






在linux中一切皆文件,里面有大量的文件,我们需要在成千上万个文件找到那些我们需要的文件!!!!这时就需要用到查找命令了,find命令比locate命令的功能要齐全而且要好用的多,所以博主只在这里接受find命令的用法。
命令格式
find [option]...[查找路径][查找条件][处理动作]
查找路径:默认为当前目录,自动向下递归
查找条件:可以是基于文件名,大小,类型,权限等标准进行
处理动作:对查找到的内容做处理,默认输出打印到屏幕
find命令通过遍历指定路径完成文件查找,它是精确查找,实时查找,仅搜索用户具 备rx权限的目录
查找条件
一、基于搜索层级:
1、-maxdepth level最大搜索深度
比如find -maxdepth 1,就表示只搜索1级,即只搜索该目录下的文件,而不再搜索其下的目录中的文件
2、-minxdepth level 最小搜索深度
比如find -mindepth 2 ,就表示至少要搜索二级。(搜索路径默认当前开始,下文就不再一一说了)
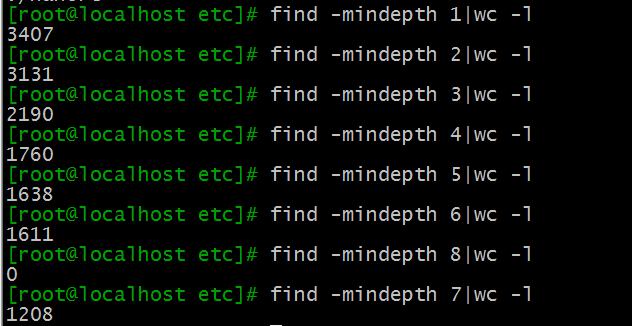
wc -l 统计搜索到的内容有多少行
由上图各个层级搜索可以看出,find的最小层级搜索,只会搜索匹配该等级的文件,比如层级为4时,则只搜索目录深度有四级以上的,而不搜索目录不足四级的!
二、基于文件名和inode以及链接数:
1、-name “文件名” 基于名称的精确查找,支持通配符*,?,[],[^],不加“”就不支持通配符了哟~
比如查找当前目录下文件名为group的文件:
find -name group

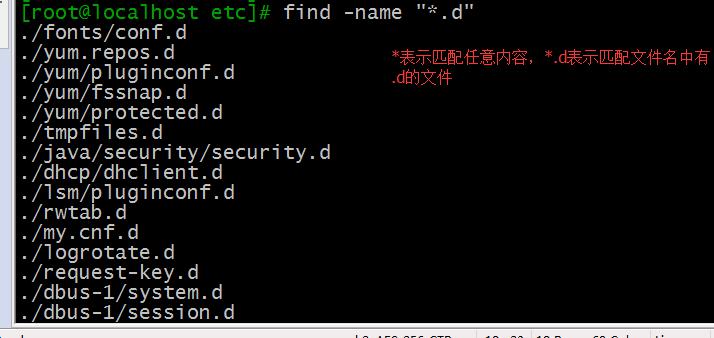
例如查找/etc下以.d结尾的文件,(加双引号表示模糊匹配,与通配符配合使用):
find /etc/ -name “*.d”
2、-iname 基于名称忽略大小写的精确查找查找
与-name用法一样,只是加上i就不区分文件名字大小写了,也就是不管大小写都会被搜索
3、-inum n 基于inode查找
例如查找/etc/ 下inode号为81的文件:
find -inum 81

