







一、集群规划
这里搭建的是3个节点的完全分布式,即1个nameNode,2个dataNode,分别如下:
hadoopmaster nameNode 192.168.100.11
hadoopnode2 dataNode 192.168.100.12
hadoopnode3 dataNode 192.168.100.13
注意:本文中hadoopmaster可能简称为master,hadoopnode2可能简称为node1,hadoopnode3可能简称为node2,实际已自己制定的hostname为主,注意替换。
二、搭建集群
1.首先创建好一个CentOS虚拟机,将它作为主节点我这里起名为hadoopmaster,起什么都行,不固定要求。
2.VMware中打开虚拟机,输入java -version,检查是否有JDK环境,不要用系统自带的openJDK版本,要自己安装的版本,可以参考https://blog.csdn.net/zht245648124/article/details/86618430
3.输入 systemctl status firewalld.service ,若如图,防火墙处于running状态,则执行第4和第5步,否则直接进入第6步
[root@hadoopmaster ~]# systemctl status firewalld.service
4.输入 systemctl stop firewalld.service ,关闭防火墙
[root@hadoopmaster ~]# systemctl stop firewalld.service
5.输入 systemctl disable firewalld.service ,禁用防火墙
[root@hadoopmaster ~]# systemctl disable firewalld.service
6.输入 mkdir /usr/local/hadoop 创建一个hadoop的文件夹
[root@hadoopmaster /]# mkdir /usr/local/hadoop
7.将hadoop的tar包放到刚创建好的目录,可以从官方进行下载
https://hadoop.apache.org/releases.html
8.进入hadoop目录,输入 tar -zxvf hadoop-2.7.3.tar.gz 解压tar包
[root@hadoopmaster /]# tar -zxvf hadoop-2.7.7.tar.gz
9.输入 vi /etc/profile ,配置环境变量
[root@hadoopmaster /]# vi /etc/profile
10.加入如下内容,保存并退出
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin
11.输入 source /etc/profile ,使环境变量生效
[root@hadoopmaster /]# source /etc/profile
12.任意目录输入 hado ,然后按Tab,如果自动补全为hadoop,则说明环境变量配的没问题,否则检查环境变量哪出错了
[root@hadoopmaster /]# hadoop
13.创建3个之后要用到的文件夹,分别如下:
[root@hadoopmaster /]# mkdir /usr/local/hadoop/tmp
[root@hadoopmaster /]# mkdir -p /usr/local/hadoop/hdfs/name
[root@hadoopmaster /]# mkdir /usr/local/hadoop/hdfs/data
14.进入hadoop解压后的 /etc/hadoop 目录,里面存放的是hadoop的配置文件,接下来要修改这里面一些配置文件
[root@hadoopmaster /]# cd /usr/local/hadoop/hadoop-2.7.7/etc/hadoop/
15.有2个.sh文件,需要指定一下JAVA的目录,首先输入 vi hadoop-env.sh 修改配置文件
[root@hadoop /]# vi hadoop-env.sh
16.将原有的JAVA_HOME注释掉,根据自己的JDK安装位置,精确配置JAVA_HOME如下,保存并退出
export JAVA_HOME=/usr/local/java/jdk1.8.0_102/

17.输入 vi yarn-env.sh 修改配置文件
[root@hadoop /]# vi yarn-env.sh
18.加入如下内容,指定JAVA_HOME,保存并退出
export JAVA_HOME=/usr/local/java/jdk1.8.0_102

19.输入 vi core-site.xml 修改配置文件
[root@hadoop /]# vi core-site.xml
20.在configuration标签中,添加如下内容,保存并退出,注意这里配置的hdfs:hadoopmaster:9000是不能在浏览器访问的,hadoopmaster注意根据自己的master hostname来指定,图片可能不一致,根据自己实际情况修改。
<property>
<name> fs.default.name </name>
<value>hdfs://hadoopmaster:9000</value>
<description>指定HDFS的默认名称</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoopmaster:9000</value>
<description>HDFS的URI</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
<description>节点上本地的hadoop临时文件夹</description>
</property>

21.输入 vi hdfs-site.xml 修改配置文件
22.在configuration标签中,添加如下内容,保存并退出
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hdfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>副本个数,默认是3,应小于datanode机器数量</description>
</property>

23.输入 cp mapred-site.xml.template mapred-site.xml 将mapred-site.xml.template文件复制到当前目录,并重命名为mapred-site.xml
[root@hadoop /]# v cp mapred-site.xml.template mapred-site.xml
24.输入 vi mapred-site.xml 修改配置文件
25.在configuration标签中,添加如下内容,保存并退出
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>指定mapreduce使用yarn框架</description>
</property>

26.输入 vi yarn-site.xml 修改配置文件
27.在configuration标签中,添加如下内容,保存并退出
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
<description>指定resourcemanager所在的hostname</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>
NodeManager上运行的附属服务。
需配置成mapreduce_shuffle,才可运行MapReduce程序
</description>
</property>

28.输入 vi slaves 修改配置文件
29.将localhost删掉,加入如下内容,即dataNode节点的主机名,图片仅供参考,根据实际情况配置。
hadoopnode2
hadoopnode3

