







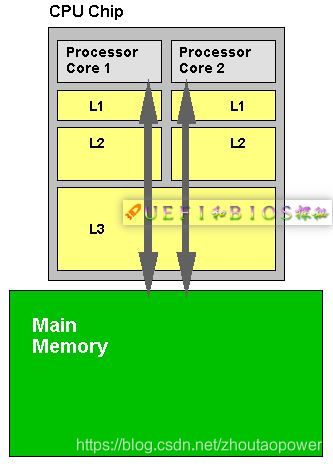
现代处理器 (CPU) 都会在主存和 CPU 之间加上几级 Cache,虽然这部分对程序员来说可能是透明的,但作为底层的程序员,咱们还是有理由去了解一下相关的原理。
1. 为什么要有 CPU Cache
随着工艺的提升最近几十年CPU的频率不断提升,而受制于制造工艺和成本限制,目前计算机的内存主要是DRAM并且在访问速度上没有质的突破。因此,CPU的处理速度和内存的访问速度差距越来越大,甚至可以达到上万倍。这种情况下传统的CPU通过FSB直连内存的方式显然就会因为内存访问的等待,导致计算资源大量闲置,降低CPU整体吞吐量。同时又由于内存数据访问的热点集中性,在CPU和内存之间用较为快速而成本较高的SDRAM做一层缓存,就显得性价比极高了。
2. 为什么要有多级 CPU Cache
随着科技发展,热点数据的体积越来越大,单纯的增加一级缓存大小的性价比已经很低了。因此,就慢慢出现了在一级缓存(L1 Cache)和内存之间又增加一层访问速度和成本都介于两者之间的二级缓存(L2 Cache)。
此外,又由于程序指令和程序数据的行为和热点分布差异很大,因此L1 Cache也被划分成L1i (i for instruction)和L1d (d for data)两种专门用途的缓存。
3. Cache 的应用
对大量典型程序运行情况的分析结果表明,在一个较短的时间间隔内,由程序产生的地址往往集中在存储器逻辑地址空间的很小范围内。指令地址的分布本来就是连续的,再加上循环程序段和子程序段要重复执行多次。因此,对这些地址的访问就自然地具有时间上集中分布的倾向。
数据分布的这种集中倾向不如指令明显,但对数组的存储和访问以及工作单元的选择都可以使存储器地址相对集中。这种对局部范围的存储器地址频繁访问,而对此范围以外的地址则访问甚少的现象,就称为程序访问的局部性。
根据程序的局部性原理,可以在主存和CPU通用寄存器之间设置一个高速的容量相对较小的存储器,把正在执行的指令地址附近的一部分指令或数据从主存调入这 个存储器,供CPU在一段时间内使用。这对提高程序的运行速度有很大的作用。这个介于主存和CPU之间的高速小容量存储器称作高速缓冲存储器 (Cache)。
系统正是依据此原理,不断地将与当前指令集相关联的一个不太大的后继指令集从内存读到Cache,然后再与CPU高速传送,从而达到速度匹配。
CPU对存储器进行数据请求时,通常先访问Cache。由于局部性原理不能保证所请求的数据百分之百地在Cache中,这里便存在一个命中率。即CPU在任一时刻从Cache中可靠获取数据的几率。
命中率越高,正确获取数据的可靠性就越大。一般来说,Cache的存储容量比主存的容量小得多,但不能太小,太小会使命中率太低;也没有必要过大,过大不仅会增加成本,而且当容量超过一定值后,命中率随容量的增加将不会有明显地增长。
只要Cache的空间与主存空间在一定范围内保持适当比例的映射关系,Cache的命中率还是相当高的。
4. Cache是怎么组织和工作的
在CPU中, Cache Memory 处于 Memory Hierarchy 的最顶端,其下是内存和外存。
