







目录

前言
在上一篇中,我们学习了什么是文件,以及如何创建和关闭文件,但那些都是针对文件进行的操作,本篇我们就来讲解如何对文件内容进行操作。
什么是IO?
I/O是“Input/Output”的缩写,中文意思是“输入/输出”,指的是计算机系统与外部环境之间进行的数据交换的过程。我们从键盘输入数据、或者点击鼠标进行操作等这些都是属于输入操作;显示屏、声音这些都是属于输出操作。
当然,不仅局限于硬件设备的IO操作(磁盘IO),还有网络方面的I/O。
IO流原理
IO流是基于流(stream)的概念,将输入的数据和输出的数据看做一个连续的流。数据从一个地方流向另一个地方,流的方向可以是输入(读取数据)或者输出(写入数据)。
IO流的原理是通过流的管道将数据从源头传输到目标地。源头可以是文件、网络连接、内存等,而目标地可以是文件、数据库、网络等。IO流提供了一组丰富的类和方法来实现不同类型的输入和输出操作。
如何判断操作是输入还是输出?我们需要一个参照物,假设以CPU为参照物,那么我们可以认为靠近CPU的操作就是输入,而远离CPU的操作就是输出操作,即如果从CPU上向文件传输数据,那么对于CPU来说,就是在输出,而对于文件来说,这个操作是输入操作。

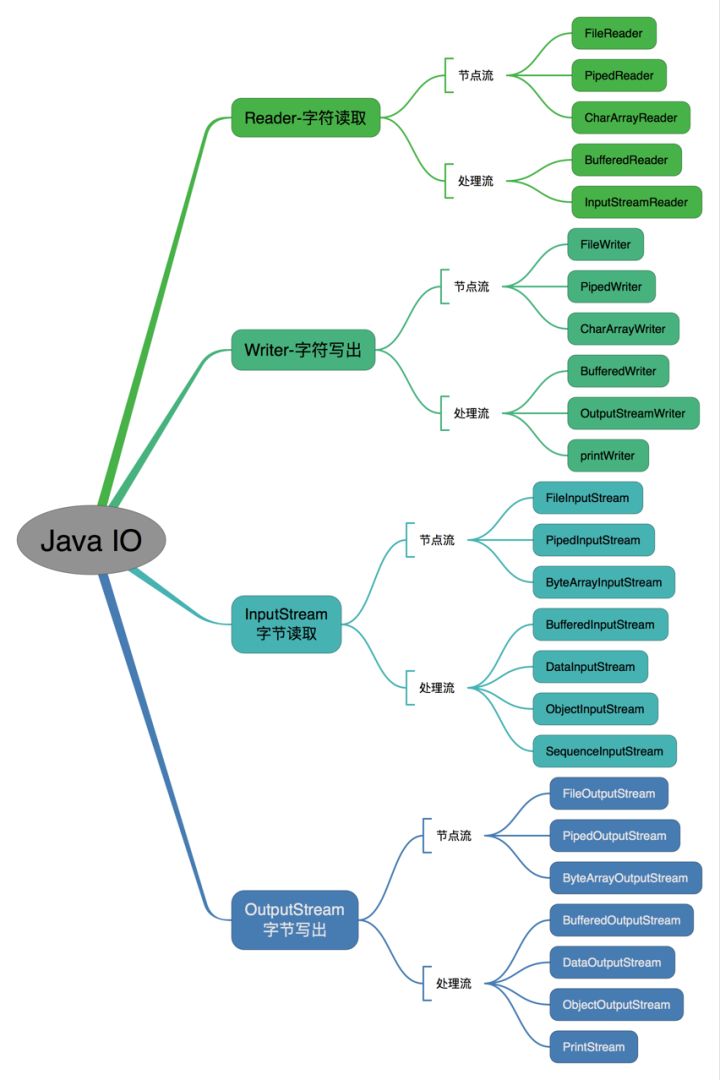
IO流分类
java中IO流可以按照数据的类型、流的方向和流的功能进行分类。
在Java中,IO流按照数据类型分为两类:
- 字节流 :读取数据的基本单位是字节,适用于处理二进制数据,如图像、音频、视频等,InputStream/OutputStream
- 字符流 :读取数据的基本单位是字符,适合处理文本数据。会自动进行字符编码和解码。Reader/Writer