4、-samefile name 基于相同inode号的查找(即查找硬链接)
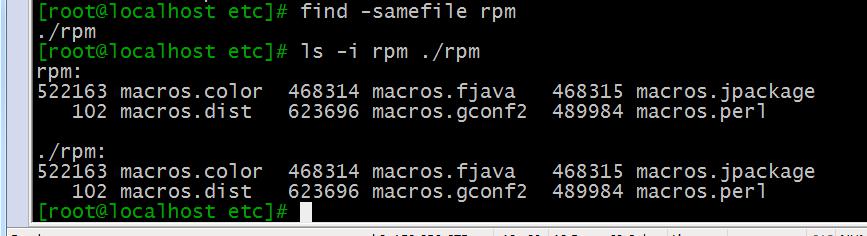
上例find -samefile rpm表示查找与rpm相同inode号的文件,使用ls -i可以查看两个文件的inode号,显而易见是一样的
5、-links n 硬链接数为n的文件
比如find -links 6就表示查找连接数为6的文件,此用法容易理解,就不再演示。
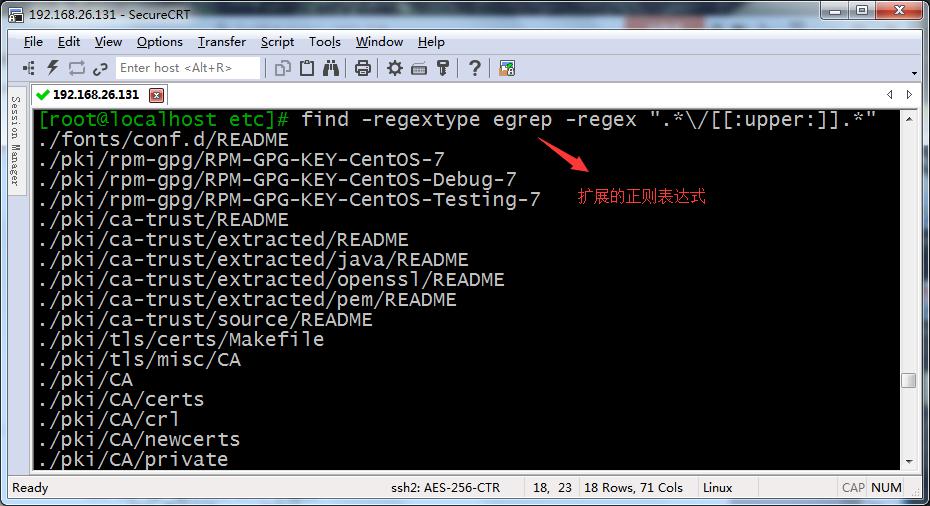
6、-regex 支持正则 默认为(emacs标准,即-regextype emacs -regex),默认标准中不能用“[[:upper:]]”,只能用“[A-Z]”
-regextype egrep -regex 支持egrep同标准的正则
比如:find -regextype egrep -regex ".*\/[[:upper:]].*"表示查找当前目录下所有以大写字母开头的文件,这里的.*相当于通配符的*(关于正则表达式及扩展正则表达式的用法,请参照博主之前的博客)。
三、基于文件的属主属组:
1、-user 用户名 基于文件owner的查找
比如find -user tss表示查找属主是tss的文件

2、-group 组名 基于文件group的查找
比如find -group root 表示查找属组是root的文件,与-user用法一样,就不再示例
3、-uid userid 基于文件uid的查找
比如find -uid 1000 表示查找用户uid是1000的文件
(可以使用id username 来查看用户的id号)
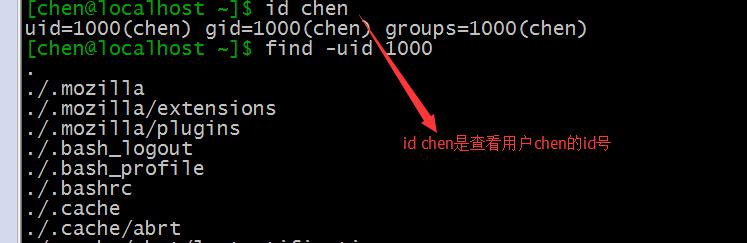
4、-gid groupid 基于文件gid的查找
与-uid用法一样,比如find -gid 1000 表示查找用户gid是1000的文件
5、-nouser 查找没有owner的文件
比如find -nouser 表示查找当前目录下没有属主的文件,用法简单,不再示例
6、-nogroup 查找没有group的文件
比如find -nogroup 表示查找当前目录下没有属组的文件,用法简单,不再示例
四、基于文件类型:
find -type type
f: 普通文件
d: 目录文件
l: 符号链接文件
s:套接字文件
b: 块设备文件
c: 字符设备文件
p: 管道文件
以上用法都一样,所以只举一个例子来说明一下。
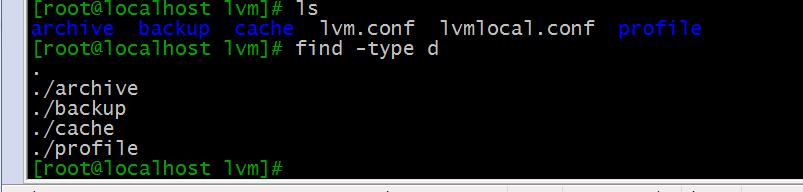
比如查找当前目录下的目录文件:
find . -type d
find . -type d | chmod u-x ##仅对文件夹修改权限
五、组合条件:
与:-a,两个之间不加-a也默认为-a
或:-o
非:-not 或者[!]
比如查找/var目录下属主为root,且属组为mail的所有文件
find /var -user root -a -group mail -ls (-ls表示对查找到的文件进行ls查看处理)