那么CPU是如何访问Cache的呢?和访问内存类似,CPU微架构也对各级Cache地址空间进行了编码,只是这些编码并不能够被软件所体察。为简化起见,我们忽略各级Cache的区别,仅仅讨论一般意义上Cache的访问。
4.1 Cache 的组成和访问方式
在现代大多数处理器中,Cache被分为很多行(Cache Line),Cache Line 大小不一,从 16Bytes 到 128Bytes 不等,一般大小是64个 Bytes,打个比方,我们在这之后都认为 Cache Line 有 16 Bytes 组成。我们假设有 8KB 的 Cache,就可以划分成 512 个Cache Line

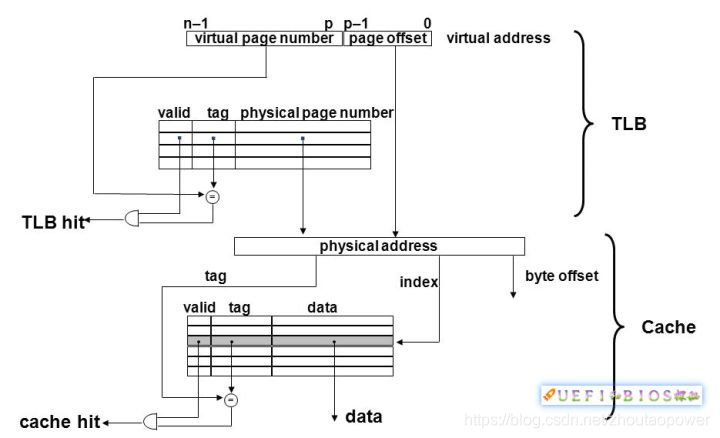
那么一个地址访问如何映射到Cache中去呢?我们都知道地址分为逻辑地址(虚拟地址)、线性地址和物理地址。一个虚拟地址通过相关的表项查询,变换成物理地址。
变换过程中线性地址到物理地址需要用到页表(page table)。页表由很多项组成,每一项叫一个页表项,整个页表由操作系统维护,并放置在内存中(或磁盘中)。
我们知道,一次内存访问需要数百个时钟周期,如果每次地址转换都要查看内存页表也太浪费时间了。现代计算机为了加速这一过程,引入了翻译后援缓冲器 TLB。TLB 可以看作页表的Cache,CPU每次转换地址都会查看TLB,如果有了就不用去取内存页表了。
那么 TLB 和 Cache有什么关系呢?可以说TLB命中是Cache命中的基本条件。TLB不命中,会更新TLB项,这个代价非常大,Cache命中的好处基本都没有了。在TLB命中的情况下,物理地址才能够被选出,Cache的命中与否才能够达成。如下图:
4.2 Cache Mapping
从前文可以看出知道物理地址,那就能够知道 Cache 命中与否。那么Cache地址和物理地址的对应关系有很多种。我们先看两个极端的例子:
4.2.1 直接映射(Direct Mapping)
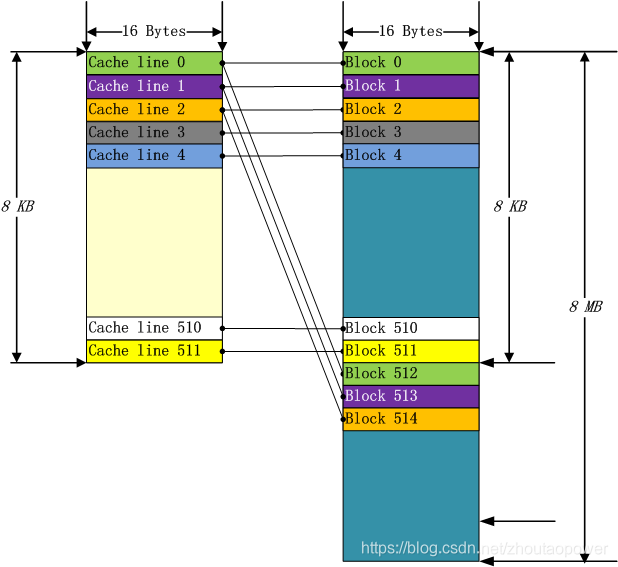
直接映射的方式可以理解为,每一个内存的地址唯一指定会映射到固定的 Cache Line 上,比如我们有 8KB 大小的 cache,每一个 Cache Line 由 16 Bytes 构成,这样这个 Cache 中就有 512 个这样的 Cache Line,Cache Line 是进行替换的最小单位,直接映射的方式如下所示:
这样做看起来很高效,哪有那些坏处呢?那就是Cache Miss率极高,因为数据的相关性和局限性,同一时刻需要用的数据大部分都在附近,会造成Cache频繁换进换出,造成颠簸。一个改进的做法是用inteleave,但也会造成Cache Miss很大,冷热不均。
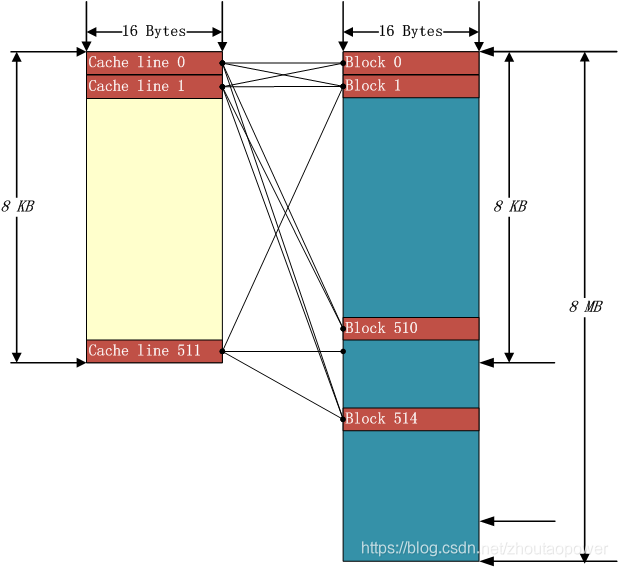
4.2.2 全相联映射(Fully Associative Mapping)
全映射就是所有Cache Line可以对应说有地址。这样Cache就不会造成冷热不均,Cache Miss减小了很多,但与此同时带来了另外的问题,那就是查找Cache命中与否的代价(Over head)很高。一条不命中的寻找,要遍历整个Cache,才能最终确定下来。
