






日常音视频开会中我们或多或少会遭遇这些场景:“喂喂喂,可以听到我说话吗?我听你的声音断断续续的”,“咦,我怎么可以听到回声?”,“太吵啦,我听不清楚你在说啥” 等等。这些语音质量问题影响音视频开会体验,如若是重要的会议,那足够让人 “恼羞成怒”。那么如何有效的减少这些问题发生呢?本系列文章就将为大家分享阿里云视频云在保障 RTC 语音质量方面的测试经验。
作者|柯淮
审校|泰一
背景介绍
音频质量是指正常网络下的听觉质量和音频 3A 算法质量。听觉质量,是在无损网络情况下人耳对语音优劣的主观感受。但在实际生活中,不同人对同一声音可能会有不同的优劣判断,另外还会受到收听环境和收听心理影响。在测试时,我们可以从声音三要素:响度、音高、音色纬度出发,对一些指标进行量化评估。另外业内标准还会将这些量化指标通过一定的加权处理以期望拟合主观感受,比如 POLQA、PESQ 等。
音频 3A 算法是指:
AGC: Automatic gain control(自动增益控制)
ANS: Adaptive noise suppression(噪声抑制)
AEC: Acoustic echo cancellation(回声消除)
这部分内容公众号中已有较多文章较详细介绍原理及实现,这里不再赘述。
往期文章
详解 WebRTC 高音质低延时的背后 — AGC(自动增益控制)
硬货专栏 |深入浅出 WebRTC AEC(声学回声消除)
本系列文章将从音频质量、适配测试、Qos 质量、自动化方案四个纬度去介绍阿里云视频云如何保障 RTC 语音质量,本文先介绍音频质量部分(正常网络下的听觉质量和音频 3A 算法质量)。
RTC 语音测试链路拆解
在正式测试前,我们先了解 RTC 语音传输的整个链路框架图,声音通过麦克风采集,而后上行音频算法进行前处理,编解码传输后通过扬声器播放出来。若想测试上行音频算法可在(1)处输入声音,而后在(2)处拉取输出音频进行分析。系统测试时,我们往往从端到端角度评估,即从(1)处输入声音而后在(4)拉取声音进行分析,本文后续测试方法均基于端到端。
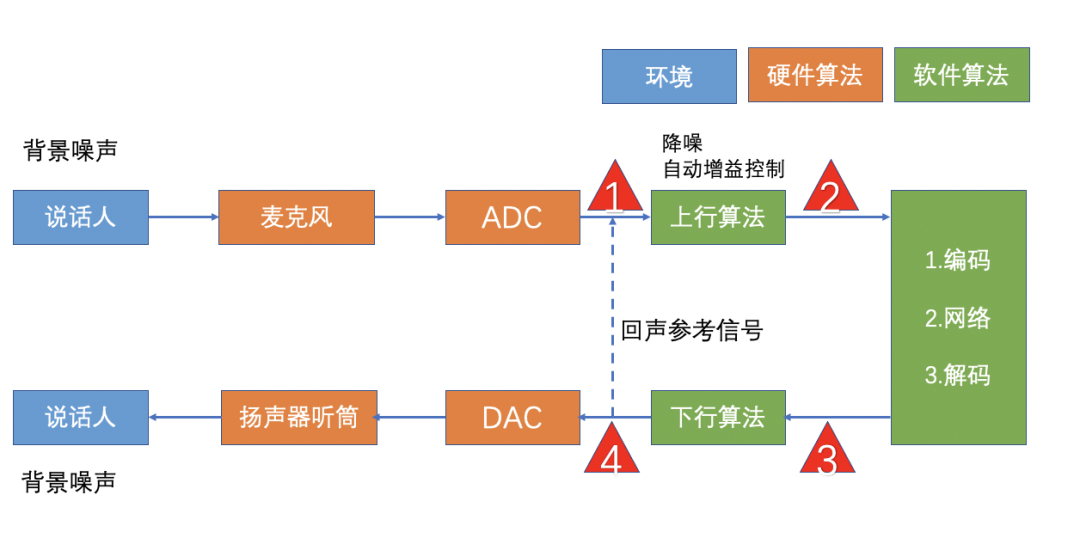
音频质量测试方案
阿里云视频云采用业内常用的客观指标+主观评价相结合的方法来保障音频质量,具体指标请参考下图:

