







论文地址:ACCV_2020_paper.pdf
Abstract
简单介绍了本文贡献,当前SOTA的方法对短动作检测的准确率很低。本文是第一个分析了样本不均衡问题,并设计了一种新的尺度不变的损失函数来缓解短动作学习不够的问题。为了进一步实现提案生成任务,作者还采用了边界评价和提案完整性回归的pipline。
Introduction
作者发现,在时序动作检测中,在完整性预测中容易遗漏较短的动作,这反映为与较长动作相比,短动作的召回率极低。作者深入研究了这一现象,并得出结论,对短行为的不预测可能是由不平衡的正样本分布引起的。另一个限制性能提高的瓶颈是边界检测模块。目前的方法主要关注局部信息和低级特征,但在确定行动边界时忽略了关键的全局上下文。局部-全局组合是扩大这一瓶颈的一个直观和有希望的方向。
具体来说,TSI新采用了多分支时间边界检测器以高回归率和高准确率捕获动作边界。同时,由提出的尺度不变损失函数监督的IoU回归,能够回归准确的置信分数,特别是对于短动作。本工作的主要贡献总结如下:
1.以时间尺度问题为中心,我们分析了其背后的样本不平衡现象,并据此设计了一个尺度不变的损失函数来提高对短动作的检测性能。 2.为了实现完整的行动方案生成,TSI除了处理尺度问题外,还利用时间上下文进行了局部-全局-互补结构的边界检测,以提高性能。 3.对THUMOS14和ActivityNet基准测试进行了综合实验。结果表明,TSI优于其他最先进的动作提案生成方法,在ActivityNet上的AUC为68.35%。
Our Approach
Problem Definition and Video Representation
作者采用双流网络将视频X的原始RGB帧和光流编码为具有代表性的视频特征序列F∈ R C × T R^{C×T} RC×T,其中C为固定特征通道,T为视频特征长度。然后通过线性插值将特征序列重新缩放为长度D,最终得到特征F∈ R C × D R^{C×D} RC×D,作为动作建议生成网络的输入。
Scale-Imbalance Analysis in Proposal Generation
由于正负样本的不平衡问题,作者认为一个好的loss函数需要包含以下两点:1.每个GT的贡献应该是相等的 2.阳性/阴性样本应适当的平衡。为此,作者提出了尺度不变损失(SI损失):
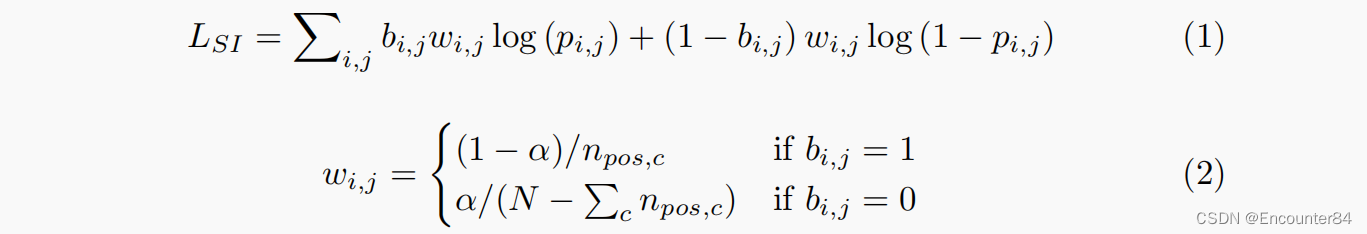
这样,考虑到正样本数分布,在视频中可以均匀地学习训练loss中的每个视频动作类别,从而达到了尺度不变的目的。此外,为了控制正负样本的平衡,在SI-Loss中采用了超参数α。当视频只包含一个annotation,α为0.5时,尺度不变损失将退化为正常的二进制逻辑损失。此外,当α大于0.5时,SI-Loss对阴性样本有较高的权重,这可以减少假阳性反应。在SI-Loss的监督下,在提案完整性回归模块中,检索小目标的能力大大提高。
Temporal Scale Invariant Network
在尺度不变损失的情况下,为了实现完整的动作proposal生成过程,我们结合了自下而上和自上而下的路径,提出了时间尺度不变网络。TSI的框架如下图所示,它包含两个模块:时间边界检测器(TBD)和IoU Map回归器(IMR)。

