






1_JAVA_并发
并发:
volatile: 内存可见性 、 防止指令重排序
volatile 使用场景:
1. 写入变量时不依赖变量当前值; 或者能够确保只有单一的线程修改变量的值
2. 变量不需要与其他的状态变量共同参与不变约束
3. 访问变量时,没有其他的原因需要加锁
乐观锁: 版本 , CAS 算法
悲观锁: synchronized , ReentrantLock
线程池 , ThreadLocal
ThreadPoolExecutor(
int corePoolSize,//核心线程数
int maximumPoolSize,//最大线程数
long keepAliveTime,//存活时间
TimeUnit unit,//单位
BlockingQueue workQueue,//阻塞队列
ThreadFactory threadFactory,//线程工厂
RejectedExecutionHandler handler//拒绝策略
)
// 拒绝策略
Abort 抛异常
Discard 悄悄扔掉
DiscardOld 扔掉最先的任务
CallerRuns 谁提交任务谁来执行
各个参数的配置
实现多线程的三种方式
Thread
Runnable
Callable
每个线程都有自己的程序计数器,栈,本地变量
编写线程安全的代码, 本质上都是管理对状态的访问,而且通常是共享的,可变的状态
线程安全: 在不可控的并发访问中保护数据
同步:
synchronized
volatile
显式锁
原子变量:
AtomicInteger
AtomicLong
AtomicReference
原子变量, 各个原子变量必须是独立的,更新一个变量时候要在同一个原子操作中更新其他几个
为了保护状态的一致性,要在单一的原子操作中更新互相关联的状态变量
ThreadLocal
检查再运行 --> 惰性初始化
竞争条件
活跃度
性能
弱并发 poor concurrency
共享对象
内存可见性
非原子的64位操作: volatile
JVM
-server 模式
-client 模式
加锁 可以保证 可见性和原子性
volatile 只能保证可见性, 不保证原子性
发布和溢出
如果希望在构造函数中注册一个监听器或者启动线程, 可以创建一个私有的构造方法和一个公有的工厂方法
线程封闭
池化技术
Ad-hoc 线程限制
栈限制
不可变对象永远是线程安全的
1 、在java中守护线程和本地线程区别?
java中分为 守护线程(Daemon Thread)和用户线程(UserThread), 只要有一个用户线程在运行, 守护线程就
会一直运行,当所有用户线程都停止工作之后,守护线程就会随着JVM一起停止工作, 典型的守护线程就是
垃圾收集线程(GC)
thread.setDaemon(true); //必须在start线程之前就设置, 否则会出现 IllegalThreadStateException
守护线程中产生的新线程也是Daemon的
不是所有的应用都可以分配给Daemon来进行服务的,比如读写操作或者计算逻辑,一旦User退出了,
数据还没有来得及读入或者写出,计算任务也可能多次运行结果不一样.
2 、线程与进程的区别?
线程的概念
概念:线程是进程中执行运算最小的单位,是进程中的一个实体,是被系统独立调度和分配的,线程不自己拥有系统资源,只拥有运行中必不可少的资源,但是它可与同属于一个进程中其它线程共享所拥有的资源
一个线程可以创建和撤销另一个线程,同一进程中多个线程可以并发执行
线程和进程的区别
一个线程只属于一个进程,但是一个进程可以拥有多个线程,但至少一个线程
资源分配个进程,同一进程中所有线程共享该进程的所有资源。
3 、什么是多线程中的上下文切换?
从任务保存到再加载的过程就是一次上下文切换
如何减少上下文切换
既然上下文切换会导致额外的开销,因此减少上下文切换次数便可以提高多线程程序的运行效率。减少上下文切换的方法有无锁并发编程、CAS算法、使用最少线程和使用协程。
无锁并发编程。多线程竞争时,会引起上下文切换,所以多线程处理数据时,可以用一些办法来避免使用锁,如将数据的ID按照Hash取模分段,不同的线程处理不同段的数据
CAS算法。Java的Atomic包使用CAS算法来更新数据,而不需要加锁
使用最少线程。避免创建不需要的线程,比如任务很少,但是创建了很多线程来处理,这样会造成大量线程都处于等待状态
协程。在单线程里实现多任务的调度,并在单线程里维持多个任务间的切换
4 、死锁与活锁的区别,死锁与饥饿的区别?
死锁:是指两个或两个以上的进程(或线程)在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。
产生死锁的必要条件:
互斥条件:所谓互斥就是进程在某一时间内独占资源。
请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
不剥夺条件:进程已获得资源,在末使用完之前,不能强行剥夺。
循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
活锁:任务或者执行者没有被阻塞,由于某些条件没有满足,导致一直重复尝试,失败,尝试,失败。
活锁和死锁的区别在于,处于活锁的实体是在不断的改变状态,所谓的“活”, 而处于死锁的实体表现为等待;活锁有可能自行解开,死锁则不能。
饥饿:一个或者多个线程因为种种原因无法获得所需要的资源,导致一直无法执行的状态。
Java中导致饥饿的原因:
高优先级线程吞噬所有的低优先级线程的CPU时间。
线程被永久堵塞在一个等待进入同步块的状态,因为其他线程总是能在它之前持续地对该同步块进行访问。
线程在等待一个本身也处于永久等待完成的对象(比如调用这个对象的wait方法),因为其他线程总是被持续地获得唤醒。
5 、Java中用到的线程调度算法是什么?
抢占式。一个线程用完CPU之后,操作系统会根据线程优先级、线程饥饿情况等数据算出一个总的优先级并分配下一个时间片给某个线程执行
6 、什么是线程组,为什么在Java中不推荐使用?
之所以要提出“线程组”的概念,一般认为,是由于“安全”或者“保密”方面的理由。根据Arnold和Gosling的说法:“线程组中的线程可以修改组内的其他线程,包括那些位于分层结构最深处的。一个线程不能修改位于自己所在组或者下属组之外的任何线程”
线程组ThreadGroup对象中的stop,resume,suspend会导致安全问题,主要是死锁问题,已经被官方废弃,多以价值已经大不如以前。
线程组ThreadGroup不是线程安全的,在使用过程中不能及时获取安全的信息。
7 、为什么使用Executor框架?
什么是 Executor框架?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZK2Gea3O-1618135569555)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210404093819705.png)]
oskernel操作系统核心包括操作系统软件和应用,只是操作系统最基本的功能,例如内存管理,进程管理,硬件驱动等
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ap8rsqc2-1618135569557)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210404094308329.png)]
Executors 框架类图, 涉及的核心类:
Executor 接口
ExecutorService extends Executor 接口
//等待之前提交的任务执行完成之后就关闭,不接受新提交的任务
void shutdowm();
//
List shutdownNow();
// 是否已经关闭
boolean isShutdown();
//如果在shutdown之后,所有任务都完成,返回true, 如果在这之前没有调用 shutdown() 或者shutdownNow() 则返回false
boolean isTerminated();
//
boolean awaitTermination(long timeout,TimeUnit unit) throws InterruptedException;
Future submit(Callable task);
Future submit(Runnable task , T result);
Future<?> submit(Runnable task);
List<Future> invokeAll(Collection<? extends Callable> tasks) throws InterruptedException;
List<Future> invokeAll(Collection<? extends Callable> tasks,
long timeout, TimeUnit unit)
throws InterruptedException;
T invokeAny(Collection<? extends Callable> tasks) throws
InterruptedException,ExecutionException;
T invokeAny(Collection<? extends Callable> tasks, long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
ScheduledExecutorService
Executors
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Q8P7RVS9-1618135569558)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210404111149473.png)]
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue());
}
1、如果当前运行的线程数少于corePoolSize,则创建新线程来执行任务。
2、在线程池完成预热之后(当前运行的线程数等于corePoolSize),将任务加入LinkedBlockingQueue。
3、线程执行完1中的任务后,会在循环中反复从LinkedBlockingQueue获取任务来执行。
FixedThreadPool使用无界队列LinkedBlockingQueue作为线程池的工作队列(队列的容量为Integer.MAX_VALUE)。使用无界队列作为工作队列会对线程池带来如下影响
1、当线程池中的线程数达到corePoolSize后,新任务将在无界队列中等待,因此线程池中的线程数不会超过corePoolSize。
2、由于1,使用无界队列时maximumPoolSize将是一个无效参数。
3、由于1和2,使用无界队列时keepAliveTime将是一个无效参数。
4、由于使用无界队列,运行中的FixedThreadPool(未执行方法shutdown()或shutdownNow())不会拒绝任务(不会调用RejectedExecutionHandler.rejectedExecution方法)。
fixedThreadPool 使用场景
FixedThreadPool适用于为了满足资源管理的需求,而需要限制当前线程数量的应用场景,它适用于负载比较重的服务器
singleThreadExecutor
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue()));
}
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue(),threadFactory));
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-14ZyDNiX-1618135569559)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210404114346358.png)]
1、如果当前运行的线程数少于corePoolSize(即线程池中无运行的线程),则创建一个新线程来执行任务。
2、在线程池完成预热之后(当前线程池中有一个运行的线程),将任务加入LinkedBlockingQueue。
3、线程执行完1中的任务后,会在一个无限循环中反复从LinkedBlockingQueue获取任务来执行。
使用场景
SingleThreadExecutor适用于需要保证顺序地执行各个任务;并且在任意时间点,不会有多个线程是活动的应用场景。
CachedThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue());
}
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue(),
threadFactory);
}
CachedThreadPool的corePoolSize被设置为0,即corePool为空;maximumPoolSize被设置为Integer.MAX_VALUE,即maximumPool是无界的。这里把keepAliveTime设置为60L,意味着CachedThreadPool中的空闲线程等待新任务的最长时间为60秒,空闲线程超过60秒后将会被终止。
FixedThreadPool和SingleThreadExecutor使用无界队列LinkedBlockingQueue作为线程池的工作队列。CachedThreadPool使用没有容量的SynchronousQueue作为线程池的工作队列,但CachedThreadPool的maximumPool是无界的。这意味着,如果主线程提交任务的速度高于maximumPool中线程处理任务的速度时,CachedThreadPool会不断创建新线程。极端情况下,CachedThreadPool会因为创建过多线程而耗尽CPU和内存资源
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YhJvlS8v-1618135569560)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210404115557110.png)]
SynchronousQueue
1、首先执行SynchronousQueue.offer(Runnable task)。如果当前maximumPool中有空闲线程正在执行SynchronousQueue.poll(keepAliveTime,TimeUnit.NANOSECONDS),那么主线程执行offer操作与空闲线程执行的poll操作配对成功,主线程把任务交给空闲线程执行,execute()方法执行完成;否则执行下面的步骤2)。
2、当初始maximumPool为空,或者maximumPool中当前没有空闲线程时,将没有线程执行SynchronousQueue.poll
(keepAliveTime,TimeUnit.NANOSECONDS)。这种情况下,步骤1)将失败。此时CachedThreadPool会创建一个新线程执行任务,execute()方法执行完成。
3、在步骤2)中新创建的线程将任务执行完后,会执行SynchronousQueue.poll(keepAliveTime,
TimeUnit.NANOSECONDS)。这个poll操作会让空闲线程最多在SynchronousQueue中等待60秒钟。如果60秒钟内主线程提交了一个新任务(主线程执行步骤1)),那么这个空闲线程将执行主线程提交的新任务;否则,这个空闲线程将终止。由于空闲60秒的空闲线程会被终止,因此长时间保持空闲的CachedThreadPool不会使用任何资源。
前面提到过,SynchronousQueue是一个没有容量的阻塞队列。每个插入操作必须等待另一个线程的对应移除操作,反之亦然。CachedThreadPool使用SynchronousQueue,把主线程提交的任务传递给空闲线程执行。CachedThreadPool中任务传递的示意图如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oPzkqfy6-1618135569561)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210404120303997.png)]
使用场景
看名字我们可以知道cached缓存,CachedThreadPool可以创建一个可根据需要创建新线程的线程池,但是在以前构造的线程可用时将重用它们,对于执行很多短期异步任务的程序而言,这些线程池通常可提高程序性能。调用 execute 将重用以前构造的线程(如果线程可用)。如果现有线程没有可用的,则创建一个新线程并添加到池中。
CachedThreadPool是大小无界的线程池,适用于执行很多的短期异步任务的小程序,或者是负载较轻的服务器。
ThreadFactory
AbstractExecutorService
ThreadPoolExecutor
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
threadFactory, defaultHandler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
RejectedExecutionHandler handler) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), handler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
BlockingQueue
Queue
ScheduledThreadPoolExecutor
ScheduledThreadPoolExecutor继承自ThreadPoolExecutor。它主要用来在给定的延迟之后运行任务,或者定期执行任务。ScheduledThreadPoolExecutor的功能与Timer类似,但ScheduledThreadPoolExecutor功能更强大、更灵活。Timer对应的是单个后台线程,而ScheduledThreadPoolExecutor可以在构造函数中指定多个对应的后台线程数
Executors中创建:
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
ScheduledThreadPoolExecutor 构造器
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue());
}
public ScheduledThreadPoolExecutor(int corePoolSize,
RejectedExecutionHandler handler) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue(), handler);
}
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue(), threadFactory);
}
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), threadFactory, handler);
}
SingleThreadScheduledExecutor
public static ScheduledExecutorService newSingleThreadScheduledExecutor() {
return new DelegatedScheduledExecutorService (new ScheduledThreadPoolExecutor(1));
}
public static ScheduledExecutorService newSingleThreadScheduledExecutor(ThreadFactory threadFactory) {
return new DelegatedScheduledExecutorService (new ScheduledThreadPoolExecutor(1, threadFactory));
}
运行过程
DelayQueue是一个无界队列,所以ThreadPoolExecutor的maximumPoolSize在ScheduledThreadPoolExecutor中没有什么意义(设置maximumPoolSize的大小没有什么效果)。ScheduledThreadPoolExecutor的执行主要分为两大部分。
1、当调用ScheduledThreadPoolExecutor的scheduleAtFixedRate()方法或者scheduleWithFixedDelay()方法时,会向ScheduledThreadPoolExecutor的DelayQueue添加一个实现了RunnableScheduledFuture接口的ScheduledFutureTask。
2、线程池中的线程从DelayQueue中获取ScheduledFutureTask,然后执行任务。
下面看看ScheduedThreadPoolExecutor运行过程示意图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9sJzs6d9-1618135569562)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210404160320483.png)]
ScheduledThreadPoolExecutor为了实现周期性的执行任务,对ThreadPoolExecutor做了如下
的修改。
1、使用DelayQueue作为任务队列。
2、获取任务的方式不同。
3、执行周期任务后,增加了额外的处理。
实现过程分析
ScheduledThreadPoolExecutor会把待调度的任务(ScheduledFutureTask)放到一个DelayQueue中。ScheduledFutureTask主要包含3个成员变量,如下。
1、long time,表示这个任务将要被执行的具体时间。
2、long sequenceNumber,表示这个任务被添加到ScheduledThreadPoolExecutor中的序号。
3、long period,表示任务执行的间隔周期。
DelayQueue封装了一个PriorityQueue,这个PriorityQueue会对队列中的ScheduledFutureTask进行排序。排序时,time小的排在前面(时间早的任务将被先执行)。如果两个ScheduledFutureTask的time相同,就比较sequenceNumber,sequenceNumber小的排在前面(也就是说,如果两个任务的执行时间相同,那么先提交的任务将被先执行)。首先,让我们看看ScheduledThreadPoolExecutor中的线程执行周期任务的过程。如下图所示
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JU4uQ5LT-1618135569562)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210404160544316.png)]
1、线程1从DelayQueue中获取已到期的ScheduledFutureTask(DelayQueue.take())。到期任务是指ScheduledFutureTask的time大于等于当前时间。
2、线程1执行这个ScheduledFutureTask。
3、线程1修改ScheduledFutureTask的time变量为下次将要被执行的时间。
4、线程1把这个修改time之后的ScheduledFutureTask放回DelayQueue中(DelayQueue.add())。
DelayQueue.take()的源码是如何实现的
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly(); // 1
try {
for (;😉 {
E first = q.peek();
if (first == null) {
available.await(); // 2.1
} else {
long delay = first.getDelay(TimeUnit.NANOSECONDS);
if (delay > 0) {
long tl = available.awaitNanos(delay); // 2.2
} else {
E x = q.poll(); // 2.3.1
assert x != null;
if (q.size() != 0)
available.signalAll(); // 2.3.2
return x;
}
}
}
} finally {
lock.unlock(); // 3
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VDtkO5wX-1618135569563)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210404160745097.png)]
1、获取Lock。
2、获取周期任务。
a、如果PriorityQueue为空,当前线程到Condition中等待;否则执行下面的2.2。
b、如果PriorityQueue的头元素的time时间比当前时间大,到Condition中等待到time时间;否则执行下面的2.3。
c、获取PriorityQueue的头元素(2.3.1);如果PriorityQueue不为空,则唤醒在Condition中等待的所有线程(2.3.2)。
3、释放Lock。
ScheduledThreadPoolExecutor在一个循环中执行步骤2,直到线程从PriorityQueue获取到一个元素之后(执行2.3.1之后),才会退出无限循环(结束步骤2)。
下面我来看看DelayQueue.add()源码实现
public boolean offer(E e) {
final ReentrantLock lock = this.lock;
lock.lock(); // 1
try {
E first = q.peek();
q.offer(e); // 2.1
if (first == null || e.compareTo(first) < 0)
available.signalAll(); // 2.2
return true;
} finally {
lock.unlock(); // 3
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zvjGvl8o-1618135569564)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210404161000576.png)]
1、获取Lock。
2、添加任务。
a、向PriorityQueue添加任务。
b、如果在上面2.1中添加的任务是PriorityQueue的头元素,唤醒在Condition中等待的所有线程。
3、释放Lock。
使用场景
SingleThreadScheduledExecutor适用于需要单个后台线程执行周期任务,同时需要保证顺序地执行各个任务的应用场景。
DelayedWorkQueue
RejectedExecutionHandler
Future
Runnable
RunnableAdapter
Callable
RunnableFuture
FutureTask
ReentrantLock
LinkedBlockingQueue
无界队列
8 、在Java中Executor和Executors的区别?
Executor 接口对象能执行我们的线程任务;
Executors 工具类的不同方法按照我们的需求创建了不同的线程池,来满足业务的需求。
ExecutorService 接口继承了Executor接口并进行了扩展,提供了更多的方法,我们能够获得任务执行的状态并且可以获取任务的返回值。
9 、如何在Windows和Linux上查找哪个线程使用的CPU时间最长?
Linux
(1)获取项目的pid,jps 或者 ps -ef | grep java
(2)top -H -p pid,顺序不能改变
这样就可以打印出当前的项目,每条线程占用CPU时间的百分比。注意这里打出的是LWP,也就是操作系统原生线程的线程号
使用”top -H -p pid”+”jps pid”可以很容易地找到某条占用CPU高的线程的线程堆栈,从而定位占用CPU高的原因,一般是因为不当的代码操作导致了死循环。
最后提一点,”top -H -p pid”打出来的LWP是十进制的,”jps pid”打出来的本地线程号是十六进制的,转换一下,就能定位到占用CPU高的线程的当前线程堆栈了。
windows
10 、什么是原子操作 ? 在JavaConcurrencyAPI中有哪些原子类?
原子操作 : 一个或多个操作在CPU执行过程中不被中断的特性 , 需要分清楚针对的是CPU指令级别还是高级语言级别。
比如:经典的银行转账场景,是语言级别的原子操作;
而当我们说volatile修饰的变量的复合操作,其原子性不能被保证,指的是CPU指令级别。二者的本质是一致的。
“原子操作”的实质其实并不是指“不可分割”,这只是外在表现,本质在于多个资源之间有一致性的要求,操作的中间态对外不可见。
比如:在32位机器上写64位的long变量有中间状态(只写了64位中的32位);银行转账操作中也有中间状态(A向B转账,A扣钱了,B还没来得及加钱)
原子类
AtomicBoolean
把 Boolean转成整型,再使用 compareAndSwapInt 进行操作的
AtomicInteger
AtomicIntegerArray
AtomicIntegerFieldUpdater
原子更新整型的字段的更新器
//创建原子更新器,并设置需要更新的对象类和对象的属性
private static AtomicIntegerFieldUpdater<User> ai = AtomicIntegerFieldUpdater.newUpdater(User.class, "age");
public static void main(String[] args) {
User u1 = new User("pangHu", 18);
//原子更新年龄,+1
System.out.println(ai.getAndIncrement(u1));
System.out.println(u1.getAge());
}
static class User {
private String name;
public volatile int age;
public User(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
代码详解
要想原子地更新字段类需要两步。第一步,因为原子更新字段类都是抽象类,每次使用的时候必须使用静态方法newUpdater()创建一个更新器,并且需要设置想要更新的类和属性。第二步,更新类的字段必须使用 public volatile 修饰
AtomicLong
AtomicLongArray
AtomicLongFieldUpdater
原子更新长整型字段的更新器
AtomicMarkableReference
原子更新带有标记位的引用类型,可以使用构造方法更新一个布尔类型的标记位和引用类型
AtomicReference
AtomicReferenceArray
AtomicReferenceFieldUpdater
原子更新引用类型的字段
AtomicStampedReference
原子更新带有版本号的引用类型
// JDK8 中新增加的原子类
DoubleAccumulator
DoubleAdder
LongAccumulator
LongAdder
这些类对应把 AtomicLong 等类的改进。比如 LongAccumulator 与 LongAdder 在高并发环境下比 AtomicLong 更高效。
Atomic、Adder在低并发环境下,两者性能很相似。但在高并发环境下,Adder 有着明显更高的吞吐量,但是有着更高的空间复杂度。
LongAdder其实是LongAccumulator的一个特例,调用LongAdder相当使用下面的方式调用LongAccumulator。
sum() 方法在没有并发的情况下调用,如果在并发情况下使用会存在计数不准。
LongAdder不可以代替AtomicLong ,虽然 LongAdder 的 add() 方法可以原子性操作,但是并没有使用 Unsafe 的CAS算法,只是使用了CAS的思想。
LongAdder其实是LongAccumulator的一个特例,调用LongAdder相当使用下面的方式调用LongAccumulator,LongAccumulator提供了比LongAdder更强大的功能,构造函数其中accumulatorFunction一个双目运算器接口,根据输入的两个参数返回一个计算值,identity则是LongAccumulator累加器的初始值。
11 、JavaConcurrencyAPI中的Lock接口(Lockinterface)是什么?对比同步它有什么优势?
已经在 jdk1.6 对 synchronized 做了优化, 性能提升了不少, 为啥还要使用Lock呢?
synchronized加锁是无法主动释放锁的,这就会涉及到死锁的问题
什么是死锁?
四个必要条件, 缺一不可: 互斥 、 不可剥夺 、 请求与保持 、 循环等待
互斥: 在一段时间内某资源仅为一个线程所占有。此时若有其他线程请求该资源,则请求线程只能等待
**不可剥夺:**线程所获得的资源在未使用完毕之前,不能被其他线程强行夺走,即只能由获得该资源的线程自己来释放(只能是主动释放)
**请求与保持:**线程已经保持了至少一个资源,但又提出了新的资源请求,而该资源已被其他线程占有,此时请求线程被阻塞,但对自己已获得的资源保持不放
**循环等待:**在发生死锁时必然存在一个进程等待队列{P1,P2,…,Pn},其中P1等待P2占有的资源,P2等待P3占有的资源,…,Pn等待P1占有的资源,形成一个进程等待环路,环路中每一个进程所占有的资源同时被另一个申请,也就是前一个进程占有后一个进程所申请的资源
synchronized的局限性: 如果我们的程序使用synchronized关键字发生了死锁时,synchronized关键是是无法破坏“不可剥夺”这个死锁的条件的。这是因为synchronized申请资源的时候, 如果申请不到, 线程直接进入阻塞状态了, 而线程进入阻塞状态, 啥都干不了, 也释放不了线程已经占有的资源。
然而,在大部分场景下,我们都是希望“不可剥夺”这个条件能够被破坏。也就是说对于“不可剥夺”这个条件,占用部分资源的线程进一步申请其他资源时, 如果申请不到, 可以主动释放它占有的资源, 这样不可剥夺这个条件就破坏掉了
锁设计: 响应中断 、 支持超时 、 非阻塞
(1)能够响应中断。 synchronized的问题是, 持有锁A后, 如果尝试获取锁B失败, 那么线程就进入阻塞状态, 一旦发生死锁, 就没有任何机会来唤醒阻塞的线程。 但如果阻塞状态的线程能够响应中断信号, 也就是说当我们给阻塞的线程发送中断信号的时候, 能够唤醒它, 那它就有机会释放曾经持有的锁A。 这样就破坏了不可剥夺条件了。
(2)支持超时。 如果线程在一段时间之内没有获取到锁, 不是进入阻塞状态, 而是返回一个错误, 那这个线程也有机会释放曾经持有的锁。 这样也能破坏不可剥夺条件。
(3)非阻塞地获取锁。 如果尝试获取锁失败, 并不进入阻塞状态, 而是直接返回, 那这个线程也有机会释放曾经持有的锁。 这样也能破坏不可剥夺条件。
// 支持中断的API
void lockInterruptibly() throws InterruptedException;
// 支持超时的API
boolean tryLock(long time, TimeUnit unit) throws InterruptedException;
// 支持非阻塞获取锁的API
boolean tryLock();
12 、什么是Executors框架?
为什么要引入Executor?
JDK1.5 引入, 解耦任务本身和任务的执行
Executor接口有哪些实现类?
