









 日萌社
日萌社
人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新)
1.3 推荐算法
学习目标
- 了解推荐模型构建流程
-
理解协同过滤原理
-
记忆相似度计算方法
- 应用杰卡德相似度实现简单协同过滤推荐案例
1 推荐模型构建流程
Data(数据)->Features(特征)->ML Algorithm(选择算法训练模型)->Prediction Output(预测输出)
-
数据清洗/数据处理
- 数据来源
- 显性数据
- Rating 打分
- Comments 评论/评价
- 隐形数据
- Order history 历史订单
- Cart events 加购物车
- Page views 页面浏览
- Click-thru 点击
- Search log 搜索记录
- 显性数据
- 数据量/数据能否满足要求
- 数据来源
-
特征工程
-
从数据中筛选特征
-
一个给定的商品,可能被拥有类似品味或需求的用户购买
-
使用用户行为数据描述商品
-
-
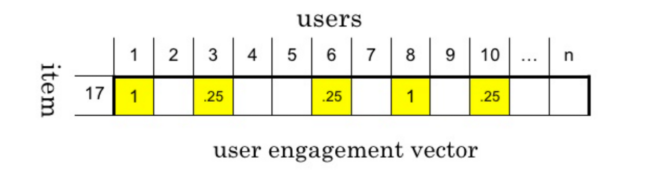
用数据表示特征
-
将所有用户行为合并在一起 ,形成一个user-item 矩阵

-
选择合适的算法
- 协同过滤
- 基于内容
-
产生推荐结果
- 对推荐结果进行评估(评估方法后面章节介绍),评估通过后上线
2 最经典的推荐算法:协同过滤推荐算法(Collaborative Filtering)
算法思想:物以类聚,人以群分
基本的协同过滤推荐算法基于以下假设:
- “跟你喜好相似的人喜欢的东西你也很有可能喜欢” :基于用户的协同过滤推荐(User-based CF)
- “跟你喜欢的东西相似的东西你也很有可能喜欢 ”:基于物品的协同过滤推荐(Item-based CF)
实现协同过滤推荐有以下几个步骤:
-
找出最相似的人或物品:TOP-N相似的人或物品
通过计算两两的相似度来进行排序,即可找出TOP-N相似的人或物品
-
根据相似的人或物品产生推荐结果
利用TOP-N结果生成初始推荐结果,然后过滤掉用户已经有过记录的物品或明确表示不感兴趣的物品
以下是一个简单的示例,数据集相当于一个用户对物品的购买记录表:打勾表示用户对物品的有购买记录
-
关于相似度计算这里先用一个简单的思想:如有两个同学X和Y,X同学爱好[足球、篮球、乒乓球],Y同学爱好[网球、足球、篮球、羽毛球],可见他们的共同爱好有2个,那么他们的相似度可以用:2/3 * 2/4 = 1/3 ≈ 0.33 来表示。
User-Based CF

Item-Based CF

通过前面两个demo,相信大家应该已经对协同过滤推荐算法的设计与实现有了比较清晰的认识。
3 相似度计算(Similarity Calculation)

相似度的计算方法
- 欧氏距离, 是一个欧式空间下度量距离的方法. 两个物体, 都在同一个空间下表示为两个点, 假如叫做p,q, 分别都是n个坐标, 那么欧式距离就是衡量这两个点之间的距离. 欧氏距离不适用于布尔向量之间

欧氏距离的值是一个非负数, 最大值正无穷, 通常计算相似度的结果希望是[-1,1]或[0,1]之间,一般可以使用
如下转化公式:
: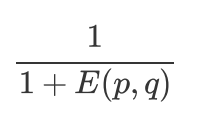
余弦相似度
- 度量的是两个向量之间的夹角, 用夹角的余弦值来度量相似的情况
- 两个向量的夹角为0是,余弦值为1, 当夹角为90度是余弦值为0,为180度是余弦值为-1
- 余弦相似度在度量文本相似度, 用户相似度 物品相似度的时候较为常用
- 余弦相似度的特点, 与向量长度无关,余弦相似度计算要对向量长度归一化, 两个向量只要方向一致,无论程度强弱, 都可以视为'相似'
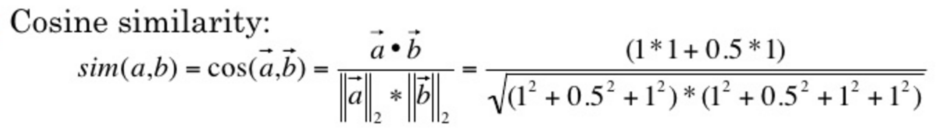

皮尔逊相关系数Pearson
- 实际上也是余弦相似度, 不过先对向量做了中心化, 向量a b各自减去向量的均值后, 再计算余弦相似度
- 皮尔逊相似度计算结果在-1,1之间 -1表示负相关, 1表示正相关
- 度量两个变量是不是同增同减
- 皮尔逊相关系数度量的是两个变量的变化趋势是否一致, 不适合计算布尔值向量之间的相关度

杰卡德相似度 Jaccard
- 两个集合的交集元素个数在并集中所占的比例, 非常适用于布尔向量表示
- 分子是两个布尔向量做点积计算, 得到的就是交集元素的个数
- 分母是两个布尔向量做或运算, 再求元素和

-
如何选择余弦相似度
- 余弦相似度/皮尔逊相关系数适合用户评分数据(实数值),
- 杰卡德相似度适用于隐式反馈数据(0,1布尔值 是否收藏,是否点击,是否加购物车)
4 协同过滤推荐算法代码实现:
-
构建数据集:
users = ["User1", "User2", "User3", "User4", "User5"] items = ["Item A", "Item B", "Item C", "Item D", "Item E"] # 构建数据集 datasets = [ ["buy",None,"buy","buy",None], ["buy",None,None,"buy","buy"], ["buy",None,"buy",None,None], [None,"buy",None,"buy","buy"], ["buy","buy","buy",None,"buy"], ] -
计算时我们数据通常都需要对数据进行处理,或者编码,目的是为了便于我们对数据进行运算处理,比如这里是比较简单的情形,我们用1、0分别来表示用户的是否购买过该物品,则我们的数据集其实应该是这样的:
users = ["User1", "User2", "User3", "User4", "User5"] items = ["Item A", "Item B", "Item C", "Item D", "Item E"] # 用户购买记录数据集 datasets = [ [1,0,1,1,0], [1,0,0,1,1], [1,0,1,0,0], [0,1,0,1,1], [1,1,1,0,1], ] import pandas as pd df = pd.DataFrame(datasets, columns=items, index=users) print(df) -
有了数据集,接下来我们就可以进行相似度的计算,不过对于相似度的计算其实是有很多专门的相似度计算方法的,比如余弦相似度、皮尔逊相关系数、杰卡德相似度等等。这里我们选择使用杰卡德相似系数[0,1]
from sklearn.metrics import jaccard_similarity_score # 直接计算某两项的杰卡德相似系数 # 计算Item A 和Item B的相似度 print(jaccard_similarity_score(df["Item A"], df["Item B"])) # 计算所有的数据两两的杰卡德相似系数 from sklearn.metrics.pairwise import pairwise_distances # 计算用户间相似度 user_similar = 1 - pairwise_distances(df, metric="jaccard") user_similar = pd.DataFrame(user_similar, columns=users, index=users) print("用户之间的两两相似度:") print(user_similar) # 计算物品间相似度 item_similar = 1 - pairwise_distances(df.T, metric="jaccard") item_similar = pd.DataFrame(item_similar, columns=items, index=items) print("物品之间的两两相似度:") print(item_similar)有了两两的相似度,接下来就可以筛选TOP-N相似结果,并进行推荐了
-
User-Based CF
import pandas as pd import numpy as np from pprint import pprint users = ["User1", "User2", "User3", "User4", "User5"] items = ["Item A", "Item B", "Item C", "Item D", "Item E"] # 用户购买记录数据集 datasets = [ [1,0,1,1,0], [1,0,0,1,1], [1,0,1,0,0], [0,1,0,1,1], [1,1,1,0,1], ] df = pd.DataFrame(datasets, columns=items, index=users) # 计算所有的数据两两的杰卡德相似系数 from sklearn.metrics.pairwise import pairwise_distances # 计算用户间相似度 1-杰卡德距离=杰卡德相似度 user_similar = 1 - pairwise_distances(df, metric="jaccard") user_similar = pd.DataFrame(user_similar, columns=users, index=users) print("用户之间的两两相似度:") print(user_similar) topN_users = {} # 遍历每一行数据 for i in user_similar.index: # 取出每一列数据,并删除自身,然后排序数据 _df = user_similar.loc[i].drop([i]) #sort_values 排序 按照相似度降序排列 _df_sorted = _df.sort_values(ascending=False) # 从排序之后的结果中切片 取出前两条(相似度最高的两个) top2 = list(_df_sorted.index[:2]) topN_users[i] = top2 print("Top2相似用户:") pprint(topN_users) # 准备空白dict用来保存推荐结果 rs_results = {} #遍历所有的最相似用户 for user, sim_users in topN_users.items(): rs_result = set() # 存储推荐结果 for sim_user in sim_users: # 构建初始的推荐结果 rs_result = rs_result.union(set(df.ix[sim_user].replace(0,np.nan).dropna().index)) # 过滤掉已经购买过的物品 rs_result -= set(df.ix[user].replace(0,np.nan).dropna().index) rs_results[user] = rs_result print("最终推荐结果:") pprint(rs_results) -
Item-Based CF
import pandas as pd import numpy as np from pprint import pprint users = ["User1", "User2", "User3", "User4", "User5"] items = ["Item A", "Item B", "Item C", "Item D", "Item E"] # 用户购买记录数据集 datasets = [ [1,0,1,1,0], [1,0,0,1,1], [1,0,1,0,0], [0,1,0,1,1], [1,1,1,0,1], ] df = pd.DataFrame(datasets, columns=items, index=users) # 计算所有的数据两两的杰卡德相似系数 from sklearn.metrics.pairwise import pairwise_distances # 计算物品间相似度 item_similar = 1 - pairwise_distances(df.T, metric="jaccard") item_similar = pd.DataFrame(item_similar, columns=items, index=items) print("物品之间的两两相似度:") print(item_similar) topN_items = {} # 遍历每一行数据 for i in item_similar.index: # 取出每一列数据,并删除自身,然后排序数据 _df = item_similar.loc[i].drop([i]) _df_sorted = _df.sort_values(ascending=False) top2 = list(_df_sorted.index[:2]) topN_items[i] = top2 print("Top2相似物品:") pprint(topN_items) rs_results = {} # 构建推荐结果 for user in df.index: # 遍历所有用户 rs_result = set() for item in df.ix[user].replace(0,np.nan).dropna().index: # 取出每个用户当前已购物品列表 # 根据每个物品找出最相似的TOP-N物品,构建初始推荐结果 rs_result = rs_result.union(topN_items[item]) # 过滤掉用户已购的物品 rs_result -= set(df.ix[user].replace(0,np.nan).dropna().index) # 添加到结果中 rs_results[user] = rs_result print("最终推荐结果:") pprint(rs_results)
关于协同过滤推荐算法使用的数据集
在前面的demo中,我们只是使用用户对物品的一个购买记录,类似也可以是比如浏览点击记录、收听记录等等。这样数据我们预测的结果其实相当于是在预测用户是否对某物品感兴趣,对于喜好程度不能很好的预测。
因此在协同过滤推荐算法中其实会更多的利用用户对物品的“评分”数据来进行预测,通过评分数据集,我们可以预测用户对于他没有评分过的物品的评分。其实现原理和思想和都是一样的,只是使用的数据集是用户-物品的评分数据。
关于用户-物品评分矩阵
用户-物品的评分矩阵,根据评分矩阵的稀疏程度会有不同的解决方案
-
稠密评分矩阵

- 稀疏评分矩阵

这里先介绍稠密评分矩阵的处理,稀疏矩阵的处理相对会复杂一些,我们到后面再来介绍。
使用协同过滤推荐算法对用户进行评分预测
-
数据集:

-
目的:预测用户1对物品E的评分
-
构建数据集:注意这里构建评分数据时,对于缺失的部分我们需要保留为None,如果设置为0那么会被当作评分值为0去对待
users = ["User1", "User2", "User3", "User4", "User5"] items = ["Item A", "Item B", "Item C", "Item D", "Item E"] # 用户购买记录数据集 datasets = [ [5,3,4,4,None], [3,1,2,3,3], [4,3,4,3,5], [3,3,1,5,4], [1,5,5,2,1], ] -
计算相似度:对于评分数据这里我们采用皮尔逊相关系数[-1,1]来计算,-1表示强负相关,+1表示强正相关
pandas中corr方法可直接用于计算皮尔逊相关系数
df = pd.DataFrame(datasets, columns=items, index=users) print("用户之间的两两相似度:") # 直接计算皮尔逊相关系数 # 默认是按列进行计算,因此如果计算用户间的相似度,当前需要进行转置 user_similar = df.T.corr() print(user_similar.round(4)) print("物品之间的两两相似度:") item_similar = df.corr() print(item_similar.round(4))# 运行结果: 用户之间的两两相似度: User1 User2 User3 User4 User5 User1 1.0000 0.8528 0.7071 0.0000 -0.7921 User2 0.8528 1.0000 0.4677 0.4900 -0.9001 User3 0.7071 0.4677 1.0000 -0.1612 -0.4666 User4 0.0000 0.4900 -0.1612 1.0000 -0.6415 User5 -0.7921 -0.9001 -0.4666 -0.6415 1.0000 物品之间的两两相似度: Item A Item B Item C Item D Item E Item A 1.0000 -0.4767 -0.1231 0.5322 0.9695 Item B -0.4767 1.0000 0.6455 -0.3101 -0.4781 Item C -0.1231 0.6455 1.0000 -0.7206 -0.4276 Item D 0.5322 -0.3101 -0.7206 1.0000 0.5817 Item E 0.9695 -0.4781 -0.4276 0.5817 1.0000可以看到与用户1最相似的是用户2和用户3;与物品A最相似的物品分别是物品E和物品D。
注意:我们在预测评分时,往往是通过与其有正相关的用户或物品进行预测,如果不存在正相关的情况,那么将无法做出预测。这一点尤其是在稀疏评分矩阵中尤为常见,因为稀疏评分矩阵中很难得出正相关系数。
-
评分预测:
User-Based CF 评分预测:使用用户间的相似度进行预测
关于评分预测的方法也有比较多的方案,下面介绍一种效果比较好的方案,该方案考虑了用户本身的评分评分以及近邻用户的加权平均相似度打分来进行预测:
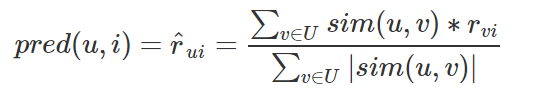
我们要预测用户1对物品E的评分,那么可以根据与用户1最近邻的用户2和用户3进行预测,计算如下:
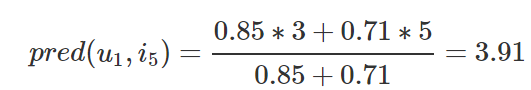
最终预测出用户1对物品5的评分为3.91
Item-Based CF 评分预测:使用物品间的相似度进行预测
这里利用物品相似度预测的计算同上,同样考虑了用户自身的平均打分因素,结合预测物品与相似物品的加权平均相似度打分进行来进行预测
我们要预测用户1对物品E的评分,那么可以根据与物品E最近邻的物品A和物品D进行预测,计算如下:

对比可见,User-Based CF预测评分和Item-Based CF的评分结果也是存在差异的,因为严格意义上他们其实应当属于两种不同的推荐算法,各自在不同的领域不同场景下,都会比另一种的效果更佳,但具体哪一种更佳,必须经过合理的效果评估,因此在实现推荐系统时这两种算法往往都是需要去实现的,然后对产生的推荐效果进行评估分析选出更优方案。
推荐系统构建流程
推荐系统构建流程:建立数据仓库(hbase/hdfs)存储数据 -> 数据清洗 -> 特征工程 -> 选择算法训练模型+模型预测输出
1.数据清洗/数据处理/数据来源(数据量/数据能否满足要求)
1.显性数据
Rating 打分
Comments 评论/评价
2.隐形数据
Order history 历史订单
Cart events 加购物车
Page views 页面浏览
Click-thru 点击
Search log 搜索记录
2.特征工程
1.从数据中筛选特征
一个给定的商品,可能被拥有类似品味或需求的用户购买
使用用户行为数据描述商品 
2.用数据表示特征
将所有用户行为合并在一起 ,形成一个user-item 矩阵
从矩阵中获取出有效数据的部分做特征工程

3.选择合适的算法
1.协同过滤(基于内容(物品)或基于用户产生推荐结果)
1.算法思想:物以类聚,人以群分
2.基本的协同过滤推荐算法基于以下假设:
1.“跟你喜好相似的人喜欢的东西你也很有可能喜欢”:基于用户的协同过滤推荐(User-based CF)。
基于用户的稀疏矩阵:矩阵行名为users,矩阵列名为items。
2.“跟你喜欢的东西相似的东西你也很有可能喜欢 ”:基于物品的协同过滤推荐(Item-based CF)。
基于内容(物品)的稀疏矩阵:矩阵行名为items,矩阵列名为users。
2.实现协同过滤推荐有以下几个步骤:
1.每个人与人之间或者每个物与物之间都有相似度,只是相似度的高低区别,求出TOP-N相似的人与人之间或物与物之间相似度。
2.根据TOP-N相似的人与人之间或物与物之间相似度产生推荐结果。
利用TOP-N结果生成初始推荐结果,然后过滤掉用户已经有过记录的物品或明确表示不感兴趣的物品。
用户已经有过记录的物品就不需要再推荐,用户表示不感兴趣(点击踩动作/不感兴趣的按钮)的物品就不需要再推荐。
3.关于相似度计算这里先用一个简单的思想:
如有两个同学X和Y,X同学爱好[足球、篮球、乒乓球],Y同学爱好[网球、足球、篮球、羽毛球],
可见他们的共同爱好有2个,X同学3个爱好中有2个共同爱好即2/3,Y同学4个爱好中有2个共同爱好即2/4,
那么他们的相似度可以用:2/3 * 2/4 = 1/3 ≈ 0.33 来表示。
4.“跟你喜好相似的人喜欢的东西你也很有可能喜欢”:基于用户的协同过滤推荐(User-based CF)。
基于用户的稀疏矩阵:矩阵行名为users,矩阵列名为items。


5.“跟你喜欢的东西相似的东西你也很有可能喜欢 ”:基于物品的协同过滤推荐(Item-based CF)。
基于内容(物品)的稀疏矩阵:矩阵行名为items,矩阵列名为users。


