







SamToNe: Improving Contrastive Loss for Dual Encoder Retrieval Models with Same Tower Negatives
原文链接:https://aclanthology.org/2023.findings-acl.761/
(2023)
摘要
双编码器已用于检索任务和表示学习,取得了良好的效果。训练双编码器的标准方法是使用批内负样本的对比损失。在这项工作中,我们提出了一种改进的对比学习目标,通过将来自相同编码器塔的查询或文档添加到负样本中,我们将其命名为“相同塔的负样本的对比损失”(SamToNe)。通过评估 MS MARCO 和 MultiReQA 的问答检索基准以及异构零样本信息检索基准(BEIR),我们证明 SamToNe 可以有效提高对称和非对称双编码器的检索质量。通过 t-SNE 算法(van der Maaten 和 Hinton,2008)直接探测两个编码塔的嵌入空间,我们观察到 SamToNe 确保了两个编码塔的嵌入空间之间的对齐。基于对top-1检索结果的嵌入距离分布的分析,我们从正则化的角度进一步解释了该方法的有效性。
1. 引言
应用于信息检索的双编码器架构在广泛的任务中表现出了优异的性能(Gillick et al, 2018; Karpukhin et al, 2020; Ni et al, 2021, 2022)。
最近,信息检索社区已经转向利用大型无监督语料库预训练的深度学习模型(Devlin 等人,2019 年;Raffel 等人,2020 年),该模型为查询和文档提供更强大的语义和上下文表示。这些模型可以成功应用于评分任务,例如Dehghani 等人 (2017),或检索任务,例如吉利克等人(2018)。相比之下,经典的检索模型,例如 BM25(Robertson 和 Zaragoza,2009),依赖于词袋词汇重叠、词频启发式、逆文档频率和文档长度。这种类型的检索模型不需要任何训练,并且可以很好地泛化,但它们无法找到术语重叠度低但语义相似度高的文档。
双编码器(Gillick 等人,2018;Yang 等人,2020;Karpukhin 等人,2020;Reimers 和 Gurevych,2019)由两个编码塔组成,分别将查询和文档映射到共享的低维密集表示中,即嵌入空间。该模型通常通过对比损失进行优化(Chopra et al, 2005),它将来自相同正例的查询和文档的嵌入移得更近,而来自负例的嵌入则移得更远。批量训练双编码器允许对于每个问题使用将批次内所有其他问题回答视为负样本的段落(Gillick 等人,2018),即“批量负样本”。在索引时,语料库中的所有文档都通过批量推理进行编码并建立索引。为了运行检索,对查询进行编码,并且可以使用相似性度量(例如,通过最近邻搜索(Vanderkam 等人,2013;Johnson 等人,2021)在嵌入空间上检索其最相关的文档。嵌入向量的点积或余弦距离。