DirectExecutor: 对于传入的任务,只有执行完成后execute才会有返回,同步执行任务
ThreadPerTaskExecutor: 对于每个任务,执行器都会创建一个新的线程去执行任务,异步执行任务
SerialExecutor: 对任务进行排队执行,会对传入的任务进行排队(FIFO顺序),然后从队首取出一个任务执行
ExecutorService
Executor接口提供的功能很简单,为了对它进行增强,出现了ExecutorService接口,ExecutorService继承了Executor,它在Executor的基础上增强了对任务的控制,同时包括对自身生命周期的管理,主要有四类:
关闭执行器,禁止任务的提交;
监视执行器的状态;
提供对异步任务的支持;
提供对批处理任务的支持。
对于Future,Future对象提供了对任务异步执行的支持,也就是说调用线程无需等待任务执行完成,提交待执行的任务后,就会立即返回往下执行。然后,可以在需要时检查Future是否有结果了,如果任务已执行完毕,通过Future.get()方法可以获取到执行结果——Future.get()是阻塞方法。
ScheduledExecutorService
ScheduledExecutorService 提供了一系列schedule方法,可以在给定的延迟后执行提交的任务,或者每个指定的周期执行一次提交的任务, 该接口继承了 ExecutorService
线程池作用
ThreadPoolExecutor是用来创建线程池的Executor,线程池概念与数据库连接池类似。
当有任务需要执行时,线程池会给该任务分配线程,如果当前没有可用线程,一般会将任务放进一个队列中,当有线程可用时,再从队列中取出任务并执行
线程池的引入,主要解决以下问题:
减少系统因为频繁创建和销毁线程所带来的开销;
自动管理线程,对使用方透明,使其可以专注于任务的构建。
Executors工厂可以创建不同类型的线程池,其中有以下几个参数:
maximumPoolSize限定了整个线程池的大小,
corePoolSize限定了核心线程池的大小,
corePoolSize≤maximumPoolSize(当相等时表示为固定线程池);
maximumPoolSize-corePoolSize表示非核心线程池。
线程池状态
ThreadPoolExecutor一共定义了5种线程池状态
RUNNING : 接受新任务, 且处理已经进入阻塞队列的任务
SHUTDOWN : 不接受新任务 , 但处理已经进入阻塞队列的任务
STOP : 不接受新任, 且不处理已经进入阻塞队列的任务, 同时中断正在运行的任务
TIDYING : 所有任务都已终止 , 工作线程数为0 , 线程转化为TIDYING状态并准备调用terminated方法
TERMINATED : terminated方法已经执行完成
各个状态之间的流转图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MKzNW9r4-1618135569564)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210404211913063.png)]
Worker工作线程
当我们向线程池提交一个任务时,将创建一个工作线程——我们称之为Worker,Worker在逻辑上从属于【核心线程池】或【非核心线程池】,具体属于哪一种,要根据corePoolSize、maximumPoolSize、Worker总数进行判断。ThreadPoolExecutor中只有一种类型的线程,名叫Worker,它是ThreadPoolExecutor定义的内部类,同时封装着Runnable任务和执行该任务的Thread对象,我们称它为【工作线程】,它也是ThreadPoolExecutor唯一需要进行维护的线程
每个Worker对象都有一个Thread线程对象与它相对应 , 当任务需要执行的时候,实际是调用内部Thread对象的start方法,而Thread对象是在Worker的构造器中通过getThreadFactory().newThread(this)方法创建的,创建的Thread将Worker自身作为任务,所以当调用Thread的start方法时,最终实际是调用了Worker.run()方法,该方法内部委托给runWorker方法执行任务
工作线程的创建
execute方法内部调用了addWorker方法来添加工作线程并执行任务,整个addWorker的逻辑并不复杂,分为两部分:
第一部分是一个自旋操作,主要是对线程池的状态进行一些判断,如果状态不适合接受新任务,或者工作线程数超出了限制,则直接返回false。
第二部分才真正去创建工作线程并执行任务:首先将Runnable任务包装成一个Worker对象,然后加入到一个工作线程集合中(名为workers的HashSet),最后调用工作线程中的Thread对象的start方法执行任务,其实最终是委托到Worker的下面方法执行:
Doug Lea 在 ThreadPoolExecutor 中 写的 addWorker方法:
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
其中 用到了标签 retry:
break label直接跳出到标签处,不再执行循环代码;continue label,只是结束本轮循环,跳转到标签处,继续下一轮循环(本质上与单层循环的break和continue类似)
public class RetryDemo {
public static void main(String[] args) {
retryTest1();
//retryTest2();
}
public static void retryTest2(){
int count = 0;
retry:
for (int i=0; i<3; i++) {
for (int j=0; j<5; j++) {
count++;
if (count == 4) {
break retry;
}
System.out.print(count + " ");
}
}
}
public static void retryTest1(){
int count = 0;
retry:
for (int i=0; i<3; i++) {
for (int j=0; j<5; j++) {
count++;
if (count == 4) {
continue retry;
}
System.out.print(count + " ");
}
}
}
}
工作线程的执行
runWoker用于执行任务,整体流程如下:
while循环不断地通过getTask()方法从队列中获取任务(如果工作线程自身携带着任务,则执行携带的任务);
控制执行线程的中断状态,保证如果线程池正在停止,则线程必须是中断状态,否则线程必须不是中断状态;
调用task.run()执行任务;
处理工作线程的退出工作。
该方法确保正在停止的线程池(STOP/TIDYING/TERMINATED)不再接受新任务,如果有新任务那么该任务的工作线程一定是中断状态;确保正常状态的线程池(RUNNING/SHUTDOWN),其所执行的任务都是不能被中断的。
另外,getTask方法用于从任务队列中获取一个任务,如果获取不到任务,会跳出while循环,最终会通过processWorkerExit方法清理工作线程。
工作线程的清理
processWorkerExit的作用就是将该退出的工作线程清理掉,然后看下线程池是否需要终止。processWorkerExit执行完之后,整个工作线程的生命周期也结束了,可以通过下图来回顾下它的整个生命周期:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vposoJ3g-1618135569565)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210404224515487.png)]
线程池的调度流程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tfApiyv9-1618135569565)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210404224351733.png)]
execute的整个执行流程关键是下面两点:
如果工作线程数小于核心线程池上限(CorePoolSize),则直接新建一个工作线程并执行任务;
如果工作线程数大于等于CorePoolSize,则尝试将任务加入到队列等待以后执行。如果加入队列失败了(比如队列已满的情况),则在总线程池未满的情况下(CorePoolSize ≤ 工作线程数 < maximumPoolSize)新建一个工作线程立即执行任务,否则执行拒绝策略。
任务队列
阻塞队列就是在我们构建ThreadPoolExecutor对象时,在构造器中指定的。由于队列是外部指定的,所以根据阻塞队列的特性不同,Worker工作线程调用getTask方法获取任务的执行情况也不同
直接提交
即直接将任务提交给等待的工作线程,这时可以选择SynchronousQueue。因为SynchronousQueue是没有容量的,而且采用了无锁算法,所以性能较好,但是每个入队操作都要等待一个出队操作,反之亦然。
使用SynchronousQueue时,当核心线程池满了以后,如果不存在空闲的工作线程,则试图把任务加入队列将立即失败(execute方法中使用了队列的offer方法进行入队操作,而SynchronousQueue在调用offer时如果没有另一个线程等待出队操作,则会立即返回false),因此会构造一个新的工作线程(未超出最大线程池容量时)。
由于,核心线程池是很容易满的,所以当使用SynchronousQueue时,一般需要将 maximumPoolSizes设置得比较大,否则入队很容易失败,最终导致执行拒绝策略,这也是为什么Executors工作默认提供的缓存线程池使用SynchronousQueue作为任务队列的原因。
无界任务队列
无界任务队列我们的选择主要有LinkedTransferQueue、LinkedBlockingQueue(近似无界,构造时不指定容量即可),从性能角度来说LinkedTransferQueue采用了无锁算法,高并发环境下性能相对更好,但如果只是做任务队列使用相差并不大。
使用无界队列需要特别注意系统资源的消耗情况,因为当核心线程池满了以后,会首先尝试将任务放入队列,由于是无界队列所以几乎一定会成功,那么系统瓶颈其实就是硬件了。如果任务的创建速度远快于工作线程处理任务的速度,那么最终会导致系统资源耗尽。Executors工厂中创建固定线程池的方法内部就是用了LinkedBlockingQueue。
有界任务队列
有界任务队列,比如ArrayBlockingQueue ,可以防止资源耗尽的情况。当核心线程池满了以后,如果队列也满了,则会创建归属于非核心线程池的工作线程,如果非核心线程池也满了 ,才会执行拒绝策略。
拒绝策略
ThreadPoolExecutor在以下两种情况下会执行拒绝策略:
当核心线程池满了以后,如果任务队列也满了,首先判断非核心线程池有没满,没有满就创建一个工作线程(归属非核心线程池), 否则就会执行拒绝策略;
提交任务时,ThreadPoolExecutor已经关闭了。
所谓拒绝策略,就是在构造ThreadPoolExecutor时,传入的RejectedExecutionHandler对象
ThreadPoolExecutor一共提供了4种拒绝策略:
AbortPolicy(默认):抛出一个RejectedExecutionException异常
DiscardPolicy:无为而治,什么都不做,等任务自己被回收
DiscardOldestPolicy:丢弃任务队列中的最近一个任务,并执行当前任务
CallerRunsPolicy:以自身线程来执行任务,这样可以减缓新任务提交的速度
线程池的关闭
ExecutorService接口提供两种方法来关闭线程池,这两种方法的区别主要在于是否会继续处理已经添加到任务队列中的任务。
shutdown方法将线程池切换到SHUTDOWN状态(如果已经停止,则不用切换),并调用interruptIdleWorkers方法中断所有空闲的工作线程,最后调用tryTerminate尝试结束线程池,注意,如果执行Runnable任务的线程本身不响应中断,那么也就没有办法终止任务。
shutdownNow方法的主要不同之处就是,它会将线程池的状态至少置为STOP,同时中断所有工作线程(无论该线程是空闲还是运行中),同时返回任务队列中的所有任务。
配置核心线程池的大小
如果任务是 CPU 密集型(需要进行大量计算、处理,比如计算圆周率、对视频进行高清解码等等),则应该配置尽量少的线程,比如 CPU 个数 + 1,这样可以避免出现每个线程都需要使用很长时间但是有太多线程争抢资源的情况;
如果任务是 IO密集型(主要时间都在 I/O,即网络、磁盘IO,CPU 空闲时间比较多),则应该配置多一些线程,比如 CPU 数的两倍,这样可以更高地压榨 CPU。
公式:最佳线程数目 = ((线程等待时间+线程CPU时间)/线程CPU时间 ) CPU数目*
比如*平均每个线程CPU运行时间为0.5s,而线程等待时间(非CPU运行时间,比如IO)为1.5s,CPU核心数为8,那么根据上面这个公式估算得到:((0.5+1.5)/0.5)8=32。
固定线程池
创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
ExecutorService newFixedThreadPool = Executors.newFixedThreadPool(3);
for (int i = 0; i < 10; i++) {
int temp = i;
newFixedThreadPool.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + ",i:" + temp);
}
});
}
单线程线程池
创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。 类似:newSingleThreadScheduledExecutor()
可缓存的线程池
如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
// 1.可缓存的线程池 重复利用
ExecutorService newCachedThreadPool = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
int temp = i;
newCachedThreadPool.execute(new Runnable() {
@Override
public void run() {
System.out.println("threadName:" + Thread.currentThread().getName() +
",i:" + temp);
}
});
}
可延时/周期调度的线程池
ScheduledThreadPoolExecutor,它是对普通线程池ThreadPoolExecutor的扩展,增加了延时调度、周期调度任务的功能。概括下ScheduledThreadPoolExecutor的主要特点:
对Runnable任务进行包装,封装成ScheduledFutureTask,该类任务支持任务的周期执行、延迟执行;
采用DelayedWorkQueue作为任务队列。该队列是无界队列,所以任务一定能添加成功,但是当工作线程尝试从队列取任务执行时,只有最先到期的任务会出队,如果没有任务或者队首任务未到期,则工作线程会阻塞;
ScheduledThreadPoolExecutor的任务调度流程与ThreadPoolExecutor略有区别,最大的区别就是,先往队列添加任务,然后创建工作线程执行任务。
创建一个定长线程池,支持定时及周期性任务执行。
ScheduledExecutorService newScheduledThreadPool = Executors.newScheduledThreadPool(3);
for (int i = 0; i < 10; i++) {
int temp = i;
newScheduledThreadPool.schedule(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + ",i:" + temp);
}
},3, TimeUnit.SECONDS);
}
逻辑和算数操作
public static void main(String[] args) {
// 20
System.out.println(10 << 1);
// -20
System.out.println(-10 << 1);
// 5
System.out.println(10 >> 1);
// -5
System.out.println(-10 >> 1);
// 5
System.out.println(10 >>> 1);
// 2147483643
System.out.println(-10 >>> 1);
}
我们都知道对于有符号数据类型,二进制最左端的数字为符号位,0代表正,1代表负,这里先介绍几个概念
逻辑左移=算术左移:高位溢出,低位补0
逻辑右移:低位溢出,高位补0
算术右移:低位溢出,高位用符号位的值补
比如一个有符号位的8位二进制数10101010,[]是添加的数字
逻辑左移一位:0101010[0]
逻辑左移两位:101010[00]
算术左移一位:0101010[0]
算术左移两位:101010[00]
逻辑右移一位:[0]1010101
逻辑右移两位:[00]101010
算术右移一位:[1]1010101
算术右移两位:[11]101010
算术左移和算术右移主要用来进行有符号数的倍增、减半
逻辑左移和逻辑右移主要用来进行无符号数的倍增、减半
(Java中是没有无符号数据类型的,C和C++中有)
num<< n : 相当于 num×2nnum×2n,算数左移(逻辑左移)
num>>n: 相当于num2nnum2n,算数右移
num>>>n: 逻辑右移,当num为正数和算术右移一个效果
Feature模式
Future模式是Java多线程设计模式中的一种常见模式,它的主要作用就是异步地执行任务,并在需要的时候获取结果。我们知道,一般调用一个函数,需要等待函数执行完成,调用线程才会继续往下执行,如果是一些计算密集型任务,需要等待的时间可能就会比较长。
Future模式可以让调用方立即返回,然后它自己会在后面慢慢处理,此时调用者拿到的仅仅是一个凭证,调用者可以先去处理其它任务,在真正需要用到调用结果的场合,再使用凭证去获取调用结果。这个凭证就是这里的Future。
看下时序图来理解下两者的区别:
传统的数据获取方式:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-svCodSL6-1618135569566)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210405092434937.png)]
Future模式下的数据获取:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t69GG5ci-1618135569566)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210405092512768.png)]z
Feature 实现通知功能
package future;
import java.util.concurrent.CancellationException;
import java.util.concurrent.Future;
import java.util.concurrent.TimeUnit;
/**
* The result of an asynchronous operation.
*
* @author lixiaohui
* @param <V> 执行结果的类型参数
*/
public interface IFuture<V> extends Future<V> {
boolean isSuccess(); // 是否成功
V getNow(); //立即返回结果(不管Future是否处于完成状态)
Throwable cause(); //若执行失败时的原因
boolean isCancellable(); //是否可以取消
IFuture<V> await() throws InterruptedException; //等待future的完成
boolean await(long timeoutMillis) throws InterruptedException; // 超时等待future的完成
boolean await(long timeout, TimeUnit timeunit) throws InterruptedException;
IFuture<V> awaitUninterruptibly(); //<span style="line-height: 1.5;">等待future的完成,不响应中断</span>
boolean awaitUninterruptibly(long timeoutMillis);<span style="line-height: 1.5;">//超时</span><span style="line-height: 1.5;">等待future的完成,不响应中断</span>
boolean awaitUninterruptibly(long timeout, TimeUnit timeunit);
IFuture<V> addListener(IFutureListener<V> l); //当future完成时,会通知这些加进来的监听器
IFuture<V> removeListener(IFutureListener<V> l);
}
当线程调用了IFuture.await()等一系列的方法时,如果Future还未完成,那么就调用future.wait() 方法使线程进入WAITING状态。而当别的线程设置Future为完成状态(注意这里的完成状态包括正常结束和异常结束)时,就需要调用future.notifyAll()方法来唤醒之前因为调用过wait()方法而处于WAITING状态的那些线程。完整的实现如下
package future;
import java.util.Collection;
import java.util.concurrent.CancellationException;
import java.util.concurrent.CopyOnWriteArrayList;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.TimeoutException;
/**
* <pre>
* 正常结束时, 若执行的结果不为null, 则result为执行结果; 若执行结果为null, 则result = {@link AbstractFuture#SUCCESS_SIGNAL}
* 异常结束时, result为 {@link CauseHolder} 的实例;若是被取消而导致的异常结束, 则result为 {@link CancellationException} 的实例, 否则为其它异常的实例
* 以下情况会使异步操作由未完成状态转至已完成状态, 也就是在以下情况发生时调用notifyAll()方法:
* <ul>
* <li>异步操作被取消时(cancel方法)</li>
* <li>异步操作正常结束时(setSuccess方法)</li>
* <li>异步操作异常结束时(setFailure方法)</li>
* </ul>
* </pre>
* @param <V>
* 异步执行结果的类型
*/
public class AbstractFuture<V> implements IFuture<V> {
protected volatile Object result; // 需要保证其可见性
/**
* 监听器集
*/
protected Collection<IFutureListener<V>> listeners = new CopyOnWriteArrayList<IFutureListener<V>>();
/**
* 当任务正常执行结果为null时, 即客户端调用{@link AbstractFuture#setSuccess(null)}时,
* result引用该对象
*/
private static final SuccessSignal SUCCESS_SIGNAL = new SuccessSignal();
@Override
public boolean cancel(boolean mayInterruptIfRunning) {
if (isDone()) { // 已完成了不能取消
return false;
}
synchronized (this) {
if (isDone()) { // double check
return false;
}
result = new CauseHolder(new CancellationException());
notifyAll(); // isDone = true, 通知等待在该对象的wait()的线程
}
notifyListeners(); // 通知监听器该异步操作已完成
return true;
}
@Override
public boolean isCancellable() {
return result == null;
}
@Override
public boolean isCancelled() {
return result != null && result instanceof CauseHolder && ((CauseHolder) result).cause instanceof CancellationException;
}
@Override
public boolean isDone() {
return result != null;
}
@Override
public V get() throws InterruptedException, ExecutionException {
await(); // 等待执行结果
Throwable cause = cause();
if (cause == null) { // 没有发生异常,异步操作正常结束
return getNow();
}
if (cause instanceof CancellationException) { // 异步操作被取消了
throw (CancellationException) cause;
}
throw new ExecutionException(cause); // 其他异常
}
@Override
public V get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException {
if (await(timeout, unit)) {// 超时等待执行结果
Throwable cause = cause();
if (cause == null) {// 没有发生异常,异步操作正常结束
return getNow();
}
if (cause instanceof CancellationException) {// 异步操作被取消了
throw (CancellationException) cause;
}
throw new ExecutionException(cause);// 其他异常
}
// 时间到了异步操作还没有结束, 抛出超时异常
throw new TimeoutException();
}
@Override
public boolean isSuccess() {
return result == null ? false : !(result instanceof CauseHolder);
}
@SuppressWarnings("unchecked")
@Override
public V getNow() {
return (V) (result == SUCCESS_SIGNAL ? null : result);
}
@Override
public Throwable cause() {
if (result != null && result instanceof CauseHolder) {
return ((CauseHolder) result).cause;
}
return null;
}
@Override
public IFuture<V> addListener(IFutureListener<V> listener) {
if (listener == null) {
throw new NullPointerException("listener");
}
if (isDone()) { // 若已完成直接通知该监听器
notifyListener(listener);
return this;
}
synchronized (this) {
if (!isDone()) {
listeners.add(listener);
return this;
}
}
notifyListener(listener);
return this;
}
@Override
public IFuture<V> removeListener(IFutureListener<V> listener) {
if (listener == null) {
throw new NullPointerException("listener");
}
if (!isDone()) {
listeners.remove(listener);
}
return this;
}
@Override
public IFuture<V> await() throws InterruptedException {
return await0(true);
}
private IFuture<V> await0(boolean interruptable) throws InterruptedException {
if (!isDone()) { // 若已完成就直接返回了
// 若允许终端且被中断了则抛出中断异常
if (interruptable && Thread.interrupted()) {
throw new InterruptedException("thread " + Thread.currentThread().getName() + " has been interrupted.");
}
boolean interrupted = false;
synchronized (this) {
while (!isDone()) {
try {
wait(); // 释放锁进入waiting状态,等待其它线程调用本对象的notify()/notifyAll()方法
} catch (InterruptedException e) {
if (interruptable) {
throw e;
} else {
interrupted = true;
}
}
}
}
if (interrupted) {
// 为什么这里要设中断标志位?因为从wait方法返回后, 中断标志是被clear了的,
// 这里重新设置以便让其它代码知道这里被中断了。
Thread.currentThread().interrupt();
}
}
return this;
}
@Override
public boolean await(long timeoutMillis) throws InterruptedException {
return await0(TimeUnit.MILLISECONDS.toNanos(timeoutMillis), true);
}
@Override
public boolean await(long timeout, TimeUnit unit) throws InterruptedException {
return await0(unit.toNanos(timeout), true);
}
private boolean await0(long timeoutNanos, boolean interruptable) throws InterruptedException {
if (isDone()) {
return true;
}
if (timeoutNanos <= 0) {
return isDone();
}
if (interruptable && Thread.interrupted()) {
throw new InterruptedException(toString());
}
long startTime = timeoutNanos <= 0 ? 0 : System.nanoTime();
long waitTime = timeoutNanos;
boolean interrupted = false;
try {
synchronized (this) {
if (isDone()) {
return true;
}
if (waitTime <= 0) {
return isDone();
}
for (;;) {
try {
wait(waitTime / 1000000, (int) (waitTime % 1000000));
} catch (InterruptedException e) {
if (interruptable) {
throw e;
} else {
interrupted = true;
}
}
if (isDone()) {
return true;
} else {
waitTime = timeoutNanos - (System.nanoTime() - startTime);
if (waitTime <= 0) {
return isDone();
}
}
}
}
} finally {
if (interrupted) {
Thread.currentThread().interrupt();
}
}
}
@Override
public IFuture<V> awaitUninterruptibly() {
try {
return await0(false);
} catch (InterruptedException e) { // 这里若抛异常了就无法处理了
throw new java.lang.InternalError();
}
}
@Override
public boolean awaitUninterruptibly(long timeoutMillis) {
try {
return await0(TimeUnit.MILLISECONDS.toNanos(timeoutMillis), false);
} catch (InterruptedException e) {
throw new java.lang.InternalError();
}
}
@Override
public boolean awaitUninterruptibly(long timeout, TimeUnit unit) {
try {
return await0(unit.toNanos(timeout), false);
} catch (InterruptedException e) {
throw new java.lang.InternalError();
}
}
protected IFuture<V> setFailure(Throwable cause) {
if (setFailure0(cause)) {
notifyListeners();
return this;
}
throw new IllegalStateException("complete already: " + this);
}
private boolean setFailure0(Throwable cause) {
if (isDone()) {
return false;
}
synchronized (this) {
if (isDone()) {
return false;
}
result = new CauseHolder(cause);
notifyAll();
}
return true;
}
protected IFuture<V> setSuccess(Object result) {
if (setSuccess0(result)) { // 设置成功后通知监听器
notifyListeners();
return this;
}
throw new IllegalStateException("complete already: " + this);
}
private boolean setSuccess0(Object result) {
if (isDone()) {
return false;
}
synchronized (this) {
if (isDone()) {
return false;
}
if (result == null) { // 异步操作正常执行完毕的结果是null
this.result = SUCCESS_SIGNAL;
} else {
this.result = result;
}
notifyAll();
}
return true;
}
private void notifyListeners() {
for (IFutureListener<V> l : listeners) {
notifyListener(l);
}
}
private void notifyListener(IFutureListener<V> l) {
try {
l.operationCompleted(this);
} catch (Exception e) {
e.printStackTrace();
}
}
private static class SuccessSignal {
}
private static final class CauseHolder {
final Throwable cause;
CauseHolder(Throwable cause) {
this.cause = cause;
}
}
}
我们就可以定制各种各样的异步结果了。下面模拟一下一个延时的任务
package future.test;
import future.IFuture;
import future.IFutureListener;
/**
* 延时加法
* @author lixiaohui
*
*/
public class DelayAdder {
public static void main(String[] args) {
new DelayAdder().add(3 * 1000, 1, 2).addListener(new IFutureListener<Integer>() {
@Override
public void operationCompleted(IFuture<Integer> future) throws Exception {
System.out.println(future.getNow());
}
});
}
/**
* 延迟加
* @param delay 延时时长 milliseconds
* @param a 加数
* @param b 加数
* @return 异步结果
*/
public DelayAdditionFuture add(long delay, int a, int b) {
DelayAdditionFuture future = new DelayAdditionFuture();
new Thread(new DelayAdditionTask(delay, a, b, future)).start();
return future;
}
private class DelayAdditionTask implements Runnable {
private long delay;
private int a, b;
private DelayAdditionFuture future;
public DelayAdditionTask(long delay, int a, int b, DelayAdditionFuture future) {
super();
this.delay = delay;
this.a = a;
this.b = b;
this.future = future;
}
@Override
public void run() {
try {
Thread.sleep(delay);
Integer i = a + b;
// TODO 这里设置future为完成状态(正常执行完毕)
future.setSuccess(i);
} catch (InterruptedException e) {
// TODO 这里设置future为完成状态(异常执行完毕)
future.setFailure(e.getCause());
}
}
}
}
package future.test;
import future.AbstractFuture;
import future.IFuture;
//只是把两个方法对外暴露
public class DelayAdditionFuture extends AbstractFuture<Integer> {
@Override
public IFuture<Integer> setSuccess(Object result) {
return super.setSuccess(result);
}
@Override
public IFuture<Integer> setFailure(Throwable cause) {
return super.setFailure(cause);
}
}
可以看到客户端不用主动去询问future是否完成, 而是future完成时自动回调operationCompleted方法,客户端只需在回调里实现逻辑即可
并发包中Future模式中的各个组件
真实的任务类
首先我们需要类可以返回线程的执行结果,而传统实现Runnable接口的线程是获取不了返回值的
于是,JDK提供了另一个接口——Callable,表示一个具有返回结果的任务:
所以,最终我们自定义的任务类一般都是实现了Callable接口。以下定义了一个具有复杂计算过程的任务,最终返回一个Double值:
public class ComplexTask implements Callable<Double> {
@Override
public Double call() {
// complex calculating...
return ThreadLocalRandom.current().nextDouble();
}
}
凭证
Future模式可以让调用方获取任务的一个凭证,以便将来拿着凭证去获取任务结果,凭证需要具有以下特点:
在将来某个时间点,可以通过凭证获取任务的结果;
可以支持取消。
并发包中提供了Future接口和它的实现类——FutureTask来满足我们的需求
所以我们可以将上面的代码改造成:
ComplexTask task = new ComplexTask();
Future<Double> future = new FutureTask<Double>(task);
上面的FutureTask就是真实的“凭证”,Future则是该凭证的接口(从面向对象的角度来讲,调用方应面向接口操作)。那既然要执行任务,FutureTask这个类其实除了实现了Future凭证接口外,还实现了Runable接口
FutureTask既可以包装Callable任务,也可以包装Runnable任务,但最终都是将Runnable转换成Callable任务,其实是一个适配过程。 最终,调用方可以以下面这种方式使用Future模式,异步地获取任务的执行结果。
public static void main(String[] args) throws ExecutionException, InterruptedException {
ComplexTask task = new ComplexTask();
Future<Double> future = new FutureTask<Double>(task);
// time passed...
Double result = future.get();
}
通过上面的分析,可以看到,整个Future模式其实就三个核心组件:
真实任务/数据类(通常任务执行比较慢,或数据构造需要较长时间),即示例中的ComplexTask
Future接口(调用方使用该凭证获取真实任务/数据的结果),即Future接口
Future实现类(用于对真实任务/数据进行包装),即FutureTask实现类
注意:
FutureTask虽然支持任务的取消(cancel方法),但是只有当任务是初始化(NEW状态)时才有效,否则cancel方法直接返回false;
当执行任务时(run方法),无论成功或异常,都会先过渡到COMPLETING状态,直到任务结果设置完成后,才会进入响应的终态。
FutureTask
既然是任务,就有状态,FutureTask一共给任务定义了7种状态:
NEW: 表示任务的初始化状态;
COMPLETING:表示任务已执行完成(正常完成或异常完成),但任务结果或异常原因还未设置完成,属于中间状态;
NORMAL:表示任务已经执行完成(正常完成),且任务结果已设置完成,属于最终状态;
EXCEPTIONAL:表示任务已经执行完成(异常完成),且任务异常已设置完成,属于最终状态;
CANCELLED:表示任务还没开始执行就被取消(非中断方式),属于最终状态;
INTERRUPTING:表示任务还没开始执行就被取消(中断方式),正式被中断前的过渡状态,属于中间状态;
INTERRUPTED:表示任务还没开始执行就被取消(中断方式),且已被中断,属于最终状态。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nqzS5bbD-1618135569567)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210405093208331.png)]
结果获取
FutureTask可以通过get方法获取任务结果,如果需要限时等待,可以调用get(long timeout, TimeUnit unit)。如果当前任务的状态是NEW或COMPLETING,会调用awaitDone阻塞线程。否则会认为任务已经完成,直接通过report方法映射结果
ScheduledFutureTask
ScheduledFutureTask是ScheduledThreadPoolExecutor这个线程池的默认调度任务类。
ScheduledFutureTask在普通FutureTask的基础上增加了周期执行/延迟执行的功能
Fork/Join框架
分治思想
算法领域有一种基本思想叫做“分治”,所谓“分治”就是将一个难以直接解决的大问题,分割成一些规模较小的子问题,以便各个击破,分而治之。
比如:对于一个规模为N的问题,若该问题可以容易地解决,则直接解决;否则将其分解为K个规模较小的子问题,这些子问题互相独立且与原问题性质相同,递归地解这些子问题,然后将各子问题的解合并得到原问题的解,这种算法设计策略叫做分治法。
许多基础算法都运用了“分治”的思想,比如二分查找、快速排序等等。
基于“分治”的思想,J.U.C在JDK1.7时引入了一套Fork/Join框架。Fork/Join框架的基本思想就是将一个大任务分解(Fork)成一系列子任务,子任务可以继续往下分解,当多个不同的子任务都执行完成后,可以将它们各自的结果合并(Join)成一个大结果,最终合并成大任务的结果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I5UDFbXP-1618135569567)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210405093434916.png)]
工作窃取算法
从上述Fork/Join框架的描述可以看出,我们需要一些线程来执行Fork出的任务,在实际中,如果每次都创建新的线程执行任务,对系统资源的开销会很大,所以Fork/Join框架利用了线程池来调度任务。
另外,这里可以思考一个问题,既然由线程池调度,根据我们之前学习普通/计划线程池的经验,必然存在两个要素:
工作线程
任务队列
一般的线程池只有一个任务队列,但是对于Fork/Join框架来说,由于Fork出的各个子任务其实是平行关系,为了提高效率,减少线程竞争,应该将这些平行的任务放到不同的队列中去,如上图中,大任务分解成三个子任务:子任务1、子任务2、子任务3,那么就创建三个任务队列,然后再创建3个工作线程与队列一一对应。
由于线程处理不同任务的速度不同,这样就可能存在某个线程先执行完了自己队列中的任务的情况,这时为了提升效率,我们可以让该线程去“窃取”其它任务队列中的任务,这就是所谓的工作窃取算法。
“工作窃取”的示意图如下,当线程1执行完自身任务队列中的任务后,尝试从线程2的任务队列中“窃取”任务:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vwlh4E0u-1618135569568)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210405093556471.png)]
对于一般的队列来说,入队元素都是在“队尾”,出队元素在“队首”,要满足“工作窃取”的需求,任务队列应该支持从“队尾”出队元素,这样可以减少与其它工作线程的冲突(因为正常情况下,其它工作线程从“队首”获取自己任务队列中的任务),满足这一需求的任务队列其实就是双端阻塞队列——LinkedBlockingDeque。
当然,出于性能考虑,J.U.C中的Fork/Join框架并没有直接利用LinkedBlockingDeque作为任务队列,而是自己重新实现了一个。
Fork/Join组件
该框架主要涉及三大核心组件:ForkJoinPool(线程池)、ForkJoinTask(任务)、ForkJoinWorkerThread(工作线程),外加WorkQueue(任务队列):
ForkJoinPool:ExecutorService的实现类,负责工作线程的管理、任务队列的维护,以及控制整个任务调度流程;
ForkJoinTask:Future接口的实现类, fork是其核心方法, 用于分解任务并异步执行;而join方法在任务结果计算完毕之后才会运行,用来合并或返回计算结果;
ForkJoinWorkerThread:Thread的子类,作为线程池中的工作线程(Worker)执行任务;
WorkQueue:任务队列,用于保存任务;
ForkJoinPool
它作为Executors框架的一员,是ExecutorService的一个实现类
ForkJoinPool的主要工作如下:
接受外部任务的提交(外部调用ForkJoinPool的invoke/execute/submit方法提交任务);
接受ForkJoinTask自身fork出的子任务的提交;
任务队列数组(WorkQueue[])的初始化和管理;
工作线程(Worker)的创建/管理。
ForkJoinPool提供了3类外部提交任务的方法:invoke、execute、submit,它们的主要区别在于任务的执行方式上。
通过invoke方法提交的任务,调用线程直到任务执行完成才会返回,也就是说这是一个同步方法,且有返回结果;
通过execute方法提交的任务,调用线程会立即返回,也就是说这是一个异步方法,且没有返回结果;
通过submit方法提交的任务,调用线程会立即返回,也就是说这是一个异步方法,且有返回结果(返回Future实现类,可以通过get获取结果)。
ForkJoinTask
从Fork/Join框架的描述上来看,“任务”必须要满足一定的条件:
支持Fork,即任务自身的分解
支持Join,即任务结果的合并
ForkJoinTask就是符合这种条件的任务。
ForkJoinTask实现了Future接口,是一个异步任务,我们在使用Fork/Join框架时,一般需要使用线程池来调度任务,线程池内部调度的其实都是ForkJoinTask任务
除了ForkJoinTask,Fork/Join框架还提供了两个ForkJoinTask的抽象实现,我们在自定义ForkJoin任务时,一般继承这两个类:
RecursiveAction:表示具有返回结果的ForkJoin任务
RecursiveTask:表示没有返回结果的ForkJoin任务
其它组件就不说了
使用示例
假设有个非常大的long[]数组,通过FJ框架求解数组所有元素的和。
任务类定义,因为需要返回结果,所以继承RecursiveTask,并覆写compute方法。任务的fork通过ForkJoinTask的fork方法执行,join方法方法用于等待任务执行后返回.
代码大致的意思就是:
ArraySumTask类初始化时会传入需要计算的数组,和begin,end。通过设置的THRESHOLD 阈值来与begin,end比较.
如果end - begin + 1 < THRESHOLD,那么不需要分段,
如果end - begin + 1 >THRESHOLD, 就需要分段计算了,怎么分呢?就再次创建两个ArraySumTask 任务,一个处理array的index为0-500的数据,一个处理501-1000的数据。然后再次调用fork方法,会执行新任务的compute方法,那么由于刚创建的两个任务还是比阈值100大,所以分别又会创建任务,就一直递归创建任务,直到end-begin小于阈值。然后分别执行任务,跳出递归,执行join方法,将结果统一相加
public class ArraySumTask extends RecursiveTask<Long> {
private final int[] array;
private final int begin;
private final int end;
private static final int THRESHOLD = 100;
public ArraySumTask(int[] array, int begin, int end) {
this.array = array;
this.begin = begin;
this.end = end;
}
@Override
protected Long compute() {
long sum = 0;
if (end - begin + 1 < THRESHOLD) { // 小于阈值, 直接计算
for (int i = begin; i <= end; i++) {
sum += array[i];
}
} else {
int middle = (end + begin) / 2;
ArraySumTask subtask1 = new ArraySumTask(this.array, begin, middle);
ArraySumTask subtask2 = new ArraySumTask(this.array, middle + 1, end);
subtask1.fork();
subtask2.fork();
long sum1 = subtask1.join();
long sum2 = subtask2.join();
sum = sum1 + sum2;
}
return sum;
}
}
调用方如下:
public class Main {
public static void main(String[] args) {
ForkJoinPool executor = new ForkJoinPool();
ArraySumTask task = new ArraySumTask(new int[10000], 0, 9999);
ForkJoinTask future = executor.submit(task);
// some time passed...
if (future.isCompletedAbnormally()) {
System.out.println(future.getException());
}
try {
System.out.println("result: " + future.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
注意:ForkJoinTask在执行的时候可能会抛出异常,但是没办法在主线程里直接捕获异常,所以ForkJoinTask提供了isCompletedAbnormally()方法来检查任务是否已经抛出异常或已经被取消了,并且可以通过ForkJoinTask的getException方法获取异常.
13 、什么是阻塞队列?阻塞队列的实现原理是什么?如何使用阻塞队列来实现生产者-消费者模型?
什么是阻塞队列?
