







 本文详细介绍了Hadoop Distributed File System (HDFS)的核心概念,包括其设计目的、系统架构、数据读写流程、NameNode与Secondary NameNode的工作机制,以及HDFS在处理小文件和实现高可用性等方面的解决方案。通过对HDFS的深入理解,有助于优化大数据存储与处理的性能。
本文详细介绍了Hadoop Distributed File System (HDFS)的核心概念,包括其设计目的、系统架构、数据读写流程、NameNode与Secondary NameNode的工作机制,以及HDFS在处理小文件和实现高可用性等方面的解决方案。通过对HDFS的深入理解,有助于优化大数据存储与处理的性能。
HDFS概述



• 能做什么
– 存储并管理PB级数据
– 处理非结构化数据
– 注重数据处理的吞吐量(延迟不敏感)
– 应用模式:write-once-read-many存取模式(无数据一致性问题)
• 不适合做
– 存储小文件(不建议)
– 大量随机读(不建议)
– 需要对文件修改(不支持)
– 多用户写入(不支持)
HDSF系统架构


- NameNode
- 管理着文件系统命名空间
– 维护着文件系统树及树中的所有文件和目录 - 存储元数据
– NameNode保存元信息的种类有:
• 文件名目录名及它们之间的层级关系
• 文件目录的所有者及其权限
• 每个文件块的名及文件有哪些块组成 - 元数据保存在内存中
– NameNode元信息并不包含每个块的位置信息 - 保存文件,block,datanode之间的映射关系
- DataNode
- 负责存储数据块,负责为系统客户端提供数据块的读写服务
- 根据NameNode的指示进行创建、删除和复制等操作
- 心跳机制,定期报告文件块列表信息
- DataNode之间进行通信,块的副本处理
HDFS写数据流程

- 1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
- 2)NameNode返回是否可以上传。
- 3)客户端请求第一个 Block上传到哪几个DataNode服务器上。
- 4)NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
- 5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
- 6)dn1、dn2、dn3逐级应答客户端。
- 7)客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
- 8)当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。
HDFS读数据流程

- 1)客户端通过Distributed FileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
- 2)挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
- 3)DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
- 4)客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
NameNode与Secondary NameNode工作机制

- 第一阶段:NameNode启动
(1)第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求。
(3)NameNode记录操作日志,更新滚动日志。
(4)NameNode在内存中对元数据进行增删改。 - 第二阶段:Secondary NameNode工作
(1)Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否检查结果。
(2)Secondary NameNode请求执行CheckPoint。
(3)NameNode滚动正在写的Edits日志。
(4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
(5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint。
(7)拷贝fsimage.chkpoint到NameNode。
(8)NameNode将fsimage.chkpoint重新命名成fsimage。 - NN和2NN工作机制详解:
- Fsimage:NameNode内存中元数据序列化后形成的文件。
- Edits:记录客户端更新元数据信息的每一步操作(可通过Edits运算出元数据)。
- NameNode启动时,先滚动Edits并生成一个空的edits.inprogress,然后加载Edits和Fsimage到内存中,此时NameNode内存就持有最新的元数据信息。Client开始对NameNode发送元数据的增删改的请求,这些请求的操作首先会被记录到edits.inprogress中(查询元数据的操作不会被记录在Edits中,因为查询操作不会更改元数据信息),如果此时NameNode挂掉,重启后会从Edits中读取元数据的信息。然后,NameNode会在内存中执行元数据的增删改的操作。
- 由于Edits中记录的操作会越来越多,Edits文件会越来越大,导致NameNode在启动加载Edits时会很慢,所以需要对Edits和Fsimage进行合并(所谓合并,就是将Edits和Fsimage加载到内存中,照着Edits中的操作一步步执行,最终形成新的Fsimage)。SecondaryNameNode的作用就是帮助NameNode进行Edits和Fsimage的合并工作。
- SecondaryNameNode首先会询问NameNode是否需要CheckPoint(触发CheckPoint需要满足两个条件中的任意一个,定时时间到和Edits中数据写满了)。直接带回NameNode是否检查结果。SecondaryNameNode执行CheckPoint操作,首先会让NameNode滚动Edits并生成一个空的edits.inprogress,滚动Edits的目的是给Edits打个标记,以后所有新的操作都写入edits.inprogress,其他未合并的Edits和Fsimage会拷贝到SecondaryNameNode的本地,然后将拷贝的Edits和Fsimage加载到内存中进行合并,生成fsimage.chkpoint,然后将fsimage.chkpoint拷贝给NameNode,重命名为Fsimage后替换掉原来的Fsimage。NameNode在启动时就只需要加载之前未合并的Edits和Fsimage即可,因为合并过的Edits中的元数据信息已经被记录在Fsimage中。
oiv查看Fsimage文件
hdfs oiv -p 文件类型 -i镜像文件 -o 转换后文件输出路径
oev查看Edits文件
hdfs oev -p 文件类型 -i编辑日志 -o 转换后文件输出路径 - CheckPoint时间设置
(1)通常情况下,SecondaryNameNode每隔一小时执行一次。
[hdfs-default.xml]
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>
(2)一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次。
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作动作次数</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description> 1分钟检查一次操作次数</description>
</property >
- NameNode故障处理
NameNode故障后,可以采用如下两种方法恢复数据。
方法一:将SecondaryNameNode中数据拷贝到NameNode存储数据的目录;
方法二:使用-importCheckpoint选项启动NameNode守护进程,从而将SecondaryNameNode中数据拷贝到NameNode目录中。
集群安全模式