动机
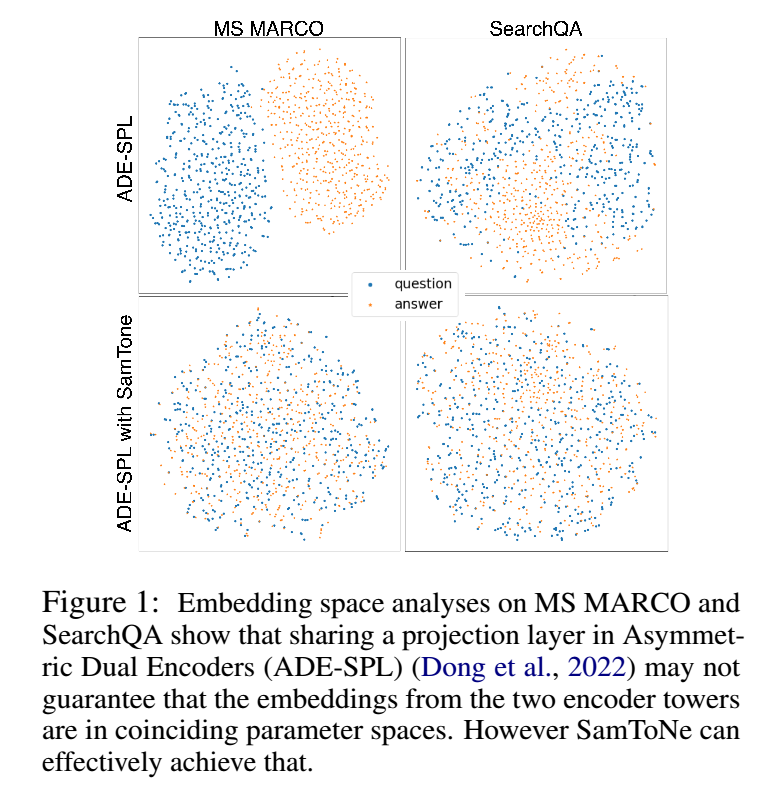
在这项工作中,我们考虑两种主要类型的双编码器架构:“对称双编码器”(SDE)1,在两个编码器塔之间共享参数,以及“非对称双编码器”(ADE),具有两个不同参数化的编码器塔。 Dong 等人 (2022) 证明,共享投影层可以显着提高 ADE 的性能。他们凭经验解释了 SDE 和 ADE-SPL 的功效,声称共享投影层有助于将两个编码器塔的嵌入映射到一致的参数空间。
通过对各种任务重复这种嵌入空间分析,我们发现 ADE-SPL 可能不足以确保两个编码器塔的嵌入空间重合,如图 1 所示。这激励我们进一步改进双编码器检索质量超出了 Dong 等人 (2022) 探索的架构变化。尽管投影层是共享的,但我们的分析表明,除了使用带有批内负片的标准对比损失之外,还需要一种额外的机制来确保真实 query-passage 对的嵌入的邻接性。
贡献
在本文中,我们提出了双编码器模型的改进训练目标:使用 Same Tower Negatives (SamToNe) 的对比损失。在第 3 节中,我们展示了它在各种信息检索任务中的有用性,包括具有任务内微调的任务和零样本基准测试套件。在探索的所有任务中,SamToNe 的表现与传统训练设置相比具有竞争力,跨任务的平均指标有了显着改进。最后,通过对生成的嵌入的分析,在第 4 节中,我们从正则化的角度进一步证明了 SamToNe 的优越性。
2. 方法
双编码器架构
我们遵循信息检索的标准设置:给定查询 q 和检索候选语料库 P,目标是检索 k 个相关候选者 pk ∈ P。候选者可以是短语、句子、段落,或文件。
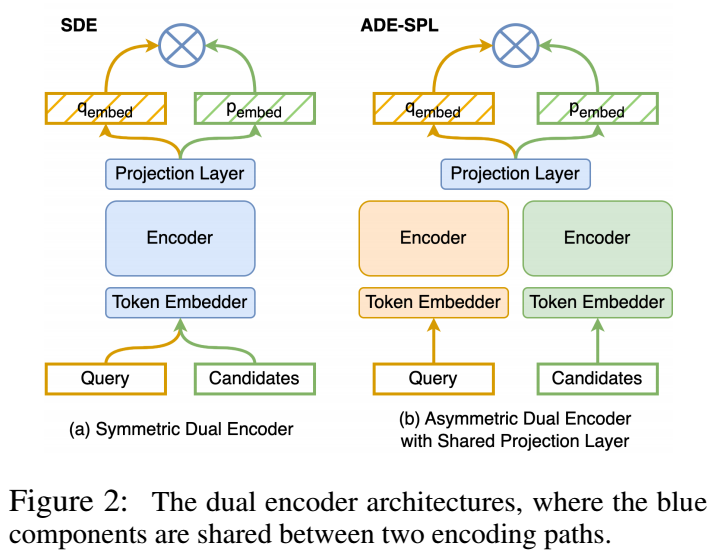
最近的研究(Dong 等人,2022)表明,共享投影层可以显着提高 ADE 的性能,并且我们在整个实验中使用 ADE 的共享投影层 (ADSPL)。图 2 说明了我们在这项工作中使用的 SDE 和 ADE-SPL 架构。我们的双编码器是从预训练的 t5.1.1 编码器初始化的(Raffel 等人,2020)。
遵循 Ni 等人 (2022); Dong 等人 (2022),我们通过对 T5 编码器输出进行平均并将其投影到最终的嵌入向量来对查询 qi 或候选者 pi 进行编码。
(Encoder 输出进行平均池化,然后通过映射层)