直接映射在Cache刚刚发明时大行其道,但随着Cache的发展,它的问题也被暴露了出来,于此同时全相连也不是很好的解决办法。人们退而求其次,在两个极端方法直接寻找平衡,提出了n路组相联映射(n-ways Set-Associative mapping):
4.2.3 n 路组相联映射(n-ways Set-Associative mapping)
组相联映射实际上是直接映射和全相联映射的折中方案,主存和Cache都分组,主存中一个组内的块数与Cache中的分组数相同,组间采用直接映射,组内采用全相联映射。
主存块存放到哪个组是固定的,至于存到该组哪一块则是灵活的。
n way 中的 n 常用的有 2、4、8、16,这里的含义就是,每组(set)含有几个 Cache line,比如,8KB 大小的 Cache,一个 Cache Line 为 16 Bytes,4-way set 相关的情况下,那么一个 Set=4*16=64 Bytes,整个 Cache 被分为了 8KB/64Bytes=128组(Set):
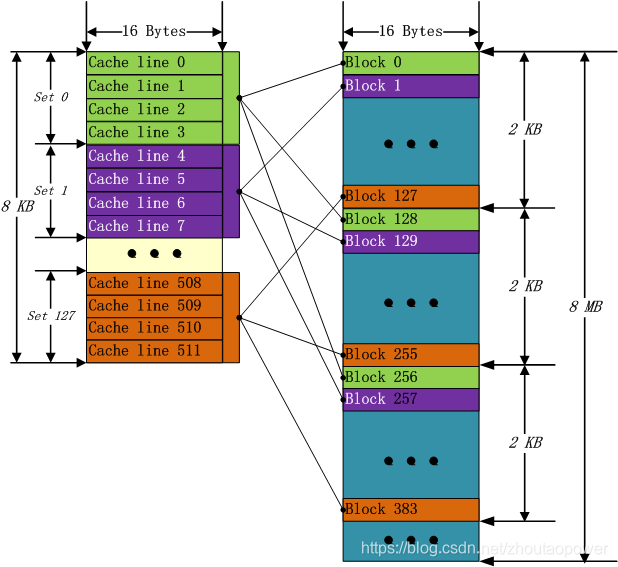
可以看出和直接映射很像,不同点在于一个在一组中,第一个没找到,可以找下一个,直到该组的最后一个。这样,可以结合两者的优点。
4.3 现实的选择
n-ways Set-Associative,这个n=1,就是直接映射;n=cache大小,就是全相关映射。我们从上面知道两者都不好,而n最好取中间某个值。那么n到底该选几呢?这比较复杂,和Cache的速度和大小、内存的速度、主频等等很多都相关,在很多情况下都是个经验值,也是大量pre-silicon实验的结果。
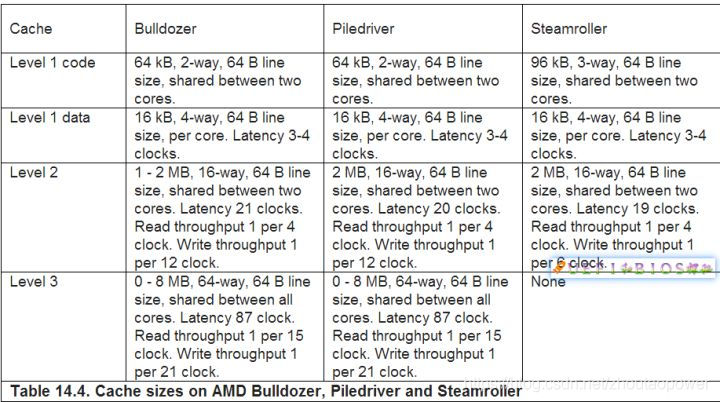
我们来看看现实生活中L1,L2和L3都是几路相连映射:
AMD 的:
Intel 的:
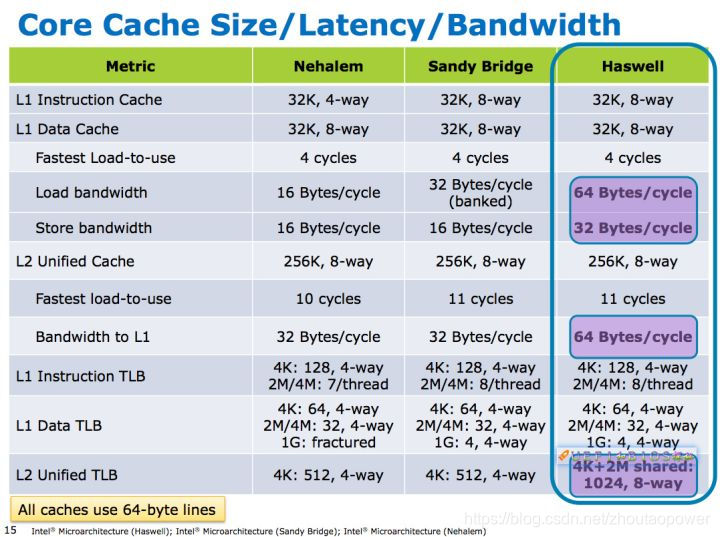
从中我们可以看出各级Cache选择几路都不一样,而且不同代际之间也会微调。Intel都是2的幂,而AMD则会有3路之类的奇葩路数。
5. 带 Cache 的 CPU 内存读写
在CPU与主存之间增加了Cache之后,便存在数据在CPU和Cache及主存之间如何存取的问题。读写各有2种方式。
1. 贯穿读出式(Look Through)
该方式将Cache隔在CPU与主存之间,CPU对主存的所有数据请求都首先送到Cache,由Cache自行在自身查找。如果命中,则切断CPU对主存的请求,并将数据送出;不命中,则将数据请求传给主存。
该方法的优点是降低了CPU对主存的请求次数,缺点是延迟了CPU对主存的访问时间。
2. 旁路读出式(Look Aside)
在这种方式中,CPU发出数据请求时,并不是单通道地穿过Cache,而是向Cache和主存同时发出请求。由于Cache速度更快,如果命中,则 Cache在将数据回送给CPU的同时,还来得及中断CPU对主存的请求;不命中,则Cache不做任何动作,由CPU直接访问主存。
它的优点是没有时间延迟,缺点是每次CPU对主存的访问都存在,这样,就占用了一部分总线时间。
