







 日萌社
日萌社
人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新)
1.监督学习
1.监督学习的 例子一:预测房价
假设现在有一栋750平方英尺的房子,能卖多少钱
1.给算法一个数据集,其中包含正确答案,也就是说我们给算法一个房价数据集,在这个数据集中的每个样本我们都给出正确的价格,
即这个房子的实际卖价,算法的目的就是给出更多正确答案。
2.回归问题:
假如要给一套新房子给出估价,用更专业的术语来称呼这为回归问题。
这里的回归问题指的是想要预测连续的数值输出,也就是价格,技术而言,价格能够被圆整到分,因此价格实际上是个离散值,
但通常我们认为房价是一个实数,标量或是连续值,回归这个术语是指我们设法预测连续值的属性。
3.数据集绘图如下:横轴是不同房屋的平方英尺数,纵轴是不同房子的价格,单位是千美元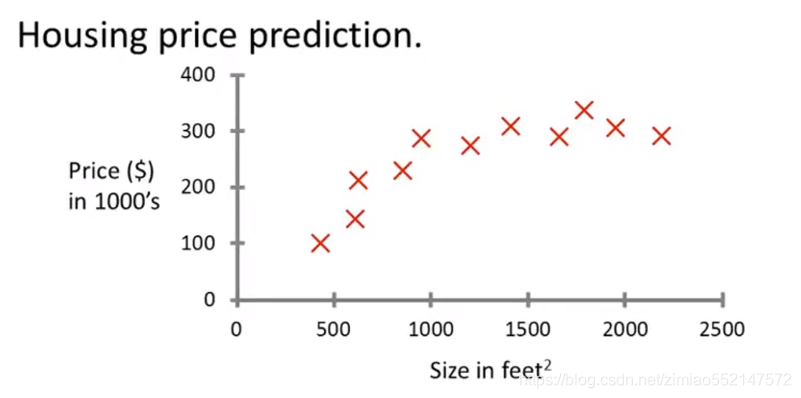
4.情况一:学习算法根据数据画一条直线,或者说一条直线拟合数据,基于此看上去房子能卖大约15万美元 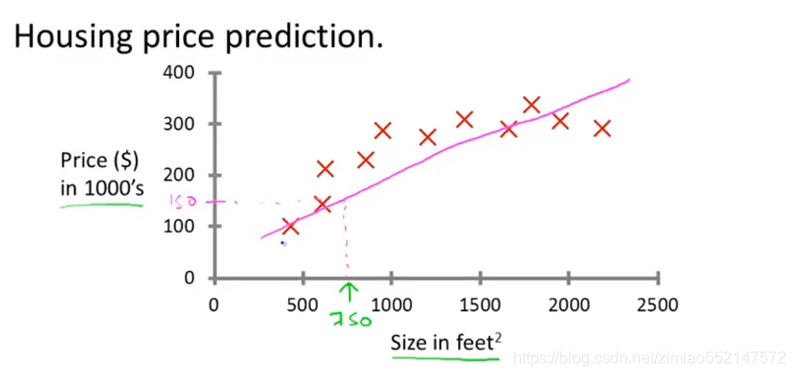
5.情况二:用二次函数 或 二阶多项式 来拟合数据,在蓝色线上可以出能卖大约 20万美元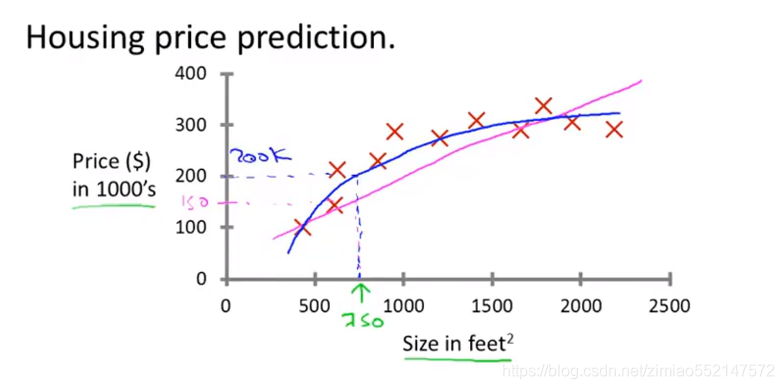
2.监督学习的 例子二:
假设看医疗记录,并且设法预测乳腺癌是恶性还是良性
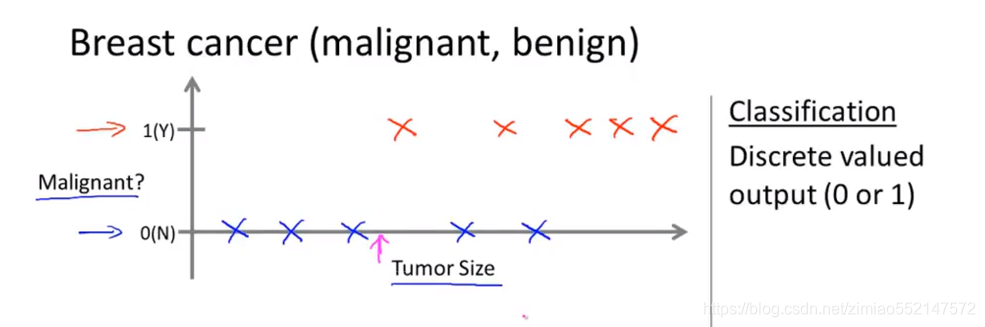
1.收集到的数据集如下:横轴是肿瘤尺寸,纵轴上的1代表恶性,0代表良性