阻塞队列是一个支持阻塞的插入和移除的队列。
- 支持阻塞的插入方法:意思是当队列满时,队列会阻塞插入元素的线程,直到队列不满。
- 支持阻塞的移除方法:意思是队列为空时,获取元素(同时移除元素)的线程会被阻塞,等到队列变为非空。
阻塞队列用法:
阻塞队列常用于生产者和消费者的场景,生产者是向队列里添加元素的线程,消费者是从队列里获取元素的线程。
当阻塞队列不可用时,会有四种相应的处理方式:
| 处理方式 | 抛出异常 | 返回特殊值 | 一直阻塞 | 超时退出 |
|---|---|---|---|---|
| 插入操作 | add(e) | offer(e) | put(e) | offer(e,time,unit) |
| 移除操作 | remove() | poll() | take() | poll(time,unit) |
| 获取操作 | element() | peek() | 不可用 | 不可用 |
四组不同的行为方式解释:
- 抛异常:如果试图的操作无法立即执行,抛一个异常。
- 特定值:如果试图的操作无法立即执行,返回一个特定的值(常常是 true / false)。
- 阻塞:如果试图的操作无法立即执行,该方法调用将会发生阻塞,直到能够执行。
- 超时:如果试图的操作无法立即执行,该方法调用将会发生阻塞,直到能够执行,但等待时间不会超过给定值。返回一个特定值以告知该操作是否成功(典型的是true / false)。
无法向一个 BlockingQueue 中插入 null。如果你试图插入 null,BlockingQueue 将会抛出一个 NullPointerException。
可以访问到 BlockingQueue 中的所有元素,而不仅仅是开始和结束的元素。比如说,你将一个对象放入队列之中以等待处理,但你的应用想要将其取消掉。那么你可以调用诸如 remove(o) 方法来将队列之中的特定对象进行移除。但是这么干效率并不高(基于队列的数据结构,获取除开始或结束位置的其他对象的效率不会太高),因此你尽量不要用这一类的方法,除非你确实不得不那么做。
- 返回特殊值:插入元素时,会返回是否插入成功,成功返回true。如果是移除方法,则是从队列中取出一个元素,没有则返回null。
- 一直阻塞:当阻塞队列满时,如果生产者线程往队列里面put元素,则生产者线程会被阻塞,知道队列不满或者响应中断退出。当队列为空时,如果消费者线程从队列里take元素。
- 超时退出:当阻塞队列满时,如果生产者线程往队列里插入元素,队列会阻塞生产者线程一段时间,如果超过了指定时间,生产者线程就会退出。
如果是无界阻塞队列,队列不会出现满的情况
阻塞队列
-
ArrayBlockingQueue:一个由数组结构组成的有界阻塞队列 。 ArrayBlockingQueue 是一个有界的阻塞队列,其内部实现是将对象放到一个数组里。有界也就意味着,它不能够存储无限多数量的元素。它有一个同一时间能够存储元素数量的上限。你可以在对其初始化的时候设定这个上限,但之后就无法对这个上限进行修改了, 因为它是基于数组实现的,也就具有数组的特性:一旦初始化,大小就无法修改 。
-
LinkedBlockingQueue:一个由链表结构组成的有界阻塞队列,LinkedBlockingQueue 内部以一个链式结构(链接节点)对其元素进行存储。如果需要的话,这一链式结构可以选择一个上限。如果没有定义上限,将使用 Integer.MAX_VALUE 作为上限。
-
PriorityBlockingQueue:一个支持优先级排序的无界阻塞队列,PriorityBlockingQueue 是一个无界的并发队列。它使用了和类 java.util.PriorityQueue 一样的排序规则。你无法向这个队列中插入 null 值。所有插入到 PriorityBlockingQueue 的元素必须实现 java.lang.Comparable 接口。因此该队列中元素的排序就取决于你自己的 Comparable 实现。
-
DelayQueue:一个使用优先级队列实现的无界阻塞队列,DelayQueue 对元素进行持有直到一个特定的延迟到期。注入其中的元素必须实现 java.util.concurrent.Delayed 接口。
-
SynchronousQueue:一个不存储元素的阻塞队列,SynchronousQueue 是一个特殊的队列,它的内部同时只能够容纳单个元素。如果该队列已有一元素的话,试图向队列中插入一个新元素的线程将会阻塞,直到另一个线程将该元素从队列中抽走。同样,如果该队列为空,试图向队列中抽取一个元素的线程将会阻塞,直到另一个线程向队列中插入了一条新的元素。据此,把这个类称作一个队列显然是夸大其词了。它更多像是一个汇合点。
-
LinkedTransferQueue:一个由链表结构组成的无界阻塞队列
-
- LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列
阻塞队列的实现原理:
如果队列是空的,消费者会一直等待,当生产者添加元素时,消费者是如何知道当前队列有元素的呢?
使用通知模式实现。所谓通知模式,就是当生产者往满的队列添加元素时会阻塞住生产者,当消费者消费了一个队列中的元素后,会通知生产者当前队列可用。
其实阻塞队列实现阻塞同步的方式很简单,使用的就是是lock锁的多条件(condition)阻塞控制。使用BlockingQueue封装了根据条件阻塞线程的过程,而我们就不用关心繁琐的await/signal操作了。
下面是Jdk 1.7中ArrayBlockingQueue部分代码:
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
//创建数组
this.items = new Object[capacity];
//创建锁和阻塞条件
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
//添加元素的方法
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
notFull.await();
//如果队列不满就入队
enqueue(e);
} finally {
lock.unlock();
}
}
//入队的方法
private void enqueue(E x) {
final Object[] items = this.items;
items[putIndex] = x;
if (++putIndex == items.length)
putIndex = 0;
count++;
notEmpty.signal();
}
//移除元素的方法
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0)
notEmpty.await();
return dequeue();
} finally {
lock.unlock();
}
}
//出队的方法
private E dequeue() {
final Object[] items = this.items;
@SuppressWarnings("unchecked")
E x = (E) items[takeIndex];
items[takeIndex] = null;
if (++takeIndex == items.length)
takeIndex = 0;
count--;
if (itrs != null)
itrs.elementDequeued();
notFull.signal();
return x;
}
双端阻塞队列(BlockingDeque)
concurrent包下还提供双端阻塞队列(BlockingDeque),和BlockingQueue是类似的,只不过BlockingDeque提供从任意一端插入或者抽取元素的队列。
阻塞队列的使用场景
import java.util.Random;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.TimeUnit;
public class BlockingQueueTest {
//生产者
public static class Producer implements Runnable{
private final BlockingQueue<Integer> blockingQueue;
private volatile boolean flag;
private Random random;
public Producer(BlockingQueue<Integer> blockingQueue) {
this.blockingQueue = blockingQueue;
flag=false;
random=new Random();
}
public void run() {
while(!flag){
int info=random.nextInt(100);
try {
blockingQueue.put(info);
System.out.println(Thread.currentThread().getName()+" produce "+info);
Thread.sleep(50);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
public void shutDown(){
flag=true;
}
}
//消费者
public static class Consumer implements Runnable{
private final BlockingQueue<Integer> blockingQueue;
private volatile boolean flag;
public Consumer(BlockingQueue<Integer> blockingQueue) {
this.blockingQueue = blockingQueue;
}
public void run() {
while(!flag){
int info;
try {
info = blockingQueue.take();
System.out.println(Thread.currentThread().getName()+" consumer "+info);
Thread.sleep(50);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
public void shutDown(){
flag=true;
}
}
public static void main(String[] args){
BlockingQueue<Integer> blockingQueue = new LinkedBlockingQueue<Integer>(10);
Producer producer=new Producer(blockingQueue);
Consumer consumer=new Consumer(blockingQueue);
//创建5个生产者,5个消费者
for(int i=0;i<10;i++){
if(i<5){
new Thread(producer,"producer"+i).start();
}else{
new Thread(consumer,"consumer"+(i-5)).start();
}
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
producer.shutDown();
consumer.shutDown();
}
}
14 、什么是Callable和Future?
一个产生结果,一个拿到结果
public class CallableAndFuture {
public static void main(String[] args) {
Callable<Integer> callable = new Callable<Integer>() {
public Integer call() throws Exception {
return new Random().nextInt(100);
}
};
FutureTask<Integer> future = new FutureTask<Integer>(callable);
new Thread(future).start();
try {
Thread.sleep(5000);// 可能做一些事情
System.out.println(future.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
15 、什么是FutureTask? 使用ExecutorService启动任务。
什么是 FutureTask
FutureTask 实现了 RunnableFuture 接口 , RunnableFutrue接口 集成了 Runnable 和 Future
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nXsjldtD-1618135569568)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210405203259514.png)]
从上面可以看出 FutureTask 既有 Runnable 的特点又有 Future 的特点。可以看出设计者就是通过在线程周期中去进行异步计算并对异步计算进行状态控制和结果获取。而且我们上一文在对 Future 异步计算的不同状态在 FutureTask 中使用了状态机来进行状态描述:
从源码注释中也注明了 FutureTask 的状态转换流程,简单画了一张图来更加清晰的描述其中的关系:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HVKeN10M-1618135569569)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210405203410700.png)]
上面的状态流程贯穿 FutureTask 的整个生命周期。接下来来对这些状态的流转进行一些分析。
FutureTask 的状态
NEW
该状态就是 FutureTask 利用构造初始化的状态。FutureTask 共有两个构造函数,一个是 Callable 作为参数的构造函数;另一个则是 Runnable 和泛型结果容器 result 作为参数的构造函数,其中 Runnable 最终也被转成了 Callable 。NEW 状态干了三件事:
初始化 FutureTask。
初始化执行任务的逻辑线程 Callable。
将当前状态设置为 NEW 。
CANCELLED
这个其实在讲Future 接口时已经说了,将计算取消意味着异步计算生命周期的结束。详情可以看上一篇文章相关的说明。但是我们还是想来看看是如何取消的:
public boolean cancel(boolean mayInterruptIfRunning) {
//如果正处于NEW状态,希望请求正在运行也希望中断就设置为INTERRUTPTING,否则直接设置CANCELLED
if (!(state == NEW &&
UNSAFE.compareAndSwapInt(this, stateOffset, NEW,
mayInterruptIfRunning ? INTERRUPTING : CANCELLED)))
return false;
try { // in case call to interrupt throws exception
if (mayInterruptIfRunning) {
try {
Thread t = runner;
if (t != null)
t.interrupt();
} finally {
// 更新到最终的打断状态
UNSAFE.putOrderedInt(this, stateOffset, INTERRUPTED);
}
}
} finally {
// 唤醒等待线程 来处理结束的状态
finishCompletion();
}
return true;
}
这里用了 CAS 原子操作来尝试进行取消。 当前如果是 NEW 状态然后结合另一个策略参数 mayInterruptIfRunning 来看看是不是正在中断或者已经取消,决定是否进行取消操作。如果允许运行时中断首先将状态更新为 INTERRUPTING 状态,然后线程中断的会把状态更新为 INTERRUPTED
COMPLETING
正在完成中,开始我以为是任务正在进行,然而我错了,该状态意思是计算已经完毕,但是没有暴露出去,而且正在设置给暴露的 outcome 变量。那么 RUNNING 状态哪里去了?
The run state transitions to a terminal state only in methods set,setException, and cancel.
这是相关的注释说明,RUN 状态仅仅是所有的 set 方法和 cancel 时的一个过度状态。其实想想也对运行状态如果不变其实也没有什么需要我们关心的。isDone() 方法说明了一切,只要不是 NEW 状态就任务任务完成了,但是没有结束。
NORMAL
当状态由 NEW 转为 COMPLETING (这又是一个CAS 操作)后,计算结果暴露出去赋值给 outcome ,然后使用自旋锁去不停向等待队列发出已经计算完毕的信号。有个地方非常有趣,作者的结束逻辑写的非常巧妙:
private void finishCompletion() {
// 已经 断言当前状态 肯定是已经开始执行任务了,即不是初始化 NEW 状态
// assert state > COMPLETING;
// 当前有线程挂起在等着拿结果
for (WaitNode q; (q = waiters) != null;) {
// 抢占线程 这里跟 for 结合的很巧妙 直接设置null 简单实用
if (UNSAFE.compareAndSwapObject(this, waitersOffset, q, null)) {
// 不停的自旋 ,当然 LockSupport和Thread. interrupted搭配必须要自旋
for (;;) {
Thread t = q.thread;
if (t != null) {
q.thread = null;
LockSupport.unpark(t);
}
WaitNode next = q.next;
if (next == null)
break;
// 优化回收
q.next = null; // unlink to help gc
// 赋值以快速获取线程快速拿到结果 这里也很巧妙
q = next;
}
break;
}
}
// 空方法 你可以覆写来做一些记录
done();
callable = null; // to reduce footprint
}
EXCEPTIONAL
当抛出中断异常或者其它异常时发出设置异常状态
INTERRUPTING
其它线程在得知当前的状态为 INTERRUPTING 时,通过 Thread.yield 让出当前的 CPU 时间片,并重新就绪竞争 CPU 调度权。就像发现某件事情正在处理,我们先出去重新等待,等人家处理完我们再来试一试一样。
INTERRUPTED
参见对 CANCELLED 的分析。
FutureTask 如何运作
FutureTask 除了控制状态外,其他都是根据状态来进行判断进而执行具体的策略。我们实际用到的有以下两个方法。
run
异步任务主要在该方法中进行计算,记住计算是另外一个线程中进行计算的。
public void run() {
// 如果当前不是NEW,或者当前任务已经有了其他执行线程执行 就不再重复
if (state != NEW ||
!UNSAFE.compareAndSwapObject(this, runnerOffset,
null, Thread.currentThread()))
return;
try {
// 在另一个线程中进行计算 并记录结果 处理异常
Callable<V> c = callable;
if (c != null && state == NEW) {
V result;
boolean ran;
try {
result = c.call();
ran = true;
} catch (Throwable ex) {
result = null;
ran = false;
setException(ex);
}
if (ran)
set(result);
}
} finally {
// runner must be non-null until state is settled to
// prevent concurrent calls to run()
// runner 用来执行 callable 并进行 cas
// 状态被设置后 runner 被设置为null
// 防止 run 方法并发
runner = null;
// state must be re-read after nulling runner to prevent
// leaked interrupts
// 设置 runner 为 null 后需要检查一下状态 防止泄露中断
int s = state;
if (s >= INTERRUPTING)
handlePossibleCancellationInterrupt(s);
}
}
get
get 方法就是一个等待任务结果的过程 核心方法为 awaitDone, 当异步任务执行时线程会挂起要么直接等到任务完成,要么直接等到超时放弃。具体看下面的源码分析:
private int awaitDone(boolean timed, long nanos)
throws InterruptedException {
final long deadline = timed ? System.nanoTime() + nanos : 0L;
WaitNode q = null;
boolean queued = false;
for (;;) {
// 如果当前线程被中断就不停尝试移除等待队列
if (Thread.interrupted()) {
removeWaiter(q);
throw new InterruptedException();
}
int s = state;
// 完成 取消或者发生异常 直接返回 不再等待
if (s > COMPLETING) {
if (q != null)
q.thread = null;
return s;
}
// 如果还在完成中 就先让出调度继续等待 yield 效率要高 它会继续抢占调度来尝试
else if (s == COMPLETING) // cannot time out yet
Thread.yield();
// 如果刚刚进入等待状态就 初始化一个等待队列
else if (q == null)
q = new WaitNode();
// 尝试将没有入队的等待线程加入等待队列 基于cas
else if (!queued)
queued = UNSAFE.compareAndSwapObject(this, waitersOffset,
q.next = waiters, q);
// 处理超时逻辑
else if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
removeWaiter(q);
return state;
}
LockSupport.parkNanos(this, nanos);
}
else
// 不设置超时将一直阻塞到当前等待结果线程
LockSupport.park(this);
}
}
16 、什么是并发容器的实现?
同步容器
在 Java 中,同步容器主要包括 2 类:
-
Vector、Stack、HashTable
- Vector 实现了 List 接口,Vector 实际上就是一个数组,和 ArrayList 类似,但是 Vector 中的方法都是 synchronized 方法,即进行了同步措施。
- Stack 也是一个同步容器,它的方法也用 synchronized 进行了同步,它实际上是继承于 Vector 类。
- HashTable 实现了 Map 接口,它和 HashMap 很相似,但是 HashTable 进行了同步处理,而 HashMap 没有。
-
Collections 类中提供的静态工厂方法创建的类(由 Collections.synchronizedXxxx 等方法)
同步容器的缺陷
同步容器的同步原理就是在方法上用 synchronized 修饰。那么,这些方法每次只允许一个线程调用执行。
性能问题
由于被 synchronized 修饰的方法,每次只允许一个线程执行,其他试图访问这个方法的线程只能等待。显然,这种方式比没有使用 synchronized 的容器性能要差。
安全问题
同步容器真的一定安全吗?
答案是:未必。同步容器未必真的安全。在做复合操作时,仍然需要加锁来保护。
常见复合操作如下:
迭代:反复访问元素,直到遍历完全部元素;
跳转:根据指定顺序寻找当前元素的下一个(下 n 个)元素;
条件运算:例如若没有则添加等;
不安全的示例
public class Test {
static Vector<Integer> vector = new Vector<Integer>();
public static void main(String[] args) throws InterruptedException {
while(true) {
for(int i=0;i<10;i++)
vector.add(i);
Thread thread1 = new Thread(){
public void run() {
for(int i=0;i<vector.size();i++)
vector.remove(i);
};
};
Thread thread2 = new Thread(){
public void run() {
for(int i=0;i<vector.size();i++)
vector.get(i);
};
};
thread1.start();
thread2.start();
while(Thread.activeCount()>10) {
}
}
}
}
执行时可能会出现数组越界错误。
Vector 是线程安全的,为什么还会报这个错?很简单,对于 Vector,虽然能保证每一个时刻只能有一个线程访问它,但是不排除这种可能:
当某个线程在某个时刻执行这句时:
for(int i=0;i<vector.size();i++)
vector.get(i);
假若此时 vector 的 size 方法返回的是 10,i 的值为 9
然后另外一个线程执行了这句:
for(int i=0;i<vector.size();i++)
vector.remove(i);
将下标为 9 的元素删除了。
那么通过 get 方法访问下标为 9 的元素肯定就会出问题了。
安全示例
因此为了保证线程安全,必须在方法调用端做额外的同步措施,如下面所示:
public class Test {
static Vector<Integer> vector = new Vector<Integer>();
public static void main(String[] args) throws InterruptedException {
while(true) {
for(int i=0;i<10;i++)
vector.add(i);
Thread thread1 = new Thread(){
public void run() {
synchronized (Test.class) { //进行额外的同步
for(int i=0;i<vector.size();i++)
vector.remove(i);
}
};
};
Thread thread2 = new Thread(){
public void run() {
synchronized (Test.class) {
for(int i=0;i<vector.size();i++)
vector.get(i);
}
};
};
thread1.start();
thread2.start();
while(Thread.activeCount()>10) {
}
}
}
}
ConcurrentModificationException 异常
在对 Vector 等容器并发地进行迭代修改时,会报 ConcurrentModificationException 异常,关于这个异常将会在后续文章中讲述。
但是在并发容器中不会出现这个问题。
并发容器
JDK 的 java.util.concurrent 包(即 juc)中提供了几个非常有用的并发容器。
- CopyOnWriteArrayList - 线程安全的 ArrayList
- CopyOnWriteArraySet - 线程安全的 Set,它内部包含了一个 CopyOnWriteArrayList,因此本质上是由 CopyOnWriteArrayList 实现的。
- ConcurrentSkipListSet - 相当于线程安全的 TreeSet。它是有序的 Set。它由 ConcurrentSkipListMap 实现。
- ConcurrentHashMap - 线程安全的 HashMap。采用
分段锁实现高效并发。 - ConcurrentSkipListMap - 线程安全的有序 Map。使用跳表实现高效并发。
- ConcurrentLinkedQueue - 线程安全的无界队列。底层采用单链表。支持 FIFO。
- ConcurrentLinkedDeque - 线程安全的无界双端队列。底层采用双向链表。支持 FIFO 和 FILO。
- ArrayBlockingQueue - 数组实现的阻塞队列。
- LinkedBlockingQueue - 链表实现的阻塞队列。
- LinkedBlockingDeque - 双向链表实现的双端阻塞队列。
ConcurrentHashMap
要点
作用:ConcurrentHashMap 是线程安全的 HashMap。
原理:JDK6 与 JDK7 中,ConcurrentHashMap 采用了分段锁机制。JDK8 中,摒弃了锁分段机制,改为利用 CAS 算法。
源码JDK7
ConcurrentHashMap 类在 jdk1.7 中的设计,其基本结构如图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NGHsZ045-1618135569569)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210405210754122.png)]
每一个 segment 都是一个 HashEntry<K,V>[] table, table 中的每一个元素本质上都是一个 HashEntry 的单向队列。比如 table[3]为首节点,table[3]->next 为节点 1,之后为节点 2,依次类推。
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V>
implements ConcurrentMap<K, V>, Serializable {
// 将整个hashmap分成几个小的map,每个segment都是一个锁;与hashtable相比,这么设计的目的是对于put, remove等操作,可以减少并发冲突,对
// 不属于同一个片段的节点可以并发操作,大大提高了性能
final Segment<K,V>[] segments;
// 本质上Segment类就是一个小的hashmap,里面table数组存储了各个节点的数据,继承了ReentrantLock, 可以作为互拆锁使用
static final class Segment<K,V> extends ReentrantLock implements Serializable {
transient volatile HashEntry<K,V>[] table;
transient int count;
}
// 基本节点,存储Key, Value值
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
}
}
JDK8
jdk8 中主要做了 2 方面的改进
- 取消 segments 字段,直接采用 transient volatile HashEntry<K,V>[] table 保存数据,采用 table 数组元素作为锁,从而实现了对每一行数据进行加锁,进一步减少并发冲突的概率。
- 将原先 table 数组+单向链表的数据结构,变更为 table 数组+单向链表+红黑树的结构。对于 hash 表来说,最核心的能力在于将 key hash 之后能均匀的分布在数组中。如果 hash 之后散列的很均匀,那么 table 数组中的每个队列长度主要为 0 或者 1。但实际情况并非总是如此理想,虽然 ConcurrentHashMap 类默认的加载因子为 0.75,但是在数据量过大或者运气不佳的情况下,还是会存在一些队列长度过长的情况,如果还是采用单向列表方式,那么查询某个节点的时间复杂度为 O(n);因此,对于个数超过 8(默认值)的列表,jdk1.8 中采用了红黑树的结构,那么查询的时间复杂度可以降低到 O(logN),可以改进性能。
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 如果table为空,初始化;否则,根据hash值计算得到数组索引i,如果tab[i]为空,直接新建节点Node即可。注:tab[i]实质为链表或者红黑树的首节点。
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// 如果tab[i]不为空并且hash值为MOVED,说明该链表正在进行transfer操作,返回扩容完成后的table。
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 针对首个节点进行加锁操作,而不是segment,进一步减少线程冲突
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 如果在链表中找到值为key的节点e,直接设置e.val = value即可。
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
// 如果没有找到值为key的节点,直接新建Node并加入链表即可。
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// 如果首节点为TreeBin类型,说明为红黑树结构,执行putTreeVal操作。
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
// 如果节点数>=8,那么转换链表结构为红黑树结构。
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
// 计数增加1,有可能触发transfer操作(扩容)。
addCount(1L, binCount);
return null;
}
public class ConcurrentHashMapDemo {
public static void main(String[] args) throws InterruptedException {
// HashMap 在并发迭代访问时会抛出 ConcurrentModificationException 异常
// Map<Integer, Character> map = new HashMap<>();
Map<Integer, Character> map = new ConcurrentHashMap<>();
Thread wthread = new Thread(() -> {
System.out.println("写操作线程开始执行");
for (int i = 0; i < 26; i++) {
map.put(i, (char) ('a' + i));
}
});
Thread rthread = new Thread(() -> {
System.out.println("读操作线程开始执行");
for (Integer key : map.keySet()) {
System.out.println(key + " - " + map.get(key));
}
});
wthread.start();
rthread.start();
Thread.sleep(1000);
}
}
CopyOnWriteArrayList
要点
作用:CopyOnWrite 字面意思为写入时复制。CopyOnWriteArrayList 是线程安全的 ArrayList。
原理:
- 在 CopyOnWriteAarrayList 中,读操作不同步,因为它们在内部数组的快照上工作,所以多个迭代器可以同时遍历而不会相互阻塞(1,2,4)。
- 所有的写操作都是同步的。他们在备份数组(3)的副本上工作。写操作完成后,后备阵列将被替换为复制的阵列,并释放锁定。支持数组变得易变,所以替换数组的调用是原子(5)。
- 写操作后创建的迭代器将能够看到修改的结构(6,7)。
- 写时复制集合返回的迭代器不会抛出 ConcurrentModificationException,因为它们在数组的快照上工作,并且无论后续的修改(2,4)如何,都会像迭代器创建时那样完全返回元素。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9hIZAJY2-1618135569570)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210405211233793.png)]
源码
重要属性
lock - 执行写时复制操作,需要使用可重入锁加锁
array - 对象数组,用于存放元素
/** The lock protecting all mutators */
final transient ReentrantLock lock = new ReentrantLock();
/** The array, accessed only via getArray/setArray. */
private transient volatile Object[] array;
重要方法
添加操作
添加的逻辑很简单,先将原容器 copy 一份,然后在新副本上执行写操作,之后再切换引用。当然此过程是要加锁的。
public boolean add(E e) {
//ReentrantLock加锁,保证线程安全
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
//拷贝原容器,长度为原容器长度加一
Object[] newElements = Arrays.copyOf(elements, len + 1);
//在新副本上执行添加操作
newElements[len] = e;
//将原容器引用指向新副本
setArray(newElements);
return true;
} finally {
//解锁
lock.unlock();
}
}
删除操作
- 删除操作同理,将除要删除元素之外的其他元素拷贝到新副本中,然后切换引用,将原容器引用指向新副本。同属写操作,需要加锁。
public E remove(int index) {
//加锁
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
E oldValue = get(elements, index);
int numMoved = len - index - 1;
if (numMoved == 0)
//如果要删除的是列表末端数据,拷贝前len-1个数据到新副本上,再切换引用
setArray(Arrays.copyOf(elements, len - 1));
else {
//否则,将除要删除元素之外的其他元素拷贝到新副本中,并切换引用
Object[] newElements = new Object[len - 1];
System.arraycopy(elements, 0, newElements, 0, index);
System.arraycopy(elements, index + 1, newElements, index,
numMoved);
setArray(newElements);
}
return oldValue;
} finally {
//解锁
lock.unlock();
}
}
读操作
- CopyOnWriteArrayList 的读操作是不用加锁的,性能很高。
public E get(int index) {
return get(getArray(), index);
}
private E get(Object[] a, int index) {
return (E) a[index];
}
public class CopyOnWriteArrayListDemo {
static class ReadTask implements Runnable {
List<String> list;
ReadTask(List<String> list) {
this.list = list;
}
public void run() {
for (String str : list) {
System.out.println(str);
}
}
}
static class WriteTask implements Runnable {
List<String> list;
int index;
WriteTask(List<String> list, int index) {
this.list = list;
this.index = index;
}
public void run() {
list.remove(index);
list.add(index, "write_" + index);
}
}
public void run() {
final int NUM = 10;
// ArrayList 在并发迭代访问时会抛出 ConcurrentModificationException 异常
// List<String> list = new ArrayList<>();
CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<>();
for (int i = 0; i < NUM; i++) {
list.add("main_" + i);
}
ExecutorService executorService = Executors.newFixedThreadPool(NUM);
for (int i = 0; i < NUM; i++) {
executorService.execute(new ReadTask(list));
executorService.execute(new WriteTask(list, i));
}
executorService.shutdown();
}
public static void main(String[] args) {
new CopyOnWriteArrayListDemo().run();
}
}
17 、多线程同步和互斥有几种实现方法,都是什么?
什么是同步?
是指在不同进程之间的若干程序片断,它们的运行必须严格按照规定的某种先后次序来运行,这种先后次序依赖于要完成的特定的任务。如果用对资源的访问来定义的话,同步是指在互斥的基础上(大多数情况),通过其它机制实现访问者对资源的有序访问。在大多数情况下,同步已经实现了互斥,特别是所有写入资源的情况必定是互斥的。少数情况是指可以允许多个访问者同时访问资源。
什么是互斥?
是指散布在不同进程之间的若干程序片断,当某个进程运行其中一个程序片段时,其它进程就不能运行它们之中的任一程序片段,只能等到该进程运行完这个程序片段后才可以运行。如果用对资源的访问来定义的话,互斥某一资源同时只允许一个访问者对其进行访问,具有唯一性和排它性。但互斥无法限制访问者对资源的访问顺序,即访问是无序的。
当我们有多个线程要同时访问一个变量或对象时,如果这些线程中既有读又有写操作时,就会导致变量值或对象的状态出现混乱,从而导致程序异常。因此多线程同步就是要解决这个问题。线程同步是指线程之间所具有的一种制约关系,一个线程的执行依赖另一个线程的消息,当它没有得到另一个线程的消息时应等待,直到消息到达时才被唤醒。
线程互斥是指对于共享的进程系统资源,在各单个线程访问时的排它性。当有若干个线程都要使用某一共享资源时,任何时刻最多只允许一个线程去使用,其它要使用该资源的线程必须等待,直到占用资源者释放该资源。线程互斥可以看成是一种特殊的线程同步。
线程间的同步方法大体可分为两类:用户模式和内核模式。顾名思义,内核模式就是指利用系统内核对象的单一性来进行同步,使用时需要切换内核态与用户态,而用户模式就是不需要切换到内核态,只在用户态完成操作。
用户模式下的方法有:原子操作(例如一个单一的全局变量),临界区。内核模式下的方法有:事件,信号量,互斥量。
18 、什么是竞争条件?你怎样发现和解决竞争?
什么是竞争条件?
在Java多线程中,当两个或以上的线程对同一个数据进行操作的时候,可能会产生“竞争条件”的现象。这种现象产生的根本原因是因为多个线程在对同一个数据进行操作,此时对该数据的操作是非“原子化”的,可能前一个线程对数据的操作还没有结束,后一个线程又开始对同样的数据开始进行操作,这就可能会造成数据结果的变化未知。
public class TestThread {
public static void main(String[] args) {
// new 出一个新的对象 t
MyThread t = new MyThread();
/**
* 两个线程是在对同一个对象进行操作
*/
Thread ta = new Thread(t, "Thread-A");
Thread tb = new Thread(t, "Thread-B");
ta.start();
tb.start();
}
}
class MyThread implements Runnable {
// 变量 a 被两个线程共同操作,可能会造成线程竞争
int a = 10;
@Override
public void run() {
for (int i = 0; i < 5; i++) {
a -= 1;
try {
Thread.sleep(1);
} catch (InterruptedException e) {}
System.out.println(Thread.currentThread().getName() + " → a = " + a);
}
}
}
最终运行结果如下:
Thread-A → a = 8
Thread-B → a = 7
Thread-A → a = 6
Thread-B → a = 5
Thread-A → a = 4
Thread-B → a = 3
Thread-A → a = 2
Thread-B → a = 1
Thread-A → a = 0
Thread-B → a = 0
从上面的结果中我们可以看到,在线程A对数据进行了操作之后,他还没有来得及数据进行下一次的操作,此时线程B也对数据进行了操作,导致数据a一次性被减了两次,以至于a为9的时候的值根本没有打印出来,a为0的时候却被打印了两次。
那么,我们要如何才能避免结果这种情况的出现呢?
线程锁
如果在一个线程对数据进行操作的时候,禁止另外一个线程操作此数据,那么,就能很好的解决以上的问题了。这种操作叫做给线程加锁。
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class TestThread {
public static void main(String[] args) {
// new 出一个新的对象 t
MyThread t = new MyThread();
/**
* 两个线程是在对同一个对象进行操作
*/
Thread ta = new Thread(t, "Thread-A");
Thread tb = new Thread(t, "Thread-B");
ta.start();
tb.start();
}
}
class MyThread implements Runnable {
// 声明锁
private Lock lock = new ReentrantLock();
// 变量 a 被两个线程共同操作,可能会造成线程竞争
int a = 10;
@Override
public void run() {
// 加锁
lock.lock();
for (int i = 0; i < 5; i++) {
a -= 1;
try {
Thread.sleep(1);
} catch (InterruptedException e) {}
System.out.println(Thread.currentThread().getName() + " → a = " + a);
}
// 解锁
lock.unlock();
}
}
上面的代码给出了给线程枷锁的方式,可以看到,在线程对数据进行操作之前先给此操作加一把锁,那么在此线程对数据进行操作的时候,其他的线程无法对此数据进行操作,只能“阻塞”在一边等待当前线程对数据操作结束后再对数据进行下一次的操作,当前线程在数据的操作完成之后会解开当前的锁以便下一个线程操作此数据。
加锁之后的运行结果如下所示,运行结果符合了我们一开始的要求了。
Thread-A → a = 9
Thread-A → a = 8
Thread-A → a = 7
Thread-A → a = 6
Thread-A → a = 5
Thread-B → a = 4
Thread-B → a = 3
Thread-B → a = 2
Thread-B → a = 1
Thread-B → a = 0
线程同步
从JDK1.0开始,Java中的每一个对象都拥有一个内部锁,如果一个方法用关键字"synchronized"声明,那么对象的锁将保护整个方法。synchronized关键字使得我们不需要再去创建一个锁对象,而只需要在声明一个方法时加上此关键字,那么方法在被一个线程操作时就会自动的被上锁,这种操作的结果和目的与手动创建Lock对象来对数据进行加锁的结果和目的相类似。
用synchronized关键字加锁来对方法进行加锁:
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class TestThread {
public static void main(String[] args) {
MyThread t = new MyThread();
Thread ta = new Thread(t, "Thread-A");
Thread tb = new Thread(t, "Thread-B");
ta.start();
tb.start();
}
}
class MyThread implements Runnable {
int a = 10;
// synchronized 关键字对方法进行加锁
@Override
public synchronized void run() {
for (int i = 0; i < 5; i++) {
a -= 1;
try {
Thread.sleep(1);
} catch (InterruptedException e) {}
System.out.println(Thread.currentThread().getName() + " → a = " + a);
}
}
}
最终运行结果如下:
Thread-A → a = 8
Thread-B → a = 7
Thread-A → a = 6
Thread-B → a = 5
Thread-A → a = 4
Thread-B → a = 3
Thread-A → a = 2
Thread-B → a = 1
Thread-A → a = 0
Thread-B → a = 0
从上面的结果中我们可以看到,在线程A对数据进行了操作之后,他还没有来得及数据进行下一次的操作,此时线程B也对数据进行了操作,导致数据a一次性被减了两次,以至于a为9的时候的值根本没有打印出来,a为0的时候却被打印了两次。
那么,我们要如何才能避免结果这种情况的出现呢?
