









import os#python环境下对文件,文件夹执行操作的一个模块。
import random
import pickle#把 Python 对象直接保存到文件里 持久化模块 将数据保存到磁盘上以便后续使用
import argparse# 命令项选项与参数解析
from collections import deque #deque 是 "double-ended queue"(双向队列)的缩写,它是一种特殊的数据结构,它可以在队列的两端进行高效的添加和删除操作。 与普通列表(list)相比,deque 提供了更快的在队列头部添加和删除元素的性能,因此它通常用于需要高效的队列操作的场合。
import numpy as np
import torch
import torch.nn as nn#nn 模块是 PyTorch 中用于构建神经网络模型的核心模块之一 使用 nn 模块,你可以更轻松地创建和训练各种类型的神经网络,包括卷积神经网络(CNN)、循环神经网络(RNN)、前馈神经网络(Feedforward Neural Network)等。
import torch.nn.functional as F #通常被缩写为 F,它包含了许多用于执行神经网络操作的函数。这些函数通常是无状态的,意味着它们没有内部状态,只是接受输入并返回输出。
import torch.optim as optim #一种优化器模块的代码
from torch.utils.data import IterableDataset, DataLoader, get_worker_info##IterableDataset 可迭代数据集 可以根据需要动态生成数据而不是一次性将所有数据加载到内存中
#DataLoader小批量加载数据
#get_worker_info打印日志
from torch.utils.tensorboard import SummaryWriter #创建 TensorBoard 的日志文件以进行训练过程的可视化。
class TripletUniformPair(IterableDataset):
# 继承 IterableDataset 表示可迭代数据集
def __init__(self, num_item, user_list, pair, shuffle, num_epochs):
self.num_item = num_item #物品数量
self.user_list = user_list #用户集合
self.pair = pair
self.shuffle = shuffle
self.num_epochs = num_epochs
def __iter__(self):#定义类的迭代器
worker_info = get_worker_info()
# Shuffle per epoch
self.example_size = self.num_epochs * len(self.pair) #数据的总大小
self.example_index_queue = deque([]) #数据索引双向队列
self.seed = 0 #设置随机种子
if worker_info is not None:#设置工作进程数量
self.start_list_index = worker_info.id #worker_info.id表示当前工作进程的id
self.num_workers = worker_info.num_workers #worker_info.num_workers 表示总工作进程的数量,即在数据加载时同时运行的工作进程的总数。
self.index = worker_info.id#在数据加载过程中分配不同的数据块给不同的工作进程
else:
self.start_list_index = None #工作进程的起始索引
self.num_workers = 1
self.index = 0
return self #返回迭代器本身
def __next__(self):#自定义数据集的迭代器
if self.index >= self.example_size:
raise StopIteration#检查当前的索引 self.index 是否超过了数据集的总样本数量 self.example_size。如果超过了,说明已经迭代完了数据集,可以触发 StopIteration 异常来结束迭代。
# If `example_index_queue` is used up, replenish this list. #如果`example_index_queue`已用完,请补充此列表。
while len(self.example_index_queue) == 0:
index_list = list(range(len(self.pair)))#range() 函数用于生成一个整数序列,生成了一个从 0 到 len(self.pair) - 1 的整数序列,又因为 range() 返回的是一个可迭代对象,而 list() 函数将其转换为一个列表。
if self.shuffle:
random.Random(self.seed).shuffle(index_list)#random.Random 类创建了一个具有指定随机种子的随机数生成器对象,并对 index_list 中的样本索引进行了随机打乱。这可以增加数据的随机性,有助于模型更好地学习。
self.seed += 1 #每次进行洗牌时,随机种子 self.seed 可能会递增,以确保每次的洗牌顺序都不同。
if self.start_list_index is not None:
index_list = index_list[self.start_list_index::self.num_workers] #这种切片操作用于在多工作进程环境中有效地拆分数据集
# Calculate next start index 计算下一个开始索引
self.start_list_index = (self.start_list_index + (self.num_workers - (len(self.pair) % self.num_workers))) % self.num_workers
self.example_index_queue.extend(index_list) #这个操作将在队列的尾部添加元素
result = self._example(self.example_index_queue.popleft()) #popleft() 是双向队列(deque)的方法,用于从队列的左侧(头部)弹出一个元素。
self.index += self.num_workers
return result