4.对推荐结果进行评估,评估通过后上线
相似度计算
注意:归一化为[-1,1]或[0,1]之间,标准化为均值为0和方差为1。
1.欧氏距离
计算的距离近则相似度高。
欧氏距离的值是一个非负数。最大值正无穷。通常计算相似度的结果希望是[-1,1]或[0,1]之间,那便需要把一个0到正无穷的范围归一化为[-1,1]或[0,1]之间。
一般可以使用1/(1+E(p,q))
2.余弦相似度
1.度量的是两个向量之间的夹角, 用夹角的余弦值来度量相似的情况
两个向量的夹角为0则余弦值为1表示完全相似。当夹角为90度则余弦值为0。当夹角为180度则余弦值为-1表示完全不相似。
余弦相似度在度量文本相似度/用户相似度/物品相似度的时候较为常用
2.余弦相似度的特点:与向量长度无关,余弦相似度计算要对向量长度归一化, 两个向量只要方向一致,无论程度强弱, 都可以视为'相似'
3.余弦相似度的漏洞:
余弦相似度虽然与向量长度无关,但是实际环境中需要考虑向量长度,不仅要考虑夹角还要向量长度。
比如用户A对电影1、电影2的评分分别为2分和3分,用户B对电影1、电影2的评分分别为4分和5分,
那么2分和3分之间的夹角 与 4分和5分之间的夹角 两者有点相近的,但是评分满分是5的话,
2分和3分的打分属于中低打分,4分和5分属于中高打分,那此时的余弦相似度无法相近,不考虑向量长度便是余弦相似度的漏洞,
所以余弦相似度计算还要对向量长度进行归一化,这样便可以只考虑两个向量只要方向一致,无论程度强弱,都可以视为'相似'。
3.皮尔逊相关系数
1.实际上也是余弦相似度, 不过先对向量做了中心化, 向量a b各自减去向量的均值后, 再计算余弦相似度。
考虑向量中心化的问题,也即用于解决余弦相似度的漏洞问题(无法考虑向量长度的问题)。
比如评分满分是5,用户A对电影1、电影2的评分分别为2分和3分,用户B对电影1、电影2的评分分别为4分和5分,
那么2分和3分都减去他们之间的平均值2.5,4分和5分都减去他们之间的平均值4.5。
2.皮尔逊相似度计算结果在-1,1之间 -1表示负相关, 1表示正相关
度量两个变量是不是同增同减
皮尔逊相关系数度量的是两个变量的变化趋势是否一致, 不适合计算布尔值向量之间的相关度
3.余弦相似度和皮尔逊相关系数之间如何选择呢
1.余弦相似度的计算复杂度 比 皮尔逊相关系数的计算复杂度 要低,所以如果算力不高的时候可以选择余弦相似度。
2.皮尔逊相关系数的精确度 比 余弦相似度的精确度 要高,所以要求精确度比较高的时候可以选择皮尔逊相关系数。
3.余弦相似度/皮尔逊相关系数适合计算连续性数值,比如用户评分数据(实数值),不适合计算0/1布尔值向量之间的相关度(是否收藏、是否点击、是否加购物车)。
如果是分类型的连续型实数值(0/1/2/3...)则可以转换为one-hot编码(即转换为0/1布尔值向量之间的相关度计算问题,即也可以使用杰卡德相似度来计算)。
4.杰卡德相似度Jaccard
1.两个集合的交集元素个数在并集中所占的比例, 非常适用于布尔向量表示
2.分子是两个布尔向量做点积计算, 得到的就是交集元素的个数
分母是两个布尔向量做或运算, 再求元素和
3.交集(∩),并集(∪)。
集合论中,设A、B是两个集合,由所有属于集合A且属于集合B的元素所组成的集合,叫做集合A与集合B的交集,记作A∩B。
4.分子:值为(1+1),代表A交B的交集,即A∩B那么返回1。
5.分母:(1+1+1)和(1+1+1+1),代表A和B的并集(即A∪B),然后减去A和B的交集(即A∩B),即得A∪B-A∩B
5.相似度算法选择
1.余弦相似度/皮尔逊相关系数适合用户评分数据(实数值),不适合计算0/1布尔值向量之间的相关度(是否收藏、是否点击、是否加购物车)
2.杰卡德相似度适用于隐式反馈数据,适合计算0/1布尔值向量之间的相关度(是否收藏、是否点击、是否加购物车)
3.如果是分类型的连续型实数值(0/1/2/3...)则可以转换为one-hot编码(即转换为0/1布尔值向量之间的相关度计算问题,即也可以使用杰卡德相似度来计算)。
基于用户的协同过滤推荐/基于基于物品的协同过滤推荐:预测用户是否对某物品感兴趣,计算的是0/1布尔值向量之间的相关度
# 构建数据集:users为行索引(行名),items为列索引(列名)
users = ["User1", "User2", "User3", "User4", "User5"]
items = ["Item A", "Item B", "Item C", "Item D", "Item E"]
# 构建数据集:"buy"为1,None为0
# datasets = [
# ["buy",None,"buy","buy",None],
# ["buy",None,None,"buy","buy"],
# ["buy",None,"buy",None,None],
# [None,"buy",None,"buy","buy"],
# ["buy","buy","buy",None,"buy"],
# ]
"""
计算时我们数据通常都需要对数据进行处理,或者编码,目的是为了便于我们对数据进行运算处理,
比如这里是比较简单的情形,我们用1、0分别来表示用户的是否购买过该物品,则我们的数据集其实应该是这样的:
Item A Item B Item C Item D Item E
User1 1 0 1 1 0
User2 1 0 0 1 1
User3 1 0 1 0 0
User4 0 1 0 1 1
User5 1 1 1 0 1
注意:
1.因为一开始datasets所构建的数据集df.values为矩阵行名(行索引)为用户users,矩阵列名(列索引)为物品items 才能计算用户和用户之间的相似度,
因此基于用户的协同过滤推荐(User-based CF)计算用户和用户之间的相似度使用:pairwise_distances(df.values, metric="jaccard")。
2.datasets所构建的数据集df.values.T转置后变为矩阵行名(行索引)为物品items,矩阵列名(列索引)为用户users 才能计算物品和物品之间的相似度,
因此基于物品的协同过滤推荐(Item-based CF))计算物品和物品之间的相似度使用:pairwise_distances(df.values.T, metric="jaccard")。
"""
# 用户购买记录数据集:"buy"为1,None为0
datasets = [
[1,0,1,1,0],
[1,0,0,1,1],
[1,0,1,0,0],
[0,1,0,1,1],
[1,1,1,0,1],
]
import pandas as pd
#index=users:users为行索引(行名)。columns=items:items为列索引(列名)
# df = pd.DataFrame(datasets, columns=items, index=users, dtype=bool)
df = pd.DataFrame(datasets, columns=items, index=users)
# print(df)
# print(df.values)
# [[ True False True True False]
# [ True False False True True]
# [ True False True False False]
# [False True False True True]
# [ True True True False True]]
#-------------------------------------------------------------------------------------------------------------#
"""
有了数据集,接下来我们就可以进行相似度的计算,不过对于相似度的计算其实是有很多专门的相似度计算方法的,
比如余弦相似度、皮尔逊相关系数、杰卡德相似度等等。这里我们选择使用杰卡德相似系数计算datasets=[0,1]值。
"""
from sklearn.metrics import jaccard_similarity_score
# 直接计算某两项的杰卡德相似系数
# 计算Item A 和Item B的相似度(物品之间的两两相似度):0.2
# print(jaccard_similarity_score(df["Item A"], df["Item B"])) #0.2
"""
报错:AttributeError: 'DataFrame' object has no attribute 'dtype'
解决:pairwise_distances(df, metric="jaccard") 修改为 pairwise_distances(df.values, metric="jaccard")
警告:DataConversionWarning: Data was converted to boolean for metric jaccard。warnings.warn(msg, DataConversionWarning)
解释:DataConversionWarning:数据已转换为度量jaccard的布尔值警告.warn(消息,数据转换警告)
解决:设置dtype=bool,比如 df = pd.DataFrame(datasets, columns=items, index=users, dtype=bool)
警告:DeprecationWarning: jaccard_similarity_score has been deprecated and replaced with jaccard_score.
It will be removed in version 0.23. This implementation has surprising behavior for binary and multiclass classification tasks.
'and multiclass classification tasks.', DeprecationWarning)
解释:不推荐警告:jaccard_similarity_score已被不推荐并替换为jaccard_score。它将在0.23版中删除。
此实现对于二进制和多类分类任务和多类分类任务具有令人惊讶的行为。DeprecationWarning)
分析:jaccard_similarity_score方法已经过时
"""
# 计算所有的数据两两的杰卡德相似系数
from sklearn.metrics.pairwise import pairwise_distances
"""
1.“跟你喜好相似的人喜欢的东西你也很有可能喜欢”:基于用户的协同过滤推荐(User-based CF)。
基于用户的稀疏矩阵:矩阵行名为users,矩阵列名为items。
2.因为一开始datasets所构建的数据集df.values为矩阵行名(行索引)为用户users,矩阵列名(列索引)为物品items 才能计算用户和用户之间的相似度,
因此基于用户的协同过滤推荐(User-based CF)计算用户和用户之间的相似度使用:pairwise_distances(df.values, metric="jaccard")。
"""
# 计算用户间相似度:metric="jaccard" 使用杰卡德相似系数
user_similar = 1 - pairwise_distances(df.values, metric="jaccard")
#DataFrame构建显示数据
user_similar = pd.DataFrame(user_similar, columns=users, index=users)
# print("用户之间的两两相似度:")
# print(user_similar)
# User1 User2 User3 User4 User5
# User1 1.000000 0.50 0.666667 0.2 0.4
# User2 0.500000 1.00 0.250000 0.5 0.4
# User3 0.666667 0.25 1.000000 0.0 0.5
# User4 0.200000 0.50 0.000000 1.0 0.4
# User5 0.400000 0.40 0.500000 0.4 1.0
"""
1.“跟你喜欢的东西相似的东西你也很有可能喜欢 ”:基于物品的协同过滤推荐(Item-based CF)。
基于内容(物品)的稀疏矩阵:矩阵行名为items,矩阵列名为users。
2.datasets所构建的数据集df.values.T转置后变为矩阵行名(行索引)为物品items,矩阵列名(列索引)为用户users 才能计算物品和物品之间的相似度,
因此基于物品的协同过滤推荐(Item-based CF))计算物品和物品之间的相似度使用:pairwise_distances(df.values.T, metric="jaccard")。
"""
# 计算物品间相似度
item_similar = 1 - pairwise_distances(df.values.T, metric="jaccard")
item_similar = pd.DataFrame(item_similar, columns=items, index=items)
# print("物品之间的两两相似度:")
# print(item_similar)
# Item A Item B Item C Item D Item E
# Item A 1.00 0.200000 0.75 0.40 0.400000
# Item B 0.20 1.000000 0.25 0.25 0.666667
# Item C 0.75 0.250000 1.00 0.20 0.200000
# Item D 0.40 0.250000 0.20 1.00 0.500000
# Item E 0.40 0.666667 0.20 0.50 1.000000
#-------------------------------------------------------------------------------------------------------------#
import numpy as np
from pprint import pprint
"""
基于用户的协同过滤推荐(User-based CF):有了用户和用户之间两两的相似度,接下来就可以筛选TOP-N相似结果,并进行推荐了。
"""
topN_users = {}
# 遍历每一行数据:index获取的是 pd.DataFrame(user_similar, columns=users, index=users)中设置的index=users 行名(行索引值)
for i in user_similar.index:
# print(i) #User1 User2 User3 User4 User5
# print("user_similar.loc[i]",user_similar.loc[i])
#比如:
# User1 1.000000
# User2 0.500000
# User3 0.666667
# User4 0.200000
# User5 0.400000
# Name: User1, dtype: float64
# 取出每一列数据,并删除自身(即删除对角线上为1的值,该值代表的是自身和自身的相似度),然后排序数据
_df = user_similar.loc[i].drop([i])
#sort_values 排序 按照相似度的 降序排列(ascending=False)
_df_sorted = _df.sort_values(ascending=False)
# 从排序之后的结果中切片 取出前两条(相似度最高的两个)
top2 = list(_df_sorted.index[:2])
topN_users[i] = top2
# print("Top2相似用户:")
# pprint(topN_users)
# {'User1': ['User3', 'User2'],
# 'User2': ['User4', 'User1'],
# 'User3': ['User1', 'User5'],
# 'User4': ['User2', 'User5'],
# 'User5': ['User3', 'User4']}
"""
警告:utureWarning:
.ix is deprecated. Please use
.loc for label based indexing or
.iloc for positional indexing
分析:
1.直接使用行列索引(先列后行):直接索引 -- 先列后行, 是需要通过索引的字符串进行获取
2.使用loc只能指定行列索引的名字去获取:loc -- 先行后列, 是需要通过索引的字符串进行获取
3.使用iloc可以通过索引的下标去获取:iloc -- 先行后列, 是通过下标进行索引
4.使用ix组合索引:ix -- 先行后列, 可以用上面两种方法混合进行索引
-------------------------------------------------------------------------
replace(to_replace=, value=)
to_replace:替换前的值
value:替换后的值
dropna(axis='rows') 删除存在缺失值的
pandas删除缺失值,使用dropna的前提是,缺失值的类型必须是np.nan
注:不会修改原数据,需要接受返回值
"""
#Index(['Item A', 'Item C'], dtype='object')
# print(df.loc['User3'].replace(0,np.nan).dropna().index)
# 准备空白dict用来保存推荐结果
rs_results = {}
#遍历所有的最相似用户
for user, sim_users in topN_users.items():
rs_result = set() # 存储推荐结果
for sim_user in sim_users:
# 构建初始的推荐结果
# rs_result = rs_result.union(set(df.ix[sim_user].replace(0,np.nan).dropna().index))
rs_result = rs_result.union(set(df.loc[sim_user].replace(0,np.nan).dropna().index)) # ix[user] 和 loc[user] 均是获取User用户对应的一行Item值
# print("行值",df.loc[sim_user].replace(0,np.nan).dropna().index)
# # Index(['Item A', 'Item C'], dtype='object')
# print("行值", df.loc[sim_user].replace(0, np.nan).dropna())
# # Item A 1.0
# # Item C 1.0
# # Name: User3, dtype: float64
# print(rs_result) #{'Item D', 'Item C', 'Item A', 'Item E'}
# print(df.loc[user].replace(0,np.nan).dropna().index) #Index(['Item A', 'Item C', 'Item D'], dtype='object')
# 过滤掉已经购买过的物品
# rs_result -= set(df.ix[user].replace(0,np.nan).dropna().index)
rs_result -= set(df.loc[user].replace(0,np.nan).dropna().index) # ix[user] 和 loc[user] 均是获取User用户对应的一行Item值
# print(rs_result) #{'Item E'}
rs_results[user] = rs_result
# print("最终推荐结果:")
# pprint(rs_results)
# {'User1': {'Item E'},
# 'User2': {'Item C', 'Item B'},
# 'User3': {'Item D', 'Item E', 'Item B'},
# 'User4': {'Item C', 'Item A'},
# 'User5': {'Item D'}}
#-------------------------------------------------------------------------------------------------------------#
"""
基于基于物品的协同过滤推荐(Item-based CF):有了物品和物品之间两两的相似度,接下来就可以筛选TOP-N相似结果,并进行推荐了。
"""
topN_items = {}
# 遍历每一行数据
for i in item_similar.index:
# print(i) #Item A Item B Item C Item D Item E
# 取出每一列数据,并删除自身(即删除对角线上为1的值,该值代表的是自身和自身的相似度),然后排序数据
_df = item_similar.loc[i].drop([i])
# sort_values 排序 按照相似度的 降序排列(ascending=False)
_df_sorted = _df.sort_values(ascending=False)
# 从排序之后的结果中切片 取出前两条(相似度最高的两个)
top2 = list(_df_sorted.index[:2])
topN_items[i] = top2
# print("Top2相似物品:")
# pprint(topN_items)
# {'Item A': ['Item C', 'Item E'],
# 'Item B': ['Item E', 'Item D'],
# 'Item C': ['Item A', 'Item B'],
# 'Item D': ['Item E', 'Item A'],
# 'Item E': ['Item B', 'Item D']}
rs_results = {}
# 构建推荐结果:index获取的是 pd.DataFrame(datasets, columns=items, index=users)
for user in df.index: # 遍历所有用户
# print(user) #User1 User2 User3 User4 User5
rs_result = set()
# 取出datasets数据集中每个用户当前已购物品列表(每个User对应的一行Item)
# ix[user] 和 loc[user] 均是获取User用户对应的一行Item值
# for item in df.ix[user].replace(0,np.nan).dropna().index:
for item in df.loc[user].replace(0,np.nan).dropna().index:
# 根据用户所购买的每个物品找出最相似的TOP-N物品,构建初始推荐结果
rs_result = rs_result.union(topN_items[item])
# 过滤掉用户已购的物品
# 用户已购的物品:df.ix[user].replace(0,np.nan).dropna().index 获取User用户对应的一行Item值
rs_result -= set(df.loc[user].replace(0,np.nan).dropna().index) #loc[user]获取User用户对应的一行Item值
# 添加到结果中
rs_results[user] = rs_result
# print("最终推荐结果:")
# pprint(rs_results)
# {'User1': {'Item E', 'Item B'},
# 'User2': {'Item B', 'Item C'},
# 'User3': {'Item E', 'Item B'},
# 'User4': {'Item A'},
# 'User5': {'Item D'}}
使用协同过滤推荐算法对用户进行评分预测(预测用户对某物品的感兴趣程度):计算的是连续实数值向量之间的相关度
1.关于协同过滤推荐算法使用的数据集
1.在前面的“基于用户的协同过滤推荐、基于基于物品的协同过滤推荐”的demo中,仅是预测用户是否对某物品感兴趣,
我们只是使用用户对物品的一个购买记录,类似也可以是比如浏览点击记录、收听记录等等。
这样数据我们预测的结果其实相当于是在预测用户是否对某物品感兴趣,对于喜好程度不能很好的预测。
2.因此在协同过滤推荐算法中其实会更多的利用用户对物品的“评分”数据来进行预测喜好程度,通过评分数据集,我们可以预测用户对于他没有评分过的物品的评分。
其实现原理和思想和都是一样的,只是使用的数据集是用户-物品的评分数据。
2.关于用户-物品评分矩阵
用户-物品的评分矩阵,根据评分矩阵的稀疏程度会有不同的解决方案
1.稠密评分矩阵
2.稀疏评分矩阵
3.使用协同过滤推荐算法对用户进行评分预测
1.数据集:

2.目的:预测用户1对物品E的评分
构建数据集:注意这里构建评分数据时,对于缺失的部分我们需要保留为None,如果设置为0那么会被当作评分值为0去对待
# 目的:预测用户1对物品E的评分
# 构建数据集:注意这里构建评分数据时,对于缺失的部分我们需要保留为None,如果设置为0那么会被当作评分值为0去对待
users = ["User1", "User2", "User3", "User4", "User5"]
items = ["Item A", "Item B", "Item C", "Item D", "Item E"]
# 用户购买记录数据集
datasets = [
[5,3,4,4,None],
[3,1,2,3,3],
[4,3,4,3,5],
[3,3,1,5,4],
[1,5,5,2,1],
]
"""
相似度算法选择
1.余弦相似度/皮尔逊相关系数适合用户评分数据(实数值),不适合计算0/1布尔值向量之间的相关度(是否收藏、是否点击、是否加购物车)
2.杰卡德相似度适用于隐式反馈数据,适合计算0/1布尔值向量之间的相关度(是否收藏、是否点击、是否加购物车)
3.如果是分类型的连续型实数值(0/1/2/3...)则可以转换为one-hot编码,即转换为0/1布尔值向量之间的相关度计算问题,
即也可以使用杰卡德相似度来计算。
"""
# 计算相似度:对于评分数据这里我们采用皮尔逊相关系数[-1,1]来计算,-1表示强负相关,+1表示强正相关
# pandas中corr方法可直接用于计算皮尔逊相关系数
import pandas as pd
#index=users:users为行索引(行名)。columns=items:items为列索引(列名)
df = pd.DataFrame(datasets, columns=items, index=users)
"""
计算皮尔逊相关系数
DataFrame中的corr() 计算皮尔逊相关系数,默认是按列进行计算。
假如数据集设置的为index=users 和 columns=items,分别代表users为行索引(行名),items为列索引(列名)。
1.计算用户之间的相似度
因为index=users代表users为行索引(行名),即行索引(行名)为用户,因为corr()默认是按列进行计算的,
那么还需要把行索引(行名)转置为列索引(列名),那么才能计算用户之间的相似度。
user_similar = df.T.corr() 即可 计算用户之间的相似度。
2.计算物品之间的相似度
因为columns=items代表items为列索引(列名),即列索引(列名)便为物品,那么corr()默认是按列进行计算便是计算的是物品之间的相似度。
item_similar = df.corr() 即可 计算物品之间的相似度。
"""
print("用户之间的两两相似度:")
# 直接计算皮尔逊相关系数
# 默认是按列进行计算,因此如果计算用户间的相似度,当前需要进行转置
user_similar = df.T.corr()
print(user_similar.round(4))
print("物品之间的两两相似度:")
item_similar = df.corr()
print(item_similar.round(4))
"""
可以看到与用户1最相似的是用户2和用户3;与物品A最相似的物品分别是物品E和物品D。
注意:
我们在预测评分时,往往是通过与其有正相关的用户或物品进行预测,如果不存在正相关的情况,那么将无法做出预测。
这一点尤其是在稀疏评分矩阵中尤为常见,因为稀疏评分矩阵中很难得出正相关系数。
"""
(正数表示正相关的相似度值,负数表示负相关,在此处负数为无效值不考虑使用,如果不存在正相关的情况,那么将无法做出预测)
# 用户之间的两两相似度:
# User1 User2 User3 User4 User5
# User1 1.0000 0.8528 0.7071 0.0000 -0.7921
# User2 0.8528 1.0000 0.4677 0.4900 -0.9001
# User3 0.7071 0.4677 1.0000 -0.1612 -0.4666
# User4 0.0000 0.4900 -0.1612 1.0000 -0.6415
# User5 -0.7921 -0.9001 -0.4666 -0.6415 1.0000
# 物品之间的两两相似度:
# Item A Item B Item C Item D Item E
# Item A 1.0000 -0.4767 -0.1231 0.5322 0.9695
# Item B -0.4767 1.0000 0.6455 -0.3101 -0.4781
# Item C -0.1231 0.6455 1.0000 -0.7206 -0.4276
# Item D 0.5322 -0.3101 -0.7206 1.0000 0.5817
# Item E 0.9695 -0.4781 -0.4276 0.5817 1.0000
3.评分预测:
1.基于用户的协同过滤推荐(User-Based CF)评分预测:使用用户间的相似度进行预测
关于评分预测的方法也有比较多的方案,下面介绍一种效果比较好的方案,
该方案考虑了用户本身的评分以及近邻用户的加权平均相似度打分来进行预测。
# 用户之间的两两相似度:
# User1 User2 User3 User4 User5
# User1 1.0000 0.8528 0.7071 0.0000 -0.7921
# User2 0.8528 1.0000 0.4677 0.4900 -0.9001
# User3 0.7071 0.4677 1.0000 -0.1612 -0.4666
# User4 0.0000 0.4900 -0.1612 1.0000 -0.6415
# User5 -0.7921 -0.9001 -0.4666 -0.6415 1.0000
从上面的计算用户之间的相似度的结果可以看到与用户1最相似的是用户2和用户3
我们要预测用户1对物品E的评分,那么可以根据与用户1最近邻的用户2和用户3进行预测,计算如下:
与用户1最相似的是用户2和用户3的相似度分别为0.8528和0.7071,用户2和用户3对物品E的评分分别是3和5,
那么最终预测出用户1对物品E的评分为3.91


2.基于基于物品的协同过滤推荐(Item-Based CF)评分预测:使用物品间的相似度进行预测
这里利用物品相似度预测的计算同上,同样考虑了用户自身的平均打分因素,结合预测物品与相似物品的加权平均相似度打分进行来进行预测。
# 物品之间的两两相似度:
# Item A Item B Item C Item D Item E
# Item A 1.0000 -0.4767 -0.1231 0.5322 0.9695
# Item B -0.4767 1.0000 0.6455 -0.3101 -0.4781
# Item C -0.1231 0.6455 1.0000 -0.7206 -0.4276
# Item D 0.5322 -0.3101 -0.7206 1.0000 0.5817
# Item E 0.9695 -0.4781 -0.4276 0.5817 1.0000
从上面的计算物品之间的相似度的结果可以看到与物品E最相似的物品分别是物品A和物品D。
我们要预测用户1对物品E的评分,那么可以根据与物品E最近邻的物品A和物品D进行预测,计算如下:
与物品E最相似的物品A和物品D的相似度分别是0.9695和0.5817,那么对应用户1的物品A和物品D的评分分别是5和4,
那么最终预测出用户1对物品E的评分为4.63。 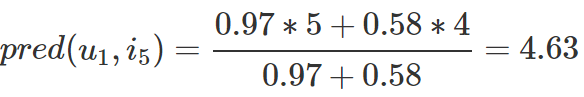

