







前言
当一个代码的工匠回首往事时,不因虚度年华而悔恨,也不因碌碌无为而羞愧,这样,当他老的时候,可以很自豪告诉世人,我曾经将代码注入生命去打造互联网的浪潮之巅,那是个很疯狂的时代,我在一波波的浪潮上留下了或重如泰山或轻如鸿毛的几笔。就比如,我今天就爬取了上百套妹子图,以此发文纪念一下!!
配置
引入爬虫工具类:
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.14.2</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>4.6.10</version>
</dependency>步骤
定义线程池,当然是为了充分利用机器配置
获取本栏目所有妹子套图节点
获取套图地址
获取套图标题用于创建目录
获取套图图片数量
下载妹子套图
代码示例:
/**
* 多线程获取妹子套图
* 关注:https://blog.52itstyle.vip
* 作者:小柒2012
*/
public class ImagesUtil {
/**
* 获取CPU个数
*/
private static int corePoolSize = Runtime.getRuntime().availableProcessors();
/**
* 创建线程池 调整队列数 拒绝服务
*/
private static ThreadPoolExecutor executor = new ThreadPoolExecutor(corePoolSize, corePoolSize+1, 10l, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(1000));
public static void main(String[] args) throws IOException {
System.out.println("系统CPU核数:"+corePoolSize);
/**
* 正则 匹配页码
*/
String regEx="[^0-9]";
Pattern p = Pattern.compile(regEx);
String baseUrl = "https://www.tupianzj.com";
Connection connect = Jsoup.connect(baseUrl+"/meinv/mm/meizitu/");
Document document = connect.get();
/**
* 获取本栏目所有妹子套图节点
*/
Elements elements = document.body().getElementsByClass("d1").select("li");
for (Element img : elements) {
Runnable task = () -> {
try {
/**
* 获取套图地址
*/
String href = img.child(0).attr("href");
Connection subConnect = Jsoup.connect(baseUrl+href)
. header("User-Agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:49.0) Gecko/20100101 Firefox/49.0")
.timeout(8000);
Document subDocument = subConnect.get();
/**
* 获取套图标题用于创建目录
*/
String title = subDocument.body().getElementsByTag("h1").eq(1).html();
System.out.println("开始下载:"+title);
/**
* 获取套图图片数量
*/
String txt = subDocument.body().getElementsByClass("pages").select("li").eq(0).html();
Matcher m = p.matcher(txt);
if(StringUtils.isNoneBlank(m.replaceAll("").trim())){
Integer pageNo = Integer.parseInt(m.replaceAll("").trim());
for (int i=0;i<pageNo;i++){
String url = baseUrl+href;
if(i!=0){
int page = i+1;
url = url.replace(".html","_"+page+".html");
}
subConnect = Jsoup.connect(url);
subDocument = subConnect.get();
String src = subDocument.getElementById("bigpicimg").attr("src");
/**
* 下载妹子
*/
HttpUtil.downloadFile(src, FileUtil.mkdir("e:/妹子图/"+title+"/"));
}
}
} catch (IOException e) {
e.printStackTrace();
}
};
executor.execute(task);
}
}
}预览
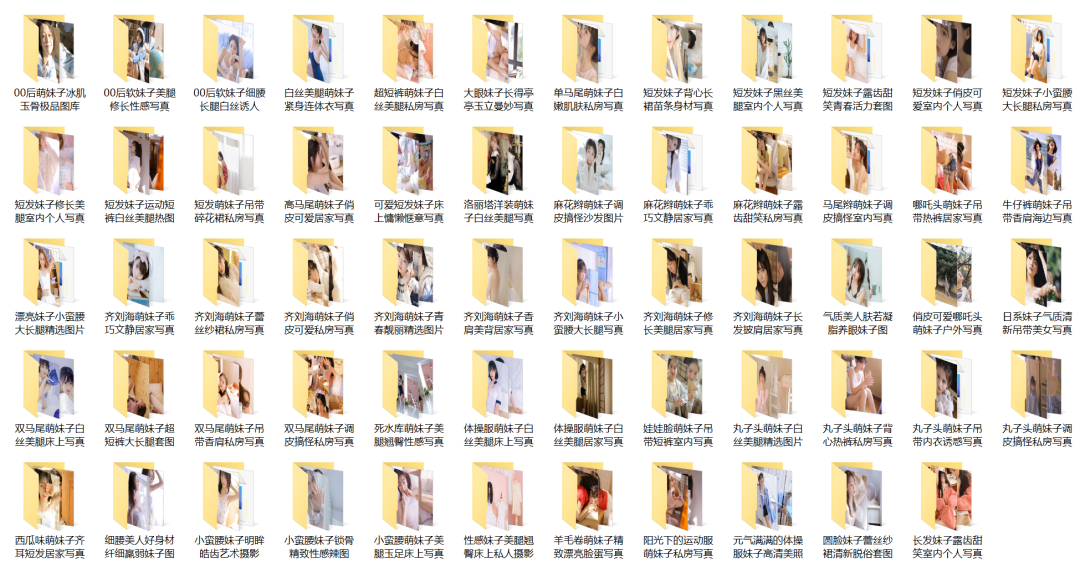
推荐一个Python爬取妹子的仓库:
https://gitee.com/52itstyle/Python
















 351
351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