def _example(self, idx): #idx 表示示例索引
u = self.pair[idx][0] #用户
i = self.pair[idx][1] #正样本
j = np.random.randint(self.num_item) #负样本项目 np.random.randint() 函数用于生成随机整数,范围在 [0, self.num_item) 之间
while j in self.user_list[u]:#这是一个循环,用于确保随机生成的项目 j 不在用户 u 的已有项目列表 self.user_list[u] 中。循环会一直运行,直到找到一个不在用户列表中的项目。
j = np.random.randint(self.num_item)
return u, i, j#这是为了确保生成的负样本与用户之前的交互不重复。
class BPR(nn.Module):#继承自 PyTorch 中的 nn.Module 类。这意味着这个类将作为一个 PyTorch 模型来使用,并且可以包含模型的参数和前向传播逻辑。
def __init__(self, user_size, item_size, dim, weight_decay):# 用户数量,项目数量,嵌入维度,权重衰减
# weight_decay:这是正则化项的权重,用于控制模型的过拟合。正则化有助于提高模型的泛化能力。
super().__init__() #super().__init__() 是 Python 中用于调用父类(基类)构造函数的语句。确保父类的初始化代码得以执行。 #调用父类初始化构造函数
self.W = nn.Parameter(torch.empty(user_size, dim))#创建一个名为 W 的可训练参数(nn.Parameter),表示用户的嵌入矩阵,其大小为 user_size 行(每行代表一个用户)和 dim 列(表示嵌入维度)。 # 这个矩阵将会在训练过程中学习,用于表示用户的特征。
self.H = nn.Parameter(torch.empty(item_size, dim))#创建一个名为 H 的可训练参数,表示项目的嵌入矩阵,其大小为 item_size 行(每行代表一个项目)和 dim 列(表示嵌入维度)。
# 这个矩阵也将会在训练过程中学习,用于表示项目的特征。
nn.init.xavier_normal_(self.W.data) #nn.init.xavier_normal_ 是一个 PyTorch 中的初始化方法,用于对神经网络的权重进行初始化 用于对模型参数 self.W 的值进行 Xavier 正态分布初始化。
#Xavier 初始化(也称为 Glorot 初始化)是一种常用的权重初始化方法,旨在使神经网络的权重具有合适的初始值,有助于训练网络。它基于正态分布,有助于避免梯度消失或梯度爆炸问题。
nn.init.xavier_normal_(self.H.data)
self.weight_decay = weight_decay #权重衰减参数
def forward(self, u, i, j):
"""Return loss value.
Args:
u(torch.LongTensor): tensor stored user indexes. [batch_size,] 张量存储的用户索引
i(torch.LongTensor): tensor stored item indexes which is prefered by user. [batch_size,] 张量存储的项目索引,用户喜欢。
j(torch.LongTensor): tensor stored item indexes which is not prefered by user. [batch_size,] 张量存储的项目索引,用户不喜欢。
Returns:
torch.FloatTensor
"""
u = self.W[u, :]
i = self.H[i, :]
j = self.H[j, :]
x_ui = torch.mul(u, i).sum(dim=1)
x_uj = torch.mul(u, j).sum(dim=1)
x_uij = x_ui - x_uj
log_prob = F.logsigmoid(x_uij).sum() #用于计算对数似然损失的操作
regularization = self.weight_decay * (u.norm(dim=1).pow(2).sum() + i.norm(dim=1).pow(2).sum() + j.norm(dim=1).pow(2).sum())
#.pow(2):这是对 L2 范数的每个元素进行平方操作,得到每个用户的 L2 范数的平方。 可以使用LaTex输出
# 正则化项是模型参数的 L2 范数的平方和,乘以一个权重衰减参数 weight_decay。这有助于控制模型的复杂度,防止过度拟合训练数
return -log_prob + regularization
# 返回BPR-Opt 损失函数
def recommend(self, u):
# 预测得分
"""Return recommended item list given users. 返回给定用户的推荐项目列表
Args:
u(torch.LongTensor): tensor stored user indexes. 张量存储的用户索引。[batch_size,]
Returns:
pred(torch.LongTensor): recommended item list sorted by preference. 按偏好排序的推荐项目列表[batch_size, item_size]
"""
u = self.W[u, :]
x_ui = torch.mm(u, self.H.t())#计算了用户嵌入向量 u 与物品嵌入矩阵 self.H 的转置之间的乘积。 self.H.t(): 这部分是对物品嵌入矩阵 self.H 进行转置操作
pred = torch.argsort(x_ui, dim=1) #这是 PyTorch 的 torch.argsort 函数,它用于对矩阵 x_ui 的行进行排序
return pred #法返回了推荐的物品列表,这个列表是按照用户的喜好排序的,得分高的物品排在前面。
def precision_and_recall_k(user_emb, item_emb, train_user_list, test_user_list, klist, batch=512): #batch是用于批量处理计算的批次大小。 klist 是一个包含要计算精度和召回率的 K 值的列表。
"""Compute precision at k using GPU.