一个字符有多少个字节?
这是不确定的,取决于编码方式,在UTF8中,一个字符是3个字节,而在Unicode中,一个字符是2个字节。
虽然分为两类,但是本质上都是字节流,不过字符流对字节进行了一些封装,根据字符集编码。
按照流的方向分类:
- 输入流(InputStream):用于读取数据。输入流从数据源读取数据,如文件、网络连接等。常见的输入流类有:FileInputStream、ByteArrayInputStream、SocketInputStream等。
- 输出流(OutputStream):用于写入数据。将数据写入到目标地,如文件、数据库、网络等。常见的输出流有:FileOutputStream、ByteArrayOnputStream、SocketOnputStream等。
按照流的功能分类:
- 节点流:直接和输入输出源交互。直接与数据源或目的地相连,没有额外的处理逻辑
- 处理流:间接和输入输出源交互。包装在节点流或其他处理流之上,添加额外的功能。
适用场景:
| 操作 | 场景 | 适用技术 |
| *文件操作 | 读写或写入文件中的数据 | 字节流:使用 FileInputStream 和 FileOutputStream 来读写二进制文件。 字符流:使用 FileReader 和 FileWriter 来读写文本文件。 缓冲流:使用 BufferedInputStream 和 BufferedOutputStream 或 BufferedReader 和 BufferedWriter 来提高文件读写的效率。 转换流:使用 InputStreamReader 和 OutputStreamWriter 来处理不同编码的文本文件。 |
| 网络通信 | 在网络上传输数据 | Socket 编程:使用 Socket 和 ServerSocket 类来实现客户端和服务端之间的通信。 字节流:使用 Socket 的 getInputStream() 和 getOutputStream() 方法来读写数据。 字符流:使用 Socket 的 getInputStream() 和 getOutputStream() 结合 InputStreamReader 和 OutputStreamWriter 来读写文本数据。 |
| 内存操作 | 在内存中创建或操作数据流 | 字节流:使用 ByteArrayInputStream 和 ByteArrayOutputStream 来处理内存中的字节数据。 字符流:使用 StringReader 和 StringWriter 来处理内存中的字符数据。 |
| 高效数据处理 | 需要高效地处理大量数据 | 缓冲流:使用 BufferedInputStream 和 BufferedOutputStream 或 BufferedReader 和 BufferedWriter 来提高读写速度。 NIO (New I/O):使用 FileChannel 和 ByteBuffer 来实现非阻塞的文件读写,以及内存映射文件等功能。 |
| 数据格式化 | 需要以特定格式读写数据 | 字节流:使用 DataInputStream 和 DataOutputStream 来读写基本数据类型。 对象序列化:使用 ObjectInputStream 和 ObjectOutputStream 来读写 Java 对象 |
| 异步 I/O | 需要非阻塞地处理 I/O 操作 | NIO.2 (Java 7+):使用 AsynchronousFileChannel 和 CompletionHandler 来实现真正的异步 I/O 操作 |
| 线程间通信 | 线程之间需要传递数据 | 管道流:使用 PipedInputStream 和 PipedOutputStream 来实现线程间的简单通信。 |
| 标准输入输出 | 控制台输入输出 | 字节流:使用 System.in 和 System.out 来处理标准输入输出。 字符流:使用 System.in 结合 InputStreamReader 和 System.out 结合 PrintWriter 来处理文本数据。 |
| 日志记录 | 记录程序运行时的信息 | 日志框架:使用如 Log4j、SLF4J 等日志框架来记录日志,通常使用字符流进行处理。 |
| 图形图像处理 | 处理图像文件 | 字节流:使用 ImageIO 类来读写图像文件,通常需要使用 FileInputStream 和 FileOutputStream。 |
| 音频视频处理 | 处理多媒体文件 | 字节流:使用 AudioSystem 和 javax.sound.sampled 包中的类来处理音频文件。 字节流:使用 javax.media 包中的类来处理视频文件。 |
本篇我们主要讲如何对文件内容进行操作。
InputStream和OutputStream都是抽象类,是所有字节输入流和输出流的父类。
InputStream字节流输入
InputStream是抽象类,是所有字节输入流父类。
在上面中,我们已经知道了InputStream是用来读入数据的。
InputStream常用方法
| 修饰符及返回值类型 | 方法签名 | 说明 |
| int | read() | 读取一个字节的数据,返回-1代表已经完全读完了 |
| int | read(byte[] b) | 最多读取b.length字节的数据到b中,返回实际读取到的数量;-1代表已经读完了 |
| int | read(byte[] b,nt off,int len) | 最多读取len-off字节的数据到b中,返回实际读取到的数量;-1代表已经读完了 |
| void | close() | 关闭字节流 |
InputStream 只是⼀个抽象类,要使⽤还需要具体的实现类。关于InputStream的实现类有很多,基 本可以认为不同的输⼊设备都可以对应⼀个InputStream类,我们现在只关心从文件中读取,所以使用FileInputStream。
文件输入流--FileInputStream
构造方法
| 签名 | 说明 |
| FileInputStream(File file) | 利用File构造文件输入流 |
| FileInputStream(String name) | 利用文件路径构造文件输入流 |
一般常用第二种构造方法,直接写入文本的绝对路径或者相对路径。
我们可以来看下:

我们可以看到当在创建一个文件流对象时,是需要抛出一个FileNotFoundException异常的。这是为什么呢? 我们可以看相关注释:如果命名的文件不存在,或者是一个目录或者是由于其他原因无法打开的时候,就会抛出FileNotFoundException异常。

同理的,我们可以看到若是传入一个文件对象,抛出异常的原因和上面基本一样。

 创建一个输入流对象
创建一个输入流对象
InputStream inputStream=new FileInputStream("./text1.txt");
如果文件不存在就会抛出异常,创建的过程其实就是打开文件的过程。

理解InputStream中的read方法
当我们创建完一个输入流对象之后,那么此时我们就可以调用read方法来读取文件中的数据了。
 我们可以看到有三个重载的read方法。InputStream是字节流,如果想要用数组来接收的话,需要传入一个字节数组。
我们可以看到有三个重载的read方法。InputStream是字节流,如果想要用数组来接收的话,需要传入一个字节数组。
我们可以看下不带参数的read方法。

这段话的大概意思就是从输入流中读取下一个字节的数据。返回一个取值返回在0~255的int类型的数据。如果读到流的结尾就会返回-1.
示例:假设现在已经有一个文本text.txt,我们往其中输入”你好“

我们可以查看一下“你好”转为16进制是什么,可以看到为“0xe4 0xbd 0xa0 0xe5 0xa5 0xbd”
在线字符串/十六进制互相转换—LZL在线工具 (lzltool.cn)