对比损失
训练双编码器模型的标准方法是优化批量采样的 softmax 损失以进行对比学习(Henderson 等人,2017):

其中 sim 是余弦相似度,B 是小批量示例,τ 是 softmax 温度。 pi 是一批检索候选 p* 中查询 qi 的真实相关段落,其中所有其他段落 pk (k ̸= i) 被视为对比学习的反例
双向批量采样 softmax 损失通常用于提高两个塔的嵌入质量,其中针对查询到段落匹配和段落到查询匹配计算对比损失(Yang 等人,2019)。我们在整个工作中使用双向损失。
相同的 tower 负样本
批量采样的softmax损失是一种对比损失,仅考虑目标示例对{qi,pi}和批量采样的负对{qi,pj}(j̸=i)之间的对比估计。提高检索质量的一种方法是提高查询嵌入之间的对比度。因此,我们提出了一种使用 Same Tower Negatives 的新型对比损失,我们将其缩写为 SamToNe:
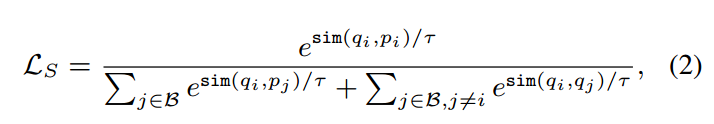
其中分母第二项是同塔负样本的贡献。
SamToNe 可以解释为批量采样的 softmax 损失的正则化版本,其中滑 j∈B,j̸=i e sim(qi,qj )/τ 是正则化项。
当查询嵌入分布不均匀时, max sim(qi , qj ) ≫ max sim(qi , pj ) ,分母中的第二项将主导负例的贡献。因此,它将推动对比学习中查询嵌入的分离。在第 4 节中,我们提供了 SamToNe 作为嵌入空间正则化器效果的经验证据。
Ren 等人 (2021) 提出了一种改进的对比损失 PAIR,它是一种混合损失 LP AIR = −(1 − α) log Lc − α log LP ,其中
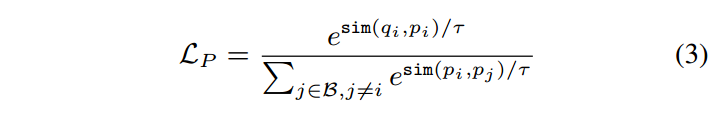
惩罚段落/文档之间的相似性。
尽管 SamToNe 和 PAIR 都在惩罚相同塔输入之间的相似性,但仍存在两个显着差异。首先,SamToNe 是无超参数的,而 PAIR 则引入了新的超参数 α。这是因为 SamToNe 从嵌入空间正则化的角度引入了新术语(详细分析请参见第 4 节)。因此 SamToNe 可以很容易地应用于查询和文档编码器(参见第 3.4 节),但 PAIR 需要引入另一个超参数来应用于两者。其次,Ren 等人 (2021) 提到它需要进行 2 阶段训练,第一阶段使用 PAIR 损失,第二阶段使用常规批内 softmax 损失。由于其自平衡特性,SamToNe 不需要多阶段训练。
与 PAIR 的彻底比较可以在第 3 节和第 4 节中找到。没有添加超参数、单阶段训练和保证嵌入空间质量的改进,使 SamToNe 更易于使用。
