







context阶段和generation阶段的不同
context阶段(又称 Encoder)主要对输入编码,产生 CacheKV(CacheKV 实际上记录的是 Transformer 中 Attention 模块中 Key 和 Value 的值),在计算完 logits 之后会接一个Sampling 采样模块,采样出来第一个生成的 token,并将这个 token 和 CacheKV 作为 generation阶段的输入,
generation阶段(又称 Decoder)在一个 While 循环里,读取 token 和 CacheKV 后通过自回归解码的方式每循环一次产生一个 token。generation阶段,自己的输出作为自己的输入,不断回归迭代,就是「自回归」。在 While 处判断需要继续生成,在 Attention 中计算出token对应的 CacheKV 信息存储下来,并拼接上所有的历史 CacheKV 信息进行计算,最后采样出来下一个 token。While 循环检测到「eos」生成结束,就会退出循环,本次生成推理过程结束。
在 DecoderSelfAttention 中,查询的序列长度始终为 1,因此使用自定义的 fused masked multi-head attention kernel 来处理。 另一方面,ContextSelfAttention 中查询的序列长度是最大输入长度,因此我们使用 cuBLAS 来利用tensor core。
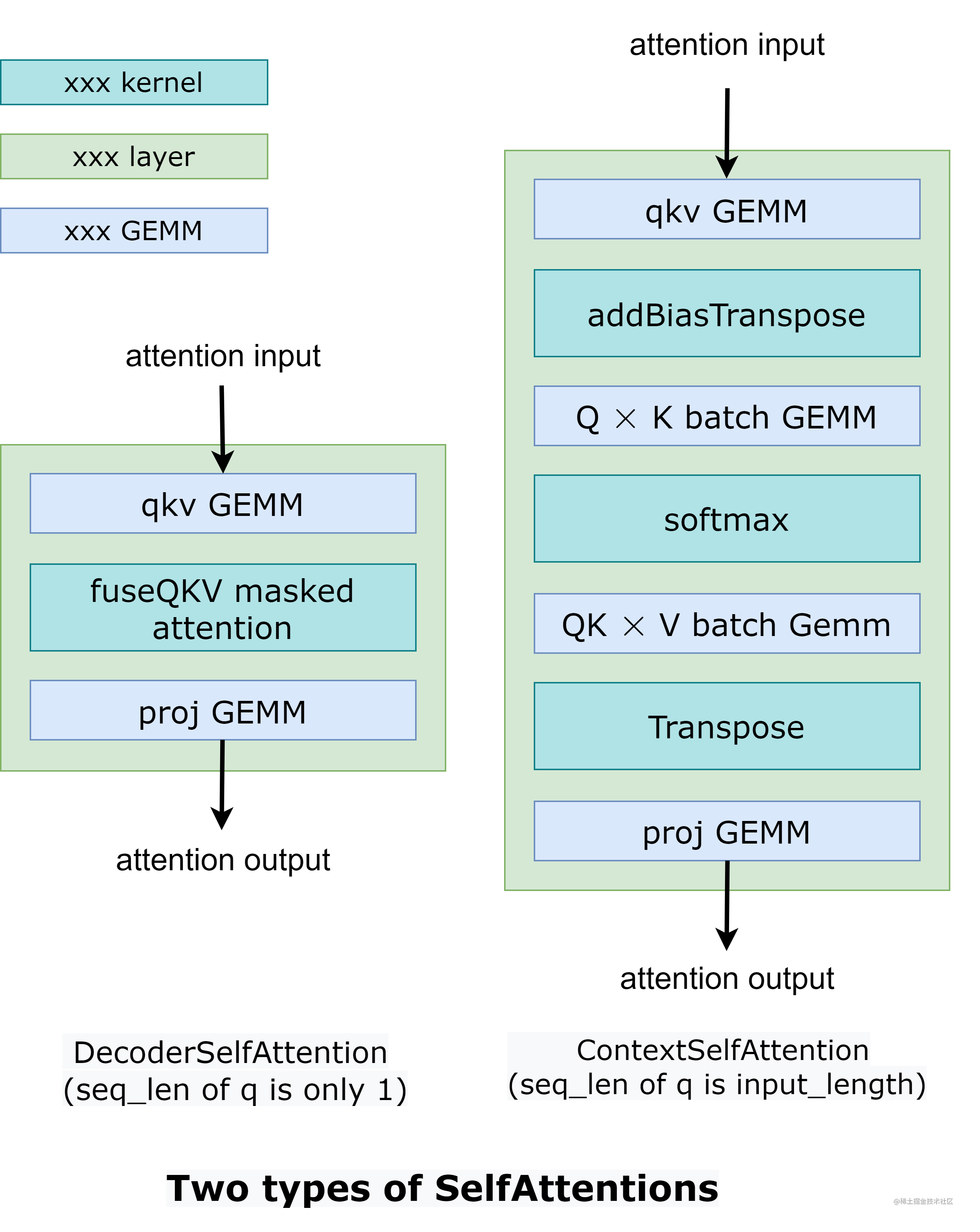
context阶段sequence length等于input_length(并行,可以类比训练的前向过程causal attention),generation阶段sequence length等于1(一个token一个token循环进行decoder)。
以 175B 的 GPT-3 模型,输入 1000 个 token,生成 250 个 token 为例,那么 Context 阶段的激活 Shape 为 [B, 1000, 12288],其中 B 为 batch_size,第二维为输入 token 数,第三位为 hidden size。而对于 Generation 阶段,由于每次输入输出都是固定的 1 个 token,是通过循环多次来产生多个输出 token,所以 Generation 阶段的激活 Shape [B, 1, 12288]的第二维始终为 1,Generation 的激活显存占用是远小于 Context 阶段的。
再来看计算量,这里可以看到挺多有趣的结论:
---Context/Generation 的计算量均随 batch size 增大而正比增大,这个很好理解,因为 batch 内每个样本的计算量是一致的;