线程锁
如果在一个线程对数据进行操作的时候,禁止另外一个线程操作此数据,那么,就能很好的解决以上的问题了。这种操作叫做给线程加锁。
其结果和第二节中的结果一致。
总结:
Java中的多线程,当多个线程对一个数据进行操作时,可能会产生“竞争条件”的现象,这时候需要对线程的操作进行加锁,来解决多线程操作一个数据时可能产生问题。加锁方式有两种,一个是申明Lock对象来对语句快进行加锁,另一种是通过synchronized 关键字来对方法进行加锁。以上两种方法都可以有效解决Java多线程中存在的竞争条件的问题。
19 、你将如何使用threaddump?你将如何分析Threaddump?
什么是threaddump , heapdump
Thread Dump是非常有用的诊断Java应用问题的工具。每一个Java虚拟机都有及时生成所有线程在某一点状态的thread-dump的能力,虽然各个 Java虚拟机打印的thread dump略有不同,但是大多都提供了当前活动线程的快照,及JVM中所有Java线程的堆栈跟踪信息,堆栈信息一般包含完整的类名及所执行的方法,如果可能的话还有源代码的行数。
Heap Dump也叫堆转储文件,是一个Java进程在某个时间点上的内存快照。Heap Dump 是有着多种类型的。不过总体上heap dump在触发快照的时候都保存了java对象和类的信息。通常在写 heap dump 文件前会触发一次FullGC,所以heap dump文件中保存的是FullGC后留下的对象信息。
heapDump里有什么
一般在Heap Dump文件中可以获取到(这仍然取决于heap dump文件的类型)如下信息:
对象信息:类、成员变量、直接量以及引用值;
类信息:类加载器、名称、超类、静态成员;
Garbage Collections Roots: JVM可达的对象;
线程栈以及本地变量: 获取快照时的线程栈信息,以及局部变量的详细信息。
也就是说我们可以对上面这些内容进行分析。通常可以基于Heap Dump分析如下类型的问题:
找出内存泄漏的原因;
找出重复引用的jar或类;
分析集合的使用;
分析类加载器。
总而言之我们对Heap Dump的分析就是对应用的内存使用进行分析,从而更加合理地使用内存。
怎样获取Heap Dump
获取heap dump有多种方式,可以通过参数配置在特定的条件下触发堆转储,也可以通过工具来获取。
通过设置如下的JVM参数,可以在发生OutOfMemoryError后获取到一份HPROF二进制Heap Dump文件:
-XX:+HeapDumpOnOutOfMemoryError
生成的文件会直接写入到工作目录。
这个方案适用于如下版本的虚拟机:Sun JVM (1.4.2_12 or higher and 1.5.0_07 or higher), HP-UX JVM (1.4.2_11 or higher) and SAP JVM (since 1.5.0)。
主动触发Heap Dump
也可以为虚拟机设置下面的参数,这样就可以在需要的时候按下CTRL+BREAK组合键随时获取一份heap dump文件。
-XX:+HeapDumpOnCtrlBreak
使用HPROF agent
使用agent可以在程序执行结束时或者收到SIGQUIT信号时生成dump文件。使用agent也是要配置虚拟机参数的:
-agentlib:hprof=heap=dump,format=b
使用jmap
jmap -dump:format=b,file=<filename.hprof> <pid>
使用jconsole
启动一个应用后,打开<JAVA_HOME>/bin/jconsole.exe,在jconsole中选择正在运行的应用
(在这个例子中选择的是eclipse,虽然进程名称为空,但是通过重启eclipse可以确认)。
建立连接后,选择页签MBean,执行com.sun.management. HotSpotDiagnostic下的操作dumpHeap。第一个参数p0是要获取的dump文件的完整路径名,记得文件要以.hprof作为扩展名(要在Memory AnalysisPerspective下打开扩展名必须是这个)。如果我们只想获取live的对象,第二个参数p1需要保持为true。
建议将导出的dump文件保存到一个独立的文件夹,在接下来的分析中会通过这个文件创建很多图表文件。
Memory Analyzer分析工具
如果要获取dump文件的Java进程和Memory Analyzer在同一台机器上,可以直接使用Memory Analyzer获取dump文件。采用这种方式获取dump文件后会直接将之解析并在Memory Analyzer中打开。
获取heap dump是受虚拟机支持的一种特定的功能。Memory Analyzer提供了一些被称为Heap Dump Provider的概念:比如支持Sun虚拟机(需要用到Sun JDK的jmap功能)的Provider或支持IBM虚拟机(也需要一个IBM JDK)的Provider。此外,Memory Analyzer也提供了对用户自定义的Heap Dump Provider插件的扩展支持。
要使用 Memory Analyzer 获取dump文件需要先打开Memory AnalysisPerspective,而后点击File -> Acquire Heap Dump…菜单项。之后会打开如下窗口
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gsbAYuFI-1618135569570)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210408190543367.png)]
在上图中,根据具体的运行环境,预装的Heap Dump Provider按照默认设置展示了当前正在运行的java进程列表。一些Heap Dump Provider也允许(或者说需要)设置一些额外的参数(比如heap dump的类型),这个可以点击Configure按钮来设置。选择要dump的线程,点击Next按钮就可以生成dump文件了。
有的时候进程列表可能为空,这时有必要调整下Heap Dump Provider的设置了。点击Configure按钮,选择合适的provider并点击,然后找到要做调整的参数并做设置就好了。
怎么生成threaddump
使用java自带命令jstack:
jstack pid > pid_stack.log
如何分析threaddump
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0TAnWgKU-1618135569571)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210408191247059.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wKylWvJP-1618135569571)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210411091154930.png)]
新建状态(New)
用new语句创建的线程处于新建状态,此时它和其他Java对象一样,仅仅在堆区中被分配了内存。
就绪状态(Runnable)
当一个线程对象创建后,其他线程调用它的start()方法,该线程就进入就绪状态,Java虚拟机会为它创建方法调用栈和程序计数器。处于这个状态的线程位于可运行池中, 等待获得CPU的使用权。
运行状态(Running)
处于这个状态的线程占用CPU,执行程序代码。只有处于就绪状态的线程才有机会转到运行状态。
阻塞状态(Blocked)
阻塞状态是指线程因为某些原因放弃CPU,暂时停止运行。当线程处于阻塞状态时,Java虚拟机不会给线程分配CPU。直到线程重新进入就绪状态,它才有机会转到运行状态。
阻塞状态可分为以下3种:
① 位于对象等待池中的阻塞状态(Blocked in object’s wait pool):当线程处于运行状态时,如果执行了某个对象的wait()方法,Java虚拟机就会把线程放到这个对象的等待池中,这涉及到“线程通信”的内容。
② 位于对象锁池中的阻塞状态(Blocked in object’s lock pool):当线程处于运行状态时,试图获得某个对象的同步锁时,如果该对象的同步锁已经被其他线程占用,Java虚拟机就会把这个线程放到这个对象的锁池中,这涉及到“线程同步”的内容。
③ 其他阻塞状态(Otherwise Blocked):当前线程执行了sleep()方法,或者调用了其他线程的join()方法,或者发出了I/O请求时,就会进入这个状态。
死亡状态(Dead)
当线程退出run()方法时,就进入死亡状态,该线程结束生命周期。
20 、为什么我们调用start()方法时会执行run()方法,为什么我们不能直接调用run()方法?
如果我们直接调用子线程的run()方法,其方法还是运行在主线程中,代码在程序中是顺序执行的,所以不会有解决耗时操作的问题。所以不能直接调用线程的run()方法,只有子线程开始了,才会有异步的效果。当thread.start()方法执行了以后,子线程才会执行run()方法,这样的效果和在主线程中直接调用run()方法的效果是截然不同的
start( )与run( )之间有什么区别
run()方法:
在本线程内调用该Runnable对象的run()方法,可以重复多次调用;直接执行run()方法不会启动多线程
start()方法:
启动一个线程,调用该Runnable对象的run()方法,不能多次启动一个线程;也就是说start()方法做了两件事情:启动线程和执行run()方法。
start与run方法的主要区别在于当程序调用start方法一个新线程将会被创建,并且
在run方法中的代码将会在新线程上运行,然而在你直接调用run方法的时候,程
序并不会创建新线程,run方法内部的代码将在当前线程上运行。大多数情况下
调用run方法是一个bug或者变成失误。因为调用者的初衷是调用start方法去开启
一个新的线程,这个错误可以被很多静态代码覆盖工具检测出来,比如与
fingbugs. 如果你想要运行需要消耗大量时间的任务,你最好使用start方法,否则
在你调用run方法的时候,你的主线程将会被卡住。
另外一个区别在于,一但一个线程被启动,你不能重复调用该thread对象的start方法,
调用已经启动线程的start方法将会报IllegalStateException异常, 而你却可以重复调用run方法。
21 、Java中你怎样唤醒一个阻塞的线程?
根据线程阻塞的原因:
**sleep **
sleep期间得不到CPU时间片 , 等到时间过去之后, 线程重新进入可执行状态, 暂停线程,不会释放锁
interrupt 打断 或者 等到时间过去自行进入可执行状态
suspend
挂起线程, 使线程进入阻塞状态, 只有对应的resume被调用的时候, 线程才会进入可执行状态,不建议使用
容易造成死锁,
yield
会使得线程放弃当前分得的cpu时间片, 但是线程目前还是处于可执行状态,随时可以再次分得cpu时间继续执行,yield方法只能使同优先级的线程有执行机会,调用yield()的效果等价于调度程序认为该线程已执行了足够的时间从而转到另一个线程。(暂停当前正在执行的线程,并执行其他线程,且让出的时间不可知)
I/O 操作:
因为I/O是操作系统实现的, Java 程序无法直接接触到操作系统 , 无法唤醒
wait : Object’s wait pool
notify , notifyAll
两个方法搭配使用,wait()使线程进入阻塞状态,调用notify()时,线程进入可执行状态。wait()内可加或不加参数,加参数时是以毫秒为单位,当到了指定时间或调用notify()方法时,进入可执行状态。(属于Object类,而不属于Thread类,wait()会先释放锁住的对象,然后再执行等待的动作。由于wait()所等待的对象必须先锁住,因此,它只能用在同步化程序段或者同步化方法内,否则,会抛出异常IllegalMonitorStateException.)
join 方法
也叫线程加入。是当前线程A调用另一个线程B的join()方法,当前线程转A入阻塞状态,直到线程B运行结束,线程A才由阻塞状态转为可执行状态。
以上是Java线程唤醒和阻塞的五种常用方法,不同的方法有不同的特点,其中wait() 和
notify()是其中功能最强大、使用最灵活的方法,但这也导致了它们效率较低、较容易出错的特性,因此,在实际应用中应灵活运用各种方法,以达到期望的目的与效果!
synchronized , Lock ,ReentrantLock: Object’s lock pool
synchronized: 不能被唤醒,只能被动等待释放锁, 容易产生死锁
lock: unlock
22 、在Java中CyclicBarriar和CountdownLatch有什么区别?
CountDownLatch和CyclicBarrier都是java.util.concurrent包下面的多线程工具类。
从字面上理解,CountDown表示减法计数,Latch表示门闩的意思,计数为0的时候就可以打开门闩了。Cyclic Barrier表示循环的障碍物。两个类都含有这一个意思:对应的线程都完成工作之后再进行下一步动作,也就是大家都准备好之后再进行下一步。然而两者最大的区别是,进行下一步动作的动作实施者是不一样的。这里的“动作实施者”有两种,一种是主线程(即执行main函数),另一种是执行任务的其他线程,后面叫这种线程为“其他线程”,区分于主线程。对于CountDownLatch,当计数为0的时候,下一步的动作实施者是main函数;对于CyclicBarrier,下一步动作实施者是“其他线程”。
备注:这里我们使用主线程(即main函数)来创建CountDown和CyclicBarrier对象。所以上文将线程分为“主线程”和“其它线程”两类,主要是便于大家理解。需要提醒读者的是,不单单是主线程可以创建该对象,其它当前正在运行的线程也可以创建CountDown和CyclicBarrier对象,此时该current thread扮演了“主线程”的角色。因此,更加准确的方式是将线程分为“当前线程”和“其它线程”,前者表示创建CountDown和CyclicBarrier对象的线程。希望这个备注没有给大家带来更大的困惑。
下面举例说明:
对于CountDownLatch,其他线程为游戏玩家,比如英雄联盟,主线程为控制游戏开始的线程。在所有的玩家都准备好之前,主线程是处于等待状态的,也就是游戏不能开始。当所有的玩家准备好之后,下一步的动作实施者为主线程,即开始游戏。
我们使用代码模拟这个过程,我们模拟了三个玩家,在三个玩家都准备好之后,游戏才能开始。代码的输出结果为:
import java.util.Random;
import java.util.concurrent.CountDownLatch;
public class CountDownLatchTest {
public static void main(String[] args) throws InterruptedException {
CountDownLatch latch = new CountDownLatch(4);
for(int i = 0; i < latch.getCount(); i++){
new Thread(new MyThread(latch), "player"+i).start();
}
System.out.println("正在等待所有玩家准备好");
latch.await();
System.out.println("开始游戏");
}
private static class MyThread implements Runnable{
private CountDownLatch latch ;
public MyThread(CountDownLatch latch){
this.latch = latch;
}
@Override
public void run() {
try {
Random rand = new Random();
int randomNum = rand.nextInt((3000 - 1000) + 1) + 1000;//产生1000到3000之间的随机整数
Thread.sleep(randomNum);
System.out.println(Thread.currentThread().getName()+" 已经准备好了, 所使用的时间为 "+((double)randomNum/1000)+"s");
latch.countDown();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
对于CyclicBarrier,假设有一家公司要全体员工进行团建活动,活动内容为翻越三个障碍物,每一个人翻越障碍物所用的时间是不一样的。但是公司要求所有人在翻越当前障碍物之后再开始翻越下一个障碍物,也就是所有人翻越第一个障碍物之后,才开始翻越第二个,以此类推。类比地,每一个员工都是一个“其他线程”。当所有人都翻越的所有的障碍物之后,程序才结束。而主线程可能早就结束了,这里我们不用管主线程。
我们使用代码来模拟上面的过程。我们设置了三个员工和三个障碍物。可以看到所有的员工翻越了第一个障碍物之后才开始翻越第二个的,下面是运行结果:
package com.huai.thread;
import java.util.Random;
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;
public class CyclicBarrierTest {
public static void main(String[] args) {
CyclicBarrier barrier = new CyclicBarrier(3);
for(int i = 0; i < barrier.getParties(); i++){
new Thread(new MyRunnable(barrier), "队友"+i).start();
}
System.out.println("main function is finished.");
}
private static class MyRunnable implements Runnable{
private CyclicBarrier barrier;
public MyRunnable(CyclicBarrier barrier){
this.barrier = barrier;
}
@Override
public void run() {
for(int i = 0; i < 3; i++) {
try {
Random rand = new Random();
int randomNum = rand.nextInt((3000 - 1000) + 1) + 1000;//产生1000到3000之间的随机整数
Thread.sleep(randomNum);
System.out.println(Thread.currentThread().getName() + ", 通过了第"+i+"个障碍物, 使用了 "+((double)randomNum/1000)+"s");
this.barrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
}
}
}
}
总结:CountDownLatch和CyclicBarrier都有让多个线程等待同步然后再开始下一步动作的意思,但是CountDownLatch的下一步的动作实施者是主线程,具有不可重复性;而CyclicBarrier的下一步动作实施者还是“其他线程”本身,具有往复多次实施动作的特点。
为了文章的完整性,补充下面一句话:
** 为了将上面的“通俗理解”进一步拓展,将前文中“主线程”替换成“当前线程”。因为创建和启动CountDownLatch和CyclicBarrier的是不仅仅是main线程,也可以是任意一个线程,这里使用当前线程来代替主线程这样的概念。**。希望这样的描述不会给大家带来额外的困惑。
23 、什么是不可变对象,它对写并发应用有什么帮助?
意味着可以传递对象的引用,不用担心改变其内容,特别是在处理并行时,不可变对象不存在锁的问题,易于构造使用
final class ImmutableClass {
final String str;
final int value;
final int[] ints;
public ImmutableClass(final String str, final int value) {
this.str = str;
this.value = value;
}
public String getStr() {
return str;
}
public int getValue() {
return value;
}
}
使用final修饰类
保证类不可继承,保证其不变性
使用final修饰类属性
防止外部改变其属性,破坏不变性
类中包含类引用时,应使用深拷贝
public ImmutableClass(int[] ints) {
this.ints = ints;
}
当直接通过构造器初始化类内部对象时,可通过外部对象的改变从而破坏类的内部状态, 破坏其不变形
public ImmutableClass(int[] ints) {
this.ints = ints.clone();
}
通过深度拷贝,保证状态的不变性
24 、什么是多线程中的上下文切换?
频繁的线程的上下文切换:从操作系统对线程的调度来看,当线程在等待资源而阻塞的时候,操作系统会将之切换出来,放到等待的队列,当线程获得资源之后,调度算法会将这个线程切换进去,放到执行队列中
大量的系统调用:因为线程的上下文切换,以及热锁的竞争,或者临界区的频繁的进出,都可能导致大量的系统调用
大部分CPU开销用在“系统态(sy) ”:线程上下文切换,和系统调用,都会导致 CPU在 “系统态 ”运行,换而言之,虽然系统很忙碌,但是 CPU用在 “用户态 ”的比例较小,应用程序(us)得不到充分的 CPU资源
随着 CPU数目的增多,系统的性能反而下降。因为CPU数目多,同时运行的线程就越多,可能就会造成更频繁的线程上下文切换和系统态的CPU开销,从而导致更糟糕的性能
在高性能编程时,经常接触到多线程. 起初我们的理解是, 多个线程并行地执行总比单个线程要快, 就像多个人一起干活总比一个人干要快. 然而实际情况是, 多线程之间需要竞争IO设备, 或者竞争锁资源,导致往往执行速度还不如单个线程. 在这里有一个经常提及的概念就是: 上下文切换(Context Switch).
多任务系统往往需要同时执行多道作业.作业数往往大于机器的CPU数, 然而一颗CPU同时只能执行一项任务, 如何让用户感觉这些任务正在同时进行呢? 操作系统的设计者巧妙地利用了时间片轮转的方式, CPU给每个任务都服务一定的时间, 然后把当前任务的状态保存下来, 在加载下一任务的状态后, 继续服务下一任务. 任务的状态保存及再加载, 这段过程就叫做上下文切换. 时间片轮转的方式使多个任务在同一颗CPU上执行变成了可能, 但同时也带来了保存现场和加载现场的直接消耗.
(Note. 更精确地说, 上下文切换会带来直接和间接两种因素影响程序性能的消耗. 直接消耗包括: CPU寄存器需要保存和加载, 系统调度器的代码需要执行, TLB实例需要重新加载, CPU 的pipeline需要刷掉; 间接消耗指的是多核的cache之间得共享数据, 间接消耗对于程序的影响要看线程工作区操作数据的大小).
25 、Java中用到的线程调度算法是什么?
抢占式。 一个线程用完CPU之后,操作系统会根据线程优先级、线程饥饿情况等数据算出一个总的优先级并分配下一个时间片给某个线程执行。
操作系统中可能会出现某条线程常常获取到CPU控制权的情况,为了让某些优先级比较低的线程也能获取到CPU控制权,可以使用Thread.sleep(0)手动触发一次操作系统分配时间片的操作,这也是平衡CPU控制权的一种操作
27 、为什么使用Executor框架比使用应用创建和管理线程好?
什么是 Executor框架:
我们知道线程池就是线程的集合,线程池集中管理线程,以实现线程的重用,降低资源消耗,提高响应速度等。线程用于执行异步任务,单个的线程既是工作单元也是执行机制,从JDK1.5开始,为了把工作单元与执行机制分离开,Executor框架诞生了,他是一个用于统一创建与运行的接口。Executor框架实现的就是线程池的功能
Executor框架怎么创建和管理线程
// 固定大小线程池 核心、最大线程数相等, 即无非核心线程数,
// 所以 keepAliveTime , TimeUnit 两个字段其实是无效的
// 阻塞队列用的是 LinkedBlockingQueue 无界队列, 就是说 如果
// 工作线程处理任务的速度赶不上新任务创建的速度, 新任务加入阻塞队列几乎一定会成功
// 极端情况下回导致 硬件资源耗尽宕机
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
/**
重载: 固定大小的线程池 , 设置 线程工厂
*/
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);
}
/**
单个线程
*/
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
/**
单个线程: 重载
*/
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory));
}
/**
使用场景: 大量的耗时较短的任务
无核心线程, 都是非核心线程, 空闲时间60秒, 同步队列
*/
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
threadFactory);
}
public static ScheduledExecutorService newSingleThreadScheduledExecutor() {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1));
}
public static ScheduledExecutorService newSingleThreadScheduledExecutor(ThreadFactory threadFactory) {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1, threadFactory));
}
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public static ScheduledExecutorService newScheduledThreadPool(
int corePoolSize, ThreadFactory threadFactory) {
return new ScheduledThreadPoolExecutor(corePoolSize, threadFactory);
}
public static ExecutorService unconfigurableExecutorService(ExecutorService executor) {
if (executor == null)
throw new NullPointerException();
return new DelegatedExecutorService(executor);
}
public static ScheduledExecutorService unconfigurableScheduledExecutorService(ScheduledExecutorService executor) {
if (executor == null)
throw new NullPointerException();
return new DelegatedScheduledExecutorService(executor);
}
/**
适配器模式
*/
public static <T> Callable<T> callable(Runnable task, T result) {
if (task == null)
throw new NullPointerException();
return new RunnableAdapter<T>(task, result);
}
public static Callable<Object> callable(Runnable task) {
if (task == null)
throw new NullPointerException();
return new RunnableAdapter<Object>(task, null);
}
public static Callable<Object> callable(final PrivilegedAction<?> action) {
if (action == null)
throw new NullPointerException();
return new Callable<Object>() {
public Object call() { return action.run(); }};
}
public static Callable<Object> callable(final PrivilegedExceptionAction<?> action) {
if (action == null)
throw new NullPointerException();
return new Callable<Object>() {
public Object call() throws Exception { return action.run(); }};
}
public static <T> Callable<T> privilegedCallable(Callable<T> callable) {
if (callable == null)
throw new NullPointerException();
return new PrivilegedCallable<T>(callable);
}
public static <T> Callable<T> privilegedCallableUsingCurrentClassLoader(Callable<T> callable) {
if (callable == null)
throw new NullPointerException();
return new PrivilegedCallableUsingCurrentClassLoader<T>(callable);
}
/**
工作窃取线程池:
ForkJoinPool:
parallelism : 并行等级
ForkJoinPool.defaultForkJoinWorkerThreadFactory : 默认ForkJoin线程工厂
UncaughtExceptionHandler handler : 未捕捉异常处理
asyncMode : true : FIFO_QUEUE , false : LIFO_QUEUE
*/
public static ExecutorService newWorkStealingPool(int parallelism) {
return new ForkJoinPool
(parallelism,
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
/**
重载方法: 如果 parallelism 参数未传, 使用 当前机器的处理器数量
*/
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool
(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
应用创建和管理线程
Executor创建和管理线程的优点
Executor创建和管理线程的缺点
ForkJoinPool的使用场景
ForkJoinPool 不是为了替代 ExecutorService,而是它的补充,在某些应用场景下性能比 ExecutorService 更好
ForkJoinPool 最适合的是计算密集型的任务,如果存在 I/O,线程间同步,sleep() 等会造成线程长时间阻塞的情况时,最好配合使用 ManagedBlocker
问题:计算1至10000000的正整数之和
for Loop 方式
public interface Calculator {
/**
* 把传进来的所有numbers 做求和处理
*
* @param numbers
* @return 总和
*/
long sumUp(long[] numbers);
}
public class ForLoopCalculator implements Calculator {
@Override
public long sumUp(long[] numbers) {
long total = 0;
for (long i : numbers) {
total += i;
}
return total;
}
}
//写一个main方法进行测试:
public static void main(String[] args) {
long[] numbers = LongStream.rangeClosed(1, 10000000).toArray();
Instant start = Instant.now();
Calculator calculator = new ForLoopCalculator();
long result = calculator.sumUp(numbers);
Instant end = Instant.now();
System.out.println("耗时:" + Duration.between(start, end).toMillis() + "ms");
System.out.println("结果为:" + result);
}
/**
输出:
耗时:10ms
结果为:50000005000000
*/
ExecutorService多线程方式实现
在 Java 1.5 引入 ExecutorService 之后,基本上已经不推荐直接创建 Thread 对象,而是统一使用 ExecutorService。毕竟从接口的易用程度上来说 ExecutorService 就远胜于原始的 Thread,更不用提 java.util.concurrent 提供的数种线程池,Future 类,Lock 类等各种便利工具。
由于上面是面向接口的设计,因此我们只需要加一个使用 ExecutorService 的实现类:
public class ExecutorServiceCalculator implements Calculator {
private int parallism;
private ExecutorService pool;
public ExecutorServiceCalculator() {
parallism = Runtime.getRuntime().availableProcessors(); // CPU的核心数 默认就用cpu核心数了
pool = Executors.newFixedThreadPool(parallism);
}
//处理计算任务的线程
private static class SumTask implements Callable<Long> {
private long[] numbers;
private int from;
private int to;
public SumTask(long[] numbers, int from, int to) {
this.numbers = numbers;
this.from = from;
this.to = to;
}
@Override
public Long call() {
long total = 0;
for (int i = from; i <= to; i++) {
total += numbers[i];
}
return total;
}
}
@Override
public long sumUp(long[] numbers) {
List<Future<Long>> results = new ArrayList<>();
// 把任务分解为 n 份,交给 n 个线程处理 4核心 就等分成4份呗
// 然后把每一份都扔个一个SumTask线程 进行处理
int part = numbers.length / parallism;
for (int i = 0; i < parallism; i++) {
int from = i * part; //开始位置
int to = (i == parallism - 1) ? numbers.length - 1 : (i + 1) * part - 1; //结束位置
//扔给线程池计算
results.add(pool.submit(new SumTask(numbers, from, to)));
}
// 把每个线程的结果相加,得到最终结果 get()方法 是阻塞的
// 优化方案:可以采用 CompletableFuture 来优化 JDK1.8的新特性
long total = 0L;
for (Future<Long> f : results) {
try {
total += f.get();
} catch (Exception ignore) {
}
}
return total;
}
}
// main方法改为:
public static void main(String[] args) {
long[] numbers = LongStream.rangeClosed(1, 10000000).toArray();
Instant start = Instant.now();
Calculator calculator = new ExecutorServiceCalculator();
long result = calculator.sumUp(numbers);
Instant end = Instant.now();
System.out.println("耗时:" + Duration.between(start, end).toMillis() + "ms");
System.out.println("结果为:" + result); // 打印结果500500
}
/**
输出:
耗时:30ms
结果为:50000005000000
*/
采用ForkJoinPool(Fork/Join)
前面花了点时间讲解了 ForkJoinPool 之前的实现方法,主要为了在代码的编写难度上进行一下对比。现在就列出本篇文章的重点——ForkJoinPool 的实现方法。
public class ForkJoinCalculator implements Calculator {
private ForkJoinPool pool;
//执行任务RecursiveTask:有返回值 RecursiveAction:无返回值
private static class SumTask extends RecursiveTask<Long> {
private long[] numbers;
private int from;
private int to;
public SumTask(long[] numbers, int from, int to) {
this.numbers = numbers;
this.from = from;
this.to = to;
}
//此方法为ForkJoin的核心方法:对任务进行拆分 拆分的好坏决定了效率的高低
@Override
protected Long compute() {
// 当需要计算的数字个数小于6时,直接采用for loop方式计算结果
if (to - from < 6) {
long total = 0;
for (int i = from; i <= to; i++) {
total += numbers[i];
}
return total;
} else { // 否则,把任务一分为二,递归拆分(注意此处有递归)到底拆分成多少分 需要根据具体情况而定
int middle = (from + to) / 2;
SumTask taskLeft = new SumTask(numbers, from, middle);
SumTask taskRight = new SumTask(numbers, middle + 1, to);
taskLeft.fork();
taskRight.fork();
return taskLeft.join() + taskRight.join();
}
}
}
public ForkJoinCalculator() {
// 也可以使用公用的线程池 ForkJoinPool.commonPool():
// pool = ForkJoinPool.commonPool()
pool = new ForkJoinPool();
}
@Override
public long sumUp(long[] numbers) {
Long result = pool.invoke(new SumTask(numbers, 0, numbers.length - 1));
pool.shutdown();
return result;
}
}
/**
输出:
耗时:390ms
结果为:50000005000000
*/
/**
可以看出,使用了 ForkJoinPool 的实现逻辑全部集中在了 compute() 这个函数里,仅用了14行就实现了完整的计算过程。特别是,在这段代码里没有显式地“把任务分配给线程”,只是分解了任务,而把具体的任务到线程的映射交给了 ForkJoinPool 来完成。
*/
// 方案四:采用并行流(JDK8以后的推荐做法)
public static void main(String[] args) {
Instant start = Instant.now();
long result = LongStream.rangeClosed(0, 10000000L).parallel().reduce(0, Long::sum);
Instant end = Instant.now();
System.out.println("耗时:" + Duration.between(start, end).toMillis() + "ms");
System.out.println("结果为:" + result); // 打印结果500500
}
/**
输出:
耗时:130ms
结果为:50000005000000
*/
并行流底层还是Fork/Join框架,只是任务拆分优化得很好。
耗时效率方面解释:Fork/Join 并行流等当计算的数字非常大的时候,优势才能体现出来。也就是说,如果你的计算比较小,或者不是CPU密集型的任务,不太建议使用并行处理
原理
**我一直以为,要理解一样东西的原理,最好就是自己尝试着去实现一遍。**根据上面的示例代码,可以看出 fork() 和 join() 是 Fork/Join Framework “魔法”的关键。我们可以根据函数名假设一下 fork() 和 join() 的作用:
fork():开启一个新线程(或是重用线程池内的空闲线程),将任务交给该线程处理。
join():等待该任务的处理线程处理完毕,获得返回值。
疑问:当任务分解得越来越细时,所需要的线程数就会越来越多,而且大部分线程处于等待状态?