Args:
user_emb (torch.Tensor): embedding for user [user_num, dim] 为用户嵌入[user_num,dim]
item_emb (torch.Tensor): embedding for item [item_num, dim] 项[item_num,dim]的嵌入
train_user_list (list(set)):
test_user_list (list(set)):
k (list(int)):
Returns:
(torch.Tensor, torch.Tensor) Precision and recall at k k处的精度和召回
"""
# Calculate max k value
max_k = max(klist) #计算传入的 K 值列表 klist 中的最大 K 值。
# Compute all pair of training and test record 计算所有成对的训练和测试记录
result = None
for i in range(0, user_emb.shape[0], batch): #user_emb.shape[0] 表示用户嵌入矩阵的行数,即用户数量。 这个循环将用户分成多个批次进行处理,每个批次包含 batch 个用户。
# Create already observed mask
mask = user_emb.new_ones([min([batch, user_emb.shape[0]-i]), item_emb.shape[0]]) #user_emb.new_ones(...) 会创建一个与 user_emb 具有相同数据类型的张量,所有元素的值都设置为1。然后将已观察到的项目的位置标记为零,以便在计算推荐时排除这些项目。
#它取 batch 和剩余用户数量 user_emb.shape[0]-i 中的较小值。这是因为在最后一个批次中可能会有不足 batch 个用户需要处理。 item_emb.shape[0]:这部分表示物品嵌入矩阵的行数,即物品的数量。因此,掩码矩阵的列数与物品数量相同。
for j in range(batch):
if i+j >= user_emb.shape[0]: #用于检查是否已经处理完所有用户。i+j 表示当前用户的索引,如果大于等于用户嵌入矩阵的行数 user_emb.shape[0],则表示已经处理完所有用户,此时退出内部循环。
break
mask[j].scatter_(dim=0, index=torch.tensor(list(train_user_list[i+j])).cuda(), value=torch.tensor(0.0).cuda())
#scatter_ 是 PyTorch 中的张量操作,用于根据索引在张量中进行散布操作。在这里,它用于根据 train_user_list[i+j] 中的索引,将掩码的相应位置设置为零。
#value=torch.tensor(0.0).cuda() 表示要设置的值,这里将已观察到的项目的位置的值设置为零。
#dim=0 表示在张量的第一个维度(行)上进行散布操作,即在行方向上修改掩码
#有助于计算精度和召回率时正确评估推荐结果。
# Calculate prediction value
cur_result = torch.mm(user_emb[i:i+min(batch, user_emb.shape[0]-i), :], item_emb.t()) #这是一个矩阵乘法操作,用于计算用户嵌入矩阵 user_emb 中当前批次的用户与所有物品嵌入向量之间的得分或相似度。
#item_emb.t():这部分是物品嵌入矩阵 item_emb 的转置操作
#user_emb[i:i+min(batch, user_emb.shape[0]-i), :]:这部分是从用户嵌入矩阵 user_emb 中选择当前批次的用户子集。i 是当前批次的起始索引,min(batch, user_emb.shape[0]-i) 是当前批次中要处理的用户数量。这是为了确保不超过用户嵌入矩阵的行数。
cur_result = torch.sigmoid(cur_result) #对张量中的每个元素进行 sigmoid 函数的计算。
assert not torch.any(torch.isnan(cur_result)) #健壮性检查,以确保计算的推荐得分没有异常值 检查张量 cur_result 中是否存在 NaN(Not-a-Number)值
# Make zero for already observed item
cur_result = torch.mul(mask, cur_result) #通过这个操作,已观察到的项目的预测得分被清除,以确保它们不会出现在推荐列表中。这是为了在计算推荐时排除已经用户已经知道的物品,以便生成新的推荐列表。
#逐元素的张量乘法操作 对应位乘
_, cur_result = torch.topk(cur_result, k=max_k, dim=1) #更新 cur_result 变量,使其包含了每个批次中用户的推荐列表,其中每行代表一个用户,每行中的元素是物品的索引,表示用户的推荐结果