2.情况一:下面一行有5个良性肿瘤样本,对应纵轴上的0,上面一行有5个恶性肿瘤样本,对应纵轴上的1。
问题:假设现在有一个乳腺癌的大小在这个值上(粉红色箭头),机器学习的问题就是能否估计出该肿瘤是良性还是恶性的概率分别是多少。
分类问题:此问题用更专业的术语可称呼为分类问题,分类是指设法预测一个离散值输出为 0(良性) 或 1(恶性)。
实际在分类问题中,有时也存在两个以上的可能的输出值,在实际例子中,可能存在有3种类型的乳腺癌,
因此便需要设法预测离散值为0,1,2或3,其中0代表良性,1代表第一种类型的乳腺癌,2代表第二种类型的乳腺癌,
3代表第三种类型的乳腺癌,这便是一组离散的输出值。
3.情况二:
在分类问题中,有另外一种方法来绘制这些数据,首先用一组不同的符号来绘制这组数据,如果肿瘤的大小是用来预测恶性或良性的特征,
将用不同的符号来表示良性或恶性,或者说阴性或阳性样本。
现在使用“○”来表示良性,用“×”来表示恶性,目的是把上面的数据集对应下来到最下面的实线上。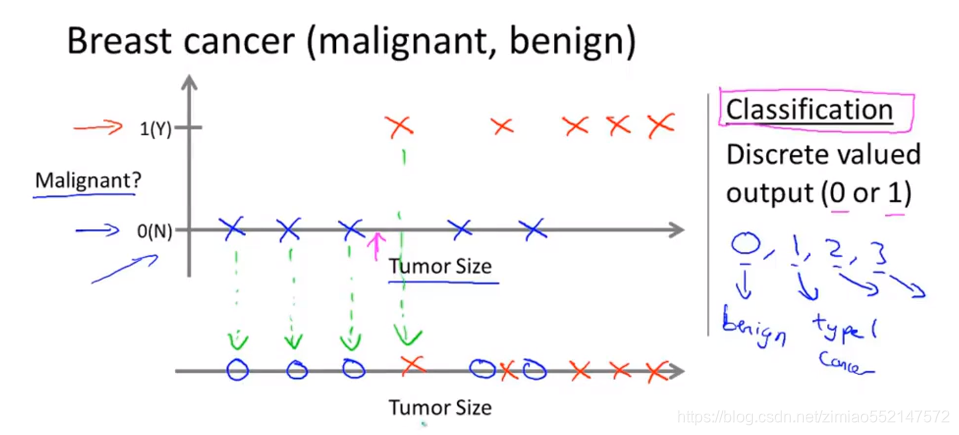
4.情况三:
1.此例子有两种特征(两种属性),比如知道肿瘤大小(横轴),病人年纪(纵轴),收集到的数据集如下。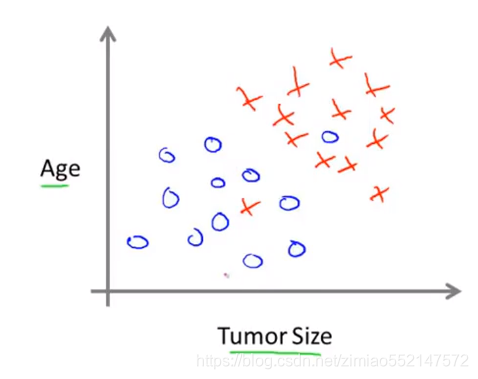
2.假设现在有一新肿瘤(粉红色圆点),对应横轴上的肿瘤大小(粉红箭头),对应纵轴上的病人年纪(粉红箭头)。
此时在给定的数据集上,学习算法可以在数据上画一条黑色直线设法将良性(“○”)和恶性(“×”)分开,