比如查找/etc下属主不是root的文件
find /etc not -user root

德·摩根定律:
!A -a !B = !(A -o B)
!A -o !B = !(A -a B)
在find中使用小括号时,小括号里面两边都要有空格,而且需对小括号使用\转义!
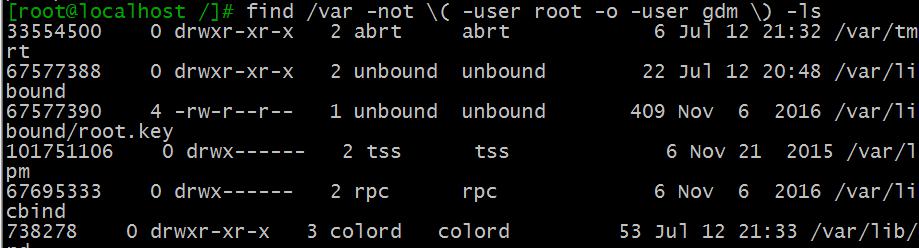
比如查找/var目录下不属于root、也不属于gdm的文件
find /var -not −userroot−o−usergdm−userroot−o−usergdm -ls 或者
find /var -not -user root -a -user gdm -ls
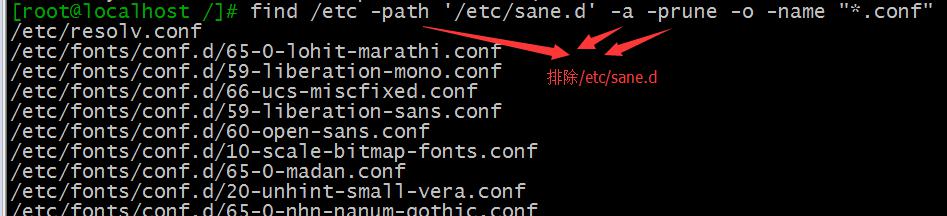
-prune :排除目录
示例:查找/etc下除/etc/sane.d目录之外,所有以.conf结尾的文件
find /etc -path '/etc/sane.d' -a -prune -o -name "*.conf"
查找/etc下除/etc/sane.d目录和/etc/fonts之外,所有以.conf结尾的文件
find /etc −path′/etc/sane.d′−o−path′/etc/fonts′−path′/etc/sane.d′−o−path′/etc/fonts′ -a -prune -o -name "*.conf"

六、基于文件大小:
-size [+|-]#UNIT 根据文件大小来查找
常用单位:k, M, G,c(byte)
#UNIT: (#-1, #]如:6k 表示(5k,6k]
-#UNIT:[0,#-1]如:-6k 表示[0,5k]
+#UNIT:(#,∞)如:+6k 表示(6k,∞)
比如查找/etc下大于3M的文件

七、基于时间戳:
以“天”为单位:
-atime [+|-]#, atime表示访问时间
-mtime[+|-]#, mtime表示数据修改时间
-ctime[+|-]#, ctime表示元数据修改时间
#: [#,#+1)如3 表示[3,4]
+#: [#+1,∞]如+3 表示[4,∞] +表示多少天以上
-#: [0,#)如-3 表示[0,3) -表示多少天以内
例如:查找/var目录下最近一周内其内容修改过,同时属主不为root,也不是postfix的文件
find /var/ -mtime -7 -not -user root -not -user postfix -ls

以“分钟”为单位:(用法同上面的以“天”为单位)
-amin
-mmin
-cmin
八、 基于权限:
-perm mode:精确权限匹配
比如,查找/etc下权限是644且以.cfg结尾的文件:
find /etc/ -perm 644 -name "*.cfg"