一、其他文章 PAIR:惩罚文章相似度
二、本文 SamToNe:惩罚查询相似度:当在 query 分布不均匀的时候(query 之间的相似度远高与 query 与 passage 相似度),通过加入这个正则化项:
1)使用 query 之间的相似度来主导负样本的贡献
2)使得 query 的嵌入在向量空间中分离
Ps:6局限性 提到,该方法依赖于数据集,数据集中相似的查询不能用作负样本的计算
3. 实验
3.1 问答检索任务
我们在 5 个问答 (QA) 检索任务上评估 SamToNe,包括 MS MARCO(Nguyen 等人,2016)和 MultiReQA(Guo 等人,2021)。对于 MS MARCO,检索候选是相关段落,而对于 MultiReQA 中的 4 个任务,检索候选是答案句子。
为了对我们的实验结果进行公平比较,相同的微调超参数应用于我们的所有模型变体。使用 Adafactor 优化器(Shazeer 和 Stern,2018)对模型进行 20, 000 个步骤的优化,其中 softmax 温度 τ = 0.01,批量大小 512,最后一步的学习率从 10−3 开始线性衰减到 0。为了比较 SamToNe 和 PAIR,我们使用 Ren 等人 (2021) 中报告的 PAIR 超参数 α = 0.1,并保持所有其他实验设置相同。 SamToNe 仅应用于查询端,因为它在不同数据集上更加稳健。在两个编码器塔上应用SamToNe的实验和分析请参考3.4节。我们使用 1 精度 (P@1) 和平均倒数排名 (MRR) 对微调模型进行基准测试。
如表1所示,SamToNe极大地提高了SDE和ADESPL模型的检索性能。使用 SamToNe,ADE-SPL 模型可以大大优于 SDE 模型,特别是对于 TriviaQA 和 SearchQA。相对于 PAIR,SamToNe 在两种类型的模型中跨不同数据集提供了更好的性能。
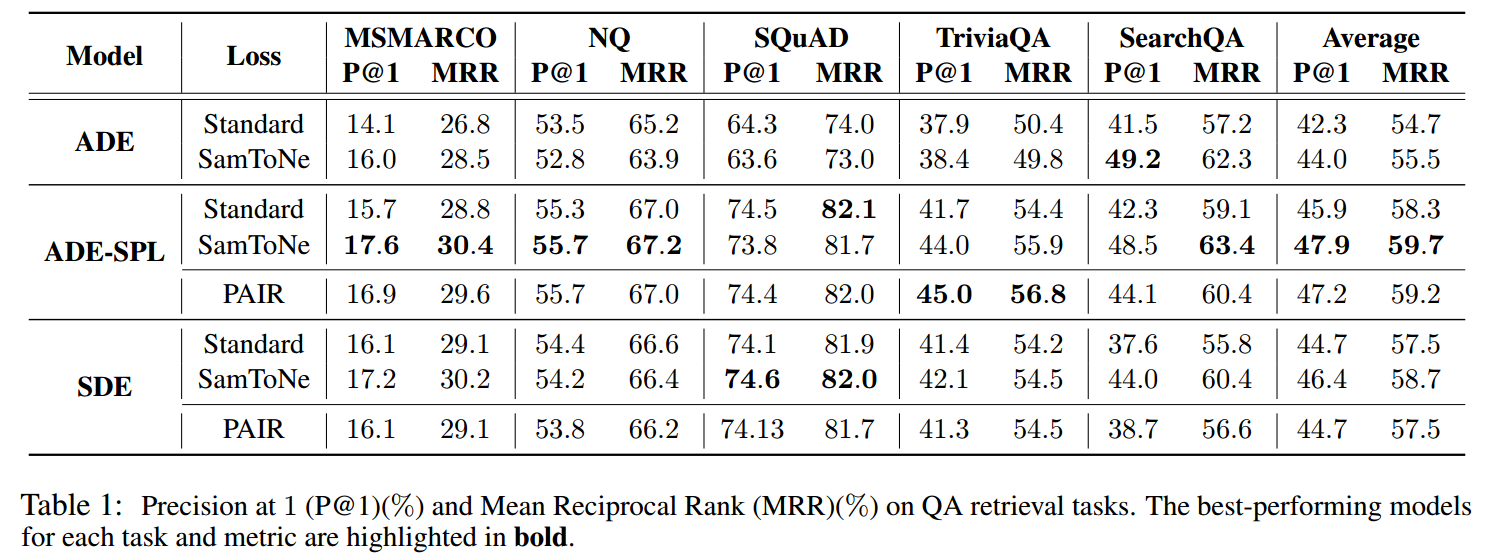
3.2 模型大小缩放
为了评估模型大小的影响,我们评估了从 t5.1.1-base(∼ 250M 参数)、t5.1.1-large(∼ 800M 参数)和 t5.1.1-XXL(∼ 11B 参数)初始化的双编码器。
图 3 和附录表 4 显示 SamToNe 持续改进了不同模型尺寸的双编码器的性能。
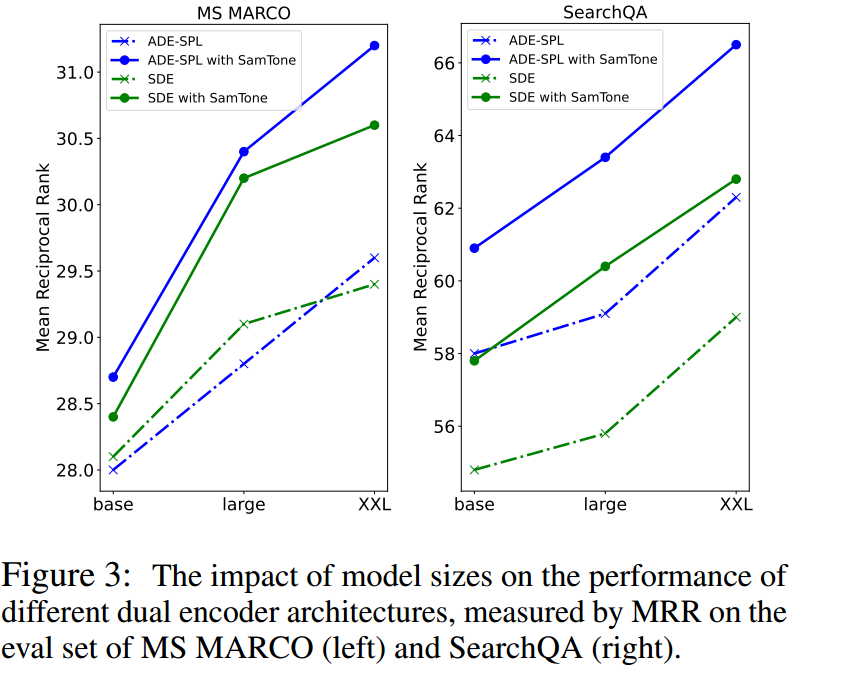
3.3 BEIR 泛化任务
我们进一步证明了在 BEIR(Thakur 等人,2021)上使用 SamToNe 训练的双编码器的功效,BEIR 是零样本评估的异构基准。