result = cur_result if result is None else torch.cat((result, cur_result), dim=0)
#如果 result 为 None,说明这是第一次合并推荐结果,因此将 cur_result 直接赋值给 result,这样 result 就包含了当前批次中的用户的推荐结果。
#如果 result 不为 None,说明已经有了部分推荐结果,这时使用 torch.cat 函数将当前批次的推荐结果 cur_result 与已有的 result 进行合并。torch.cat 函数会按指定的维度(这里是 dim=0,表示在行方向上合并)将两个张量连接起来,形成一个新的张量。
#result 将包含了所有用户的推荐列表
result = result.cpu() #result 从 GPU(图形处理单元)上移动到 CPU(中央处理单元)。具体来说,它将张量的存储位置从 GPU 内存移动到 CPU 内存。
# Sort indice and get test_pred_topk
precisions, recalls = [], []
for k in klist:
precision, recall = 0, 0
for i in range(user_emb.shape[0]):
test = set(test_user_list[i]) #set(test_user_list[i]) 将这个列表转换为一个集合(set),其中每个物品在集合中只会出现一次。这是因为集合是一种无重复元素的数据结构,适用于表示用户观察到的物品集合。
pred = set(result[i, :k].numpy().tolist())
#result[i, :k] 表示从 result 中获取用户 i(索引) 的推荐列表中的前 k 个物品
#因为set是python对象,通过将张量转换为 NumPy 数组,可以将其元素转换为 Python 整数。
#.tolist() 将 NumPy 数组转换为 Python 列表。这是为了将数组中的元素放入一个列表中,以便创建集合。
val = len(test & pred)
#test 是一个集合,其中包含了测试集中用户 i 观察到的物品。这是通过前面的代码 test = set(test_user_list[i]) 创建的。
#pred 是一个集合,其中包含了用户 i 的前 k 个推荐物品的索引或标识符。这是通过前面的代码 pred = set(result[i, :k].numpy().tolist()) 创建的。
#test & pred 表示集合的交集操作。这将计算两个集合之间的交集,即测试集中用户 i 观察到的物品与推荐列表中的物品的交集。
#len(test & pred) 返回交集的大小,即测试集中用户 i 实际观察到的物品中有多少个物品也出现在了推荐列表中。这个值表示用户 i 的推荐列表中有多少个物品是正确的(也就是推荐的物品用户实际喜欢或观察到的物品)。
precision += val / max([min([k, len(test)]), 1]) #如果一个用户在测试集中只观察到了少数物品,而模型为该用户生成的推荐列表长度 k 很大,可能会导致计算的分母非常大,从而影响了精确度的计算。这是因为精确度的计算中,分母应该反映用户实际观察到的物品的数量。 为了解决这个问题,我们使用 min([k, len(test)]) 来限制分母的最大值。这个表达式选择了 k 和用户实际观察到的物品数量 len(test) 中的较小值,以确保分母不会超过用户实际观察到的物品数量。这是为了使精确度的计算更合理和实际。
recall += val / max([len(test), 1]) #max([len(test), 1]) 用于确保分母不为零。它比较 len(test) 和 1,取其中的较大值。这是因为如果用户没有观察到任何物品(len(test) 为零),分母会变成零,这会导致除零错误。通过取较大值为 1,可以避免这种情况。
precisions.append(precision / user_emb.shape[0]) #user_emb.shape[0]表示用户数量,求得平均后,再追加到precisions
recalls.append(recall / user_emb.shape[0]) #同理
return precisions, recalls
def main(args):
# Initialize seed
np.random.seed(args.seed) #设置随机数生成器的种子,args.seed 是作为输入参数传递的种子值,它决定了随机数生成器的初始状态。
torch.manual_seed(args.seed) #于设置PyTorch库的随机数生成器的种子,其中 torch 是PyTorch库的别名。args.seed 是作为输入参数传递的种子值,它决定了PyTorch随机数生成器的初始状态。
#生成的随机数序列都是一致的,这有助于实验的可重复性和结果的一致性。
#如果你改变了种子值,生成的随机数序列将会改变,但在同一个种子值下,生成的随机数序列将保持一致。这对于比较不同模型的性能、调试代码以及确保实验结果一致性非常有用。
