






 一、什么是网络爬虫
一、什么是网络爬虫
即爬取网络数据的虫子,也就是Python程序。
二、爬虫的实质是什么?
模拟浏览器的工作原理,向服务器发送请求数据。
三、浏览器的工作原理是什么?
浏览器还可以起到翻译数据的作用。

四、爬虫工作原理
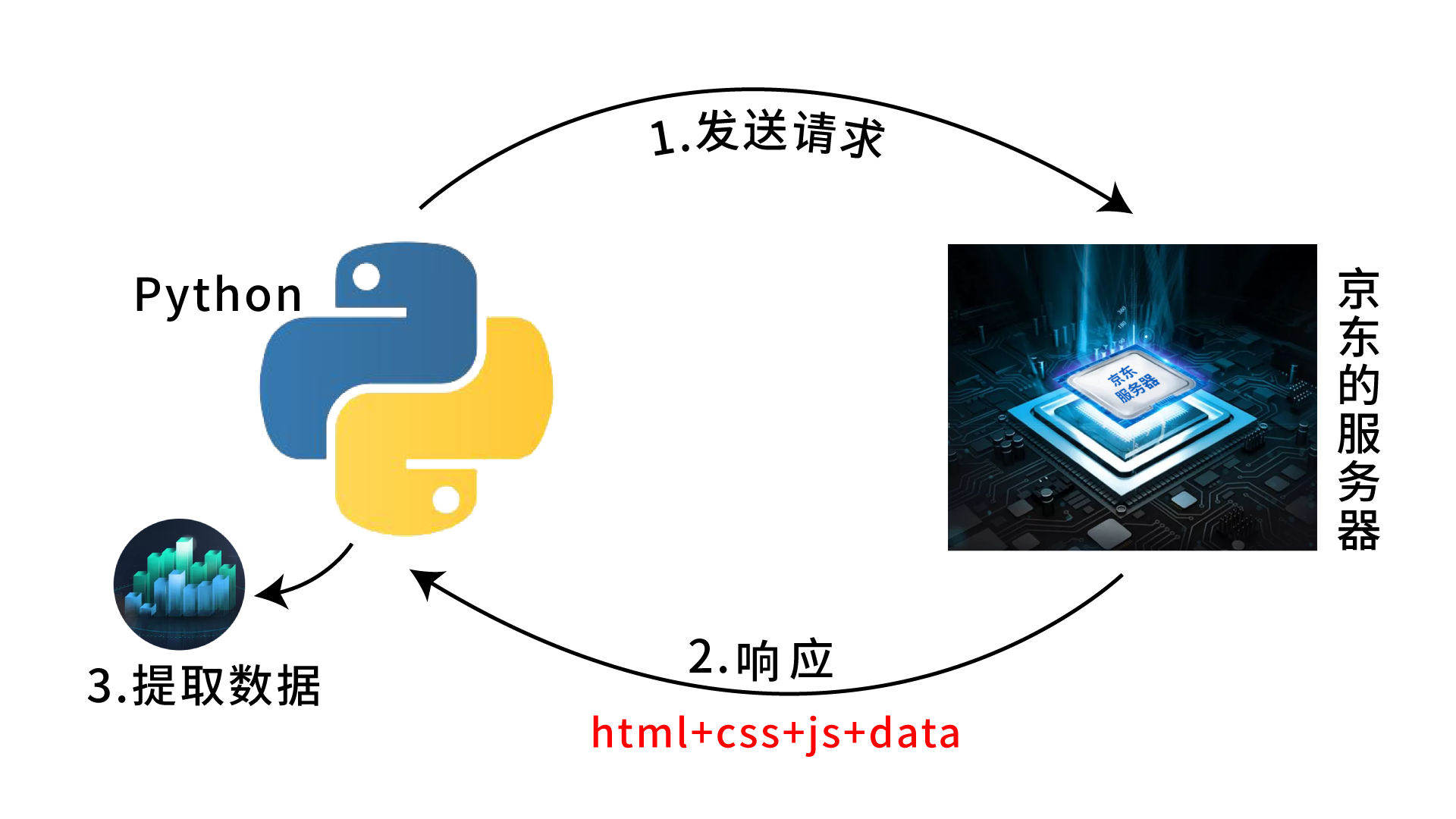
五、实操-----爬取商品的销售数据
1、数据背后的秘密
找不到商品的销售数据怎么办------可以通过评论数据间接获得销售数据。
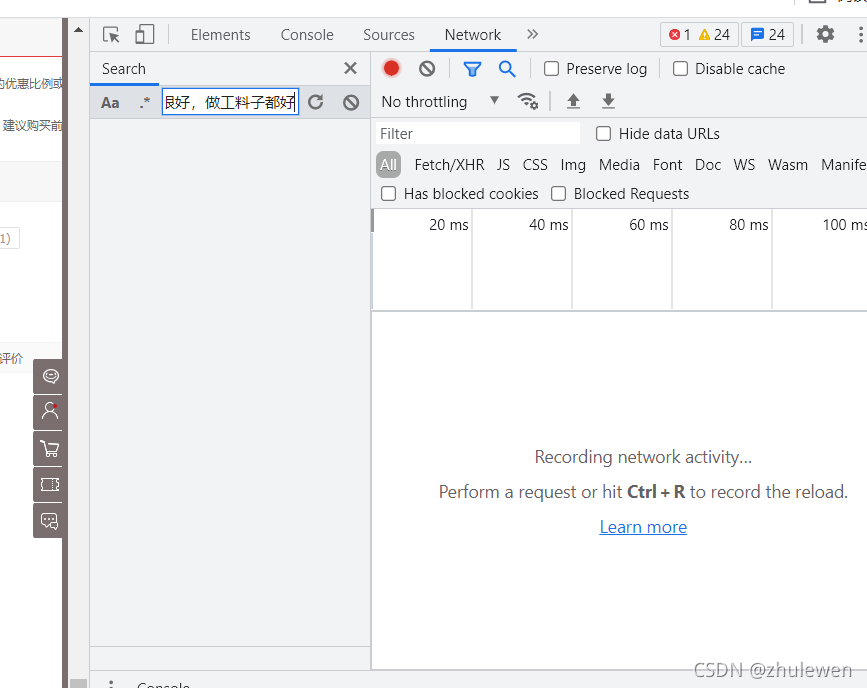
2、如何找到评论区背后的URL
a、鼠标右击选择检查,打开程序员调试窗口,选择Network
b、刷新当前页面,复制评论区内容,进入程序员调试窗口search,点击粘贴,点击刷新小圆圈🔄查找
c、点击查询结果的第二行,跳转到对应的请求
d、点击Headers,找到Request URL即评论区数据背后的URL
3、三行代码爬取京东数据
梳理代码流程:
- (1)引入Python工具包requests
- (2)使用工具包中的get方法,向服务器发起请求
- (3)打印输出请求回来的数据(print语法)
import requests
resp=requests.get('https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=10335871588&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1')
print(resp.text)程序运行结果:
7709789,"imageCount":8,"anonymousFlag":0,"plusAvailable":103,"mobileVersion":"8.1.2","images":[{"id":898430983,"imgUrl":"//img30.360buyimg.com/n0/s128x96_jfs/t1/73453/23/5402/183289/5d37b2f1E7d719d68/ae916b1ccade5c81.jpg","imgTitle":"","status":0},{"id":898430984,"imgUrl":"//img30.360buyimg.com/n0/s128x96_jfs/t1/63761/23/5296/274313/5d37b2f1Ee9d83ef4/87c8439ac27d1e9a.jpg","imgTitle":"","status":0},{"id":898430985,"imgUrl":"//img30.360buyimg.com/n0/s128x96_jfs/t1/57506/13/5995/190423/5d37b2f1E2e1b71ea/7adb9bc598ba3a75.jpg","imgTitle":"","status":0},{"id":898430986,"imgUrl":"//img30.360buyimg.com/n0/s128x96_jfs/t1/64197/24/5319/214532/5d37b2f1Ece94ba28/1736543f3dc2a3c2.jpg","imgTitle":"","status":0},{"id":898430987,"imgUrl":"//img30.360buyimg.com/n0/s128x96_jfs/t1/65166/40/5238/265145/5d37b2f1E7b9a2f73/25d0160b8ae53e99.jpg","imgTitle":"","status":0},{"id":898430988,"imgUrl":"//img30.360buyimg.com/n0/s128x96_