BEIR 拥有跨 9 个领域的 18 个信息检索数据集2,包括生物医学、金融、新闻、Twitter、维基百科、StackExchange、Quora、科学和杂项。大多数数据集都有二进制查询相关性标签。其他数据集有3级或5级相关性判断。
由于 BEIR 正在评估泛化能力,而 SDE 通常用于通用检索(Ni 等人,2021),因此我们重点评估 SamToNe 使用 SDE 架构对 BEIR 的影响。在本次评估中,我们重用了通过 MS MARCO 微调的模型,如第 3.1 节所述。
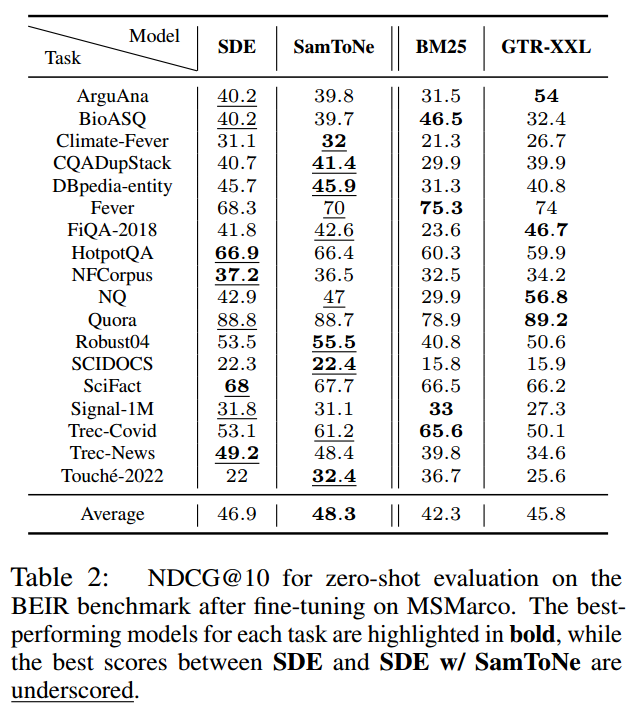
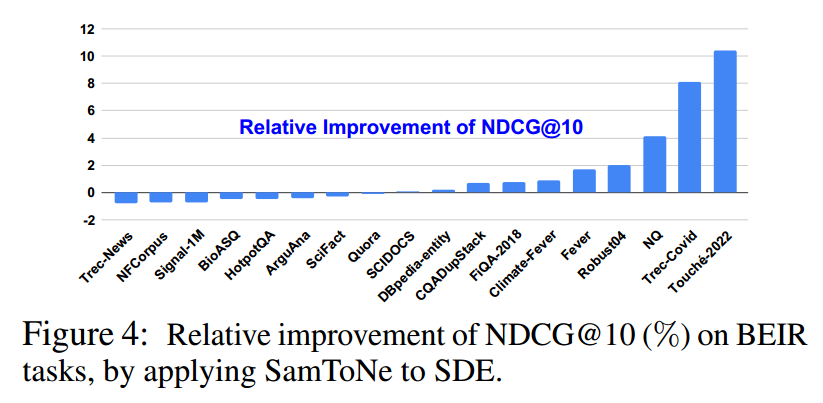
使用与 GTR 相同的设置进行评估(Ni 等人,2021),SamToNe 在 BEIR 上表现出强大的性能,如表 2 和图 4 所示。平均而言,对于 XXL 大小的 SDE,SamToNe 将 NDCG@10 提高了 1.4%。使用 SamToNe 训练的 SDE 显着优于 BM-25(一种稀疏检索方法)和 GTR(一种密集检索方法),GTR 与 SDE 具有相同的架构和相同的模型大小,但使用不同的语料库进行了微调。
3.4 SamToNe 应用于双塔
正如查询塔一样,SamToNe 可以应用于文档塔,从而实现更好的查询-文档对齐。然而,训练数据通常包含大量针对不同查询集的重复文档。
例如,训练分割中只有 17% 的文档对于 TriviaQA 是唯一的,但对于 MSMARCO 来说是 98%。对于唯一文档率较低的数据集,在文档端应用 SamToNe 将会对 pi = pj 的 sim(pi , pj ) 进行惩罚,并可能会降低性能,如表 3 所示。
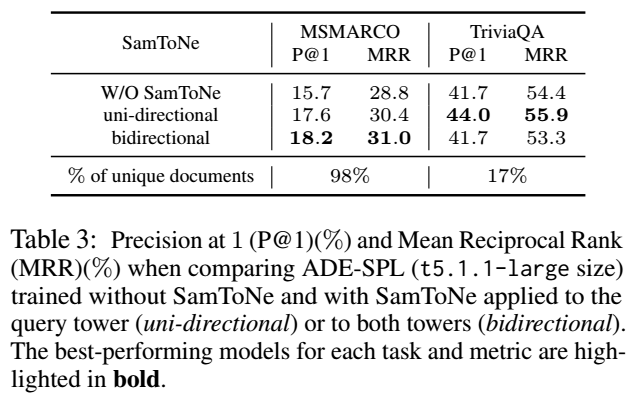
1)本文优于 PAIR,ADE-SPL 通常优于 SDE
2)模型规模越大,效果越好
3)提升基础模型的泛化能力
4)在 passage 训练时,也使用 SamToNe 正则化,对于训练集与 dev 集 passage 重合度高的数据集来说,效果不如不用
4. 分析
4.1 嵌入空间分析
如图 1 顶行所示,对于 MS MARCO 和 SearchQA,ADE-SPL 生成两个连接但拓扑可分离的嵌入空间。除了共享投影层之外,它还需要一种额外的机制,以确保地面实况对的嵌入的邻接性。
SamToNe 被提议作为将每个真实训练对的嵌入绘制在一起的“力量”。其功效如图 1 的下半部分所示
4.2 SamToNe:嵌入距离正则化
