






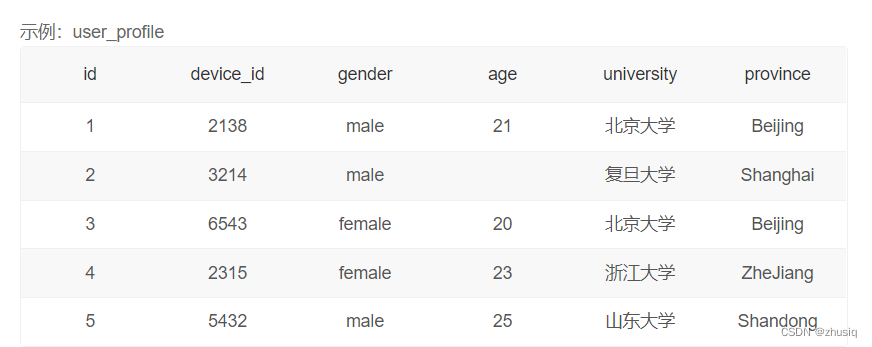
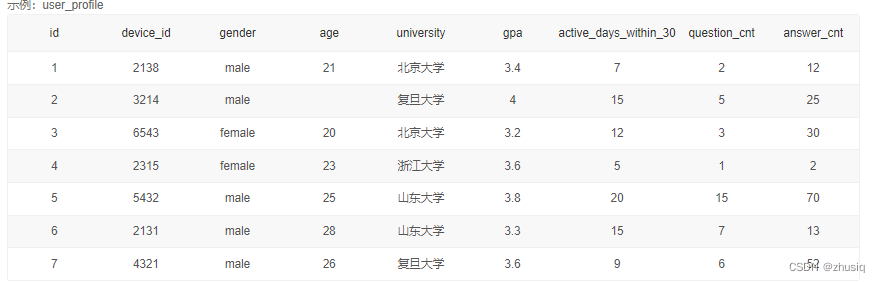
一、基础查询
1.基础查询
查询所有列:select * from user_profile
查询指定列或多列:select device_id,gender from 表名
2.简单处理查询结果
查询结果去重:select distinct 列名 from 表名
查询结果限制返回行数:
select * from 表名 limit n 从第0+1(m=0)条开始,取n条数据,是LIMIT 0,n的缩写
select * from 表名 limit m,n 从第m+1条开始,取n条数据
select * from 表名 limit n offset m 从第m+1条开始,取n条数据
将查询地列重新命名:
select device_id as user_infos_example from 表名 limit 2 offset 0
二、条件查询
1.基础排序(默认升序ASC)
查找后排序:select device_id ,age from user_profile order by age
查找后多列排序:select device_id,gpa,age from user_profile order by gpa,age
查找后降序排序:select device_id,gpa,age from user_profile order by gpa desc,age desc
2.基础操作符
查找学校是北大的信息:
select device_id,university from user_profile where university='北京大学'
select device_id,university from user_profile where university like '%北京大学%'(运行时间短)
查找年龄大于24岁的用户信息:
select device_id,gender,age,university from user_profile where age>24
查找某个年龄段的用户信息:
select device_id,gender,age from user_profile where age between 20 and 23
select device_id,gender,age from user_profile where age >= 20 and age <= 23
查找除复旦大学的用户信息:
select device_id,gender,age,university from user_profile where university != '复旦大学'
select device_id,gender,age,university from user_profile where university not like '复旦大学'
select device_id,gender,age,university from user_profile where university not in ( '复旦大学')
用where过滤空值练习:
select device_id,gender,age,university from user_profile where age is not NULL;
select device_id,gender,age,university from user_profile where age != ' ';
3.高级操作符
高级操作符练习1:
select device_id, gender, age,university,gpa from user_profile where gender ='male' and gpa>3.5
高级操作符练习2:
select device_id, gender, age,university,gpa from user_profile where university ='北京大学' or gpa>3.7
where in 和 not in:
select device_id,gender,age,university,gpa from user_profile where university in ("北京大学","复旦大学","山东大学")
操作符混合运用:
select device_id,gender,age,university,gpa from user_profile where university ='山东大学' and gpa>3.5 or university='复旦大学' and gpa>3.8
select device_id, gender, age, university, gpa from user_profile where device_id in (select device_id from user_profile where gpa>3.5 and university='山东大学') or device_id in (select device_id from user_profile where gpa>3.8 and university='复旦大学') (复杂但运行时间短)
查看学校名称中含有北京的用户:
select device_id,age,university from user_profile where university like '北京%'