客观测试方法
有效频宽
Line in 输入扫频文件 +48K 采样率的人声音频(音频素材参考如下),Line out 录制输出音频,通过频率分析读取有效频宽;

端到端延迟
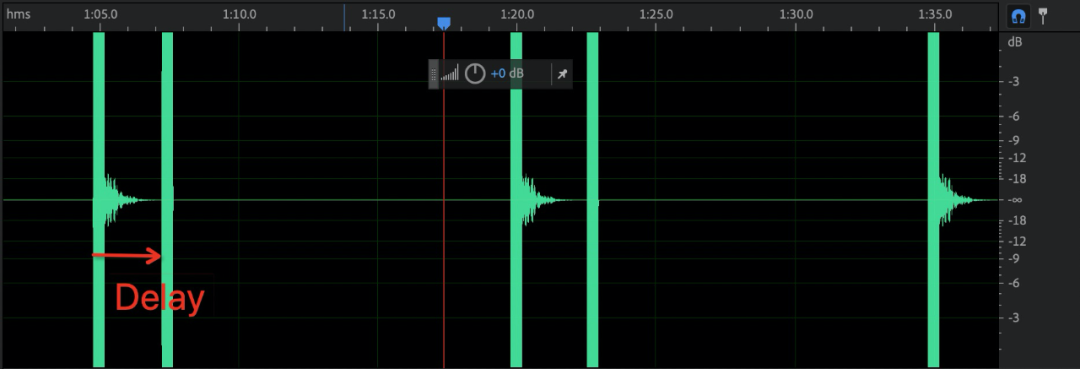
方法一:使用 VQT 测试,测试结果中输出延迟时间。
方法二:自研。Line in 测试素材,Line out 录制未经过传输及输出音频,计算音频延迟时间。
测试素材:一段连续的单音。
指标计算:录制文件中读取未经过传输的音频起始时间记为 t1,读取经过会议传输的音频起始时间记为 t2,则 Delay=t2-t1。
ANS
考察 ANS 算法在纯噪声和语噪混合场景下的表现,分析指标包含:降噪一致性、信噪比提升、收敛时间、消噪后人声音质。
测试拓扑
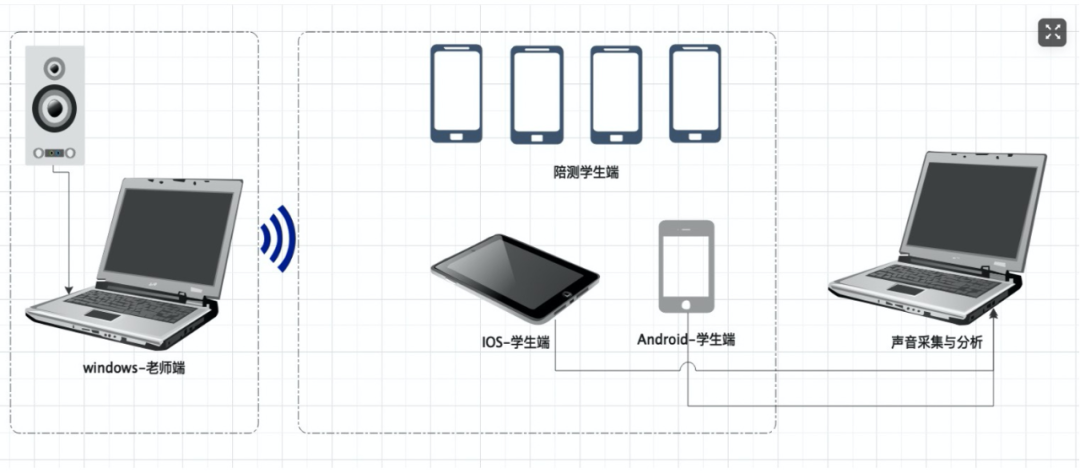
通过音量 Line in 或者外放输入背景素材及语音素材,在拉流端 Line out 录制输出音频进行指标分析。
测试素材
分类 | 音频素材 | 音频素材 |
声学噪声 | 白噪声 | 如下是粉红噪声示意图:
|
粉红噪声 | ||
真实环境噪声 | 咖啡馆噪声 | 如下是办公环境噪声示意图:
|
汽车空间内噪声 | ||
会议室空间内噪声 | ||
办公环境噪声 | ||
餐馆环境噪声 | ||
地铁站/高铁站环境噪声 | ||
街道环境噪声 | ||
带噪人声 | 信噪比10dB | 如下是信噪比为10dB的带噪人声:
|
信噪比15dB | ||
信噪比25dB |