---Context/Generation 的访存量随 batch size 增大却基本不变,访存量可以分为权重访存和激活访存,很显然激活的访存是随 batch size 增大而增大的,但是权重访存却不会随 batch size 变化而变化,而由于激活的访存量远小于权重的访存量,就会出现总访存量几乎不随 batch size 变化而变化;
Context 是计算密集型的任务,compute bound;而 Generation 是访存密集型的任务,IO bound(显存带宽指的是 GPU 计算单元与显存之间的数据传输速度)。这是由于 Context 的计算量大, Generation 由于每次都只计算 1 个 token,所以计算量远小于 Context;但是两个阶段权重的访存量确实一致的,因为Generation 要循环调用,所以 Generation 阶段反而是访存密集型的任务。
量化的优缺点
量化通过使用较少的比特数来表示模型参数,从而减小模型的内存占用。此外,由于整数乘法要快于浮点数乘法,量化通常可以提高推理速度。然而,量化运算的一个缺点是会引入误差,随着模型参数量的增加,误差累积会变得更加明显。
大模型的参数量和显存占用估算
现在业界的大语言模型都是基于transformer模型的,模型结构主要有两大类:encoder-decoder(代表模型是T5)和decoder-only,具体的,decoder-only结构又可以分为Causal LM(代表模型是GPT系列)和Prefix LM(代表模型是GLM)。针对decoder-only框架,估算其参数量和显存占用。
参数量约为,其中l指transformer层数,h指隐藏层维度。
训练显存占用约为20*参数量,单位B。20=2+4+2+4+4+4,前两个数字是权重,接着两个是梯度,最后两个是优化器状态大小。每个可训练模型参数都会对应1个梯度,并对应2个优化器状态。在混合精度训练中,会使用float16的模型参数进行前向传递和后向传递,计算得到float16的梯度;在优化器更新模型参数时,会使用float32的优化器状态、float32的梯度、float32的模型参数来更新模型参数。
推理显存占用约为2*参数量,单位B。如果使用KV cache来加速推理过程,KV cache也需要占用显存,约为,b是batch,l是transformer层数,h指隐藏层维度,s是输入序列长度,n是输出序列长度,4=2*2,k和v的cache,每个cache fp16存储,占用2B。
计算量FLOPs约为
计算量和参数量的关系,近似认为,在一次前向传递中,对于每个token,每个模型参数,需要进行2次浮点数运算,即一次乘法法运算和一次加法运算。一次训练迭代包含了前向传递和后向传递,后向传递的计算量是前向传递的2倍。因此,一次训练迭代中,对于每个token,每个模型参数,需要进行6次浮点数运算。
训练时间估计参考下面的公式,8是因为激活重计算技术来减少中间激活显存需要进行一次额外的前向传递,即4*2次浮点数运算。

