







1 为什么需要配置中心?
把配置信息写在nacos配置中心里,相比于把配置信息写在application.yml等配置文件里,有以下好处:
- 实时生效:在 application.yml 中配置的参数,若要修改就必须重启应用程序。而 Nacos 配置中心支持动态配置更新,当配置发生变更时,应用程序能实时感知到并自动更新配置,无需重启,从而保证系统的高可用性和不间断运行。例如,在电商系统中,促销活动的折扣率、限时抢购的时间范围等配置随时可能调整,使用 Nacos 配置中心就能快速响应这些变化,及时生效。
- 统一维护:对于微服务架构而言,每个服务都有自己的配置文件,管理起来较为繁琐。Nacos 配置中心可以把所有服务的配置集中管理,提供统一的界面和 API 来进行配置的增删改查操作,提升了配置管理的效率和可维护性。比如,在一个包含多个微服务的项目中,数据库连接信息、缓存服务器地址等公共配置可以统一存放在 Nacos 中,方便统一修改和维护。
- 版本控制:Nacos 配置中心支持配置的版本管理,你能够查看配置的历史版本,回滚到之前的某个版本。这在配置修改出现问题时非常有用,可以快速恢复到正常状态。
- 多环境配置:在不同的环境(如开发、测试、生产)中,应用程序的配置可能存在差异。Nacos 配置中心支持多环境配置管理,你可以为每个环境创建独立的配置集,并且可以设置配置的继承关系,减少配置的重复编写。
2 springcloud与nacos的版本兼容对照表
| Spring Cloud Alibaba Version | Spring Cloud Version | Spring Boot Version | Nacos Version | Dubbo Version | Seata Version | RocketMQ Version | Sentinel Version |
|---|---|---|---|---|---|---|---|
| 2021.0.5.0 | 2021.0.5 | 2.6.13 | 2.2.3 | ||||
| 2021.0.9 | 2021.0.9 | 2.7.18 | 2.2.3 | ||||
| 2023.0.1.2 | 2024.0.1 | 3.4.4 | 2.5.1 |
注:以上3种版本组合是我在公司实战项目中使用过的版本组合。
3 nacos管理后台使用操作
3.1 配置命名空间
对于一个新项目,分别添加开发、测试、生产、公共配置命名空间。比如,对于xxx项目,可添加如下几个命名空间tyjt-dev、tyjt-test、tyjt-prod、tyjt-common:
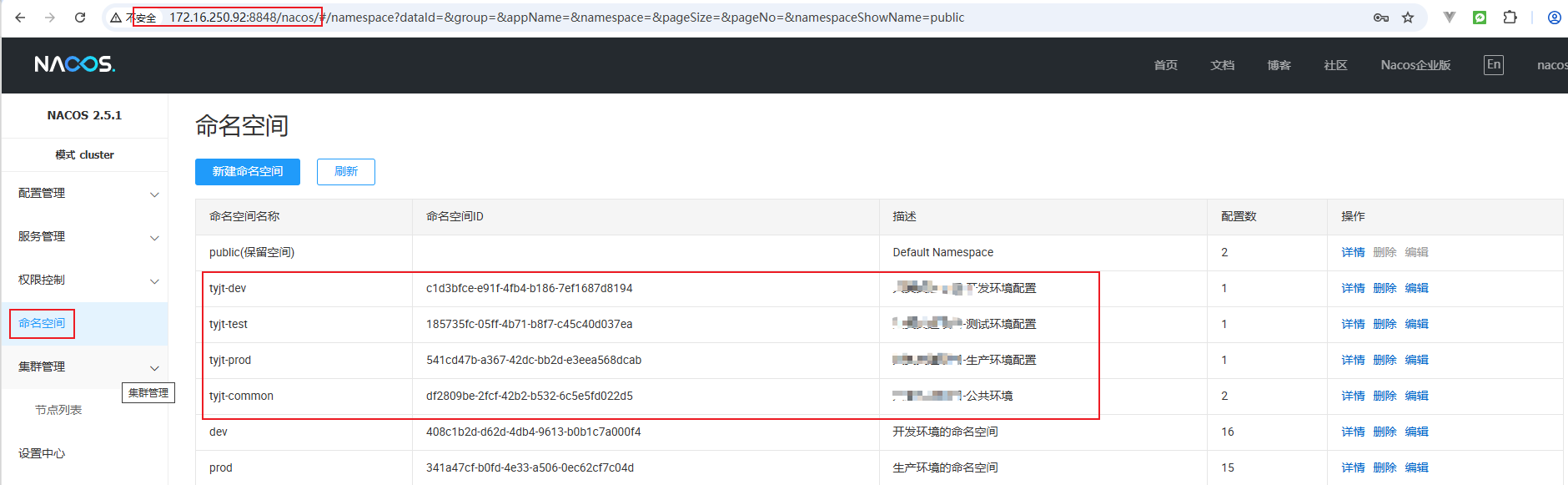
2.2 配置用户
对于不同开发部署环境,分别创建一个自己的用户,方便隔离管理。比如分别添加用户tyjt-dev、tyjt-test、tyjt-prod:
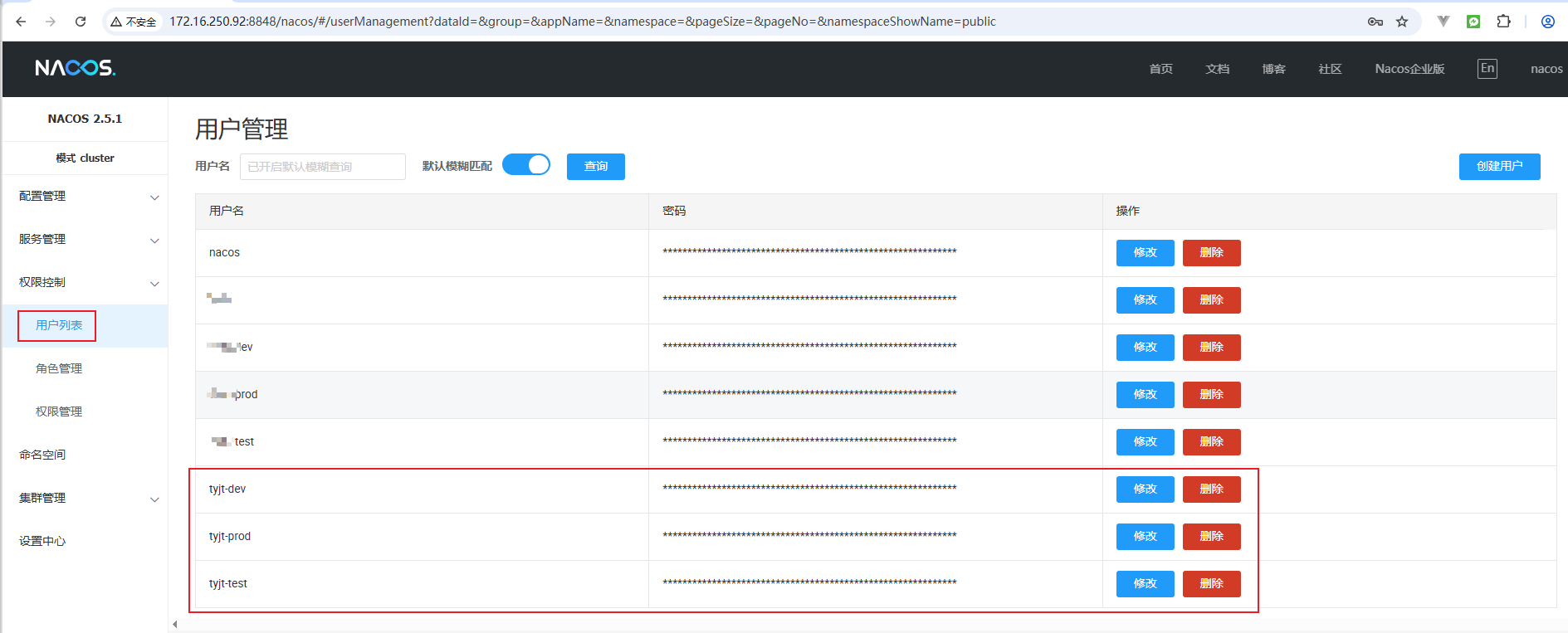
2.3 配置角色