指标计算
1. 信噪比提升:求取经过消噪后音频的信噪比为 A,则信噪比提升值 =A- 输入信噪比。
2. 降噪一致性:计算各种噪声输入后噪声的残留值,并统计各种噪声下噪声残留是否一致。
3. 收敛时间:记录噪声能量开始下降的时间为 t1,记录噪声已收敛至平稳的初始时间 t2,收敛时间 =t2-t1。
4. 音质:改造 VQT POLQA 测试脚本,计算不同信噪比输入下输出音频 MOS 分。下表展示输入信噪比为 10dB 带噪人声,输出音频音质 MOS 分:

AGC
考察AGC算法在不同音量下表现,分析指标包括:声音平稳性、输出响度。
测试拓扑
参考 ANS 测试拓扑图,通过音量 Line in 或者外放输入语音素材,在拉流端 Line out 录制输出音频进行指标分析。
测试素材
分类 | 音频素材 | 音频素材 |
阶梯音量人声 | “大-小-大”平稳性声音素材(以3dB步长音量增减) | 如下是“大-小-大”平稳性声音素材示意图:
|
不同音量男声&女声(打分) | 小音量(打分) | 如下是用于打分中音量人声:
|
中音量(打分) | ||
大音量(打分) |


指标计算
1. 声音平稳性:计算输出音频各音量段的平均 RMS,而后求解这个输出音频的平均 RMS 的方差。如下是平均 RMS 的计算公式:

2. 输出响度:Line out 方式计算输出音频的平均 RMS;外放方式使用标准声压计,以 A 计权方式记录响度值。
3. 音质:改造 VQT POLQA 测试脚本,计算不同音量输入下输出音频 MOS 分。下表展示大中小音量输入下,输出音频音质 MOS 分:

AEC
考察 AEC 算法单讲和双讲场景下是否存在漏回声、人声抑制等问题。
测试拓扑
【单讲】
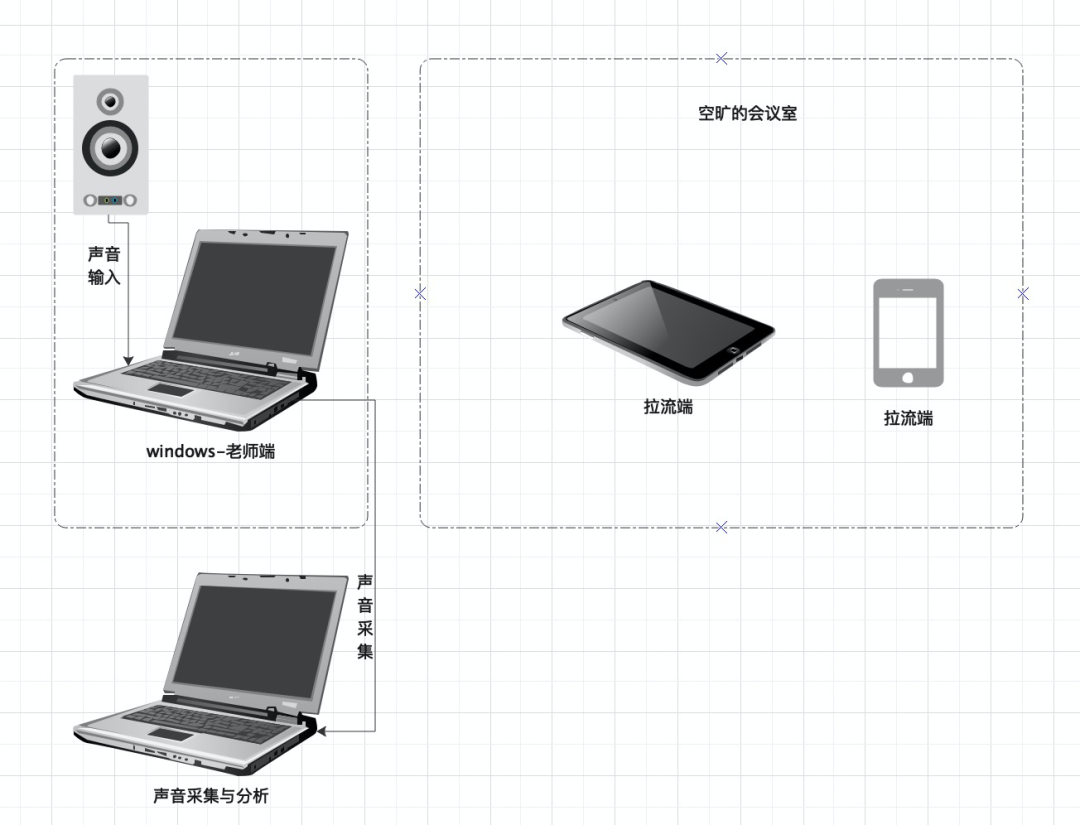
推流端播放单讲语音素材,拉流端默认配置放在空旷会议室中。Line out 录制推流端的输出,判断拉流端是否存在漏回声。
【双讲】
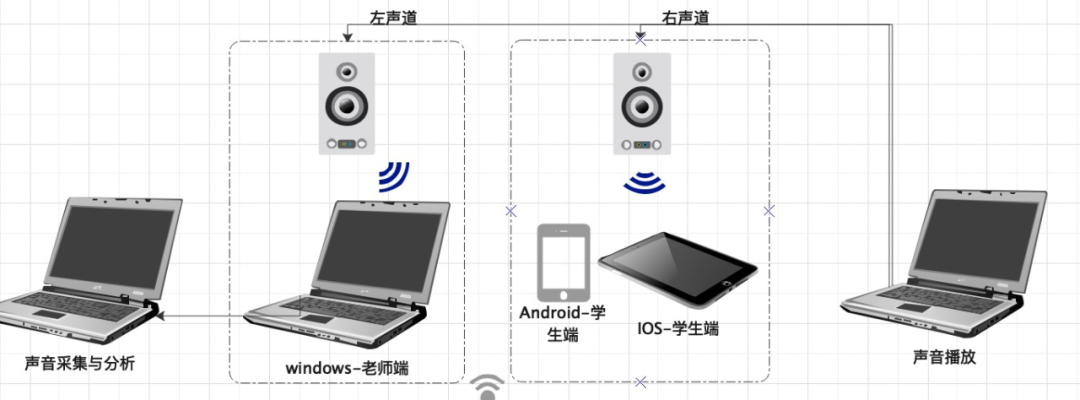
同时向推流端和拉流端播放双讲测试素材,Line out 录制推流端的输出,判断拉流端是否存在漏回声和人声抑制。
同时向推流端和拉流端播放双讲测试素材,Line out 录制推流端的输出,判断拉流端是否存在漏回声和人声抑制。
测试素材
分类 | 音频素材 | 音频素材 |
单讲 | 连续标准人声素材(男声、女声、孩童、老人) | 连续人声素材示意图:
|
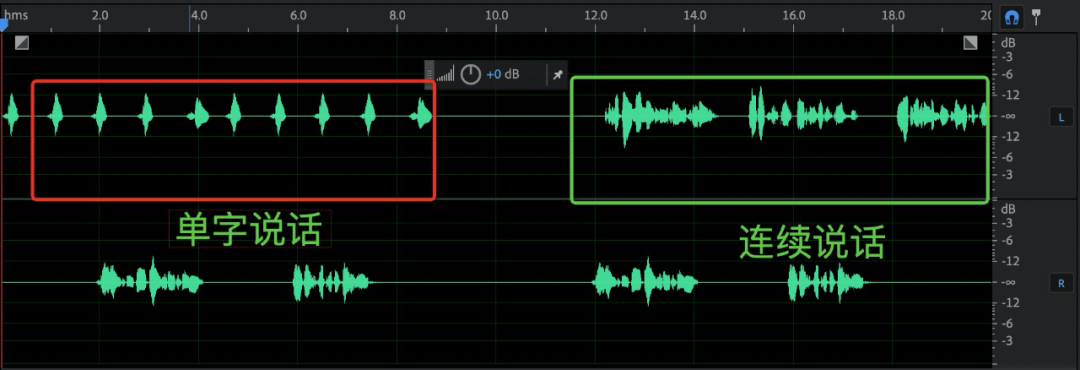
双讲 | 双讲人声素材(包含连续说话、单字说话) | 双讲人声素材(包含连续说话、单字说话)示意如下:
|