为了进一步了解 SamToNe 作为嵌入距离正则化器的作用,我们在 MS MARCO 和 SearchQA 的测试集中评估了查询嵌入与其 top-1 检索结果之间的距离分布。嵌入距离通过余弦相似度来测量,其中 1.0 表示完美对齐,范围为 [−1.0, 1.0]。
如图 5 所示,SamToNe 将(查询、top-1 检索结果)对的分布大幅转变为 1.0,展示了 SamToNe 在嵌入距离上的正则化效果。
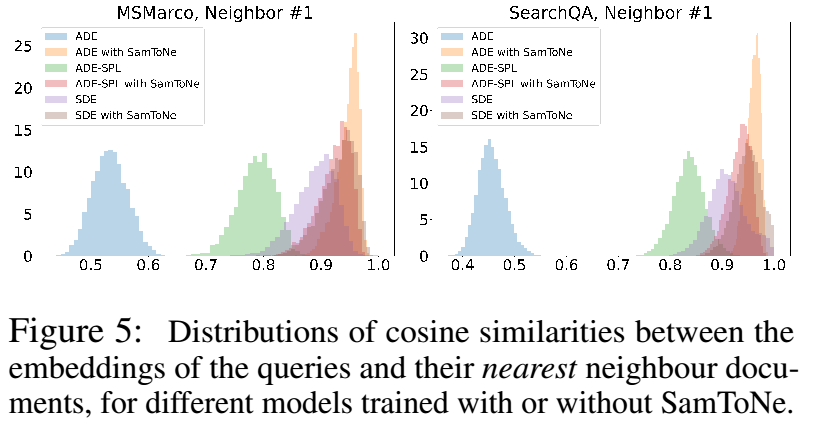
通过将正则化查询-查询相似度项 e sim(qi,qj )/τ 和标准批量负查询-文档相似度项 e sim(qi,pj )/τ 放在具有相同权重的分母中,SamToNe 推动了相似度比在查询-查询和查询-文档之间,sim(qi , qj )/sim(qi , pj ),以 1.0 为中心。
这是一种自平衡正则化效应。查询空间和文档空间被设置为彼此紧密重叠,并且正对的嵌入更有可能位于嵌入空间的同一区域。
为了凭经验说明这种效果,我们在图 6 中绘制了随机选择的 i 和 j 的 sim(qi,qj ) sim(qi,pj ) 比率的直方图。正则化效果仅在使用 SamToNe 时显示,但在使用 PAIR (Ren等人,2021)是。这是因为像 PAIR 这样的混合损耗不存在自平衡效应。
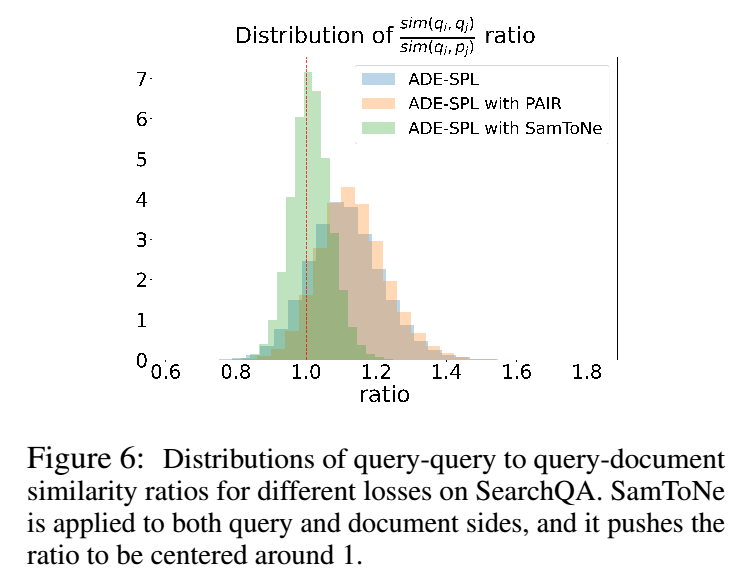
该正则化项使得 query 和 passage 在同一向量空间更接近
5. 结论
通过评估 QA 检索任务和零样本泛化基准,我们证明使用 SamToNe 进行训练可以显着提高双编码器检索质量。通过查询和文档嵌入的 t-SNE 映射,我们表明使用 SamToNe 训练的模型的两个编码塔的嵌入空间更好地对齐。
通过查询嵌入与其最近邻之间的相似距离的分布,我们从正则化的角度凭经验解释了 SamToNe 的有效性。一般来说,我们建议使用 SamToNe 来训练用于信息检索任务的双编码器。
6. 局限
相同的塔负样本可以应用于其他对比损失,例如三重态损失(Chechik 等人,2010)。因为我们专注于改进最流行的训练双编码器模型的方法,即对于批量采样的 softmax 损失,我们将同塔负样本应用于其他类型的对比损失作为未来的工作。
虽然 SamToNe 已被证明可以有效改善双编码器的训练,但其功效可能取决于用作输入的查询的多样性。在训练集中具有大量相似查询的数据集中,可能需要使用屏蔽或其他技术将它们从负计算中删除。当应用于查询塔和文档塔时,此类技术还可以提高 SamToNe 的效率,目前已知 SamToNe 会阻碍唯一文档率较低的数据集的性能,如第 3.4 节所述。我们将对上述考虑因素的深入探索留给未来的工作。