针对不同的用户,添加不同的角色,做到角色细化管控。比如分别添加角色ROLE_TYJT_DEV、ROLE_TYJT_TEST、ROLE_TYJT_PROD,并分别赋给对应的用户:
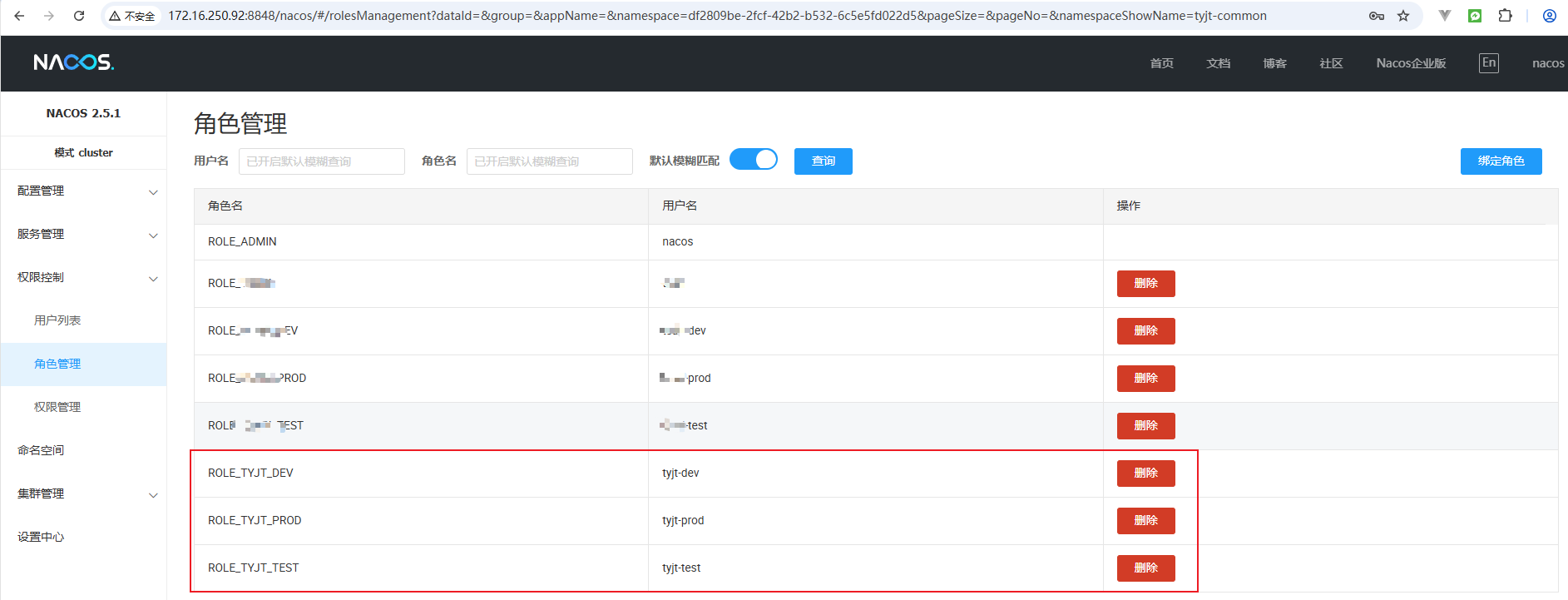
2.4 配置权限
针对不同的角色,添加不同的权限,做到权限细化管控。比如分别添加权限,并分别赋给对应的角色,并指明能访问哪些资源以及对应的能否读写操作:
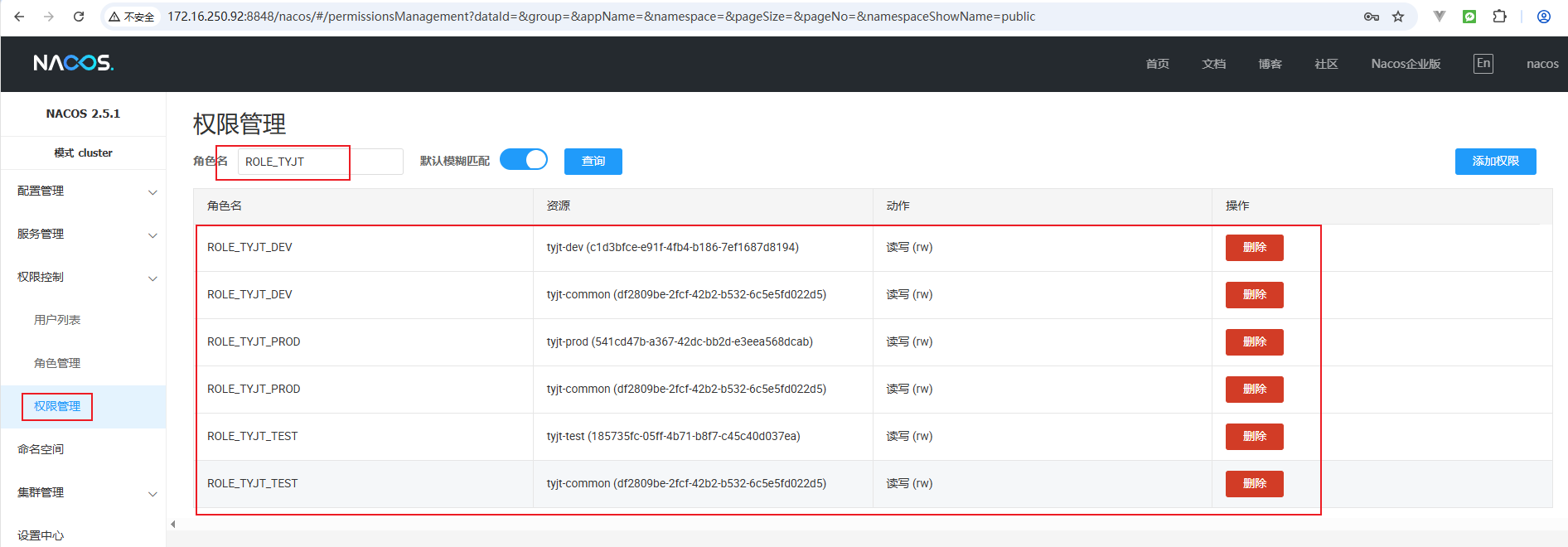
2.5 添加不同环境配置
2.5.1 配置dev开发环境
配置文件内容如下:
server:
port: 45000
#HBase
hbase:
config:
hbase:
zookeeper:
property:
clientPort: 2181
quorum: hbase01 #HBase主机IP
zookeeper:
znode:
parent: /hbase
#swagger文档开启/关闭
springfox:
documentation:
auto-startup: true
#knife4j
knife4j:
production: false # 开启/屏蔽文档资源
mqtt:
# mqtt入站(即根据topic订阅mqtt里的消息数据)
inbound:
clientId: mqtt-in-dev
#公网地址
#urls: tcp://xxx:1883
#内网地址
urls: tcp://172.16.250.134:8083
username: admin
password: xxx
topics:
points:
- road/BGFusionSSM
cars:
- isaelocation_fake
# mqtt出站(即发送数据到mqtt服务器)
outbound:
clientId: mqtt-out-dev
password: xxx
#若不指定topic则默认通过 /xyz/2w1/12q 来发送消息到mqtt服务器
topic: xyz/2w1/12q
urls: tcp://172.16.250.134:1883
username: admin
sys:
pack:
for:
algorithm:
periodMills: 30000 #每此打包多少时间的数据供算法调用(毫秒), 测试设备和测试点位的数据在内存中的保存时间应该=此数据*1.5
cacheMills: 50000 #供算法调用的数据在内存里边的缓存时间(毫秒),一般应该是period*1.5
radius: 0.2 #算法只检索车辆200m范围内的测试点位(km)
spring:
#spring boot admin配置
boot:
admin:
client:
# 指定admin-server的地址
url: http://localhost:${
server.port}/monitor # 提供监控服务的地址
context-path: /monitor
redis:
host: 172.16.250.84
port: 6379