# Load preprocess data 加载预处理数据
with open(args.data, 'rb') as f: #文件的路径由 args.data 指定, 'rb' 表示以二进制只读模式打开文件。
dataset = pickle.load(f) #从指定的文件中加载数据,
user_size, item_size = dataset['user_size'], dataset['item_size'] #user_size 和 item_size:这两个变量分别存储了数据集中的用户数量和物品(或项目)数量。
train_user_list, test_user_list = dataset['train_user_list'], dataset['test_user_list'] #train_user_list 和 test_user_list:这两个变量分别存储了训练数据集和测试数据
train_pair = dataset['train_pair']#存储了训练数据集中的用户-物品对
print('Load complete')
# Create dataset, model, optimizer
dataset = TripletUniformPair(item_size, train_user_list, train_pair, True, args.n_epochs) #args.n_epochs: 这个参数是训练的时代数量(epochs)。通常情况下,训练模型时需要指定要执行多少个时代,每个时代都包含了对整个训练数据集的一次完整遍历
loader = DataLoader(dataset, batch_size=args.batch_size, num_workers=16) #num_workers: 这是一个整数参数,指定了数据加载过程中使用的工作进程数量,可以加速数据加载过程,特别是当数据集很大时。较大的值可以利用多核CPU来并行加载数据。
model = BPR(user_size, item_size, args.dim, args.weight_decay).cuda() #加上args就是自行指定
optimizer = optim.Adam(model.parameters(), lr=args.lr) #Adam 是一种常用的梯度下降优化算法,用于调整模型参数以最小化损失函数。 lr=learning rate,用于控制每次参数更新的步长大小。
#model.parameters(): 这个方法用于获取模型中所有需要优化的参数。
writer = SummaryWriter()
# Training
smooth_loss = 0
idx = 0
for u, i, j in loader:
optimizer.zero_grad() #在每个迭代开始时,用于清除优化器中之前计算的梯度信息
loss = model(u, i, j) #通过模型前向传播计算损失值
loss.backward() #通过反向传播计算损失函数相对于模型参数的梯度
optimizer.step() #使用计算得到的梯度来更新模型参数。这是梯度下降法的一次迭代步骤,它将模型朝着损失函数的最小值方向调整。 一种优化器
writer.add_scalar('train/loss', loss, idx) #将损失值(loss)写入 TensorBoard 的事件文件以进行记录和可视化的操作。 'train/loss' 是写入的标量数据的名称
#idx 是迭代的索引或步数。通常,迭代次数或步数会随着训练的进行而增加。将迭代步数作为 x 轴,损失值作为 y 轴,可以在 TensorBoard 上绘制损失曲线,以帮助您监视训练过程中损失的变化趋势。
smooth_loss = smooth_loss*0.99 + loss*0.01 # #过去损失*0.996 + 当前损失*0.01 实现损失值平滑更新
if idx % args.print_every == (args.print_every - 1):
print('loss: %.4f' % smooth_loss) #会把 smooth_loss 的值插入到 %4.f 的位置,并将其格式化为包含四位小数的浮点数,并生成一个类似 'loss: 0.1234' 的字符串,其中 0.1234 是 smooth_loss 的值。
if idx % args.eval_every == (args.eval_every - 1): #eval评估
plist, rlist = precision_and_recall_k(model.W.detach(),#.detach() 的作用是创建这些参数的副本,但不会计算梯度。
model.H.detach(),
train_user_list,
test_user_list,
klist=[1, 5, 10])#klist=[1, 5, 10]:这是一个包含了 [1, 5, 10] 的列表,表示要计算的不同的精确度和召回率的值。例如,k=1 表示计算精确度和召回率时只考虑前1个推荐物品,而 k=5 表示考虑前5个推荐物品。
print('P@1: %.4f, P@5: %.4f P@10: %.4f, R@1: %.4f, R@5: %.4f, R@10: %.4f' % (plist[0], plist[1], plist[2], rlist[0], rlist[1], rlist[2]))