那么我们期望在从文本读取到的结果也与我们在所查找的一致
read():每次获取一个字节的数据
import java.io.IOException;
import java.io.InputStream;
public class Demo {
public static void main(String[] args) throws IOException {
InputStream inputStream=new FileInputStream("./text.txt");
while(true) {
int ch=inputStream.read();
if(ch==-1) break;
System.out.printf("0x%x ",ch);
}
}
}

read(byte[] b):将数据读取到字节数组中
但对于上述这种,每次从硬盘中读取一个字节,所带来的I/O次数太多,效率也不会很高。
所以我们传入一个字节数组去接受每次获取到的字节,尽可能的填满字节数组。
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
public class Demo1 {
/**
* 程序的入口点。读取并打印指定文件的二进制内容。
*
* @param args 命令行参数
* @throws IOException 如果文件不存在或无法读取,将抛出此异常
*/
public static void main(String[] args) throws IOException {
// 创建一个文件输入流,用于读取指定文件的内容
InputStream inputStream=new FileInputStream("./text.txt");
// 创建一个字节数组,用于存储从文件中读取的数据
byte[] bytes=new byte[1024];
// 读取文件中的数据到字节数组中,并返回实际读取的字节数
int ch=inputStream.read(bytes);
// 遍历已读取的字节数组,并以十六进制格式打印每个字节
for(int i=0;i<ch;i++){
System.out.printf("0x%x ",bytes[i]);
}
}
}

read(byte[] b,int off,int len):字节数组从off位置开始写入,最大不能超过len。
我们也可以让read从off位置开始向后读入。
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
public class Demo1 {
/**
* 程序的入口点。读取并打印指定文件的二进制内容。
*
* @param args 命令行参数
* @throws IOException 如果文件不存在或无法读取,将抛出此异常
*/
public static void main(String[] args) throws IOException {
// 创建一个文件输入流,用于读取指定文件的内容
InputStream inputStream=new FileInputStream("./text.txt");
// 创建一个字节数组,用于存储从文件中读取的数据
byte[] bytes=new byte[1024];
// 读取文件中的数据到字节数组中,并返回实际读取的字节数
int ch=inputStream.read(bytes,5,100);
// 遍历已读取的字节数组,并以十六进制格式打印每个字节
for(int i=5;i<ch+5;i++){
System.out.printf("0x%x ",bytes[i]);
}
}
}

关闭文件操作
当我们把所有的文件操作都完成之后,那么我们就得关闭文件,使用inputStream.close()。来防止文件资源泄露。但如果在执行这段代码之前就发生了异常,导致程序提前终止,那么这个文件就不会被关闭,所以我们需要使用异常处理机制来解决这个问题。
try {
//...
} finally {
inputstream.close();
}
通过try-finally语句,就可以保证finally中的代码无论如何都会被执行到。
但如果我们按照上面这种方法,可能就会写成:
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
public class Demo2 {
/**
* 程序的入口点。此方法用于读取指定文件并将其内容输出到控制台。
*
* @param args 命令行参数,本程序未使用。
*/
public static void main(String[] args) {
// 尝试打开一个文件输入流以读取文件内容。
try {
InputStream inputStream=new FileInputStream("./text.txt");
// 创建一个字节数组,用于存储从文件读取的数据。
byte[] bytes=new byte[1024];
// 读取文件内容到字节数组中。
int len=inputStream.read(bytes);
// 循环读取文件,直到文件末尾。
while (len!=-1){
// 将读取的字节数组转换为字符串并打印。
System.out.println(new String(bytes,0,len));
// 继续读取文件的下一部分内容。
len=inputStream.read(bytes);
}
}
// 如果文件不存在,抛出运行时异常。
catch (FileNotFoundException e) {
throw new RuntimeException(e);
}
// 如果发生IO错误,抛出运行时异常。
catch (IOException e) {
throw new RuntimeException(e);
}
}
}
这样看起来是不是不雅观?
那么有没有一种方法能够让我们的方法看起来更加简洁呢?
try (InputStream inputStream=new FileInputStream("./text.txt")) {
//....
}
上面这种语句叫做 try-with-resources 语句,这个语句的特性:当括号里的对象实现了 closerable 的话,当{}内的代码执行完之后会自动调用该对象的 close() 方法。