+mode[/mode] 任何一类(u,g,o)对象的权限中只要能一位匹配即可,是‘或’关系,+ 从centos7开始淘汰
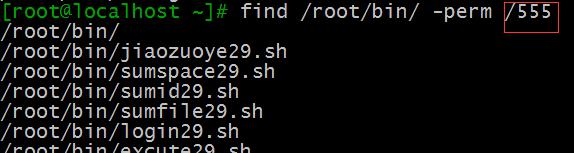
比如查找/root/bin下属主或者属组或者其他人有读和执行权限的文件:
find /etc/ -perm /555
-mode 每一类对象都必须同时拥有指定权限,‘与’关系,0表示不关注,一定要注意0不是没有权限,是忽略,可有可无!!
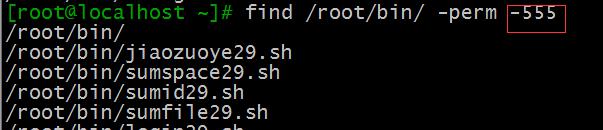
比如查找/root/bin下属主以及属组以及其他人都有读和执行权限的文件:
find /root/bin -perm -555
处理动作
1、-print 默认,打印出文件名
2、-delete 直接删除所查找到的文件,不询问。
比如删除/tmp下,元数据修改时间超过3天且属主是chen的文件:
find /tmp -ctime +3 -user chen -delete

3、-ls 长列出所查找到的文件
比如查找/root/bin下属主以及属组以及其他人都有读和执行权限的文件,并且长列出:
find /root/bin -perm /555 -ls

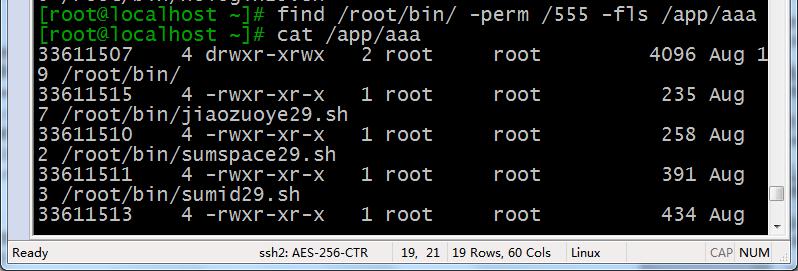
4、-fls file 将查找到的文件长列出导入到指定文件,也可以使用 > file
比如查找/root/bin下属主以及属组以及其他人都有读和执行权限的文件,将其导入/app/aaa
find /root/bin -perm /555 -fls /app/aaa 或者
find /root/bin -perm /555 > /app/aaa
5、-ok command \; 对查找到的文件当做下一命令的参数去执行(交互式),执行每一个文件时都会询问.
比如删除/app下以数字结尾的文件:
find /app -name "*[[:digit:]]" -ok rm {} \;
[:digit:]表示任意数字0-9,{}表示前面查找到的所有文件,\与命令之间要有空格!

6、-exec command \; 对查找到的文件当做下一命令的参数去执行(非交互式),不询问。与-ok对比会发现两者区别是-ok执行命令前询问,-exec不询问(如下图所示)

7、|xargs :用于产生某个命令的参数(不单单只能用在find中)
有时候有些命令不支持管道,而且执行rm,touch等命令时,对参数个数有一定限制,此时就可以使用|xargs将查找到的文件通过|xargs进行传参,这种传参相当于一个一个传。
例:查找/sbin下属主权限为满的文件,并且详细列出
find /sbin -perm /700 |xargs ls -l