3. 写穿式(Write Through)
任一从CPU发出的写信号送到Cache的同时,也写入主存,以保证主存的数据能同步地更新。
它的优点是操作简单,但由于主存的慢速,降低了系统的写速度并占用了总线的时间。
4. 回写式(Copy Back)
为了克服贯穿式中每次数据写入时都要访问主存,从而导致系统写速度降低并占用总线时间的弊病,尽量减少对主存的访问次数,又有了回写式。
它是这样工作的:数据一般只写到Cache,这样有可能出现Cache中的数据得到更新而主存中的数据不变(数据陈旧)的情况。但此时可在Cache 中设一标志地址及数据陈旧的信息,只有当Cache中的数据被再次更改时,才将原更新的数据写入主存相应的单元中,然后再接受再次更新的数据。这样保证了 Cache和主存中的数据不致产生冲突。
ARM cache 策略
Cache的写策略分为直写策略和回写策略。同时向cache行和相应的主存位置写数据,同时更新这两个地方的数据的方法称为直写策略 (writethrough),把数据写入cache行,不写入主存的或者只有当cache被替换时或清理cache行时才写入主存的策略称为回写策略 (writeback)。采用回写策略时,当处理器cache命中,只向cache存储器写数据,不写入主存,主存里的数据就和cache里不一 致,cache里的数据是最新的,主存里的数据是早前的。这就用cache存储器信息状态标志位了,当向cache存储器里某行写数据时,置相应行的信息 标志脏位为1,那么主控制器下次访问cache存储器就知道cache里有主存没有的数据了,把数据写回到主存中去。
当一个cache访问失效时,cache控制器必须从当前有效行中取出一个cache行存储从主存中取到的信息,被选中替换的cache行称为丢弃者,如 果这个cache行中脏位为1则应把该cache行中的数据回写到主存中,而替换策略决定了那个cache行会被替换,在arm926ejs中ARM支持 两种策略:轮转策略和伪随机策略。轮转策略就是取当前cache行的下一行,伪随机策略是控制器随机产生一个值。
当cache失效时,ARM采取两种方式分配cache行,一种是读操作(read-allocate)还有一种是读-写分配策略(read- write-allocate),当cache未命中时对于读操作策略,在对cache存储器读操作时才会分配cache行
参考文献:
https://my.oschina.net/fileoptions/blog/1630855
https://zhuanlan.zhihu.com/p/31859105
https://blog.csdn.net/linyangspring/article/details/24719971
http://www.cnblogs.com/hoys/archive/2013/04/22/3036837.html
http://cenalulu.github.io/linux/all-about-cpu-cache/


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