但是如果我们在上面的示例代码加入以下代码
System.out.println(pool.getPoolSize());
1
这会显示当前线程池的大小,在我的机器上这个值是4,也就是说只有4个工作线程。甚至即使我们在初始化 pool 时指定所使用的线程数为1时,上述程序也没有任何问题——除了变成了一个串行程序以外。
这个矛盾可以导出,我们的假设是错误的,并不是每个 fork() 都会促成一个新线程被创建,而每个 join() 也不是一定会造成线程被阻塞。Fork/Join Framework 的实现算法并不是那么“显然”,而是一个更加复杂的算法——这个算法的名字就叫做work stealing 算法。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gPfuzntW-1618135569572)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210408221850214.png)]
ForkJoinPool 的每个工作线程都维护着一个工作队列(WorkQueue),这是一个双端队列(Deque),里面存放的对象是任务(ForkJoinTask)。
每个工作线程在运行中产生新的任务(通常是因为调用了 fork())时,会放入工作队列的队尾,并且工作线程在处理自己的工作队列时,使用的是 LIFO 方式,也就是说每次从队尾取出任务来执行。
每个工作线程在处理自己的工作队列同时,会尝试窃取一个任务(或是来自于刚刚提交到 pool 的任务,或是来自于其他工作线程的工作队列),窃取的任务位于其他线程的工作队列的队首,也就是说工作线程在窃取其他工作线程的任务时,使用的是 FIFO 方式。
在遇到 join() 时,如果需要 join 的任务尚未完成,则会先处理其他任务,并等待其完成。
在既没有自己的任务,也没有可以窃取的任务时,进入休眠。
submit() 和 fork() 其实没有本质区别,只是提交对象变成了 submitting queue 而已(还有一些同步,初始化的操作)。submitting queue 和其他 work queue 一样,是工作线程”窃取“的对象,因此当其中的任务被一个工作线程成功窃取时,就意味着提交的任务真正开始进入执行阶段。
ForkJoinPool的commonPool相关参数配置
commonPool是ForkJoinPool内置的一个线程池对象,JDK8里有些都是使用它的。他怎么来的呢?具体源码为ForkJoinPool的静态方法:makeCommonPool
private static ForkJoinPool makeCommonPool() {
int parallelism = -1;
ForkJoinWorkerThreadFactory factory = null;
UncaughtExceptionHandler handler = null;
try { // ignore exceptions in accessing/parsing properties
String pp = System.getProperty
("java.util.concurrent.ForkJoinPool.common.parallelism");
String fp = System.getProperty
("java.util.concurrent.ForkJoinPool.common.threadFactory");
String hp = System.getProperty
("java.util.concurrent.ForkJoinPool.common.exceptionHandler");
if (pp != null)
parallelism = Integer.parseInt(pp);
if (fp != null)
factory = ((ForkJoinWorkerThreadFactory)ClassLoader.
getSystemClassLoader().loadClass(fp).newInstance());
if (hp != null)
handler = ((UncaughtExceptionHandler)ClassLoader.
getSystemClassLoader().loadClass(hp).newInstance());
} catch (Exception ignore) {
}
if (factory == null) {
if (System.getSecurityManager() == null)
factory = defaultForkJoinWorkerThreadFactory;
else // use security-managed default
factory = new InnocuousForkJoinWorkerThreadFactory();
}
if (parallelism < 0 && // default 1 less than #cores
(parallelism = Runtime.getRuntime().availableProcessors() - 1) <= 0)
parallelism = 1;
if (parallelism > MAX_CAP)
parallelism = MAX_CAP;
return new ForkJoinPool(parallelism, factory, handler, LIFO_QUEUE,
"ForkJoinPool.commonPool-worker-");
}
参数解释 以及自定义commonPool的参数
通过代码指定,必须得在commonPool初始化之前(parallel的stream被调用之前,一般可在系统启动后设置)注入进去,否则无法生效。
通过启动参数指定无此限制,较为安全
parallelism(即配置线程池个数)
可以通过java.util.concurrent.ForkJoinPool.common.parallelism进行配置,最大值不能超过MAX_CAP,即32767.
static final int MAX_CAP = 0x7fff; //32767
1
如果没有指定,则默认为Runtime.getRuntime().availableProcessors() - 1.
自定义:代码指定(必须得在commonPool初始化之前注入进去,否则无法生效)
System.setProperty(“java.util.concurrent.ForkJoinPool.common.parallelism”, “8”);
// 或者启动参数指定
-Djava.util.concurrent.ForkJoinPool.common.parallelism=8
threadFactory:默认为defaultForkJoinWorkerThreadFactory,没有securityManager的话。
exceptionHandler:如果没有设置,默认为null
WorkQueue:控制是FIFO还是LIFO
ForkJoinPool 的每个工作线程都维护着一个工作队列(WorkQueue),这是一个双端队列(Deque),里面存放的对象是任务(ForkJoinTask)。
每个工作线程在运行中产生新的任务(通常是因为调用了 fork())时,会放入工作队列的队尾,并且工作线程在处理自己的工作队列时,使用的是 LIFO 方式,也就是说每次从队尾取出任务来执行。
每个工作线程在处理自己的工作队列同时,会尝试窃取一个任务(或是来自于刚刚提交到 pool的任务,或是来自于其他工作线程的工作队列),窃取的任务位于其他线程的工作队列的队首,也就是说工作线程在窃取其他工作线程的任务时,使用的是 FIFO 方式。
queue capacity:队列容量
继续介绍
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t6itEOSF-1618135569572)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210408222442233.png)]
创建了ForkJoinPool实例之后,就可以调用ForkJoinPool的submit(ForkJoinTask task) 或invoke(ForkJoinTask task)方法来执行指定任务了。
其中ForkJoinTask代表一个可以并行、合并的任务。ForkJoinTask是一个抽象类,它还有两个抽象子类:RecusiveAction和RecusiveTask。
其中RecusiveTask代表有返回值的任务,
而RecusiveAction代表没有返回值的任务。
它同ThreadPoolExecutor一样,也实现了Executor和ExecutorService接口。它使用了一个无限队列来保存需要执行的任务,而线程的数量则是通过构造函数传入,如果没有向构造函数中传入希望的线程数量,那么当前计算机可用的CPU数量会被设置为线程数量作为默认值。
ForkJoinPool主要用来使用分治法(Divide-and-Conquer Algorithm)来解决问题。典型的应用比如快速排序算法。
这里的要点在于,ForkJoinPool需要使用相对少的线程来处理大量的任务。
比如要对1000万个数据进行排序,那么会将这个任务分割成两个500万的排序任务和一个针对这两组500万数据的合并任务。以此类推,对于500万的数据也会做出同样的分割处理,到最后会设置一个阈值来规定当数据规模到多少时,停止这样的分割处理。比如,当元素的数量小于10时,会停止分割,转而使用插入排序对它们进行排序。
那么到最后,所有的任务加起来会有大概2000000+个。问题的关键在于,对于一个任务而言,只有当它所有的子任务完成之后,它才能够被执行。
所以当使用ThreadPoolExecutor时,使用分治法会存在问题,因为ThreadPoolExecutor中的线程无法像任务队列中再添加一个任务并且在等待该任务完成之后再继续执行。而使用ForkJoinPool时,就能够让其中的线程创建新的任务,并挂起当前的任务,此时线程就能够从队列中选择子任务执行。
使用ThreadPoolExecutor或者ForkJoinPool,会有什么性能的差异呢?
使用ForkJoinPool能够使用数量有限的线程来完成非常多的具有父子关系的任务,比如使用4个线程来完成超过200万个任务。但是,使用ThreadPoolExecutor时,是不可能完成的,因为ThreadPoolExecutor中的Thread无法选择优先执行子任务,需要完成200万个具有父子关系的任务时,也需要200万个线程,显然这是不可行的。
这就是工作窃取模式的优点
总结
- 在了解了 Fork/Join Framework 的工作原理之后,相信很多使用上的注意事项就可以从原理中找到原因。例如:为什么在 ForkJoinTask 里最好不要存在 I/O 等会阻塞线程的行为?,这个各位读者可以思考思考了。
- 还有一些延伸阅读的内容,在此仅提及一下:
ForkJoinPool 有一个 Async Mode ,效果是工作线程在处理本地任务时也使用 FIFO 顺序。这种模式下的 ForkJoinPool 更接近于是一个消息队列,而不是用来处理递归式的任务。
在需要阻塞工作线程时,可以使用 ManagedBlocker - Java 1.8 新增加的 CompletableFuture 类可以实现类似于 Javascript 的 promise-chain,内部就是使用 ForkJoinPool 来实现的
28 、java中有几种方法可以实现一个线程?
-
继承Thread类
-
实现Runnable接口
-
使用Callable和FutureTask
-
使用线程池,例如用Executor框架
-
Spring实现多线程(底层是线程池)
import java.util.Random;
import java.util.UUID;
import org.springframework.scheduling.annotation.Async;
import org.springframework.stereotype.Service;
@Service // 注解的方式把AsyncService交给Spring来管理
public class AsynTaskService {
// 这里可以注入spring中管理的其他bean,这也是使用spring来实现多线程的一大优势
@Async // 这里进行标注为异步任务,在执行此方法的时候,会单独开启线程来执行
public void f1() {
System.out.println("f1 : " + Thread.currentThread().getName() + " " + UUID.randomUUID().toString());
try {
Thread.sleep(new Random().nextInt(100));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@Async
public void f2() {
System.out.println("f2 : " + Thread.currentThread().getName() + " " + UUID.randomUUID().toString());
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
- 定时器Timer (底层封装了一个TimerThread对象)
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println(Thread.currentThread().getName() + "-->" + i);
}
}
}, 100, 100);
29 、如何停止一个正在运行的线程?
public class BestPractice extends Thread {
private volatile boolean finished = false; // ① volatile条件变量
public void stopMe() {
finished = true; // ② 发出停止信号
interrupt();
}
@Override
public void run() {
while (!finished) { // ③ 检测条件变量
try {
// do dirty work // ④业务代码
} catch (InterruptedException e) {
if (finished) {
return;
}
continue;
}
}
}
}
30 、notify()和notifyAll()有什么区别?
Java提供了两个方法notify和notifyAll来唤醒在某些条件下等待的线程,你可以使用它们中的任何一个,但是Java中的notify和notifyAll之间存在细微差别,这使得它成为Java中流行的多线程面试问题之一。当你调用notify时,只有一个等待线程会被唤醒而且它不能保证哪个线程会被唤醒,这取决于线程调度器。虽然如果你调用notifyAll方法,那么等待该锁的所有线程都会被唤醒,但是在执行剩余的代码之前,所有被唤醒的线程都将争夺锁定,这就是为什么在循环上调用wait,因为如果多个线程被唤醒,那么线程是将获得锁定将首先执行,它可能会重置等待条件,这将迫使后续线程等待。因此,notify和notifyAll之间的关键区别在于notify()只会唤醒一个线程,而notifyAll方法将唤醒所有线程。
如果所有线程都在等待相同的条件,并且一次只有一个线程可以从条件变为true,则可以使用notify over notifyAll。
在这种情况下,notify是优于notifyAll 因为唤醒所有这些因为我们知道只有一个线程会受益而所有其他线程将再次等待,所以调用notifyAll方法只是浪费CPU。
虽然这看起来很合理,但仍有一个警告,即无意中的接收者吞下了关键通知。通过使用notifyAll,我们确保所有收件人都会收到通知
wait + notify + flag 实现线程间通信
import java.util.concurrent.atomic.AtomicInteger;
public class CommunicatingThreads {
static boolean isOne = true;
public static void main(String[] args) {
Object lock = new Object();
AtomicInteger atoi = new AtomicInteger(1);
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
while(atoi.get() <=10){
try{
synchronized (lock){
if(!isOne){
lock.wait();
}else{
System.out.println(Thread.currentThread().getName()+"----"+atoi.getAndIncrement());
isOne = false;
lock.notify();
}
}
}catch(Exception e){
e.printStackTrace();
}
}
}
},"t1");
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
while(atoi.get() <=10){
try{
synchronized (lock){
if(isOne){
lock.wait();
}else{
System.out.println(Thread.currentThread().getName()+"----"+atoi.getAndIncrement());
isOne = true;
lock.notify();
}
}
}catch(Exception e){
e.printStackTrace();
}
}
}
},"t2");
t1.start();
t2.start();
}
lock + condition + flag 实现线程间通信
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class ConditionTest {
public static void main(String[] args) {
Counter counter = new Counter();
new Thread(()->{
for (int i = 0; i < 100; i++) {
counter.count1();
}
},"t1").start();
new Thread(()->{
for (int i = 0; i < 100; i++) {
counter.count2();
}
},"t2").start();
}
static class Counter{
private Lock lock = new ReentrantLock();
private Condition condition1 = lock.newCondition();
private Condition condition2 = lock.newCondition();
private AtomicInteger atomi = new AtomicInteger(1);
private volatile boolean isOne = true;
public void count1(){
lock.lock();
try{
while ( atomi.get() <= 10 ){
if(!isOne){
condition1.await();
}else{
System.out.println(Thread.currentThread().getName()+"---"+atomi.getAndIncrement());
condition2.signal();
isOne = false;
}
}
}catch(Exception e){
e.printStackTrace();
}finally{
lock.unlock();
}
}
public void count2(){
lock.lock();
try{
while ( atomi.get() <= 10 ){
if(isOne){
condition2.await();
}else{
System.out.println(Thread.currentThread().getName()+"---"+atomi.getAndIncrement());
condition1.signal();
isOne = true;
}
}
}catch(Exception e){
e.printStackTrace();
}finally{
lock.unlock();
}
}
}
31 、什么是Daemon线程?它有什么意义?
什么是守护线程 Daemon ?
守护线程(即daemon thread),是个服务线程,准确地来说就是服务其他的线程.
如何创建守护线程?
Thread.setDaemon(true);
常见的守护线程有哪些?
gc 是守护线程
守护线程有什么意义?
32 、java如何实现多线程之间的通讯和协作?
-
wait + notify + flag
-
lock + condition + flag
-
Semaphore
-
CyclicBarrier
-
CountDownLatch
Semaphore
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
public class SemaphoreTestN {
public static void main(String[] args) throws InterruptedException {
ExecutorService executorService = Executors.newCachedThreadPool();
Semaphore semaphore = new Semaphore(3);
CountDownLatch countDownLatch = new CountDownLatch(10);
for (int i = 1; i <= 10 ; i++) {
final int count = i;
executorService.submit(new Runnable() {
@Override
public void run() {
try{
semaphore.acquire(1);
System.out.println("开始服务:"+count);
Thread.sleep(1000);
semaphore.release(1);
countDownLatch.countDown();
}catch(Exception e){
e.printStackTrace();
}
}
});
}
countDownLatch.await();
executorService.shutdown();
}
}
33 、什么是可重入锁(ReentrantLock)?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-44l2AOtC-1618135569572)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210410200621051.png)]
34 、当一个线程进入某个对象的一个synchronized的实例方法后,其它线程是否可进入此对象的其它方法?
可以
35 、乐观锁和悲观锁的理解及如何实现,有哪些实现方式?
什么是乐观锁?使用场景是啥
总是认为临界值不会被其他线程修改, 使用 CAS 算法 , 多用于读比较多的场景
CAS怎么实现线程安全?
线程在读取数据时不进行加锁,在准备写回数据时,先去查询原值,操作的时候比较原值是否修改,若未被其他线程修改则写回,若已被修改,则重新执行读取流程。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jRVr3AOf-1618135569573)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210410202805235.png)]c
有什么问题 ?
要是结果一直就一直循环了,CPU开销是个问题,还有ABA问题和只能保证一个共享变量原子操作的问题
CAS操作单个共享变量的时候可以保证原子的操作,多个变量就不行了,JDK 5之后 AtomicReference可以用来保证对象之间的原子性,就可以把多个对象放入CAS中操作。
乐观锁在项目开发中的实战有么?
有的就比如我们在很多订单表,流水表,为了防止并发问题,就会加入CAS的校验过程,保证了线程的安全,但是看场景使用,并不是适用所有场景,他的优点缺点都很明显
那开发过程中ABA你们是怎么保证的?
加标志位,例如搞个自增的字段,操作一次就自增加一,或者搞个时间戳,比较时间戳的值。
举个栗子:现在我们去要求操作数据库,根据CAS的原则我们本来只需要查询原本的值就好了,现在我们一同查出他的标志位版本字段version
之前不能防止ABA的正常修改:
什么是悲观锁?
总认为临界值一定会被其他线程修改, 用于多写场景,
synchronized
synchronized,代表这个方法加锁,相当于不管哪一个线程(例如线程A),运行到这个方法时,都要检查有没有其它线程B(或者C、 D等)正在用这个方法(或者该类的其他同步方法),有的话要等正在使用synchronized方法的线程B(或者C 、D)运行完这个方法后再运行此线程A,没有的话,锁定调用者,然后直接运行。
分别从他对对象、方法和代码块三方面加锁,去介绍他怎么保证线程安全的:
synchronized 对对象进行加锁,在 JVM 中,对象在内存中分为三块区域:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。
对象头:我们以Hotspot虚拟机为例,Hotspot的对象头主要包括两部分数据:Mark Word(标记字段)、Klass Pointer(类型指针)。
Mark Word:默认存储对象的HashCode,分代年龄和锁标志位信息。它会根据对象的状态复用自己的存储空间,也就是说在运行期间Mark Word里存储的数据会随着锁标志位的变化而变化。
Klass Point:对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。
你可以看到在对象头中保存了锁标志位和指向 monitor 对象的起始地址,如下图所示,右侧就是对象对应的 Monitor 对象。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1PiphCxl-1618135569573)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210410204715983.png)]
当 Monitor 被某个线程持有后,就会处于锁定状态,如图中的 Owner 部分,会指向持有 Monitor 对象的线程。
另外 Monitor 中还有两个队列分别是EntryList和WaitList,主要是用来存放进入及等待获取锁的线程。
如果线程进入,则得到当前对象锁,那么别的线程在该类所有对象上的任何操作都不能进行。
在对象级使用锁通常是一种比较粗糙的方法,为什么要将整个对象都上锁,而不允许其他线程短暂地使用对象中其他同步方法来访问共享资源?
如果一个对象拥有多个资源,就不需要只为了让一个线程使用其中一部分资源,就将所有线程都锁在外面。
由于每个对象都有锁,可以如下所示使用虚拟对象来上锁:
synchronized 应用在方法上时,在字节码中是通过方法的 ACC_SYNCHRONIZED 标志来实现的。
我反编译了一小段代码,我们可以看一下我加锁了一个方法,在字节码长啥样,flags字段瞩目
synchronized 应用在同步块上时,在字节码中是通过 monitorenter 和 monitorexit 实现的。
每个对象都会与一个monitor相关联,当某个monitor被拥有之后就会被锁住,当线程执行到monitorenter指令时,就会去尝试获得对应的monitor。
步骤如下:
每个monitor维护着一个记录着拥有次数的计数器。未被拥有的monitor的该计数器为0,当一个线程获得monitor(执行monitorenter)后,该计数器自增变为 1 。
当同一个线程再次获得该monitor的时候,计数器再次自增;
当不同线程想要获得该monitor的时候,就会被阻塞。
当同一个线程释放 monitor(执行monitorexit指令)的时候,计数器再自减。
当计数器为0的时候,monitor将被释放,其他线程便可以获得monitor。
同样看一下反编译后的一段锁定代码块的结果:
public void syncTask();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=3, locals=3, args_size=1
0: aload_0
1: dup
2: astore_1
3: monitorenter //注意此处,进入同步方法
4: aload_0
5: dup
6: getfield #2 // Field i:I
9: iconst_1
10: iadd
11: putfield #2 // Field i:I
14: aload_1
15: monitorexit //注意此处,退出同步方法
16: goto 24
19: astore_2
20: aload_1
21: monitorexit //注意此处,退出同步方法
22: aload_2
23: athrow
24: return
Exception table:
//省略其他字节码.......
小结:
同步方法和同步代码块底层都是通过monitor来实现同步的。
两者的区别:同步方式是通过方法中的access_flags中设置ACC_SYNCHRONIZED标志来实现,同步代码块是通过monitorenter和monitorexit来实现。
我们知道了每个对象都与一个monitor相关联,而monitor可以被线程拥有或释放。
小伙子我只能说,你确实有点东西,以前我们一直锁synchronized是重量级的锁,为啥现在都不提了?
在多线程并发编程中 synchronized 一直是元老级角色,很多人都会称呼它为重量级锁。
但是,随着 Java SE 1.6 对 synchronized 进行了各种优化之后,有些情况下它就并不那么重,Java SE 1.6 中为了减少获得锁和释放锁带来的性能消耗而引入的偏向锁和轻量级锁。
针对 synchronized 获取锁的方式,JVM 使用了锁升级的优化方式,就是先使用偏向锁优先同一线程然后再次获取锁,如果失败,就升级为 CAS 轻量级锁,如果失败就会短暂自旋,防止线程被系统挂起。最后如果以上都失败就升级为重量级锁。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OtwDdPls-1618135569573)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210410205707645.png)]
还有其他同步手段么?
ReentrantLock但是在介绍这玩意之前,我觉得我有必要先介绍AQS(AbstractQueuedSynchronizer)。
AQS:也就是队列同步器,这是实现 ReentrantLock 的基础。
AQS 有一个 state 标记位,值为1 时表示有线程占用,其他线程需要进入到同步队列等待,同步队列是一个双向链表。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HkNygOMj-1618135569574)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210410205913098.png)]
当获得锁的线程需要等待某个条件时,会进入 condition 的等待队列,等待队列可以有多个。
当 condition 条件满足时,线程会从等待队列重新进入同步队列进行获取锁的竞争。
ReentrantLock 就是基于 AQS 实现的,如下图所示,ReentrantLock 内部有公平锁和非公平锁两种实现,差别就在于新来的线程是否比已经在同步队列中的等待线程更早获得锁。
和 ReentrantLock 实现方式类似,Semaphore 也是基于 AQS 的,差别在于 ReentrantLock 是独占锁,Semaphore 是共享锁。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BtNWsxAG-1618135569574)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210410210125041.png)]
从图中可以看到,ReentrantLock里面有一个内部类Sync,Sync继承AQS(AbstractQueuedSynchronizer),添加锁和释放锁的大部分操作实际上都是在Sync中实现的。
它有公平锁FairSync和非公平锁NonfairSync两个子类。
ReentrantLock默认使用非公平锁,也可以通过构造器来显示的指定使用公平锁。
36 、SynchronizedMap和ConcurrentHashMap有什么区别?
Hashmap中的链表大小超过八个时会自动转化为红黑树,当删除小于六时重新变为链表,为啥呢?
根据泊松分布,在负载因子默认为0.75的时候,单个hash槽内元素个数为8的概率小于百万分之一,所以将7作为一个分水岭,等于7的时候不转换,大于等于8的时候才进行转换,小于等于6的时候就化为链表。
HashMap在多线程环境下存在线程安全问题,那你一般都是怎么处理这种情况的?
- 使用Collections.synchronizedMap(Map)创建线程安全的map集合;
- Hashtable
- ConcurrentHashMap
不过出于线程并发度的原因,我都会舍弃前两者使用最后的ConcurrentHashMap,他的性能和效率明显高于前两者。
Collections.synchronizedMap是怎么实现线程安全的你有了解过么
在SynchronizedMap内部维护了一个普通对象Map,还有排斥锁mutex,如图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fZuikdGg-1618135569575)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210411074606584.png)]
我们在调用这个方法的时候就需要传入一个Map,可以看到有两个构造器,如果你传入了mutex参数,则将对象排斥锁赋值为传入的对象。
如果没有,则将对象排斥锁赋值为this,即调用synchronizedMap的对象,就是上面的Map。
创建出synchronizedMap之后,再操作map的时候,就会对方法上锁,如图全是
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FJq7023n-1618135569575)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210411074721219.png)]
能跟我聊一下Hashtable么?
跟HashMap相比Hashtable是线程安全的,适合在多线程的情况下使用,但是效率可不太乐观。
你能说说他效率低的原因么?
我看过他的源码,他在对数据操作的时候都会上锁,所以效率比较低下
除了这个你还能说出一些Hashtable 跟HashMap不一样点么?
Hashtable 是不允许键或值为 null 的,HashMap 的键值则都可以为 null。
为啥 Hashtable 是不允许 KEY 和 VALUE 为 null, 而 HashMap 则可以呢?
因为Hashtable在我们put 空值的时候会直接抛空指针异常,但是HashMap却做了特殊处理
但是你还是没说为啥Hashtable 是不允许键或值为 null 的,HashMap 的键值则都可以为 null
这是因为Hashtable使用的是安全失败机制(fail-safe),这种机制会使你此次读到的数据不一定是最新的数据。
如果你使用null值,就会使得其无法判断对应的key是不存在还是为空,因为你无法再调用一次contain(key)来对key是否存在进行判断,ConcurrentHashMap同理。
继续说不同点吧
- 实现方式不同:Hashtable 继承了 Dictionary类,而 HashMap 继承的是 AbstractMap 类。
Dictionary 是 JDK 1.0 添加的,貌似没人用过这个,我也没用过。
-
初始化容量不同:HashMap 的初始容量为:16,Hashtable 初始容量为:11,两者的负载因子默认都是:0.75。
-
扩容机制不同:当现有容量大于总容量 * 负载因子时,HashMap 扩容规则为当前容量翻倍,Hashtable 扩容规则为当前容量翻倍 + 1。
-
迭代器不同:HashMap 中的 Iterator 迭代器是 fail-fast 的,而 Hashtable 的 Enumerator 不是 fail-fast 的。
所以,当其他线程改变了HashMap 的结构,如:增加、删除元素,将会抛出
ConcurrentModificationException 异常,而 Hashtable 则不会。
fail-fast是啥?
**快速失败(fail—fast)**是java集合中的一种机制, 在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加、删除、修改),则会抛出Concurrent Modification Exception。
他的原理是啥?
迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个 modCount 变量。
集合在被遍历期间如果内容发生变化,就会改变modCount的值。
每当迭代器使用hashNext()/next()遍历下一个元素之前,都会检测modCount变量是否为expectedmodCount值,是的话就返回遍历;否则抛出异常,终止遍历。
Tip:这里异常的抛出条件是检测到 modCount!=expectedmodCount 这个条件。如果集合发生变化时修改modCount值刚好又设置为了expectedmodCount值,则异常不会抛出。
因此,不能依赖于这个异常是否抛出而进行并发操作的编程,这个异常只建议用于检测并发修改的bug。
说说他的场景?
java.util包下的集合类都是快速失败的,不能在多线程下发生并发修改(迭代过程中被修改)算是一种安全机制吧。
Tip:**安全失败(fail—safe)**大家也可以了解下,java.util.concurrent包下的容器都是安全失败,可以在多线程下并发使用,并发修改。
ConcurrentHashMap连环炮能不能顶得住了。都说了他的并发度不够,性能很低,这个时候你都怎么处理的?
他来了他来了,他终于还是来了,等了这么久,就是等你问我这个点,你还是掉入了我的陷阱啊,我早有准备,在HashMap埋下他线程不安全的种子,就是为了在ConcurrentHashMap开花结果!
这样的场景,我们在开发过程中都是使用ConcurrentHashMap,他的并发的相比前两者好很多。
那你跟我说说他的数据结构吧,以及为啥他并发度这么高?
ConcurrentHashMap 底层是基于 数组 + 链表 组成的,不过在 jdk1.7 和 1.8 中具体实现稍有不同。
我先说一下他在1.7中的数据结构吧:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nB1WDy1O-1618135569575)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210411082236170.png)]
如图所示,是由 Segment 数组、HashEntry 组成,和 HashMap 一样,仍然是数组加链表。
Segment 是 ConcurrentHashMap 的一个内部类,主要的组成如下:
static final class Segment<K,V> extends ReentrantLock implements Serializable {
private static final long serialVersionUID = 2249069246763182397L;
// 和 HashMap 中的 HashEntry 作用一样,真正存放数据的桶
transient volatile HashEntry<K,V>[] table;
transient int count;
// 记得快速失败(fail—fast)么?
transient int modCount;
// 大小
transient int threshold;
// 负载因子
final float loadFactor;
}
HashEntry跟HashMap差不多的,但是不同点是,他使用volatile去修饰了他的数据Value还有下一个节点next。
volatile的特性是啥?
- 保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。(实现可见性)
- 禁止进行指令重排序。(实现有序性)
- volatile 只能保证对单次读/写的原子性。i++ 这种操作不能保证原子性。
那你能说说他并发度高的原因么?
原理上来说,ConcurrentHashMap 采用了分段锁技术,其中 Segment 继承于 ReentrantLock。
不会像 HashTable 那样不管是 put 还是 get 操作都需要做同步处理,理论上 ConcurrentHashMap 支持 CurrencyLevel (Segment 数组数量)的线程并发。
每当一个线程占用锁访问一个 Segment 时,不会影响到其他的 Segment。
就是说如果容量大小是16他的并发度就是16,可以同时允许16个线程操作16个Segment而且还是线程安全的。
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();//这就是为啥他不可以put null值的原因
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject
(segments, (j << SSHIFT) + SBASE)) == null)
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
他先定位到Segment,然后再进行put操作。
我们看看他的put源代码,你就知道他是怎么做到线程安全的了,关键句子我注释了。
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 将当前 Segment 中的 table 通过 key 的 hashcode 定位到 HashEntry
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
// 遍历该 HashEntry,如果不为空则判断传入的 key 和当前遍历的 key 是否相等,相等则覆盖旧的 value。
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
// 不为空则需要新建一个 HashEntry 并加入到 Segment 中,同时会先判断是否需要扩容。
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
//释放锁
unlock();
}
return oldValue;
}
首先第一步的时候会尝试获取锁,如果获取失败肯定就有其他线程存在竞争,则利用 scanAndLockForPut() 自旋获取锁。
- 尝试自旋获取锁。
- 如果重试的次数达到了
MAX_SCAN_RETRIES则改为阻塞锁获取,保证能获取成功。
那他get的逻辑呢?
get 逻辑比较简单,只需要将 Key 通过 Hash 之后定位到具体的 Segment ,再通过一次 Hash 定位到具体的元素上。
由于 HashEntry 中的 value 属性是用 volatile 关键词修饰的,保证了内存可见性,所以每次获取时都是最新值。
ConcurrentHashMap 的 get 方法是非常高效的,因为整个过程都不需要加锁。
你有没有发现1.7虽然可以支持每个Segment并发访问,但是还是存在一些问题?
是的,因为基本上还是数组加链表的方式,我们去查询的时候,还得遍历链表,会导致效率很低,这个跟jdk1.7的HashMap是存在的一样问题,所以他在jdk1.8完全优化了。
那你再跟我聊聊jdk1.8他的数据结构是怎么样子的呢?
其中抛弃了原有的 Segment 分段锁,而采用了 CAS + synchronized 来保证并发安全性。
跟HashMap很像,也把之前的HashEntry改成了Node,但是作用不变,把值和next采用了volatile去修饰,保证了可见性,并且也引入了红黑树,在链表大于一定值的时候会转换(默认是8)。
同样的,你能跟我聊一下他值的存取操作么?以及是怎么保证线程安全的?
ConcurrentHashMap在进行put操作的还是比较复杂的,大致可以分为以下步骤:
根据 key 计算出 hashcode 。
判断是否需要进行初始化。
即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
如果当前位置的 hashcode == MOVED == -1,则需要进行扩容。
如果都不满足,则利用 synchronized 锁写入数据。
如果数量大于 TREEIFY_THRESHOLD 则要转换为红黑树。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AHBTUFHh-1618135569576)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210411083334298.png)]
你在上面提到CAS是什么?自旋又是什么?
CAS 是乐观锁的一种实现方式,是一种轻量级锁,JUC 中很多工具类的实现就是基于 CAS 的。
CAS 操作的流程如下图所示,线程在读取数据时不进行加锁,在准备写回数据时,比较原值是否修改,若未被其他线程修改则写回,若已被修改,则重新执行读取流程。
这是一种乐观策略,认为并发操作并不总会发生。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rA6CF0Y6-1618135569576)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210411083511651.png)]
还是不明白?那我再说明下,乐观锁在实际开发场景中非常常见,大家还是要去理解。
就比如我现在要修改数据库的一条数据,修改之前我先拿到他原来的值,然后在SQL里面还会加个判断,原来的值和我手上拿到的他的原来的值是否一样,一样我们就可以去修改了,不一样就证明被别的线程修改了你就return错误就好了。
SQL伪代码大概如下:
-- oldValue就是我们执行前查询出来的值
update a set value = newValue where value = #{oldValue}
CAS就一定能保证数据没被别的线程修改过么?
并不是的,比如很经典的ABA问题,CAS就无法判断了。
什么是ABA?
