







第一题
问题:如果不缺内存,如何使用一个具有库的语言来实现一种排序算法以表示和排序集合?
解答:c++语言可以调用STL中的set容器来进行排序
#include <iostream>
#include <set>
using namespace std;
int main(void)
{
set<int> S;
int i;
set<int>::iterator j;
while (cin >> i)
S.insert(i);
for (j = S.begin(); j != S.end(); ++j)
cout << *j << "\n";
return 0;
}8 7 3 5 ^Z
3
5
7
8
请按任意键继续. . .第二题
问题:如果使用位逻辑(例如与、或、移位)来实现位向量。
解答:思路就是一个int占了32位,所以对数据i进行左移位(5位)就可以算出放到int数组的哪一个元素里面去,然后取余数进行存储,这一部分可以用与或非来实现。
/***********************************************************/
// 程序目的:使用位逻辑(例如与、或、移位)来实现位向量
// 日期: 2014-8-31
// 作者: spencer_chong
/***********************************************************/
#include <stdio.h>
#define BITSPERWORD 32
#define SHIFT 5
#define MASK 0x1F
#define N 10000000
int a[1 + N/BITSPERWORD];//使用整型数组模拟定义1000万个位的数组
//i>>SHIFT指的是右移5位,也就是除以32,指的是该位存在于那个数组中
//i&MASK指的是i%32,剩下的数字为多少,1<<(i&MASK))表示1左移i&MASK位
void set(int i)
{
a[i>>SHIFT] |= (1<<(i & MASK)); return;
}
void clr(int i) // 初始化清零
{
a[i>>SHIFT] &= ~(1<<(i & MASK)); // 逐次将32为值清零
}
int test(int i) // 测试逻辑位置为n的二进制位是否为1
{
return a[i>>SHIFT] & (1<<(i & MASK));
}
int main()
{
int i;
for (i = 0; i < N; i++)
clr(i);
int arr[11] = {0, 34, 2, 3, 31,1,63, 4, 62, 33, 64};
for (i = 0; i < 11; i++)
set(arr[i]);
for (i = 0; i < N; i++)
{
if (test(i))
printf("%d ", i);
}
printf("\n");
return 0;
}
<pre name="code" class="cpp">0 1 2 3 4 31 33 34 62 63 64
请按任意键继续. . .第三题
问题:运行效率是设计目标的一个重要组成部分,所得到的程序需要足够高效。在你自己的系统上实现位图排序并度量其运行时间。该时间与系统排序的运行时间及习题1中排序的运行时间相比如何?假设n为10 000 000,且输入文件包含1 000 000个整数。
解答:这个是从网上找到的答案,结果和计算机本身有关,但是这个比例是基本可以保证的。
| System Sort | C++/STL | C/qsort | C/bitmaps | |
|---|---|---|---|---|
| Total Secs | 89 | 38 | 12.6 | 10.7 |
| Compute Secs | 79 | 28 | 2.4 | .5 |
| Megabytes | .8 | 70 | 4 | 1.25 |
第四题
如果认真考虑了习题3,你将会面对生成小于n且没有重复的k个整数的问题。最简单的方法就是使用前k个正整数。这个极端的数据集合将不会明显的改变位图方法的运行时间,但是可能会歪曲系统排序的运行时间。如何生成位于0至n-1之间k个不同的随机顺序的随机数?尽量使你的程序简短且高效。
/***********************************************************/
// 程序目的:产生0-N之间k个不同的随机数
// 日期: 2014-8-31
// 作者: spencer_chong
/***********************************************************/
#include <iostream>
#include <stdlib.h>
#include <time.h>
using namespace std;
int main ()
{
//输入范围N和输出个数K,建立动态数组;
int n;int k;
cout<<"Input the range N:"<<endl; cin>>n;
cout<<"Output number K:"<<endl; cin>>k;
cout<<"Result is :"<<endl;
int *randnum=new int[n];
//初始化数组每个元素为其索引
for (int i=0;i<n;i++)
{
randnum[i]=i;
}
//初始化种子点,rand()返回15位的数
srand((unsigned)time(NULL));
int temp=0;
int i,j;
for(i=0;i<k;i++)
{
j=i+rand()/double(RAND_MAX)*(n-i-1);
temp=randnum[i];
randnum[i]=randnum[j];
randnum[j]=temp;
cout<<randnum[i]<<endl;
}
delete[] randnum;
return 0;
}
Input the range N:
15
Output number K:
5
Result is :
4
13
5
9
8
请按任意键继续. . .第五题
问题:那个程序员说他又1MB的可用存储空间,但是我们概要描述的代码需要1.25MB的空间。他可用不费力气的索取到额外的空间。如果1MB空间是严格的边界,你会推荐如何处理呢?