distance: 8
database: 11
password: xxx
timeout: 10000ms
lettuce:
pool:
max-active: 100 # 连接池最大连接数(使用负值表示没有限制)
max-idle: 100 # 连接池中的最大空闲连接
min-idle: 50 # 连接池中的最小空闲连接
max-wait: 6000ms # 连接池最大阻塞等待时间(使用负值表示没有限制)
kafka:
bootstrap-servers: 172.16.250.84:9092
producer:
retries: 0
batch-size: 16384
buffer-memory: 33554432
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: xjcloudtrack-prod
# 手动提交
enable-auto-commit: false
auto-offset-reset: latest
key-deserializer: org.apache.kafka.common.serialization.ByteArrayDeserializer
value-deserializer: org.apache.kafka.common.serialization.ByteArrayDeserializer
properties:
session.timeout.ms: 60000
listener:
log-container-config: false
concurrency: 5
# 手动提交
ack-mode: manual_immediate
# 数据库连接信息
datasource:
# 指定数据源为 DruidDataSource,默认值为 HikariDataSource
#type: com.zaxxer.hikari.HikariDataSource
type: com.alibaba.druid.pool.DruidDataSource
dynamic:
primary: master #设置默认的数据源或者数据源组
strict: false
datasource:
master:
# driver-class需要注意mysql驱动的版本(com.mysql.cj.jdbc.Driver 或 com.mysql.jdbc.Driver)
driver-class-name: com.p6spy.engine.spy.P6SpyDriver
url: jdbc:p6spy:mysql://172.16.250.84:3306/xxx?autoReconnect=true&useServerPreparedStmts=false&rewriteBatchedStatements=true&characterEncoding=UTF-8&useSSL=false&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: root