就是说来了一个线程把值改回了B,又来了一个线程把值又改回了A,对于这个时候判断的线程,就发现他的值还是A,所以他就不知道这个值到底有没有被人改过,其实很多场景如果只追求最后结果正确,这是没关系的。
但是实际过程中还是需要记录修改过程的,比如资金修改什么的,你每次修改的都应该有记录,方便回溯。
那怎么解决ABA问题?
用版本号去保证就好了,就比如说,我在修改前去查询他原来的值的时候再带一个版本号,每次判断就连值和版本号一起判断,判断成功就给版本号加1。
-- 判断原来的值和版本号是否匹配,中间有别的线程修改,值可能相等,但是版本号100%不一样
update a set value = newValue ,vision = vision + 1 where value = #{oldValue} and vision = #{vision}
其实有很多方式,比如时间戳也可以,查询的时候把时间戳一起查出来,对的上才修改并且更新值的时候一起修改更新时间,这样也能保证,方法很多但是跟版本号都是异曲同工之妙,看场景大家想怎么设计吧。
CAS性能很高,但是我知道synchronized性能可不咋地,为啥jdk1.8升级之后反而多了synchronized?
synchronized之前一直都是重量级的锁,但是后来java官方是对他进行过升级的,他现在采用的是锁升级的方式去做的。
针对 synchronized 获取锁的方式,JVM 使用了锁升级的优化方式,就是先使用偏向锁优先同一线程然后再次获取锁,如果失败,就升级为 CAS 轻量级锁,如果失败就会短暂自旋,防止线程被系统挂起。最后如果以上都失败就升级为重量级锁。
所以是一步步升级上去的,最初也是通过很多轻量级的方式锁定的。
那我们回归正题,ConcurrentHashMap的get操作又是怎么样子的呢?
- 根据计算出来的 hashcode 寻址,如果就在桶上那么直接返回值。
- 如果是红黑树那就按照树的方式获取值。
- 就不满足那就按照链表的方式遍历获取值。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lAkpJoFj-1618135569577)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210411083930305.png)]
小结:1.8 在 1.7 的数据结构上做了大的改动,采用红黑树之后可以保证查询效率(O(logn)),甚至取消了 ReentrantLock 改为了 synchronized,这样可以看出在新版的 JDK 中对 synchronized 优化是很到位的。
总结
Hashtable
ConcurrentHashMap
HashMap基本上就是一套连环组合
是的因为提到HashMap你肯定会聊到他的线程安全性这一点,那你总不能加锁一句话就搞定了吧,java的作者们也不想,所以人家写开发了对应的替代品,那就是线程安全的Hashtable&ConcurrentHashMap。
两者都有特点,但是线程安全场景还是后者用得多一点
你们发现了面试就是一个个的坑,你说到啥面试官可能就怼到你啥
你知道不确定能不能为这场面试加分,但是不知道肯定是减分的,文中的快速失败(fail—fast)问到,那对应的安全失败(fail—safe)也是有可能知道的,我想读者很多都不知道吧
还有提到CAS乐观锁,你要知道ABA,你要知道解决方案,因为在实际的开发场景真的不要太常用了,sync的锁升级你也要知道。
我没过多描述线程安全的太多东西
常见问题
谈谈你理解的 Hashtable,讲讲其中的 get put 过程。ConcurrentHashMap同问。
1.8 做了什么优化?
线程安全怎么做的?
不安全会导致哪些问题?
如何解决?有没有线程安全的并发容器?
ConcurrentHashMap 是如何实现的?
ConcurrentHashMap并发度为啥好这么多?
1.7、1.8 实现有何不同?为什么这么做?
CAS是啥?
ABA是啥?场景有哪些,怎么解决?
synchronized底层原理是啥?
synchronized锁升级策略
快速失败(fail—fast)是啥,应用场景有哪些?安全失败(fail—safe)同问。
……
加分项
在回答Hashtable和ConcurrentHashMap相关的面试题的时候,一定要知道他们是怎么保证线程安全的,那线程不安全一般都是发生在存取的过程中的,那get、put你肯定要知道。
HashMap是必问的那种,这两个经常会作为替补问题,不过也经常问,他们本身的机制其实都比较简单,特别是ConcurrentHashMap跟HashMap是很像的,只是是否线程安全这点不同。
提到线程安全那你就要知道相关的知识点了,比如说到CAS你一定要知道ABA的问题,提到synchronized那你要知道他的原理,他锁对象,方法、代码块,在底层是怎么实现的。
synchronized你还需要知道他的锁升级机制,以及他的兄弟ReentantLock,两者一个是jvm层面的一个是jdk层面的,还是有很大的区别的。
那提到他们两个你是不是又需要知道juc这个包下面的所有的常用类,以及他们的底层原理了?
37 、CopyOnWriteArrayList可以用于什么应用场景?
Java学习者都清楚ArrayList并不是线程安全的,在读线程在读取ArrayList的时候如果有写线程在写数据的时候,基于fast-fail机制,会抛出ConcurrentModificationException异常,也就是说ArrayList并不是一个线程安全的容器,当然您可以用Vector,或者使用Collections的静态方法将ArrayList包装成一个线程安全的类,但是这些方式都是采用Java关键字synchronzied对方法进行修饰,利用独占式锁来保证线程安全的。但是,由于独占式锁在同一时刻只有一个线程能够获取到对象监视器,很显然这种方式效率并不是太高。
回到业务场景中,有很多业务往往是读多写少的,比如系统配置的信息,除了在初始进行系统配置的时候需要写入数据,其他大部分时刻其他模块之后对系统信息只需要进行读取,又比如白名单,黑名单等配置,只需要读取名单配置然后检测当前用户是否在该配置范围以内。类似的还有很多业务场景,它们都是属于读多写少的场景。如果在这种情况用到上述的方法,使用Vector,Collections转换的这些方式是不合理的,因为尽管多个读线程从同一个数据容器中读取数据,但是读线程对数据容器的数据并不会发生发生修改。很自然而然的我们会联想到ReenTrantReadWriteLock(关于读写锁可以看这篇文章),通过读写分离的思想,使得读读之间不会阻塞,无疑如果一个list能够做到被多个读线程读取的话,性能会大大提升不少。但是,如果仅仅是将list通过读写锁(ReentrantReadWriteLock)进行再一次封装的话,由于读写锁的特性,当写锁被写线程获取后,读写线程都会被阻塞。如果仅仅使用读写锁对list进行封装的话,这里仍然存在读线程在读数据的时候被阻塞的情况,如果想list的读效率更高的话,这里就是我们的突破口,如果我们保证读线程无论什么时候都不被阻塞,效率岂不是会更高?
Doug Lea大师就为我们提供CopyOnWriteArrayList容器可以保证线程安全,保证读写之间在任何时候都不会被阻塞,CopyOnWriteArrayList也被广泛应用于很多业务场景之中,CopyOnWriteArrayList值得被我们好好认识一番。
COW的设计思想
回到上面所说的,如果简单的使用读写锁的话,在写锁被获取之后,读写线程被阻塞,只有当写锁被释放后读线程才有机会获取到锁从而读到最新的数据,站在读线程的角度来看,即读线程任何时候都是获取到最新的数据,满足数据实时性。既然我们说到要进行优化,必然有trade-off,我们就可以牺牲数据实时性满足数据的最终一致性即可。而CopyOnWriteArrayList就是通过Copy-On-Write(COW),即写时复制的思想来通过延时更新的策略来实现数据的最终一致性,并且能够保证读线程间不阻塞。
COW通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。对CopyOnWrite容器进行并发的读的时候,不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,延时更新的策略是通过在写的时候针对的是不同的数据容器来实现的,放弃数据实时性达到数据的最终一致性。
CopyOnWriteArrayList的实现原理
现在我们来通过看源码的方式来理解CopyOnWriteArrayList,实际上CopyOnWriteArrayList内部维护的就是一个数组
/** The array, accessed only via getArray/setArray. */
private transient volatile Object[] array;
并且该数组引用是被volatile修饰,注意这里仅仅是修饰的是数组引用,其中另有玄机,稍后揭晓。关于volatile很重要的一条性质是它能够够保证可见性,关于volatile的详细讲解可以看这篇文章。对list来说,我们自然而然最关心的就是读写的时候,分别为get和add方法的实现。
get方法实现原理
get方法的源码为:
public E get(int index) {
return get(getArray(), index);
}
/**
* Gets the array. Non-private so as to also be accessible
* from CopyOnWriteArraySet class.
*/
final Object[] getArray() {
return array;
}
private E get(Object[] a, int index) {
return (E) a[index];
}
可以看出来get方法实现非常简单,几乎就是一个“单线程”程序,没有对多线程添加任何的线程安全控制,也没有加锁也没有CAS操作等等,原因是,所有的读线程只是会读取数据容器中的数据,并不会进行修改。
add方法实现原理
再来看下如何进行添加数据的?add方法的源码为:
public boolean add(E e) {
final ReentrantLock lock = this.lock;
//1. 使用Lock,保证写线程在同一时刻只有一个
lock.lock();
try {
//2. 获取旧数组引用
Object[] elements = getArray();
int len = elements.length;
//3. 创建新的数组,并将旧数组的数据复制到新数组中
Object[] newElements = Arrays.copyOf(elements, len + 1);
//4. 往新数组中添加新的数据
newElements[len] = e;
//5. 将旧数组引用指向新的数组
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
add方法的逻辑也比较容易理解,请看上面的注释。需要注意这么几点:
采用ReentrantLock,保证同一时刻只有一个写线程正在进行数组的复制,否则的话内存中会有多份被复制的数据;
前面说过数组引用是volatile修饰的,因此将旧的数组引用指向新的数组,根据volatile的happens-before规则,写线程对数组引用的修改对读线程是可见的。
由于在写数据的时候,是在新的数组中插入数据的,从而保证读写实在两个不同的数据容器中进行操作。
总结
我们知道COW和读写锁都是通过读写分离的思想实现的,但两者还是有些不同,可以进行比较:
COW vs 读写锁
相同点:1. 两者都是通过读写分离的思想实现;2.读线程间是互不阻塞的
不同点:对读线程而言,为了实现数据实时性,在写锁被获取后,读线程会等待或者当读锁被获取后,写线程会等待,从而解决“脏读”等问题。也就是说如果使用读写锁依然会出现读线程阻塞等待的情况。而COW则完全放开了牺牲数据实时性而保证数据最终一致性,即读线程对数据的更新是延时感知的,因此读线程不会存在等待的情况。
对这一点从文字上还是很难理解,我们来通过debug看一下,add方法核心代码为:
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
假设COW的变化如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-it8lwHid-1618135569578)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210411095333714.png)]
数组中已有数据1,2,3,现在写线程想往数组中添加数据4,我们在第5行处打上断点,让写线程暂停。读线程依然会“不受影响”的能从数组中读取数据,可是还是只能读到1,2,3。如果读线程能够立即读到新添加的数据的话就叫做能保证数据实时性。当对第5行的断点放开后,读线程才能感知到数据变化,读到完整的数据1,2,3,4,而保证数据最终一致性,尽管有可能中间间隔了好几秒才感知到。
这里还有这样一个问题: 为什么需要复制呢? 如果将array 数组设定为volitile的, 对volatile变量写happens-before读,读线程不是能够感知到volatile变量的变化。
原因是,这里volatile的修饰的仅仅只是数组引用,数组中的元素的修改是不能保证可见性的。因此COW采用的是新旧两个数据容器,通过第5行代码将数组引用指向新的数组。这也是为什么concurrentHashMap只具有弱一致性的原因。
COW的缺点
CopyOnWrite容器有很多优点,但是同时也存在两个问题,即内存占用问题和数据一致性问题。所以在开发的时候需要注意一下。
内存占用问题:因为CopyOnWrite的写时复制机制,所以在进行写操作的时候,内存里会同时驻扎两个对 象的内存,旧的对象和新写入的对象(注意:在复制的时候只是复制容器里的引用,只是在写的时候会创建新对 象添加到新容器里,而旧容器的对象还在使用,所以有两份对象内存)。如果这些对象占用的内存比较大,比 如说200M左右,那么再写入100M数据进去,内存就会占用300M,那么这个时候很有可能造成频繁的minor GC和major GC。
数据一致性问题:CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。所以如果你希望写入的的数据,马上能读到,请不要使用CopyOnWrite容器。
38 、什么叫线程安全?servlet是线程安全吗?
什么叫线程安全?
如果你的代码所在的进程中有多个线程在同时运行,而这些线程可能会同时运行这段代码。如果每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的,就是线程安全的。
或者说:一个类或者程序所提供的接口对于线程来说是原子操作或者多个线程之间的切换不会导致该接口的执行结果存在二义性,也就是说我们不用考虑同步的问题。
线程安全问题都是由全局变量及静态变量引起的。
若每个线程中对全局变量、静态变量只有读操作,而无写操作,一般来说,这个全局变量是线程安全的;若有多个线程同时执行写操作,一般都需要考虑线程同步,否则就可能影响线程安全。
servlet 是线程安全的么?
那么我们都知道servlet是多线程的,同时一个servlet实现类只会有一个实例对象,也就是它是Singleton的,所以多个线程是可能会访问同一个servlet实例对象的。
每个线程都会为数据实例对象开辟单独的引用,那么servlet会是线程安全的吗?
要判断是否是线程安全,我们需要知道线程安全问题是由什么引起的。
搜索得到答案:线程安全问题都是由全局变量及静态变量引起的。
看到这个答案,突然想起很多年前调查过的一个bug, 那时我们系统中遗留的代码中写了很多全局变量,有一次发布后,客户反馈,当有多人同时进行某个操作时,我们的数据出了问题,那时我们调查后的结果就是:多人同步操作时,有些全局变量的值不对了,之后我们专门设一个人花了很多工夫来将所有全局变量都改成了局部变量了,并且项目要求以后不允许用全局变量。原来那时侯我就已经碰到过线程不安全的情况了啊,不过处理方式或者不用全局,或者加入同步,若加入同步同时也要考虑一下对程序效率会不会产生影响。
由此可知,servlet是否线程安全是由它的实现来决定的,如果它内部的属性或方法会被多个线程改变,它就是线程不安全的,反之,就是线程安全的。
39 、volatile有什么用?能否用一句话说明下volatile的应用场景?
volatile是变量修饰符,其修饰的变量具有可见性(可见性也就是说一旦某个线程修改了该被volatile修饰的变量,它会保证修改的值会立即被更新到物理内存,当有其他线程需 要读取时,可以立即获取修改之后的值)。在Java中为了加快程序的运行效率,对一些变量的操作通常是在寄存器或是CPU缓存上进行的,之后才会同步到物理内存中,而加了volatile修饰符的变量则是直接读写物理内存。
例子请查看下面的3.1,帮助理解。
volatile可以禁止进行指令重排,什么是指令重排序?一般来说,处理器为了提高程序运行效率,可能会对输入代码进行优化,它不保证程序中各个语句的执行先后顺序同代码中的顺序一致,但是它会保证程序最终执行结果和代码顺序执行的结果是一致的。指令重排序不会影响单个线程的执行,但是会影响到线程并发执行的正确性。
但是volatile可以保证有序性。程序执行到volatile变量的读操作或者写操作时,在其前面的语句中,更改操作肯定已经完成,且结果已经对后面的操作可见,在其后面的操作肯定还没有进行。
例子请查看下面3.2,帮助理解。
synchronized则作用于一段代码或方法,使用了该修饰符既可以保证可见性(通过synchronized和Lock也能够保证可见性,synchronized和Lock能保证同一时刻只有一个线程获取锁然后执行同步代码,并且在释放锁之前会将对变量的修改刷新到物理内存中。因此可以保证可见性),也能够保证原子性(原子性表现在要么不执行,要么执行到底)。有时候必须使用synchronized,而不能使用volatile。
例子请查看下面3.3,帮助理解。
总结
(1)从而我们可以看出volatile虽然具有可见性但是并不能保证原子性。
(2)synchronized关键字是防止多个线程同时执行一段代码,那么就会影响程序执行效率,而volatile关键字在某些情况下性能要优于synchronized,但是要注意volatile关键字是无法替代synchronized关键字的,因为volatile关键字无法保证操作的原子性。
volatile的使用举例
class MyThread extends Thread {
private volatile boolean isStop = false;
public void run() {
while (!isStop) {
System.out.println("do something");
}
}
public void setStop() {
isStop = true;
}
}
线程执行run()的时候我们需要在线程中不停的做一些事情,比如while循环,那么这时候该如何停止线程呢?如果线程做的事情不是耗时的,那么只需要使用一个标志即可。如果需要退出时,调用setStop()即可。这里就使用了关键字volatile,这个关键字的目的是如果修改了isStop的值,那么在while循环中可以立即读取到修改后的值。
如果线程做的事情是耗时的,那么可以使用interrupt方法终止线程。
volatile的使用举例
//线程1:
context = loadContext(); //语句1 context初始化操作
inited = true; //语句2
//线程2:
while(!inited ){
sleep()
}
doSomethingwithconfig(context);
因为指令重排序,有可能语句2会在语句1之前执行,可能导致context还没被初始化,而线程2中就使用未初始化的context去进行操作,导致程序出错。
这里如果用volatile关键字对inited变量进行修饰,就不会出现这种问题了,因为当执行到语句2时,必定能保证context已经初始化完毕。
必须使用synchronized而不能使用volatile的场景
public class Test {
public volatile int inc = 0;
public void increase() {
inc++;
}
public static void main(String[] args) {
final Test test = new Test();
for(int i=0;i<10;i++){
new Thread(){
public void run() {
for(int j=0;j<1000;j++)
test.increase();
};
}.start();
}
while(Thread.activeCount()>1) //保证前面的线程都执行完
Thread.yield();
System.out.println(test.inc);
}
}
例子中用new了10个线程,分别去调用1000次increase()方法,每次运行结果都不一致,都是一个小于10000的数字。自增操作不是原子操作,volatile 是不能保证原子性的。回到文章一开始的例子,使用volatile修饰int型变量i,多个线程同时进行i++操作。比如有两个线程A和B对volatile修饰的i进行i++操作,i的初始值是0,A线程执行i++时刚读取了i的值0,就切换到B线程了,B线程(从内存中)读取i的值也为0,然后就切换到A线程继续执行i++操作,完成后i就为1了,接着切换到B线程,因为之前已经读取过了,所以继续执行i++操作,最后的结果i就为1了。同理可以解释为什么每次运行结果都是小于10000的数字。
但是使用synchronized对部分代码进行如下修改,就能保证同一时刻只有一个线程获取锁然后执行同步代码。运行结果必然是10000。
public int inc = 0;
public synchronized void increase() {
inc++;
}
40 、为什么代码会重排序?
CPU的速度至少比内存快100倍,为了提升效率,会打乱原来的执行顺序,会在一条指令执行过程中(比如去内存读数据,大概慢100多倍),去同时执行另一条指令,前提是两条指令没有依赖关系
41 、在java中wait和sleep方法的不同?
wait 是Object的方法, 会释放锁,进入等待池,需要调用notify方法才能进入锁池等待加锁
sleep是Thread类的方法,不会释放锁,需要调用interrupt方法,进入就绪状态,等待CPU时间片
yield是直接放弃当前cpu时间片,进入runnable状态,
42 、用Java实现阻塞队列
LinkedBlockingQueue
ArrayBlockingQueue
BlockingQueue
43 、一个线程运行时发生异常会怎样?
44 、如何在两个线程间共享数据?
import java.util.concurrent.atomic.AtomicInteger;
public class MultiThreadTest {
private AtomicInteger i = new AtomicInteger(0);
private Object lock = new Object();
private volatile boolean isAdd = true;
public static void main(String[] args) {
MultiThreadTest multiThreadTest = new MultiThreadTest();
Thread t1 = new Thread(multiThreadTest.new Inc(),"Inc");
Thread t2 = new Thread(multiThreadTest.new Dec(),"Dec");
t1.start();
t2.start();
}
class Inc implements Runnable{
@Override
public void run() {
try{
while(i.intValue()<=100){
synchronized (lock){
if(!isAdd){
lock.wait();
}else{
i.getAndIncrement();
System.out.println(Thread.currentThread().getName()+"--"+i.intValue());
Thread.sleep(1000);
lock.notify();
isAdd = false;
}
}
}
}catch(Exception e){
e.printStackTrace();
}
}
}
class Dec implements Runnable{
@Override
public void run() {
try{
while(i.intValue()<=100){
synchronized (lock){
if(isAdd){
lock.wait();
}else{
i.getAndDecrement();
System.out.println(Thread.currentThread().getName()+"--"+i.intValue());
Thread.sleep(1000);
lock.notify();
isAdd = true;
}
}
}
}catch(Exception e){
e.printStackTrace();
}
}
}
}
45 、Java中notify 和 notifyAll有什么区别?
46 、为什么wait,notify 和 notifyAll这些方法不在thread类里面?
47 、什么是ThreadLocal变量?
ThreadLocal的作用主要是做数据隔离,填充的数据只属于当前线程,变量的数据对别的线程而言是相对隔离的,在多线程环境下,如何防止自己的变量被其它线程篡改。
你能跟我说说它隔离有什么用,会用在什么场景么?
其实我第一时间想到的就是Spring实现事务隔离级别的源码
Spring采用Threadlocal的方式,来保证单个线程中的数据库操作使用的是同一个数据库连接,同时,采用这种方式可以使业务层使用事务时不需要感知并管理connection对象,通过传播级别,巧妙地管理多个事务配置之间的切换,挂起和恢复。
Spring框架里面就是用的ThreadLocal来实现这种隔离,主要是在TransactionSynchronizationManager这个类里面,代码如下所示:
private static final Log logger = LogFactory.getLog(TransactionSynchronizationManager.class);
private static final ThreadLocal<Map<Object, Object>> resources =
new NamedThreadLocal<>("Transactional resources");
private static final ThreadLocal<Set<TransactionSynchronization>> synchronizations =
new NamedThreadLocal<>("Transaction synchronizations");
private static final ThreadLocal<String> currentTransactionName =
new NamedThreadLocal<>("Current transaction name");
Spring的事务主要是ThreadLocal和AOP去做实现的,我这里提一下,大家知道每个线程自己的链接是靠ThreadLocal保存的就好了,继续的细节我会在Spring章节细说的
除了源码里面使用到ThreadLocal的场景,你自己有使用他的场景么?一般你会怎么用呢?
之前我们上线后发现部分用户的日期居然不对了,排查下来是SimpleDataFormat的锅,当时我们使用SimpleDataFormat的parse()方法,内部有一个Calendar对象,调用SimpleDataFormat的parse()方法会先调用Calendar.clear(),然后调用Calendar.add(),如果一个线程先调用了add()然后另一个线程又调用了clear(),这时候parse()方法解析的时间就不对了。
其实要解决这个问题很简单,让每个线程都new 一个自己的 SimpleDataFormat就好了,但是1000个线程难道new1000个SimpleDataFormat?
所以当时我们使用了线程池加上ThreadLocal包装SimpleDataFormat,再调用initialValue让每个线程有一个SimpleDataFormat的副本,从而解决了线程安全的问题,也提高了性能。
我在项目中存在一个线程经常遇到横跨若干方法调用,需要传递的对象,也就是上下文(Context),它是一种状态,经常就是是用户身份、任务信息等,就会存在过渡传参的问题。
使用到类似责任链模式,给每个方法增加一个context参数非常麻烦,而且有些时候,如果调用链有无法修改源码的第三方库,对象参数就传不进去了,所以我使用到了ThreadLocal去做了一下改造,这样只需要在调用前在ThreadLocal中设置参数,其他地方get一下就好了。
before
void work(User user) {
getInfo(user);
checkInfo(user);
setSomeThing(user);
log(user);
}
then
void work(User user) {
try{
threadLocalUser.set(user);
// 他们内部 User u = threadLocalUser.get(); 就好了
getInfo();
checkInfo();
setSomeThing();
log();
} finally {
threadLocalUser.remove();
}
}
我看了一下很多场景的cookie,session等数据隔离都是通过ThreadLocal去做实现的。
对了我面试官允许我再秀一下知识广度,在Android中,Looper类就是利用了ThreadLocal的特性,保证每个线程只存在一个Looper对象。
static final ThreadLocal<Looper> sThreadLocal = new ThreadLocal<Looper>();
private static void prepare(boolean quitAllowed) {
if (sThreadLocal.get() != null) {
throw new RuntimeException("Only one Looper may be created per thread");
}
sThreadLocal.set(new Looper(quitAllowed));
}
底层实现的原理么
ThreadLocal<String> localName = new ThreadLocal();
localName.set("张三");
String name = localName.get();
localName.remove();
其实使用真的很简单,线程进来之后初始化一个可以泛型的ThreadLocal对象,之后这个线程只要在remove之前去get,都能拿到之前set的值,注意这里我说的是remove之前。
他是能做到线程间数据隔离的,所以别的线程使用get()方法是没办法拿到其他线程的值的,但是有办法可以做到,我后面会说。
我们先看看他set的源码:
public void set(T value) {
Thread t = Thread.currentThread();// 获取当前线程
ThreadLocalMap map = getMap(t);// 获取ThreadLocalMap对象
if (map != null) // 校验对象是否为空
map.set(this, value); // 不为空set
else
createMap(t, value); // 为空创建一个map对象
}
大家可以发现set的源码很简单,主要就是ThreadLocalMap我们需要关注一下,而ThreadLocalMap呢是当前线程Thread一个叫threadLocals的变量中获取的。
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
public class Thread implements Runnable {
……
/* ThreadLocal values pertaining to this thread. This map is maintained
* by the ThreadLocal class. */
ThreadLocal.ThreadLocalMap threadLocals = null;
/*
* InheritableThreadLocal values pertaining to this thread. This map is
* maintained by the InheritableThreadLocal class.
*/
ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
……
这里我们基本上可以找到ThreadLocal数据隔离的真相了,每个线程Thread都维护了自己的threadLocals变量,所以在每个线程创建ThreadLocal的时候,实际上数据是存在自己线程Thread的threadLocals变量里面的,别人没办法拿到,从而实现了隔离。
ThreadLocalMap底层结构是怎么样子的呢
既然有个Map那他的数据结构其实是很像HashMap的,但是看源码可以发现,它并未实现Map接口,而且他的Entry是继承WeakReference(弱引用)的,也没有看到HashMap中的next,所以不存在链表了。
static class ThreadLocalMap {
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
……
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OGwMvaxW-1618135569578)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210411114442233.png)]
为什么需要数组呢?没有了链表怎么解决Hash冲突呢
用数组是因为,我们开发过程中可以一个线程可以有多个TreadLocal来存放不同类型的对象的,但是他们都将放到你当前线程的ThreadLocalMap里,所以肯定要数组来存。
至于Hash冲突,我们先看一下源码:
private void set(ThreadLocal<?> key, Object value) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
if (k == key) {
e.value = value;
return;
}
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
我从源码里面看到ThreadLocalMap在存储的时候会给每一个ThreadLocal对象一个threadLocalHashCode,在插入过程中,根据ThreadLocal对象的hash值,定位到table中的位置i,int i = key.threadLocalHashCode & (len-1)。
然后会判断一下:如果当前位置是空的,就初始化一个Entry对象放在位置i上;
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
如果位置i不为空,如果这个Entry对象的key正好是即将设置的key,那么就刷新Entry中的value;
if (k == key) {
e.value = value;
return;
}
如果位置i的不为空,而且key不等于entry,那就找下一个空位置,直到为空为止。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-s4xFvXfn-1618135569579)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210411114816300.png)]
这样的话,在get的时候,也会根据ThreadLocal对象的hash值,定位到table中的位置,然后判断该位置Entry对象中的key是否和get的key一致,如果不一致,就判断下一个位置,set和get如果冲突严重的话,效率还是很低的。
以下是get的源码,是不是就感觉很好懂了:
private Entry getEntry(ThreadLocal<?> key) {
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
if (e != null && e.get() == key)
return e;
else
return getEntryAfterMiss(key, i, e);
}
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
// get的时候一样是根据ThreadLocal获取到table的i值,然后查找数据拿到后会对比key是否相等 if (e != null && e.get() == key)。
while (e != null) {
ThreadLocal<?> k = e.get();
// 相等就直接返回,不相等就继续查找,找到相等位置。
if (k == key)
return e;
if (k == null)
expungeStaleEntry(i);
else
i = nextIndex(i, len);
e = tab[i];
}
return null;
}
能跟我说一下对象存放在哪里么?
在Java中,栈内存归属于单个线程,每个线程都会有一个栈内存,其存储的变量只能在其所属线程中可见,即栈内存可以理解成线程的私有内存,而堆内存中的对象对所有线程可见,堆内存中的对象可以被所有线程访问。
那么是不是说ThreadLocal的实例以及其值存放在栈上呢
其实不是的,因为ThreadLocal实例实际上也是被其创建的类持有(更顶端应该是被线程持有),而ThreadLocal的值其实也是被线程实例持有,它们都是位于堆上,只是通过一些技巧将可见性修改成了线程可见。
如果我想共享线程的ThreadLocal数据怎么办?
使用InheritableThreadLocal可以实现多个线程访问ThreadLocal的值,我们在主线程中创建一个InheritableThreadLocal的实例,然后在子线程中得到这个InheritableThreadLocal实例设置的值。
private void test() {
final ThreadLocal threadLocal = new InheritableThreadLocal();
threadLocal.set("帅得一匹");
Thread t = new Thread() {
@Override
public void run() {
super.run();
Log.i( "张三帅么 =" + threadLocal.get());
}
};
t.start();
}
在子线程中我是能够正常输出那一行日志的,这也是我之前面试视频提到过的父子线程数据传递的问题。
怎么传递的呀?
传递的逻辑很简单,我在开头Thread代码提到threadLocals的时候,你们再往下看看我刻意放了另外一个变量:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yCgDdAxN-1618135569579)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210411115021607.png)]
Thread源码中,我们看看Thread.init初始化创建的时候做了什么:
public class Thread implements Runnable {
……
if (inheritThreadLocals && parent.inheritableThreadLocals != null)
this.inheritableThreadLocals=ThreadLocal.createInheritedMap(parent.inheritableThreadLocals);
……
}
我就截取了部分代码,如果线程的inheritThreadLocals变量不为空 ,比如我们上面的例子,而且父线程的inheritThreadLocals也存在,那么我就把父线程的inheritThreadLocals给当前线程的inheritThreadLocals。
内存泄露么
这个问题确实会存在的,我跟大家说一下为什么,还记得我上面的代码么?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VqGzwfUD-1618135569579)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210411115121875.png)]
ThreadLocal在保存的时候会把自己当做Key存在ThreadLocalMap中,正常情况应该是key和value都应该被外界强引用才对,但是现在key被设计成WeakReference弱引用了。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LeOXN3fd-1618135569580)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210411115137219.png)]
我先给大家介绍一下弱引用:
只具有弱引用的对象拥有更短暂的生命周期,在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。
不过,由于垃圾回收器是一个优先级很低的线程,因此不一定会很快发现那些只具有弱引用的对象。
这就导致了一个问题,ThreadLocal在没有外部强引用时,发生GC时会被回收,如果创建ThreadLocal的线程一直持续运行,那么这个Entry对象中的value就有可能一直得不到回收,发生内存泄露。
就比如线程池里面的线程,线程都是复用的,那么之前的线程实例处理完之后,出于复用的目的线程依然存活,所以,ThreadLocal设定的value值被持有,导致内存泄露。
按照道理一个线程使用完,ThreadLocalMap是应该要被清空的,但是现在线程被复用了。
那怎么解决?
在代码的最后使用remove就好了,我们只要记得在使用的最后用remove把值清空就好了。
ThreadLocal<String> localName = new ThreadLocal();
try {
localName.set("张三");
……
} finally {
localName.remove();
}
remove的源码很简单,找到对应的值全部置空,这样在垃圾回收器回收的时候,会自动把他们回收掉。
那为什么ThreadLocalMap的key要设计成弱引用
key不设置成弱引用的话就会造成和entry中value一样内存泄漏的场景。
补充一点:ThreadLocal的不足,我觉得可以通过看看netty的fastThreadLocal来弥补,大家有兴趣可以看看。
其实ThreadLocal用法很简单,里面的方法就那几个,算上注释源码都没多少行,我用了十多分钟就过了一遍了,但是在我深挖每一个方法背后逻辑的时候,也让我不得不感慨Josh Bloch 和 Doug Lea的厉害之处。
在细节设计的处理其实往往就是我们和大神的区别,我认为很多不合理的点,在Google和自己不断深入了解之后才发现这才是合理,真的不服不行。
ThreadLocal是多线程里面比较冷门的一个类,使用频率比不上别的方法和类
48 、Java中interrupted 和 isInterrupted方法的区别?
public static boolean interrupted() {
return currentThread().isInterrupted(true);
}
public boolean isInterrupted() {
return isInterrupted(false);
}
private native boolean isInterrupted(boolean ClearInterrupted);
49 、为什么wait和notify方法要在同步块中调用?
