







最近在写实现同样功能SQL语句,当使用DISTINCT时效率非常低,而GROUP BY 的效率远远高于DISTINCT.现贴出语句供参考.
这两条SQL语句功能为,查询清单表中有多少用户进行通话.
DITINCT语句:
--2395517 312S
SELECT COUNT(DISTINCT USR_ID) FROM APP.CR_GSM_DETAIL_MS_730_1312 WITH UR;
执行计划:
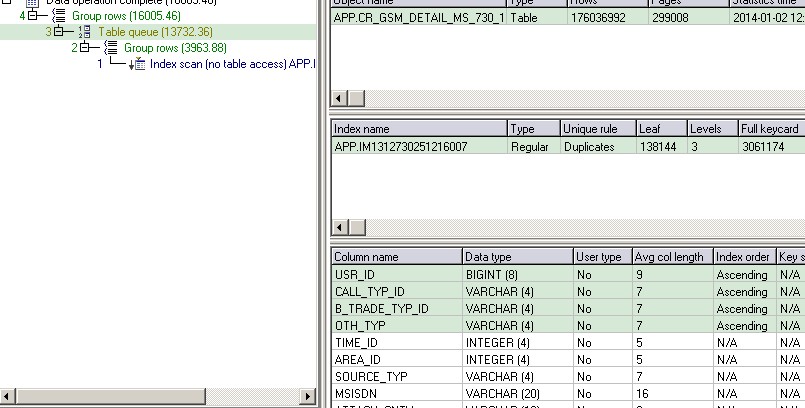
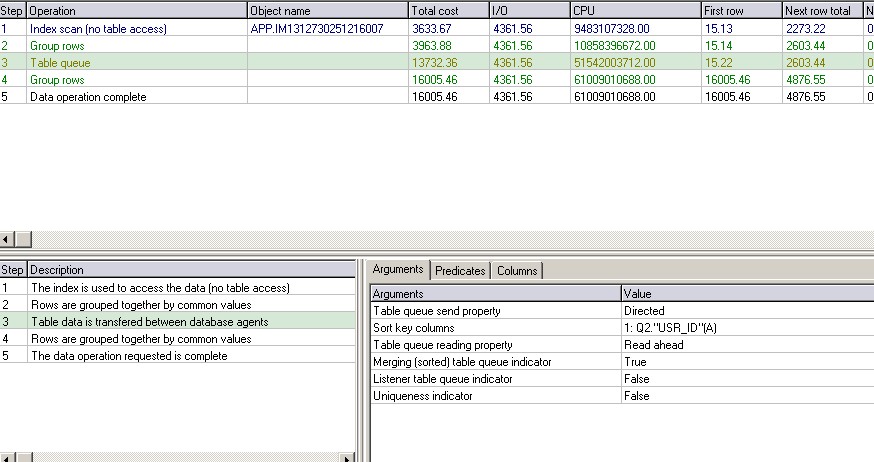
GROUP BY 语句:
--2395517 34.4S
SELECT COUNT(USR_ID) FROM(
SELECT USR_ID FROM APP.CR_GSM_DETAIL_MS_730_1312 GROUP BY USR_ID
)C
WITH UR;
执行计划:
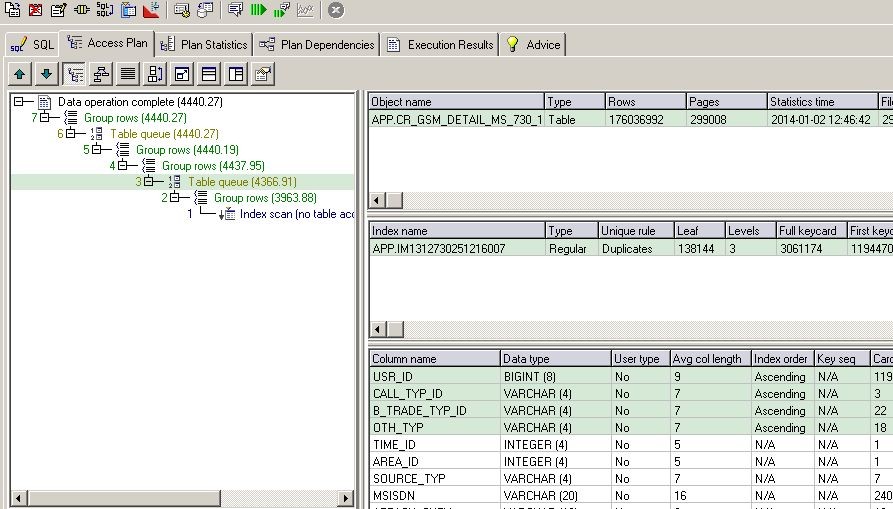
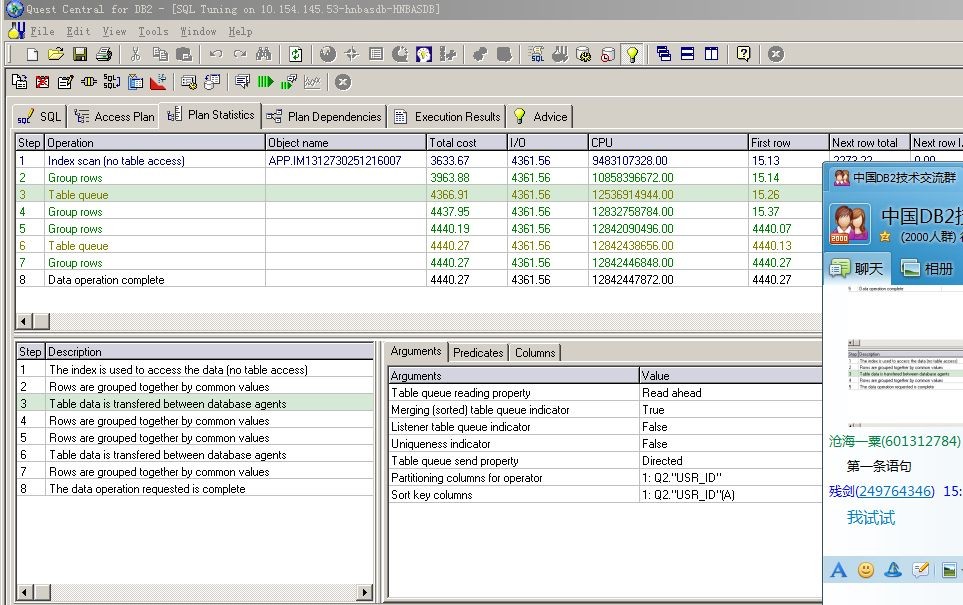
可以看到两条语句执行结果,一共有239万用户通话,DISTINCT语句执行时间312秒,GROUPBY 语句34.4秒.考虑缓存问题, 两条语句交叉执行三遍结果一样.
查看DB2资料没有找到group by与distinct相应的算法,但找到IBM官网上的sql编写建议:DISTINCT与GROUP BY 都进行排序操作,但DISTINCT要排序整个表,而GROUP BY是在分组之后再进行排序,所以可以解释DISTINCT效率低于GROUP BY.
从执行计划也可以证明IBM官方建议,从两条语句执行到第三步时,DISTINCT的CPU成本明显高于GROUP BY,但GROUP BY 的IO成本高于DISTINCT,因为它首先形成一个内嵌视力再做COUNT(*)操作.
根据以上分析可以得出:当一个表按分组字段来说,字段分组数据不是唯一但是要取字段唯一值,请使用GROUP BY .因为GROUP BY分组再排序,数据量相比DISTINCT大大减少.当一个按分组来说,数据是唯一的,那么DISTINCT与GROUP BY没有区别.















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