- 基本语法
集群处于安全模式,不能执行重要操作(写操作)。集群启动完成后,自动退出安全模式。
(1)bin/hdfs dfsadmin -safemode get (功能描述:查看安全模式状态)
(2)bin/hdfs dfsadmin -safemode enter (功能描述:进入安全模式状态)
(3)bin/hdfs dfsadmin -safemode leave (功能描述:离开安全模式状态)
(4)bin/hdfs dfsadmin -safemode wait (功能描述:等待安全模式状态)
DataNode工作机制
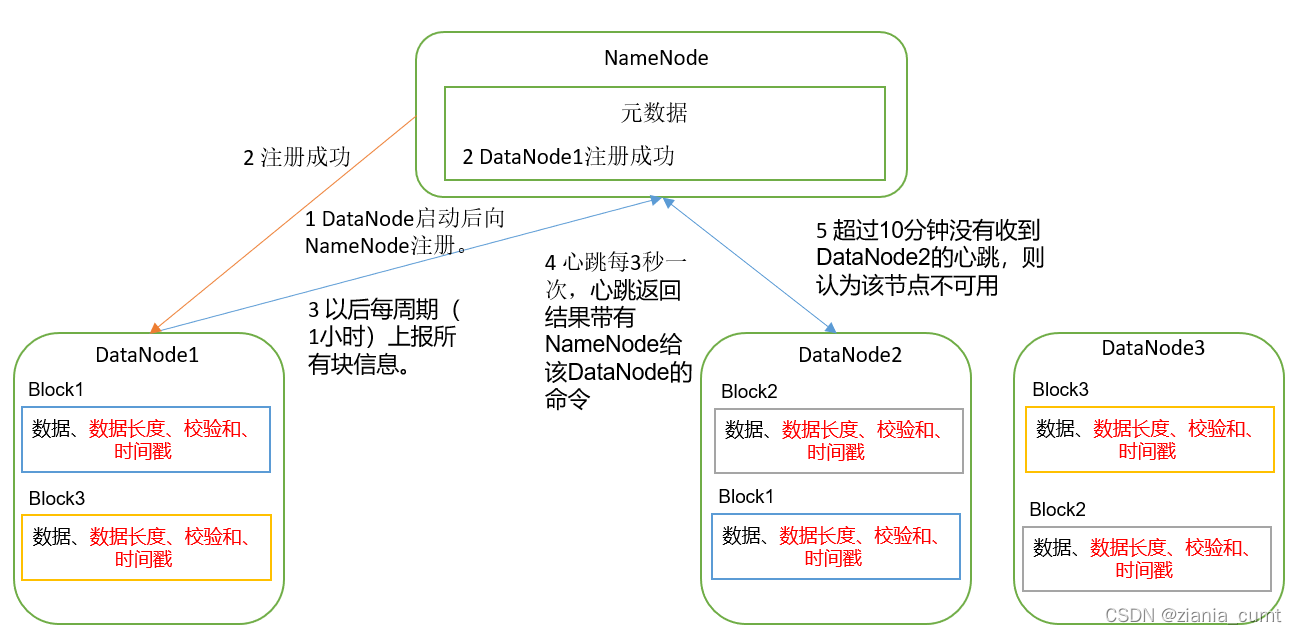
- 1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
- 2)DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息。
- 3)心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
- 4)集群运行中可以安全加入和退出一些机器。
HDFS DataNode添加与退役
- 服役新节点具体步骤
(1)直接启动DataNode,即可关联到集群
[atguigu@hadoop105 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode
[atguigu@hadoop105 hadoop-2.7.2]$ sbin/yarn-daemon.sh start nodemanager
退役旧节点太 - 添加白名单(hdfs-site.xml)
<property>
<name>dfs.hosts</name>
<value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts</value>
</property>
//dfs.hosts文件了配置允许访问的DataNode节点
- 添加黑名单(hdfs-site.xml)
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts.exclude</value>
</property>
//dfs.hosts.exclude文件里配置不允许访问的DateNode节点
HDFS 2.X新特性
- 1 集群间数据拷贝
- scp实现两个远程主机之间的文件复制
scp -r hello.txt root@hadoop103:/user/atguigu/hello.txt // 推 push
scp -r root@hadoop103:/user/atguigu/hello.txt hello.txt // 拉 pull
scp -r root@hadoop103:/user/atguigu/hello.txt root@hadoop104:/user/atguigu //是通过本地主机中转实现两个远程主机的文件复制;如果在两个远程主机之间ssh没有配置的情况下可以使用该方式。 - 采用distcp命令实现两个Hadoop集群之间的递归数据复制
[atguigu@hadoop102 hadoop-2.7.2]$ bin/hadoop distcp
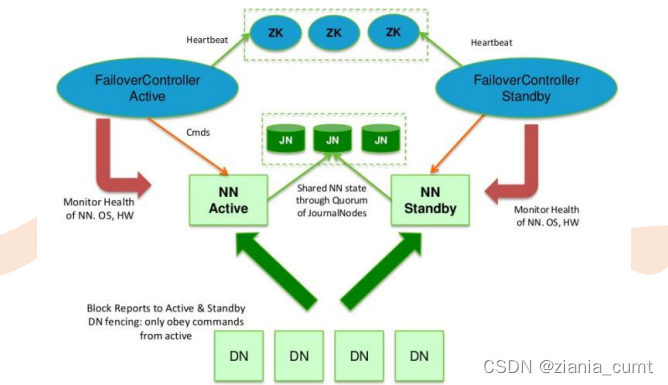
hdfs://haoop102:9000/user/atguigu/hello.txt hdfs://hadoop103:9000/user/atguigu/hello.txt - NameNode高可用(HA)
什么问题:Hadoop 1.0中NameNode在整个HDFS中只有一个,存在单点故障(SPOF)风险,一旦NameNode挂掉,整个集群无法使用