因为 wait 和 notify 方法不在同步块中使用的话, 可能会引发 IllegalMonitorStateException ,
具体: Lost Wake-Up Problem
事情得从一个多线程编程里面臭名昭著的问题"Lost wake-up problem"说起。
这个问题并不是说只在Java语言中会出现,而是会在所有的多线程环境下出现。
假如有两个线程,一个消费者线程,一个生产者线程。生产者线程的任务可以简化成将count加一,而后唤醒消费者;消费者则是将count减一,而后在减到0的时候陷入睡眠:
生产者伪代码:
count+1;
notify();
消费者伪代码:
while(count<=0)
wait()
count--
熟悉多线程的朋友一眼就能够看出来,这里面有问题。什么问题呢?
生产者是两个步骤:
- count+1;
- notify();
消费者也是两个步骤:
- 检查count值;
- 睡眠或者减一;
万一这些步骤混杂在一起呢?比如说,初始的时候count等于0,这个时候消费者检查count的值,发现count小于等于0的条件成立;就在这个时候,发生了上下文切换,生产者进来了,噼噼啪啪一顿操作,把两个步骤都执行完了,也就是发出了通知,准备唤醒一个线程。这个时候消费者刚决定睡觉,还没睡呢,所以这个通知就会被丢掉。紧接着,消费者就睡过去了……
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ldBi9Im9-1618135569580)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210411155823544.png)]
这就是所谓的lost wake up问题。
那么怎么解决这个问题呢?
现在我们应该就能够看到,问题的根源在于,消费者在检查count到调用wait()之间,count就可能被改掉了。
这就是一种很常见的竞态条件。
很自然的想法是,让消费者和生产者竞争一把锁,竞争到了的,才能够修改count的值。
于是生产者的代码是:
tryLock()
count+1
notify()
releaseLock()
消费者的代码是:
tryLock()
while(count <= 0)
wait()
count-1
releaseLock()
注意的是,我这里将两者的两个操作都放进去了同步块中。
现在来思考一个问题,生产者代码这样修改行不行?
tryLock()
count+1
notify()
releaseLock()
答案是,这样改毫无卵用,依旧会出现lost wake up问题,而且和无锁的表现是一样的。
终极答案
所以,我们可以总结到,为了避免出现这种lost wake up问题,在这种模型之下,总应该将我们的代码放进去的同步块中。Java强制我们的wait()/notify()调用必须要在一个同步块中,就是不想让我们在不经意间出现这种lost wake up问题。不仅仅是这两个方法,包括java.util.concurrent.locks.Condition的await()/signal()也必须要在同步块中:
private ReentrantLock lock = new ReentrantLock();
private Condition condition = lock.newCondition();
@Test
public void test() {
try {
condition.signal();
} catch (Exception e) {
e.printStackTrace();
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5DY36kMP-1618135569581)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210411160214047.png)]
准确的来说,即便是我们自己在实现自己的锁机制的时候,也应该要确保类似于wait()和notify()这种调用,要在同步块内,防止使用者出现lost wake up问题。
Java的这种检测是很严格的。它要求的是,一定要处于锁对象的同步块中。举例来说:
private Object obj = new Object();
private Object anotherObj = new Object();
@Test
public void produce() {
synchronized (obj) {
try {
anotherObj.notify();
} catch (Exception e) {
e.printStackTrace();
}
}
}
这样是没有什么卵用的。一样出现IllegalMonitorStateException。
可以拿去套路面试官的话术
到这里,按照道理来说,就可以结束了。不过既然是面试遇到的问题,我就提供点面试回答的小技巧。
假如面试官问你这个问题了,你最开始不要巴啦啦全部说出来。只需要轻描淡写地说:“这是Java设计者为了避免使用者出现lost wake up问题而搞出来的。”
注意演技,一定要轻描淡写中透露着一丝“我其实就知道lost wake up这个名词,再问就要露馅了”的感觉。
于是面试官肯定会追问:“lost wake up问题是什么?”
这个时候你就可以巴啦啦一大堆了。这个过程你要充满自信,表露出那种睥睨天下这种小问题就别来烦我的气概来。
50 、为什么你应该在循环中检查等待条件?
51 、Java中的同步集合与并发集合有什么区别?
同步集合与并发集合都为多线程和并发提供了合适的线程安全的集合,不过并发集合的可扩展性更高。
在Java1.5之前程序员们只有同步集合来用且在多线程并发的时候会导致争用,阻碍了系统的扩展性。Java5介绍了并发集合像ConcurrentHashMap,不仅提供线程安全还用锁分离和内部分区等现代技术提高了可扩展性。
不管是同步集合还是并发集合他们都支持线程安全,他们之间主要的区别体现在性能和可扩展性,还有他们如何实现的线程安全上。
同步HashMap, Hashtable, HashSet, Vector, ArrayList 相比他们并发的实现(ConcurrentHashMap, CopyOnWriteArrayList, CopyOnWriteHashSet)会慢得多。造成如此慢的主要原因是锁, 同步集合会把整个Map或List锁起来,而并发集合不会。并发集合实现线程安全是通过使用先进的和成熟的技术像锁剥离。
比如ConcurrentHashMap 会把整个Map 划分成几个片段,只对相关的几个片段上锁,同时允许多线程访问其他未上锁的片段。
同样的,CopyOnWriteArrayList 允许多个线程以非同步的方式读,当有线程写的时候它会将整个List复制一个副本给它。
如果在读多写少这种对并发集合有利的条件下使用并发集合,这会比使用同步集合更具有可伸缩性。
52 、什么是线程池? 为什么要使用它?
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
//获取clt,clt记录着线程池状态和运行线程数。
int c = ctl.get();
//运行线程数小于核心线程数时,创建线程放入线程池中,并且运行当前任务。
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
//创建线程失败,重新获取clt。
c = ctl.get();
}
//线程池是运行状态并且运行线程大于核心线程数时,把任务放入队列中。
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
//重新检查线程池不是运行状态时,
//把任务移除队列,并通过拒绝策略对该任务进行处理。
if (! isRunning(recheck) && remove(command))
reject(command);
//当前运行线程数为0时,创建线程加入线程池中。
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//运行线程大于核心线程数时并且队列已满时,
//创建线程放入线程池中,并且运行当前任务。
else if (!addWorker(command, false))
//运行线程大于最大线程数时,失败则拒绝该任务
reject(command);
}
在execute方法中,多次调用的addWorker方法,再看一下这个方法:
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
//获取clt,clt记录着线程池状态和运行线程数。
int c = ctl.get();
//获取线程池的运行状态。
int rs = runStateOf(c);
//线程池处于关闭状态,或者当前任务为null
//或者队列不为空,则直接返回失败。
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
//获取线程池中的线程数
int wc = workerCountOf(c);
//线程数超过CAPACITY,则返回false;
//这里的core是addWorker方法的第二个参数,
//如果为true则根据核心线程数进行比较,
//如果为false则根据最大线程数进行比较。
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
//尝试增加线程数,如果成功,则跳出第一个for循环
if (compareAndIncrementWorkerCount(c))
break retry;
//如果增加线程数失败,则重新获取ctl
c = ctl.get();
//如果当前的运行状态不等于rs,说明状态已被改变,
//返回第一个for循环继续执行
if (runStateOf(c) != rs)
continue retry;
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
//根据当前任务来创建Worker对象
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
//获得锁以后,重新检查线程池状态
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive())
throw new IllegalThreadStateException();
//把刚刚创建的线程加入到线程池中
workers.add(w);
int s = workers.size();
//记录线程池中出现过的最大线程数量
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
//启动线程,开始运行任务
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
53 、怎么检测一个线程是否拥有锁?
54 、你如何在Java中获取线程堆栈?
什么是线程堆栈?线程堆栈也称线程调用堆栈,是虚拟机中线程(包括锁)状态的一个瞬间快照,即系统在某一个时刻所有线程的运行状态,包括每一个线程的调用堆栈,锁的持有情况。虽然不同的虚拟机打印出来的格式有些不同,但是线程堆栈的信息都包含:
1、线程名字,id,线程的数量等。
2、线程的运行状态,锁的状态(锁被哪个线程持有,哪个线程在等待锁等)
3、调用堆栈(即函数的调用层次关系)调用堆栈包含完整的类名,所执行的方法,源代码的行数。
借助堆栈信息可以帮助分析很多问题,如线程死锁,锁争用,死循环,识别耗时操作等等。在多线程场合下的稳定性问题分析和性能问题分析,线程堆栈分析湿最有效的方法,在多数情况下,无需对系统了解就可以进行相应的分析。
由于线程堆栈是系统某个时刻的线程运行状况(即瞬间快照),对于历史痕迹无法追踪。只能结合日志分析。总的来说线程堆栈是多线程类应用程序非功能型问题定位的最有效手段,最善于分析如下类型问题:
- 系统无缘无故的cpu过高
- 系统挂起,无响应
- 系统运行越来越慢
- 性能瓶颈(如无法充分利用cpu等)
- 线程死锁,死循环等
- 由于线程数量太多导致的内存溢出(如无法创建线程等)
借助线程堆栈可以帮助我们缩小范围,找到突破口。线程堆栈分析很多时候不需要源代码,在很多场合都有优势。下面我们就开始我们的线程堆栈之旅。
如何输出线程堆栈?
ava虚拟机提供了线程转储(thread dump)的后门,通过这个后门可以把线程堆栈打印出来。通常我们将堆栈信息重定向到一个文件中,便于我们分析,由于信息量太大,很可能超出控制台缓冲区的最大行数限制造成信息丢失。这里介绍一个jdk自带的打印线程堆栈的工具,jstack用于打印出给定的Java进程ID或core file或远程调试服务的Java堆栈信息。
示例:$ jstack –l 23561 >> xxx.dump
命令 : $ jstack [option] pid >> 文件
>>表示输出到文件尾部,实际运行中,往往一次dump的信息,还不足以确认问题,建议产生三次dump信息,如果每次dump都指向同一个问题,我们才确定问题的典型性。
"main" prio=1 tid=0x0805c988 nid=0xd28 runnable [0xfff65000..0xfff659c8]
at java.lang.String.indexOf(String.java:1352)
at java.io.PrintStream.write(PrintStream.java:460)
- locked <0xc8bf87d8> (a java.io.PrintStream)
at java.io.PrintStream.print(PrintStream.java:602)
at MyTest.fun2(MyTest.java:16)
- locked <0xc8c1a098> (a java.lang.Object)
at MyTest.fun1(MyTest.java:8)
- locked <0xc8c1a090> (a java.lang.Object)
at MyTest.main(MyTest.java:26)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WFf4CG9U-1618135569581)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210411162537680.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DjDDnvte-1618135569581)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210411162549962.png)]
其中"线程对应的本地线程Id号"所指的本地线程是指该java虚拟机所对应的虚拟机中的本地线程,
我们知道java是解析型语言,执行的实体是java虚拟机,因此java代码是依附于java虚拟机的本地线程执行的,之前文章中讲过,当启动一个线程时,是创建一个native本地线程,本地线程才是真实的线程实体,为了更加深入理解本地线程和java线程的关系,我们可以通过以下方式将java虚拟机的本地线程打印出来:
1、试用ps -ef|grep java 获得java进行id
2、试用pstack 获得java虚拟机本地线程的堆栈
从操作系统打印出来的虚拟机的本地线程看,本地线程数量和java线程数量是相同的,
说明二者是一一对应的关系。
我们获取的本地线程堆栈如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t1A31RTU-1618135569582)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210411162723034.png)]
这个本地线程号如何与java线程堆栈文件对应起来呢,每一个线程都有tid,nid的属性,通过这些属性可以对应相应的本地线程,我们先看java线程第一行,里面有一个属性是nid,
main" prio=1 tid=0x0805c988 nid=0xd28 runnable [0xfff65000..0xfff659c8]
其中nid是native thread id,也就是本地线程中的LWPID, 二者是相同的,只不过java线程中的nid用16进制表示,本地线程的id用十进制表示。3368的十六进制表示0xd28,在java线程堆栈中查找nid为0xd28就是本地线程对应的java线程。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TpDsKQ2E-1618135569582)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210411162839056.png)]
锁的解读
在介绍线程堆栈的解读方法之前,先介绍一点关于多线程的知识,即wait和sleep的重要区别。wait和sleep有一个共同点,就是二者都把当前线程阻塞住,我们叫睡眠或等待,二者有着本质区别:
- wait() 当线程执行到wait()方法上,当前线程会释放监视锁,此时其他线程可以占有该锁,一旦wait()方法执行完成,当前线程继续持有该锁,直到执行完锁的作用域。结合notify(),可以实现两个线程之间的通信,一个线程可以通过这种方法通知另一个线程继续执行,完成线程之间的配合。wait()锁的示意图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lM0KOsix-1618135569582)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210411163037418.png)]
在wait(5000)这个期间,当前线程会释放它占用的锁,其他线程有机会获得到该锁,当wait(5000)结束后,当前线程继续获取该锁的使用权。满足以下条件之一,wait退出:
1、达到等待时间之后,自动退出
2、其他线程调用了该锁的notify方法,如果多个线程在等待同一个锁,只有一个线程会被通知到。
- sleep() 和锁操作无关,如果该方法恰好在一个锁的保护范围内,当前线程即使执行sleep的时候,仍然保持监视锁。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LJZ9w9zp-1618135569583)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210411163129026.png)]
sleep方法是线程的一个静态方法,实际上和锁操作无关,不会产生特别的锁,如果原来持有,现在仍然持有,如果原来没有,现在仍然没有。
从上面介绍的线程堆栈看,线程堆栈中包含直接信息为:线程个数,每个线程调用的方法堆栈,当前锁的状态。从线程个数可以直接数出来,线程调用的方法堆栈,从下向上看,表示了当前线程调用哪个类哪个方法,锁的状态看起来需要一些技巧,与锁相关的重要信息如下:
- 当一个线程占有一个锁的时候,线程堆栈会打印一个-locked<0x22bffb60>
- 当一个线程正在等在其他线程释放该锁,线程堆栈会打印一个-waiting to lock<0x22bffb60>
- 当一个线程占有一个锁,但又执行在该锁的wait上,线程堆栈中首先打印locked,然后打印-waiting on <0x22c03c60>
在线程堆栈中与锁相关的三个最重要的特征字:locked,waiting to lock,waiting on 了解这三个特征字,就可以对锁进行分析了。
一般情况下,当一个或一些线程正在等待一个锁的时候,应该有一个线程占用了这个锁,即如果有一个线程正在等待一个锁,该锁必然被另一个线程占用,从线程堆栈中看,如果看到waiting to lock<0x22bffb60>,应该也应该有locked<0x22bffb60>,大多数情况下确实如此,但是有些情况下,会发现线程堆栈中可能根本没有locked<0x22bffb60>,而只有waiting to ,这是什么原因呢,实际上,在一个线程释放锁和另一个线程被唤醒之间有一个时间窗,如果这个期间,恰好打印堆栈信息,那么只会找到waiting to ,但是找不到locked 该锁的线程,当然不同的JAVA虚拟机有不同的实现策略,不一定会立刻响应请求,也许会等待正在执行的线程执行完成。
线程状态的解读
借助线程堆栈信息,可以分析很多问题,其中cpu的消耗分析也是线程堆栈分析的一个重要内容。
java线程状态有以下几类:
- RUNNABLE 从虚拟机的角度看,线程正在运行状态。
处于RUNNABLE状态的线程是不是一定会消耗cpu呢,不一定,像socket IO操作,线程正在从网络上读取数据,尽管线程状态RUNNABLE,但实际上网络io,线程绝大多数时间是被挂起的,只有当数据到达后,线程才会被唤起,挂起发生在本地代码(native)中,虚拟机根本不一致,不像显式的调用sleep和wait方法,虚拟机才能知道线程的真正状态,但在本地代码中的挂起,虚拟机无法知道真正的线程状态,因此一概显示为RUNNABLE。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VVI3bmQ9-1618135569583)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210411164828512.png)]
- TIMED_WAITING(on object monitor)表示当前线程被挂起一段时间,说明该线程正在执行obj.wait(ing time)方法,该线程不消耗cpu。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Rckf4rkF-1618135569583)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210411164847839.png)]
- TIMED_WAITING(sleeping) 表示当前线程被挂起一段时间,正在执行Thread.sleep(int time )方法,如:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hrT2HE0J-1618135569584)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210411164916313.png)]
- WAITING(on object monitor)当前线程被挂起,正在执行无参数的obj.wait()方法,只能通过notify唤醒,因此不消耗cpu
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AdYuKRzt-1618135569584)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210411164935241.png)]
总结:
- 处于timed_waiting,waiting状态的线程一定不消耗cpu,处于runnable状态的线程不一定会消耗cpu,要结合当前线程代码的性质判断,是否消耗cpu
- 如果是纯java运算代码,则消耗cpu
- 如果网络io,很少消耗cpu
- 如果是本地代码,集合本地代码的性质,可以通过pstack获取本地的线程堆栈,如果是纯运算代码,则消耗cpu,如果被挂起,则不消耗,如果是io,则不怎么消耗cpu。
56 、Thread类中的yield方法有什么作用?
使得当前线程让出CPU时间片,交给同级别或者更高级别的线程去执行,自己的状态改为 runnable
/**
* A hint to the scheduler that the current thread is willing to yield
* its current use of a processor. The scheduler is free to ignore this
* hint.
*
* <p> Yield is a heuristic attempt to improve relative progression
* between threads that would otherwise over-utilise a CPU. Its use
* should be combined with detailed profiling and benchmarking to
* ensure that it actually has the desired effect.
*
* <p> It is rarely appropriate to use this method. It may be useful
* for debugging or testing purposes, where it may help to reproduce
* bugs due to race conditions. It may also be useful when designing
* concurrency control constructs such as the ones in the
* {@link java.util.concurrent.locks} package.
*/
public static native void yield();
yield 即 “谦让”,也是 Thread 类的方法。它让掉当前线程 CPU 的时间片,使正在运行中的线程重新变成就绪状态,并重新竞争 CPU 的调度权。它可能会获取到,也有可能被其他线程获取到。
下面是一个使用示例。
public static void main(String[] args) {
Runnable runnable = () -> {
for (int i = 0; i <= 100; i++) {
System.out.println(Thread.currentThread().getName() + "-----" + i);
if (i % 20 == 0) {
Thread.yield();
}
}
};
new Thread(runnable, "栈长").start();
new Thread(runnable, "小蜜").start();
}
这个示例每当执行完 20 个之后就让出 CPU,每次谦让后就会马上获取到调度权继续执行。
运行以上程序,可以有以下两种结果。
结果1:栈长让出了 CPU 资源,小蜜成功上位。
栈长-----29
栈长-----30
小蜜-----26
栈长-----31
yield 和 sleep 的异同
1)yield, sleep 都能暂停当前线程,sleep 可以指定具体休眠的时间,而 yield 则依赖 CPU 的时间片划分。
2)yield, sleep 两个在暂停过程中,如已经持有锁,则都不会释放锁资源。
3)yield 不能被中断,而 sleep 则可以接受中断。
如果一定要用它的话,一句话解释就是:yield 方法可以很好的控制多线程,如执行某项复杂的任务时,如果担心占用资源过多,可以在完成某个重要的工作后使用 yield 方法让掉当前 CPU 的调度权,等下次获取到再继续执行,这样不但能完成自己的重要工作,也能给其他线程一些运行的机会,避免一个线程长时间占有 CPU 资源。
57 、Java中ConcurrentHashMap的并发度是什么?
58 、Java中Semaphore是什么?
信号量: 管理一系列临界资源的使用, 许可
Semaphore是一个计数信号量,它的本质是一个”共享锁”。
信号量维护了一个信号量许可集。线程可以通过调用acquire()来获取信号量的许可;当信号量中有可用的许可时,线程能获取该许可;否则线程必须等待,直到有可用的许可为止。 线程可以通过release()来释放它所持有的信号量许可。
Semaphore的函数列表
// 创建具有给定的许可数和非公平的公平设置的 Semaphore。
Semaphore(int permits)
// 创建具有给定的许可数和给定的公平设置的 Semaphore。
Semaphore(int permits, boolean fair)
// 从此信号量获取一个许可,在提供一个许可前一直将线程阻塞,否则线程被中断。
void acquire()
// 从此信号量获取给定数目的许可,在提供这些许可前一直将线程阻塞,或者线程已被中断。
void acquire(int permits)
// 从此信号量中获取许可,在有可用的许可前将其阻塞。
void acquireUninterruptibly()
// 从此信号量获取给定数目的许可,在提供这些许可前一直将线程阻塞。
void acquireUninterruptibly(int permits)
// 返回此信号量中当前可用的许可数。
int availablePermits()
// 获取并返回立即可用的所有许可。
int drainPermits()
// 返回一个 collection,包含可能等待获取的线程。
protected Collection<Thread> getQueuedThreads()
// 返回正在等待获取的线程的估计数目。
int getQueueLength()
// 查询是否有线程正在等待获取。
boolean hasQueuedThreads()
// 如果此信号量的公平设置为 true,则返回 true。
boolean isFair()
// 根据指定的缩减量减小可用许可的数目。
protected void reducePermits(int reduction)
// 释放一个许可,将其返回给信号量。
void release()
// 释放给定数目的许可,将其返回到信号量。
void release(int permits)
// 返回标识此信号量的字符串,以及信号量的状态。
String toString()
// 仅在调用时此信号量存在一个可用许可,才从信号量获取许可。
boolean tryAcquire()
// 仅在调用时此信号量中有给定数目的许可时,才从此信号量中获取这些许可。
boolean tryAcquire(int permits)
// 如果在给定的等待时间内此信号量有可用的所有许可,并且当前线程未被中断,则从此信号量获取给定数目的许可。
boolean tryAcquire(int permits, long timeout, TimeUnit unit)
// 如果在给定的等待时间内,此信号量有可用的许可并且当前线程未被中断,则从此信号量获取一个许可。
boolean tryAcquire(long timeout, TimeUnit unit)
Semaphore数据结构
Semaphore的UML类图如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-akMG6NSX-1618135569584)(C:\Users\itzz008\AppData\Roaming\Typora\typora-user-images\image-20210411171206712.png)]
从图中可以看出:
(01) 和”ReentrantLock”一样,Semaphore也包含了sync对象,sync是Sync类型;而且,Sync是一个继承于AQS的抽象类。
(02) Sync包括两个子类:”公平信号量”FairSync 和 “非公平信号量”NonfairSync。sync是”FairSync的实例”,或者”NonfairSync的实例”;默认情况下,sync是NonfairSync(即,默认是非公平信号量)。
Semaphore源码分析(基于JDK1.7.0_40)
Semaphore是通过共享锁实现的。根据共享锁的获取原则,Semaphore分为”公平信号量”和”非公平信号量”。
“公平信号量”和”非公平信号量”的区别
“公平信号量”和”非公平信号量”的释放信号量的机制是一样的!不同的是它们获取信号量的机制:
线程在尝试获取信号量许可时,对于公平信号量而言,如果当前线程不在CLH队列的头部,则排队等候;而对于非公平信号量而言,无论当前线程是不是在CLH队列的头部,它都会直接获取信号量。该差异具体的体现在,它们的tryAcquireShared()函数的实现不同。
“公平信号量”类
static final class FairSync extends Sync {
private static final long serialVersionUID = 2014338818796000944L;
FairSync(int permits) {
super(permits);
}
protected int tryAcquireShared(int acquires) {
for (;;) {
if (hasQueuedPredecessors())
return -1;
int available = getState();
int remaining = available - acquires;
if (remaining < 0 ||
compareAndSetState(available, remaining))
return remaining;
}
}
}
“非公平信号量”类
static final class NonfairSync extends Sync {
private static final long serialVersionUID = -2694183684443567898L;
NonfairSync(int permits) {
super(permits);
}
protected int tryAcquireShared(int acquires) {
return nonfairTryAcquireShared(acquires);
}
}
下面,我们逐步的对它们的源码进行分析。
1. 信号量构造函数
public Semaphore(int permits) {
sync = new NonfairSync(permits);
}
public Semaphore(int permits, boolean fair) {
sync = fair ? new FairSync(permits) : new NonfairSync(permits);
}
从中,我们可以信号量分为“公平信号量(FairSync)”和“非公平信号量(NonfairSync)”。Semaphore(int permits)函数会默认创建“非公平信号量”。
2. 公平信号量获取和释放
2.1 公平信号量的获取
Semaphore中的公平信号量是FairSync。它的获取API如下:
public void acquire() throws InterruptedException {
sync.acquireSharedInterruptibly(1);
}
public void acquire(int permits) throws InterruptedException {
if (permits < 0) throw new IllegalArgumentException();
sync.acquireSharedInterruptibly(permits);
}
信号量中的acquire()获取函数,实际上是调用的AQS中的acquireSharedInterruptibly()。
acquireSharedInterruptibly()的源码如下:
public final void acquireSharedInterruptibly(int arg)
throws InterruptedException {
// 如果线程是中断状态,则抛出异常。
if (Thread.interrupted())
throw new InterruptedException();
// 否则,尝试获取“共享锁”;获取成功则直接返回,获取失败,则通过doAcquireSharedInterruptibly()获取。
if (tryAcquireShared(arg) < 0)
doAcquireSharedInterruptibly(arg);
}
Semaphore中”公平锁“对应的tryAcquireShared()实现如下:
protected int tryAcquireShared(int acquires) {
for (;;) {
// 判断“当前线程”是不是CLH队列中的第一个线程线程,
// 若是的话,则返回-1。
if (hasQueuedPredecessors())
return -1;
// 设置“可以获得的信号量的许可数”
int available = getState();
// 设置“获得acquires个信号量许可之后,剩余的信号量许可数”
int remaining = available - acquires;
// 如果“剩余的信号量许可数>=0”,则设置“可以获得的信号量许可数”为remaining。
if (remaining < 0 ||
compareAndSetState(available, remaining))
return remaining;
}
}
说明:tryAcquireShared()的作用是尝试获取acquires个信号量许可数。
对于Semaphore而言,state表示的是“当前可获得的信号量许可数”。
下面看看AQS中doAcquireSharedInterruptibly()的实现:
private void doAcquireSharedInterruptibly(long arg)
throws InterruptedException {
// 创建”当前线程“的Node节点,且Node中记录的锁是”共享锁“类型;并将该节点添加到CLH队列末尾。
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
for (;;) {
// 获取上一个节点。
// 如果上一节点是CLH队列的表头,则”尝试获取共享锁“。
final Node p = node.predecessor();
if (p == head) {
long r = tryAcquireShared(arg);
if (r >= 0) {
setHeadAndPropagate(node, r);
p.next = null; // help GC
failed = false;
return;
}
}
// 当前线程一直等待,直到获取到共享锁。
// 如果线程在等待过程中被中断过,则再次中断该线程(还原之前的中断状态)。
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
说明:doAcquireSharedInterruptibly()会使当前线程一直等待,直到当前线程获取到共享锁(或被中断)才返回。
(01) addWaiter(Node.SHARED)的作用是,创建”当前线程“的Node节点,且Node中记录的锁的类型是”共享锁“(Node.SHARED);并将该节点添加到CLH队列末尾。关于Node和CLH在”Java多线程系列–“JUC锁”03之 公平锁(一)”已经详细介绍过,这里就不再重复说明了。
(02) node.predecessor()的作用是,获取上一个节点。如果上一节点是CLH队列的表头,则”尝试获取共享锁“。
(03) shouldParkAfterFailedAcquire()的作用和它的名称一样,如果在尝试获取锁失败之后,线程应该等待,则返回true;否则,返回false。
(04) 当shouldParkAfterFailedAcquire()返回ture时,则调用parkAndCheckInterrupt(),当前线程会进入等待状态,直到获取到共享锁才继续运行。
doAcquireSharedInterruptibly()中的shouldParkAfterFailedAcquire(), parkAndCheckInterrupt等函数在”Java多线程系列–“JUC锁”03之 公平锁(一)”中介绍过,这里也就不再详细说明了。
2.2 公平信号量的释放
Semaphore中公平信号量(FairSync)的释放API如下:
public void release() {
sync.releaseShared(1);
}
public void release(int permits) {
if (permits < 0) throw new IllegalArgumentException();
sync.releaseShared(permits);
}
信号量的releases()释放函数,实际上是调用的AQS中的releaseShared()。
releaseShared()在AQS中实现,源码如下:
public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) {
doReleaseShared();
return true;
}
return false;
}1234567
说明:releaseShared()的目的是让当前线程释放它所持有的共享锁。
它首先会通过tryReleaseShared()去尝试释放共享锁。尝试成功,则直接返回;尝试失败,则通过doReleaseShared()去释放共享锁。
Semaphore重写了tryReleaseShared(),它的源码如下:
protected final boolean tryReleaseShared(int releases) {
for (;;) {
// 获取“可以获得的信号量的许可数”
int current = getState();
// 获取“释放releases个信号量许可之后,剩余的信号量许可数”
int next = current + releases;
if (next < current) // overflow
throw new Error("Maximum permit count exceeded");
// 设置“可以获得的信号量的许可数”为next。
if (compareAndSetState(current, next))
return true;
}
}12345678910111213
如果tryReleaseShared()尝试释放共享锁失败,则会调用doReleaseShared()去释放共享锁。doReleaseShared()的源码如下:
private void doReleaseShared() {
for (;;) {
// 获取CLH队列的头节点
Node h = head;
// 如果头节点不为null,并且头节点不等于tail节点。
if (h != null && h != tail) {
// 获取头节点对应的线程的状态
int ws = h.waitStatus;
// 如果头节点对应的线程是SIGNAL状态,则意味着“头节点的下一个节点所对应的线程”需要被unpark唤醒。
if (ws == Node.SIGNAL) {
// 设置“头节点对应的线程状态”为空状态。失败的话,则继续循环。
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
continue;
// 唤醒“头节点的下一个节点所对应的线程”。
unparkSuccessor(h);
}
// 如果头节点对应的线程是空状态,则设置“文件点对应的线程所拥有的共享锁”为其它线程获取锁的空状态。
else if (ws == 0 &&
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE))
continue; // loop on failed CAS
}
// 如果头节点发生变化,则继续循环。否则,退出循环。
if (h == head) // loop if head changed
break;
}
}1234567891011121314151617181920212223242526
说明:doReleaseShared()会释放“共享锁”。它会从前往后的遍历CLH队列,依次“唤醒”然后“执行”队列中每个节点对应的线程;最终的目的是让这些线程释放它们所持有的信号量。
3 非公平信号量获取和释放
Semaphore中的非公平信号量是NonFairSync。在Semaphore中,“非公平信号量许可的释放(release)”与“公平信号量许可的释放(release)”是一样的。
不同的是它们获取“信号量许可”的机制不同,下面是非公平信号量获取信号量许可的代码。
非公平信号量的tryAcquireShared()实现如下:
protected int tryAcquireShared(int acquires) {
return nonfairTryAcquireShared(acquires);
}123
nonfairTryAcquireShared()的实现如下:
final int nonfairTryAcquireShared(int acquires) {
for (;;) {
// 设置“可以获得的信号量的许可数”
int available = getState();
// 设置“获得acquires个信号量许可之后,剩余的信号量许可数”
int remaining = available - acquires;
// 如果“剩余的信号量许可数>=0”,则设置“可以获得的信号量许可数”为remaining。
if (remaining < 0 ||
compareAndSetState(available, remaining))
return remaining;
}
}123456789101112
说明:非公平信号量的tryAcquireShared()调用AQS中的nonfairTryAcquireShared()。而在nonfairTryAcquireShared()的for循环中,它都会直接判断“当前剩余的信号量许可数”是否足够;足够的话,则直接“设置可以获得的信号量许可数”,进而再获取信号量。
而公平信号量的tryAcquireShared()中,在获取信号量之前会通过if (hasQueuedPredecessors())来判断“当前线程是不是在CLH队列的头部”,是的话,则返回-1。
Semaphore示例
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
public class SemaphoreTest1 {
private static final int SEM_MAX = 10;
public static void main(String[] args) {
Semaphore sem = new Semaphore(SEM_MAX);
//创建线程池
ExecutorService threadPool = Executors.newFixedThreadPool(3);
//在线程池中执行任务
threadPool.execute(new MyThread(sem, 5));
threadPool.execute(new MyThread(sem, 4));
threadPool.execute(new MyThread(sem, 7));
//关闭池
threadPool.shutdown();
}
}
class MyThread extends Thread {
private volatile Semaphore sem; // 信号量
private int count; // 申请信号量的大小
MyThread(Semaphore sem, int count) {
this.sem = sem;
this.count = count;
}
public void run() {
try {
// 从信号量中获取count个许可
sem.acquire(count);
Thread.sleep(2000);
System.out.println(Thread.currentThread().getName() + " acquire count="+count);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
// 释放给定数目的许可,将其返回到信号量。
sem.release(count);
System.out.println(Thread.currentThread().getName() + " release " + count + "");
}
}
}1234567891011121314151617181920212223242526272829303132333435363738394041424344
(某一次)运行结果:
pool-1-thread-1 acquire count=5
pool-1-thread-2 acquire count=4
pool-1-thread-1 release 5
pool-1-thread-2 release 4
pool-1-thread-3 acquire count=7
pool-1-thread-3 release 7123456
结果说明:信号量sem的许可总数是10个;共3个线程,分别需要获取的信号量许可数是5,4,7。前面两个线程获取到信号量的许可后,sem中剩余的可用的许可数是1;因此,最后一个线程必须等前两个线程释放了它们所持有的信号量许可之后,才能获取到7个信号量许可。
59 、Java线程池中submit() 和 execute()方法有什么区别?