此时可以通过这样来判断这一新肿瘤(粉红色圆点)的类型,此时学习算法判断位于良性区域,即良性的概率大于恶性的概率。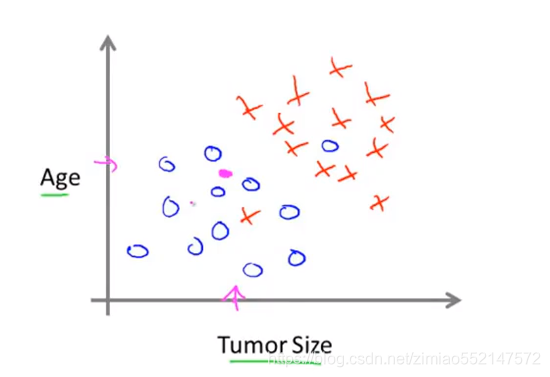
5.情况四:
在更多的机器学习的例子中,一般都有更多的特征(更多的属性),比如肿瘤厚度,肿瘤细胞大小的均匀性,肿瘤细胞形状的均匀性,以及其他特征。
在更多的机器学习的例子中,可以是无穷多的特征(无穷多很属性),因此学习算法就需要用很多特征(属性)或线索来做预测,
那么如何处理无穷多的特征(属性),如何在计算机中存储无穷多数量的事物,你的计算机可能溢出。
以支持向量机算法为例,允许计算机处理无穷多特征,假设有无数多的特征,我们还是能够设计一个算法来处理这种情况。
3.总结:
在监督学习中,对于数据集中的每个样本,想要通过算法预测得出正确答案,比如房价,肿瘤类型。
回归问题:回归的目标是预测一个连续值输出。
分类问题:目的是预测离散值输出。
4.提问:判断以下问题是属于回归问题还是属于分类问题
1.第一个提问:你有很多同一件货物的库存,假设你有数千件相同货物要卖,现在要预测接下来3个月能卖多少件?
答案:回归问题
原因:因为假设我有数千个货物,我将它看成一个实数,即一个连续的值,即把我要卖的货物数量看作是一个连续的值
2.第二提问:你有很多客户,想要写一个软件来检查每一个客户的账户,对于每一个客户的账户,要判断这个账户是否被入侵或破坏?
答案:分类问题
原因:比如我设置预测值为0表示账户没有被入侵,设置预测值为1表示账户被入侵,使用算法来预测这两个离散值,
因为只有少量的离散值,所以把它作为一个分类问题



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