_:匹配任意一个字符;
%匹配0或多个字符
[^ ]:不匹配[ ]中的任意一个字符。
[ ]:匹配[ ]中的任意一个字符(若要比较的字符是连续的,则可以用连字符“-”表 达 );
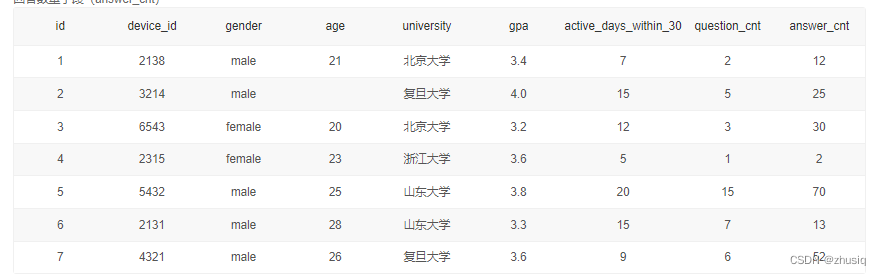
三、高级查询
1.计算函数
查找GPA的最高值:
select gpa from user_profile where university='复旦大学' order by gpa desc limit 1
select max(gpa) from user_profile where university='复旦大学'
计算男生人数以及平均GPA:
select count(gender) as male_num,round(avg(gpa),1) as avg_gpa
from user_profile
where gender='male'; (round(avg(gpa),1)保留一位小数)
2.分组查询(GROUP BY 按某个字段分组)
分组计算练习题:
现在运营想要对每个学校不同性别的用户活跃情况和发帖数量进行分析,请分别计算出每个学校每种性别的用户数、30天内平均活跃天数和平均发帖数量。
select
gender, university,
count(device_id) as user_num,
avg(active_days_within_30) as avg_active_days,
avg(question_cnt) as avg_question_cnt
from user_profile
group by gender, university
分组过滤练习题:
取出平均发贴数低于5的学校或平均回帖数小于20的学校
select university,
avg(question_cnt) as avg_question_cnt,
avg(answer_cnt) as avg_answer_cnt
from user_profile
group by university
having avg_question_cnt<5 or avg_answer_cnt<20
函数结果作为筛选条件时,不能用where,而是用having语法,配合重命名即可;
分组排序练习题:
不同大学的用户平均发帖情况,并按照平均发帖情况进行升序排列
select university,
avg(question_cnt) as avg_question_cnt
from user_profile
group by university
order by avg_question_cnt
四、多表查询
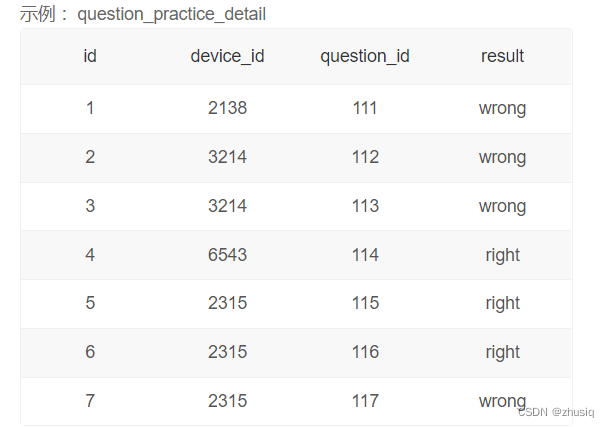
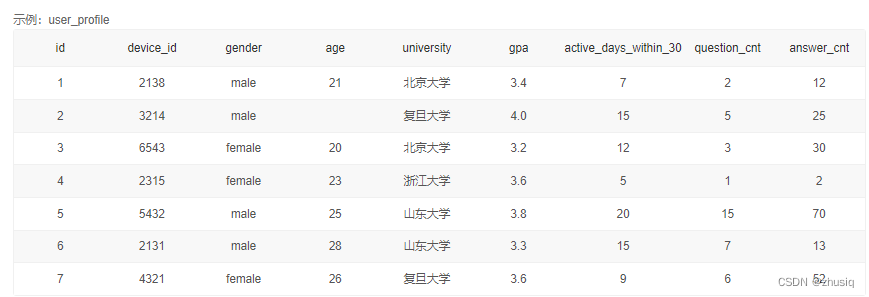
1.子查询
所有来自浙江大学的用户题目回答明细情况:
浙江大学用户题目回答情况:
第一种写法:select device_id, question_id, result from question_practice_detail
where device_id in (
select device_id from user_profile
where university='浙江大学'
) order by question_id
第二:select device_id,question_id,result from question_practice_detail
where device_id = (select device_id from user_profile where university = '浙江大学')
第三:SELECT
u.device_id,
question_id,
result
FROM
question_practice_detail AS q,
user_profile AS u
WHERE
q.device_id = u.device_id
AND u.university = '浙江大学'
第四:SELECT u.device_id,q.question_id,q.result from question_practice_detail q
join user_profile u on q.device_id=u.device_id
where university="浙江大学"
第五:select t1.device_id,question_id,result
from question_practice_detail t1
left JOIN user_profile t2
on t1.device_id = t2.device_id
where university = '浙江大学'
2.链接查询
统计每个学校的答过题的用户平均答题数:(暗示以学校作为分组)
select university,count(qpd.question_id)/ count(distinct qpd.device_id) as avg_answer_cnt
from question_practice_detail as qpd
inner join user_profile as up
on qpd.device_id=up.device_id
group by university