中间激活的显存占用大小约为,其中b是batch,s是序列长度,a是注意力头数,l是transformer层数,h指隐藏层维度。在训练过程中中,模型参数(或梯度)占用的显存大小只与模型参数量和参数数据类型有关,与输入数据的大小是没有关系的。优化器状态占用的显存大小也是一样,与优化器类型有关,与模型参数量有关,但与输入数据的大小无关。而中间激活值与输入数据的大小(批次大小 和序列长度是成正相关的,随着批次大小和序列长度的增大,中间激活占用的显存会同步增大。
参考资料:分析transformer模型的参数量、计算量、中间激活、KV cache
MBU和MFU
MBU(模型带宽利用率) = 实际内存带宽 / 峰值内存带宽,其中实际内存带宽为(模型参数大小+KV缓存大小) / 每token生成时延。如70亿参数的16位精度的模型(大小为14GB),每token时延为14ms,则实际内存带宽为1TB/s,如果峰值内存带宽为2TB/s,则MBU=50%。
MFU(模型FLOPs利用率)是实际计算量/理论算力。
两者的关系见下图。红色区域表示batch很小时主要是带宽瓶颈,橙色区域表示batch很大时主要是计算瓶颈。现实情况下,对于小batch(红色区域白点),观察到的性能低于最大吞吐量,降低程度可通过MBU来度量。对于大batch(黄色区域白点),系统受计算限制,实际所占的吞吐量以MFU衡量。
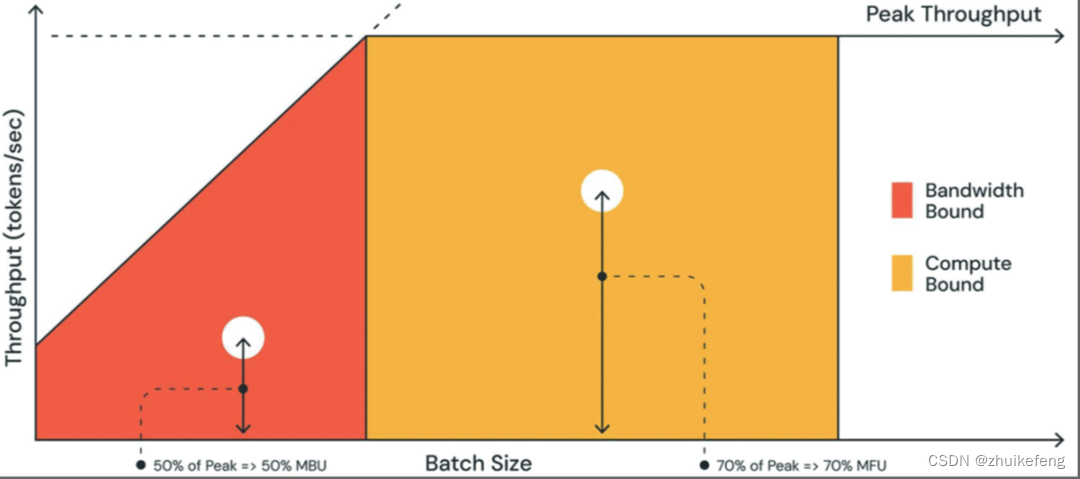
参考资料:A guide to LLM inference and performance
知名产品
LLM
GPT4:OpenAI
Claude:Anthropic
文生图
DALL·E:OpenAI
Midjourney:Midjourney
Stable Diffusion:Stability AI
Imagen:Google
Gemini:Google
eDiff-I:Nvidia
文生视频
Sora:OpenAI
Gen-2:Runway
Pika:Pika Labs
Dream Machine:Luma
大模型推理实例
Qwen1.5-72B
#网址 https://huggingface.co/Qwen/Qwen1.5-72B-Chat
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen1.5-72B-Chat",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen1.5-72B-Chat")
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template( #此命令需要在较新transformers版本上支持,如4.37.0
messages, #此版本的信息可以在Qwen1.5-72B-Chat/config.json的transformers_version字段看到
tokenize=False,
add_generation_prompt=True
)
#拼好的prompt像下面这样,实际就是问了“what is your name?”
