







本文将深入介绍如何使用Python结合XPath来爬取汽车之家二手车信息,包括对汽车之家二手汽车网站的HTML结构解析。
顺便吐槽一下,二手车也不便宜,特别是宝马。
一、准备工作
首先,我们需要导入lxml库中的etree模块。这个模块提供了强大的功能来处理HTML和XML数据。
# 导入相关库
from lxml import etree
二、读取数据
在代码中,我们指定了本地文件goods.html作为数据来源。这是我事先保存好的汽车之家二手车页面的HTML文件。通过with open语句以UTF - 8编码读取文件内容,并将其存储在html变量中。
网站源代码见官网:
汽车之家二手车网站
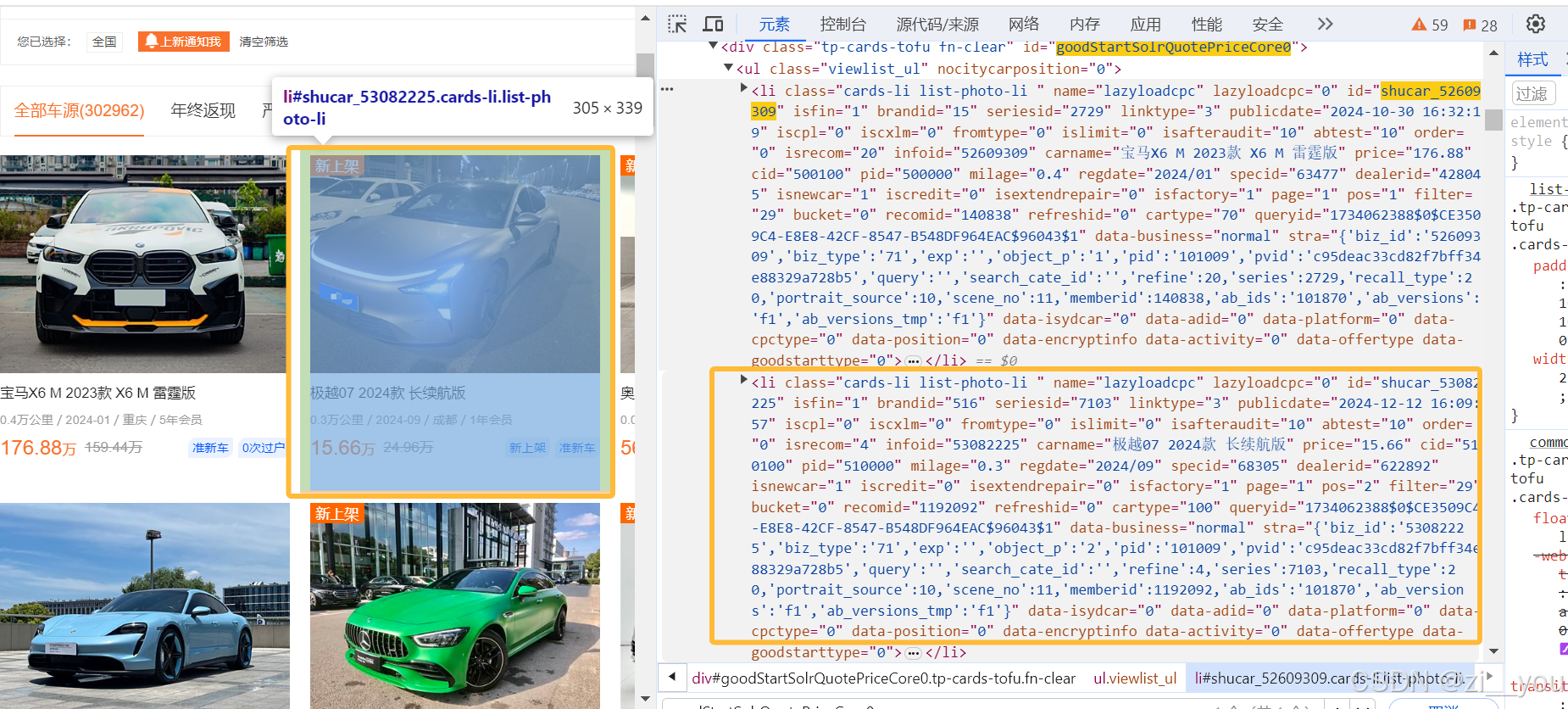
三、汽车之家二手汽车网站HTML结构解析
通过观察汽车之家二手车页面的HTML结构(如图所示),我们可以看到以下关键部分:

- 整体页面布局
- 页面顶部有一些筛选和导航选项,如“全国”、“上新通知我”、“清仓筛选”等。这些选项通常是通过
div或ul等标签进行布局的。 - 例如,可能存在
<div class="filter - options">...</div>这样的结构来存放筛选选项。
- 页面顶部有一些筛选和导航选项,如“全国”、“上新通知我”、“清仓筛选”等。这些选项通常是通过
- 车辆展示区域
- 每辆二手车的信息以卡片的形式展示。从HTML结构来看,这些车辆信息可能被包含在多个
li元素中,这些li元素可能位于一个ul列表中。 - 例如,对应我们XPath中的
//*[@id = "goodStartSolrQuotePriceCore0"]/ul/li,id为goodStartSolrQuotePriceCore0的元素可能是一个大的容器,内部的ul列表存放了各个车辆的li元素。 - 每辆二手车的具体信息在
li元素内又有详细的布局:- 车辆图片:通常在一个
img标签中展示,可能位于类似<div class="img - box">...</div>的结构中,在HTML代码中可以看到<div class="img - box" style="width:285px;height:214px;">...</div>,这是展示车辆图片的区域。 - 车辆详情:包括车型、价格、里程等信息。这些信息通过文本节点和一些
p、span等标签来呈现。- 车型:在
<p class="card - name">...</p>标签内,例如<p class="card - name">宝马X6 M 2023款 X6 M雷霆版</p>。 - 价格:可能在
<p class="card - unit - price">...</p>标签内,例如<p class="card - unit - price">176.88万</p>。 - 车辆信息:包括里程、上牌时间、地点、会员年限等,在
<p class="card - info">...</p>标签内,例如<p class="card - info">0.4万公里/2024 - 01/重庆/5年会员</p>。
- 车型:在
- 车辆图片:通常在一个
- 每辆二手车的信息以卡片的形式展示。从HTML结构来看,这些车辆信息可能被包含在多个
四、使用XPath解析数据
- 创建解析树
- 我们使用
etree.HTML(html)将读取到的HTML字符串转换为一个可以用XPath进行操作的解析树对象tree。这一步是后续数据提取的基础。
- 我们使用
- 定位汽车信息元素
- 关键的XPath表达式
//*[@id = "goodStartSolrQuotePriceCore0"]/ul/li被用来定位所有的二手车信息元素。这里的//表示在整个HTML文档中进行搜索,*表示匹配任意元素,[@id = "goodStartSolrQuotePriceCore0"]是一个属性筛选条件,它选择了id属性为goodStartSolrQuotePriceCore0的元素,然后通过/ul/li进一步定位到其下的ul元素中的li元素,这些li元素就是包含每辆二手车信息的节点。
- 关键的XPath表达式
- 提取汽车信息
- 对于每一个
li元素(代表一辆车),我们进一步使用XPath提取具体信息。- 车型:通过
car.xpath('./@carname')[0]来获取carname属性的值,这里的./表示从当前li节点开始搜索,@carname表示选择carname属性。 - 价格:使用
car.xpath('./@price')[0]来获取price属性的值。 - 车辆信息:通过
car.xpath('./a/div[2]/p/text()')[0]来获取车辆信息。这里./a/div[2]/p/text()表示从当前li节点下的a元素,再到其下的第二个div元素中的p元素的文本内容。
- 车型:通过
- 对于每一个
- 代码实现
# 导入相关库
from lxml import etree
# 本地新闻网页文件路径
file_path = "goods.html"
# 读取本地文件内容
with open(file_path, 'r', encoding='utf-8') as file:
html = file.read()
# 解析 HTML
tree = etree.HTML(html)
# 提取所有汽车信息
cars = tree.xpath('//*[@id = "goodStartSolrQuotePriceCore0"]/ul/li')
# 打印
# print(cars)
# 获取所有汽车项的名称、价格
for car in cars:
name = car.xpath('./@carname')[0]
price = car.xpath('./@price')[0]
unit = car.xpath('./a/div[2]/p/text()')[0]
print("车型:"+name)
print("价格:"+price)
print("信息:"+unit)
print('-'*30)

通过以上步骤,我们能够利用Python和XPath轻松地从汽车之家二手车页面(这里是本地保存的HTML文件)中提取出我们需要的车型、价格和车辆信息。这种方法在数据挖掘和分析领域具有重要的应用价值,例如我们可以进一步对这些二手车数据进行价格分析、市场趋势研究等。同时,使用XPath能够精确地定位到我们需要的数据,避免了从大量无关的HTML内容中手动筛选的繁琐过程。


















 2077
2077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









