







导语
在机器学习入门的过程中,我们经常见到在导入数据时,常常出现的一步操作叫做数据归一化(normalization),一开始我并不知道它的作用,甚至发现有些时候去掉数据归一化的步骤,代码一样可以运行,机器学习的结果甚至也是正确的,所以去调查了一番,什么是数据归一化,又到底是做什么的。
一、为什么要进行数据归一化
我们先观察下面的两个图像。
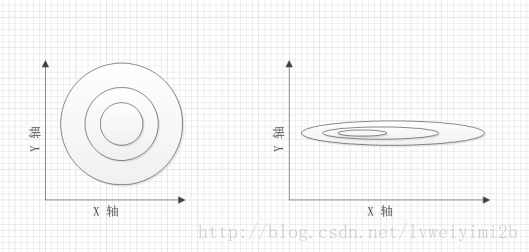
要找到他们的梯度方向。如下图所示
很显然是左侧的图像更容易去找,换作是机器学习之中,这一组数据更利于你的程序快速收敛。
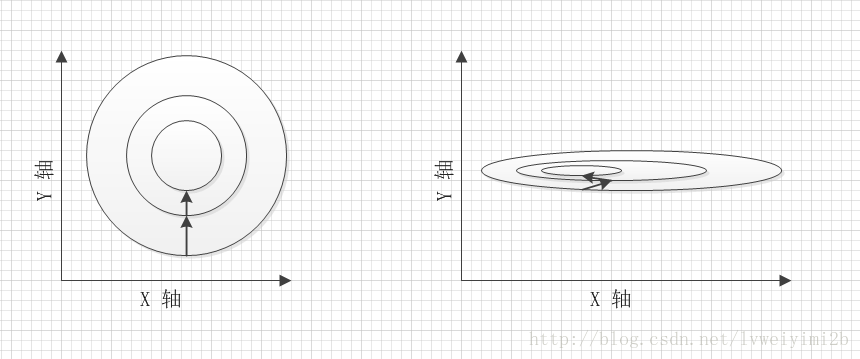
往往我们需要进行学习和训练的一手数据都比较粗糙,大多都有着不同甚至是相差很大的量纲,这样就会出现右图中图像过“扁”的情况。这会导致学习过程中,收敛过慢甚至是不收敛的情况。
出于各种考虑,我们需要对数据进行处理,使我们的数据尽量处在相同的量纲,比如我们的x和y向量的数据经过处理后都处在[-1,1]的范围内。
二、数据归一化的基本方法
- 线性归一化
- 标准差归一化
- 对数归一化
- 反余切归一化
- mapminmax
1.线性归一化
简单公式表达:y = (x-min Value)/(max Value-min Value)
其中,x是归一化之前的数据,y是归一化之后的数据,max Value 和 min Value 分别对应这一组数据中的最大值和最小值。范围:[0,1]。
适用于:把原来数据等比例缩放限定在某一范围内,在不涉及距离度量和协方差计算的时候使用。
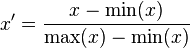
2.标准差归一化
简单公式表达:y = (x-μ)/σ
其中,x,y分别对应归一化前后数据。μ代表这组数据的均差,σ代表这组数据的方差。
适用于:原来数据近似高斯分布。同时是距离度量的。
![]()
3.对数归一化
简单公示表达:y= log10(x)
其中,x,y分别对应归一化前后数据。
4.反余切归一化
简单公示表达:y = atan(x)*2/pi
其中,x,y分别对应归一化前后数据。反余切函数的范围在[0,π/2],因此对反余切得到的值乘2除π,把范围控制在[0,1]
5.mapminmax归一化
这是matlab中封装好的方法,是线性归一化的一种。
表达式为:y = (ymax-ymin)*(x-xmin)/(xmax-xmin) + ymin
其中,x,y分别对应归一化前后数据。xmax,xmin分别对应处理前数据的最大值和最小值,而ymax,ymin则是处理后的数据的最大值最小值,换言之,就是我们希望我们处理后的数据的范围。matlab中使用方式是,[matlab_minmax_data,s1] = mapminmax(minmax_data);
matlab_minmax_data是处理后的矩阵,s1为mapminmax操作的索引,可以输出查看。minmax_data是处理前的数据。
Python实现
- 线性归一化
定义数组:x = numpy.array(x)
获取二维数组列方向的最大值:x.max(axis = 0)
获取二维数组列方向的最小值:x.min(axis = 0)
对二维数组进行线性归一化:
def max_min_normalization(data_value, data_col_max_values, data_col_min_values):
""" Data normalization using max value and min value
Args:
data_value: The data to be normalized
data_col_max_values: The maximum value of data's columns
data_col_min_values: The minimum value of data's columns
"""
data_shape = data_value.shape
data_rows = data_shape[0]
data_cols = data_shape[1]
for i in xrange(0, data_rows, 1):
for j in xrange(0, data_cols, 1):
data_value[i][j] = \
(data_value[i][j] - data_col_min_values[j]) / \
(data_col_max_values[j] - data_col_min_values[j])- 标准差归一化
定义数组:x = numpy.array(x)
获取二维数组列方向的均值:x.mean(axis = 0)
获取二维数组列方向的标准差:x.std(axis = 0)
对二维数组进行标准差归一化:
def standard_deviation_normalization(data_value, data_col_means,
data_col_standard_deviation):
""" Data normalization using standard deviation
Args:
data_value: The data to be normalized
data_col_means: The means of data's columns
data_col_standard_deviation: The variance of data's columns
"""
data_shape = data_value.shape
data_rows = data_shape[0]
data_cols = data_shape[1]
for i in xrange(0, data_rows, 1):
for j in xrange(0, data_cols, 1):
data_value[i][j] = \
(data_value[i][j] - data_col_means[j]) / \
data_col_standard_deviation[j]- 非线性归一化(以lg为例)
定义数组:x = numpy.array(x)
获取二维数组列方向的最大值:x.max(axis=0)
获取二维数组每个元素的lg值:numpy.log10(x)
获取二维数组列方向的最大值的lg值:numpy.log10(x.max(axis=0))
对二维数组使用lg进行非线性归一化:
def nonlinearity_normalization_lg(data_value_after_lg,
data_col_max_values_after_lg):
""" Data normalization using lg
Args:
data_value_after_lg: The data to be normalized
data_col_max_values_after_lg: The maximum value of data's columns
"""
data_shape = data_value_after_lg.shape
data_rows = data_shape[0]
data_cols = data_shape[1]
for i in xrange(0, data_rows, 1):
for j in xrange(0, data_cols, 1):
data_value_after_lg[i][j] = \
data_value_after_lg[i][j] / data_col_max_values_after_lg[j]














 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