import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
public class Demo3 {
/**
* 程序的入口点
* 该方法用于读取指定文件并打印出文件内容的十六进制表示
* @param args 命令行参数,本程序未使用此参数
*/
public static void main(String[] args) {
// 尝试打开一个文件输入流以读取文件内容
try(InputStream inputStream=new FileInputStream("./text.txt")){
// 创建一个字节数组,用于存储从文件读取的数据
byte[] bytes=new byte[1024];
// 读取文件内容到字节数组中
int len=inputStream.read(bytes);
// 遍历已读取的字节数组,以十六进制格式打印每个字节
for(int i=0;i<len;i++){
System.out.printf("0x%x ",bytes[i]);
}
} catch (IOException e) {
// 捕获可能发生的IO异常,并打印异常信息
e.printStackTrace();
}
}
}
为什么不关闭文件,会造成文件资源泄露?
在前面,我们学习了进程和线程,当我们创建一个线程后,就有一个对应的PCB(进程控制块),而PCB中存在着多种属性,例如pid、、内存指针、文件描述表等。当在一个进程中打开一个文件,就需要在这个文件描述符表中分配一个元素,而这些元素存在一个长度固定的数组中,如果我们打开一个文件,并且不将文件关闭,这个数组中的元素就会越来越多,直到数组元素满了,就会出现文件资源泄露问题。
所以我们在用完文件之后,一定要关闭文件!
利用Scanner进行字符获取
在上述的例子中,其实我们可以看到对字符类型的直接使用InputStream进行读取是非常麻烦且困难的,所以,我们可以使用一种我们之前比较熟悉的类来完成该工作,就是Scanner类。
| 构造方法 | 说明 |
| Scanner(InputStream,String charset) | 使用charset字符集进行is的扫描读取 |
charset使用的是系统默认字符编码来读取。
我们可以使用下面的代码来查看系统的默认编码方式。
Charset defaultCharset = Charset.defaultCharset();
System.out.println("Default charset: " + defaultCharset.name());
示例:
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.Scanner;
public class Demo4 {
/**
* 程序的入口点
* 该方法用于读取指定文件中的内容,并将其打印到控制台
*
* @param args 命令行参数,本例中未使用
*/
public static void main(String[] args) {
// 尝试打开文件 "./text.txt" 以读取其内容,在文本内写入:你好
try(InputStream inputStream=new FileInputStream("./text.txt")){
// 创建扫描器以读取输入流中的数据
Scanner scanner=new Scanner(inputStream);
// 循环读取并打印文件内容,直到文件末尾
while(scanner.hasNext()){
System.out.printf("%s",scanner.next());
}
}catch (IOException e){
// 捕获并处理可能的IO异常
e.printStackTrace();
}
}
}
OutputStream字节流输出
OutputStream也是一个抽象类,是所有字节输出流的父类。
方法
| 修饰符及返回值类型 | 方法签名 | 说明 |
| void | write(int b) | 写入要给字节的数据 |
| void | write(byte[] b) | 将b这个字符数组中的数据全部写入os中 |
| int | write(byte[] b,int off,int len) | 将b这个字符数组中从off开始的数据写入到os中,一共写len个 |
| void | close() | 关闭字节流 |
| void | flush() | 重要:我们知道I/O的速度是很慢 的,所以,大多的OutputStream 为了减少设备操作的次数,在写数 据的时候都会将数据先暂时写⼊内 存的⼀个指定区域⾥,直到该区域 满了或者其他指定条件时才真正将 数据写⼊设备中,这个区域⼀般称 为缓冲区。但造成⼀个结果,就是 我们写的数据,很可能会遗留⼀部 分在缓冲区中。需要在最后或者合 适的位置,调⽤flush(刷新)操 作,将数据刷到设备中。 |
OutputStream同样只是⼀个抽象类,要使⽤还需要具体的实现类。我们现在还是只关⼼写⼊⽂件 中,所以使⽤FileOutputStream
文件输出流--FileOutputStream
既然我们知道了如何以字节为单位来读取文件数据,那么就来学习如何输出字节到文件中。
构造方法
| 签名 | 说明 |
| FileOutputStream(File file) | 利用文件构造文件输入流根据传入的文件,创建一个文件输出流对象 |
| FileOutputStream(File file,boolean append) | 利用文件构造文件输入流创建一个文件输出流对象,若append为true,说明保留文件中的内容,不清除 |
| FileOutputStream(String name) | 利用文件路径构造文件输入流 |
| FileOutputStream(String name,boolean append) | 利用文件路径构造文件输入流创建一个文件输出流对象,若append为true,说明保留文件中的内容,不清除 |
首先需要构造一个OutputStream对象。同样的,这里我们使用FileOutputStream来实例化一个输出流对象。这里同样需要抛出IO异常。
try(OutputStream outputStream=new FileOutputStream("./text.txt")){
//.....
}catch (IOException e){
e.printStackTrace();
}理解OutputStream中的write方法
我们知道OutputStream其实是一个抽象类,所以其中的方法也是需要其子类来实现,这里我们将FileOutputStream类。

我们可以看到其实与InputStream中的read的方法相似,都是由三个重载的方法.
我们可以看到当参数为int的时候,其实b的值对于的是ASCII码中的字符,其余两个方法的参数,与InputStream类似。
示例:假设现在我们要在一个空文本text中写入“你好”,那么我们可以查看其对于的16进制值。

0xe4 0xbd 0xa0 0xe5 0xa5 0xbd
write(int b):一次写入一个字节的数据
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
public class Demo5 {
/**
* 程序的入口点 主函数
* 将一组Unicode字符写入到文件中
*
* @param args 命令行参数,本程序中未使用
*/
public static void main(String[] args) {
// 使用try-with-resources语句确保文件流正确关闭
try(OutputStream outputStream=new FileOutputStream("./text.txt")){
outputStream.write(0xe4);
outputStream.write(0xbd);
outputStream.write(0xa0);
outputStream.write(0xe5);
outputStream.write(0xa5);
outputStream.write(0xbd);
}catch (IOException e){
// 捕获并处理可能的IO异常
e.printStackTrace();
}
}
}
运行前:

运行后:

当然,这样一个字节一个字节写入效率是很低的,所有我们可以使用字节数组。
write(byte[] b):最多读取b.length字节的数据到b中,返回实际读取到的数量;-1代表已经读完了
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
public class Demo6 {
/**
* 主函数,用于向指定文件写入字节数据
* @param args 命令行参数,本例中未使用
*/
public static void main(String[] args) {
// 使用try-with-resources语句确保文件流正确关闭
try(OutputStream outputStream=new FileOutputStream("./text.txt",true)){
// 定义要写入文件的字节数组,此处为"你好"的UTF-8编码
byte[] bytes={(byte) 0xe4, (byte) 0xbd, (byte) 0xa0, (byte) 0xe5, (byte) 0xa5, (byte) 0xbd};
// 将字节数组写入文件
outputStream.write(bytes);
}catch (IOException e){
// 捕获并处理可能的IO异常
e.printStackTrace();
}
}
}
这里我们可以在构造的时候传入一个true,不删除文本原有内容。且这里需要注意的是:
由于数组是字节型,但是我们16进制表示的时候,其实是整型,所以我们这里存储的时候需要强转为字节类型。
运行前:

运行后:

write(byte[] b,int off,int len):将b这个字符数组中从off开始的数据写入到os中,一共写len个
接着上面的程序,我们想要拼接个“好”
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
public class Demo7 {
/**
* 程序的入口点
* 使用try-with-resources语句确保文件流正确关闭,以向文件追加写入字节
* @param args 命令行参数,本程序不使用此参数
*/
public static void main(String[] args) {
// 使用try-with-resources语句确保文件流正确关闭
try(OutputStream outputStream=new FileOutputStream("./text.txt",true)){
// 定义要写入文件的字节数组,此处为"你好"的UTF-8编码
byte[] bytes={(byte) 0xe4, (byte) 0xbd, (byte) 0xa0, (byte) 0xe5, (byte) 0xa5, (byte) 0xbd};
// 将字节数组写入文件
outputStream.write(bytes,3,3);
}catch (IOException e){
// 捕获并处理可能的IO异常
e.printStackTrace();
}
}
}
运行前:
运行后:

有时候我们会看见我们运行程序之后,但是我们查看的时候,并没有写入的数据,这是为什么?
其实在写入数据的时候,并不是直接将内存中的数据写入文件中的,而是在这个过程中还会经过一个特殊的内存空间--缓冲区。当数据传入缓冲区的时候,缓冲区并不会立即将数据传输到文件中,而是当缓冲区中的数据达到一定大小之后,才会将这些数据一起传输到文件中。
为什么要有缓冲区这个东西呢?
数据从内存到缓冲区中的速度是很欢的,但是数据从缓存区到文件中速度是比较慢的。如果缓冲区中接收到了数据之后就立即将这些数据传输到文件中,这样的I/O次数就会很多,效率自然也高不了。就类似于:你的领导给你分配了一个任务,那么你就去执行,但在这个过程中,由于领导又临时给你分配了一些任务,如果你在这个过程中,完成一个任务就上交给领导一次,这样不仅效率低,领导对你的好感也会降低,所以,可以选择把任务都完成之后再交给领导,这样效率就提高了很多。这就是缓冲区的作用。
我们既然知道了数据在写入的过程中,会经过缓冲区,那么为什么在写入数据的时候,是数据最终没有被写入?这就是由于缓冲区内的数据太少,没有达到数据传入文件的大小,那么缓冲区就不会将接收到的数据传入文件,而这时由于程序执行结束,那么缓冲区内的数据就会被释放掉,导致数据最终没有被写入文件中。
因此,为了解决这个问题,我们在把数据都写入后,可以刷新一下缓冲区。outputstream.flush().
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
public class Demo7 {
/**
* 程序的入口点
* 使用try-with-resources语句确保文件流正确关闭,以向文件追加写入字节
* @param args 命令行参数,本程序不使用此参数
*/
public static void main(String[] args) {
// 使用try-with-resources语句确保文件流正确关闭
try(OutputStream outputStream=new FileOutputStream("./text.txt",true)){
// 定义要写入文件的字节数组,此处为"你好"的UTF-8编码
byte[] bytes={(byte) 0xe4, (byte) 0xbd, (byte) 0xa0, (byte) 0xe5, (byte) 0xa5, (byte) 0xbd};
// 将字节数组写入文件
outputStream.write(bytes,3,3);
outputStream.flush();
}catch (IOException e){
// 捕获并处理可能的IO异常
e.printStackTrace();
}
}
}
利⽤PrintWriter找到我们熟悉的⽅法
上述,我们其实已经完成输出⼯作,但总是有所不⽅便,我们接来下将OutputStream处理下,使⽤ PrintWriter 类来完成输出,因为 PrintWriter 类中提供了我们熟悉的print/println/printf方法。
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.io.PrintStream;
public class Demo8 {
/**
* 程序的入口点 主要用于演示如何向文件写入文本内容
* @param args 命令行参数,本例中未使用
*/
public static void main(String[] args) {
// 使用try-with-resources语句确保文件输出流在使用后能被正确关闭
try(OutputStream outputStream=new FileOutputStream("./text.txt")){
// 创建打印流,用于向文件输出流中写入可读的文本格式
PrintStream printStream=new PrintStream(outputStream);
// 向文件中写入并换行,以展示良好的文本格式
printStream.println("你好");
// 继续向文件中写入文本,不换行,以连续书写句子
printStream.print("世界");
// 使用格式化输出向文件中写入欢迎信息,增强文本的可读性
printStream.printf("\n欢迎来到程序人生");
}catch (IOException e){
// 捕获并处理可能发生的IO异常,避免程序因未捕获异常而终止
e.printStackTrace();
}
}
}

就此,我们关于如何以字节为单位对文件进行读取和写入操作就讲完了。
那么接下来,我们就来讲解如何以字符为单位对文件进行读取和写入操作,其实也就是对字节流的包装。
Reader读操作
Reader是一个抽象类,是所有字符输出流的父类。
所以如果我们要使用,需要使用其子类。我们可以看到,直接继承Reader的类有:

这里我们讲的是文件操作,所以我们使用FileReader类 。
我们可以看到,其实看起来像是FileReader继承了inputStreamReader,但其实不是。根据 Java 文档,FileReader 是直接继承自 InputStreamReader 的父类 Reader,并且它内部使用了一个 InputStreamReader 实例来完成从文件到字符流的转换。