#<|im_start|>system
#You are a helpful assistant.<|im_end|>
#<|im_start|>user
#what is your name?<|im_end|>
#<|im_start|>assistant
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
参数repetition_penalty,presence_penalty和frequency_penalty的区别
Repetition Penalty
- 也称为“重复惩罚”或“重复项惩罚”。
- 它主要针对连续生成序列中相同词汇或短语的重复现象。
- 当模型在生成下一个词时,如果这个词与前几个生成的词完全相同,重复惩罚就会增加生成该词的负log概率,也就是说,模型在决定生成下一个词时会因为这个惩罚而更少选择最近刚刚生成过的词。
- 取值范围通常是一个大于等于1的浮点数,通常默认设置为1(无惩罚),当需要抑制重复时会设置为大于1的值。
- 值越大,模型在生成下一个词时,如果该词之前不久已经出现过,那么它的生成概率会被进一步降低,从而更倾向于生成不同的词汇,减少连续重复的现象。
Presence Penalty
- 这个参数同样用于惩罚模型在生成文本时对已出现过的任意位置词汇的偏好。
- 不仅限于连续重复,而是对整个生成序列中已出现过的任何词汇或信息都会产生影响。
- 如果设置了 presence_penalty > 0,对于那些在整个生成文本中已经出现过的词,不论它们是否连续出现,模型都会在计算其生成概率时施加一个额外的惩罚因子。
- 取值范围也是通常为一个大于等于0的浮点数,且默认情况下可能设置为0(不惩罚)
- 当
presence_penalty被设置为一个大于0的值时,模型会在计算整个序列中每个词的生成概率时考虑它已经出现过的次数,并对其施加一个额外的惩罚。 - 值越大,模型对已经在输出序列中出现过的任何一个词的再次生成都会更加谨慎,这有助于整体上减少重复内容和过度依赖某些特定词汇的现象。
Frequency_Penalty:
- 作用:类似于
repetition_penalty,但关注的是整个词汇表中某个词汇的全局出现频率。当frequency_penalty > 0时,高频词汇在生成文本时会被系统性地降权,有助于增加生成文本的多样性,避免过度依赖常用的高频词汇。 - 实现:在生成过程中,可能会统计词汇在整个训练数据集或者前缀文本中的出现次数,并对概率分布进行调整,使得高频词汇生成的可能性降低。
- 当
frequency_penalty = 0时,不对词汇的出现频率进行任何惩罚。 - 当
frequency_penalty > 0时,模型会减少高频词汇被选中的概率,促进文本多样性和新颖性。值越大,对高频词的抑制越强。
top_k, top_p, top_k_top_p和 beam_search的区别
top_k, top_p, top_k_top_p, 和 beam_search是自然语言处理中的几种不同的解码策略,它们都应用于基于概率分布生成文本的场景,尤其是对于自回归式的语言模型。下面是每种策略的基本原理和区别:
1. Top-K Sampling (top_k):
在每次生成一个新词时,模型会预测下一个词的概率分布,然后只保留概率最高的K个词汇,并重新归一化这些词的概率分布,最后从这K个词中随机选择一个作为下一个生成的词。这种方法有助于避免生成过于罕见的词汇,但可能会导致文本多样性受限。
2. Nucleus Sampling (top_p):
类似于Top-K,但在这种情况下,不是选取固定数量的最高概率词汇,而是保留累积概率大于给定阈值P的所有词汇,这样可以包容一些低频但重要的词汇。这种方法通常允许更多的多样性,因为它不强制限定候选词的数量。
3. Top-K Top-P Sampling (top_k_top_p):
结合了Top-K和Top-P的特点,在每次生成时先按照累积概率排序,然后选择那些累积概率之和达到阈值P内的前K个词汇进行采样。这种方式既保证了一定的多样性,又能控制生成词汇的稀有程度。
4. Beam Search (beam_search):
这是一种基于搜索树的策略,它维护一组(beam宽度所确定的)最有希望的候选序列,每个时间步都会扩展每个序列的一个后代,并保留总得分(通常是概率乘积)最高的beam宽度个序列继续向前生成。相比于纯粹的随机采样,Beam Search倾向于产生更高概率的文本,但可能会牺牲一定的创造性,因为其倾向于保守的选择。