password: xxx
druid:
#初始连接数
initial-size: 5
#最小连接数
min-idle: 5
#最大连接数
max-active: 20
#最大等待时间,单位为毫秒
max-wait: 60000
#空闲连接最小保留时间,单位为毫秒
min-evictable-idle-time-millis: 30000
#检测空闲连接间隔时间,如果连接空闲时间大于等于min-evictable-idle-time-millis则回收连接
time-between-eviction-runs-millis: 20000
#是否回收空闲连接,增强time-between-eviction-runs-millis
remove-abandoned: true
#空闲连接回收时,是否打印日志
log-abandoned: true
#空闲连接回收超时时间,单位为毫秒
remove-abandoned-timeout-millis: 30000
#空闲连接保持时间,单位为毫秒
keep-alive-between-time-millis: 30000
#是否保持连接有效,当连接空闲时间大于等于keep-alive-between-time-millis,小于min-evictable-idle-time-millis时生效
keep-alive: true
#检测连接是否有效查询
# validation-query: # select 1 或者 或者 SELECT 1 FROM DUAL,设置为空是为了防止不停的刷日志
#检测连接是否有效查询超时时间,单位为秒
validation-query-timeout: 1
#是否在申请连接时执行validation-query
test-on-borrow: false
#是否在归还连接时执行validation-query
test-on-return: false
#是否在申请连接时进行检测,如果空闲时间大于等于min-evictable-idle-time-millis,执行validation-query
test-while-idle: true
#是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说Oracle。在MySQL下建议关闭
pool-prepared-statements: false
#最大缓存数量,当大于0时,pool-prepared-statements会自动修改为true
max-pool-prepared-statement-per-connection-size: 0
#是否合并多数据源的监控数据
use-global-data-source-stat: true
#配置扩展插件,stat(监控统计),Slf4j(日志),waLL(防御SQL注入)
filters: stat,slf4j,wall
#监控页面配置
stat-view-servlet:
#是否启用监控页面配置
enabled: true
#监控页面路径
