






- 聚类算法(无监督学习)
- K-means(k-均值聚类):基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。(欧氏距离)
- 基本思想:基于给定的目标函数,算法采用迭代更新的方法,每次迭代向目标函数减少的方向更新,最终目标函数取极小值;
- 原理:
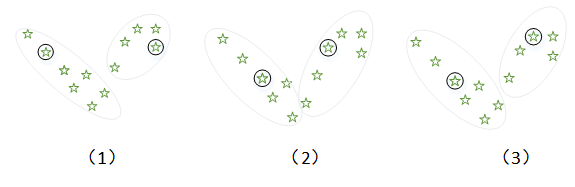
- 随机选择一个点,后在剩余的n-1个点中的尽可能选择距离最远的一个作为簇初始结点;
- 将K类别中的分别聚类到当前质心最近的簇中;
- 分配完所有结点,更新K簇质心位置;
- 将所有结点重新分配于最近的结点(在簇间移动);
- 重复3,4知道完成最终分类,结点在簇间不在移动;
基于sklearn框架使用:
![]()
2.基于密度聚类算法:从样本密度的角度来考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇,以获取最终聚类结果。
- DBSCAN:基于领域参数刻画样本分布紧密程度;
核心思想:先发现密度较高的点,然后把相近的高密度点逐步都连成一片,进而生成各种簇。
原理:
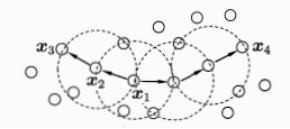
- 对每个数据点为圆心,以eps为半径画个圈(称为邻域eps-neigbourhood),然后数有多少个点在这个圈内,这个数就是该点密度值。
- 然后选取一个密度阈值MinPts,如圈内点数小于MinPts的圆心点为低密度的点,而大于或等于MinPts的圆心点高密度的点(称为核心点Core point)。
- 如果有一个高密度的点在另一个高密度的点的圈内,把这两个点连接起来,并将其串联起来。之后,如果有低密度的点也在高密度的点的圈内,把它也连到最近的高密度点上,称之为边界点。
- 把所有能连到一起的点聚类成为一个簇,而不在任何高密度点的圈内的低密度点就是异常点。
参考资料:https://blog.csdn.net/liudongdong19/article/details/80968459
3.经典的降维方法线性判别分析(Linear Discriminant Analysis,简称LDA):
在自然语言处理领域中,LDA指隐狄利克雷分布,是一种处理文档的主题模型。
LDA(线性判别分析):是一种监督学习的降维技术;数据集每个样本均有类别输出;PCA是不考虑样本类别输出的无监督降维技术。
算法流程:

LDA与PCA间的异同点:
| 相同点 | 不同点 |
| 1)两者均可以对数据进行降维。 2)两者在降维时均使用了矩阵特征分解的思想。 3)两者都假设数据符合高斯分布。 | 1)LDA是有监督的降维方法,而PCA是无监督的降维方法 2)LDA降维最多降到类别数k-1的维数,而PCA没有这个限制。 3)LDA除了可以用于降维,还可以用于分类。 4)LDA选择分类性能最好的投影方向,而PCA选择样本点投影具有最大方差的方向。 |
具体原理参考:https://blog.csdn.net/zhaoguanghua0407/article/details/78694791















 394
394











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









