








 /**/
/*
/**/
/* 功能说明:分析字符串s,提取s里面的超链接和链接文字.并存入动态数组 同时根据指定包含和不包含的字符串进行过滤相关链接。 2008年3月30日
功能说明:分析字符串s,提取s里面的超链接和链接文字.并存入动态数组 同时根据指定包含和不包含的字符串进行过滤相关链接。 2008年3月30日  */
*/
 import
java.util.regex.Matcher;
import
java.util.regex.Pattern;
import
java.util.
*
;
public
class
RegTest
...
{ public static void main(String[] args)
import
java.util.regex.Matcher;
import
java.util.regex.Pattern;
import
java.util.
*
;
public
class
RegTest
...
{ public static void main(String[] args)
 ...{ //定义一个文章列表类。包含文章的网址和文章标题 class ArticleList ...{ String URLs; String title; public ArticleList()...{} public ArticleList(String t,String u) ...{ title=t; URLs=u;
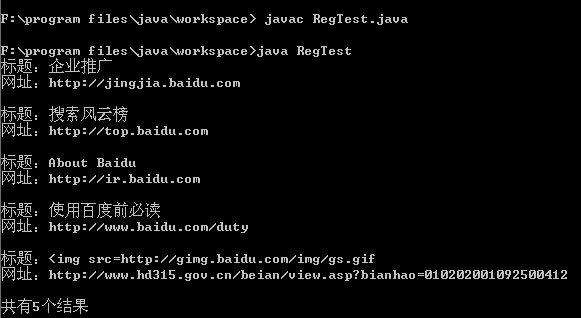
...{ //定义一个文章列表类。包含文章的网址和文章标题 class ArticleList ...{ String URLs; String title; public ArticleList()...{} public ArticleList(String t,String u) ...{ title=t; URLs=u;  } public String toString() ...{ return ("标题:"+title+" 网址:"+URLs+" "); } } ArrayList <ArticleList> al=new ArrayList<ArticleList>(); String s="</p><p style=height:14px><a href=http://jingjia.baidu.com>企业推广</a> | <a href=http://top.baidu.com>搜索风云榜</a> | <a href=/home.html>关于百度</a> | <a href=http://ir.baidu.com>About Baidu</a></p><p id=b>©2008 Baidu <a href=http://www.baidu.com/duty>使用百度前必读</a> <a href=http://www.miibeian.gov.cn target=_blank>京ICP证030173号</a> <a href=http://www.hd315.gov.cn/beian/view.asp?bianhao=010202001092500412><img src=http://gimg.baidu.com/img/gs.gif></a></p></center></body></html><!--543ff95f18f36b11-->"; String regex="<a.*?/a>"; Pattern pt=Pattern.compile(regex); //System.out.println(regex); Matcher mt=pt.matcher(s); String includeString=".*?baidu/.com.*?";//必须包含 字符串"baidu.com" while(mt.find()) ...{ if(mt.group().matches(includeString)) ...{ //System.out.println(mt.group()); String s2=">.*?</a>";//标题部分 String s3="href=.*?>"; Pattern pt2=Pattern.compile(s2); Matcher mt2=pt2.matcher(mt.group()); Pattern pt3=Pattern.compile(s3); Matcher mt3=pt3.matcher(mt.group()); while(mt2.find()&&mt3.find()) ...{ //System.out.println("标题:"+mt2.group().replaceAll(">|</a>","")); //System.out.println("网址:"+mt3.group().replaceAll("href=|>","")); String t=mt2.group().replaceAll(">|</a>",""); String u=mt3.group().replaceAll("href=|>",""); al.add(new ArticleList(t,u)); } } }//end while for(int i=0;i<al.size();i++) System.out.println(al.get(i)); System.out.println("共有"+al.size()+"个结果"); } }
} public String toString() ...{ return ("标题:"+title+" 网址:"+URLs+" "); } } ArrayList <ArticleList> al=new ArrayList<ArticleList>(); String s="</p><p style=height:14px><a href=http://jingjia.baidu.com>企业推广</a> | <a href=http://top.baidu.com>搜索风云榜</a> | <a href=/home.html>关于百度</a> | <a href=http://ir.baidu.com>About Baidu</a></p><p id=b>©2008 Baidu <a href=http://www.baidu.com/duty>使用百度前必读</a> <a href=http://www.miibeian.gov.cn target=_blank>京ICP证030173号</a> <a href=http://www.hd315.gov.cn/beian/view.asp?bianhao=010202001092500412><img src=http://gimg.baidu.com/img/gs.gif></a></p></center></body></html><!--543ff95f18f36b11-->"; String regex="<a.*?/a>"; Pattern pt=Pattern.compile(regex); //System.out.println(regex); Matcher mt=pt.matcher(s); String includeString=".*?baidu/.com.*?";//必须包含 字符串"baidu.com" while(mt.find()) ...{ if(mt.group().matches(includeString)) ...{ //System.out.println(mt.group()); String s2=">.*?</a>";//标题部分 String s3="href=.*?>"; Pattern pt2=Pattern.compile(s2); Matcher mt2=pt2.matcher(mt.group()); Pattern pt3=Pattern.compile(s3); Matcher mt3=pt3.matcher(mt.group()); while(mt2.find()&&mt3.find()) ...{ //System.out.println("标题:"+mt2.group().replaceAll(">|</a>","")); //System.out.println("网址:"+mt3.group().replaceAll("href=|>","")); String t=mt2.group().replaceAll(">|</a>",""); String u=mt3.group().replaceAll("href=|>",""); al.add(new ArticleList(t,u)); } } }//end while for(int i=0;i<al.size();i++) System.out.println(al.get(i)); System.out.println("共有"+al.size()+"个结果"); } }
输出为:















 1942
1942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









