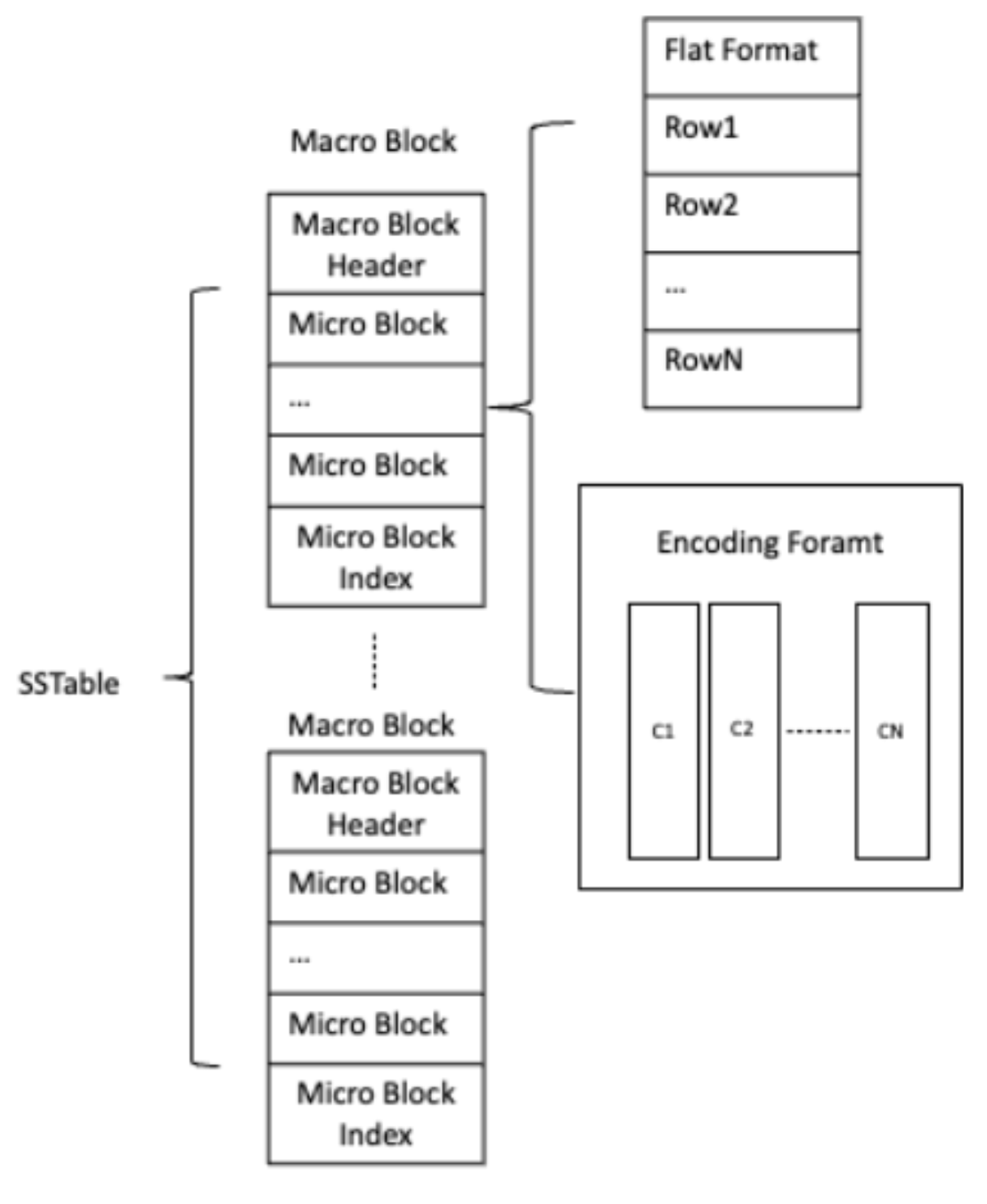
在宏块的最前面的是宏块头,记录宏块内部微块个数,微块数据起始位置等信息;后面跟着的就是一个个长度不固定的微块,存储用户数据;在微块之后,存储微块索引信息(Micro Block Index),记录每个微块在宏块内的相对偏移 Offset、每个微块的 EndRowKey 等信息。
2. OceanBase 提供 MacroBlockWriter 类来实现SSTable宏块的生成,Demo 代码中实现了单线程生成 Major SSTable 的代码,其主要流程有初始化、调用 MacroBlockWriter 的append_row(const ObDatumRow &row)函数将记录按主键顺序交给 MacroBlockWriter 处理、关闭 MacroBlockWriter 与创建 SSTable 的相关元数据。MacroBlockWriter 相关接口分析如下:
class ObMacroBlockWriter {
public:
// 根据data_store_desc中的table_id、partition_id等信息,打开一个宏块写入器
int open(ObDataStoreDesc &data_store_desc, const ObMacroDataSeq &start_seq,
ObIMacroBlockFlushCallback *callback = nullptr);
// 追加一个宏块,主要会应用在这些场景:
// 1. 在合并时,原来的SSTable的某个宏块没有修改,直接复用到当前SSTable中;
// 2. 并行合并后,也可以用到这个接口,将多个没有重合数据的宏块进行追加。
int append_macro_block(const ObMacroBlockDesc ¯o_desc);
// 追加一个微块,和append_macro_block不同的是需要考虑是否存在数据重叠:
// 1. 如果数据不重叠,则将micro_block追加到当前宏块中;
// 2. 如果数据重叠,则需要构建micro_block的reader,将数据按row写到当前宏块中。
int append_micro_block(const ObMicroBlock& micro_block);
// 追加一行数据,会调用ObMicroBlockWriter::append_row
// 主要逻辑为:
// 1. 将行数据写入到微块中,并更新 bloomfilter 和 checksum
// 2. 在当前微块写满的情况下:构建当前的微块,并切换微块写入器
int append_row(const ObDatumRow &row);
// 关闭ObMacroBlockWriter,在关闭之前,会尝试将最后两个宏块合并,节省空间,
// 最后将当前最后的宏块flush到磁盘,并等待刷盘成功(wait_io_finish)
int close();
};3. 可以通过让每个线程操作一个 MacroBlocker 的append_row(const ObDatumRow &row)的方式实现多线程写入 SSTable,每一个 MacroBlock 都有一个int64_t cur_macro_seq_的字段来表示当前宏块在 SSTable 中的编号,它被定义为一个 union:
union
{
int64_t macro_data_seq_;
struct
{
uint64_t data_seq_ : BIT_DATA_SEQ; // 32bit
uint64_t parallel_idx_ : BIT_PARALLEL_IDX; // 11bit
uint64_t block_type_ : BIT_BLOCK_TYPE; // 3bit
uint64_t merge_type_ : BIT_MERGE_TYPE; // 2bit
uint64_t reserved_ : BIT_RESERVED; // 15bit
uint64_t sign_ : BIT_SIGN; // 1bit
};
};其中,高32位的 data_seq 为递增的序列号,次11位 parallel_idx,可以用来给不同线程持有的 MacroBlockWriter 设置起始编号,使不同线程写的 MacroBlock 序列号互不冲突。
data_seq.set_parallel_degree(parallel_writer_id);
macro_block_writer->open(data_store_desc_, data_seq);

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