FileReader 类的目的是为了简化从文件中读取字符的过程。它使用平台默认的字符编码来创建一个 InputStreamReader,这样用户就不需要关心底层的编码细节。FileReader 提供了一个更简便的方式来读取文件中的文本数据。
创建Reader对象
那么我们就可以根据Fileder类来实例化一个Reader对象。
FileReader的构造方法
| 签名 | 说明 |
| FileReader(File file) | 根据文件来构造FileReader对象。 |
| FileReader(String name) | 根据文件路径来构造FileReader对象 |
这里我们选择第二种方法:
try(Reader reader=new FileReader("./text.txt")){
//...
}catch (IOException e){
e.printStackTrace();
}创建 Reader 的过程就是打开文件的过程,如果文件不存在就会创建失败。

理解Reader类中的不同read方法
当我们创建出Reader对象之后,那么我们就可以读取文件中的内容了。

| 修饰符及返回值类型 | 方法签名 | 说明 |
| int | read() | 一次读取一个字符的数据,返回-1说明已经读完了 |
| int | read(char[] cbuf) | 一次读取若干个字符,直到把这个cbuf数组给填满 |
| int | read(char[] cbuf,int off,int len) | 一次读取若干个字符,并且将读取到的数据从 cbuf 的off位置开始,len长度的大小填充满 |
| void | close() | 关闭字符流 |
这里我们所需要的是字符,那么他为什么不用char作为返回值类型呢?
在java中,char类型是用来表示字符的,是一个16位的Unicode字符,可以有65536个不同的字节数。但是,我们read()需要能够返回一个特殊的值来表示文件结尾(EOF ,End and File)。所以,我们如果使用char类型,那么我们就无法表示这个特殊值。
为了解决这个问题,read()使用int作为返回类型。在java中,int是一个32位的整型,可以用来表示更大的范围。在Reader类中,read()返回废是一个int类型的值,其中0~65536表示实际的字符,而01表示文件结尾(EOF).
所以,在java中,Reader类的read()方法返回int类型是因为该方法需要能够表示所有可能的字符以及特殊值。
既然知道了read()的返回值为什么是int后,那么为什么返回的int值是2个字节的长度而不是三个字节的长度?
在java标准库 ,对字符编码做了很多操作。
如果我们只使用char,此时的字符集就是Unicode,每个字符都是2个字节;
如果我们使用String,此时就会把字符的Unicode编码转为UTF-8,在utf-8中,一个英文字符是1个字节,一个中文字符是3个字节。
char[] c = {'a','b','c'}; String s = new String(c);在上面代码中,c字符数组中一个字符占两个字节,但是如果将其转换为字符串的是,字符的编码方式就从Unicode转换为UTF-8编码了。
char cc=s.charAt(0);当我们取其中一个字符,获取到的字符就会从UTF-8编码转化为Unicode编码。
使用Reader中的read()方法
1.read():一次读取一个字符,当到文件结尾会返回-1。
这个方法的返回值就是将读取到的字符转换为int类型。

Reader抽象类实现了Closeable接口,所以可以使用try-with-resources语句。
示例:假设现在有文本文件text,在文本内存放:“你好”。

import java.io.FileReader;
import java.io.IOException;
import java.io.Reader;
public class Demo9 {
/**
* 程序的入口点
* 该方法打开并读取本地文件系统中的文本文件,并将文件内容打印到控制台
*
* @param args 命令行参数,本例中未使用
*/
public static void main(String[] args) {
// 尝试打开文件并创建一个Reader对象用于读取文件内容
try(Reader reader=new FileReader("./text.txt")){
// 循环读取文件中的每个字符,直到文件末尾
while(true) {
// 读取下一个字符,如果达到文件末尾,则返回-1
int n = reader.read();
// 如果达到文件末尾,则停止读取
if(n==-1) break;
// 打印读取的字符到控制台
System.out.printf("%c",(char)n);
}
}catch (IOException e){
// 捕获并处理可能的IO异常,例如文件不存在或无法读取
e.printStackTrace();
}
}
}
2.read(char[] cbuf):一次读取多个字符,将字符读取到cbuf字符数组中。
import java.io.FileReader;
import java.io.IOException;
import java.io.Reader;
public class Demo10 {
/**
* 程序的入口点
* 该方法用于读取指定文本文件的内容,并将其输出到控制台
*
* @param args 命令行参数,本程序未使用
*/
public static void main(String[] args) {
// 尝试读取名为text.txt的文件内容
try(Reader reader=new FileReader("./text.txt")) {
// 创建一个能够一次读取1024个字符的字符数组
char[] chars = new char[1024];
// 读取文件内容到字符数组中
int len = reader.read(chars);
// 遍历已读取的字符数组,输出每个字符到控制台
for(int i = 0; i < len; i++) {
System.out.printf("%c", chars[i]);
}
} catch (IOException e) {
// 如果在文件读取过程中发生错误,打印异常信息
e.printStackTrace();
}
}
}

第三个方法与我们前面讲的InputStream中的read方法是一样的意思的,不过Reader中读取的是一个字符,而InputStream中read读取的是一个字节。
利用Scanner进行字符获取
对于上面这样读取字符,可能效率比较低,所以我们也可以使用Scanner来进行字符获取。
示例:现有一个文本内让内容如下,要求使用Scanner进行读取。

import java.io.FileReader;
import java.io.IOException;
import java.io.Reader;
import java.util.Scanner;
public class Demo13 {
/**
* 程序的入口点
* 该方法用于读取指定文本文件的内容,并将其输出到控制台
*
* @param args 命令行参数,本程序未使用
*/
public static void main(String[] args) {
// 尝试读取名为text.txt的文件内容
try(Reader reader=new FileReader("./text.txt")) {
Scanner scanner=new Scanner(reader);
// 循环读取文件的每一行内容,并输出到控制台
while(scanner.hasNext()){
System.out.println(scanner.next());
}
} catch (IOException e) {
// 如果在文件读取过程中发生错误,打印异常信息
e.printStackTrace();
}
}
}