writer.add_scalars('eval', {'P@1': plist[0],
'P@5': plist[1],
'P@10': plist[2]}, idx)#将模型的评估指标(P@1、P@5、P@10)记录到一个名为 'eval' 的日志中
writer.add_scalars('eval', {'R@1': rlist[0],
'R@5': rlist[1],
'R@10': rlist[2]}, idx)
if idx % args.save_every == (args.save_every - 1):
dirname = os.path.dirname(os.path.abspath(args.model)) #os.path.abspath(args.model)用于获取 args.model 的绝对路径。绝对路径是从文件系统的根目录开始的完整路径。
#dirname 变量会存储 args.model 文件的父目录的路径,而不包括文件名。这通常用于确保在保存模型或其他文件时,它们被存储在指定目录中而不是当前工作目录
os.makedirs(dirname, exist_ok=True)#这行代码的目的是创建一个目录,以便在该目录下存储模型或其他文件。
#exist_ok=True 是一个参数,用于确保如果目录已经存在,不会触发异常。
torch.save(model.state_dict(), args.model) #args.model: 这是保存模型的文件路径,通常包括文件名和文件扩展名。它是在脚本的命令行参数中指定的。
#model.state_dict(): 这是模型的方法,它返回一个包含了模型的所有参数的字典。状态字典包括了模型的权重和偏差等参数,是模型训练过程中的"状态快照"。
idx += 1
if __name__ == '__main__':
# Parse argument
parser = argparse.ArgumentParser()
parser.add_argument('--data',
type=str,
default=os.path.join('preprocessed', 'ml-1m.pickle'),
help="File path for data")
# Seed
parser.add_argument('--seed',
type=int,
default=0,
help="Seed (For reproducability)")
# Model
parser.add_argument('--dim',
type=int,
default=4,
help="Dimension for embedding")
# Optimizer
parser.add_argument('--lr',
type=float,
default=1e-3,
help="Learning rate")
parser.add_argument('--weight_decay',
type=float,
default=0.025,
help="Weight decay factor")
# Training
parser.add_argument('--n_epochs',
type=int,
default=500,
help="Number of epoch during training")
parser.add_argument('--batch_size',
type=int,
default=4096,
help="Batch size in one iteration")
parser.add_argument('--print_every',
type=int,
default=20,
help="Period for printing smoothing loss during training")
parser.add_argument('--eval_every',
type=int,
default=1000,
help="Period for evaluating precision and recall during training")
parser.add_argument('--save_every',
type=int,
default=10000,
help="Period for saving model during training")
parser.add_argument('--model',
type=str,
default=os.path.join('output', 'bpr.pt'),
help="File path for model")
args = parser.parse_args() #这行代码的作用是解析命令行参数,将用户在命令行中提供的参数值存储在一个名为 args 的对象中。
main(args) #main(args) 是一个函数调用,用于启动你的程序的主要功能
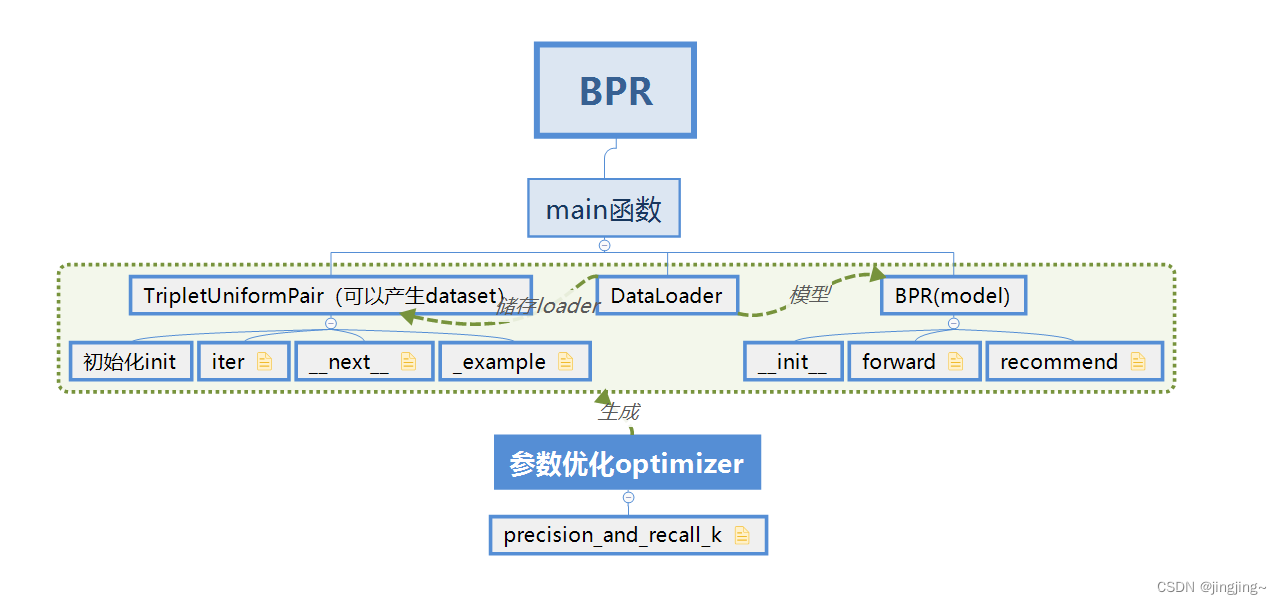
下图为BPR函数的流程图,为.xmind文件,资源可私信我。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