补充知识
1. 对称编码器 vs 非对称编码器
对称双编码器:在对称双编码器中,两个编码器的结构和参数是相同的。它们分别对输入进行编码,然后通过一种相似性度量方法(如余弦相似度)来计算它们的相似度。
非对称双编码器:在非对称双编码器中,两个编码器的结构和参数可以是不同的。通常,其中一个编码器被称为查询编码器,而另一个编码器被称为文档编码器。查询编码器用于将查询转换为嵌入向量,而文档编码器用于将文档(或候选项)转换为嵌入向量。然后,通过计算查询向量与文档向量之间的相似度来执行检索或相似性计算。
这两种架构在不同的应用场景中都有各自的优势和用途。对称双编码器通常用于简单的相似性计算任务,而非对称双编码器更适用于信息检索等需要区分查询和文档的任务。
2. 编码器的嵌入空间对齐 & 利用 t-SNE 来证明这种对齐
两个编码器嵌入空间对齐意味着它们在某种程度上彼此相似或匹配,以便在检索任务中更好地协同工作。当两个编码器的嵌入空间对齐时,它们可以更好地共同表示相似的语义信息,从而提高了检索质量。
t-SNE(t-distributed stochastic neighbor embedding)算法是一种用于降维和可视化高维数据的技术,它可以将高维数据点映射到二维或三维空间,并保持数据点之间的局部相似性。在这种情况下,使用t-SNE算法可以将编码器产生的高维嵌入向量映射到二维空间,以便直观地观察它们之间的关系。
证明两个编码器嵌入空间对齐通常包括以下步骤:
1)使用两个编码器对数据进行编码,得到两组嵌入向量。
2)对这些嵌入向量应用t-SNE算法,将它们映射到二维空间。
3)观察映射后的嵌入空间中的分布情况。如果两个编码器的嵌入空间对齐,那么它们在映射后的空间中应该显示出相似的结构和分布。
4)通过比较映射后的嵌入空间,可以定量评估它们之间的相似性和对齐程度。
3. 检索结果的嵌入距离分布 & 正则化角度解释
检索结果的嵌入距离分布指的是检索任务中得到的嵌入向量之间的距离分布。在检索任务中,通常会将查询与数据库中的候选项进行比较,并根据它们的相似性得到一个排名列表。然后,可以计算查询与排名列表中每个候选项之间的嵌入距离,这些距离的分布可以用来评估检索系统的性能。
从正则化的角度解释方法的有效性意味着通过正则化技术对模型进行改进,可以提高检索结果的嵌入距离分布的质量。正则化是一种用于控制模型复杂度和减少过拟合的技术,在这种情况下,它可以帮助模型更好地学习到嵌入向量的表示,使得它们在嵌入空间中更好地组织和分布。
具体来说,通过正则化技术可以在训练过程中向模型引入额外的约束或惩罚,以防止模型学习到无用的信息或过度拟合训练数据。这样做可以帮助模型更好地泛化到未见过的数据,并且可以更好地学习到具有更好区分度的嵌入表示。因此,从正则化的角度解释方法的有效性意味着通过正则化技术改进模型可以提高检索结果的嵌入距离分布的质量,从而提高检索任务的性能。