通过上图比较可发现直接使用|查找到的内容并不是自己想要的,所以使用find时要用|xargs
下面举了一些有增强性的题来巩固一下上面的内容:
1、查找家目录下其他人有写权限的文件,取消其写权限。
find ~ -perm -002 -exec chmod o-w {} \;
2、查找/data下权限是644且以.sh结尾的普通文间件,修改权限为755。
find /data –type f -perm 644 -name “*.sh” –exec chmod 755 {} \;
3、查找当前系统上没有属主或属组,且最近一个周内曾被访问过的文件
find / -nouser -o -nogroup -a -atime -7
4、查找/etc目录下所有用户都没有写权限的文件
find /etc ! -perm /222 -ls
5、查找/etc目录下至少有一类用户没有执行权限的文件
find /etc ! -perm -111 -ls
6、查找/etc目录下所有子目录,取消其other访问权限
find /etc -mindepth 1 -type d -exec chmod o-x {} \;
7、用find模拟tree命令打印目录树,并打印时间戳
find . -print | sed -e "s#[^/]*/#|--#g" -e "s#--|# |#g"
find . -printf "%CH:%CM %Cd %Cb %CY " -print | sed -e "s#[^/ ]*/#|--#g" -e "s#--|# |#g"
附加(正则表达式语法)
元字符 描述
\ 将下一个字符标记符、或一个向后引用、或一个八进制转义符。例如,“\\n”匹配\n。“\n”匹配换行符。序列“\\”匹配“\”而“\(”则匹配“(”。即相当于多种编程语言中都有的“转义字符”的概念。
^ 匹配输入字行首。如果设置了RegExp对象的Multiline属性,^也匹配“\n”或“\r”之后的位置。
$ 匹配输入行尾。如果设置了RegExp对象的Multiline属性,$也匹配“\n”或“\r”之前的位置。
* 匹配前面的子表达式任意次。例如,zo*能匹配“z”,也能匹配“zo”以及“zoo”。*等价于{0,}。
+ 匹配前面的子表达式一次或多次(大于等于1次)。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。
? 匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“do”或“does”。?等价于{0,1}。
{n} n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。
{n,} n是一个非负整数。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。
{n,m} m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}”将匹配“fooooood”中的前三个o为一组,后三个o为一组。“o{0,1}”等价于“o?”。请注意在逗号和两个数之间不能有空格。
? 当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少地匹配所搜索的字符串,而默认的贪婪模式则尽可能多地匹配所搜索的字符串。例如,对于字符串“oooo”,“o+”将尽可能多地匹配“o”,得到结果[“oooo”],而“o+?”将尽可能少地匹配“o”,得到结果 ['o', 'o', 'o', 'o']
.点 匹配除“\n”和"\r"之外的任何单个字符。要匹配包括“\n”和"\r"在内的任何字符,请使用像“[\s\S]”的模式。
(pattern) 匹配pattern并获取这一匹配。所获取的匹配可以从产生的Matches集合得到,在VBScript中使用SubMatches集合,在JScript中则使用$0…$9属性。要匹配圆括号字符,请使用“\(”或“\)”。
(?:pattern) 非获取匹配,匹配pattern但不获取匹配结果,不进行存储供以后使用。这在使用或字符“(|)”来组合一个模式的各个部分时很有用。例如“industr(?:y|ies)”就是一个比“industry|industries”更简略的表达式。
(?=pattern) 非获取匹配,正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如,“Windows(?=95|98|NT|2000)”能匹配“Windows2000”中的“Windows”,但不能匹配“Windows3.1”中的“Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
(?!pattern) 非获取匹配,正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如“Windows(?!95|98|NT|2000)”能匹配“Windows3.1”中的“Windows”,但不能匹配“Windows2000”中的“Windows”。
(?<=pattern) 非获取匹配,反向肯定预查,与正向肯定预查类似,只是方向相反。例如,“(?<=95|98|NT|2000)Windows”能匹配“2000Windows”中的“Windows”,但不能匹配“3.1Windows”中的“Windows”。
*python的正则表达式没有完全按照正则表达式规范实现,所以一些高级特性建议使用其他语言如java、scala等