时间边界检测器:对动作边界的精确预测是一种执行良好的动作方案生成方法的必要条件之一。传统的方法认为边界是一种局部信息,不需要对时间上下文或深度语义特征的关注,因此它们都具有有限的接受域。
在TBD中,local分支观察到一个小的接受域,只有两个时间卷积层。因此,该分支关注于local突变,生成一个高召回率的粗糙边界,覆盖所有实际的起始/终点,但带来极低的精度。为了弥补这一缺点,global分支扩大了接受域,并以背景u型网络呈现边界,这是受到UNet的启发。global分支使用多个时态卷积层,然后进行降采样步骤来提取不同粒度的语义信息。为了恢复时间特征序列的分辨率,我们重复了多个上采样操作,并连接了相同分辨率下的特征。
下图是TBD架构的具体实现,TBD包含局部分支和全局分支,以高准确率、高回归率检测边界。c表示连接操作。conv1d(3,128)表示核大小为3和输出通道128的时间卷积层。ReLU用于激活功能。最后,利用2个通道的1x1卷积和sigmoid函数生成两个分支的起始和结束边界。综上所述,这种局部结构和全局结构的结合将最好地利用具有上下文特征的低级细粒度特征。

IoU Map Regressor:除了边界评价的自底而上路径外,提案置信回归对行动建议的生成也至关重要。为了密集回归潜在的建议置信度,我们采用了BMN中的边界匹配机制,该机制可以将时间特征序列F∈
R
C
×
D
R^{C×D}
RC×D通过BM层转移到建议特征矩阵MF∈
R
C
×
M
×
D
×
D
R^{C×M×D×D}
RC×M×D×D中。边界匹配机制本质上是用矩阵乘积实现的ROI对齐层。通过使用该模块,所有提案的完整性都可以同时进行回归。
Training and Inference
Training of TBD:
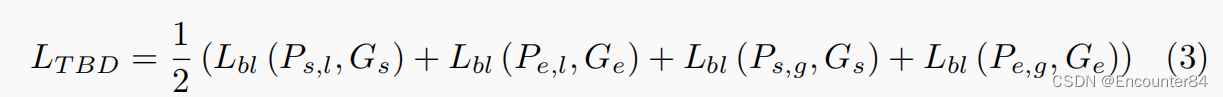
Loss of IMR:
作者使用提出的SI-Loss作为分类损失
l
c
l_c
lc,L2-Loss作为回归损失
L
r
L_r
Lr。
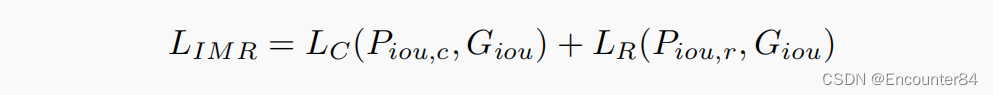
TSI的训练目标是在统一的框架下进行多任务学习。总体损失函数包含TBD损失、IMR损失和L2正则化项:

Inference of TSI:
方案选择:为了保证提案的多样性和保证高召回率,只使用TBD的Local branch进行提案选择。将所有边界概率满足(1)局部峰值和(2)概率大于0.5·max§的时间位置作为起始位置和结束位置。然后匹配所有的起始位置和结束位置,以生成候选提案。
分数融合和提案抑制。对每个proposal(i,j),其持续时间为i,开始时间为j,结束时间为i+j,其IoU完整性表示为分类得分和回归得分的融合。其起始概率记为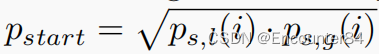
,与结束概率结束相同。因此,提案置信度评分定义为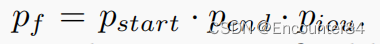
。然后采用Soft-NMS去除冗余提案,以检索最终的高质量提案。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