对比可见,User-Based CF预测评分和Item-Based CF的评分结果也是存在差异的,因为严格意义上他们其实应当属于两种不同的推荐算法,
各自在不同的领域不同场景下,都会比另一种的效果更佳,但具体哪一种更佳,必须经过合理的效果评估,
因此在实现推荐系统时这两种算法往往都是需要去实现的,然后对产生的推荐效果进行评估分析选出更优方案。
使用协同过滤推荐算法对用户进行评分预测
# 目的:预测用户1对物品E的评分
# 构建数据集:注意这里构建评分数据时,对于缺失的部分我们需要保留为None,如果设置为0那么会被当作评分值为0去对待
users = ["User1", "User2", "User3", "User4", "User5"]
items = ["Item A", "Item B", "Item C", "Item D", "Item E"]
# 用户购买记录数据集
datasets = [
[5,3,4,4,None],
[3,1,2,3,3],
[4,3,4,3,5],
[3,3,1,5,4],
[1,5,5,2,1],
]
"""
相似度算法选择
1.余弦相似度/皮尔逊相关系数适合用户评分数据(实数值),不适合计算0/1布尔值向量之间的相关度(是否收藏、是否点击、是否加购物车)
2.杰卡德相似度适用于隐式反馈数据,适合计算0/1布尔值向量之间的相关度(是否收藏、是否点击、是否加购物车)
3.如果是分类型的连续型实数值(0/1/2/3...)则可以转换为one-hot编码(即转换为0/1布尔值向量之间的相关度计算问题,即也可以使用杰卡德相似度来计算)。
"""
# 计算相似度:对于评分数据这里我们采用皮尔逊相关系数[-1,1]来计算,-1表示强负相关,+1表示强正相关
# pandas中corr方法可直接用于计算皮尔逊相关系数
import pandas as pd
#index=users:users为行索引(行名)。columns=items:items为列索引(列名)
df = pd.DataFrame(datasets, columns=items, index=users)
"""
计算皮尔逊相关系数
DataFrame中的corr() 计算皮尔逊相关系数,默认是按列进行计算。
假如数据集设置的为index=users 和 columns=items,分别代表users为行索引(行名),items为列索引(列名)。
1.计算用户之间的相似度
因为index=users代表users为行索引(行名),即行索引(行名)为用户,因为corr()默认是按列进行计算的,
那么还需要把行索引(行名)转置为列索引(列名),那么才能计算用户之间的相似度。
user_similar = df.T.corr() 即可 计算用户之间的相似度。
2.计算物品之间的相似度
因为columns=items代表items为列索引(列名),即列索引(列名)便为物品,那么corr()默认是按列进行计算便是计算的是物品之间的相似度。
item_similar = df.corr() 即可 计算物品之间的相似度。
"""
print("用户之间的两两相似度:")
# 直接计算皮尔逊相关系数
# 默认是按列进行计算,因此如果计算用户间的相似度,当前需要进行转置
user_similar = df.T.corr()
print(user_similar.round(4))
print("物品之间的两两相似度:")
item_similar = df.corr()
print(item_similar.round(4))
"""
可以看到与用户1最相似的是用户2和用户3;与物品A最相似的物品分别是物品E和物品D。
注意:
我们在预测评分时,往往是通过与其有正相关的用户或物品进行预测,如果不存在正相关的情况,那么将无法做出预测。
这一点尤其是在稀疏评分矩阵中尤为常见,因为稀疏评分矩阵中很难得出正相关系数。
"""
# 用户之间的两两相似度:(正数表示正相关的相似度值,负数表示负相关,在此处负数为无效值不考虑使用,如果不存在正相关的情况,那么将无法做出预测。)
# User1 User2 User3 User4 User5
# User1 1.0000 0.8528 0.7071 0.0000 -0.7921
# User2 0.8528 1.0000 0.4677 0.4900 -0.9001
# User3 0.7071 0.4677 1.0000 -0.1612 -0.4666
# User4 0.0000 0.4900 -0.1612 1.0000 -0.6415
# User5 -0.7921 -0.9001 -0.4666 -0.6415 1.0000
# 物品之间的两两相似度:
# Item A Item B Item C Item D Item E
# Item A 1.0000 -0.4767 -0.1231 0.5322 0.9695
# Item B -0.4767 1.0000 0.6455 -0.3101 -0.4781
# Item C -0.1231 0.6455 1.0000 -0.7206 -0.4276
# Item D 0.5322 -0.3101 -0.7206 1.0000 0.5817
# Item E 0.9695 -0.4781 -0.4276 0.5817 1.0000 协同过滤推荐算法代码实现
# 构建数据集:users为行索引(行名),items为列索引(列名)
users = ["User1", "User2", "User3", "User4", "User5"]
items = ["Item A", "Item B", "Item C", "Item D", "Item E"]
# 构建数据集:"buy"为1,None为0
# datasets = [
# ["buy",None,"buy","buy",None],
# ["buy",None,None,"buy","buy"],
# ["buy",None,"buy",None,None],
# [None,"buy",None,"buy","buy"],
# ["buy","buy","buy",None,"buy"],
# ]
"""
计算时我们数据通常都需要对数据进行处理,或者编码,目的是为了便于我们对数据进行运算处理,
比如这里是比较简单的情形,我们用1、0分别来表示用户的是否购买过该物品,则我们的数据集其实应该是这样的:
Item A Item B Item C Item D Item E
User1 1 0 1 1 0
User2 1 0 0 1 1
User3 1 0 1 0 0
User4 0 1 0 1 1
User5 1 1 1 0 1
注意:
1.因为一开始datasets所构建的数据集df.values为矩阵行名(行索引)为用户users,矩阵列名(列索引)为物品items 才能计算用户和用户之间的相似度,
因此基于用户的协同过滤推荐(User-based CF)计算用户和用户之间的相似度使用:pairwise_distances(df.values, metric="jaccard")。
2.datasets所构建的数据集df.values.T转置后变为矩阵行名(行索引)为物品items,矩阵列名(列索引)为用户users 才能计算物品和物品之间的相似度,
因此基于物品的协同过滤推荐(Item-based CF))计算物品和物品之间的相似度使用:pairwise_distances(df.values.T, metric="jaccard")。
"""
# 用户购买记录数据集:"buy"为1,None为0
datasets = [
[1,0,1,1,0],
[1,0,0,1,1],
[1,0,1,0,0],
[0,1,0,1,1],
[1,1,1,0,1],
]
import pandas as pd
#index=users:users为行索引(行名)。columns=items:items为列索引(列名)
# df = pd.DataFrame(datasets, columns=items, index=users, dtype=bool)
df = pd.DataFrame(datasets, columns=items, index=users)
# print(df)
# print(df.values)
# [[ True False True True False]
# [ True False False True True]
# [ True False True False False]
# [False True False True True]
# [ True True True False True]]
#-------------------------------------------------------------------------------------------------------------#
"""
有了数据集,接下来我们就可以进行相似度的计算,不过对于相似度的计算其实是有很多专门的相似度计算方法的,
比如余弦相似度、皮尔逊相关系数、杰卡德相似度等等。这里我们选择使用杰卡德相似系数计算datasets=[0,1]值。
"""
from sklearn.metrics import jaccard_similarity_score
# 直接计算某两项的杰卡德相似系数
# 计算Item A 和Item B的相似度(物品之间的两两相似度):0.2
# print(jaccard_similarity_score(df["Item A"], df["Item B"])) #0.2
"""
报错:AttributeError: 'DataFrame' object has no attribute 'dtype'
解决:pairwise_distances(df, metric="jaccard") 修改为 pairwise_distances(df.values, metric="jaccard")
警告:DataConversionWarning: Data was converted to boolean for metric jaccard。warnings.warn(msg, DataConversionWarning)
解释:DataConversionWarning:数据已转换为度量jaccard的布尔值警告.warn(消息,数据转换警告)
解决:设置dtype=bool,比如 df = pd.DataFrame(datasets, columns=items, index=users, dtype=bool)
警告:DeprecationWarning: jaccard_similarity_score has been deprecated and replaced with jaccard_score.
It will be removed in version 0.23. This implementation has surprising behavior for binary and multiclass classification tasks.
'and multiclass classification tasks.', DeprecationWarning)
解释:不推荐警告:jaccard_similarity_score已被不推荐并替换为jaccard_score。它将在0.23版中删除。
此实现对于二进制和多类分类任务和多类分类任务具有令人惊讶的行为。DeprecationWarning)
分析:jaccard_similarity_score方法已经过时
"""
# 计算所有的数据两两的杰卡德相似系数
from sklearn.metrics.pairwise import pairwise_distances
"""
1.“跟你喜好相似的人喜欢的东西你也很有可能喜欢”:基于用户的协同过滤推荐(User-based CF)。
基于用户的稀疏矩阵:矩阵行名为users,矩阵列名为items。
2.因为一开始datasets所构建的数据集df.values为矩阵行名(行索引)为用户users,矩阵列名(列索引)为物品items 才能计算用户和用户之间的相似度,
因此基于用户的协同过滤推荐(User-based CF)计算用户和用户之间的相似度使用:pairwise_distances(df.values, metric="jaccard")。
"""
# 计算用户间相似度:metric="jaccard" 使用杰卡德相似系数
user_similar = 1 - pairwise_distances(df.values, metric="jaccard")
#DataFrame构建显示数据
user_similar = pd.DataFrame(user_similar, columns=users, index=users)
# print("用户之间的两两相似度:")
# print(user_similar)
# User1 User2 User3 User4 User5
# User1 1.000000 0.50 0.666667 0.2 0.4
# User2 0.500000 1.00 0.250000 0.5 0.4
# User3 0.666667 0.25 1.000000 0.0 0.5
# User4 0.200000 0.50 0.000000 1.0 0.4
# User5 0.400000 0.40 0.500000 0.4 1.0
"""
1.“跟你喜欢的东西相似的东西你也很有可能喜欢 ”:基于物品的协同过滤推荐(Item-based CF)。
基于内容(物品)的稀疏矩阵:矩阵行名为items,矩阵列名为users。
2.datasets所构建的数据集df.values.T转置后变为矩阵行名(行索引)为物品items,矩阵列名(列索引)为用户users 才能计算物品和物品之间的相似度,
因此基于物品的协同过滤推荐(Item-based CF))计算物品和物品之间的相似度使用:pairwise_distances(df.values.T, metric="jaccard")。
"""
# 计算物品间相似度
item_similar = 1 - pairwise_distances(df.values.T, metric="jaccard")
item_similar = pd.DataFrame(item_similar, columns=items, index=items)
# print("物品之间的两两相似度:")
# print(item_similar)
# Item A Item B Item C Item D Item E
# Item A 1.00 0.200000 0.75 0.40 0.400000
# Item B 0.20 1.000000 0.25 0.25 0.666667
# Item C 0.75 0.250000 1.00 0.20 0.200000
# Item D 0.40 0.250000 0.20 1.00 0.500000
# Item E 0.40 0.666667 0.20 0.50 1.000000
#-------------------------------------------------------------------------------------------------------------#
import numpy as np
from pprint import pprint
"""
基于用户的协同过滤推荐(User-based CF):有了用户和用户之间两两的相似度,接下来就可以筛选TOP-N相似结果,并进行推荐了。
"""
topN_users = {}
# 遍历每一行数据:index获取的是 pd.DataFrame(user_similar, columns=users, index=users)中设置的index=users 行名(行索引值)
for i in user_similar.index:
# print(i) #User1 User2 User3 User4 User5
# print("user_similar.loc[i]",user_similar.loc[i])
#比如:
# User1 1.000000
# User2 0.500000
# User3 0.666667
# User4 0.200000
# User5 0.400000
# Name: User1, dtype: float64
# 取出每一列数据,并删除自身(即删除对角线上为1的值,该值代表的是自身和自身的相似度),然后排序数据
_df = user_similar.loc[i].drop([i])
#sort_values 排序 按照相似度的 降序排列(ascending=False)
_df_sorted = _df.sort_values(ascending=False)
# 从排序之后的结果中切片 取出前两条(相似度最高的两个)
top2 = list(_df_sorted.index[:2])
topN_users[i] = top2
# print("Top2相似用户:")
# pprint(topN_users)
# {'User1': ['User3', 'User2'],
# 'User2': ['User4', 'User1'],
# 'User3': ['User1', 'User5'],
# 'User4': ['User2', 'User5'],
# 'User5': ['User3', 'User4']}
"""
警告:utureWarning:
.ix is deprecated. Please use
.loc for label based indexing or
.iloc for positional indexing
分析:
1.直接使用行列索引(先列后行):直接索引 -- 先列后行, 是需要通过索引的字符串进行获取
2.使用loc只能指定行列索引的名字去获取:loc -- 先行后列, 是需要通过索引的字符串进行获取
3.使用iloc可以通过索引的下标去获取:iloc -- 先行后列, 是通过下标进行索引
4.使用ix组合索引:ix -- 先行后列, 可以用上面两种方法混合进行索引
-------------------------------------------------------------------------
replace(to_replace=, value=)
to_replace:替换前的值
value:替换后的值
dropna(axis='rows') 删除存在缺失值的
pandas删除缺失值,使用dropna的前提是,缺失值的类型必须是np.nan
注:不会修改原数据,需要接受返回值
"""
#Index(['Item A', 'Item C'], dtype='object')
# print(df.loc['User3'].replace(0,np.nan).dropna().index)
# 准备空白dict用来保存推荐结果
rs_results = {}
#遍历所有的最相似用户
for user, sim_users in topN_users.items():
rs_result = set() # 存储推荐结果
for sim_user in sim_users:
# 构建初始的推荐结果
# rs_result = rs_result.union(set(df.ix[sim_user].replace(0,np.nan).dropna().index))
rs_result = rs_result.union(set(df.loc[sim_user].replace(0,np.nan).dropna().index)) # ix[user] 和 loc[user] 均是获取User用户对应的一行Item值
# print("行值",df.loc[sim_user].replace(0,np.nan).dropna().index)
# # Index(['Item A', 'Item C'], dtype='object')
# print("行值", df.loc[sim_user].replace(0, np.nan).dropna())
# # Item A 1.0
# # Item C 1.0
# # Name: User3, dtype: float64
# print(rs_result) #{'Item D', 'Item C', 'Item A', 'Item E'}
# print(df.loc[user].replace(0,np.nan).dropna().index) #Index(['Item A', 'Item C', 'Item D'], dtype='object')
# 过滤掉已经购买过的物品
# rs_result -= set(df.ix[user].replace(0,np.nan).dropna().index)
rs_result -= set(df.loc[user].replace(0,np.nan).dropna().index) # ix[user] 和 loc[user] 均是获取User用户对应的一行Item值
# print(rs_result) #{'Item E'}
rs_results[user] = rs_result
# print("最终推荐结果:")
# pprint(rs_results)
# {'User1': {'Item E'},
# 'User2': {'Item C', 'Item B'},
# 'User3': {'Item D', 'Item E', 'Item B'},
# 'User4': {'Item C', 'Item A'},
# 'User5': {'Item D'}}
#-------------------------------------------------------------------------------------------------------------#
"""
基于基于物品的协同过滤推荐(Item-based CF):有了物品和物品之间两两的相似度,接下来就可以筛选TOP-N相似结果,并进行推荐了。
"""
topN_items = {}
# 遍历每一行数据
for i in item_similar.index:
# print(i) #Item A Item B Item C Item D Item E
# 取出每一列数据,并删除自身(即删除对角线上为1的值,该值代表的是自身和自身的相似度),然后排序数据
_df = item_similar.loc[i].drop([i])
# sort_values 排序 按照相似度的 降序排列(ascending=False)
_df_sorted = _df.sort_values(ascending=False)