总结来说,top_k 和 top_p 更侧重于探索生成的多样性,而 beam_search 则是为了找到全局最优(或近似最优)的序列。top_k_top_p试图平衡多样性与生成质量。在实践中,beam_search 适用于需要高质量、连贯性强的文本生成场景,而 top_k 或 top_p 等采样策略更适合于追求新颖性和创造性的应用场合。使用哪种策略取决于具体的应用需求以及计算资源的限制。
PCIe 带宽、内存带宽、NVLink 带宽、HBM 带宽、网络带宽
在大规模GPU训练场景中,数据传输速度是决定训练效率的关键因素之一。下面分别解释您提到的几种带宽的作用:
-
PCIe(Peripheral Component Interconnect Express)带宽: PCIe是一种常见的高速接口标准,用于连接计算机系统中的外部设备,如GPU、硬盘等,到CPU和主内存。在GPU训练中,PCIe带宽决定了GPU与系统内存之间数据交换的速度。更高的PCIe带宽可以更快地传输数据,减少数据传输等待时间,从而提升训练效率。例如,PCIe 4.0提供了每通道大约16 GT/s(Gen4)的传输速率,而在PCIe 5.0中,这一速率提升到了约32 GT/s。
-
内存带宽: 这通常指的是系统的DRAM(Dynamic Random Access Memory)主内存带宽,它影响着CPU访问数据的速度。在深度学习训练过程中,内存带宽决定了数据从内存载入CPU或GPU的速度,以及中间结果从GPU回写到内存的速度。更高的内存带宽可以减少数据传输瓶颈,提升整体计算效率。
-
NVLink带宽: NVLink是NVIDIA推出的一种高速互连技术,专为GPU间直接通信设计,提供比PCIe更高的带宽。它允许GPU之间直接交换数据,无需绕经CPU和系统内存,从而大大加快了多GPU并行计算和模型同步的速度。例如,最新一代的NVLink-C2C技术能够提供高达900GB/s的连接带宽,这对于大规模分布式训练特别有利。
-
HBM(High Bandwidth Memory)带宽: HBM是一种高性能的存储技术,通常直接集成在高性能GPU或其他计算密集型芯片上,作为高速缓存或显存使用。HBM通过堆叠内存芯片并在硅中介层上使用微凸点互联,极大提高了数据传输速率,降低了功耗。HBM带宽极高,比如可达921GB/s,它减少了GPU等待数据的时间,提升了训练和计算的效率。
-
网络带宽: 在分布式训练场景中,网络带宽指的是连接不同计算节点(可能包含多个GPU)的网络通信能力。高效的网络架构(如InfiniBand或以太网)和足够的带宽对于确保节点间数据的快速传输至关重要。这直接影响到模型参数的同步速度和整体训练时长,尤其是在涉及大量数据交换的深度学习模型训练中。
PCIe带宽: PCIe(Peripheral Component Interconnect Express)带宽主要衡量的是GPU与主板上的CPU以及系统内存之间的外部互连速度。当数据需要在GPU和系统内存之间移动时(比如,将训练数据从内存加载到GPU,或者将GPU处理的结果保存回内存),这个过程会通过PCIe总线进行。因此,PCIe带宽决定了这一数据传输通道的最大容量。如果GPU需要频繁地与系统内存交换大量数据,而PCIe带宽较低,可能会成为性能瓶颈,导致数据传输等待时间增加。
内存带宽: 内存带宽,特别是指系统DRAM(Dynamic Random Access Memory)的带宽,关注的是CPU直接从内存读取或写入数据的能力。当CPU执行指令需要读取数据或存储计算结果时,内存带宽的大小直接影响到这些操作的速度。在深度学习训练中,虽然大部分数据交换可能发生在GPU和内存之间(通过PCIe),但CPU也需要高效地处理控制逻辑、数据预处理以及某些情况下与内存交互的任务。因此,内存带宽对于确保CPU能够高效地执行其任务同样重要。
简而言之,PCIe带宽专注于GPU与系统内存之间的数据传输效率,而内存带宽则更多关乎于CPU访问内存数据的速度。两者都是影响整个系统数据处理能力的关键因素,尤其在涉及GPU加速的复杂计算任务中。在理想情况下,为了达到最佳性能,这两者都应该足够高,以避免成为系统性能的瓶颈。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