select university,count(qpd.question_id)/ count(distinct qpd.device_id) as avg_answer_cnt
from question_practice_detail as qpd,user_profile as up
where qpd.device_id=up.device_id
group by university
统计每个学校各难度的用户平均刷题数:
select university,difficult_level,
count(qpd.question_id) / count(distinct qpd.device_id) as avg_answer_cnt
from question_practice_detail as qpd
left join user_profile as up on up.device_id=qpd.device_id
left join question_detail as qd on qd.question_id = qpd.question_id
group by university,difficult_level
统计每个用户的平均刷题数:
SELECT
t1.university,
t3.difficult_level,
COUNT(t2.question_id) / COUNT(DISTINCT(t2.device_id)) as avg_answer_cnt
from
user_profile as t1,
question_practice_detail as t2,
question_detail as t3
WHERE
t1.university = '山东大学'
and t1.device_id = t2.device_id
and t2.question_id = t3.question_id
GROUP BY
t3.difficult_level;
select
"山东大学" as university,
difficult_level,
count(qpd.question_id) / count(distinct qpd.device_id) as avg_answer_cnt
from question_practice_detail as qpd
inner join user_profile as up
on up.device_id=qpd.device_id and up.university="山东大学"
inner join question_detail as qd
on qd.question_id=qpd.question_id
group by difficult_level
SELECT t1.university,
t3.difficult_level,
COUNT(t2.result) / COUNT(DISTINCT t2.device_id) AS avg_answer_cnt
FROM question_practice_detail AS t2
LEFT JOIN user_profile AS t1
ON t2.device_id = t1.device_id
LEFT JOIN question_detail AS t3
ON t2.question_id = t3.question_id
GROUP BY t1.university, t3.difficult_level
HAVING t1.university = '山东大学';
3.组合查询
查找山东大学或者性别为男生的信息:
(分别查看&结果不去重:所以直接使用两个条件的or是不行的,直接用union也不行,要用union all,分别去查满足条件1的和满足条件2的,然后合在一起不去重)
select
device_id, gender, age, gpa
from user_profile
where university='山东大学'
union all
select
device_id, gender, age, gpa
from user_profile
where gender='male'
五、必会的常用函数
1.条件函数:
计算25岁以上和以下的用户数量:
SELECT CASE WHEN age < 25 OR age IS NULL THEN '25岁以下'
WHEN age >= 25 THEN '25岁及以上'
END age_cut,COUNT(*)number
FROM user_profile
GROUP BY age_cut
SELECT
IF(age < 25 OR age IS NULL, "25岁以下", "25岁及以上") AS age_cut,
COUNT(id) AS num
FROM
user_profile
GROUP BY
age_cut
查看不同年龄段的用户明细:
select device_id,gender,
case when age<20 then '20岁以下'
when age<=24 then '20-24岁'
when age>=25 then '25岁及以上'
else '其他'
end as age_cut
from user_profile
2.日期函数:
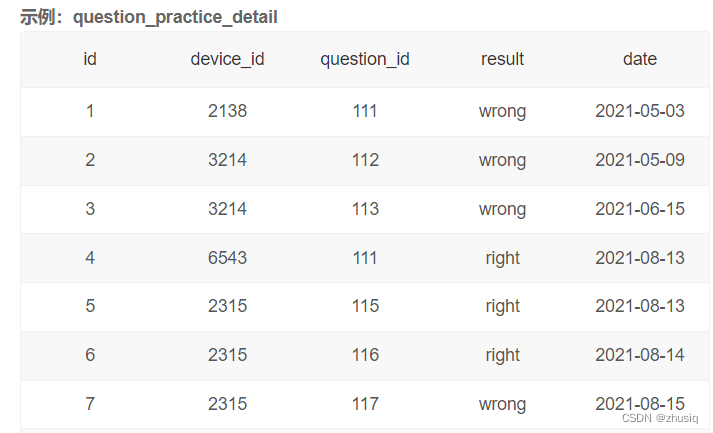
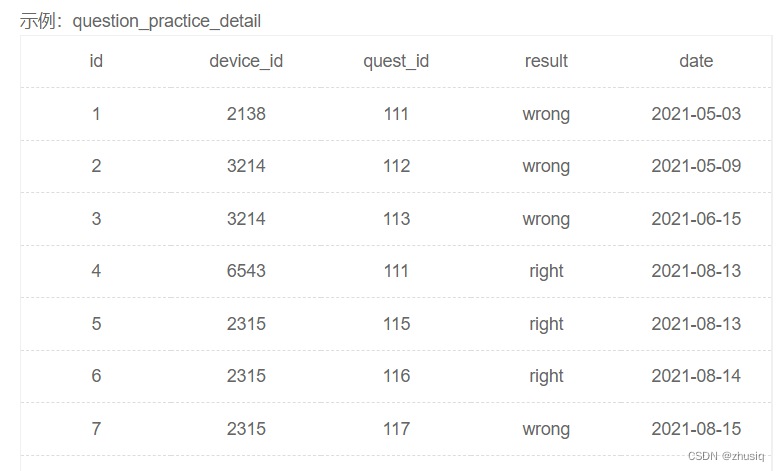
计算用户8月每天的练题数量:
select
day(date) as day,
count(question_id) as question_cnt
from question_practice_detail
where month(date)=8 and year(date)=2021
group by date
计算用户的平均次日留存率:
select count(date2) / count(date1) as avg_ret
from (
select
distinct qpd.device_id,
qpd.date as date1,
uniq_id_date.date as date2
from question_practice_detail as qpd
left join(
select distinct device_id, date
from question_practice_detail
) as uniq_id_date
on qpd.device_id=uniq_id_date.device_id
and date_add(qpd.date, interval 1 day)=uniq_id_date.date
) as id_last_next_date
3.文本函数:
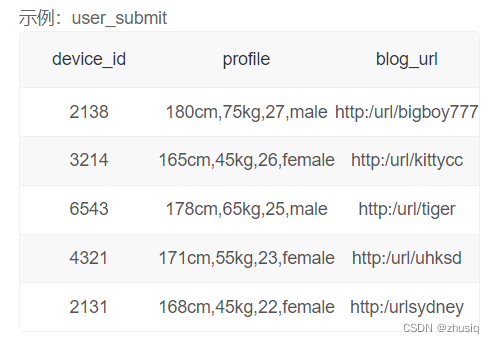
统计每种性别的人数:
-
每个性别:按性别分组group by gender,但是没有gender字段,需要从profile字段截取,按字符,分割后取出即可。可使用substring_index函数可以按特定字符串截取源字符串。
substring_index(FIELD, sep, n)可以将字段FIELD按照sep分隔:
(1).当n大于0时取第n个分隔符(n从1开始)左边的全部内容;
(2).当n小于0时取倒数第n个分隔符(n从-1开始)右边的全部内容;
因此,本题可以直接用
substring_index(profile, ',', -1)取出性别。 附:substring_index函数解析 -
多少参赛者:计数统计,count(device_id)
select
substring_index(profile, ',', -1) as gender,
count(device_id) as number
from user_submit
group by gender
截取出年龄:
- 限定条件:无;
- 每个年龄:按年龄分组group by age,但是没有age字段,需要从profile字段截取,按字符,分割后取出即可。可使用substring_index函数可以按特定字符串截取源字符串。
substring_index(FIELD, sep, n)可以将字段FIELD按照sep分隔:
(1).当n大于0时取第n个分隔符(n从1开始)之后的全部内容;
(2).当n小于0时取倒数第n个分隔符(n从-1开始)之前的全部内容;
因此,本题可以先用substring_index(profile, ',', 3)取出"180cm,75kg,27",然后用substring_index(profile, ',', -1)取出27。
当然也可以用substring_index(substring_index(profile, ",", -2), ",", 1)取出27。
附:substring_index函数解析 - 多少参赛者:计数统计,count(device_id)
select
substring_index(substring_index(profile, ',', 3), ',', -1) as age,
count(device_id) as number
from user_submit
group by age
提取博客URL中的用户名:
select
-- 替换法 replace(string, '被替换部分','替换后的结果')
-- device_id, replace(blog_url,'http:/url/','') as user_name
-- 截取法 substr(string, start_point, length*可选参数*)
-- device_id, substr(blog_url,11,length(blog_url)-10) as user_nam
-- 删除法 trim('被删除字段' from 列名)
-- device_id, trim('http:/url/' from blog_url) as user_name
-- 字段切割法 substring_index(string, '切割标志', 位置数(负号:从后面开始))
device_id, substring_index(blog_url,'/',-1) as user_name
from user_submit;
4.窗口函数:
找出每个学校GPA最低的同学:
select device_id,university,gpa
from user_profile
where (university,gpa) in (select university,min(gpa) from user_profile group by university)
order by university
















 681
681











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