Writer写操作
Writer是一个抽象类,是所有字符输出流的父类。

与Reader所讲的差不多,这里进行文件操作,我们需要使用FileWriter。
创建Writer对象
FileWriter构造方法
| 签名 | 说明 |
| FileWriter(String name) | 根据文件路径来构造FileWriter对象 |
| FileWriter(String name,boolean append) | 根据文件路径来构造FileWriter对象,若append为true,说明保留文件中的内容,不清除 |
| FileWriter(File file) | 根据文件来构造FileWriter对象 |
| FileWriter(File file,boolean append) | 根据文件来构造FileWriter对象,若append为true,说明保留文件中的内容,不清除 |
这里我们使用通过指定文件路径来创建Writer对象。
理解Writer中的write方法
此处的write方法其实与我们前面讲的OutputStream的write用法基本相同。不过此处比OutputStream的write多了两个额外的重载的方法,可以直接写入字符串,这样就方便多了。
当我们指定的文件不存在,那么Writer就会帮我们创建一个文件。

这里由于和OutputStream的write类似,所以我们只讲2个字节流中没有的。
使用Writer中的write方法
1.write(String str):给文件写入一个字符串。
示例:从控制台输入一段字符串并写入到text.txt文本文件中,(若文本不存在,会自动创建)
import java.io.FileWriter;
import java.io.IOException;
import java.io.Writer;
import java.util.Scanner;
public class Demo11 {
/**
* 程序的入口点
* 从标准输入读取一行文本,并将其写入到文件中
*
* @param args 命令行参数,本程序中未使用
*/
public static void main(String[] args) {
// 创建Scanner对象,用于读取标准输入
Scanner scanner=new Scanner(System.in);
// 使用try-with-resources语句创建FileWriter对象,用于写入文件,自动管理资源
try(Writer writer=new FileWriter("./text.txt")){
// 读取标准输入中的一行文本
String str=scanner.nextLine();
// 将读取的文本写入文件
writer.write(str);
}catch (IOException e){
// 捕获IOException,打印异常信息
e.printStackTrace();
}
}
}运行中(等待输入):

运行结束:

2.1.write(String str,int off ,int len):给文件写入一个从off位置开始,长度为len的字符串。
示例:这里我们接着上面的例子,拼接上一段字符串。
import java.io.FileWriter;
import java.io.IOException;
import java.io.Writer;
import java.util.Scanner;
public class Demo12 {
public static void main(String[] args) {
// 创建Scanner对象,用于读取标准输入
Scanner scanner=new Scanner(System.in);
// 使用try-with-resources语句创建FileWriter对象,用于写入文件,自动管理资源
try(Writer writer=new FileWriter("./text.txt",true)){
// 读取标准输入中的一行文本
String str=scanner.nextLine();
// 将读取的文本写入文件
writer.write(str,2,2);
}catch (IOException e){
// 捕获IOException,打印异常信息
e.printStackTrace();
}
}
}
运行中(待输入):

运行后:

既然我们已经学习了文件的基本操作+文件内容的读写操作,那么就下来,我们就可以来实现一些小工具来锻炼我们的能力。
运用文件操作和IO实现一个删除指定文件的功能
要求:实现一个扫描指定目录,并且找到名称中包含指定字符的所有普通文件(不包括目录),并且后序访问用户是否要删除该文件。
思路:根据要求,我们要在一个指定的目录下寻找包含指定字符的文件,并询问是否要删除。我们知道文件底层其实是使用树形结构,那么我们就需要使用递归,当遇到目录的时候,就继续递归;当递归遇到文件的时候,就判断这个文件是否包含用户指定的字符。如果包含那么进行询问是否要删除。
代码实现:
import java.io.File;
import java.util.Scanner;
/**
* Demo类用于演示如何在指定目录中搜索并删除包含特定关键词的文件
*/
public class Demo {
/**
* 程序的入口点
* @param args 命令行参数,未使用
*/
public static void main(String[] args) {
// 创建Scanner对象,用于读取用户输入
Scanner sc = new Scanner(System.in);
// 提示用户输入目录路径
System.out.println("请输入你要扫描的目录路径:");
// 读取用户输入的目录路径
String path=sc.next();
// 根据用户输入的路径创建File对象
File root=new File(path);
// 检查所给路径是否为目录
if(!root.isDirectory()){
System.out.println("输入的路径不是目录");
return;
}
// 提示用户输入要删除的文件的关键词
System.out.println("请输入你要删除的文件的关键词:");
// 读取用户输入的关键词
String dest=sc.next();
// 调用fileSearch方法,在指定目录中搜索包含关键词的文件
fileSearch(root,dest);
}
/**
* 递归搜索指定目录下的文件,并对匹配关键词的文件进行删除确认
* @param root 搜索的根目录
* @param dest 要匹配并删除的文件的关键词
*/
private static void fileSearch(File root, String dest) {
// 列出目录下的所有文件和子目录
File[] files=root.listFiles();
// 如果该目录为空,则直接返回
if(files==null) return;
// 遍历目录中的每个文件或子目录
for(File file:files){
// 如果是文件,则检查是否匹配关键词并进行删除确认
if(file.isFile()){
doDelete(file,dest);
}else{
// 如果是目录,则递归搜索
fileSearch(file,dest);
}
}
}
/**
* 检查文件名是否包含关键词,如果包含则提示用户是否删除
* @param file 待检查的文件
* @param dest 关键词
*/
private static void doDelete(File file, String dest) {
// 检查文件名是否包含关键词
if(file.getName().contains(dest)){
// 提示用户找到匹配文件,并询问是否删除
System.out.println("当前文件为:"+file.getAbsoluteFile()+", 是否要删除(Y/N)?");
// 创建Scanner对象,用于读取用户输入
Scanner sc=new Scanner(System.in);
// 读取用户的删除选择
String choice=sc.next();
if(choice.equals("Y")){
// 如果用户选择删除,则执行删除操作
file.delete();
System.out.println("删除成功");
}else{
System.out.println("取消删除");
}
}
}
}