# 从排序之后的结果中切片 取出前两条(相似度最高的两个)
top2 = list(_df_sorted.index[:2])
topN_items[i] = top2
# print("Top2相似物品:")
# pprint(topN_items)
# {'Item A': ['Item C', 'Item E'],
# 'Item B': ['Item E', 'Item D'],
# 'Item C': ['Item A', 'Item B'],
# 'Item D': ['Item E', 'Item A'],
# 'Item E': ['Item B', 'Item D']}
rs_results = {}
# 构建推荐结果:index获取的是 pd.DataFrame(datasets, columns=items, index=users)
for user in df.index: # 遍历所有用户
# print(user) #User1 User2 User3 User4 User5
rs_result = set()
# 取出datasets数据集中每个用户当前已购物品列表(每个User对应的一行Item)
# ix[user] 和 loc[user] 均是获取User用户对应的一行Item值
# for item in df.ix[user].replace(0,np.nan).dropna().index:
for item in df.loc[user].replace(0,np.nan).dropna().index:
# 根据用户所购买的每个物品找出最相似的TOP-N物品,构建初始推荐结果
rs_result = rs_result.union(topN_items[item])
# 过滤掉用户已购的物品
# 用户已购的物品:df.ix[user].replace(0,np.nan).dropna().index 获取User用户对应的一行Item值
rs_result -= set(df.loc[user].replace(0,np.nan).dropna().index) #loc[user]获取User用户对应的一行Item值
# 添加到结果中
rs_results[user] = rs_result
# print("最终推荐结果:")
# pprint(rs_results)
# {'User1': {'Item E', 'Item B'},
# 'User2': {'Item B', 'Item C'},
# 'User3': {'Item E', 'Item B'},
# 'User4': {'Item A'},
# 'User5': {'Item D'}} In [1]:
import pandas as pdIn [2]:
users = ["User1", "User2", "User3", "User4", "User5"]items = ["Item A", "Item B", "Item C", "Item D", "Item E"]# 用户购买记录数据集datasets = [ [1,0,1,1,0], [1,0,0,1,1], [1,0,1,0,0], [0,1,0,1,1], [1,1,1,0,1],]In [3]:
df = pd.DataFrame(data=datasets,index=users,columns=items)In [4]:
dfOut[4]:
| Item A | Item B | Item C | Item D | Item E | |
|---|---|---|---|---|---|
| User1 | 1 | 0 | 1 | 1 | 0 |
| User2 | 1 | 0 | 0 | 1 | 1 |
| User3 | 1 | 0 | 1 | 0 | 0 |
| User4 | 0 | 1 | 0 | 1 | 1 |
| User5 | 1 | 1 | 1 | 0 | 1 |
In [5]:
from sklearn.metrics import jaccard_similarity_scoreIn [6]:
jaccard_similarity_score(df["Item A"],df["Item B"])Out[6]:
0.2In [7]:
from sklearn.metrics.pairwise import pairwise_distancesIn [8]:
user_similar = 1-pairwise_distances(df,metric="jaccard")C:\ProgramData\Anaconda3\lib\site-packages\sklearn\utils\validation.py:475: DataConversionWarning: Data with input dtype int64 was converted to bool by check_pairwise_arrays.
warnings.warn(msg, DataConversionWarning)
In [9]:
user_similarOut[9]:
array([[1. , 0.5 , 0.66666667, 0.2 , 0.4 ],
[0.5 , 1. , 0.25 , 0.5 , 0.4 ],
[0.66666667, 0.25 , 1. , 0. , 0.5 ],
[0.2 , 0.5 , 0. , 1. , 0.4 ],
[0.4 , 0.4 , 0.5 , 0.4 , 1. ]])In [10]:
user_similar = pd.DataFrame(user_similar, columns=users, index=users)In [11]:
user_similarOut[11]:
| User1 | User2 | User3 | User4 | User5 | |
|---|---|---|---|---|---|
| User1 | 1.000000 | 0.50 | 0.666667 | 0.2 | 0.4 |
| User2 | 0.500000 | 1.00 | 0.250000 | 0.5 | 0.4 |
| User3 | 0.666667 | 0.25 | 1.000000 | 0.0 | 0.5 |
| User4 | 0.200000 | 0.50 | 0.000000 | 1.0 | 0.4 |
| User5 | 0.400000 | 0.40 | 0.500000 | 0.4 | 1.0 |
In [13]:
# 计算物品间相似度item_similar = 1 - pairwise_distances(df.T, metric="jaccard")item_similar = pd.DataFrame(item_similar, columns=items, index=items)print("物品之间的两两相似度:")print(item_similar)物品之间的两两相似度:
Item A Item B Item C Item D Item E
Item A 1.00 0.200000 0.75 0.40 0.400000
Item B 0.20 1.000000 0.25 0.25 0.666667
Item C 0.75 0.250000 1.00 0.20 0.200000
Item D 0.40 0.250000 0.20 1.00 0.500000
Item E 0.40 0.666667 0.20 0.50 1.000000
C:\ProgramData\Anaconda3\lib\site-packages\sklearn\utils\validation.py:475: DataConversionWarning: Data with input dtype int64 was converted to bool by check_pairwise_arrays.
warnings.warn(msg, DataConversionWarning)
In [14]:
#定义一个字典,用于盛放用户的topN个相似用户(这里是2)topN_users={}In [28]:
for i in user_similar.index: #删除对角线上的自己与自己的相似度1 _df = user_similar.loc[i].drop([i]) _df_sorted = _df.sort_values(ascending=False) #print(_df_sorted.values) #top2 = list(_df_sorted)[:2] top2=list(_df_sorted.index[:2]) print(top2) topN_users[i]=top2['User3', 'User2']
['User4', 'User1']
['User1', 'User5']
['User2', 'User5']
['User3', 'User4']
In [17]:
user_similarOut[17]:
| User1 | User2 | User3 | User4 | User5 | |
|---|---|---|---|---|---|
| User1 | 1.000000 | 0.50 | 0.666667 | 0.2 | 0.4 |
| User2 | 0.500000 | 1.00 | 0.250000 | 0.5 | 0.4 |
| User3 | 0.666667 | 0.25 | 1.000000 | 0.0 | 0.5 |
| User4 | 0.200000 | 0.50 | 0.000000 | 1.0 | 0.4 |
| User5 | 0.400000 | 0.40 | 0.500000 | 0.4 | 1.0 |
In [29]:
topN_usersOut[29]:
{'User1': ['User3', 'User2'],
'User2': ['User4', 'User1'],
'User3': ['User1', 'User5'],
'User4': ['User2', 'User5'],
'User5': ['User3', 'User4']}In [33]:
import numpy as npIn [37]:
list(df.ix['User3'].replace(0,np.nan).dropna().index)Out[37]:
['Item A', 'Item C']In [32]:
dfOut[32]:
| Item A | Item B | Item C | Item D | Item E | |
|---|---|---|---|---|---|
| User1 | 1 | 0 | 1 | 1 | 0 |
| User2 | 1 | 0 | 0 | 1 | 1 |
| User3 | 1 | 0 | 1 | 0 | 0 |
| User4 | 0 | 1 | 0 | 1 | 1 |
| User5 | 1 | 1 | 1 | 0 | 1 |
In [38]:
rs_results={}In [39]:
for user,sim_users in topN_users.items(): rs_result=set() for sim_user in sim_users: rs_result = rs_result.union(set(df.loc[sim_user].replace(0,np.nan).dropna().index)) rs_result -= set(df.loc[user].replace(0,np.nan).dropna().index) rs_results[user]=rs_resultIn [40]:
rs_resultsOut[40]:
{'User1': {'Item E'},
'User2': {'Item B', 'Item C'},
'User3': {'Item B', 'Item D', 'Item E'},
'User4': {'Item A', 'Item C'},
'User5': {'Item D'}}In [41]:
import pandas as pdimport numpy as npfrom pprint import pprintusers = ["User1", "User2", "User3", "User4", "User5"]items = ["Item A", "Item B", "Item C", "Item D", "Item E"]# 用户购买记录数据集datasets = [ [1,0,1,1,0], [1,0,0,1,1], [1,0,1,0,0], [0,1,0,1,1], [1,1,1,0,1],]df = pd.DataFrame(datasets, columns=items, index=users)In [42]:
#计算物品的两两相似度In [43]:
#直接计算出两两的jaccard相似度item_similar = 1-pairwise_distances(df.T,metric='jaccard')print(item_similar)[[1. 0.2 0.75 0.4 0.4 ]
[0.2 1. 0.25 0.25 0.66666667]
[0.75 0.25 1. 0.2 0.2 ]
[0.4 0.25 0.2 1. 0.5 ]
[0.4 0.66666667 0.2 0.5 1. ]]
C:\ProgramData\Anaconda3\lib\site-packages\sklearn\utils\validation.py:475: DataConversionWarning: Data with input dtype int64 was converted to bool by check_pairwise_arrays.
warnings.warn(msg, DataConversionWarning)
In [47]:
item_similar = pd.DataFrame(item_similar,index=items,columns=items)In [48]:
item_similarOut[48]:
| Item A | Item B | Item C | Item D | Item E | |
|---|---|---|---|---|---|
| Item A | 1.00 | 0.200000 | 0.75 | 0.40 | 0.400000 |
| Item B | 0.20 | 1.000000 | 0.25 | 0.25 | 0.666667 |
| Item C | 0.75 | 0.250000 | 1.00 | 0.20 | 0.200000 |
| Item D | 0.40 | 0.250000 | 0.20 | 1.00 | 0.500000 |
| Item E | 0.40 | 0.666667 | 0.20 | 0.50 | 1.000000 |
In [46]:
itemsOut[46]:
['Item A', 'Item B', 'Item C', 'Item D', 'Item E']In [44]:
#目标:找到物品的topN个相似物品In [45]:
topN_items={}In [54]:
for i in item_similar.index: _df = item_similar.loc[i].drop([i]) _df_sorted = _df.sort_values(ascending=False) top2 = list(_df_sorted.index[:2]) topN_items[i]=top2In [55]:
topN_itemsOut[55]:
{'Item A': ['Item C', 'Item E'],
'Item B': ['Item E', 'Item D'],
'Item C': ['Item A', 'Item B'],
'Item D': ['Item E', 'Item A'],
'Item E': ['Item B', 'Item D']}In [56]:
#获取需要推荐给用户的物品In [57]:
#定义一个字典,用于盛放所有的推荐结果rs_results={}In [62]:
for user in df.index: #定义一个针对于单个用户的推荐结果的集合 rs_result=set() #将遍历的每个用户的已经买过的物品取出 for item in df.loc[user].replace(0,np.nan).dropna().index: rs_result = rs_result.union(topN_items[item]) #过滤用户已经购买过的物品 rs_result -= set(df.loc[user].replace(0,np.nan).dropna().index) #将每次遍历得到的推荐结果放入总的推荐结果中 rs_results[user]=rs_resultIn [63]:
rs_resultsOut[63]:
{'User1': {'Item B', 'Item E'},
'User2': {'Item B', 'Item C'},
'User3': {'Item B', 'Item E'},
'User4': {'Item A'},
'User5': {'Item D'}}In [64]:
users = ["User1", "User2", "User3", "User4", "User5"]items = ["Item A", "Item B", "Item C", "Item D", "Item E"]# 用户购买记录数据集datasets = [ [5,3,4,4,None], [3,1,2,3,3], [4,3,4,3,5], [3,3,1,5,4], [1,5,5,2,1],]In [65]:
df = pd.DataFrame(datasets, columns=items, index=users)In [66]:
dfOut[66]:
| Item A | Item B | Item C | Item D | Item E | |
|---|---|---|---|---|---|
| User1 | 5 | 3 | 4 | 4 | NaN |
| User2 | 3 | 1 | 2 | 3 | 3.0 |
| User3 | 4 | 3 | 4 | 3 | 5.0 |
| User4 | 3 | 3 | 1 | 5 | 4.0 |
| User5 | 1 | 5 | 5 | 2 | 1.0 |
In [67]:
print("用户之间的两两相似度:")用户之间的两两相似度:
In [68]:
df.T.corr()Out[68]:
| User1 | User2 | User3 | User4 | User5 | |
|---|---|---|---|---|---|
| User1 | 1.000000 | 0.852803 | 0.707107 | 0.000000 | -0.792118 |
| User2 | 0.852803 | 1.000000 | 0.467707 | 0.489956 | -0.900149 |
| User3 | 0.707107 | 0.467707 | 1.000000 | -0.161165 | -0.466569 |
| User4 | 0.000000 | 0.489956 | -0.161165 | 1.000000 | -0.641503 |
| User5 | -0.792118 | -0.900149 | -0.466569 | -0.641503 | 1.000000 |
In [69]:
df.corr()Out[69]:
| Item A | Item B | Item C | Item D | Item E | |
|---|---|---|---|---|---|
| Item A | 1.000000 | -0.476731 | -0.123091 | 0.532181 | 0.969458 |
| Item B | -0.476731 | 1.000000 | 0.645497 | -0.310087 | -0.478091 |
| Item C | -0.123091 | 0.645497 | 1.000000 | -0.720577 | -0.427618 |
| Item D | 0.532181 | -0.310087 | -0.720577 | 1.000000 | 0.581675 |
| Item E | 0.969458 | -0.478091 | -0.427618 | 0.581675 | 1.000000 |
In [1]:
import osimport pandas as pdimport numpy as npIn [5]:
DATA_PATH = "./ratings.csv"In [6]:
dtype={"userId":np.int32,"movieId": np.int32, "rating": np.float32}In [7]:
#useCols:读取一个文件,需要的列索引值ratings = pd.read_csv(DATA_PATH,dtype=dtype,usecols=range(3))In [8]:
#构建透视表:行索引为userId,列索引为movieId,值为ratingIn [10]:
ratings_matrix = ratings.pivot_table(index=["userId"],columns=["movieId"],values="rating")In [11]:
#计算相似度user_similar = ratings_matrix.T.corr()In [12]:
user_similarOut[12]:
| userId | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ... | 601 | 602 | 603 | 604 | 605 | 606 | 607 | 608 | 609 | 610 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| userId | |||||||||||||||||||||
| 1 | 1.000000 | NaN | 0.079819 | 0.207983 | 0.268749 | -2.916358e-01 | -0.118773 | 0.469668 | 0.918559 | -0.037987 | ... | 0.091574 | 0.000000 | -0.061503 | -0.407556 | -0.164871 | 6.637849e-02 | 0.174557 | 0.268070 | -0.175412 | -0.032086 |