答案:只需要把10^7分成两批,分别是0-4999999以及5000000-999999,然后分别利用位图数据结构的方法进行排序。这里其实是时间和空间的权衡,将花费更多的时间来达到减少空间的目的。
第六题
问题:如果那个程序员说的不是每个整数最多出现一次,而是每个整数最多出现10次,你又如何建议他呢?你的解决方案如何随着可用存储空间总量的变化而变化呢?
解答:如果是最多出现10次,因为2^3<10<2^4,所以需要用半个字节(4位)来表示,这样子存储空间可能又不够了。参考第五题,可以把空间向时间转换,空间少用k倍,时间多花k倍。
第七题
问题:[R.Weil]所勾画的程序有几个缺陷。首先,它假定所输入的整数不会重复出现。如果某一个整数出现多次,会发生什么情况呢?在那种情况下,如何可以对程序进行修改以调用错误函数?输入整数小于0、大于或等于n时会发生什么情况?如果不是数字,那怎么办?程序应该怎么处理这些情况?程序还可采用其他什么稳健的检测措施呢?请描述一下测试该程序的各种小数据集,包括对这些情况以及其他行为不规则情况的适当处理。
解答:
1、如果出现多次: 程序只会当作只出现过一次。 要判断这种情况,只需在set(i)之前,用test(i)判断就行了。test(i)就是用于判断位置n出的逻辑位是否为1用的,如果是1表示重复过了。
2、输入超过范围,会引起数组下标访问越界问题
3、如果不是数字:只要这个值不是[0,N)的范围的话,都有可能发生越界问题。
第八题
问题:当那个程序员解决该问题的时候,美国所有的免费电话的区号是800。现在免费电话的区号包括800、877和888,而且还在增多。如何在1MB空间内完成对所有这些免费电话的号码的排序?如何将免费电话号码存储在一个集合中,要求可以实现非常快速的查找以判定一个给定的免费电话号码是否可用或者已经存在?
解答:(个人认为)这道题空间是给定了,但是时间说要非常快速,所以这个标准有点难以拿捏。区号是3位,那么做一般化考虑的话,就可能有1000种可能了。按照的方法,那么1MB的空间就要分1000位给区号用了,速度比之前慢1000倍,这速度可能无法满足要求。如果免费区号比较少的话,那么就可以分少一些出来用,例如知道只有3种,那么就分三位出来就行了,速度自然可以提高。或者按照区号进行分组,分别算出来再合并结果。
第九题
问题:使用更多的空间来换取更少的运行时间存在一个问题:初始化空间本身需要消耗大量的时间。说明如何设计一种技术,在第一次访问向量的项时将其初始化为0。你的方案应该使用常量时间进行初始化和向量访问,使用的额外空间应正比于向量的大小。因为该方法通过进一步增加空间减少初始化的时间,所以仅在空间很廉价、时间很宝贵且向量很稀疏的情况下才考虑。
解答:(答案来自互联网)
这个以空间换时间的数据结构是很Amusing的。首先应考虑初始化数组导致的直接结果是什么? 就是第一次访问某个元素的时候,这个元素的值是初始化后的值。由此就想到了,我们提出的算法应该能够实现:当我们第一次访问某个元素的时候,这个元素的值是初始化后的值。这个实现的关键点是:如何判断是第一次访问,即如何判断数组中的元素是初始化过还是没有初始化过。思考如下几点:
1)当时我看这道题的时候第一个反应就是:再建立一个数组,然后第一次访问时候将已初始化元素的数组下标存储在里面,每次访问的时候查询这个数组,要是数组下标在里面,就说明这个数组下标的元素已经被初始化了。相信很多人都有同样的想法,但是如果这样做的话,虽然节省了初始化的时间,但是每次访问都要在存已访问元素下标的数组里进行线性搜索,这样的时间也是浪费不少,如何不用线性时间而用常数时间就能判断是否一个数组元素是否初始化过呢