解决方法:HDFS的高可用性将通过在同一个集群中运行两个NameNode (Active NameNode & Standby NameNode )来解决
在任何时间,只有一台机器处于Active状态;另一台机器是处于Standby状态
Active NN负责集群中所有客户端的操作;
Standby NN主要用于备用,它主要维持足够的状态,如果必要,可以提供快速的故障恢复。
- HDFS快照
HDFS快照是一个只读的基于时间点文件系统拷贝
快照可以是整个文件系统的也可以是一部分。
常用来作为数据备份,防止用户错误操作和容灾恢复。
Snapshot 并不会影响HDFS 的正常操作:修改会按照时间的反序记录,这样可以直接读取到最新的数据。
快照数据是当前数据减去修改的部分计算出来的。
快照会存储在snapshottable的目录下。
HDFS快照是对目录进行设定,是某个目录的某一个时刻的镜像
对于一个snapshottable文件夹,“.snapshot” 被用于进入他的快照 /foo 是一个snapshottable目录,/foo/bar是一个/foo下面的文件目录,/foo有一个快照s0,那么路径就是:/foo/.snapshot/s0/bar
hdfs dfsadmin -allowSnapshot /user/spark
hdfs dfs -createSnapshot /user/spark s0
hdfs dfs -renameSnapshot /user/spark s0 s_init
hdfs dfs -deleteSnapshot /user/spark s_init
hdfs dfsadmin -disallowSnapshot /user/spark - HDFS缓存
- 允许用户指定要缓存的HDFS路径
- 明确的锁定可以阻止频繁使用的数据被从内存中清除
- 集中化缓存管理对于重复访问的文件很有用
- 可以换成目录或文件,但目录是非递归的
- HDFS ACL
- Hadoop从2.4.0开始支持
- 目前HDFS的权限控制与Linux一致,包括用户、用户组、其他用户组三类权限,这种方式有很大局限性
- 首先参数上要开启基本权限和访问控制列表功能
– dfs.permissions.enabled
– dfs.namenode.acls.enabled - 常用命令:
– hadoop fs -getfacl /input/acl
– hdfs dfs -setfacl -m user:mapred:r-- /input/acl
– hdfs dfs -setfacl -x user:mapred /input/acl
- 异构层级存储结构
- Hadoop2.6.0开始支持
- 一个集群中,有多种不同的存储介质,比如有SSD、RAM等
- 由于一个Hadoop集群中有多种类型的任务,不同的任务对数据访问速度要求不一样,于是通过相应配置,控制目录和文件写到什么样的介质上去,并且具备配额控制要求
- 目前支持不够完整
<property>
<name>dfs.datanode.data.dir</name>
<value>[disk]/dir0,[ssd]/dir1/,[disk]/dir2/</value>
</property>
HDFS小文件解决方案
- 小文件的优化无非以下几种方式:
(1)在数据采集的时候,就将小文件或小批数据合成大文件再上传HDFS。
(2)在业务处理之前,在HDFS上使用MapReduce程序对小文件进行合并。
(3)在MapReduce处理时,可采用CombineTextInputFormat提高效率。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