| 2 | NaN | 1.000000 | NaN | NaN | NaN | NaN | -0.991241 | NaN | NaN | 0.037796 | ... | -0.387347 | NaN | -1.000000 | NaN | NaN | 5.833333e-01 | NaN | -0.125000 | NaN | 0.623288 |
| 3 | 0.079819 | NaN | 1.000000 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | 0.433200 | NaN | NaN | -7.913343e-01 | -0.333333 | -0.395092 | NaN | 0.569562 |
| 4 | 0.207983 | NaN | NaN | 1.000000 | -0.336525 | 1.484982e-01 | 0.542861 | 0.117851 | NaN | 0.485794 | ... | -0.222113 | 0.396641 | 0.090090 | -0.080296 | 0.400124 | 1.446033e-01 | 0.116518 | -0.170501 | -0.277350 | -0.043786 |
| 5 | 0.268749 | NaN | NaN | -0.336525 | 1.000000 | 4.316590e-02 | 0.158114 | 0.028347 | NaN | -0.777714 | ... | 0.000000 | 0.153303 | 0.234743 | 0.067791 | -0.364156 | 2.443212e-01 | 0.231080 | -0.020546 | 0.384111 | 0.040582 |
| 6 | -0.291636 | NaN | NaN | 0.148498 | 0.043166 | 1.000000e+00 | -0.126595 | -0.200062 | NaN | 0.957427 | ... | -0.292770 | -0.027495 | -0.112141 | -0.090297 | 0.100735 | -4.919190e-02 | 0.255639 | 0.125428 | 0.193649 | 0.115580 |
| 7 | -0.118773 | -0.991241 | NaN | 0.542861 | 0.158114 | -1.265950e-01 | 1.000000 | 0.220416 | 0.925000 | -0.156764 | ... | -0.280496 | 0.110432 | 0.343649 | 0.560968 | 0.416186 | 1.377715e-01 | 0.402792 | 0.008081 | 0.420288 | 0.341233 |
| 8 | 0.469668 | NaN | NaN | 0.117851 | 0.028347 | -2.000621e-01 | 0.220416 | 1.000000 | NaN | -1.000000 | ... | 1.000000 | 0.190902 | 0.249252 | 0.534375 | -0.217405 | 2.535821e-01 | 0.251280 | 0.434423 | 0.141860 | 0.167931 |
| 9 | 0.918559 | NaN | NaN | NaN | NaN | NaN | 0.925000 | NaN | 1.000000 | NaN | ... | 0.577350 | NaN | 0.376715 | NaN | 0.158777 | 5.726999e-01 | NaN | 0.336625 | NaN | 0.615638 |
| 10 | -0.037987 | 0.037796 | NaN | 0.485794 | -0.777714 | 9.574271e-01 | -0.156764 | -1.000000 | NaN | 1.000000 | ... | -0.397276 | -0.944911 | -0.424631 | -1.000000 | 0.268684 | -3.829551e-01 | -0.241121 | -0.571043 | NaN | -0.205081 |
| 11 | -0.087643 | NaN | NaN | 0.564737 | 0.268293 | 4.832447e-01 | -0.027349 | 0.253576 | NaN | NaN | ... | -0.301511 | 0.274963 | -0.176996 | -0.015131 | -0.019104 | 6.213867e-01 | 0.434014 | 0.335976 | 0.151744 | 0.137054 |
| 12 | NaN | NaN | NaN | -0.344031 | 1.000000 | 0.000000e+00 | 0.000000 | -1.000000 | NaN | 0.562500 | ... | NaN | 1.000000 | -0.248679 | -0.507093 | 0.500000 | 8.956222e-02 | -0.365148 | -0.322817 | NaN | -0.672977 |
| 13 | 0.878310 | NaN | NaN | -0.558242 | NaN | NaN | -0.500000 | 1.000000 | NaN | -0.381246 | ... | 0.375000 | 1.000000 | 0.674020 | NaN | NaN | 7.755102e-02 | 0.188982 | 0.493318 | NaN | 0.796969 |
| 14 | 0.229081 | NaN | NaN | -0.139347 | -0.153323 | 2.766621e-01 | 0.806872 | 0.123460 | NaN | 0.500000 | ... | -1.000000 | 0.017314 | 0.188061 | 0.507168 | -0.151620 | 3.468145e-01 | 0.223669 | 0.238901 | -0.077615 | 0.140482 |
| 15 | 0.232636 | -0.330174 | -0.944911 | 0.481605 | -0.252352 | 1.163945e-02 | -0.155384 | -0.139122 | -0.482805 | -0.030515 | ... | 0.098446 | 0.665169 | -0.047094 | 0.534634 | 0.124442 | 8.667785e-02 | -0.084814 | 0.344304 | 0.458333 | -0.099907 |
| 16 | 0.191851 | -0.176471 | NaN | -0.137553 | -0.684653 | -1.837726e-02 | -0.096233 | 0.665133 | NaN | 0.583639 | ... | -0.157174 | 0.086212 | 0.157807 | -0.754337 | 0.012649 | -4.867394e-02 | 0.055125 | -0.302915 | NaN | -0.134150 |
| 17 | 0.037901 | 0.000000 | NaN | -0.218928 | 0.310835 | 2.400077e-02 | 0.287803 | 0.000000 | NaN | -0.005896 | ... | 0.192548 | 0.323875 | 0.174955 | 0.528594 | -0.147821 | 1.226658e-01 | -0.189118 | 0.300821 | 0.638915 | -0.034653 |
| 18 | 0.205371 | -0.264646 | -0.354548 | -0.007641 | 0.162995 | 9.380339e-03 | 0.206082 | 0.029953 | 0.252714 | -0.082679 | ... | 0.264801 | 0.423578 | 0.389637 | 0.203806 | 0.103834 | 5.216392e-01 | 0.169145 | 0.375750 | 0.400000 | 0.327397 |
| 19 | 0.325180 | NaN | -0.442498 | 0.072000 | 0.271827 | 2.591888e-01 | 0.194649 | 0.139882 | 0.976296 | -0.561617 | ... | 0.561962 | 0.246154 | 0.160288 | 0.093863 | 0.256556 | 2.542703e-01 | 0.003567 | 0.229268 | -0.068519 | 0.399213 |
| 20 | 0.419641 | NaN | NaN | 0.620758 | 0.040032 | 2.133011e-01 | 0.451035 | 0.747018 | 0.561249 | 0.122967 | ... | -0.338062 | 0.393445 | 0.244265 | -0.610802 | 0.085819 | 4.328764e-01 | 0.319964 | 0.030331 | NaN | 0.413368 |
| 21 | 0.107119 | -0.020535 | -0.991241 | -0.059131 | -0.339422 | 3.057183e-01 | 0.024363 | 0.084020 | -0.386592 | 0.269043 | ... | -0.150859 | 0.147429 | -0.485182 | 0.265872 | -0.008274 | -1.638329e-01 | -0.237823 | 0.028065 | 0.623250 | -0.063044 |
| 22 | -0.463039 | -0.619292 | NaN | 0.259412 | NaN | 8.964215e-01 | 0.053010 | -0.500000 | NaN | -0.035275 | ... | -0.113398 | 0.500000 | 0.424252 | NaN | -0.321719 | 2.230021e-02 | 0.141421 | -0.106111 | NaN | 0.208517 |
| 23 | -0.364372 | NaN | NaN | -0.229480 | 0.000000 | -4.050463e-01 | 0.175781 | 0.324443 | NaN | -0.218218 | ... | 0.261839 | -0.090909 | 0.023665 | -0.190941 | 0.500000 | 2.367592e-01 | 0.024012 | -0.029124 | 1.000000 | -0.074424 |
| 24 | 0.249046 | -0.641689 | NaN | 0.151800 | 0.193649 | 7.775791e-02 | -0.057351 | 0.166667 | 1.000000 | -0.049613 | ... | 0.448297 | 0.128046 | 0.207174 | -0.099340 | -0.229170 | 1.857959e-01 | 0.195180 | 0.176818 | NaN | 0.121548 |
| 25 | -0.166667 | 0.108465 | NaN | NaN | NaN | NaN | NaN | 1.000000 | NaN | NaN | ... | 0.284901 | 1.000000 | NaN | NaN | NaN | 7.287987e-01 | NaN | 0.693375 | NaN | 0.371303 |
| 26 | 0.141421 | NaN | NaN | NaN | 0.586739 | -1.036641e-17 | -0.099504 | 0.094655 | NaN | -1.000000 | ... | NaN | 0.566266 | 0.408248 | 0.448943 | -0.625000 | 9.128709e-02 | 0.224934 | 0.493881 | 0.336011 | 0.701646 |
| 27 | 0.189437 | NaN | NaN | 0.101143 | 0.000000 | 4.821188e-01 | -0.117892 | -0.108465 | 1.000000 | 0.654654 | ... | 0.198030 | -0.255678 | -0.318164 | 0.114708 | 0.194420 | -4.161383e-02 | 0.058042 | 0.018718 | 0.707107 | -0.199442 |
| 28 | -0.014257 | -0.166667 | 0.204140 | 0.125013 | 0.201241 | -1.383784e-01 | 0.000068 | 0.056400 | -0.057640 | -0.051243 | ... | 0.122248 | 0.104556 | 0.040900 | 0.031379 | 0.064034 | 7.209501e-02 | -0.123055 | 0.202252 | 0.337080 | 0.176014 |
| 29 | -0.070495 | -0.310087 | NaN | 0.455842 | -0.681385 | 7.145774e-01 | -0.428521 | -0.298807 | NaN | 0.568982 | ... | 0.132353 | 0.030802 | 0.560054 | 0.426401 | 0.368782 | -5.475182e-17 | 0.372222 | 0.032340 | 0.174078 | 0.048994 |
| 30 | -0.142857 | NaN | NaN | NaN | 0.500000 | 1.000000e+00 | 0.105577 | NaN | NaN | NaN | ... | NaN | NaN | -0.303770 | NaN | 0.403473 | 4.536438e-01 | -0.312255 | 0.402953 | 0.500000 | -0.251636 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 581 | 0.000000 | -0.790569 | NaN | 0.688499 | NaN | -5.000000e-01 | 0.069077 | 1.000000 | NaN | 0.324953 | ... | 0.223836 | 1.000000 | -0.311400 | NaN | -0.297936 | -4.707512e-03 | 0.069843 | -0.247073 | NaN | -0.107907 |
| 582 | 0.250000 | 0.044194 | NaN | -0.613941 | NaN | NaN | -0.325818 | NaN | NaN | 0.135653 | ... | 0.093532 | NaN | 0.400000 | NaN | -0.027639 | -1.935282e-02 | 0.577350 | 0.438529 | NaN | 0.415336 |
| 583 | -0.037878 | NaN | NaN | -0.793045 | -0.612372 | -1.477635e-01 | -0.300123 | -0.663403 | NaN | -0.380072 | ... | 0.583333 | -0.080845 | 0.249950 | -0.391965 | 0.310530 | 2.557321e-01 | -1.000000 | -0.048508 | NaN | -0.099776 |
| 584 | -0.076086 | NaN | NaN | -0.127294 | 0.257629 | 4.749685e-01 | 0.132260 | 0.078422 | NaN | 0.514259 | ... | NaN | 0.154225 | -0.105695 | 0.078851 | 0.116250 | -1.458650e-01 | 0.709014 | -0.104141 | -0.032978 | 0.521057 |
| 585 | 0.055703 | 0.000000 | NaN | 0.058537 | NaN | 5.000000e-01 | -0.174078 | NaN | 1.000000 | -0.894675 | ... | -0.500000 | 0.250000 | -0.103975 | 1.000000 | -1.000000 | 1.836735e-01 | 0.577350 | 0.001186 | NaN | 0.059085 |
| 586 | 0.163573 | -0.197203 | NaN | -0.170842 | -0.423659 | 2.995523e-01 | 0.036261 | -0.198539 | 0.142857 | 0.101297 | ... | 0.112945 | 0.224965 | -0.343401 | -0.286770 | 0.376335 | -6.999917e-02 | -0.343266 | 0.102785 | 0.342594 | 0.038017 |
| 587 | -0.302195 | NaN | -0.500000 | -0.259693 | 0.704361 | 3.380148e-02 | -0.253046 | 0.094555 | -0.277350 | -0.126745 | ... | 0.194257 | 0.302627 | -0.079892 | 0.724882 | 0.066567 | 1.583314e-01 | -0.125983 | 0.212576 | 0.166667 | 0.396926 |
| 588 | -0.028161 | -1.000000 | NaN | 0.357217 | 0.314098 | 7.215966e-02 | 0.474101 | 0.084579 | NaN | -1.000000 | ... | 0.870388 | 0.476251 | -0.019080 | 0.102512 | -0.498922 | 5.858504e-01 | 0.642569 | 0.531998 | 0.373737 | 0.198529 |
| 589 | -0.388075 | NaN | NaN | -0.052342 | 0.484248 | 4.108614e-01 | -0.133631 | 0.116775 | NaN | NaN | ... | NaN | 0.317258 | 0.164717 | 0.520855 | -0.868243 | 3.984854e-01 | -0.290129 | 0.370555 | 0.885438 | -0.154303 |
| 590 | 0.311182 | 0.000000 | -0.471728 | 0.388334 | 0.402967 | 1.119786e-01 | 0.449615 | 0.323569 | 0.486943 | 0.110148 | ... | 0.331841 | 0.498185 | 0.337366 | 0.317766 | 0.300918 | 5.564658e-01 | 0.152790 | 0.231666 | 0.280692 | 0.522279 |
| 591 | 0.280875 | NaN | NaN | -0.024876 | NaN | 9.449112e-01 | 0.038029 | NaN | NaN | 0.399381 | ... | -0.468521 | 0.188982 | -0.044991 | NaN | 0.687500 | -8.918451e-02 | 0.046176 | 0.133974 | NaN | 0.059337 |
| 592 | -0.096225 | -1.000000 | NaN | 0.054554 | -0.104103 | 3.039877e-01 | 0.140563 | 0.114093 | NaN | 0.257130 | ... | NaN | 0.225521 | -0.076214 | -0.004300 | 0.043129 | 1.934440e-01 | 0.413537 | 0.154820 | 0.037860 | 0.257958 |
| 593 | 0.492483 | -0.576557 | NaN | 0.239270 | 0.327896 | -1.125112e-01 | 0.230481 | 0.262538 | 0.639602 | 0.144380 | ... | -0.006489 | 0.398806 | 0.259879 | 0.787234 | 0.210114 | 4.502224e-01 | -0.298675 | 0.202490 | 0.726816 | 0.271216 |
| 594 | 0.198460 | NaN | NaN | -0.082305 | 0.145599 | 2.379293e-01 | 0.311258 | -0.450281 | NaN | 0.011086 | ... | 0.259828 | 0.098512 | -0.233680 | -0.270617 | -0.153040 | -1.051694e-01 | -0.115238 | -0.180774 | -0.650000 | -0.043506 |
| 595 | 0.509525 | NaN | NaN | 0.110432 | NaN | -8.164966e-01 | 0.471405 | NaN | NaN | NaN | ... | NaN | 0.000000 | 0.570406 | NaN | NaN | 1.544249e-01 | NaN | 0.745356 | NaN | 0.894427 |
