







 本教程详细介绍了如何在CentOS上搭建Hadoop完全分布式集群,包括克隆虚拟机、系统配置调整、SSH无密码登录、配置集群环境和执行分布式实例。过程中强调了内存管理和节点间的通信配置,适合初学者实践。
本教程详细介绍了如何在CentOS上搭建Hadoop完全分布式集群,包括克隆虚拟机、系统配置调整、SSH无密码登录、配置集群环境和执行分布式实例。过程中强调了内存管理和节点间的通信配置,适合初学者实践。
本篇在前一篇《Hadoop单机模式和伪分布式搭建教程》的基础上完成完全分布式的搭建,所以本篇的前提是已经按照之前的教程完成了伪分布式的安装。注意截图中的slaver应该是slave,哈哈,搭建的时候多打了r,没弄清slaver和slave的区别。
1. 说明
本教程中电脑为8G内存,故而将使用四个节点作为集群环境,其中一个为master,3个为slave(分别是slave1、slave2和slave3、master节点将仅为namenode存在,而slave节点是datanode),这样也算是比较标准的一个集群了。集群最后启动运行的时候8G内存不够了,崩溃了(原因可能是我设置虚拟机的内存是1.5G,可以考虑改成1G试试),所以建议大家学习弄个1个slave或者2个就可以了...视自己的情况而定....
2. 克隆虚拟机
右键虚拟机-->管理-->克隆,打开克隆向导,然后一路next,直至选择克隆类型为完整克隆:

输入虚拟机的名称为slave1,并且选择一个合适的虚拟机位置,点击完成即可。
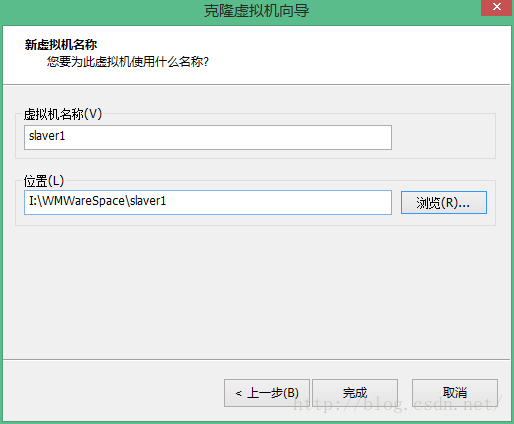
同理:再克隆一个slave2
结果图:
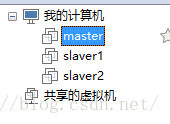
通过上面的步骤,每台虚拟机中都已经搭建了一个伪分布式的Hadoop,但是除了master外,其他的节点上的/usr/local/hadoop目录我们在后面会将其删除,然后将/usr/local/hadoop目录拷贝到每台slave节点上。如果是在实体机上面,那么需要给每个机器按照《Hadoop单机模式和伪分布式搭建教程CentOS》中1所做的准备工作做一遍。
Hadoop 集群的安装配置大致为如下流程:
1. 选定一台机器作为 Master
2. 在 Master 节点上配置 hadoop 用户、安装 SSH server、安装 Java 环境
3. 在 Master 节点上安装 Hadoop,并完成配置
4. 在其他 Slave 节点上配置 hadoop 用户、安装 SSH server、安装 Java 环境
5. 将 Master 节点上的 /usr/local/hadoop 目录复制到其他 Slave 节点上
6. 在 Master 节点上开启 Hadoop
3. 系统配置调整
因为我们是复制过来的虚拟机,需要对每个虚拟机的主机名以及Hosts文件进行编辑和修改,然后建立它们之间的互通。
1) 首先通过XShell建立与虚拟机之间的联系,通过远程来控制每台虚拟机。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4493
4493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