30.将虚拟机关闭,再复制两份虚拟机,重命名为如下,注意这里一定要关闭虚拟机,再复制
31.将3台虚拟机都打开,后两台复制的虚拟机打开时,都选择“完整克隆”
32.在master机器上,输入 vi /etc/hostname,将localhost改为master,保存并退出
a. 永久性的修改主机名
[root@hadoop /]# hostnamectl set-hostname hadoopmaster
#>vi /etc/sysconfig/network
添加或修改:
NETWORKING=yes
HOSTNAME=hadoopmaster
33.在node1机器上,输入 vi /etc/hostname,将localhost改为hadoopnode2,保存并退出
34. 修改/etc/sysconfig/network文件
#>vi /etc/sysconfig/network
添加或修改:
NETWORKING=yes
HOSTNAME=hadoopnode2
35.在node1机器上,输入 vi /etc/hostname,将localhost改为hadoopnode3,保存并退出
36. 修改/etc/sysconfig/network文件
#>vi /etc/sysconfig/network
添加或修改:
NETWORKING=yes
HOSTNAME=hadoopnode3
35.在三台机器分别输入 vi /etc/hosts 修改文件,其作用是将一些常用的网址域名与其对应的IP地址建立一个关联,当用户在访问网址时,系统会首先自动从Hosts文件中寻找对应的IP地址
36.三个文件中都加入如下内容,保存并退出,注意这里要根据自己实际IP和节点主机名进行更改,IP和主机名中间要有一个空格
hadoopnode2 192.168.100.13
hadoopnode3 192.168.100.12
hadoopmaster 192.168.100.11
注意:克隆之后的主机每台都要修改自己的ip地址和mac地址,指定每台机器的ip和修改mac地址可以参考:https://blog.csdn.net/zht245648124/article/details/88094319
37.在master机器上输入 ssh-keygen -t dsa -P ‘’ -f ~/.ssh/id_dsa 创建一个无密码的公钥,-t是类型的意思,dsa是生成的密钥类型,-P是密码,’’表示无密码,-f后是秘钥生成后保存的位置
[root@hadoop /]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
38.在master机器上输入 cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys 将公钥id_dsa.pub添加进keys,这样就可以实现无密登陆ssh
[root@hadoop /]# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
39.在master机器上输入 ssh master 测试免密码登陆
[root@hadoop /]# ssh master
如果有询问,则输入 yes ,回车

40.在node1主机上执行 mkdir ~/.ssh
41.在node2主机上执行 mkdir ~/.ssh
42.在master机器上输入 scp ~/.ssh/authorized_keys root@node1:~/.ssh/authorized_keys 将主节点的公钥信息导入node1节点,导入时要输入一下node1机器的登陆密码

43.在master机器上输入 scp ~/.ssh/authorized_keys root@node2:~/.ssh/authorized_keys 将主节点的公钥信息导入node2节点,导入时要输入一下node2机器的登陆密码

44.在三台机器上分别执行 chmod 600 ~/.ssh/authorized_keys 赋予密钥文件权限

45.在master节点上分别输入 ssh node1 和 ssh node2 测试是否配置ssh成功
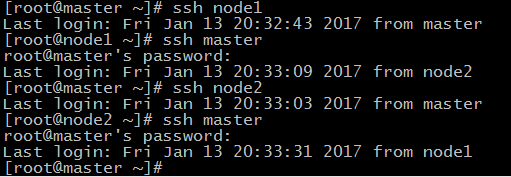
46.如果node节点还没有hadoop,则master机器上分别输入如下命令将hadoop复制
scp -r /usr/local/hadoop/ root@node1:/usr/local/
scp -r /usr/local/hadoop/ root@node2:/usr/local/
47.在master机器上,任意目录输入 hdfs namenode -format 格式化namenode,第一次使用需格式化一次,之后就不用再格式化,如果改一些配置文件了,可能还需要再次格式
化

48.格式化完成

49.在master机器上,进入hadoop的sbin目录,输入 ./start-all.sh 启动hadoop
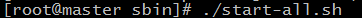
50.输入yes,回车
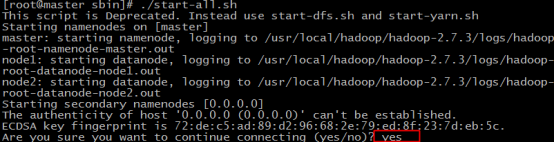
51.输入 jps 查看当前java的进程,该命令是JDK1.5开始有的,作用是列出当前java进程的PID和Java主类名,nameNode节点除了JPS,还有3个进程,启动成功
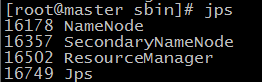
52.在node1机器和node2机器上分别输入 jps 查看进程如下,说明配置成功
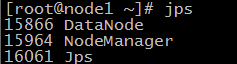
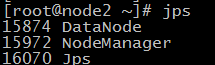
53.在浏览器访问nameNode节点的8088端口和50070端口可以查看hadoop的运行状况
54.在master机器上,进入hadoop的sbin目录,输入 ./stop-all.sh 关闭hadoop
55.运行wordcount测试
先在 /usr/local/hadoop/file中创建file.txt1和file.txt2
[root@hadoopmaster sbin]# hadoop fs -put /usr/local/hadoop/file/file*.txt input
[root@hadoopmaster sbin]# hadoop fs -ls input
Found 2 items
-rw-r--r-- 1 root supergroup 30 2019-03-03 23:01 input/file1.txt
-rw-r--r-- 1 root supergroup 44 2019-03-03 23:01 input/file2.txt
[root@hadoopmaster sbin]# hadoop fs -text input/file1.txt
hello word
hello java
hello c
[root@hadoopmaster mapreduce]# hadoop jar /usr/local/hadoop/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount input output















 756
756











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









