







本节要点:
- 表达式类型自动提升的陷阱
- 复合赋值运算符隐含的类型转换
- 原始类型带来的泛型擦除
- Java 不支持泛型数组
- 正则表达式中点号(.)匹配任意字符
- 不要调用线程对象的 run() 方法
- 静态同步方法的同步监视器是类
- 多线程执行环境的线程安全问题
1 JVM 对字符串的处理
先看一条创建字符串对象的代码,如下:
String str = new String("hello");该代码创建了几个对象?
该代码实际创建了 2 个字符串对象,一个是 “hello” 这个直接量(会缓存在字符串缓存池中)对应的字符串对象,一个是由 new String()构造器返回的字符串对象。
**注:**Java 创建对象的常规方式有如下 4 种:
1) 通过 new 调用构造器创建对象;
2) 通过 Class 对象的 newInstance() 方法调用构造器创建对象;
3) 通过 Java 的反序列号机制从 IO 流中恢复 Java 对象;
4) 通过 Java 对象提供的 clone() 方法复制一个新的 Java 对象。
此外,对于 String 以及 Boolean、Byte、Short、Integer、Long、Character、Float、Double这些基本类型对应的包装类,可以以直接量的方式来创建对象,如:
String str = "aaa";
Integer num = 5;对于程序中的字符串常量,JVM 会使用一个字符串缓存池来保存。
字符串连接表达式的值(如 “aaa”+”bbb”)可以在程序编译时就确定下来,并让引用变量指向字符串常量池中对应的字符串。
若字符串连接表达式中使用了变量,或者调用了方法,那就只能等到运行时才可确定该字符串连接表达式的值,此时无法在编译时确定该字符串变量的值。
所以:当程序中需要使用字符串、基本类型包装类的实例时,应该尽量使用字符串直接量、基本类型值的直接量,避免通过 new String()、new Integer() 的形式来创建实例,以保证较好的性能。
2 表达式类型的陷阱
类型的自动提升
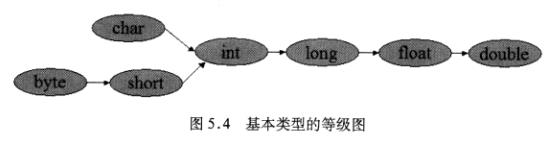
当表达式中包含多个基本类型的值时,整个算术表达式的数据类型将发生自动提升,规则如下:
- 所有 byte 型、short 型和 char 型将被提升到 int 型
- 整个算术表达式的数据类型自动提升到与表达式中最高等级操作数同样的类型。
程序不能自动向下转型(如将一个 int 值赋给 short 类型的变量),否则在编译期间就会提示“可能丢失精度”的错误。
// 自动将 'a'、7 转换为字符串
System.out.println("Hello"+'a'+7); // Helloa7
// 将 'a' 转换为 int 处理
System.out.println('a'+7+"Hello"); // 104Hello复合赋值运算符的陷阱
short sValue = 5;
// sValue = sValue - 2; // 提示错误
sValue -= 2; // 编译通过对于上面的代码,sValue - 2 会自动提升为 int 类型,然后将 int 值赋给 short 类型的变量导致编译错误,而用复合运算符就能正常编译。
因为复合运算符(如 +=、-=、<<= 等)包含了一个隐式的类型转换,即下面两条语句并不等价:
a = a + 2;
a += 2;a += 2; 等价于 a = (a 的类型)(a + 2); 即复合运算符会自动将它计算的结果值强制转为其左侧变量的类型。该强制类型转换将有可能导致高位“截断”,丢失精度。或者int 的值较大,转为 short 时超过其接受的范围值(-32768 ~ 32767),造成溢出。
可见,复合运算符虽然简单、方便,而且具有性能上的优势,但有潜在的隐式类型转换危险,可能导致计算结果的高位被“截断”,或因向下强转造成值溢出。
为了避免这种潜在的危险,需特别注意如下几种情况:
1) 将符合运算符用于 byte、short 或 char 等类型的变量
2) 将符合运算符用于 int 类型变量,而表达式右侧是 long、float 或 double 等类型的值