4. Bert 嵌入层
嵌入层有参数:
嵌入层通常是有参数的。在深度学习中,嵌入层的参数是可学习的,它们会根据训练数据进行调整,以使得嵌入向量能够更好地表示词汇之间的语义关系。在BERT中,嵌入层的参数即词嵌入矩阵,这个矩阵的维度通常是词汇表大小(词的数量)乘以嵌入维度(向量的长度)。这些参数会在预训练阶段和微调阶段进行学习更新。
嵌入层在BERT和Word2Vec中的作用是类似的,它们都将词汇表中的词映射到连续的向量空间中。Word2Vec是一种经典的词嵌入模型,它通过训练一个浅层神经网络来学习词向量,使得在向量空间中语义相近的词在距离上也比较接近。而在BERT中,嵌入层也扮演着类似的角色,将每个词映射成一个固定长度的实数向量,但BERT中的嵌入层通常更深更复杂,同时结合了位置编码,以适应Transformer编码器的输入要求。
嵌入层参数会更新:
嵌入层的参数在训练过程中会被更新。在深度学习中,参数更新是通过反向传播算法实现的,该算法根据损失函数的梯度调整模型参数,以最小化损失。在训练过程中,模型通过不断地观察输入和目标输出之间的差异来更新参数,使得模型能够逐渐学习到数据中的模式和规律。因此,在BERT中,嵌入层的参数也会随着训练过程逐渐调整,以使得模型能够更好地捕捉语言的语义信息。
5. 正则化项
机器学习中经常会在损失函数中加入正则项,称之为正则化(Regularize)。
目的:防止模型过拟合
原理:在损失函数上加上某些规则(限制),缩小解空间,从而减少求出过拟合解的可能性
6. 自平衡的正则化效应
self-balancing regularization effect
自平衡的正则化效应是指在机器学习或统计建模中,一种能够自动调整模型复杂度的机制。通常情况下,正则化是为了防止模型过拟合(过度适应训练数据,导致泛化能力下降),它通过对模型参数进行惩罚来实现。而自平衡的正则化效应则是指这种惩罚机制可以根据数据的特性自动调整,以在不同的数据集上保持一定的平衡,而不需要手动调节超参数。
在实际应用中,自平衡的正则化效应可以帮助模型在不同的数据集上表现稳定,而无需过多地依赖人工调整。这种效应可以使模型更加健壮,并且更适应各种数据的变化和特性。
参考资料:
【1】【2】【3】【4】【6】chatgpt
【5】正则化:https://zhuanlan.zhihu.com/p/67931198


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