2)然后我就又想到,还不如建立一个和需要访问数组等长的数组,在访问某个元素的时候先看这个数组,要是这个数组的对应元素标记为1则表示已经初始化过了,没有就把相应元素置为1。不过同样 ,这个等长的数组没有被初始化过,那么它里面存储的随机数有很大的概率就是1,这样很容易误判。
3)然后我看了习题答案后,恍然大悟。作者通过巧妙地利用from和to数组以及整数top保障了方法的可靠性。
分析:首先,我们应该对题目进行彻底分析---我们需要访问的是一个长度(假设为n)非常大的数组,一般而言对数组中某个元素访问前我们必须要进行初始化,但是当n值非常大而程序对time要求较严格时,对所有的数组元素都进行统一的初始化是不可取的。为了达到程序对time的要求,我们应该对需要访问的元素(它的个数相对于n来说很小)进行初始化。其次,对元素初始化的判断---为了提高判断的准确性,答案引入了两个数组from和to以及整数top,且对于元素data[i]已初始化的条件是from[i]<top && to[from[i]]==i。现在让我们来具体分析这些规则是如何被应用的:假设当我们第一次访问的数组元素下标为1时,先判断初始化条件(此时数组from和to都没有初始化,当然time也不允许让我们多管闲事),一般而言from[1]中的随机数是大于top(现在为0)的,但我们不能保证,于是我们加入了第二个判断条件--to[from[1]]==1,对于这个表达式我们两次取随机值且让后者等于1,这样的概率有但几乎为0!因此,data[1]未被初始化,于是执行from[1]=top; to[top]=1; data[1]=0; top++;这样做的目的就是保证以后再次访问data[1]时不需要再初始化(条件满足了直接读取即可)。最后,对于该方法的可靠性分析---让我们先来分析一下整数top的作用,不难发现,top记录了当前data中已初始化元素的个数,但主要是保证了from中已初始化的元素都小于top(通过from[i]=top; top++),这给我们的判断条件(from[i]<top)提供了一定的可靠性,当然再加上第二到保险(to[from[i]]==i)使得此方法可靠性值得信赖!
答案:借助于两个额外的n元向量from、to和一个整数top,我们就可以使用标识来初始化向量data[0....n-1]。如果元素data[i]已始化,那么from[i] < top并且 to[from[i]] =i.因此,from是一个简单的标识,to和top一起确保了from中不会被写入内存里的随机内容,变量top初始为0。下图中data的空白项未被始化:
from[i] =top;
to[top] = i;
data[i] = 0;
top ++; 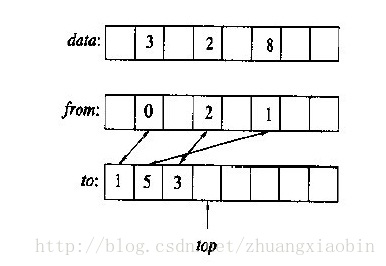
假如我现在要判断data[5]=8是否被初始化过,那么我先看to[from[5]]是否等于5,同理data[3]就判断to[from[3]]是否等于3就可以了。
第十题
问题:在成本低廉的隔日送达时代之前,商店允许顾客通过电话订购商品,并在几天后上门自取。商店数据库使用客户的电话号码作为其检索的主关键字(客户知道他们的电话号码,并且这些关键字几乎都是唯一的)。你如何组织商店的数据库,以允许高效的插入和检索操作?
解答:我们以电话号码最后两位作为散列索引, 那么其索引值就10 x 10大小数组中,如果有电话号码的后两位冲突,我们还是将他放到此数组中,这样效率会很高。在实际编程中对应的实现我们可以使用散列的链表解决法来解决上述碰撞冲突!















 4940
4940

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