复制指定文件
进⾏普通⽂件的复制,通过传入一个要被复制的文件的路径,判断是否是文件,如果是文件,则进行下一步操作;反之,则直接返回。输入要复制到的文件路径,判断该文件是否存在,如果存在就需要判断是否要进行覆盖;反之则直接返回。通过字节流来复制。
import java.io.*;
import java.util.Scanner;
/**
* Demo1类用于演示文件复制的功能
*/
public class Demo1 {
/**
* 主函数,用于处理文件复制的流程
* @param args 命令行参数,未使用
*/
public static void main(String[] args) {
// 创建Scanner对象,用于从命令行读取用户输入
Scanner sc = new Scanner(System.in);
// 提示用户输入源文件路径,并读取
System.out.println("请输入你要复制的文件的路径:");
String src = sc.next();
// 根据输入的路径创建File对象
File scFile = new File(src);
// 检查源文件是否存在
if (!scFile.exists()) {
System.out.println("您输入的文件不存在,请确认文件路径的正确性");
return;
}
// 检查源文件是否为文件夹
if (scFile.isDirectory()) {
System.out.println("您输入的是一个文件夹,请输入一个文件路径");
return;
}
// 提示用户输入目标文件路径,并读取
System.out.println("请输入你要复制到的目标路径:");
String dest = sc.next();
// 根据输入的目标路径创建File对象
File destFile = new File(dest);
// 检查目标路径是否已存在文件
if (destFile.exists()) {
// 如果目标路径是一个目录而不是文件,则提示错误
if (destFile.isDirectory()) {
System.out.println("您输入的路径是一个目录,不是文件,请确认文件路径是否正确");
return;
}
}
// 如果源文件是文件,则进行以下操作
if (scFile.isFile()) {
// 如果目标文件已存在,则询问用户是否覆盖
if (destFile.exists()) {
System.out.println("您要复制到的文件已经存在,是否需要覆盖:Y/N");
String choice = sc.next();
// 如果用户选择不覆盖,则退出程序
if (!choice.equalsIgnoreCase("Y")) return;
}
}
// 使用try-with-resources语句复制文件内容
try (InputStream inputStream = new FileInputStream(scFile);
OutputStream outputStream = new FileOutputStream(destFile)) {
// 创建字节数组用于读取文件内容
byte[] bytes = new byte[1024];
// 循环读取源文件内容直到末尾
while (true) {
// 读取字节数组的下一个块
int n = inputStream.read(bytes);
// 如果读取到文件末尾则退出循环
if (n == -1) break;
// 将读取的内容写入目标文件
outputStream.write(bytes, 0, n);
}
} catch (IOException e) {
// 处理异常
e.printStackTrace();
}
}
}
示例:复制图片
现有一张图片,我们想要给他复制一张那么我们就得找到其相应的文件路径

输入对应的文件路径,并指定一个目标路径


在指定目录中查找文件名或文件内容含有关键词的文件
import java.io.*;
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
public class Demo2 {
/**
* 主函数,用于交互式输入目录和关键词,并打印出包含关键词的文件
* @param args 命令行参数
*/
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
System.out.println("请输入你要扫描的目录:");
String root = sc.next();
File rootFile = new File(root);
if (!rootFile.exists()) {
System.out.println("目录不存在");
return;
}
if (!rootFile.isDirectory()) {
System.out.println("您输入的路径不是正确的目录路径,请检查你输入的路径");
return;
}
System.out.println("请输入你要查找的文件名或者文件内容中包含中包含的关键词:");
String word = sc.next();
List<File> list = new ArrayList<>();
Serach(rootFile, word, list);
for (File file : list) {
System.out.println(file.getAbsoluteFile());
}
}
/**
* 递归搜索目录下包含特定关键词的文件
* @param rootFile 根目录文件对象
* @param word 关键词
* @param list 保存匹配文件的列表
*/
private static void Serach(File rootFile, String word, List<File> list) {
File[] files = rootFile.listFiles();
if (files == null) return;
for (File file : files) {
if (file.isDirectory()) {
Serach(file, word, list);
} else {
if (isContainsContent(file, word)) {
list.add(file);
}
}
}
}
/**
* 检查文件是否包含特定内容
* @param file 待检查的文件
* @param word 关键词
* @return 如果文件名或文件内容包含关键词,返回true;否则返回false
*/
private static boolean isContainsContent(File file, String word) {
if (file.getName().contains(word)) return true;
StringBuilder sb = new StringBuilder();
try (InputStream inputStream = new FileInputStream(file)) {
Scanner scanner = new Scanner(file);
while (scanner.hasNextLine()) {
sb.append(scanner.nextLine());
if (sb.indexOf(word) != -1) return true;
}
return false;
} catch (IOException e) {
e.printStackTrace();
}
return false;
}
}

以上就是本篇IO操作的所有内容啦,若有不足欢迎指正~
















 607
607

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