- execute() 参数 Runnable ;submit() 参数 (Runnable) 或 (Runnable 和 结果 T) 或 (Callable)
- execute() 没有返回值;而 submit() 有返回值
- submit() 的返回值 Future 调用get方法时,可以捕获处理异常
60 、什么是阻塞式方法?
61 、Java中的ReadWriteLock是什么?
ReadWriteLock 如何使用?
ReadWriteLock,读写锁。
ReentrantReadWriteLock 是 ReadWriteLock 的一种实现。
特点:
包含一个 ReadLock 和 一个 WriteLock 对象
读锁与读锁不互斥;读锁与写锁,写锁与写锁互斥
适合对共享资源有读和写操作,写操作很少,读操作频繁的场景
可以从写锁降级到读锁。获取写锁->获取读锁->释放写锁
无法从读锁升级到写锁
读写锁支持中断
写锁支持Condition;读锁不支持Condition
示例1–根据 key 获取 value 值
private ReadWriteLock lock = new ReentrantReadWriteLock();//定义读写锁
//根据 key 获取 value 值
public Object getValue(String key){
//使用读写锁的基本结构
lock.readLock().lock();//加读锁
Object value = null;
try{
value = cache.get(key);
if(value == null){
lock.readLock().unlock();//value值为空,释放读锁
lock.writeLock().lock();//加写锁,写入value值
try{
//重新检查 value值是否已经被其他线程写入
if(value == null){
value = "value";//写入数据
}
}finally{
lock.writeLock().unlock();
}
lock.readLock().lock();
}
}finally{
lock.readLock().unlock();
}
return value;
}
示例2–多线程环境下的读写锁使用
package constxiong.interview;
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.locks.ReadWriteLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
/**
* 测试可重入 读写锁
* @author ConstXiong
* @date 2019-06-10 11:19:42
*/
public class TestReentrantReadWriteLock {
private Map<String, Object> map = new HashMap<String, Object>();
private ReadWriteLock lock = new ReentrantReadWriteLock();
/**
* 根据 key 获取 value
* @param key
* @return
*/
public Object get(String key) {
Object value = null;
lock.readLock().lock();
try {
Thread.sleep(50L);
value = map.get(key);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.readLock().unlock();
}
return value;
}
/**
* 设置key-value
* @param key
* @return
*/
public void set(String key, Object value) {
lock.writeLock().lock();
try {
Thread.sleep(50L);
map.put(key, value);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.writeLock().unlock();
}
}
//测试5个线程读数据,5个线程写数据
public static void main(String[] args) {
final TestReentrantReadWriteLock test = new TestReentrantReadWriteLock();
final String key = "lock";
final Random r = new Random();
for (int i = 0; i < 5; i++) {
new Thread(){
@Override
public void run() {
for (int j = 0; j < 10; j++) {
System.out.println(Thread.currentThread().getName() + " read value=" + test.get(key));
}
}
}.start();
new Thread(){
@Override
public void run() {
for (int j = 0; j < 10; j++) {
int value = r.nextInt(1000);
test.set(key, value);
System.out.println(Thread.currentThread().getName() + " write value=" + value);
}
}
}.start();
}
}
}
62 、volatile 变量和 atomic 变量有什么不同?
前言
对于ThreadLocal、Volatile、synchronized、Atomic这四个关键字,我想一提及到大家肯定都想到的是解决在多线程并发环境下资源的共享问题,但是要细说每一个的特点、区别、应用场景、内部实现等,却可能模糊不清,说不出个所以然来,所以,本文就对这几个关键字做一些作用、特点、实现上的讲解。
1、Atomic
具体参考:https://blog.csdn.net/fly910905/article/details/80737784
作用
对于原子操作类,Java的concurrent并发包中主要为我们提供了这么几个常用的:AtomicInteger、AtomicLong、AtomicBoolean、AtomicReference<T>。
对于原子操作类,最大的特点是在多线程并发操作同一个资源的情况下,使用Lock-Free算法来替代锁,这样开销小、速度快,对于原子操作类是采用原子操作指令实现的,从而可以保证操作的原子性。什么是原子性?比如一个操作i++;实际上这是三个原子操作,先把i的值读取、然后修改(+1)、最后写入给i。所以使用Atomic原子类操作数,比如:i++;那么它会在这步操作都完成情况下才允许其它线程再对它进行操作,而这个实现则是通过Lock-Free+原子操作指令来确定的
如:
AtomicInteger类中:
public final int incrementAndGet() {
for (;;) {
int current = get();
int next = current + 1;
if (compareAndSet(current, next))
return next;
}
}
而关于Lock-Free算法,则是一种新的策略替代锁来保证资源在并发时的完整性的,Lock-Free的实现有三步:
1、循环(for(;😉、while)
2、CAS(CompareAndSet)
3、回退(return、break)
用法
比如在多个线程操作一个count变量的情况下,则可以把count定义为AtomicInteger,如下:
public class Counter {
private AtomicInteger count = new AtomicInteger();
public int getCount() {
return count.get();
}
public void increment() {
count.incrementAndGet();
}
}
在每个线程中通过increment()来对count进行计数增加的操作,或者其它一些操作。这样每个线程访问到的将是安全、完整的count。
内部实现
采用Lock-Free算法替代锁+原子操作指令实现并发情况下资源的安全、完整、一致性
2、Volatile
作用
Volatile可以看做是一个轻量级的synchronized,它可以在多线程并发的情况下保证变量的“可见性”,什么是可见性?就是在一个线程的工作内存中修改了该变量的值,该变量的值立即能回显到主内存中,从而保证所有的线程看到这个变量的值是一致的。所以在处理同步问题上它大显作用,而且它的开销比synchronized小、使用成本更低。
举个栗子:在写单例模式中,除了用静态内部类外,还有一种写法也非常受欢迎,就是Volatile+DCL:
**具体参考:**https://blog.csdn.net/fly910905/article/details/79286680
public class Singleton {
private static volatile Singleton instance;
private Singleton() {
}
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
这样单例不管在哪个线程中创建的,所有线程都是共享这个单例的。
虽说这个Volatile关键字可以解决多线程环境下的同步问题,不过这也是相对的,因为它不具有操作的原子性,也就是它不适合在对该变量的写操作依赖于变量本身自己。举个最简单的栗子:在进行计数操作时count++,实际是count=count+1;,count最终的值依赖于它本身的值。所以使用volatile修饰的变量在进行这么一系列的操作的时候,就有并发的问题
举个栗子:因为它不具有操作的原子性,有可能1号线程在即将进行写操作时count值为4;而2号线程就恰好获取了写操作之前的值4,所以1号线程在完成它的写操作后count值就为5了,而在2号线程中count的值还为4,即使2号线程已经完成了写操作count还是为5,而我们期望的是count最终为6,所以这样就有并发的问题。而如果count换成这样:count=num+1;假设num是同步的,那么这样count就没有并发的问题的,只要最终的值不依赖自己本身。
用法
因为volatile不具有操作的原子性,所以如果用volatile修饰的变量在进行依赖于它自身的操作时,就有并发问题,如:count,像下面这样写在并发环境中是达不到任何效果的:
public class Counter {
private volatile int count;
public int getCount(){
return count;
}
public void increment(){
count++;
}
}
而要想count能在并发环境中保持数据的一致性,则可以在increment()中加synchronized同步锁修饰,改进后的为:
public class Counter {
private volatile int count;
public int getCount(){
return count;
}
public synchronized void increment(){
count++;
}
}
内部实现
汇编指令实现
可以看这篇详细了解:Volatile实现原理
3、synchronized
具体参考:https://blog.csdn.net/fly910905/article/details/79765381
作用
synchronized叫做同步锁,是Lock的一个简化版本,由于是简化版本,那么性能肯定是不如Lock的,不过它操作起来方便,只需要在一个方法或把需要同步的代码块包装在它内部,那么这段代码就是同步的了,所有线程对这块区域的代码访问必须先持有锁才能进入,否则则拦截在外面等待正在持有锁的线程处理完毕再获取锁进入,正因为它基于这种阻塞的策略,所以它的性能不太好,但是由于操作上的优势,只需要简单的声明一下即可,而且被它声明的代码块也是具有操作的原子性。
用法
public synchronized void increment(){
count++;
}
public void increment(){
synchronized (Counte.class){
count++;
}
}
内部实现
重入锁ReentrantLock+一个Condition,所以说是Lock的简化版本,因为一个Lock往往可以对应多个Condition
4、ThreadLocal
具体参考:
https://blog.csdn.net/fly910905/article/details/78860865
https://blog.csdn.net/fly910905/article/details/78869251
作用
关于ThreadLocal,这个类的出现并不是用来解决在多线程并发环境下资源的共享问题的,它和其它三个关键字不一样,其它三个关键字都是从线程外来保证变量的一致性,这样使得多个线程访问的变量具有一致性,可以更好的体现出资源的共享。
而ThreadLocal的设计,并不是解决资源共享的问题,而是用来提供线程内的局部变量,这样每个线程都自己管理自己的局部变量,别的线程操作的数据不会对我产生影响,互不影响,所以不存在解决资源共享这么一说,如果是解决资源共享,那么其它线程操作的结果必然我需要获取到,而ThreadLocal则是自己管理自己的,相当于封装在Thread内部了,供线程自己管理。
用法
一般使用ThreadLocal,官方建议我们定义为private static ,至于为什么要定义成静态的,这和内存泄露有关,后面再讲。
它有三个暴露的方法,set、get、remove。
public class ThreadLocalDemo {
private static ThreadLocal<String> threadLocal = new ThreadLocal<String>(){
@Override
protected String initialValue() {
return "hello";
}
};
static class MyRunnable implements Runnable{
private int num;
public MyRunnable(int num){
this.num = num;
}
@Override
public void run() {
threadLocal.set(String.valueOf(num));
System.out.println("threadLocalValue:"+threadLocal.get());
}
}
public static void main(String[] args){
new Thread(new MyRunnable(1));
new Thread(new MyRunnable(2));
new Thread(new MyRunnable(3));
}
}
运行结果如下,这些ThreadLocal变量属于线程内部管理的,互不影响:
threadLocalValue:2
threadLocalValue:3
threadLocalValue:4
对于get方法,在ThreadLocal没有set值得情况下,默认返回null,所有如果要有一个初始值我们可以重写initialValue()方法,在没有set值得情况下调用get则返回初始值。
值得注意的一点:ThreadLocal在线程使用完毕后,我们应该手动调用remove方法,移除它内部的值,这样可以防止内存泄露,当然还有设为static。
内部实现
ThreadLocal内部有一个静态类ThreadLocalMap,使用到ThreadLocal的线程会与ThreadLocalMap绑定,维护着这个Map对象,而这个ThreadLocalMap的作用是映射当前ThreadLocal对应的值,它key为当前ThreadLocal的弱引用:WeakReference
内存泄露问题
对于ThreadLocal,一直涉及到内存的泄露问题,即当该线程不需要再操作某个ThreadLocal内的值时,应该手动的remove掉,为什么呢?我们来看看ThreadLocal与Thread的联系图:
此图来自网络:
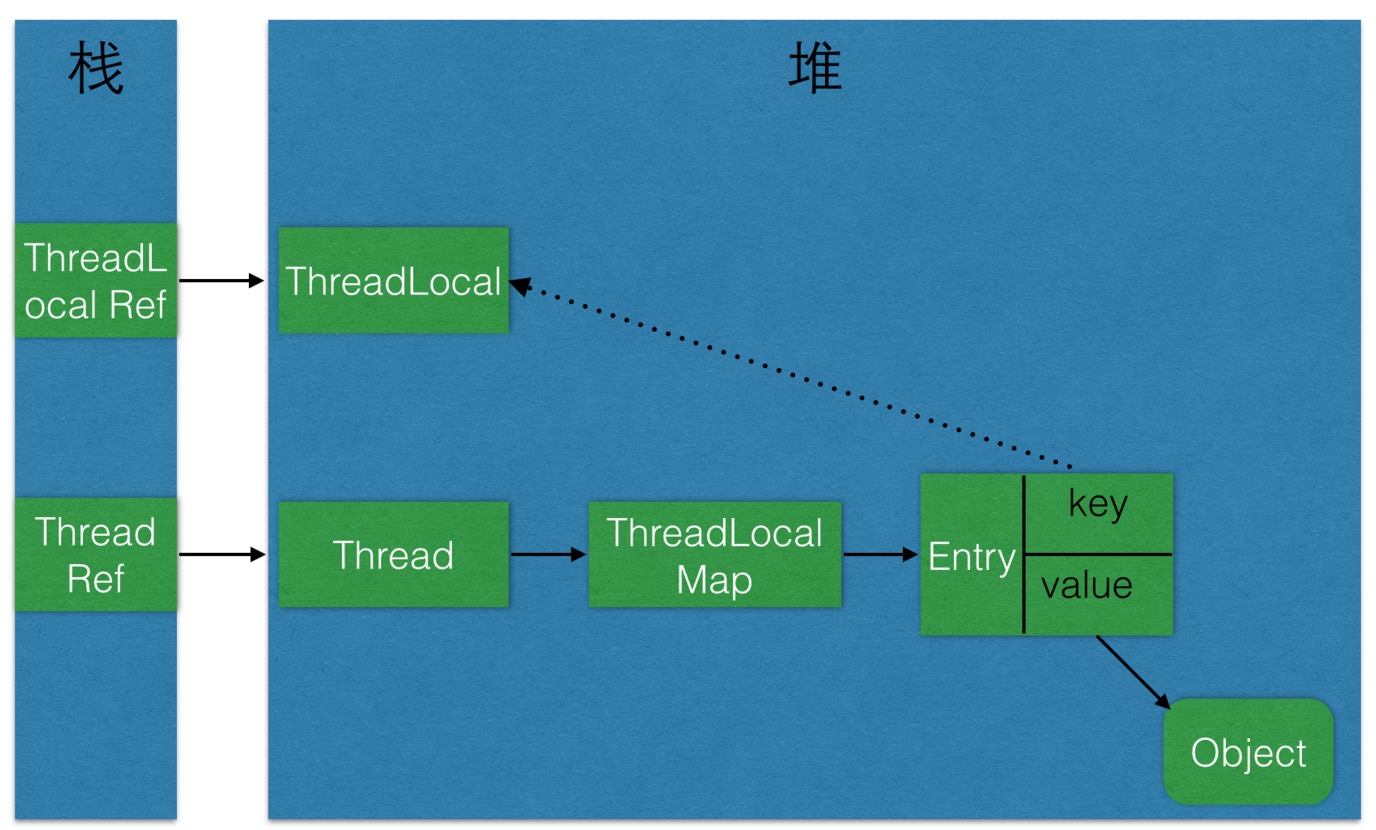
其中虚线表示弱引用,从该图可以看出,一个Thread维持着一个ThreadLocalMap对象,而该Map对象的key又由提供该value的ThreadLocal对象弱引用提供,所以这就有这种情况:
如果ThreadLocal不设为static的,由于Thread的生命周期不可预知,这就导致了当系统gc时将会回收它,而ThreadLocal对象被回收了,此时它对应key必定为null,这就导致了该key对应得value拿不出来了,而value之前被Thread所引用,所以就存在key为null、value存在强引用导致这个Entry回收不了,从而导致内存泄露。
所以避免内存泄露的方法,是对于ThreadLocal要设为static静态的,除了这个,还必须在线程不使用它的值是手动remove掉该ThreadLocal的值,这样Entry就能够在系统gc的时候正常回收,而关于ThreadLocalMap的回收,会在当前Thread销毁之后进行回收。
总结
关于Volatile关键字具有可见性,但不具有操作的原子性,而synchronized比volatile对资源的消耗稍微大点,但可以保证变量操作的原子性,保证变量的一致性,最佳实践则是二者结合一起使用。
1、对于synchronized的出现,是解决多线程资源共享的问题,同步机制采用了“以时间换空间”的方式:访问串行化,对象共享化。同步机制是提供一份变量,让所有线程都可以访问。
2、对于Atomic的出现,是通过原子操作指令+Lock-Free完成,从而实现非阻塞式的并发问题。
3、对于Volatile,为多线程资源共享问题解决了部分需求,在非依赖自身的操作的情况下,对变量的改变将对任何线程可见。
4、对于ThreadLocal的出现,并不是解决多线程资源共享的问题,而是用来提供线程内的局部变量,省去参数传递这个不必要的麻烦,ThreadLocal采用了“以空间换时间”的方式:访问并行化,对象独享化。ThreadLocal是为每一个线程都提供了一份独有的变量,各个线程互不影响。
63 、可以直接调用Thread类的run()方法么?
64 、如何让正在运行的线程暂停一段时间?
sleep
wait
yield
65 、你对线程优先级的理解是什么?
66 、 什么是线程调度器(Thread Scheduler)和时间分片(TimeSlicing)?
67 、你如何确保main()方法所在的线程是Java 程序最后结束的线程?
join
69 、为什么线程通信的方法wait(),notify()和notifyAll()被定义在Object类里?
71 、为什么Thread类的sleep()和yield()方法是静态的?
72 、如何确保线程安全?
不管单个线程还是多个线程执行, 结果要一样。 对临界值(共享变量)操作具有原子性和可见性
73 、同步方法和同步块,哪个是更好的选择?
能用同步块的就用同步块, 尽量使同步范围变小
75 、什么是Java Timer 类?如何创建一个有特定时间间隔的任务?
import java.util.Timer;
import java.util.TimerTask;
public class TimerTest {
public static void main(String[] args) {
Timer timer = new Timer();
timer.scheduleAtFixedRate(new TimerTask() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName());
}
},1000,1000);
}
}
76、 怎么排查死锁
打线程dump,
jstack -l pid
并行和并发有什么区别?
并发: 多个任务在同一个 CPU 核上,按细分的时间片轮流(交替)执行,从逻辑上来看那些任务是同时执行。
并行: 单位时间内,多个处理器或多核处理器同时处理多个任务,是真正意义上的“同时进行”。
串行: 有n个任务,由一个线程按顺序执行。由于任务、方法都在一个线程执行所以不存在线程不安全情况,也就不存在临界区的问题。
做一个形象的比喻:
并发 = 两个队列和一台咖啡机。
并行 = 两个队列和两台咖啡机。
串行 = 一个队列和一台咖啡机。
sleep() 和 yield() 方法有啥区别
(1) sleep()方法给其他线程运行机会时不考虑线程的优先级,因此会给低优先级的线程以运行的机会;yield()方法只会给相同优先级或更高优先级的线程以运行的机会;
(2) 线程执行 sleep()方法后转入阻塞(blocked)状态,而执行 yield()方法后转入就绪(ready)状态;
(3)sleep()方法声明抛出 InterruptedException,而 yield()方法没有声明任何异常;
(4)sleep()方法比 yield()方法(跟操作系统 CPU 调度相关)具有更好的可移植性,通常不建议使用yield()方法来控制并发线程的执行。
如何停止一个正在运行的线程?
在java中有以下3种方法可以终止正在运行的线程:
- 使用退出标志,使线程正常退出,也就是当run方法完成后线程终止。
- 使用stop方法强行终止,但是不推荐这个方法,因为stop和suspend及resume一样都是过期作废的方法。
- 使用interrupt方法中断线程。
Java 中 interrupted 和 isInterrupted 方法的区别?
interrupt:用于中断线程。调用该方法的线程的状态为将被置为”中断”状态。
注意:线程中断仅仅是置线程的中断状态位,不会停止线程。需要用户自己去监视线程的状态为并做处理。支持线程中断的方法(也就是线程中断后会抛出interruptedException 的方法)就是在监视线程的中断状态,一旦线程的中断状态被置为“中断状态”,就会抛出中断异常。
interrupted:是静态方法,查看当前中断信号是true还是false并且清除中断信号。如果一个线程被中断了,第一次调用 interrupted 则返回 true,第二次和后面的就返回 false 了。
isInterrupted:查看当前中断信号是true还是false
gleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
这样单例不管在哪个线程中创建的,所有线程都是共享这个单例的。
虽说这个Volatile关键字可以解决多线程环境下的同步问题,不过这也是相对的,因为它不具有操作的原子性,也就是它不适合在对该变量的写操作依赖于变量本身自己。举个最简单的栗子:在进行计数操作时count++,实际是count=count+1;,count最终的值依赖于它本身的值。所以使用volatile修饰的变量在进行这么一系列的操作的时候,就有并发的问题
举个栗子:因为它不具有操作的原子性,有可能1号线程在即将进行写操作时count值为4;而2号线程就恰好获取了写操作之前的值4,所以1号线程在完成它的写操作后count值就为5了,而在2号线程中count的值还为4,即使2号线程已经完成了写操作count还是为5,而我们期望的是count最终为6,所以这样就有并发的问题。而如果count换成这样:count=num+1;假设num是同步的,那么这样count就没有并发的问题的,只要最终的值不依赖自己本身。
**用法**
因为volatile不具有操作的原子性,所以如果用volatile修饰的变量在进行依赖于它自身的操作时,就有并发问题,如:count,像下面这样写在并发环境中是达不到任何效果的:
```java
public class Counter {
private volatile int count;
public int getCount(){
return count;
}
public void increment(){
count++;
}
}
而要想count能在并发环境中保持数据的一致性,则可以在increment()中加synchronized同步锁修饰,改进后的为:
public class Counter {
private volatile int count;
public int getCount(){
return count;
}
public synchronized void increment(){
count++;
}
}
内部实现
汇编指令实现
可以看这篇详细了解:Volatile实现原理
3、synchronized
具体参考:https://blog.csdn.net/fly910905/article/details/79765381
作用
synchronized叫做同步锁,是Lock的一个简化版本,由于是简化版本,那么性能肯定是不如Lock的,不过它操作起来方便,只需要在一个方法或把需要同步的代码块包装在它内部,那么这段代码就是同步的了,所有线程对这块区域的代码访问必须先持有锁才能进入,否则则拦截在外面等待正在持有锁的线程处理完毕再获取锁进入,正因为它基于这种阻塞的策略,所以它的性能不太好,但是由于操作上的优势,只需要简单的声明一下即可,而且被它声明的代码块也是具有操作的原子性。
用法
public synchronized void increment(){
count++;
}
public void increment(){
synchronized (Counte.class){
count++;
}
}
内部实现
重入锁ReentrantLock+一个Condition,所以说是Lock的简化版本,因为一个Lock往往可以对应多个Condition
4、ThreadLocal
具体参考:
https://blog.csdn.net/fly910905/article/details/78860865
https://blog.csdn.net/fly910905/article/details/78869251
作用
关于ThreadLocal,这个类的出现并不是用来解决在多线程并发环境下资源的共享问题的,它和其它三个关键字不一样,其它三个关键字都是从线程外来保证变量的一致性,这样使得多个线程访问的变量具有一致性,可以更好的体现出资源的共享。
而ThreadLocal的设计,并不是解决资源共享的问题,而是用来提供线程内的局部变量,这样每个线程都自己管理自己的局部变量,别的线程操作的数据不会对我产生影响,互不影响,所以不存在解决资源共享这么一说,如果是解决资源共享,那么其它线程操作的结果必然我需要获取到,而ThreadLocal则是自己管理自己的,相当于封装在Thread内部了,供线程自己管理。
用法
一般使用ThreadLocal,官方建议我们定义为private static ,至于为什么要定义成静态的,这和内存泄露有关,后面再讲。
它有三个暴露的方法,set、get、remove。
public class ThreadLocalDemo {
private static ThreadLocal<String> threadLocal = new ThreadLocal<String>(){
@Override
protected String initialValue() {
return "hello";
}
};
static class MyRunnable implements Runnable{
private int num;
public MyRunnable(int num){
this.num = num;
}
@Override
public void run() {
threadLocal.set(String.valueOf(num));
System.out.println("threadLocalValue:"+threadLocal.get());
}
}
public static void main(String[] args){
new Thread(new MyRunnable(1));
new Thread(new MyRunnable(2));
new Thread(new MyRunnable(3));
}
}
运行结果如下,这些ThreadLocal变量属于线程内部管理的,互不影响:
threadLocalValue:2
threadLocalValue:3
threadLocalValue:4
对于get方法,在ThreadLocal没有set值得情况下,默认返回null,所有如果要有一个初始值我们可以重写initialValue()方法,在没有set值得情况下调用get则返回初始值。
值得注意的一点:ThreadLocal在线程使用完毕后,我们应该手动调用remove方法,移除它内部的值,这样可以防止内存泄露,当然还有设为static。
内部实现
ThreadLocal内部有一个静态类ThreadLocalMap,使用到ThreadLocal的线程会与ThreadLocalMap绑定,维护着这个Map对象,而这个ThreadLocalMap的作用是映射当前ThreadLocal对应的值,它key为当前ThreadLocal的弱引用:WeakReference
内存泄露问题
对于ThreadLocal,一直涉及到内存的泄露问题,即当该线程不需要再操作某个ThreadLocal内的值时,应该手动的remove掉,为什么呢?我们来看看ThreadLocal与Thread的联系图:
此图来自网络:
其中虚线表示弱引用,从该图可以看出,一个Thread维持着一个ThreadLocalMap对象,而该Map对象的key又由提供该value的ThreadLocal对象弱引用提供,所以这就有这种情况:
如果ThreadLocal不设为static的,由于Thread的生命周期不可预知,这就导致了当系统gc时将会回收它,而ThreadLocal对象被回收了,此时它对应key必定为null,这就导致了该key对应得value拿不出来了,而value之前被Thread所引用,所以就存在key为null、value存在强引用导致这个Entry回收不了,从而导致内存泄露。
所以避免内存泄露的方法,是对于ThreadLocal要设为static静态的,除了这个,还必须在线程不使用它的值是手动remove掉该ThreadLocal的值,这样Entry就能够在系统gc的时候正常回收,而关于ThreadLocalMap的回收,会在当前Thread销毁之后进行回收。
总结
关于Volatile关键字具有可见性,但不具有操作的原子性,而synchronized比volatile对资源的消耗稍微大点,但可以保证变量操作的原子性,保证变量的一致性,最佳实践则是二者结合一起使用。
1、对于synchronized的出现,是解决多线程资源共享的问题,同步机制采用了“以时间换空间”的方式:访问串行化,对象共享化。同步机制是提供一份变量,让所有线程都可以访问。
2、对于Atomic的出现,是通过原子操作指令+Lock-Free完成,从而实现非阻塞式的并发问题。
3、对于Volatile,为多线程资源共享问题解决了部分需求,在非依赖自身的操作的情况下,对变量的改变将对任何线程可见。
4、对于ThreadLocal的出现,并不是解决多线程资源共享的问题,而是用来提供线程内的局部变量,省去参数传递这个不必要的麻烦,ThreadLocal采用了“以空间换时间”的方式:访问并行化,对象独享化。ThreadLocal是为每一个线程都提供了一份独有的变量,各个线程互不影响。
63 、可以直接调用Thread类的run()方法么?
64 、如何让正在运行的线程暂停一段时间?
sleep
wait
yield
65 、你对线程优先级的理解是什么?
66 、 什么是线程调度器(Thread Scheduler)和时间分片(TimeSlicing)?
67 、你如何确保main()方法所在的线程是Java 程序最后结束的线程?
join
69 、为什么线程通信的方法wait(),notify()和notifyAll()被定义在Object类里?
71 、为什么Thread类的sleep()和yield()方法是静态的?
72 、如何确保线程安全?
不管单个线程还是多个线程执行, 结果要一样。 对临界值(共享变量)操作具有原子性和可见性
73 、同步方法和同步块,哪个是更好的选择?
能用同步块的就用同步块, 尽量使同步范围变小
75 、什么是Java Timer 类?如何创建一个有特定时间间隔的任务?
import java.util.Timer;
import java.util.TimerTask;
public class TimerTest {
public static void main(String[] args) {
Timer timer = new Timer();
timer.scheduleAtFixedRate(new TimerTask() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName());
}
},1000,1000);
}
}
76、 怎么排查死锁
打线程dump,
jstack -l pid
并行和并发有什么区别?
并发: 多个任务在同一个 CPU 核上,按细分的时间片轮流(交替)执行,从逻辑上来看那些任务是同时执行。
并行: 单位时间内,多个处理器或多核处理器同时处理多个任务,是真正意义上的“同时进行”。
串行: 有n个任务,由一个线程按顺序执行。由于任务、方法都在一个线程执行所以不存在线程不安全情况,也就不存在临界区的问题。
做一个形象的比喻:
并发 = 两个队列和一台咖啡机。
并行 = 两个队列和两台咖啡机。
串行 = 一个队列和一台咖啡机。
sleep() 和 yield() 方法有啥区别
(1) sleep()方法给其他线程运行机会时不考虑线程的优先级,因此会给低优先级的线程以运行的机会;yield()方法只会给相同优先级或更高优先级的线程以运行的机会;
(2) 线程执行 sleep()方法后转入阻塞(blocked)状态,而执行 yield()方法后转入就绪(ready)状态;
(3)sleep()方法声明抛出 InterruptedException,而 yield()方法没有声明任何异常;
(4)sleep()方法比 yield()方法(跟操作系统 CPU 调度相关)具有更好的可移植性,通常不建议使用yield()方法来控制并发线程的执行。
如何停止一个正在运行的线程?
在java中有以下3种方法可以终止正在运行的线程:
- 使用退出标志,使线程正常退出,也就是当run方法完成后线程终止。
- 使用stop方法强行终止,但是不推荐这个方法,因为stop和suspend及resume一样都是过期作废的方法。
- 使用interrupt方法中断线程。
Java 中 interrupted 和 isInterrupted 方法的区别?
interrupt:用于中断线程。调用该方法的线程的状态为将被置为”中断”状态。
注意:线程中断仅仅是置线程的中断状态位,不会停止线程。需要用户自己去监视线程的状态为并做处理。支持线程中断的方法(也就是线程中断后会抛出interruptedException 的方法)就是在监视线程的中断状态,一旦线程的中断状态被置为“中断状态”,就会抛出中断异常。
interrupted:是静态方法,查看当前中断信号是true还是false并且清除中断信号。如果一个线程被中断了,第一次调用 interrupted 则返回 true,第二次和后面的就返回 false 了。
isInterrupted:查看当前中断信号是true还是false















 1806
1806











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