(?<!patte_n) 非获取匹配,反向否定预查,与正向否定预查类似,只是方向相反。例如“(?<!95|98|NT|2000)Windows”能匹配“3.1Windows”中的“Windows”,但不能匹配“2000Windows”中的“Windows”。
*python的正则表达式没有完全按照正则表达式规范实现,所以一些高级特性建议使用其他语言如java、scala等
x|y 匹配x或y。例如,“z|food”能匹配“z”或“food”(此处请谨慎)。“[zf]ood”则匹配“zood”或“food”。
[xyz] 字符集合。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a”。
[^xyz] 负值字符集合。匹配未包含的任意字符。例如,“[^abc]”可以匹配“plain”中的“plin”任一字符。
[a-z] 字符范围。匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。
注意:只有连字符在字符组内部时,并且出现在两个字符之间时,才能表示字符的范围; 如果出字符组的开头,则只能表示连字符本身.
[^a-z] 负值字符范围。匹配任何不在指定范围内的任意字符。例如,“[^a-z]”可以匹配任何不在“a”到“z”范围内的任意字符。
\b 匹配一个单词的边界,也就是指单词和空格间的位置(即正则表达式的“匹配”有两种概念,一种是匹配字符,一种是匹配位置,这里的\b就是匹配位置的)。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”;“\b1_”可以匹配“1_23”中的“1_”,但不能匹配“21_3”中的“1_”。
\B 匹配非单词边界。“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er”。
\cx 匹配由x指明的控制字符。例如,\cM匹配一个Control-M或回车符。x的值必须为A-Z或a-z之一。否则,将c视为一个原义的“c”字符。
\d 匹配一个数字字符。等价于[0-9]。grep 要加上-P,perl正则支持
\D 匹配一个非数字字符。等价于[^0-9]。grep要加上-P,perl正则支持
\f 匹配一个换页符。等价于\x0c和\cL。
\n 匹配一个换行符。等价于\x0a和\cJ。
\r 匹配一个回车符。等价于\x0d和\cM。
\s 匹配任何不可见字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。
\S 匹配任何可见字符。等价于[^ \f\n\r\t\v]。
\t 匹配一个制表符。等价于\x09和\cI。
\v 匹配一个垂直制表符。等价于\x0b和\cK。
\w 匹配包括下划线的任何单词字符。类似但不等价于“[A-Za-z0-9_]”,这里的"单词"字符使用Unicode字符集。
\W 匹配任何非单词字符。等价于“[^A-Za-z0-9_]”。
\xn 匹配n,其中n为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,“\x41”匹配“A”。“\x041”则等价于“\x04&1”。正则表达式中可以使用ASCII编码。
\num 匹配num,其中num是一个正整数。对所获取的匹配的引用。例如,“(.)\1”匹配两个连续的相同字符。
\n 标识一个八进制转义值或一个向后引用。如果\n之前至少n个获取的子表达式,则n为向后引用。否则,如果n为八进制数字(0-7),则n为一个八进制转义值。
\nm 标识一个八进制转义值或一个向后引用。如果\nm之前至少有nm个获得子表达式,则nm为向后引用。如果\nm之前至少有n个获取,则n为一个后跟文字m的向后引用。如果前面的条件都不满足,若n和m均为八进制数字(0-7),则\nm将匹配八进制转义值nm。
\nml 如果n为八进制数字(0-7),且m和l均为八进制数字(0-7),则匹配八进制转义值nml。
\un 匹配n,其中n是一个用四个十六进制数字表示的Unicode字符。例如,\u00A9匹配版权符号(©)。
\p{P} 小写 p 是 property 的意思,表示 Unicode 属性,用于 Unicode 正表达式的前缀。中括号内的“P”表示Unicode 字符集七个字符属性之一:标点字符。
其他六个属性:
L:字母;
M:标记符号(一般不会单独出现);
Z:分隔符(比如空格、换行等);
S:符号(比如数学符号、货币符号等);
N:数字(比如阿拉伯数字、罗马数字等);
C:其他字符。
*注:此语法部分语言不支持,例:javascript。
\<
\> 匹配词(word)的开始(\<)和结束(\>)。例如正则表达式\<the\>能够匹配字符串"for the wise"中的"the",但是不能匹配字符串"otherwise"中的"the"。注意:这个元字符不是所有的软件都支持的。
( ) 将( 和 ) 之间的表达式定义为“组”(group),并且将匹配这个表达式的字符保存到一个临时区域(一个正则表达式中最多可以保存9个),它们可以用 \1 到\9 的符号来引用。
| 将两个匹配条件进行逻辑“或”(Or)运算。例如正则表达式(him|her) 匹配"it belongs to him"和"it belongs to her",但是不能匹配"it belongs to them."。注意:这个元字符不是所有的软件都支持的。
本文基于查找命令find的用法_51CTO博客_find命令查找文件整理完善















 1073
1073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