url-pattern: /druid/*
#用户名
login-username: druid
#密码
login-password: 123456
#是否允许重置
reset-enable: false
#白名单
allow: 127.0.0.1
#黑名单(IP在黑名单与白名单共同存在时,优先黑名单)
deny:
#Web统计过滤器配置
web-stat-filter:
#是否启用Web统计过滤器配置
enabled: true
#添加过滤规则
url-pattern: /*
#忽略过滤格式
exclusions: /druid/*,*.js,*.gif,*.jpg,*.jpeg,*.png,*.css,*.ico
#是否启用会话统计功能
session-stat-enable: true
#最大会话统计数量
session-stat-max-count: 1000
#过滤器配置
filter:
slf4j:
statement-create-after-log-enabled: false
statement-close-after-log-enabled: false
result-set-open-after-log-enabled: false
result-set-close-after-log-enabled: false
#SQL统计过滤器配置
stat:
#是否启用SQL统计过滤器配置
enabled: true
db-type: mysql
#是否启用慢SQL日志记录
log-slow-sql: true
#慢SQL执行时间,单位为毫秒
slow-sql-millis: 5000
#是否合并相同SQL
merge-sql: true
wall:
enabled: true
db-type: mysql
config:
multi-statement-allow: true
decorator:
datasource:
p6spy:
# logging: slf4j
log-file: ./log/spy.log
# log-format: executionTime:%(executionTime) | sql:%(sqlSingleLine)
enabled: true
oso:
kafka:
consumer:
topic: rs-DataAdapter-tracking_fake
point:
online:
position:
enable: true
schedule:
fixedRate: 10000 #单位为秒,即定时任务检测点位在线状态的频率是10s
initialDelay: 1000 #延迟1s开始执行
timeSlot: 60000 #查找最近60s内的数据
coordinate-origin:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3484
3484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