| 596 | 0.563226 | 0.494077 | 0.607764 | -0.065938 | 0.406382 | 3.363921e-01 | 0.539608 | 0.680877 | 0.367607 | -0.200189 | ... | 0.187672 | 0.056980 | 0.375950 | 0.319438 | 0.325484 | 3.417831e-01 | 0.184548 | 0.226736 | 0.141421 | 0.477917 |
| 597 | 0.427029 | NaN | -0.352130 | 0.202100 | 0.519907 | -8.959725e-02 | 0.088391 | 0.176200 | 0.572078 | -0.592220 | ... | 0.475923 | 0.254153 | 0.333188 | -0.123988 | 0.314511 | 3.796592e-01 | 0.154189 | 0.182582 | 0.247207 | 0.342623 |
| 598 | 1.000000 | NaN | NaN | 0.277350 | NaN | NaN | 0.042796 | NaN | NaN | -1.000000 | ... | -0.225845 | NaN | -0.970725 | NaN | -0.295540 | -2.054782e-01 | NaN | -0.320427 | NaN | -0.024915 |
| 599 | 0.219768 | -0.016021 | 0.197731 | 0.080606 | 0.398080 | 6.142150e-02 | 0.251225 | 0.291301 | 0.394710 | -0.413272 | ... | 0.190302 | 0.286660 | 0.268020 | 0.031686 | 0.255495 | 3.681679e-01 | -0.029093 | 0.346733 | 0.329146 | 0.510982 |
| 600 | 0.253649 | 0.188982 | 0.104257 | 0.128722 | 0.178820 | 1.527447e-01 | 0.345327 | 0.016668 | 0.506024 | -0.106625 | ... | 0.446703 | 0.246610 | 0.137651 | 0.262475 | 0.143555 | 2.836092e-01 | -0.226531 | 0.107811 | 0.714920 | 0.325230 |
| 601 | 0.091574 | -0.387347 | NaN | -0.222113 | 0.000000 | -2.927700e-01 | -0.280496 | 1.000000 | 0.577350 | -0.397276 | ... | 1.000000 | NaN | 0.182719 | NaN | 0.412162 | 2.904896e-01 | 0.698241 | 0.473967 | 1.000000 | 0.007025 |
| 602 | 0.000000 | NaN | NaN | 0.396641 | 0.153303 | -2.749519e-02 | 0.110432 | 0.190902 | NaN | -0.944911 | ... | NaN | 1.000000 | -0.089846 | 0.231290 | 0.113515 | 1.406134e-01 | 0.217210 | 0.297646 | 0.188512 | 0.049263 |
| 603 | -0.061503 | -1.000000 | 0.433200 | 0.090090 | 0.234743 | -1.121408e-01 | 0.343649 | 0.249252 | 0.376715 | -0.424631 | ... | 0.182719 | -0.089846 | 1.000000 | 0.212682 | -0.105975 | 3.184733e-01 | 0.192787 | 0.086423 | 0.343303 | 0.270908 |
| 604 | -0.407556 | NaN | NaN | -0.080296 | 0.067791 | -9.029693e-02 | 0.560968 | 0.534375 | NaN | -1.000000 | ... | NaN | 0.231290 | 0.212682 | 1.000000 | -0.365959 | 6.829493e-01 | 0.035806 | 0.053986 | 0.641624 | 0.310611 |
| 605 | -0.164871 | NaN | NaN | 0.400124 | -0.364156 | 1.007346e-01 | 0.416186 | -0.217405 | 0.158777 | 0.268684 | ... | 0.412162 | 0.113515 | -0.105975 | -0.365959 | 1.000000 | 1.670620e-01 | -0.299641 | -0.075673 | -0.550000 | 0.462274 |
| 606 | 0.066378 | 0.583333 | -0.791334 | 0.144603 | 0.244321 | -4.919190e-02 | 0.137771 | 0.253582 | 0.572700 | -0.382955 | ... | 0.290490 | 0.140613 | 0.318473 | 0.682949 | 0.167062 | 1.000000e+00 | 0.114191 | 0.240842 | 0.533002 | 0.389185 |
| 607 | 0.174557 | NaN | -0.333333 | 0.116518 | 0.231080 | 2.556391e-01 | 0.402792 | 0.251280 | NaN | -0.241121 | ... | 0.698241 | 0.217210 | 0.192787 | 0.035806 | -0.299641 | 1.141912e-01 | 1.000000 | 0.200814 | 0.190117 | 0.106605 |
| 608 | 0.268070 | -0.125000 | -0.395092 | -0.170501 | -0.020546 | 1.254283e-01 | 0.008081 | 0.434423 | 0.336625 | -0.571043 | ... | 0.473967 | 0.297646 | 0.086423 | 0.053986 | -0.075673 | 2.408422e-01 | 0.200814 | 1.000000 | 0.488929 | 0.147606 |
| 609 | -0.175412 | NaN | NaN | -0.277350 | 0.384111 | 1.936492e-01 | 0.420288 | 0.141860 | NaN | NaN | ... | 1.000000 | 0.188512 | 0.343303 | 0.641624 | -0.550000 | 5.330018e-01 | 0.190117 | 0.488929 | 1.000000 | -0.521773 |
| 610 | -0.032086 | 0.623288 | 0.569562 | -0.043786 | 0.040582 | 1.155802e-01 | 0.341233 | 0.167931 | 0.615638 | -0.205081 | ... | 0.007025 | 0.049263 | 0.270908 | 0.310611 | 0.462274 | 3.891852e-01 | 0.106605 | 0.147606 | -0.521773 | 1.000000 |
610 rows × 610 columns
In [13]:
# 1. 找出uid用户的相似用户similar_users = user_similar[1].drop([1]).dropna()# 相似用户筛选规则:正相关的用户similar_users = similar_users.where(similar_users>0).dropna()In [16]:
similar_usersOut[16]:
userId
3 0.079819
4 0.207983
5 0.268749
8 0.469668
9 0.918559
13 0.878310
14 0.229081
15 0.232636
16 0.191851
17 0.037901
18 0.205371
19 0.325180
20 0.419641
21 0.107119
24 0.249046
26 0.141421
27 0.189437
31 0.033366
32 0.277017
33 0.088523
34 0.032356
35 0.297044
36 0.432426
38 0.246085
42 0.140809
43 0.111291
44 0.684448
45 0.267402
46 0.083333
47 0.502977
...
558 0.123876
560 0.086872
561 0.205417
562 0.022797
567 0.004302
568 0.144338
570 0.148609
572 0.319158
573 0.054390
574 0.643796
575 0.422577
577 0.311132
580 0.116808
582 0.250000
585 0.055703
586 0.163573
590 0.311182
591 0.280875
593 0.492483
594 0.198460
595 0.509525
596 0.563226
597 0.427029
598 1.000000
599 0.219768
600 0.253649
601 0.091574
606 0.066378
607 0.174557
608 0.268070
Name: 1, Length: 377, dtype: float64In [17]:
ratings_matrix[1].dropna().indexOut[17]:
Int64Index([ 1, 5, 7, 15, 17, 18, 19, 21, 27, 31,
...
600, 601, 603, 604, 605, 606, 607, 608, 609, 610],
dtype='int64', name='userId', length=215)In [23]:
ratings_matrix[1].indexOut[23]:
Int64Index([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10,
...
601, 602, 603, 604, 605, 606, 607, 608, 609, 610],
dtype='int64', name='userId', length=610)In [26]:
# 2. 从用户1的近邻相似用户中筛选出对物品1有评分记录的近邻用户ids = set(ratings_matrix[1].dropna().index)&set(similar_users.index)In [27]:
idsOut[27]:
{5,
15,
17,
18,
19,
21,
27,
31,
32,
33,
43,
44,
45,
46,
57,
63,
64,
66,
68,
76,
78,
82,
86,
89,
90,
91,
93,
96,
103,
107,
112,
119,
124,
130,
132,
135,
137,
140,
141,
144,
145,
151,
153,
155,
156,
159,
160,
166,
167,
169,
171,
177,
178,
182,
185,
191,
193,
200,
201,
202,
206,
214,
216,
219,
220,
223,
226,
232,
233,
234,
239,
247,
249,
254,
263,
266,
269,
270,
274,
275,
276,
282,
283,
288,
292,
304,
307,
314,
322,
323,
328,
330,
332,
336,
339,
341,
350,
357,
359,
380,
381,
385,
389,
391,
399,
401,
412,
414,
420,
422,
432,
434,
436,
438,
448,
451,
453,
456,
462,
468,
469,
470,
474,
476,
477,
480,
483,
484,
488,
490,
504,
509,
514,
517,
522,
524,
525,
533,
550,
555,
560,
561,
562,
567,
570,
572,
573,
580,
590,
596,
597,
599,
600,
601,
606,
607,
608}In [30]:
finally_similar_users = similar_users.ix[list(ids)]In [29]:
#定义两个变量,分子和分母#分子:numerator =0denominator =0In [34]:
for sim_uid,similarty in finally_similar_users.iteritems(): #得到近邻用户的评分 sim_user_rated_movies = ratings_matrix.loc[sim_uid].dropna() #print(sim_user_rated_movies) sim_user_rating_for_item1 = sim_user_rated_movies[1] #计算分子和分母 #分子: numerator += similarty*sim_user_rating_for_item1 denominator += similartyIn [35]:
predict_rating = numerator/denominatorIn [36]:
predict_ratingOut[36]:
3.872341815681296In [37]:
def predict(uid, iid, ratings_matrix, user_similar): ''' 预测给定用户对给定物品的评分值 :param uid: 用户ID :param iid: 物品ID :param ratings_matrix: 用户-物品评分矩阵 :param user_similar: 用户两两相似度矩阵 :return: 预测的评分值 ''' print("开始预测用户<%d>对电影<%d>的评分..."%(uid, iid)) # 1. 找出uid用户的相似用户 similar_users = user_similar[uid].drop([uid]).dropna() # 相似用户筛选规则:正相关的用户 similar_users = similar_users.where(similar_users>0).dropna() if similar_users.empty is True: raise Exception("用户<%d>没有相似的用户" % uid) # 2. 从uid用户的近邻相似用户中筛选出对iid物品有评分记录的近邻用户 ids = set(ratings_matrix[iid].dropna().index)&set(similar_users.index) finally_similar_users = similar_users.ix[list(ids)] # 3. 结合uid用户与其近邻用户的相似度预测uid用户对iid物品的评分 numerator = 0 # 评分预测公式的分子部分的值 denominator = 0 # 评分预测公式的分母部分的值 for sim_uid, similarity in finally_similar_users.iteritems(): # 近邻用户的评分数据 sim_user_rated_movies = ratings_matrix.ix[sim_uid].dropna() # 近邻用户对iid物品的评分 sim_user_rating_for_item = sim_user_rated_movies[iid] # 计算分子的值 numerator += similarity * sim_user_rating_for_item # 计算分母的值 denominator += similarity # 计算预测的评分值并返回 predict_rating = numerator/denominator print("预测出用户<%d>对电影<%d>的评分:%0.2f" % (uid, iid, predict_rating)) return round(predict_rating, 2)In [38]:
def predict_all(uid, ratings_matrix, user_similar): ''' 预测全部评分 :param uid: 用户id :param ratings_matrix: 用户-物品打分矩阵 :param user_similar: 用户两两间的相似度 :return: 生成器,逐个返回预测评分 ''' # 准备要预测的物品的id列表 item_ids = ratings_matrix.columns # 逐个预测 for iid in item_ids: try: rating = predict(uid, iid, ratings_matrix, user_similar) except Exception as e: print(e) else: yield uid, iid, ratingif __name__ == '__main__': for i in predict_all(1, ratings_matrix, user_similar): pass开始预测用户<1>对电影<1>的评分...
预测出用户<1>对电影<1>的评分:3.87
开始预测用户<1>对电影<2>的评分...
预测出用户<1>对电影<2>的评分:3.38
开始预测用户<1>对电影<3>的评分...
预测出用户<1>对电影<3>的评分:3.14
开始预测用户<1>对电影<4>的评分...
预测出用户<1>对电影<4>的评分:2.41
开始预测用户<1>对电影<5>的评分...
预测出用户<1>对电影<5>的评分:3.09
开始预测用户<1>对电影<6>的评分...
预测出用户<1>对电影<6>的评分:3.83
开始预测用户<1>对电影<7>的评分...
预测出用户<1>对电影<7>的评分:3.22
开始预测用户<1>对电影<8>的评分...
预测出用户<1>对电影<8>的评分:2.47
开始预测用户<1>对电影<9>的评分...
预测出用户<1>对电影<9>的评分:2.59
开始预测用户<1>对电影<10>的评分...
预测出用户<1>对电影<10>的评分:3.41
开始预测用户<1>对电影<11>的评分...
预测出用户<1>对电影<11>的评分:3.68
开始预测用户<1>对电影<12>的评分...
预测出用户<1>对电影<12>的评分:2.49
开始预测用户<1>对电影<13>的评分...
预测出用户<1>对电影<13>的评分:3.19
开始预测用户<1>对电影<14>的评分...
预测出用户<1>对电影<14>的评分:4.23
开始预测用户<1>对电影<15>的评分...
In [39]:
results = predict_all(1, ratings_matrix, user_similar)In [41]:
sorted(results, key=lambda x: x[2], reverse=True)[:20]开始预测用户<1>对电影<1>的评分...
预测出用户<1>对电影<1>的评分:3.87
开始预测用户<1>对电影<2>的评分...
预测出用户<1>对电影<2>的评分:3.38
开始预测用户<1>对电影<3>的评分...
预测出用户<1>对电影<3>的评分:3.14
开始预测用户<1>对电影<4>的评分...
预测出用户<1>对电影<4>的评分:2.41
开始预测用户<1>对电影<5>的评分...
预测出用户<1>对电影<5>的评分:3.09
开始预测用户<1>对电影<6>的评分...
预测出用户<1>对电影<6>的评分:3.83
开始预测用户<1>对电影<7>的评分...
预测出用户<1>对电影<7>的评分:3.22
开始预测用户<1>对电影<8>的评分...
预测出用户<1>对电影<8>的评分:2.47
开始预测用户<1>对电影<9>的评分...
预测出用户<1>对电影<9>的评分:2.59
开始预测用户<1>对电影<10>的评分...
开始预测用户<1>对电影<13>的评分...
预测出用户<1>对电影<13>的评分:3.19
开始预测用户<1>对电影<14>的评分...
预测出用户<1>对电影<14>的评分:4.23
开始预测用户<1>对电影<15>的评分...
预测出用户<1>对电影<15>的评分:2.79
开始预测用户<1>对电影<16>的评分...
预测出用户<1>对电影<16>的评分:3.98
开始预测用户<1>对电影<17>的评分...
预测出用户<1>对电影<17>的评分:3.88
开始预测用户<1>对电影<18>的评分...
预测出用户<1>对电影<18>的评分:3.61
开始预测用户<1>对电影<19>的评分...
预测出用户<1>对电影<19>的评分:2.77
开始预测用户<1>对电影<20>的评分...
Out[41]:
[(1, 99, 5.0),
(1, 123, 5.0),
(1, 148, 5.0),
(1, 271, 5.0),
(1, 484, 5.0),
(1, 496, 5.0),
(1, 549, 5.0),
(1, 633, 5.0),
(1, 876, 5.0),
(1, 1105, 5.0),
(1, 1150, 5.0),
(1, 1151, 5.0),
(1, 1406, 5.0),
(1, 1533, 5.0),
(1, 1596, 5.0),
(1, 1631, 5.0),
(1, 1696, 5.0),
(1, 2075, 5.0),
(1, 2131, 5.0),
(1, 2196, 5.0)]















 2411
2411











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