jfs/t1/46440/20/5884/195354/5d37b2f1E6cc71270/d833e86142831041.jpg","imgTitle":"","status":0},{"id":898430989,"imgUrl":"//img30.360buyimg.com/n0/s128x96_jfs/t1/78051/28/5296/157233/5d37b2f1E5d08092a/e7c240d31399c1ee.jpg","imgTitle":"","status":0},{"id":898430990,"imgUrl":"//img30.360buyimg.com/n0/s128x96_jfs/t1/66794/25/5199/146718/5d37b2f1E69c25c61/dbc0681c475caaea.jpg","imgTitle":"","status":0}],"videos":[{"id":898430991,"mainUrl":"https://img.300hu.com/4c1f7a6atransbjngwcloud1oss/2b708372206340310602141697/imageSampleSnapshot/1609987936_712557345.100_977.jpg","videoHeight":1280,"videoWidth":720,"videoLength":9,"videoTitle":"","videoUrl":104790708,"videoId":104790708,"status":0,"remark":"https://vod.300hu.com/4c1f7a6atransbjngwcloud1oss/2b708372206340310602141697/v.f30.mp4?source=1&h265=v.f1022_h265.mp4"}],"mergeOrderStatus":0,"productColor":"-5黑【店长推荐】","productSize":"39","textIntegral":20,"imageIntegral":20,"status":1,"referenceId":"43139143228","referenceTime":"2019-07-15 19:14:07","nickname":"沐***晨","replyCount2":26,"userImage":"storage.360buyimg.com/i.imageUpload/6a645f3662386266313436343334643531363239323531393630383036_sma.jpg","orderId":0,"integral":40,"productSales":"[]","referenceImage":"jfs/t1/198738/32/8948/268079/61457f03E3c6d8bdf/30aaa28610042488.jpg","referenceName":"安踏男鞋休闲运动鞋男士2021秋季耐磨防滑轻便板鞋慢跑步鞋子户外训练旅游 -10黑/大学红/安踏白 42","firstCategory":1318,"secondCategory":12099,"thirdCategory":9756,"aesPin":"CqZhh9LMjN8X3zBCRgzYfj5WVG2Mk7oUESnYlurCllHlZbANssrlW6wt3sZETh9w36unsNE3jcqP9f2YljaOdQ","days":9,"afterDays":0},


















 3440
3440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