3) 将符合运算符用于 long 类型变量,而表达式右侧是 double 类型的值
这 3 种情况都可能导致结果值的高位被“截断”,从而导致数据精度丢失。
3 泛型可能引起的错误
对于 List<Integer>类型,编译器会认为该集合的每个元素都是 Integer 类型,若代码中有 String str = list.get(i); 这样的赋值语句,编译器会提示编译错误。
对于泛型需要注意如下 3 点:
1) 当程序把原始类型的变量赋给带泛型的变量时,总是可以通过编译,但会提示警告信息;
2) 当访问带泛型声明的集合中的元素时,编译器总是把该元素当成泛型类型处理,并不关心集合里元素的实际类型;
3) JVM 在遍历每个集合元素时自动执行强制转型,若元素的实际类型与泛型信息不匹配,在运行时将引发 ClassCastException。
原始类型带来的擦除
当把一个具有泛型信息的对象赋给另一个没有泛型信息的变量时,所有泛型信息都将被丢弃。如:将 List<String>类型的对象赋给 List 变量,则该集合元素的类型检查变成了原泛型的上限(即 Object)。
这种擦除不仅会擦除使用该 Java 类时传入的类型实参,而且会擦除所有的泛型信息。
4 正则表达式的陷阱
先看如下程序:
String str = "www.abc.org";
// 需求:将字符串以点号.分割成多个字符
String[] strArr = str.split(".");
for(String s : strArr){
System.out.println(s);
}运行程序,输出结果为空。
对于上面代码,需要注意如下两点:
1) String 提供的 split(String regex)方法的入参是正则表达式;
2) 正则表达式中的点号(.)可匹配任意字符。
所以上面程序实际上不是以点号为分隔符,而是以任意字符作为分隔符。
只对点号进行转义(\.)即可实现分割需求。
5 多线程的陷阱
1. 不要调用 run 方法
从 JDK 1.5 开始,Java 提供了 3 种方式来创建、启动多线程:
1) 继承 Thread 类来创建线程类,重写 run() 方法作为线程执行体;
2) 实现 Runnable 接口来创建线程类,重写 run() 方法作为线程执行体;
3) 实现 Callable 接口来创建线程类,重写 call() 方法作为线程执行体。
第二种和第三种方式的本质是一样的,只是 Callable 接口里包含的 call 方法即可以声明抛出异常,也可以拥有返回值。
第一种方式的效果最差,有两点不足:
① 线程类继承了 Thread 类,无法再继承其它类;
② 因为每条线程都是一个 Thread 子类的实例,因此多个线程之间共享数据比较麻烦。
通过继承 Thread 类创建线程时,一定要调用 start() 方法来启动线程,若程序没有调用线程对象的 start() 方法启动线程,那么该线程对象将一直处于“新建”状态,不会作为线程获得执行的机会,只是一个普通的 Java 对象,此时调用线程对象的 run() 方法时,与调用普通方法无异。
2. 静态的同步方法
任何线程进入同步方法、同步代码块之前,必须先获取同步方法、同步代码块对应的同步监视器(锁)。
对于同步代码块,程序必须显式的指定同步监视器;
对于非静态同步方法,该方法的同步监视器是 this,即调用该方法的 Java 对象;
对于静态的同步方法,该方法的同步监视器是该类本身。
静态同步方法(以类本身为监视器)和以 this 为同步监视器的同步代码块可以同时执行,不会相互影响(锁不同)。
静态同步方法和指定以当前类为同步监视器的同步代码块不能同时执行,必须等正执行的方法释放锁后才能执行另外一个同步方法。
public void test(){
synchronized (SynchronizedStatic.class){
...
}
}参考资料:
疯狂Java:突破程序员基本功的16课-表达式中的陷阱















 630
630











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