指标计算
1. 漏回声:读取录制音频文件的人声残留量,理论上该处值为 0- 没有漏回声。
2. 人声抑制:双讲场景下评估此指标。利用 3gpp TS 26.132 标准评价剪切情况,最终评价以 D 类(连续剪切大于 150ms)为标准,值越接近于 0 质量越好。
3. 收敛时间:测试开始时间记为 t1,AEC 收敛完成无漏回声出现时间记为 t2,收敛时间 =t2-t1。
4. 人声音质:双讲场景下评估此指标。改造 VQT POLQA 测试脚本,计算双讲场景下人声的音质得分。
STOI
短时客观可懂度,当前学术上比较精确,可靠的客观评估方法来计算语音可懂度,客观测试结果可以一定程度上反映语音可懂性和自然性。存在局限性:需降采样到 16K 进行计算。
测试拓扑:参考 ANS 测试拓扑。
测试素材:ITU-P863 提供标准人声素材。
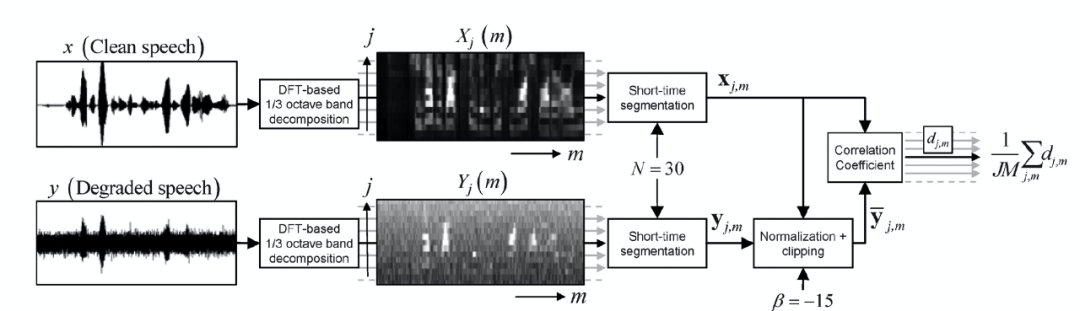
指标计算:如下框架图展示了 STOI 计算流程,当前业内已有 matlab 和 python 对该算法的工程实现。
POLQA
ITU-T P.863 提供测试方法,可得到 MOS 分和音频延迟。支持 8K、16K、48K 测试,局限性是设备贵。
测试拓扑:参考 ANS 测试拓扑。
测试素材:ITU-P863 提供标准人声素材 &VQT 内置语音测试素材。
指标计算:POLQA MOS 分。
PESQ
ITU-T P.862 提供测试方法,可得到 MOS 分,局限性是仅可支持 8K 和 16K。
测试拓扑:参考 ANS 测试拓扑。
测试方法:测试素材:ITU-P863 提供标准人声素材。
指标计算:PESQ MOS 分
主观测试方法
采用 “YD/T 2309 音频质量主观测试方法(ITU-R BS.1284)” 中提及的评分规则和维度,在不同场景下为专家和普通用户进行打分测试。
评分方法

评价维度

测试场景
测试素材采用“惠威试音碟”和“TUT-acoustic-scenes-2017-development”。

技术交流,欢迎加我微信:ezglumes ,拉你入技术交流群。

推荐阅读:
觉得不错,点个在看呗~
















 7750
7750











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









